Архитектура персонального компьютера — online presentation
1. Архитектура персонального компьютера
2. Магистрально-модульный принцип построения компьютера
• Модульность позволяет потребителюсамому комплектовать нужную ему
конфигурацию компьютера и производить
при необходимости ее модернизацию.
• Модульная организация компьютера
опирается на магистральный (шинный)
принцип обмена информацией между
устройствами.
3. Магистраль — три различные шины,
через которые• подключаются процессор и оперативная
память, а также периферийные устройства
ввода, вывода и хранения информации;
• устройства обмениваются информацией в
форме последовательностей нулей и
единиц, реализованных электрическими
импульсами.
4. Чипсет
Современные компьютеры содержат двеосновные большие микросхемы чипсета:
контроллер-концентратор памяти, или
Северный мост (англ. North Bridge), который
обеспечивает работу процессора с оперативной
памятью и с видеоподсистемой;
контроллер-концентратор ввода/вывода, или
Южный мост (англ.

обеспечивающий работу с внешними
устройствами.
5. Пропускная способность шины
Пропускная способность шины (бит/с) равнапроизведению разрядности шины (в битах) и
частоты шины (в герцах — Гц, 1 Гц = 1 такт в
секунду):
пропускная способность шины = разрядность
шины * частота шины
Такт — это промежуток времени между подачами
электрических импульсов, синхронизирующих
работу устройств компьютера.
6. Системная шина – между Северным мостом и процессором (FSB от англ. FrontSide Bus).
Частота системной шины может составлять 400 МГц.Однако между Северным мостом и процессором эффективная
частота передачи данных в 4 раза выше.
Процессор может получать и передавать данные с частотой 400
МГц * 4 = 1600 МГц.
процессора и составляет 64 бита, то пропускная способность
системной шины равна:
64 бита * 1600 МГц = 102400 Мбит/с = = 100 Гбит/с = 12,5
Гбайт/с.

7. Частота процессора
В процессоре используется внутреннееумножение частоты, поэтому частота
процессора в несколько раз больше, чем
частота системной шины.
Это означает, что процессор за один такт шины
способен генерировать 8 своих внутренних
тактов и, следовательно, частота процессора
составляет
400 МГц * 8 = 3,2 ГГц.
8. Шина памяти – обмен данными между северным мостом и оперативной памятью
У современных модулей памяти (DDR3 от англ. double-data-rate) частотапамять получает данные с такой же частотой, что и процессор.
Так как разрядность шины памяти равна разрядности процессора и
составляет 64 бита, то пропускная способность шины памяти также
равна:
64 бита * 1600 МГц = 102 400 Мбит/с = = 100 Гбит/с = 12,5 Гбайт/с = 12
800 Мбайт/с.
Модули памяти маркируются своей пропускной способностью, выраженной
в Мбайт/с: РС4200, РС8500, РС12800 и др.

9. Шина PCI Express
Для подключения видеоплаты к северномумосту шина (Peripherial Component
взаимодействия периферийных устройств).
Пропускная способность этой шины может
достигать 32 Гбайт/с.
10. Шина SATA
Устройства внешней памяти (жесткие диски,CD- и DVD-дисководы) подключаются к
южному мосту по шине SATA (англ. Serial
Advanced Technology Attachment последовательная шина подключения
накопителей).
Скорость передачи данных по которой может
достигать 300 Мбайт/с.
11. Шина USB
Для подключения принтеров, сканеров, цифровыхкамер и других периферийных устройств обычно
используется шина USB (Universal Serial Bus универсальная последовательная шина).
Эта шина обладает пропускной способностью до 60
компьютеру одновременно до 127 периферийных
устройств (принтер, сканер, цифровая камера, Webкамера, модем и др.
 ).
).12. Увеличение производительности процессора
Увеличение производительности процессоровза счет увеличения частоты имеет свой
предел из-за тепловыделения.
Выделение процессором теплоты Q
пропорционально потребляемой мощности
Р, которая, в свою очередь,
пропорциональна квадрату частоты v :
Q ~ Р ~ v2.
13. Архитектура персонального компьютера
14. Увеличение производительности процессора
Увеличение производительности процессора, азначит и компьютера, достигается за счет
увеличения количества ядер процессора
(арифметических логических устройств).
или четыре ядра, что позволяет распараллелить
вычисления и повысить производительность
процессора.
15. Контрольные вопросы
В чем состоит магистрально-модульныйпринцип построения компьютера?
Какие устройства обмениваются
информацией через Северный мост?
Какие устройства обмениваются
информацией через Южный мост?
В каком направлении развивается
архитектура процессоров?
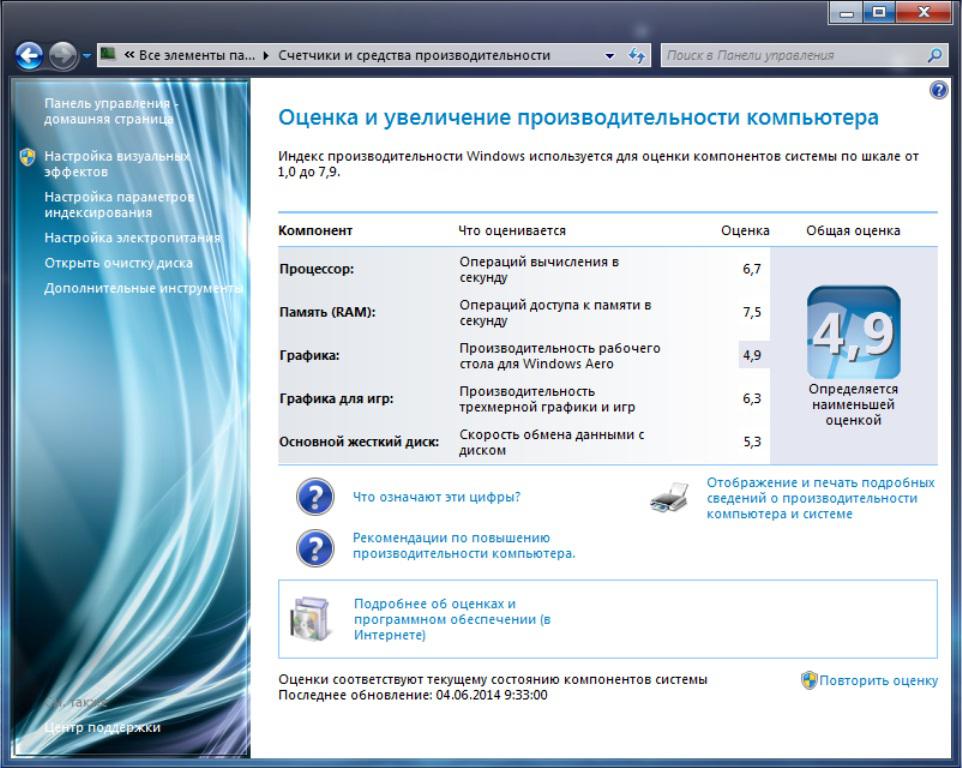
Об устранении неполадок управления питанием в Windows 7
PowerCFG
PowerCFG является мощным средством командной строки, помогает при диагностике неполадок управления питанием.
Ниже перечислены наиболее распространенные команды, которые можно использовать для определения состояния сна и параметры по умолчанию.
-
POWERCFG -L или POWERCFG -LIST
Данная команда сначала. Эта команда выводит список всех схем управления питанием в текущей пользовательской среде. Схема управления питанием, перечисленных со звездочкой (*) – схему управления питанием.
-
POWERCFG -Q или POWERCFG-запрос
Во-вторых, используйте эту команду.
 Затем можно определить точные параметры, которые применяются. Эта команда выводит содержимое схемы управления питанием. Для перенаправления списка в файл, используйте команду, подобную следующей:
Затем можно определить точные параметры, которые применяются. Эта команда выводит содержимое схемы управления питанием. Для перенаправления списка в файл, используйте команду, подобную следующей:Powercfg -Q > c:\test.txt
-
Wake_armed POWERCFG — DEVICEQUERY
Эта команда используется для определения устройств, которые установлены так, что пользователь может Разбудить компьютер.
Для мобильных ПК эта команда может показать устройства следующим образом:
-
Стандартной 101/102 клавиши
-
Клавиатура Microsoft Natural PS/2 с HP QLB
-
Сенсорная панель Synaptics PS/2 порт
Для настольного компьютера эта команда может показать устройства следующим образом:-
HID-совместимая мышь (002)
-
Broadcom NetXtreme Gigabit Ethernet
-
Устройство HID клавиатуры (002)
-
 Затем можно определить точные параметры, которые применяются. Эта команда выводит содержимое схемы управления питанием. Для перенаправления списка в файл, используйте команду, подобную следующей:
Затем можно определить точные параметры, которые применяются. Эта команда выводит содержимое схемы управления питанием. Для перенаправления списка в файл, используйте команду, подобную следующей:Дополнительные сведения о параметрах PowerCFG запустить POWERCFG /? команды.
Параметры командной строки Powercfg
Советы по устранению неполадок
Ниже приведены советы, что нужно учитывать при устранении неполадок управления питанием в Windows 7.
-
Каково назначение компьютера? Это мобильный ПК, опыт высокопроизводительные способствовать? Это сервер центра обработки данных класса с критически важных установлен SQL? Или это что-то между ними?
-
Есть ли в компьютере установлена новейшая версия BIOS? Это важно при исследовании проблемы питания.
-
Что такое установок BIOS, которые доступны? Просмотрите параметры BIOS.
Как правило пользователь может изменить параметры, влияющие на операционную систему. Изготовители оборудования могут предоставлять метод _OSC ACPI для включения операционной системы для настройки параметров BIOS. Например режим контроллера домена для мобильных ПК может задать уровень P-СОСТОЯНИЯ производительности Процессора. Операционная система сможет изменить этот параметр, если поставщик BIOS не разрешил операционной системе стать владельцем этого ресурса. ПВТ могут также настроить BIOS и оборудования таким образом, совместимые со стандартами набор нормативных требований. В этих случаях изменение параметров может оказаться вариант. Эти параметры могут даже не появляется в консоли управления питанием. -
Были изменены параметры по умолчанию для схемы управления питанием? Чтобы определить это, с помощью команды POWERCFG -Q . Если изменены параметры по умолчанию, сброс текущей схемы управления питанием. Часто пользователь или системный администратор может настроить схемы управления питанием.
Помните, что групповая политика может применяться; Изменение политики питания, который управляется групповой политики продолжается только до входа в систему снова. Администратор может полностью заблокировать изменения или элементы из списка могут быть удалены из использования. На эти вопросы необходимо обратиться к администратору, а при использовании удаленного рабочего стола для внесения изменений необходимо подключиться с правами администратора. Главное помнить, что не все политики питания подходят для всех пользователей и их конкретного оборудования. -
Схемы управления питанием могут быть настроены администратором, приложением питания или с помощью групповой политики. Проверьте эти элементы, прежде чем продолжить устранение неполадок. Прежде чем запустить любой диагностики или восстановления схемы управления питанием с помощью параметра восстановить параметры по умолчанию для этого плана , должен сохранить текущие параметры с помощью POWERCFG-Экспорт команды.
Можно также нажать кнопку Создать план электропитания и затем настроить параметры настроенный план. При повреждении схем управления питанием, схем управления питанием можно восстановить настройки по умолчанию. Эта операция перезапишет все схемы по умолчанию.Чтобы восстановить схем управления питанием по умолчанию, выполните следующие действия.
-
Нажмите кнопку Пуск.
-
Введите команду cmdв поле Найти программы и файлы .
-
Щелкните правой кнопкой мыши CMDи нажмите кнопку Запуск от имени администратора.
-
В командной строке введите powercfg — restoredefaultschemesи нажмите клавишу ВВОД.
-
В командной строке введите exit для выхода из окна командной строки.
-
Перезагрузите компьютер.
-
-
Компьютер имеет ПВТ приложения управления питанием, установлена? Если это так, искать обновления и тестирования, отключите его. Во многих случаях ПВТ может дополнить политик управления питанием путем настройки политик для их конкретного устройства. Когда приложение управления питанием работает неправильно, обратитесь к производителю.
-
Просмотрите обновления Windows. Центр обновления Windows является ключевой элемент для просмотра. Кроме того убедитесь, что поиск в базе знаний Майкрософт об известных проблемах. Центр обновления Windows обновления драйверов, может относиться к текущей проблемы. Во многих случаях обновленные драйверы, перечислены в разделе «Дополнительно» Центр обновления Windows.
 Как правило пользователь может изменить параметры, влияющие на операционную систему. Изготовители оборудования могут предоставлять метод _OSC ACPI для включения операционной системы для настройки параметров BIOS. Например режим контроллера домена для мобильных ПК может задать уровень P-СОСТОЯНИЯ производительности Процессора. Операционная система сможет изменить этот параметр, если поставщик BIOS не разрешил операционной системе стать владельцем этого ресурса. ПВТ могут также настроить BIOS и оборудования таким образом, совместимые со стандартами набор нормативных требований. В этих случаях изменение параметров может оказаться вариант. Эти параметры могут даже не появляется в консоли управления питанием.
Как правило пользователь может изменить параметры, влияющие на операционную систему. Изготовители оборудования могут предоставлять метод _OSC ACPI для включения операционной системы для настройки параметров BIOS. Например режим контроллера домена для мобильных ПК может задать уровень P-СОСТОЯНИЯ производительности Процессора. Операционная система сможет изменить этот параметр, если поставщик BIOS не разрешил операционной системе стать владельцем этого ресурса. ПВТ могут также настроить BIOS и оборудования таким образом, совместимые со стандартами набор нормативных требований. В этих случаях изменение параметров может оказаться вариант. Эти параметры могут даже не появляется в консоли управления питанием. Помните, что групповая политика может применяться; Изменение политики питания, который управляется групповой политики продолжается только до входа в систему снова. Администратор может полностью заблокировать изменения или элементы из списка могут быть удалены из использования. На эти вопросы необходимо обратиться к администратору, а при использовании удаленного рабочего стола для внесения изменений необходимо подключиться с правами администратора. Главное помнить, что не все политики питания подходят для всех пользователей и их конкретного оборудования.
Помните, что групповая политика может применяться; Изменение политики питания, который управляется групповой политики продолжается только до входа в систему снова. Администратор может полностью заблокировать изменения или элементы из списка могут быть удалены из использования. На эти вопросы необходимо обратиться к администратору, а при использовании удаленного рабочего стола для внесения изменений необходимо подключиться с правами администратора. Главное помнить, что не все политики питания подходят для всех пользователей и их конкретного оборудования. Можно также нажать кнопку Создать план электропитания и затем настроить параметры настроенный план. При повреждении схем управления питанием, схем управления питанием можно восстановить настройки по умолчанию. Эта операция перезапишет все схемы по умолчанию.
Можно также нажать кнопку Создать план электропитания и затем настроить параметры настроенный план. При повреждении схем управления питанием, схем управления питанием можно восстановить настройки по умолчанию. Эта операция перезапишет все схемы по умолчанию.

Часто задаваемые вопросы
Q1: Почему мой компьютер пробуждения ежедневно в 12:48 и запустите средство диагностики?
A1: Чтобы определить, почему это происходит, используйте параметр — WAKETIMERS для определения того, что в данный момент находится. Запланированными задачами являются одним из основных элементов, которые будут отображаться параметр — WAKETIMERS . Чтобы использовать этот параметр, выполните следующую команду:
POWERCFG — WAKETIMERSПримечание. Если компьютер является OEM-производителями, результаты данной команды может выглядеть следующим образом:
Истечения срока действия таймера задается имя_процесса\Device\HarddiskVolume2\Windows\System32\svchost.exe в 12:48:06 AM на 9/15/2010.
Причина: Планировщик заданий выполнит задачу «\OEM\OEM Assistant Application\First Boot».
Q2: Как определить все доступные сна?
A2: Используйте параметр — AVAILABLESLEEPSTATES . Чтобы сделать это, выполните следующую команду:
POWERCFG-AVAILABLESLEEPSTATESПример 1.
Ниже приведен пример сна на мобильных ПК у поставщика вычислительной Техники:
Следующие состояния спящего режима доступны в этой системе: ждущий режим (S3) Гибернация гибридный спящий режим
Следующие состояния спящего режима недоступны в данной системе:
Ждущий режим (S1)
Системные микропрограммы не поддерживают ждущий режим.
Ждущий режим (S2)
Системные микропрограммы не поддерживают ждущий режим.
Пример 2
Ниже приведен пример случая, в котором отключаются состояния сна. В этом примере был создан путем удаления текущий драйвер видеоадаптера и с помощью драйвера VGA. Драйвер VGA не поддерживает состояния сна и не опрашивать устройство для поддержки состояния спящий режим поддерживается. Windows опрашивает не только драйвер, но BIOS, прежде чем он позволяет любого состояния сна.
Следующие состояния спящего режима недоступны в данной системе:
Ждущий режим (S1)
Системные микропрограммы не поддерживают ждущий режим.
Внутренний системный компонент отключил ждущий режим.
Ждущий режим (S2)
Системные микропрограммы не поддерживают ждущий режим.
Внутренний системный компонент отключил ждущий режим.
Ждущий режим (S3)
Внутренний системный компонент отключил ждущий режим.
Спящий режим
Внутренний системный компонент отключил спящего режима.
Гибридный спящий режим
Примечание. Не забудьте проверить элемент Электропитание в панели управления и в BIOS компьютера, поскольку доступных режимов сна можно включить или отключить в этих местах.
Q3: Почему времени автономной работы на мобильном ПК на дисплее VGA уменьшить после Обновления до Windows 7 с Windows XP?
A3: Это общие проблемы, в котором отображения используется стандартный драйвер VGA. Этот драйвер не оптимизирован для видеокарты и будет потреблять больше энергии. Чтобы устранить эту проблему, обновите драйвер видеоадаптера.
Этот драйвер не оптимизирован для видеокарты и будет потреблять больше энергии. Чтобы устранить эту проблему, обновите драйвер видеоадаптера.
Q4: Почему не удается просмотреть некоторые параметры управления электропитанием?
A4: Windows 7 не удается отобразить параметры управления питанием, компьютер не поддерживает.
Вопрос 5: Как определить ли групповая политика действует и перезагрузки или рекомендацией конкретного питанием?
A5: Команда Gpresult . Эта команда отображает параметры питания применяются. Дополнительные сведения о команде Gpresult посетите следующий веб-узел Microsoft TechNet:
GpresultТакже схему управления питанием можно настроить с помощью настройки политики. Кроме того можно включить трассировку неполадок предпочтения, относящиеся к параметрам питания.
Вопрос 6: Как можно настроить схему управления питанием на месте, без перезапуска?
A6: С помощью команды POWERCFG — SETACTIVE {GUID} . Например выполните команду, подобную следующей:
Например выполните команду, подобную следующей:
8c5e7fda-e8bf-4a96-9a85-a6e23a8c635c — SETACTIVE POWERCFGЗапустите команду POWERCFG/l для просмотра изменений в режиме реального времени. Ниже приведен пример просмотра при выполнении команды POWERCFG/l :
Существующие схемы управления питанием (* активный)
GUID схемы питания: 381b4222-f694-41f0-9685-ff5bb260df2e (Сбалансированный)
GUID схемы питания: 8c5e7fda-e8bf-4a96-9a85-a6e23a8c635c (высокая производительность) *
GUID схемы питания: a1841308-3541-4fab-bc81-f71556f20b4a (энергосберегающая)
Q7: Компьютер работает медленно на «Энергосберегающая» схемы управления питанием и быстрее, чем ожидалось сток батареи. Что можно сделать? Выявлять, что происходит?
A7: Чтобы диагностировать проблему, создайте отчет питания. Чтобы сделать это, выполните следующие действия.
-
Нажмите кнопку Пуск.
-
n поле Найти программы и файлы типа cmd.
-
Щелкните правой кнопкой мыши CMDи нажмите кнопку Запуск от имени администратора.
-
В командной строке введите powercfg-энергии-вывода c:\temp\energy.html, и нажмите клавишу ВВОД.
-
В папке «Temp» откройте файл report.html энергию. Этот отчет использует 60 секунд выполнения. Тем не менее время отчета является настраиваемым. Просмотрите этот документ для ошибок и предупреждений. Информационный раздел содержит подробную информацию о плане политика питания и конфигурации компьютера во время теста.

В следующем примере показано несколько способов оптимизации работы батареи. Отчет содержит результаты, которые позволяют принимать обоснованные решения. Можно работать через всех ошибок и предупреждений для оптимизации компьютера.
Отчет содержит результаты, которые позволяют принимать обоснованные решения. Можно работать через всех ошибок и предупреждений для оптимизации компьютера.
Отчет о диагностике эффективности питания
Имя компьютера имя_компьютера
Время, Дата и время сканирования
Длительность 60 секунд сканирования
Производитель системы OEM_name
Название продукта системы product_name
Дата BIOS Дата
BIOS версии version_number
Операционная система построения build_number
PlatformRoleMobile роль платформы
Подключено в true
Счетчик процессов 72
Число потоков 742
Отчет GUID {GUID}
Результаты анализа
Ошибки
-
Политика питания: Dim таймаут отключен (питание от батареи)
Отображение не настроен на автоматическое затемнять после определенного периода бездействия. -
Политика питания: политика питания стандарта 802.
11 радио является максимальной производительности (на батареи)
Текущая политика питания для адаптеров беспроводной сети 802.11-совместимый не настроен на использование режима пониженного энергопотребления. -
Политика питания: Dim таймаут отключен (питание от сети в)
Отображение не настроен на автоматическое затемнять после определенного периода бездействия. Средняя загрузка 7.38 (%)
 11 радио является максимальной производительности (на батареи)
11 радио является максимальной производительности (на батареи)
Предупреждения
-
Политика питания: Время ожидания диска является длинная (питание от батареи)
Диск настроен на отключение после более чем 30 минут. Время ожидания (в секундах) 2400 -
Политика питания: Время ожидания выключения экрана велик (питание от сети в)
Отображение настроен на отключение после более 10 минут. Время ожидания (в секундах) 900 -
Политика питания: политика питания стандарта 802.11 радио является максимальной производительности (питание от сети)
Текущая политика питания для адаптеров беспроводной сети 802.11-совместимый не настроен на использование режима пониженного энергопотребления.
 Время ожидания (в секундах) 900
Время ожидания (в секундах) 900Режим «производительность» повышает частоту смены кадров в Fortnite
УСКОРЕННАЯ ЗАГРУЗКА. ПОВЫШЕННОЕ БЫСТРОДЕЙСТВИЕ. ПОЛЬЗОВАТЕЛЯМ БОЛЕЕ СТАРЫХ КОМПЬЮТЕРОВ ДОСТУПЕН НОВЫЙ ПАРАМЕТР ДЛЯ ИГРЫ В FORTNITE.
Теперь пользователям компьютеров, отвечающих минимальным требованиям Fortnite, доступна альфа-версия режима «производительность». Его можно включить во внутриигровом меню параметров. Режим «производительность» позволит значительно повысить быстродействие, а также снизить расход оперативной памяти и нагрузку на процессор и видеокарту за счёт ухудшения качества изображения. Благодаря этому режиму у пользователей, которые играют при низких значениях параметров или на менее мощных компьютерах, игра будет работать лучше, чем прежде, а смена кадров станет стабильней.
Благодаря этому режиму у пользователей, которые играют при низких значениях параметров или на менее мощных компьютерах, игра будет работать лучше, чем прежде, а смена кадров станет стабильней.
Режим «производительность» в «дополнительных настройках графики».
Режим «производительность» доступен большинству игроков и работает только в «Королевской битве» и творческом режиме. Режим «производительность» можно в любой момент включить или отключить во внутриигровом меню параметров, после чего потребуется перезапустить игру.
Примечание: на ПК при включённом режиме «производительность» кампания «Сражение с Бурей» недоступна.
Экономия места на жёстком диске
Игроки также могут отказаться от текстур в высоком разрешении. Это можно сделать на странице настроек установки в программе запуска Epic Games. Следуйте этим инструкциям:
1. Откройте программу запуска Epic Games.
2. Выберите пункт «Библиотека».
3. Щёлкните по трём точкам рядом с надписью Fortnite.
4. Выберите «Параметры».
5. Уберите галочку рядом с опцией «Текстуры высокого разрешения».
Из файлов игры будет удалено около 14 ГБ материалов в высоком разрешении, так что итоговый размер игры составит всего 18 ГБ без всех дополнительных компонентов. Пользователям, которые играют при низких значениях параметров или с низким разрешением, это позволит освободить много места на диске за счёт небольшого ухудшения качества изображения!
Рекомендуемая конфигурация системы
Улучшение заметят все игроки, которые воспользуются режимом «производительность», но при определённой конфигурации системы игра будет работать ещё стабильнее. На более старых компьютерах с оперативной памятью 6 ГБ и больше или с игрой, установленной на диске SSD, расход памяти будет меньше, а рывки и зависания станут случаться реже. Наличие дискретной видеокарты не обязательно, однако она также поможет сбалансировать нагрузку на систему и сделает игровой процесс более комфортным.
Чего стоит ожидать?
В режиме «производительность» качество изображения в игре снизится, а частота смены кадров — повысится. Так в Fortnite смогут комфортно играть владельцы компьютеров, конфигурация которых отвечает минимальным требованиям. Наряду с возможностью удалить текстуры в высоком разрешении игра будет загружаться быстрее, чем когда-либо, причём на игровой процесс это никак не повлияет.
Ниже приведены средние значения частоты смены кадров в обычном матче для отрядов в игре, запущенной на ноутбуках с низкими значениями параметров, в сравнении с таким же матчем, но при включённом режиме «производительность». В обоих случаях выбрано разрешение 720p.
Конфигурация №1: | Конфигурация №2: |
ЦП: Intel i5-8265U (1,60 ГГц) | ЦП: AMD A10-5745M APU (2,1 ГГц) |
Оперативная память: 8 ГБ | Оперативная память: 6 ГБ |
Видеокарта: Intel UHD Graphics 620 | Видеокарта: AMD Radeon(TM) HD 8610G |
Частота смены кадров до: 24 кадра/с | Частота смены кадров до: 18 кадров/с |
Частота смены кадров после: 61 кадров/с | Частота смены кадров после: 45 кадров/с |
Режим «производительность» с разрешением 720p и отключёнными текстурами высочайшего качества.
ПОЗНАКОМЬТЕСЬ С FORTNITE В РЕЖИМЕ «ПРОИЗВОДИТЕЛЬНОСТЬ»!
Сменят ли ARM процессоры x86 и почему все зависит от Apple
В мире электроники два лагеря: мобильные гаджеты с процессорами ARM и классические компьютеры с x86. В статье разберемся в отличиях и изучим тренд, который задала Apple, перейдя на собственный ARM-чип M1 в настольных ПК
Какими бывают процессоры: x86 и ARM
В мобильных устройствах (планшеты, смартфоны) и классических компьютерах (ноутбуки, настольные ПК, серверы) используются разные процессоры. Они по-разному взаимодействуют с операционными системами и программами — взаимной совместимости нет. Именно поэтому вы не сможете запустить привычные Word или Photoshop на своем iPhone или Android-смартфоне. Вам придется скачивать из AppStore или Google Play специальную версию софта для мобильных устройств. И она будет сильно отличаться от версии для настольного ПК: как визуально, так и по функциональности, не говоря уже о программном коде, который пользователь обычно не видит.
Сверху — материнская плата iMac предыдущего поколения с процессором Intel (x86), снизу — плата iMac 2021 года с чипом M1 (ARM) (Фото: Apple)
Процессоры для классических компьютеров строятся на архитектуре x86. Своим названием она обязана ранним чипам компании Intel c модельными индексами 8086, 80186 и так далее. Первым таким решением с полноценной реализацией x86 стал Intel 80386, выпущенный в 1985 году. Сегодня подавляющее большинство процессоров в мире с архитектурой x86 делают Intel и AMD. При этом у AMD, в отличие от Intel, нет собственного производства: с 2018 года им по заказу компании занимается тайваньская корпорация TSMC.
Сегодня подавляющее большинство процессоров в мире с архитектурой x86 делают Intel и AMD. При этом у AMD, в отличие от Intel, нет собственного производства: с 2018 года им по заказу компании занимается тайваньская корпорация TSMC.
Процессор Intel 8086, 1978 год (Фото: wikipedia.org)
Когда Acer, Asus, Dell, HP, Lenovo и любые другие производители классических компьютеров используют процессоры Intel или AMD, то им приходится работать с тем, что есть. Они вынуждены закупать готовые решения без возможности гибко доработать чипы под свой конкретный продукт. А свои собственные процессоры на архитектуре x86 никто из производителей ПК делать не может. Дело не только в том, что это крайне сложно и дорого, но и в том, что лицензия на архитектуру принадлежит Intel, и компания не планирует ее ни с кем делить. AMD же воевала в американских судах за право создавать чипы на архитектуре x86 со своим главным конкурентом более десяти лет в 1980-х и 1990-х годах.
А свои собственные процессоры на архитектуре x86 никто из производителей ПК делать не может. Дело не только в том, что это крайне сложно и дорого, но и в том, что лицензия на архитектуру принадлежит Intel, и компания не планирует ее ни с кем делить. AMD же воевала в американских судах за право создавать чипы на архитектуре x86 со своим главным конкурентом более десяти лет в 1980-х и 1990-х годах.
Процессоры для мобильных устройств строятся на базе архитектуры ARM. И это не какая-то быстро и внезапно взлетевшая вверх молодая компания. Корни истории современной британской ARM Limited уходят далеко в 1980-е. Только в отличие от своих доминирующих на рынке «больших» ПК-конкурентов ARM Limited процессоры не делает. Бизнес компании построен на том, что она продает лицензии на производство чипов по своей технологии всем желающим. Причем возможности для доработки у лицензиатов максимально широкие — отсюда популярность и многообразие решений. Именно на основе архитектуры ARM Huawei делает свои мобильные чипы Kirin, у Samsung это Exynos, у Apple — серия Ax. В этот же список входят Qualcomm, MediaTek, NVIDIA и другие компании. А еще свои процессоры на ARM делает Fujitsu. Японцы назвали их A64X, и именно они в количестве 158 976 штук используются в самом мощном на момент выхода этой статьи суперкомпьютере в мире — Fujitsu Fugaku.
В этот же список входят Qualcomm, MediaTek, NVIDIA и другие компании. А еще свои процессоры на ARM делает Fujitsu. Японцы назвали их A64X, и именно они в количестве 158 976 штук используются в самом мощном на момент выхода этой статьи суперкомпьютере в мире — Fujitsu Fugaku.
Суперкомпьютер Fujitsu Fugaku (Фото: Riken)
Из открытого подхода ARM вытекает и главный недостаток: архитектура очень фрагментирована. Для x86 достаточно написать программу один раз, и она будет одинаково стабильно работать на всех устройствах. Для ARM приходится адаптировать софт под процессоры каждого производителя, что замедляет и удорожает разработку. Ну, а главный недостаток x86 вытекает из отсутствия конкуренции. В последние годы Intel, например, много упрекали за медленный или порой вовсе едва ощутимый прирост производительности от поколения к поколению. Также есть проблемы с высокими уровнями нагрева и энергопотребления.
Для ARM приходится адаптировать софт под процессоры каждого производителя, что замедляет и удорожает разработку. Ну, а главный недостаток x86 вытекает из отсутствия конкуренции. В последние годы Intel, например, много упрекали за медленный или порой вовсе едва ощутимый прирост производительности от поколения к поколению. Также есть проблемы с высокими уровнями нагрева и энергопотребления.
Архитектура процессоров: CISC, RISC, и в чем разница
Ключевое отличие между x86 и ARM кроется в разной архитектуре набора инструкций. По-английски — ISA, Instruction Set Architecture. В основе x86 изначально лежала технология CISC. Это расшифровывается как Complex Instruction Set Command — вычислительная машина со сложным набором инструкций. «Сложность» здесь в том, что в одну инструкцию для процессора может быть заложено сразу несколько действий.
Полвека назад, когда первые процессоры только появились, программисты писали код вручную (сейчас для этого есть компиляторы). Одну сложную команду на старом низкоуровневом языке программирования Assembler написать было гораздо проще, чем множество простых, досконально разъясняющих весь процесс. А еще сложная команда занимала меньше места, потому что код для нее был короче, чем несколько отдельных простых команд. Это было важно, потому что объем памяти в те времена был крайне ограничен, стоила она дорого и работала медленно. Заказчики от этого тоже выигрывали — под любой их запрос можно было придумать специальную команду.
А еще сложная команда занимала меньше места, потому что код для нее был короче, чем несколько отдельных простых команд. Это было важно, потому что объем памяти в те времена был крайне ограничен, стоила она дорого и работала медленно. Заказчики от этого тоже выигрывали — под любой их запрос можно было придумать специальную команду.
Но вот архитектура самого процессора страдала. По мере развития микроэлектроники в чипах с CISC копились команды, которые использовались редко, но все еще были нужны для совместимости со старыми программами. При этом под них резервировалось пространство на кристалле (место, где расположены физические блоки процессора). Это привело к появлению альтернативной технологии RISC, что расшифровывается как Reduced Instruction Set Command — вычислительная машина с сокращенным набором инструкций. Именно она легла в основу процессоров ARM и дала им название: Advanced RISC Machines.
Здесь ставку сделали на простые и наиболее востребованные команды. Да, код поначалу писать было сложнее, поскольку он занимал больше места, но с появлением компиляторов это перестало быть значимым недостатком. Результат — экономия места на кристалле и, как следствие, сокращение нагрева и потребления энергии. Плюс множество других преимуществ.
Да, код поначалу писать было сложнее, поскольку он занимал больше места, но с появлением компиляторов это перестало быть значимым недостатком. Результат — экономия места на кристалле и, как следствие, сокращение нагрева и потребления энергии. Плюс множество других преимуществ.
Почему о превосходстве ARM заговорили только недавно и при чем здесь Apple?
Если архитектура ARM так хороша, то почему же Intel и AMD не бросили все и не стали строить свои чипы на ней? На самом деле, они не оставили технологию без внимания, и к сегодняшнему дню CISC в чистом виде фактически уже не существует. Еще в середине 1990-х годов процессоры обеих компаний (начиная с Pentium Pro у Intel и K5 у AMD) обзавелись блоком преобразования инструкций. Сложные команды разбиваются на простые и затем выполняются именно там. Так что современные процессоры на архитектуре x86 в плане набора инструкций гораздо ближе к RISC, чем к CISC.
Кроме того, важно понимать, что противостояние x86 и ARM — это прежде всего противостояние Intel (потому что AMD гораздо меньше во всех отношениях: от капитализации до доли на рынках) и множества разрозненных производителей чипов для мобильных устройств. Долгое время два направления развивались как бы отдельно друг от друга. У Intel не получалось сделать достаточно мощное и энергоэффективное решение на x86 для мобильных устройств, а производители ARM-процессоров не стремились на рынок «больших» ПК. В нише мобильных устройств хватало места всем, и конкурировать там было проще, чем на фактически монополизированном Intel рынке процессоров для традиционных компьютеров.
Долгое время два направления развивались как бы отдельно друг от друга. У Intel не получалось сделать достаточно мощное и энергоэффективное решение на x86 для мобильных устройств, а производители ARM-процессоров не стремились на рынок «больших» ПК. В нише мобильных устройств хватало места всем, и конкурировать там было проще, чем на фактически монополизированном Intel рынке процессоров для традиционных компьютеров.
Однако в последние годы доминирующее положение Intel пошатнулось. Прежде всего из-за того, что бизнес компании перестал соответствовать ее же собственной производственной стратегии. Согласно прогнозу одного из основателей Intel Гордона Мура, количество транзисторов в процессорах должно удваиваться каждые два года за счет перехода на более компактный технологический процесс производства (измеряется в нанометрах — нм). Как раз за счет этого повышается производительность. Впоследствии впервые озвученный в середине 1960-х годов «Закон Мура» корректировался, но сегодня стало ясно, что бесконечным этот рост быть не может.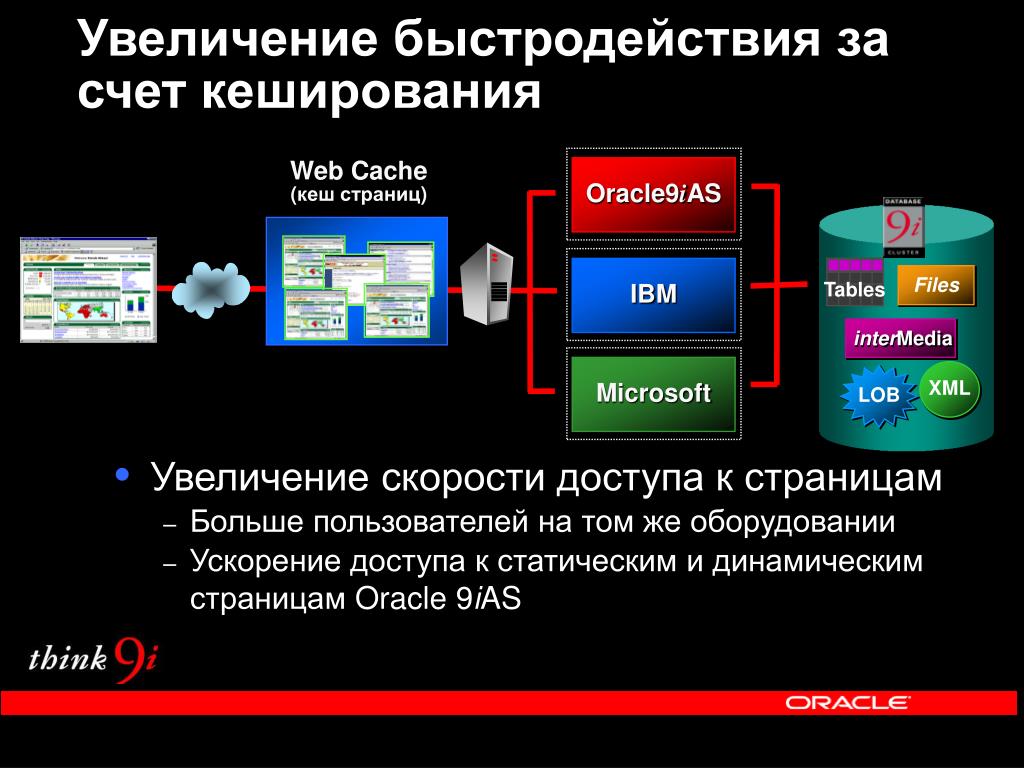 Технологии Intel дошли до «потолка возможностей» и пока уперлись в него. Переход на 14 нм, а потом и на 10 нм сильно затянулся, в то время как AMD в партнерстве с TSMC уже работает по техпроцессу 7 нм, а первым 5-нанометровым процессором в мире стал Apple M1 на архитектуре ARM.
Технологии Intel дошли до «потолка возможностей» и пока уперлись в него. Переход на 14 нм, а потом и на 10 нм сильно затянулся, в то время как AMD в партнерстве с TSMC уже работает по техпроцессу 7 нм, а первым 5-нанометровым процессором в мире стал Apple M1 на архитектуре ARM.
О законе Мура на английском с русскими субтитрами
Решая множество технологических проблем с процессорами для «больших» компьютеров, Intel полностью упустила из вида рынок мобильных чипов, и теперь здесь господствуют решения ARM. Проблемы, кстати, при этом никуда не делись — чипы Intel для настольных ПК последних лет активно и справедливо критикуют. Мощные процессоры компании страдают от высокого нагрева и сильного энергопотребления, а энергоэффективные, наоборот, сильно ограничены в плане производительности.
Мощные процессоры компании страдают от высокого нагрева и сильного энергопотребления, а энергоэффективные, наоборот, сильно ограничены в плане производительности.
Большинство производителей ноутбуков и компьютеров продолжают с этим мириться, и не уходят на ARM — не позволяет огромный багаж популярного софта и массовость их техники. Как вы помните, одна и та же программа не сможет работать и на x86 и, на ARM — ее нужно обязательно программировать заново. Но в 2020 году после почти 15 лет выпуска компьютеров с процессорами Intel компания Apple объявила о переходе на процессоры ARM собственной разработки. Они, кстати, тоже производятся внешним подрядчиком: на заводах уже упомянутой TSMC.
И это крайне важное заявление, потому что на рынке только у Apple есть все возможности для того, чтобы сделать этот переход успешным. Во-первых, компания сама разрабатывает процессоры на базе ARM много лет. Настольные M1 «выросли»
из мобильных чипов серии Ax. У производителей ПК на других ОС такого опыта нет или он сильно ограничен. Во-вторых, у Apple огромный опыт разработки собственных операционных систем: как мобильной, так и настольной. Конкуренты в основном используют Windows или «надстройки» для Android.
Во-вторых, у Apple огромный опыт разработки собственных операционных систем: как мобильной, так и настольной. Конкуренты в основном используют Windows или «надстройки» для Android.
Остается совместить две системы (OS X для компьютеров, iOS для смартфонов), «заточенные» под разную архитектуру вместе, унифицировав софт, и это самый сложный пункт программы. Но и тут у Apple есть целая россыпь козырей. Это и лояльная аудитория, не готовая смотреть на продукцию конкурентов, но готовая подождать пока программы адаптируют под ARM. И собственный язык программирования Swift, который давно унифицировал процесс разработки ПО для iOS и OS X. И пусть небольшая в количестве устройств, но зато очень заметная доля на рынке ПК в деньгах, чтобы процесс адаптации «настольного» софта для x86 под работу с «мобильным» ARM стал интересен крупным разработчикам ПО. За примерами далеко ходить не надо: в Adobe на зов откликнулись одними из первых.
Немаловажно и то, что переход с Intel на ARM для Apple — далеко не первый опыт смены процессоров в своих устройствах. На Intel корпорация из Купертино переходила с PowerPC в 2005 году. А чипы PowerPC пришли на замену Motorola 68K в начале 1990-х.
На Intel корпорация из Купертино переходила с PowerPC в 2005 году. А чипы PowerPC пришли на замену Motorola 68K в начале 1990-х.
Стив Джобс о переходе на процессоры Intel в 2005 году
Процессор Apple M1: чем он так хорош?
Apple M1 интересен не столько тем, что построен на базе технологий ARM, сколько своей архитектурой. Здесь на одной подложке собраны сам процессор, в котором по 4 производительных и энергоэффективных ядра, восьмиядерная графическая подсистема, нейромодуль для машинного обучения, огромные (по меркам процессоров) объемы кэш-памяти плюс тут же распаяна оперативная память. Такое решение занимает совсем мало места в корпусе компьютера, потребляет мало энергии (аккумулятор ноутбука дольше не разрядится) и может работать без активного охлаждения (ноутбук будет тихим или вовсе бесшумным) при хорошем уровне производительности.
Чип Apple M1 в Macbook Air Late 2020 (Фото: iFixit)
И совсем не просто так первым компьютером Apple с процессором M1 стал MacBook Air. С одной стороны, это лэптоп, главными преимуществами которого как раз и должно быть все, что дает новый процессор: компактность, автономность, тишина. С другой стороны, это компьютер для наименее требовательных пользователей, которым практически не нужен никакой специфический софт — достаточно того, что сама Apple предлагает «из коробки»: браузера, проигрывателя, офисного пакета. А для софта, который под ARM адаптировать пока не успели, Apple использует встроенный эмулятор Rosetta 2.
А для софта, который под ARM адаптировать пока не успели, Apple использует встроенный эмулятор Rosetta 2.
Следующими ПК Apple с M1 после MacBook Air стали 13-дюймовый MacBook Pro и Mac Mini. Также недавно был анонсирован новый iMac. Такие машины уже ориентированы на задачи посерьезнее, но все равно это еще далеко не профессиональный сегмент — на него в Купертино пока лишь намекают. И именно здесь к решению Apple на базе технологий ARM возникает основной вопрос: получится ли «отмасштабировать» M1 до уровня профессиональных решений, где компактность и энергоэффективность не так важны, а на первый план выходит именно производительность? Как реализовать связку М1 с мощными дискретными видеокартами, без которых о монтаже, рендеринге и других сложных вычислениях говорить не приходится? Или может быть Apple вообще готовится к выпуску собственной дискретной графики? Вопросов пока куда больше, чем ответов на них.
Новая линейка тонких (11,5 мм) iMac 2021 на базе M1 (Фото: Apple)
Уже готовые компактные устройства Apple с чипами M1 выглядят действительно интересно, правда выигрыш в производительности в них явно ощущается в основном только в уже адаптированных под ARM программах, но зато он очень заметный. Так что если Intel и AMD не смогут дать достойный ответ конкуренту в нише энергоэффективных ПК, то рост популярности решений Apple не заставит себя ждать даже несмотря на то, что еще какое-то время софта будет не хватать. Массовому пользователю ведь много не нужно.
Так что если Intel и AMD не смогут дать достойный ответ конкуренту в нише энергоэффективных ПК, то рост популярности решений Apple не заставит себя ждать даже несмотря на то, что еще какое-то время софта будет не хватать. Массовому пользователю ведь много не нужно.
Сравнение производительности отдельных ядер на чипах M1 и Intel, больше — лучше (Фото: GeekBench)
Сравнение производительности всех ядер на чипах M1 и Intel, больше — лучше (Фото: GeekBench)
Придут ли процессоры ARM на смену x86?
Точного ответа на этот вопрос пока не знает никто. Но уже сейчас очевидно, что в ближайшие годы основная борьба x86 в лице Intel и ARM в лице Apple развернется на рынке компактных ноутбуков. Они, в отличие от неттопов (Mac Mini) и моноблоков (iMac), значительно более востребованы. Также очевидно и то, что пользователи от такого противостояния только выиграют.
Но уже сейчас очевидно, что в ближайшие годы основная борьба x86 в лице Intel и ARM в лице Apple развернется на рынке компактных ноутбуков. Они, в отличие от неттопов (Mac Mini) и моноблоков (iMac), значительно более востребованы. Также очевидно и то, что пользователи от такого противостояния только выиграют.
Конечно, техника (особенно у Apple) от этого не подешевеет, но зато мы прямо сейчас получили ультрапортативные лэптопы без активного охлаждения с долгожданным ощутимым приростом мощности и времени работы от батареи. Здорово и то, что разработчики Intel наконец-то взбодрятся. Из-за отсутствия конкуренции они слишком долго почивали на лаврах: самое время доставать из рукавов все припрятанные козыри. Собственно, именно так технологии и развиваются. Новый виток эволюции процессоров происходит прямо у нас на глазах, и ситуация выглядит так, что все вполне может обернуться революцией, которая полностью изменит как рынок процессоров, так и рынок компьютеров.
spydell — ЖЖ
Существует иллюзия истины в последней инстанции, некого абсолютного знания и понимая глубинных процессов мироздания у властьдержащих. Предположение, что там, на самом верху все известно и все решения, которые принимаются взвешенные, обдуманные, проанализированные со всех сторон и безусловно правильные, ведь им там сверху виднее, не так ли? Они располагают инсайдерской информацией, доступом к первичным данным по первому требованию и в любом объеме, у них самые мощные компьютеры, датацентры, лучшие умы и все требуемое, чтобы делать необходимые действия в нужное время. Так ли это? Нет, конечно.
Предположение, что там, на самом верху все известно и все решения, которые принимаются взвешенные, обдуманные, проанализированные со всех сторон и безусловно правильные, ведь им там сверху виднее, не так ли? Они располагают инсайдерской информацией, доступом к первичным данным по первому требованию и в любом объеме, у них самые мощные компьютеры, датацентры, лучшие умы и все требуемое, чтобы делать необходимые действия в нужное время. Так ли это? Нет, конечно.В действительности, самой емкой валютной системой в мире управляют долбанные ублюдки, которые ничего не контролируют, ничего не понимают, не соображают и не способны просчитывать действия даже на два шага вперед. Вся их аналитическая мощь сосредотачивается в отслеживании скользящей средней уже реализованной макроэкономической тенденции и самозаклинания «за все хорошее, против всего плохого». Проще говоря, они следуют за рынком, а не формируют этот рынок.
Каждый квартал ФРС выпускает прогнозы/оценки основных макроэкономических индикаторов (ВВП, безработица, инфляция, процентные ставки). История изменения прогнозов показывает то, каким образов эволюционирует представление ФРС о верхних пороговых значениях и траектории движения экономики и денежной системы. Во-первых, перед самым взлетом инфляции в 2021 году, ФРС в декабрьском обзоре ожидала 1.8% инфляции в 2021 и 1.9% в 2022.
История изменения прогнозов показывает то, каким образов эволюционирует представление ФРС о верхних пороговых значениях и траектории движения экономики и денежной системы. Во-первых, перед самым взлетом инфляции в 2021 году, ФРС в декабрьском обзоре ожидала 1.8% инфляции в 2021 и 1.9% в 2022.
Не важно, что происходит в мире, какие факторы и дисбалансы действуют на экономическую и монетарную систему, не имеет значения конфигурация межотраслевых связей. ФРС «заякоривает» в своих воспаленных умах то, что не имеет никакого значения к реальности. В этом смысле, если вы хотите понять то, в какую сторону все движется и пытаетесь использовать платформу ФРС для выстраивания прогнозов, то мимо. Содержательно, все их прогнозы дерьмо собачье, которое показывает не то, что будет и не то, что есть, а то, что они хотят. Отсюда следует, что любая риторика официальных представителей ФРС имеет ровно такую же пользу, как их прогнозы.
Во-вторых, что не менее важно, эти придурки даже не владеют арифметикой начальной школы. Их прогноз на инфляцию в 2021 составляет 4.2%, причем распределение голосов членов ФРС не выходит далеко за этот уровень.
Сейчас сентябрь, инфляция за 8 месяцев известна. Что значит 4.2% среднегодовых цен 2021 относительно 2020? Средний ИПЦ по индексу за 2020 составляет 258.84, а 4.2% инфляция это 269.71, что означает, что с сентября по декабрь 2021 включительно накопленный рост цен должен составить ровно НОЛЬ! то естественно невозможно, т.е эти болваны выпускают как бы актуальный прогноз под конец года, который не работает в момент выхода, что как бы символизирует о качестве аналитики ФРС. Управление инфляционными ожиданиями через постоянную ложь, блеф и манипуляции? Ну-ну, посмотрим насколько запаса доверия хватит… ( Читать дальше…Свернуть )
Как делают процессоры и что такое техпроцесс
Самый первый коммерческий микропроцессор в истории, Intel 4004, был представлен в 1971 году. Тогда это была революция — на его площади размещалось целых 2250 транзисторов. Всего через 7 лет, в 1978-ом, был представлен Intel 8086 с 29 тысячами транзисторов. И ровно через 42 года, в 2020-м, у нас есть Apple M1 — без прикрас революционный чип с 16 миллиардами транзисторов. А всё благодаря техпроцессу.
Сегодня такие производители, как TSMC освоили производство чипов, а вернее сказать транзисторов, по 5-нанометровой технологии. Чтобы вы наглядно понимали, насколько малы такие транзисторы — волос человека имеет толщину 80 тысяч нанометров — выходит, на его разрезе в теории можно разместить 16 тысяч транзисторов. Вирус COVID-19 имеет размер 110 нм и на нём можно разместить целых 22 транзистора от Apple M1.
Однако есть теории, что производители нам немного врут и за этими значениями нанометров, как правило, скрываются другие цифры. В этом материале мы разберём с вами в том, как вообще устроен техпроцесс, что в нём измеряют, затронем производство чипов, поймём преимущества уменьшения размеров транзисторов и заглянем в будущее.
Что делают транзисторы в процессорах
Любое вычислительное устройство, будь то компьютер, смартфон или ваши AirPods, работает в двоичной системе счисления. То есть все операции записываются, просчитываются и выводятся в последовательности нулей и единиц.
Транзистор в процессоре можно представить в роли своеобразного переключателя. Если ток через него проходит — это 1, если нет — то это 0. И таких переключателей в современных процессорах миллиарды. Разная последовательность нулей и единиц образует информацию — программы, музыку, картинки, видео и даже этот текст. Раньше роль транзисторов в первых ЭВМ выполняли вакуумные лампы.
Например, в ENIAC (это первый компьютер общего назначения) использовалось 17,5 тысяч вакуумных ламп. На этом компьютере производили вычисления для создания водородной бомбы, а ещё составляли прогнозы погоды и решали задачи из математики и физики. Суммарное энергопотребление этих 17 с половиной тысяч вакуумных ламп составляло целых 150 кВт, а сама ЭВМ требовала площадь для её сборки в 167 квадратных метров при весе в 27 тонн.
Само собой, всё это очень ограничивало технические возможности таких компьютеров, благо в январе 1959 года Роберт Нойс, по совместительству один из восьми основателей легендарной компании Fairсhild Semiconductor Company в Кремниевой долине, изобрёл интегральную схему на основе кремния, принципы которой легли в основу производства всех микропроцессоров.
Почему кремний?
Все чипы, которые производятся для массового рынка, делаются на кремниевой основе. Если не углубляться совсем в какие-то страшные и непонятные цифры с формулами, то причина кроется в атомной структуре кремния, которая идеально подходит для того, чтобы делать микросхемы и процессоры практически любой конфигурации.
Получают кремний, к слову, из песка. Да, самого обычного, который у вас есть на ближайшем берегу. Но вот в чём подвох — его чистота, если говорить в цифрах, составляет 99,5% (0,5% в таком кремнии составляют разные примеси). Может показаться, что это уже суперблизко к идеальной чистоте, но нет, для процессора необходимо, чтобы кремний имел чистоту 99,9999999%. Для этого материал проводят через цепочку определённых химических реакций. После этого кремний плавят и наращивают в один большой кристалл. Весит он под сотню килограмм и выглядит следующим образом:
После этот кристалл нарезается на пластины с диаметром около 30-сантиметров, которые тщательно шлифуются, чтобы не было никаких зазубрин. Дополнительно применяется ещё химическая шлифовка. Если хотя бы на одной пластине будут шероховатости — её забракуют. А вот готовые пластины кремния отправляют на дальнейшее производство.
Как создаются транзисторы процессора?
На отполированный кремниевый диск наносится специальный фоточувствительный слой, на который затем поступает поток света — он реагирует с молекулами слоя и изменяет свойства кремниевого диска. Этот процесс называется фотолитографией. В отдельных его частях после этого ток начинает проходить иначе — где-то сильнее, где-то слабее.
Затем этот слой покрывается изолирующим веществом (диэлектриком). После на него снова наносится специальный фоточувствительный слой и данный процесс повторяется несколько раз, чтобы на площади появились миллиарды мельчайших транзисторов. Которые потом ещё соединяют между собой, тестируют, разрезают на ядра, соединяют с контактами и упаковывают в корпус процессора.
Благодаря фотолитографии у инженеров есть возможность создания мельчайших нанометровых транзисторов. Однако, как оказывается, техпроцессом в разное время называли разные вещи.
«Он вам не техпроцесс»
Изначально техпроцессом производители обозначали длину затвора у транзистора. Затвор — это один из элементов транзистора, которым контролируется поток движения электронов. То есть, он решает — будет 0 или 1.
В соответствии с законом Гордона Мура (одного из основателей Intel), количество транзисторов в чипах удваивается в два раза каждые два года. Этот закон был им выведен в 1975 году сугубо на основе личных наблюдений, но они оказались в итоге верны.
За последние годы процессоры прибавили в количестве транзисторов, производительности, но не в размерах. Когда индустрия перешла с техпроцесса 1000 нм на 700 нм, производители обратили внимание, что другие элементы транзистора не так податливы уменьшению, в отличие от затворов. Однако и уменьшать затвор тоже уже было нельзя — потому что в таком случае электроны смогли бы проходить сквозь него и вызывать нестабильную работу чипа.
В 2012 году с переходом на 22-нанометровый техпроцесс инженеры придумали новый формат проектирование транзисторов — FinFET (от «fin» — рус. «Плавник»). Потому что он действительно стал похож на плавник рыбы.
Принцип заключается в увеличении длины канала, через который проходят электроны. За счёт этого в целом увеличивается площадь поверхности канала, что даёт возможность прохождения через него большему количеству электронов. С увеличением длины производители также получили возможность упаковки транзисторов с большей плотностью на один квадратный миллиметр.
Это, кстати, повысило производительность чипов за последние несколько лет, особенно в мобильных процессорах. Однако, из-за того что транзисторы перестали быть плоскими, став трёхмерными — это усложнило измерения их размера. Простите за тавтологию.
Разные производители, как правило, по-своему производят измерения. Например, Intel берут среднее значение двух размеров от наиболее распространённых ячеек. Кто-то делает иначе, однако в целом всё равно — нанометры, о которых говорят в графе «техпроцесс» являются чем-то усреднённым, но в целом значение практически полностью соответствует размеру одного транзистора. Но ещё, что важно в процессоре — это плотность размещения транзисторов.
Что важнее — нанометры или плотность
Многие ругают Intel за то, что они ещё не смогли выпустить свой коммерческий процессор на архитектуре 5 или 7 нм, как это делают Apple и Qualcomm. Но вот по плотности размещения транзисторов — Intel безусловный лидер. На один квадратный миллиметр 10 нм процессора Intel помещается на целых 5% больше транзисторов, чем в чипах от Apple, Qualcomm или AMD. Кстати, последние поколения процессоров от этих трёх брендов производит TSMC.
В интернете я наткнулся на сравнительную табличку процессоров Intel и TSMC:
Обратите внимание на 10- и 7-нанометровые чипы у Intel и TSMC соответственно. Размеры составляющих у них почти идентичны, поэтому 10-нанометров Intel не сильно-то и уступают 7 нм у TSMC. А вот по производительности, за счёт повышенной плотности транзисторов, как я уже сказал выше, даже выигрывают.
Однако, чем больше плотность — тем больше нагрев, поэтому чипы Intel не подойдут для использования в мобильной технике. Зато TSMC выигрывает в плане меньшего энергопотребления и тепловыделения.
А вот тут вы можете сказать — «стоп, но как Intel выдаёт больше производительности, если Apple M1, который производит TSMC разносит старые десктопные процессоры в пух и прах». Да, это действительно так, на деле Apple M1 действительно превосходит в вычислениях Intel, но причина тут не сколько в количестве транзисторов или техпроцессе, сколько в том, насколько эффективно процессор работает с этими транзисторами. В Intel x86 есть много лишних блоков команд, которые TSMC в некоторых производимых чипах, не использует. Об этом более подробно мы писали в отдельном материале с разбором x86 и Apple M1.
Так что дают нанометры
В действительности, уменьшение техпроцесса и правда положительно влияет на такие показатели, как энергопотребление и производительность. Однако многие нюансы в производстве чипов компании не раскрывают, и найти в интернете их невозможно. А из того, что есть — создаётся впечатление о множестве противоречий.
В целом я бы советовал воспринимать цифры, которые говорят нам производители чипов, как среднее значение от всех составляющих. Так что заявлять, что производители нам врут — нельзя, но и что нанометры полностью соответствуют действительности тоже нельзя. Влияет также то, по какому формату производятся эти чипы и какие применяются материалы. В любом случае — чем меньше техпроцесс, тем лучше.
Новая структура транзистора
Вполне возможно, что вместо уменьшения техпроцесса начнётся работа по изменению структуры создание транзисторов. К примеру, Samsung недавно анонсировали технологию Gate-All-Around FET (GAAFET) для технормы в 5 нм. Подобная структура транзистора обеспечивает вхождение электронов со всех сторон, что более эффективно.
На картинке выше вы можете увидеть, что гребень затвора не сплошной, а разделён на несколько нитей. Если подобное будет реализовано и в других чипах, тогда можно рассчитывать на повышение производительности в процессорах и понижение энергопотребления не уменьшением техпроцесса, а доведением до ума того, что есть сейчас.
Что ждать в будущем?
Летающие автомобили, киборги, путешествие со скоростью света и перемещение во времени — это всё фантастика. Но вот 3 нм или 1,4 нм чипы, вполне возможно, нет.
На сегодня известно, что Intel к 2029 году планируют освоить 1,4 нм техпроцесс, а TSMC уже начали исследование 2 нм. Для этого компании должны разработать новое оборудование для производства, обучить персонал и сделать многое другое.
Другой вопрос, что транзистор 1,4 нм по размерам сопоставим примерно с 10 атомами и это может плохо отразиться на производительности. Случайные электроны могут менять биты по несколько раз в секунду и тогда о стабильных вычислениях может не идти и речи. Может быть закон Мура уже не актуален и его эпоха просто подходит к концу, а мы ещё этого не понимаем?
Вопросы и ответы по Amazon EC2 – Amazon Web Services
Вопрос. Что такое спотовый инстанс?
Спотовые инстансы – это свободные ресурсы EC2, которые позволяют сэкономить до 90 % средств по сравнению с инстансами по требованию. При этом AWS может прервать работу спотовых инстансов после соответствующего уведомления, отправленного за 2 минуты. Для спотовых инстансов используются те же базовые инстансы EC2, что и для инстансов по требованию и зарезервированных инстансов, при этом спотовые инстансы лучше всего подходят для отказоустойчивых и гибких рабочих нагрузок. Спотовые инстансы – это дополнительный вычислительный ресурс, который можно использовать вместе с инстансами по требованию и зарезервированными инстансами.
Вопрос. Чем отличается спотовый инстанс от инстанса по требованию или зарезервированного инстанса?
Во время работы спотовые инстансы ничем не отличаются от инстансов по требованию или зарезервированных инстансов. Основное отличие состоит в стоимости спотовых инстансов, которые обычно оказываются дешевле инстансов по требованию. Кроме того, в зависимости от потребности в ресурсах Amazon EC2 может прервать работу инстансов после соответствующего уведомления, отправленного за 2 минуты до отключения. При этом спотовые цены постепенно корректируются в соответствии с долгосрочными тенденциями предложения и спроса на свободные ресурсы EC2.
Дополнительную информацию о спотовых инстансах см. здесь.
Вопрос. Как приобрести и запустить спотовый инстанс?
Спотовые инстансы можно запускать с помощью тех же инструментов, которые в настоящее время используются для запуска инстансов, включая Консоль управления AWS, группы Auto Scaling, команду запуска инстансов и спотовые группы. Кроме того, запуск спотовых инстансов поддерживают многие сервисы AWS, например EMR, ECS, Datapipeline, Cloudformation и Batch.
Для запуска спотового инстанса нужно просто выбрать шаблон запуска и указать количество инстансов, которое необходимо запросить.
Дополнительную информацию о запросе спотовых инстансов см. здесь.
Вопрос. Сколько спотовых инстансов может запросить пользователь?
Количество запрашиваемых спотовых инстансов должно быть в рамках лимита инстансов, установленного для каждого региона. Следует отметить, что для новых клиентов AWS установленное ограничение может иметь меньшее значение. Дополнительную информацию о лимитах для спотовых инстансов см. в Руководстве пользователя Amazon EC2.
При необходимости получения большего количества заполните документ Форма запроса инстанса Amazon EC2 с указанием примера их использования, после чего мы рассмотрим возможность увеличения количества инстансов. Увеличение лимитов распространяется на тот регион, для которого оно было запрошено.
Вопрос. Какая плата будет начисляться за использование спотовых инстансов?
Вы будете производить оплату по спотовой цене, которая действует для работающего инстанса в начале каждого инстанс-часа. Если цена на спотовый инстанс изменится после его запуска, это будет учтено при начислении платы со следующего часа работы инстанса.
Вопрос. Что такое пул спотовых ресурсов?
Пул спотовых ресурсов – это набор неиспользуемых инстансов EC2 с тем же типом инстанса, операционной системой, зоной доступности и сетевой платформой (EC2-Classic или EC2-VPC). Цены разных пулов спотовых ресурсов могут отличаться в зависимости от предложения и спроса.
Вопрос. Какие существуют рекомендации по использованию спотовых инстансов?
Настоятельно рекомендуется использовать несколько пулов спотовых ресурсов для максимального увеличения доступных спотовых ресурсов. EC2 предоставляет встроенные возможности автоматизации, позволяющие найти самые экономичные ресурсы среди множества пулов спотовых ресурсов с помощью спотовой группы, группы EC2 или EC2 Auto Scaling. Дополнительную информацию см. в Рекомендациях по использованию спотовых инстансов.
Вопрос. Как узнать состояние запроса на спотовые инстансы?
Состояние запроса на спотовые инстансы можно узнать с помощью кода состояния запроса на спотовые инстансы и соответствующего сообщения. Доступ к информации о состоянии запроса на спотовые инстансы можно получить на странице спотовых инстансов консоли EC2 в Консоли управления AWS, API и интерфейсе командной строки. Дополнительную информацию см. в Руководстве по Amazon EC2 для разработчиков.
Вопрос. Есть ли возможность заказывать спотовые инстансы любых семейств и размеров в любых регионах?
Спотовые инстансы доступны во всех публичных регионах AWS. Спотовые инстансы доступны практически для всех семейств и размеров инстансов EC2, включая самые новые типы инстансов: оптимизированные для вычислений, инстансы с применением графического ускорения и инстансы FPGA. Полный список типов инстансов, поддерживаемых в каждом регионе, см. здесь.
Вопрос. Какие операционные системы доступны на спотовых инстансах?
В список доступных систем входят Linux/UNIX, Windows Server и Red Hat Enterprise Linux (RHEL). Windows Server с SQL Server в настоящее время недоступна.
Вопрос. Можно ли использовать спотовый инстанс с платным AMI для стороннего программного обеспечения (например, программных пакетов IBM)?
В настоящий момент нет.
Вопрос. Могу ли я остановить запущенные мной спотовые инстансы?
Да, вы можете остановить запущенные спотовые инстансы, когда они не нужны, и сохранить их для последующего использования вместо их завершения или отмены запроса на спотовые инстансы. Остановить можно постоянные запросы на спотовые инстансы.
Вопрос. Как остановить спотовые инстансы?
Можно остановить свои спотовые инстансы, вызвав API StopInstances и предоставив идентификаторы для спотовых инстансов. Эти действия похожи на те, которые предпринимаются для остановки инстансов по требованию. Перевести инстанс в спящий режим можно в Консоли управления AWS, указав нужный инстанс, а затем выбрав «Actions > Instance State > Stop – Hibernate».
Вопрос. Как запустить остановленные спотовые инстансы?
Можно запустить остановленные спотовые инстансы, вызвав API StartInstances и предоставив идентификаторы для спотовых инстансов. Эти действия похожи на те, которые предпринимаются для запуска инстансов по требованию. Можно возобновить работу инстанса в Консоли управления AWS, указав нужный инстанс, а затем выбрав «Actions > Instance State > Start».
Примечание. Спотовые инстансы будут запущены, только если спотовые ресурсы все еще доступны в пределах вашей максимальной цены. Каждый раз, когда вы запускаете остановленный спотовый инстанс, он оценивает доступность ресурсов.
Вопрос. Как узнать, остановил ли я свой спотовый инстанс или его работа была прервана?
Узнать, был спотовый инстанс остановлен или все же его работа была прервана, можно с помощью кода состояния запроса на спотовые инстансы. Информация отображается как состояние запроса на спотовые инстансы на соответствующей странице в Консоли управления AWS или посредством ввода команды DescribeSpotInstanceRequests API в поле «status-code».
Если код состояния запроса на спотовые инстансы – «instance-stopped-by-user», это означает, что вы остановили свой спотовый инстанс.
Вопрос. Как будет начисляться плата, если работа моего спотового инстанса остановлена или прервана?
Если работа спотового инстанса будет прервана или остановлена Amazon EC2 во время первого часа работы инстанса, это время его использования оплачиваться не будет. Однако если вы завершите или остановите работу спотового инстанса самостоятельно, будет начислена плата с округлением до ближайшей секунды. Если работа спотового инстанса будет прервана или остановлена Amazon EC2 в любое время в течение любого последующего часа работы инстанса, будет начислена плата за фактическое время использования с округлением до ближайшей секунды. Если вы используете ОС Windows или Red Hat Enterprise Linux (RHEL) и при этом завершите или остановите работу спотового инстанса самостоятельно, будет начислена плата за полный час.
Вопрос. Когда работа моего спотового инстанса может быть прервана?
За последние 3 месяца 92 % прерываний работы спотовых инстансов происходили на стороне клиентов, которые вручную останавливали работу инстансов после завершения работы приложений.
EC2 может потребоваться отозвать спотовые инстансы, выделенные клиенту, по двум возможным причинам. Основная причина – это потребности в ресурсах Amazon EC2 (например, использование инстансов по требованию или зарезервированных инстансов). Во втором случае, если задан параметр «максимальная спотовая цена», при этом спотовая цена превысила указанную цену, через две минуты после соответствующего уведомления инстанс будет остановлен. Указанный параметр определяет максимальную цену, которую клиент готов заплатить за час работы спотового инстанса, при этом по умолчанию его значение соответствует цене инстанса по требованию. Как и прежде, работа спотовых инстансов будет оплачиваться по рыночной спотовой цене, действующей в момент запуска инстанса, а не по указанной максимальной цене, при этом плата будет начисляться на посекундной основе.
Вопрос. Что произойдет со спотовым инстансом, когда его работа будет прервана?
У клиентов есть возможность выбрать, что произойдет со спотовым инстансом, если его работа будет прервана: завершить работу, остановить или перевести в спящий режим. Остановка и перевод в спящий режим доступны для постоянных заявок на спотовые инстансы и спотовых групп с включенным параметром «maintain». По умолчанию работа инстансов завершается.
Дополнительную информацию об обработке прерываний см. в разделе, посвященном спящему режиму для спотовых инстансов.
Вопрос. В чем разница между остановкой и спящим режимом?
При переходе инстанса в спящий режим данные оперативной памяти сохраняются. В случае остановки инстанс отключается, а данные оперативной памяти удаляются.
В обоих случаях данные из корневого тома EBS и любых подключенных томов данных EBS сохраняются. Неизменным остается как частный IP‑адрес, так и эластичный IP‑адрес (если такой используется). Поведение на сетевом уровне будет аналогично тому, что описано для рабочего процесса EC2, связанного с остановкой‑запуском. Остановка и спящий режим доступны только для инстансов на базе Amazon EBS. Локальное хранилище инстансов не сохраняется.
Вопрос. Что делать, если объем корневого тома EBS недостаточен для сохранения состояния памяти (ОЗУ) для спящего режима?
Для записи данных из памяти на корневом томе EBS должно быть достаточно места. Если места на корневом томе EBS недостаточно, попытка перехода в спящий режим завершится ошибкой, при этом инстанс будет выключен. Убедитесь, что том EBS имеет достаточный объем для сохранения данных памяти, прежде чем выбирать спящий режим.
Вопрос. В чем преимущество перевода инстанса в спящий режим при прерывании его работы?
В спящем режиме работа спотовых инстансов в случае прерывания будет приостановлена и возобновлена, что позволяет продолжить выполнение рабочих нагрузок с момента остановки. Спящий режим можно использовать, если один или несколько инстансов должны сохранять свое состояние между циклами отключения-запуска, т. е. когда работа приложений, запущенных на спотовых инстансах, зависит от контекстных, деловых или сеансовых данных, хранящихся в ОЗУ.
Вопрос. Что нужно сделать, чтобы включить спящий режим для спотовых инстансов?
Дополнительную информацию о включении спящего режима для спотовых инстансов см. в разделе, посвященном спящему режиму для спотовых инстансов.
Вопрос. Будет ли взиматься плата за использование спящего режима для спотовых инстансов?
Дополнительная плата за использование спящего режима для инстанса не взимается. Оплачивается только хранилище EBS и любые другие используемые ресурсы EC2. При переводе инстанса в спящий режим плата за пользование инстансом не взимается.
Вопрос. Можно ли возобновить работу инстанса, находящегося в спящем режиме?
Нет. Нельзя напрямую возобновить работу инстанса, находящегося в спящем режиме. Amazon EC2 управляет циклами перехода в спящий режим, а также выхода из него. Если спотовый инстанс был переведен в спящий режим, он будет восстановлен Amazon EC2, когда ресурсы станут доступны.
Вопрос. Какие инстансы и операционные системы поддерживают спящий режим?
В настоящее время спящий режим для спотовых инстансов поддерживается для образов Amazon Linux AMI и операционных систем Ubuntu и Microsoft Windows, работающих на любом типе инстансов семейств C3, C4, C5, M4, M5, R3 и R4 с объемом памяти (RAM) до 100 ГиБ.
Перечень поддерживаемых версий ОС см. в разделе, посвященном спящему режиму для спотовых инстансов.
Вопрос. Как начисляется плата, если спотовая цена изменяется во время работы инстанса?
Оплачиваться будет полный час работы каждого инстанса с округлением до ближайшей секунды по ценам, которые устанавливаются в начале каждого инстанс-часа.
Вопрос. Где получить информацию об истории использования спотовых инстансов и платежах?
Консоль управления AWS создает подробный отчет о платежах, в котором указывается время запуска и завершения работы/остановки по каждому инстансу. Используя API, клиенты могут сравнить отчет о платежах с данными истории для проверки соответствия платежей и спотовых цен.
Вопрос. Будет ли прерываться работа блоков спотовых инстансов (спотовых инстансов фиксированной продолжительности)?
Блоки спотовых инстансов настроены на бесперебойную работу и будут работать непрерывно в течение всего заданного срока независимо от рыночной спотовой цены. В редких случаях работа блоков спотовых инстансов может прерываться из-за возросшего потребления ресурсов платформой AWS. В подобных случаях за две минуты до прекращения работы инстанса система выдает предупреждение (предупреждение о прекращении работы), при этом плата за работу затронутых инстансов взиматься не будет.
Вопрос. Что такое спотовая группа?
Спотовая группа позволяет автоматически запрашивать сразу несколько спотовых инстансов и управлять ими, что позволяет обеспечить наименьшую цену за единицу ресурсов для кластера или приложения, например задания пакетной обработки, рабочего процесса Hadoop или высокопроизводительных распределенных вычислений. Можно включать те типы инстансов, которые может использовать приложение. С учетом требований приложения задается необходимый объем ресурсов (можно указать количество инстансов, виртуальных ЦПУ, объем памяти, емкость хранилища или пропускную способность сети) и обновляется необходимый объем ресурсов после запуска группы. Спотовые группы позволяют запускать и поддерживать целевой уровень ресурсов, а также автоматически запрашивать ресурсы для замещения инстансов, работа которых была прервана или прекращена вручную. Подробнее о спотовых группах.
Вопрос. Взимается ли дополнительная плата за запросы на спотовые группы?
Нет, дополнительная плата за запросы на спотовые группы не взимается.
Вопрос. Какие существуют ограничения по запросам на спотовые группы?
Ознакомьтесь с разделом Ограничения для спотовых групп Руководства пользователя Amazon EC2, чтобы узнать о существующих ограничениях по запросам на спотовые группы.
Вопрос. Что происходит, если запрос на спотовую группу пытается запустить спотовые инстансы и при этом превышается ограничение на спотовые запросы для данного региона?
Если запрос на спотовую группу превышает ограничение на запросы спотовых инстансов для данного региона, отдельные запросы спотовых инстансов будут отклонены с состоянием «Превышено ограничение запросов на спотовую группу». В истории запросов на спотовые группы будут отображаться все ошибки, связанные с превышением ограничений на спотовые запросы. Ознакомьтесь с разделом Мониторинг спотовых групп Руководства пользователя Amazon EC2, чтобы узнать, как отобразить историю запросов на спотовые группы.
Вопрос. Есть ли гарантия, что запросы на спотовые группы будут выполнены?
Нет. Запросы на спотовые группы позволяют одновременно размещать запросы на несколько спотовых инстансов, при этом к ним применимы те же самые параметры доступности и цены, что и к запросам на отдельные спотовые инстансы. Например, если нет доступных ресурсов для типов инстансов, указанных в запросе спотовой группы, запрос не может быть выполнен частично или полностью. Рекомендуется включать в спотовую группу все возможные типы инстансов и зоны доступности, которые подходят для рабочих нагрузок.
Вопрос. Можно ли подать запрос на спотовую группу в нескольких зонах доступности?
Да. Ознакомьтесь с разделом Примеры спотовых групп Руководства пользователя Amazon EC2, чтобы узнать, как подать запрос на спотовую группу в нескольких зонах доступности.
Вопрос. Можно ли подать запрос на спотовую группу в нескольких регионах?
Нет, запросы на группы в нескольких регионах не поддерживаются.
Вопрос. Каким образом спотовые группы распределяют ресурсы между различными пулами спотовых инстансов, заданными в параметрах запуска?
API RequestSpotFleet позволяет воспользоваться одной из трех стратегий распределения: capacity‑optimized, lowestPrice и diversified. Стратегия распределения с оптимизацией ресурсов пытается выделить спотовые инстансы из пула с наибольшей доступностью, анализируя метрики ресурсов. Эта стратегия хорошо подходит для рабочих нагрузок с высокой стоимостью прерывания, к которым относятся большие данные и аналитика, рендеринг изображений и мультимедийного контента, машинное обучение и высокопроизводительные вычисления.
Стратегия lowestPrice позволяет распределять ресурсы спотовой группы между пулами инстансов с минимальной стоимостью единицы ресурсов на время передачи запроса. Стратегия diversified позволяет распределять ресурсы спотовой группы между несколькими пулами спотовых инстансов. Эта стратегия позволяет поддерживать целевой уровень ресурсов группы и повысить доступность приложения в процессе колебаний объема спотовых ресурсов.
Запуск ресурсов приложения в неоднородных пулах спотовых инстансов позволяет дополнительно сократить эксплуатационные расходы группы с течением времени. Подробности см. в Руководстве пользователя по Amazon EC2.
Вопрос. Возможно ли с помощью тега отметить запрос на спотовую группу?
Теги можно использовать, чтобы запросить запуск спотовых инстансов с помощью спотовой группы. Назначение тегов для самой группы не поддерживается.
Вопрос. Как посмотреть, к каким спотовым группам принадлежат мои спотовые инстансы?
Чтобы посмотреть, какие спотовые инстансы принадлежат к спотовой группе, укажите запрос на группу. Запросы на группы остаются доступны в течение 48 часов после прекращения работы всех спотовых инстансов. Дополнительную информацию об отображении запроса на спотовую группу см. в Руководстве пользователя Amazon EC2.
Вопрос. Можно ли изменить запрос на спотовую группу?
В настоящее время можно изменять только целевые ресурсы запроса на спотовую группу. Чтобы изменить другие параметры конфигурации запроса, вам может потребоваться отменить текущий запрос и отправить новый.
Вопрос. Можно ли указать различные образы AMI для каждого типа инстанса, который будет использоваться?
Да, для этого достаточно указать нужный образ AMI в каждой конфигурации запуска, которая указывается в запросе на спотовую группу.
Вопрос. Можно ли использовать спотовую группу вместе с сервисами Elastic Load Balancing, Auto Scaling или Elastic MapReduce?
Спотовую группу можно использовать с такими возможностями сервиса Auto Scaling, как отслеживание целевых значений, проверка работоспособности, метрики CloudWatch и т. д. Кроме того, можно подключать инстансы к балансировщикам нагрузки сервиса Elastic Load Balancing (как к Classic Load Balancer, так и к Application Load Balancer). В Elastic MapReduce есть функция под названием «Группы инстансов», которая предоставляет возможности, подобные возможностям спотовой группы.
Вопрос. Может ли запрос на спотовую группу прекратить работу спотовых инстансов, если они больше не выполняются в спотовом пуле с самой низкой ценой или оптимизацией по ресурсам, и затем повторно запустить их?
Нет, запросы на спотовые группы не предусматривают автоматического прекращения работы запущенных спотовых инстансов и повторного их запуска. Тем не менее,если пользователь прекращает работу спотового инстанса, спотовая группа заменит его новым спотовым инстансом из нового пула с самой низкой ценой или оптимизацией по ресурсам в соответствии с выбранной стратегией распределения.
Вопрос. Можно ли использовать со спотовой группой модели поведения, связанные с остановкой или переходом в спящий режим после прерывания работы?
Да. Остановка-запуск и спящий режим-возобновление работы поддерживаются спотовой группой при включенном параметре «maintain» группы.
% PDF-1.3 % 13 0 объект > эндобдж xref 13 184 0000000016 00000 н. 0000005007 00000 н. 0000005106 00000 п. 0000006674 00000 н. 0000007005 00000 н. 0000007428 00000 н. 0000007933 00000 п. 0000008016 00000 н. 0000008127 00000 н. 0000008240 00000 н. 0000008732 00000 н. 0000009110 00000 н. 0000009633 00000 н. 0000009678 00000 н. 0000009724 00000 н. 0000017880 00000 п. 0000026284 00000 п. 0000032262 00000 п. 0000032552 00000 п. 0000032718 00000 п. 0000038996 00000 н. 0000047349 00000 п. 0000047492 00000 п. 0000047635 00000 п. 0000047751 00000 п. 0000047894 00000 п. 0000048039 00000 п. 0000048211 00000 п. 0000048382 00000 п. 0000048525 00000 п. 0000048669 00000 н. 0000048812 00000 н. 0000048984 00000 п. 0000049127 00000 п. 0000049272 00000 п. 0000049415 00000 п. 0000049560 00000 п. 0000049703 00000 п. 0000049846 00000 п. 0000049991 00000 н. 0000050134 00000 п. 0000050279 00000 п. 0000050422 00000 п. 0000050518 00000 п. 0000050661 00000 п. 0000050858 00000 п. 0000050954 00000 п. 0000051097 00000 п. 0000051240 00000 п. 0000051412 00000 п. 0000059116 00000 п. 0000059257 00000 п. 0000059400 00000 п. 0000059572 00000 п. 0000059715 00000 п. 0000059861 00000 п. 0000060004 00000 п. 0000060100 00000 н. 0000060243 00000 п. 0000060339 00000 п. 0000060482 00000 п. 0000060578 00000 п. 0000060721 00000 п. 0000060817 00000 п. 0000060960 00000 п. 0000061097 00000 п. 0000061240 00000 п. 0000061383 00000 п. 0000061528 00000 п. 0000061649 00000 п. 0000061685 00000 п. 0000061828 00000 п. 0000061924 00000 п. 0000062067 00000 п. 0000062188 00000 п. 0000062331 00000 п. 0000070000 00000 н. 0000070181 00000 п. 0000070353 00000 п. 0000070521 00000 п. 0000070689 00000 п. 0000070861 00000 п. 0000071029 00000 п. 0000071197 00000 п. 0000071365 00000 п. 0000071601 00000 п. 0000071782 00000 п. 0000071963 00000 п. 0000072132 00000 п. 0000073583 00000 п. 0000074677 00000 п. 0000074846 00000 п. 0000075015 00000 п. 0000075184 00000 п. 0000076376 00000 п. 0000076549 00000 п. 0000076773 00000 п. 0000078205 00000 п. 0000078415 00000 п. 0000078624 00000 п. 0000079707 00000 п. 0000080734 00000 п. 0000080916 00000 п. 0000081098 00000 п. 0000082295 00000 п. 0000083451 00000 п. 0000083620 00000 н. 0000084735 00000 п. 0000084904 00000 п. 0000085073 00000 п. 0000085242 00000 п. 0000085411 00000 п. 0000085580 00000 п. 0000085749 00000 п. 0000087147 00000 п. 0000087337 00000 п. 0000087510 00000 п. 0000087679 00000 п. 0000088793 00000 п. 00000 00000 п. 00000
Память и местонахождение
Память и местонахождениеДо сих пор мы говорили о производительности, как если бы все шаги в оценочные модели одинаково дороги. Оказывается, это даже не так приблизительно верно; они могут отличаться на два порядка и более. Асимптотически это не имеет значения, потому что существует верхняя граница того, как долго каждый шаг занимает. Но на практике 100-кратное замедление может иметь значение, если оно влияющие на критическую для производительности часть программы.Писать быстро программ, нам иногда нужно понять, как производительность базовых компьютерное оборудование влияет на производительность языка программирования и разрабатывайте наши программы соответствующим образом.
Абстракция памяти
У компьютеров есть память, которую можно абстрактно представить как большой массив
ints, а точнее, из 32-битных слов . Индексы в
этот массив называют адресами. В зависимости от процессора адреса могут быть
длиной 32 бита (что позволяет адресовать до 4 гигабайт) или 64 бита,
позволяя памяти в четыре миллиарда раз больше.Операции, поддерживаемые
память являются чтением и записью, аналогично Array.sub и Array.update :
тип модуля MEMORY = sig введите адрес (* Возвращает: read (addr) - текущее содержимое памяти по адресу addr. *) val читать: адрес -> int (* Эффекты: write (addr, x) изменяет память по адресу addr, чтобы она содержала x. *) val написать: адрес * int -> unit конец
Все богатые возможности и типы языков более высокого уровня доступны.
реализован поверх этой простой абстракции.Например, каждый
переменная в программе, когда она находится в области видимости, имеет место в памяти
назначенный на это. (На самом деле компилятор пытается поставить как можно больше переменных
по возможности в регистры , которые намного быстрее, чем
память, но мы можем думать об этом как о других местах памяти для
цель этого обсуждения.) Например, если мы объявляем let x: int = 2 , тогда во время выполнения есть место в памяти
для x, который мы можем представить в виде прямоугольника, содержащего число 2:
Ящики и указатели
Поскольку поле переменной может содержать только 32 бита, многие значения не могут поместиться в
расположение их переменной.Поэтому языковая реализация помещает такие значения в другое место.
в памяти. Например, кортеж let x = (2,3,4) будет представлен
как три последовательных ячейки памяти, которые мы можем нарисовать в виде прямоугольников.
Ячейка памяти (поле) для x будет содержать адрес первого из этих
места в памяти. Мы можем думать об этом адресе как о стрелке, указывающей из
поле для x в первое поле кортежа. Поэтому мы ссылаемся на этот адрес
как указатель .Поскольку фактические адреса памяти обычно не
важно, мы можем нарисовать диаграммы того, как используется память, без
адреса и просто показывать указатели.
Тип кортежа является примером упакованного типа : его значения тоже большой, чтобы поместиться в ячейку памяти переменной, и поэтому нуждаются в их собственные ячейки памяти или ящики. Распакованные типы в OCaml включают основные типы, такие как int, char, bool, real, nil и NONE. Типы в штучной упаковке включают кортежи, записи, типы данных, узлы списков, массивы, ссылки, строки и функции.
Каждый раз, когда у нас есть имя переменной с рамкой
type, это означает, что для доступа к этому значению процессор должен использовать
адрес указателя для доступа к данным. Следующие указатели называются косвенное обращение .
Например, если мы объявляем переменную let x = (2, Some "Hi") ,
Для перехода к символам строки «Hi» необходимы три косвенных обращения:
Причина, по которой мы заботимся о том, есть ли указатели или нет, заключается в том, что косвенные ссылки может быть очень дорогим.Чтобы понять почему, нам нужно посмотреть, как компьютер память работает аккуратнее.
Реализация памяти
Память компьютера состоит из множества больших массивов, выгравированных на различных чипсы. Каждый массив имеет большое количество строк и столбцов, которые память Чип можно активировать самостоятельно. На пересечении каждой строки и столбца В строке есть небольшая память, реализованная с использованием одного или нескольких транзисторов.
Чтобы считать биты из ряда памяти, каждый транзистор в строке должен перекачивать достаточное количество электронов на линии столбца или за ее пределами, чтобы позволить логику восприятия на столбец, чтобы определить, был ли этот бит 0 или 1.Все остальное равно, большие воспоминания медленнее, потому что транзисторы меньше по сравнению с линией столбца, в которой они нужно активировать. В результате компьютерная память становится все медленнее и медленнее. относительно скорости обработки (например, сложение двух чисел). Добавление двух номеров занимает один цикл (или даже меньше на машинах с несколькими выпусками, таких как семейство x86). Типичной компьютерной памяти в наши дни требуется около 30 нс, чтобы доставить запрошенную данные. Звучит довольно быстро, но нужно иметь в виду, что частота 4 ГГц процессор выполняет новую инструкцию каждые 0.25нс. Таким образом, процессор будет приходится ждать более 100 циклов каждый раз, когда требуется память для доставки данные. Достаточно много вычислений может быть выполнено за время, необходимое для получения одно число из памяти.
Кеши
Чтобы справиться с относительным замедлением памяти компьютера, компьютерные архитекторы представили кеши , которые представляют собой меньшие по размеру и более быстрые воспоминания, которые сидят между процессором и основной памятью. Кеш отслеживает содержимое места в памяти недавно запрашивается процессором.Если процессор запрашивает одно из этих мест, вместо этого кеш дает ответ. Поскольку кеш намного меньше, чем основная память (сотни килобайт вместо десятков или сотен мегабайт), это можно сделать доставлять запросы намного быстрее, чем основная память: за десятки циклов, а не за сотни. Фактически, одного уровня кеша недостаточно. Обычно бывает два или три уровня кэша, каждый меньше и быстрее следующего. Праймериз (L1) кэш — самый быстрый кэш, обычно прямо на микросхеме процессора и способный обрабатывать запросы к памяти за один – три цикла.Вторичный кэш (L2) больше и медленнее. В современных процессорах есть как минимум первичный и вторичный кеш-память. микросхему процессоров, часто также третичные кеши. Уровней может быть больше кеширования (L3, L4) на отдельном чипе.
Например, процессор Itanium 2 от Intel имеет три уровня кеша прямо на чипе, с увеличением времени отклика (измеряется в циклов процессора) и увеличение размера кеш-памяти. В результате почти все запросы памяти могут быть удовлетворены без обращения к основной памяти.
- Первичный (L1) кэш: 32 КБ, 1 цикл
- Вторичный (L2) кэш: 96 КБ, 5 циклов
- Третичный (L3) кэш: 3 МБ, 12 циклов Кэш
- L4: ~ 32 МБ, ~ 25 циклов
- Основная память: вне кристалла, 100–200 циклов
Эти числа являются лишь практическим правилом, потому что разные процессоры настроил иначе. Pentium 4 не имеет встроенной кэш-памяти третьего уровня; Core Duo имеет нет кэша L3, но имеет гораздо больший кэш L2 (2 МБ).Потому что кеши не влияют набор команд процессора, архитекторы обладают большой гибкостью для изменения конструкции кэша по мере развития семейства процессоров.
Наличие кешей помогает только в том случае, если процессору нужно получить некоторые данные, уже в кеше. Таким образом, при первом обращении процессора к памяти он должен дождаться поступления данных. При последующих чтениях из того же места есть хороший шанс, что кеш сможет обслуживать запрос памяти без привлечения основной памяти.Конечно, поскольку кеш намного меньше, чем основная память, она не может хранить всю основную память. Кеш постоянно выбросить информацию о ячейках памяти, чтобы освободить место для новых данные. Процессор получает ускорение от кеша только в том случае, если данные извлекаются из память все еще находится в кэше, когда она снова понадобится. Когда в кеше есть данные, необходимые процессору, называются попаданием в кэш . Если нет, это кеш-промах .Отношение количества попаданий к промахам составляет называется коэффициент попадания в кэш .
Поскольку память намного медленнее процессора, коэффициент попадания в кеш имеет решающее значение для общей производительности. Например, если промах кеша равен сотне раз медленнее, чем попадание в кеш, то коэффициент промахов в 1% означает, что половина время тратится на промахи кеша. Конечно, реальная ситуация больше сложный, потому что вторичный и третичный кеши часто обрабатывают промахи в первичном кеш.
Кэш записывает ячейки кэшированной памяти в единицах по строк кэша содержащие несколько слов памяти. Типичная строка кэша может содержать 4–32 слова памяти. При промахе кеша строка кеша заполняется из основного объем памяти. Таким образом, серия чтений из памяти в соседние ячейки памяти, скорее всего, в основном попадает в кеш. Когда происходит промах кэша, вся последовательность памяти слова запрашиваются сразу из основной памяти. Это хорошо работает, потому что память Чипы предназначены для чтения целого ряда смежных местоположений дешевый.
Следовательно, кеши улучшают производительность, когда доступ к памяти показывает местонахождение : доступы сгруппированы во времени и пространстве, так что чтение из память имеет тенденцию многократно запрашивать одни и те же места или даже места в памяти рядом с предыдущими запросами. Кеши предназначены для хорошей работы с вычислениями, которые выставить местонахождение; у них будет высокий коэффициент попадания в кеш.
Программирование с учетом кеширования
Как кеширование влияет на нас, программистов? Мы хотели бы написать код, в котором хорошее месторасположение, чтобы получить максимальную производительность.Это имеет значение для многих структуры данных, которые мы рассмотрели, которые имеют различные характеристики местности.
Массивы
Массивы реализованы как последовательность последовательных ячеек памяти. Следовательно, если индексы, используемые в последовательных операциях с массивом, имеют locality, соответствующие адреса памяти также будут отображать локальность. Существует большая разница между последовательным доступом к массиву и доступ к нему случайным образом, потому что последовательные обращения будут производить много попаданий в кеш, а случайный доступ приведет в основном к пропускам.Итак, массивы даст лучшую производительность, если есть локальность индекса.
Списки
В списках много указателей. Короткие списки поместятся в кеш, но длинные списки не будут. Таким образом, хранение больших наборов в списках, как правило, приводит к большому количеству промахи в кэше.
Деревья
Деревья имеют множество косвенных обращений, которые могут вызывать промахи кеша. С другой стороны, несколько верхних уровней дерева, вероятно, поместятся в кеш, и поскольку они будут часто посещаться, они, как правило, хранятся в кеше.Промахи кеша будут, как правило, происходить на менее часто посещаемых узлах. ниже на дереве.
Одно красивое поместье в деревья в том, что они сохраняют местность. Близкие друг к другу ключи будут иметь тенденцию разделять большую часть пути от корня до соответствующих узлов. Кроме того, обход дерева по порядку будет обращаться к узлам дерева с хорошей локализацией. Таким образом, деревья особенно эффективны, когда они используются для хранения наборов или карт. где доступ к элементам / ключам показывает хорошую локальность.
Хеш-таблицы
Хеш-таблицы — это массивы, но хорошая хеш-функция уничтожает большую часть местности, дизайн. Повторный доступ к одному и тому же элементу приведет к соответствующему хешу ведро в кеш. Но доступ к клавишам, которые находятся рядом друг с другом в любом упорядочение ключей приведет к доступу к памяти без определения местоположения. Если у ключей есть большая местность, древовидная структура данных может быть быстрее, даже если она асимптотически медленнее!
Разделение на части
Списки неэффективно используют кеш.Доступ к узлу списка вызывает дополнительную информацию в строке кеша, которая будет загружена в кеш, возможно, выталкивая полезные данные также. Для лучшей производительности строки кэша должны использоваться полностью. Часто данные структуры можно настроить, чтобы это произошло. Например, со списками мы можем поместить несколько элементов в каждый узел. Представление набора ведра затем связанный список, где каждый узел в связанном списке содержит несколько элементов (и указатель цепочки) и занимает всю строку кэша.Таким образом, мы переходим от связанный список, который выглядит как верхний и нижний:
Выполнение такой оптимизации производительности может быть непростой задачей на таком языке, как Ocaml, где язык упорно трудится, чтобы скрыть такие низкоуровневые выбор представительства от вас. Однако практическое правило в том, что записи и кортежи OCaml хранятся рядом в памяти. Так что это вид макета памяти может быть до некоторой степени реализован в OCaml, например:
введите 'a onelist = Null | Минусы 'a *' в онелисте
введите chunklist = NullChunk
| Фрагмент списка фрагментов 'a *' a * 'a *' a * int * '
let cons x (y: 'chunklist) = сопоставить y с
Чанк (_, _, _, a, 1, хвост) -> Чанк (x, x, x, a, 2, хвост)
| Чанк (_, _, b, a, 2, хвост) -> Чанк (x, x, b, a, 3, хвост)
| Чанк (_, c, b, a, 3, хвост) -> Чанк (x, c, b, a, 4, хвост)
| (Chunk (_, _, _, _, _, _) | NullChunk) -> Chunk (x, x, x, x, 1, y)
пусть rec find (l: int chunklist) (x: int): bool =
сопоставить l с
NullChunk -> ложь
| Чанк (a, b, c, d, n, t) ->
(a = x || b = x || c = x || d = x || найти t x)
Идея состоит в том, что блок хранит четыре элемента и счетчик, который отслеживает количество полей элементов (1-4), которые уже используются.Оказывается, сканирование связанного списка реализовано таким образом примерно на 10 процентов быстрее, чем сканирование по простой связанной list (по крайней мере, на ноутбуке 2009 года выпуска). В язык, такой как C или C ++, программисты могут лучше контролировать структуру памяти и может получить гораздо больший выигрыш в производительности, если учесть локальность в учетная запись. Возможность тщательно контролировать, как информация хранится в память, пожалуй, лучшая особенность этих языков.
Хеш-таблицы
Поскольку в хэш-таблицах используются связанные списки, их обычно можно улучшить с помощью такая же оптимизация фрагментов.Чтобы избежать погони за начальным указателем из bucket в связанный список, мы вставляем некоторое количество записей в каждый ячейку массива, а также разбить связанный список на части. Это может дать существенное ускорение, но требует некоторой настройки различных параметров. В идеале каждый элемент массива должен занимать одну строку кэша на соответствующем уровень кеша. Наилучшая производительность достигается при более высоком коэффициенте нагрузки, чем при использовании обычный связанный список. Другие структуры данных, богатые указателями, могут быть разделены аналогичным образом. для повышения производительности памяти.
Кэш-память— обзор
4.1 Функция модифицированной стоимости
В случае кэш-памяти каждая выборка инструкции приведет либо к попаданию в кэш, либо к промаху кеша, что, в свою очередь, может привести к двум очень разным временам выполнения инструкций. Простая модель микроархитектуры, согласно которой для выполнения каждой инструкции требуется постоянное время, больше не моделирует эту ситуацию точно. Нам нужно разделить исходное количество инструкций на количество попаданий и промахов в кеш. Если мы сможем определить эти подсчеты и время выполнения каждой инструкции, то можно будет установить более жесткие ограничения на время выполнения программы.
Как и в предыдущем разделе, мы можем группировать смежные инструкции вместе. Мы определяем новый тип атомарной структуры для анализа, линейный блок или просто l-блок. L-блок определяется как непрерывная последовательность кода в одном и том же базовом блоке, которая отображается в один и тот же набор кэша в кэше команд. Другими словами, l-блоки образованы пересечением базовых блоков с размером строки набора кэша. Все инструкции в пределах l-блока всегда выполняются вместе последовательно.Кроме того, поскольку контроллер кеша всегда загружает строку кода в кеш, эти инструкции либо находятся в кеше полностью, либо не находятся в кеше вообще. Они обозначаются как попадание в кэш или промах в кэш соответственно l-блока .
На рисунке 2 (i) показан CFG с 3 базовыми блоками. Предположим, что кэш инструкций имеет 4 набора кешей. Поскольку начальный адрес каждого базового блока может быть определен из исполняемого кода программы, мы можем найти все наборы кешей, которым сопоставлен каждый базовый блок, и добавить запись в эти строки кэша в кэш-таблице (рисунок 2 (ii)). .Граница каждого l-блока показана прямоугольником сплошной линией. Предположим, что базовый блок B i разделен на n i l-блоки. Обозначим эти l-блоки B i .1 , B i .2 ,…, B i.n i .
Рис. 2. Пример, показывающий, как построены l-блоки .Каждый прямоугольник в кэш-таблице представляет собой l-блок.
Для любых двух l-блоков , которые отображаются в один и тот же набор кэш-памяти, они будут конфликтовать друг с другом, если у них разные адресные теги. Выполнение одного l-блока приведет к смещению содержимого кэша другого. Например, l-блок B 1.1 конфликтует с l-блоком B 3.1 на рисунке 2. Также есть случаи, когда два l-блока не конфликтуют друг с другом.Такая ситуация возникает, когда граница базового блока не совпадает с границей строки кэша. Например, l-блоки B 1.3 и B 2.1 на рисунке 2, каждый занимает частичную строку кэша, и они не конфликтуют друг с другом. Их называют неконфликтными l-блоками.
Поскольку l-блок B i.j находится внутри базового блока B i , его количество выполнений равно x i .Счетчики попаданий в кэш и промахов в кэше l-блока B i.j обозначены xijhit и xijmiss, соответственно, и
(12) xi = xijhit + xijmiss, j = 1,2,…, ni.
Новое общее время выполнения (функция стоимости) равно
(13) totalexecutiontime = ∑i = 1N∑j = 1ni (cijhitxijhit + cijmissxijmiss)
, где cijhit и cijmiss — это, соответственно, стоимость попадания и промах. Стоимость l-блока B ij .
Уравнение (12) связывает новую функцию стоимости (13) со структурными ограничениями программы и ограничениями функциональности программы, которые остаются неизменными.Кроме того, поведение кеша теперь можно указать с помощью новых переменных xijhit’s и xijmiss’s.
Новая тенденция разработки аппаратного обеспечения и проблемы в управлении и анализе данных
Bordawekar RR, Sadoghi M (2016) Ускорение рабочих нагрузок баз данных за счет совместного проектирования программного обеспечения, оборудования и систем. В: 32-я международная конференция IEEE по инженерии данных (ICDE), 2016 г. IEEE, стр. 1428–1431
Viglas SD (2015) Управление данными в энергонезависимой памяти.В: Материалы международной конференции ACM SIGMOD 2015 по управлению данными. ACM, pp 1707–1711
Ailamaki A (2015) Базы данных и оборудование: начало и продолжение прекрасной дружбы. Proc VLDB Endow 8 (12): 2058–2061
Статья Google ученый
Swanson S, Caulfield AM (2013) Рефакторинг, сокращение, переработка: реструктуризация стека ввода-вывода для будущего хранения. Компьютер 46 (8): 52–59
Артикул Google ученый
Лим К., Чанг Дж., Мадж Т. и др. (2009) Дезагрегированная память для расширения и совместного использования в блейд-серверах. ACM SIGARCH Comput Archit News 37 (3): 267–278
Статья Google ученый
Сюэ CJ, Sun G, Zhang Y et al (2011) Новые энергонезависимые воспоминания: возможности и проблемы. В: 2011 Труды 9-й международной конференции по аппаратному / программному кодированию и системному синтезу (CODES + ISSS). IEEE, стр. 325–334
Freitas R (2010) Память класса хранения: технологии, системы и приложения. В: 2010 IEEE Hot Chips 22 Symposium (HCS). IEEE, стр. 1–37
Арулрадж Дж., Павло А. (2017) Как создать систему управления базами данных с энергонезависимой памятью. В: Материалы международной конференции ACM 2017 г. по управлению данными. ACM, pp 1753–1758
Zamanian E, Binnig C, Harris T. et al (2017) Конец мифа: распределенные транзакции можно масштабировать. Proc VLDB Endow 10 (6): 685–696
Статья Google ученый
Barthels C, Alonso G, Hoefler T (2017) Проектирование баз данных для будущих высокопроизводительных сетей. IEEE Data Eng Bull 40 (1): 15–26
Google ученый
Graefe G (1994) Volcano / spl minus / расширяемая и параллельная система оценки запросов. IEEE Trans Knowl Data Eng 6 (1): 120–135
Статья Google ученый
Idreos S, Groffen F, Nes N et al (2012) MonetDB: два десятилетия исследований в области архитектуры баз данных, ориентированной на столбцы.Q Bull База данных IEEE Comput Soc Tech Comm Eng 35 (1): 40–45
Google ученый
Zukowski M, van de Wiel M, Boncz P (2012) Vectorwise: векторизованная аналитическая СУБД. В: 2012 IEEE 28-я международная конференция по инженерии данных (ICDE). IEEE, pp 1349–1350
Neumann T (2011) Эффективное составление эффективных планов запросов для современного оборудования. Proc VLDB Endow 4 (9): 539–550
Статья Google ученый
Lang H, Mühlbauer T, Funke F et al (2016) Блоки данных: гибридный OLTP и OLAP в сжатом хранилище с использованием как векторизации, так и компиляции. В: Материалы международной конференции по управлению данными 2016 г. ACM, pp 311–326
Polychroniou O, Raghavan A, Ross KA (2015) Переосмысление векторизации SIMD для баз данных в памяти. В: Материалы международной конференции ACM SIGMOD 2015 по управлению данными. ACM, pp 1493–1508
Sukhwani B, Thoennes M, Min H et al (2015) Аппаратный / программный подход для ускорения запросов к базе данных с помощью fpgas.Параллельная программа Int J 43 (6): 1129–1159
Статья Google ученый
Meister A, Breß S, Saake G (2015) На пути к оптимизации базы данных с ускорением на GPU. Datenbank Spektrum 15 (2): 131–140
Статья Google ученый
Jha S, He B, Lu M et al (2015) Улучшение хеш-соединений основной памяти на процессорах Intel Xeon Phi: экспериментальный подход. Proc VLDB Endow 8 (6): 642–653
Статья Google ученый
Woods L, István Z, Alonso G (2014) Ibex: интеллектуальный механизм хранения с поддержкой расширенной разгрузки SQL. Proc VLDB Endow 7 (11): 963–974
Статья Google ученый
Вудс Л., Алонсо Дж., Тубнер Дж. (2015) Распараллеливание обработки данных на ПЛИС со списками сдвигов. ACM Trans Reconfig Technol Syst (TRETS) 8 (2): 7
Google ученый
He B, Yang K, Fang R et al (2008) Реляционные соединения на графических процессорах.В: Материалы международной конференции ACM SIGMOD 2008 по управлению данными. ACM, pp 511–524
Дебрабант Дж., Арулрадж Дж., Павло А. и др. (2014) Прогноз систем баз данных OLTP для энергонезависимой памяти. В: ADMS @ VLDB
Павло А (2015) Новые тенденции в оборудовании для обработки крупномасштабных транзакций. IEEE Internet Comput 19 (3): 68–71
Статья Google ученый
Коберн Дж., Бункер Т., Шварц М. и др. (2013) От ARIES к MARS: поддержка транзакций для твердотельных накопителей следующего поколения. В: Материалы двадцать четвертого симпозиума ACM по принципам операционных систем. ACM, pp 197–212
DeBrabant J, Pavlo A, Tu S. et al (2013) Anti-caching: новый подход к архитектуре системы управления базами данных. Proc VLDB Endow 6 (14): 1942–1953
Статья Google ученый
Kim D, Lee S, Chung J et al (2012) Гибридная основная память на основе DRAM / PRAM для однокристального CPU / GPU. В кн .: Материалы 49-й ежегодной конференции по автоматизации проектирования. ACM, pp 888–896
Yoon HB, Meza J, Ausavarungnirun R et al (2012) Политики кэширования с учетом локального буфера строк для гибридной памяти. В: 2012 IEEE 30-я международная конференция по компьютерному дизайну (ICCD). IEEE, pp. 337–344
Meza J, Chang J, Yoon HB и др. (2012) Обеспечение эффективных и масштабируемых гибридных запоминающих устройств с использованием управления кеш-памятью DRAM с высокой степенью детализации.IEEE Comput Archit Lett 11 (2): 61–64
Статья Google ученый
Манегольд С., Бонц П., Керстен М.Л. (2002) Общие модели стоимости баз данных для систем с иерархической памятью. В кн .: Материалы 28-й международной конференции по очень большим базам данных. Фонд VLDB, стр. 191–202
Группа баз данных Карнеги-Меллона [EB / OL] (2016) N-Store. http://db.cs.cmu.edu/projects/nvm/. По состоянию на 22 ноября 2017 г.
Тиннефельд К., Коссманн Д., Грунд М. и др. (2013) Эластичная онлайн-аналитическая обработка на ramcloud. В: Материалы 16-й международной конференции по расширению технологии баз данных. ACM, pp 454–464
Li F, Das S, Syamala M et al (2016) Ускорение реляционных баз данных за счет использования удаленной памяти и RDMA. В: Материалы международной конференции по управлению данными 2016 г. ACM, pp 355–370
Бинниг К., Кротти А., Галакатос А. и др. (2016) Конец медленных сетей: пора изменить дизайн.Proc VLDB Endow 9 (7): 528–539
Статья Google ученый
Элмор А.Дж., Арора В., Тафт Р и др. (2015) Squall: детальная реконфигурация в реальном времени для разделенных баз данных с основной памятью. В: Материалы международной конференции ACM SIGMOD 2015 по управлению данными. ACM, pp. 299–313
Polychroniou O, Sen R, Ross KA (2014) Track join: распределенные соединения с минимальным сетевым трафиком. В: Материалы международной конференции ACM SIGMOD 2014 по управлению данными.ACM, pp 1483–1494
Калия А., Каминский М., Андерсен Д.Г. (2014) Эффективное использование RDMA для сервисов «ключ-значение». ACM SIGCOMM Comput Commun Rev 44 (4): 295–306
Статья Google ученый
Драгоевич А., Нараянан Д., Ходсон О. и др. (2014) FaRM: быстрая удаленная память. В: Материалы 11-й конференции USENIX по проектированию и внедрению сетевых систем, стр. 401–414
Бишной Р., Оборил Ф., Эбрахими М. и др. (2014) Избегание ненужных операций записи в STT-MRAM для реализации с низким энергопотреблением. .В: 2014 15-й международный симпозиум по качеству электронного дизайна (ISQED). IEEE, pp 548–553
Yue J, Zhu Y (2013) Ускорение записи за счет использования асимметрии PCM. В: 19-й международный симпозиум IEEE по архитектуре высокопроизводительных компьютеров, 2013 г. (HPCA2013). IEEE, pp. 282–293
Ян Дж., Minturn DB, Hady F (2012) Когда опрос лучше, чем прерывание. БЫСТРО 12: 3
Google ученый
Qureshi MK, Srinivasan V, Rivers JA (2009) Масштабируемая высокопроизводительная система основной памяти с использованием технологии памяти с фазовым переходом. ACM SIGARCH Comput Archit News 37 (3): 24–33
Статья Google ученый
Диман Дж., Аюб Р., Розинг Т. (2009) PDRAM: гибридная система оперативной памяти PRAM и DRAM. В: 46-я конференция ACM / IEEE по автоматизации проектирования, 2009, DAC’09. IEEE, pp. 664–669
Wang Z, Shan S, Cao T et al (2013) WADE: управление динамическим кешем с поддержкой обратной записи для системы основной памяти на основе NVM.ACM Trans Archit Code Optim (TACO) 10 (4): 51
Google ученый
Seok H, Park Y, Park KH (2011) Алгоритм кэширования страниц на основе миграции для гибридной основной памяти DRAM и PRAM. В: Материалы симпозиума ACM 2011 г. по прикладным вычислениям. ACM, pp 595–599
Коберн Дж., Колфилд А.М., Акель А. и др. (2011) NV-Heaps: создание постоянных объектов быстрым и безопасным с помощью энергонезависимой памяти нового поколения.ACM Sigplan Not 46 (3): 105–118
Статья Google ученый
Кондит Дж., Найтингейл Э. Б., Фрост С. и др. (2009) Улучшенный ввод-вывод с помощью постоянной памяти с байтовой адресацией. В: Материалы 22-го симпозиума ACM SIGOPS по принципам операционных систем. ACM, pp 133–146
Volos H, Tack AJ, Swift MM (2011) Мнемозина: легкая постоянная память. Новости ACM SIGARCH Comput Archit ACM 39 (1): 91–104
Статья Google ученый
Hwang T, Jung J, Won Y (2015) Heapo: хранилище постоянных объектов на основе кучи. ACM Trans Storage (TOS) 11 (1): 3
Google ученый
Джайлс Э., Доши К., Варман П. (2013) Устранение разрыва в программировании между постоянной и энергозависимой памятью с помощью WrAP. В: Материалы международной конференции ACM по компьютерным границам. ACM, стр. 30
Чжао Дж., Ли С., Юн Д.Х. и др. (2013) Печь: сокращение разрыва в производительности между системами с поддержкой постоянства и без нее.В: 2013 46-й ежегодный международный симпозиум IEEE / ACM по микроархитектуре (MICRO). IEEE, pp 421–432
Lee S, Kim J, Lee M et al (2014) Механизм регистрации последнего блока для повышения производительности и срока службы файловой системы на основе SCM. В: Материалы 8-й международной конференции по повсеместному управлению информацией и коммуникациям. ACM, стр. 38
Колфилд А.М., Де А., Кобурн Дж. И др. (2010) Moneta: высокопроизводительная архитектура массива хранения для энергонезависимой памяти нового поколения.В: Материалы 43-го ежегодного международного симпозиума IEEE / ACM по микроархитектуре 2010 г. IEEE Computer Society, стр. 385–395
PRAMFS Team (2016) Защищенная и постоянная файловая система RAM [EB / OL]. http://pRamfs.SourceForge.net. По состоянию на 16 марта 2018 г.
Sha EHM, Chen X, Zhuge Q et al (2016) Новый дизайн файловой системы в памяти, основанный на структуре виртуальных адресов файлов. IEEE Trans Comput 65 (10): 2959–2972
MathSciNet Статья Google ученый
Fang R, Hsiao HI, He B et al (2011) Высокопроизводительное ведение журнала базы данных с использованием памяти класса хранения. В: 2011 IEEE 27-я международная конференция по инженерии данных (ICDE). IEEE, pp. 1221–1231
Колфилд AM, Моллов Т.И., Эйснер Л.А. и др. (2012) Обеспечение безопасного доступа пользователя к быстрым твердотельным дискам. ACM SIGARCH Comput Archit News 40 (1): 387–400
Статья Google ученый
Venkataraman S, Tolia N, Ranganathan P et al (2011) Согласованные и надежные структуры данных для энергонезависимой памяти с байтовой адресацией.БЫСТРО 11: 61–75
Google ученый
Чжан Дж., Донофрио Д., Шалф Дж. И др. (2015) Nvmmu: модуль управления энергонезависимой памятью для гетерогенных архитектур GPU-SSD. В: Международная конференция по параллельной архитектуре и компиляции, 2015 г. (PACT). IEEE, pp. 13–24
Zhang Y, Zhou X, Zhang Y et al (2016) Виртуальная денормализация с помощью ссылки на индекс массива для OLAP основной памяти. IEEE Trans Knowl Data Eng 28 (4): 1061–1074
Статья Google ученый
Wu S, Jiang D, Ooi BC et al (2010) Эффективное индексирование на основе B-дерева для обработки облачных данных. Proc VLDB Endow 3 (1-2): 1207–1218
Статья Google ученый
Ван Дж, Ву С., Гао Х и др. (2010) Индексирование многомерных данных в облачной системе. В: Материалы международной конференции ACM SIGMOD 2010 по управлению данными. ACM, pp 591–602
Ding L, Qiao B, Wang G et al (2011) Эффективная структура индекса на основе четырехугольного дерева для управления облачными данными.In: WAIM, pp. 238–250
Jin R, Cho HJ, Chung TS (2014) Схема хранения индекса B-дерева на основе группового циклического перебора для устройств флэш-памяти. В: Материалы 8-й международной конференции по повсеместному управлению информацией и коммуникациям. ACM, стр. 29
On ST, Hu H, Li Y et al (2009) Lazy-update B + -tree для флеш-устройств. В: Десятая международная конференция по управлению мобильными данными: системы, сервисы и промежуточное ПО, 2009, MDM’09. IEEE, стр. 323–328
Lomet D (2004) Простые, надежные и высоко конкурентные B-деревья с удалением узлов. В кн .: Известия. 20-я международная конференция по инженерии данных. IEEE, pp. 18–27
Левандоски Дж. Дж., Ломет DB, Сенгупта С. (2013) Bw-tree: B-tree для новых аппаратных платформ. В: 29-я международная конференция IEEE по инженерии данных (ICDE), 2013 г. IEEE, pp 302–313
Куреши М.К., Франческини М.М., Ластрас-Монтано, Лос-Анджелес (2010) Повышение производительности чтения памяти с фазовым переходом посредством отмены записи и приостановки записи.В: 2010 IEEE 16-й международный симпозиум по архитектуре высокопроизводительных компьютеров (HPCA). IEEE, pp 1–11
Ahn J, Yoo S, Choi K (2014) DASCA: архитектура кеш-памяти STT-RAM с помощью прогнозирования мертвой записи. В: 2014 20-й международный симпозиум IEEE по архитектуре высокопроизводительных компьютеров (HPCA). IEEE, pp. 25–36
Li J, Shi L, Li Q et al (2013) Согласованность кэша позволила адаптивное обновление для энергозависимой STT-RAM. В кн .: Материалы конференции по проектированию, автоматизации и испытаниям в Европе.Консорциум EDA, стр. 1247–1250
Феррейра А.П., Чжоу М., Бок С. и др. (2010) Увеличение срока службы основной памяти PCM. В кн .: Материалы конференции по проектированию, автоматизации и испытаниям в Европе. Европейская ассоциация проектирования и автоматизации, стр. 914–919
Вамсикришна М.В., Су З., Тан К.Л. (2012) Сортировка с учетом PCM, эффективная при записи. В кн .: Международная конференция по приложениям баз данных и экспертных систем. Springer, Berlin, pp. 86–100
. Google ученый
Гарг В., Сингх А., Харица Дж. Р. (2015) На пути к созданию систем баз данных, совместимых с PCM. В кн .: Международная конференция по приложениям баз данных и экспертных систем. Springer, Cham, pp. 269–284
Google ученый
Чен С., Гиббонс ПБ, Нат С. и др. (2011) Переосмысление алгоритмов базы данных для памяти с фазовым переходом. В: Конференция по исследованиям инновационных систем данных, стр. 21–31
Viglas SD (2012) Адаптация B + -дерева для асимметричного ввода-вывода.В: Восточноевропейская конференция по достижениям в базах данных и информационных системах. Springer, Berlin, pp 399–412
Глава Google ученый
Chi P, Lee WC, Xie Y (2014) Создание эффективного B + -дерева в основной памяти на основе PCM. В кн .: Материалы международного симпозиума 2014 г. по маломощной электронике и дизайну. ACM, pp 69–74
Бауш Д., Петров И., Бухманн А. (2012) Обеспечение учета асимметрии оптимизации запросов на основе затрат.В: Материалы восьмого международного семинара по управлению данными на новом оборудовании. ACM, pp 24–32
Ailamaki A, DeWitt DJ, Hill MD (2002) Макеты страниц данных для реляционных баз данных в глубоких иерархиях памяти. VLDB J Int J Очень большие базы данных 11 (3): 198–215
Статья Google ученый
Ли И.Х., Ли С.Г., Шим Дж. (2011) Обеспечение учета кэша Т-деревьев на стандартных микропроцессорах. J Inf Sci Eng 27 (1): 143–161
Google ученый
Manegold S, Boncz P, Kersten M (2002) Оптимизация соединения основной памяти на современном оборудовании. IEEE Trans Knowl Data Eng 14 (4): 709–730
Статья Google ученый
Хэнкинс Р.А., Патель Дж. М. (2003) Морфинг данных: адаптивный метод хранения с учетом кеширования. В: Материалы 29-й международной конференции по очень большим базам данных, том 29. VLDB Endowment, pp 417–428
Chapter Google ученый
Răducanu B, Boncz P, Zukowski M (2013) Микроадаптивность в векторе. В: Материалы международной конференции ACM SIGMOD 2013 по управлению данными. ACM, pp 1231–1242
Johnson R, Raman V, Sidle R et al (2008) Построчное параллельное вычисление предикатов. Proc VLDB Endow 1 (1): 622–634
Статья Google ученый
Balkesen C, Teubner J, Alonso G et al (2013) Хеширование основной памяти на многоядерных процессорах: настройка на базовое оборудование.В: 29-я международная конференция IEEE по инженерии данных (ICDE), 2013 г. IEEE, pp. 362–373
Balkesen C, Alonso G, Teubner J et al (2013) Многоядерные соединения основной памяти: пересмотр сортировки и хеширования. Proc VLDB Endow 7 (1): 85–96
Статья Google ученый
He J, Zhang S, He B (2014) Совместная обработка запросов в кэше на связанных архитектурах CPU-GPU. Proc VLDB Endow 8 (4): 329–340
Статья Google ученый
Cheng X, He B, Lu M и др. (2016) Эффективная обработка запросов на многоядерных архитектурах: пример использования процессора Intel Xeon Phi. В: Материалы международной конференции по управлению данными 2016 г. ACM, pp 2081–2084
Вернер С., Генрих Д., Стельцнер М. и др. (2016) Ускоренная оценка соединений в базах данных семантической паутины с использованием ПЛИС. Concurr Comput Pract Exp 28 (7): 2031–2051
Статья Google ученый
Sitaridi EA, Ross KA (2016) Сопоставление строк с ускорением на GPU для приложений баз данных. VLDB J 25 (5): 719–740
Статья Google ученый
He J, Lu M, He B (2013) Возвращение к совместной обработке для хеш-объединений в архитектуре связанных процессоров и графических процессоров. Proc VLDB Endow 6 (10): 889–900
Статья Google ученый
Zhang Y, Zhang Y, Su M et al (2013) Индекс соединения HG-Bitmap: гибридный механизм индекса соединения битовых карт GPU / CPU для OLAP.В: Международная конференция по проектированию веб-информационных систем. Springer, Berlin, pp. 23–36
Blanas S, Li Y, Patel JM (2011) Разработка и оценка алгоритмов хеш-соединения основной памяти для многоядерных процессоров. В: Материалы международной конференции ACM SIGMOD 2011 по управлению данными. ACM, pp 37–48
Альбутиу М.К., Кемпер А., Нойман Т. (2012) Массивно-параллельные соединения сортировки-слияния в системах многоядерных баз данных с основной памятью. Proc VLDB Endow 5 (10): 1064–1075
Статья Google ученый
Pagh R, Wei Z, Yi K et al (2010) Хеширование без учета кеширования. В: Материалы двадцать девятого симпозиума ACM SIGMOD-SIGACT-SIGART по принципам систем баз данных. ACM, pp 297–304
Mitzenmacher M (2016) Новый подход к анализу хеширования робин-гуд. В: 2016 материалы тринадцатого семинара по аналитической алгоритмике и комбинаторике (ANALCO). Общество промышленной и прикладной математики, стр. 10–24
Рихтер С., Альварес В., Диттрих Дж. (2015) Семимерный анализ методов хеширования и его влияние на обработку запросов.Proc VLDB Endow 9 (3): 96–107
Статья Google ученый
Schuh S, Chen X, Dittrich J (2016) Экспериментальное сравнение тринадцати реляционных равных объединений в основной памяти. В: Материалы международной конференции по управлению данными 2016 г. ACM, pp 1961–1976
Mohan C, Haderle D, Lindsay B. et al (1992) ARIES: метод восстановления транзакции, поддерживающий блокировку с высокой степенью детализации и частичный откат с использованием ведения журнала с упреждающей записью.ACM Trans Database Syst (TODS) 17 (1): 94–162
Статья Google ученый
Пелли С., Вениш Т.Ф., Голд BT и др. (2013) Управление хранением в эпоху NVRAM. Proc VLDB Endow 7 (2): 121–132
Статья Google ученый
Гао С., Сюй Дж., Хердер Т. и др. (2015) PCMLogging: оптимизация ведения журнала транзакций и производительности восстановления с помощью PCM. IEEE Trans Knowl Data Eng 27 (12): 3332–3346
Статья Google ученый
Хуанг Дж., Шван К., Куреши М.К. (2014) Ведение журнала с учетом NVRAM в системах транзакций. Proc VLDB Endow 8 (4): 389–400
Статья Google ученый
Ван Т., Джонсон Р. (2014) Масштабируемое ведение журнала за счет новой энергонезависимой памяти. Proc VLDB Endow 7 (10): 865–876
Статья Google ученый
Harizopoulos S, Abadi DJ, Madden S. et al (2008) OLTP через зеркало и то, что мы там обнаружили.В: Материалы международной конференции ACM SIGMOD 2008 по управлению данными. ACM, pp 981–992
Larson PÅ, Blanas S, Diaconu C et al (2011) Высокопроизводительные механизмы управления параллелизмом для баз данных в основной памяти. Proc VLDB Endow 5 (4): 298–309
Статья Google ученый
Johnson R, Pandis I, Ailamaki A (2009) Улучшение масштабируемости OLTP с использованием спекулятивного наследования блокировок. Proc VLDB Endow 2 (1): 479–489
Статья Google ученый
Пандис И., Джонсон Р., Хардавеллас Н. и др. (2010) Выполнение транзакций, ориентированных на данные. Proc VLDB Endow 3 (1-2): 928–939
Статья Google ученый
Джонсон Р., Атанассулис М., Стойка Р. и др. (2009) Новый взгляд на роли вращения и блокировки. В кн .: Материалы пятого международного семинара по управлению данными на новом оборудовании. ACM, pp. 21–26
Хорикава Т. (2013) Свободные от защелки структуры данных для СУБД: проектирование, реализация и оценка.В: Материалы международной конференции ACM SIGMOD 2013 по управлению данными. ACM, pp 409–420
Юнг Х, Хан Х, Фекете А. и др. (2014) Масштабируемый диспетчер блокировок для многоядерных процессоров. Система баз данных ACM Trans (TODS) 39 (4): 29
MathSciNet Статья Google ученый
Рен К., Томсон А., Абади Д. Д. (2012) Облегченная блокировка для систем баз данных в основной памяти. В: Известия эндаумента VLDB, том 6, №2.VLDB Endowment, pp. 145–156
Sadoghi M, Ross KA, Canim M et al (2013) Создание обновлений, удобных для дискового ввода-вывода с помощью SSD. Proc VLDB Endow 6 (11): 997–1008
Статья Google ученый
Каллман Р., Кимура Х., Наткинс Дж. И др. (2008) H-store: высокопроизводительная система обработки транзакций с распределенной основной памятью. Proc VLDB Endow 1 (2): 1496–1499
Статья Google ученый
Драгоевич А., Нараянан Д., Найтингейл Э. Б. и др. (2015) Без компромиссов: распределенные транзакции с согласованностью, доступностью и производительностью. В кн .: Материалы 25-го симпозиума по принципам операционных систем. ACM, pp 54–70
Levandoski JJ, Lomet DB, Sengupta S. et al (2015) Высокопроизводительные транзакции во дейтерономии. In: CIDR
Zhenkun Y, Chuanhui Y, Zhen L (2013) OceanBase — массивная система управления хранением структурированных данных.E Sci Technol Appl 4 (1): 41–48
Google ученый
Бейлис П., Дэвидсон А., Фекете А. и др. (2013) Высокодоступные транзакции: достоинства и ограничения. Proc VLDB Endow 7 (3): 181–192
Статья Google ученый
Stonebraker M, Madden S, Abadi DJ et al (2007) Конец архитектурной эпохи: (пора полностью переписать). В кн .: Материалы 33-й международной конференции по очень большим базам данных.VLDB Endowment, pp. 1150–1160
Павло А., Курино С., Здоник С. (2012) Автоматическое разбиение базы данных с учетом асимметрии в параллельных OLTP-системах без совместного использования ресурсов. В: Материалы международной конференции ACM SIGMOD 2012 по управлению данными. ACM, pp 61–72
NuoDB Team [EB / OL] (2016) NuoDB. http://www.nuodb.com/. По состоянию на 22 января 2018 г.
Брантнер М., Флореску Д., Граф Д. и др. (2008) Создание базы данных на S3. В: Материалы международной конференции ACM SIGMOD 2008 по управлению данными.ACM, pp 251–264
Stonebraker M (2010) Базы данных SQL v. Базы данных NoSQL. Commun ACM 53 (4): 10–11
Статья Google ученый
Озкан Ф, Татбул Н., Абади Д.Дж. и др. (2014) Мы переживаем пузырь больших данных? В: Материалы международной конференции ACM SIGMOD 2014 по управлению данными. ACM, pp 1407–1408
Павло А., Аслетт М. (2016) Что действительно нового в NewSQL? ACM Sigmod Rec 45 (2): 45–55
Статья Google ученый
Krueger J, Kim C, Grund M et al (2011) Быстрые обновления баз данных, оптимизированных для чтения, с использованием многоядерных процессоров. Proc VLDB Endow 5 (1): 61–72
Статья Google ученый
Баршай В., Чан И, Лу Х и др. (2012) Обеспечение непрерывности и максимальной производительности с помощью функции IBM DB2 pureScale. IBM Redbooks, Нью-Йорк
Google ученый
Ailamaki A, Liarou E, Tözün P et al (2015) Как остановить недоиспользование и полюбить многоядерные процессоры.В: 2015 IEEE 31-я международная конференция по инженерии данных (ICDE). IEEE, стр. 1530–1533
Контрольные вопросы для «Суперкомпьютерные вычисления на простом английском» ================================================== ==== Выберите ЛУЧШИЙ ответ на каждый вопрос. ————————————————— ———————- (1) Что из этого * НЕ * вызывает беспокойство в области суперкомпьютеров? (а) Размер (б) объектно-ориентированное программирование (c) Параллельность (d) Скорость ОТВЕТ: (б).Хотя ООП можно использовать в суперкомпьютерах, это не так. необходимо, и многие популярные суперкомпьютерные приложения не используют ООП. ————————————————— ———————- (2) Что из этого * НЕ * является общей категорией использования суперкомпьютеров? а) интеллектуальный анализ данных (б) Графические пользовательские интерфейсы (c) Визуализация (d) Моделирование физических явлений ОТВЕТ: (б). Фактически, многие популярные суперкомпьютерные приложения не имеют GUI, потому что интерактивное использование компьютера не является высокой производительностью.————————————————— ———————- (3) Что такое компилятор? (а) Программа, преобразующая понятный человеку исходный код в машиночитаемый исполняемый код. (б) Программа, которая выполняет другие программы параллельно в кластере. (c) язык программирования. (d) Программа, преобразующая слышимую человеческую речь в видимый текст. ОТВЕТ: (а) ————————————————— ———————- (4) В чем разница между параллелизмом с общей памятью? а распределенный параллелизм? (а) Многие задачи выполняются одновременно.(б) В одной из этих форм параллелизма все данные являются частными, а в другом — некоторые данные могут совместно использоваться процессорами. (c) Необходимо указать количество процессов / потоков. (d) Количество процессов / потоков должно совпадать с количеством доступных процессоров. ОТВЕТ: (б) ————————————————— ———————- (5) Какой из них является правильным порядком скорости, от самой быстрой до самый медленный? (а) CD-ROM, жесткий диск, основная память, кэш-память (b) Основная память, кэш-память, жесткий диск, CD-ROM (c) Жесткий диск, кэш-память, CD-ROM, основная память (d) Кэш-память, основная память, жесткий диск, CD-ROM. ОТВЕТ: (d) ————————————————— ———————- (6) Какой из них является правильным порядком цены, от наивысшего до самый низкий? (а) CD-ROM, жесткий диск, основная память, кэш-память (b) Основная память, кэш-память, жесткий диск, CD-ROM (c) Жесткий диск, кэш-память, CD-ROM, основная память (d) Кэш-память, основная память, жесткий диск, CD-ROM. ОТВЕТ: (d) ————————————————— ———————- (7) Какой из них является правильным порядком размеров, от наибольшего до самый маленький, на обычном компьютере? (а) CD-ROM, жесткий диск, основная память, кэш-память (b) Основная память, кэш-память, жесткий диск, CD-ROM (c) Жесткий диск, кэш-память, CD-ROM, основная память (d) Кэш-память, основная память, жесткий диск, CD-ROM. ОТВЕТ: (а) ————————————————— ———————- (8) Что из этого лучше всего описывает данные, хранящиеся в регистрах? (а) Данные, которые используются прямо сейчас.(б) Данные, которые собираются использовать или только что были использованы. (c) Данные, которые используются программой, которая в настоящее время выполняется. (d) Данные, которые необходимо сохранить, даже когда компьютер выключен. выключенный. ОТВЕТ: (а) ————————————————— ———————- (9) Какой из них лучше всего описывает данные, хранящиеся в кеше? (а) Данные, которые используются прямо сейчас. (b) Данные, которые собираются использовать или только что были использованы. (c) Данные, которые используются программой, которая в настоящее время выполняется.(d) Данные, которые необходимо сохранить, даже когда компьютер выключен. выключенный. ОТВЕТ: (б) ————————————————— ———————- (10) Что из этого лучше всего описывает данные, хранящиеся в ОЗУ? (а) Данные, которые используются прямо сейчас. (b) Данные, которые собираются использовать или только что были использованы. (c) Данные, которые используются программой, которая в настоящее время выполняется. (d) Данные, которые необходимо сохранить, даже когда компьютер выключен. выключенный. ОТВЕТ: (c) ————————————————— ———————- (11) Какой из них лучше всего описывает данные, хранящиеся на жестком диске? (а) Данные, которые используются прямо сейчас.(b) Данные, которые собираются использовать или только что были использованы. (c) Данные, которые используются программой, которая в настоящее время выполняется. (d) Данные, которые необходимо сохранить, даже когда компьютер выключен. выключенный. ОТВЕТ: (d) ————————————————— ———————- (12) Почему у большинства современных компьютеров есть кэш? (а) ЦП может вычислять немного быстрее, чем могут перемещаться данные между процессором и кешем, но намного быстрее, чем данные могут перемещаться между ЦП и ОЗУ.(b) Кэш — это место, где временные результаты сохраняются во время расчета, но эти результаты никогда не переместятся в оперативную память. (c) Кэш — это место, где временные результаты сохраняются во время расчета, и эти результаты в конечном итоге переместятся в ОЗУ. (d) Наиболее важные данные программы хранятся в кеш-памяти, но не в ОЗУ. ОТВЕТ: (а) ————————————————— ———————- (13) Что из этого НЕ является синонимом основной памяти? (а) Оперативная память (RAM) (б) Ядро (c) Постоянное запоминающее устройство (ПЗУ) ОТВЕТ: (c) ————————————————— ———————- (14) Что такое строка кэша? (а) Один байт кеша.(b) Значение с плавающей запятой двойной точности (т. е. 8 байтов). (c) Фиксированное количество байтов, в зависимости от типа процессора, которое все перемещаться в кэш или из кеша вместе. (d) Все байты в кэше. ОТВЕТ: (c) ————————————————— ———————- (15) В схеме кэша с прямым отображением, сколько разных расположений в кеше мог ли байт ОЗУ войти? (а) 1 (Би 2 (в) 4 (d) Любое место в тайнике ОТВЕТ: (а) ————————————————— ———————- (16) В полностью ассоциативной схеме кэширования сколько разных мест в кеше мог ли байт ОЗУ войти? (а) 1 (Би 2 (в) 4 (d) Любое место в тайнике ОТВЕТ: (d) ————————————————— ———————- (17) В четырехсторонней схеме ассоциативного кеширования, сколько разных расположений в кеше мог ли байт ОЗУ войти? (а) 1 (Би 2 (в) 4 (d) Любое место в тайнике ОТВЕТ: (c) ————————————————— ———————- (18) Что происходит в схеме кэша с прямым отображением в случае конфликт кеша? (a) Данные, находящиеся в данный момент в данной строке кэша, копируются обратно в ОЗУ. при необходимости, а затем новая строка RAM затирает данный строка кеша.(b) Выбрана одна из ограниченного числа возможных строк кэша, данные, находящиеся в данный момент в этой строке кэша, копируются обратно в ОЗУ при необходимости, а затем новая линейка клобберов RAM, которые строка кеша. (c) Выбрана любая из строк кэша, данные, находящиеся в данный момент в этой строке кэша, копируются обратно в ОЗУ, если необходимо, а затем новая линейка клобберов RAM, которые строка кеша. ОТВЕТ: (а) ————————————————— ———————- (19) Популярны ли схемы кэширования с прямым отображением? (а) Да, потому что они недорогие.(b) Нет, поскольку существует неоправданно высокая вероятность затирать строку кеша, которая скоро понадобится. (c) Нет, потому что большое количество соединений между ОЗУ и кешем сделать эту схему слишком дорогой. (d) Нет, потому что множество возможных алгоритмов отображения для этой схемы усложняют проектирование оборудования. ОТВЕТ: (б) ————————————————— ———————- (20) Насколько популярны схемы ассоциативного кэширования? (а) Да, потому что существует достаточно низкая вероятность заткнуть строка кэша, которая понадобится в ближайшее время, в сочетании с разумным низкое количество соединений между ОЗУ и кешем и, следовательно, разумная стоимость.(c) Нет, потому что большое количество соединений между ОЗУ и кешем сделать эту схему слишком дорогой. (d) Нет, потому что множество возможных алгоритмов отображения для этой схемы усложняют проектирование оборудования. ОТВЕТ: (а) ————————————————— ———————- (21) Популярны ли полностью ассоциативные схемы кэширования? (а) Да, потому что существует очень низкая вероятность заткнуть строка кеша, которая скоро понадобится. б) Да, потому что они недорогие. (c) Нет, потому что большое количество соединений между ОЗУ и кешем сделать эту схему слишком дорогой.(d) Нет, потому что множество возможных алгоритмов отображения для этой схемы усложняют проектирование оборудования. ОТВЕТ: (c) ————————————————— ———————- (22) Что из этого * НЕ * является стратегией замены кеша? (а) Наименее недавно использованные (б) Наименее измененные в последнее время (c) Круговая система (d) Первая подгонка ОТВЕТ: (d) ————————————————— ———————- (23) Если переменная находится в кеше, находится ли она также в ОЗУ? (а) Да, потому что кеш содержит подмножество ОЗУ.(b) Нет, потому что кэш и оперативная память не пересекаются. (c) Возможно, потому что программа может использовать кеш, но не использовать оперативную память. (d) Нет, потому что программа не может использовать оба одновременно. ОТВЕТ: (а) ————————————————— ———————- (24) Что значит грязная строка кэша? (a) Все байты в строке кэша были изменены. (b) Любой из байтов в строке кэша был изменен. (c) Ни один из байтов в строке кэша не был изменен. (d) Строка кэша в настоящее время не используется.ОТВЕТ: (б) ————————————————— ———————- (25) Что такое временная локальность данных? (а) Если данные по определенному адресу использовались недавно, то эти данные скоро будут использоваться снова. (b) Если данные по определенному адресу использовались недавно, то данные по близлежащим адресам скоро будут использоваться. (c) Если данные по определенному адресу использовались недавно, то тогда никакие данные на заданном расстоянии от этого адреса не будут используется в течение определенного времени.(d) В любое время данные по всем адресам имеют равную вероятность быть использованным. ОТВЕТ: (а) ————————————————— ———————- (26) Что такое локальность пространственных данных? (а) Если данные по определенному адресу использовались недавно, то эти данные скоро будут использоваться снова. (b) Если данные по определенному адресу использовались недавно, то данные по близлежащим адресам скоро будут использоваться. (c) Если данные по определенному адресу использовались недавно, то тогда никакие данные на заданном расстоянии от этого адреса не будут используется в течение определенного времени.(d) В любое время данные по всем адресам имеют равную вероятность быть использованным. ОТВЕТ: (б) ————————————————— ———————- (27) Что такое тайлинг? (а) Разделение проблемной области на части, каждая из которых может уместиться в cache, чтобы увеличить количество попаданий в кеш и, следовательно, представление. (б) разбиение проблемной области на части одинакового размера, для увеличения количества попаданий в кеш и, следовательно, представление. (c) Добавление любого дополнительного кода в программу для улучшения ее представление.ОТВЕТ: (а) ————————————————— ———————- (28) Почему жесткий диск медленнее ОЗУ? (а) Жесткий диск является механическим, а ОЗУ — электронным. (б) Жесткий диск больше ОЗУ. (c) Жесткий диск использует магнетизм, в то время как RAM использует электричество. (d) Жесткий диск дешевле ОЗУ. ОТВЕТ: (а) ————————————————— ———————- (29) Почему для ввода-вывода жесткого диска следует использовать двоичные представления а не текст, читаемый человеком? (a) Двоичные данные обычно занимают меньше места на диске, чем текст.(b) Данные, удобочитаемые человеком, менее безопасны, чем данные, считываемые компьютером. (c) Двоичные данные всегда переносимы между разными типами компьютеры. (d) Двоичные данные не могут быть легко преобразованы в читаемый человеком текст. ОТВЕТ: (а) ————————————————— ———————- (30) Что из этого * НЕ * является причиной использования переносимой библиотеки ввода-вывода? например HDF или NetCDF? (а) Переносимые библиотеки ввода-вывода оптимизированы по скорости. (б) Двоичные данные компактнее текста. (c) Переносимые двоичные данные могут быть прочитаны на машинах другого типа. чем было написано.(d) Переносимые двоичные данные всегда сохраняют точные побитовые копии данные, которые изначально были в ОЗУ. ОТВЕТ: (d) ————————————————— ———————- (31) Что из перечисленного лучше всего определяет параллелизм? (а) Запуск в кластере. (b) Работает на компьютере с общей памятью. (c) Работает на нескольких процессорах. (d) одновременное выполнение нескольких потоков выполнения. ОТВЕТ: (d) ————————————————— ———————- (32) Что из перечисленного лучше всего определяет параллелизм на уровне инструкций? (а) Набор методов для выполнения нескольких инструкций на в то же время.(b) Набор методов для выполнения нескольких инструкций на в одно и то же время на одном компьютере. (c) Набор методов для выполнения нескольких инструкций на в одно и то же время в одном процессоре. (d) Набор методов для выполнения нескольких инструкций на в то же время на многих процессорах. ОТВЕТ: (c) ————————————————— ———————- (33) Что из этого * НЕ * является формой параллелизма на уровне инструкций? (а) Суперскаляр (б) Трубопровод (c) Вектор (d) OpenMP ОТВЕТ: (d) ————————————————— ———————- (34) Что из этого НЕ является инструкцией? (а) Доступ к памяти (например,г., загрузка, магазин) (б) Арифметические операции (например, сложение, деление) (c) Переход (переход от одной последовательности инструкций к другой) (d) Обратная подстановка (решите систему уравнений, которая была факторизовано разложением LU) ОТВЕТ: (d) ————————————————— ———————- (35) Если процессор имеет частоту 1 ГГц, сколько циклов у него будет? (а) 1 миллиард в секунду (б) 2 миллиарда в секунду (c) 1 миллион в секунду (г) 2 миллиона в секунду ОТВЕТ: (а) ————————————————— ———————- (36) Две инструкции независимы, когда: (а) Неважно, какой из них будет выполнен первым.(б) Имеет значение, кто из них будет выполнен первым. (c) Они работают с разными частями данных. (d) Один использует данные, которые находятся в кеше, а другой использует данные, которые в ОЗУ. ОТВЕТ: (а) ————————————————— ———————- (37) Что из этого * НЕ * является причиной, по которой циклы легко оптимизировать? (а) Их поведение очень предсказуемо. (б) Они очень распространены в программах, которые используют люди. суперкомпьютеры для. (c) У них гарантированно высокая локальность данных.(d) Их можно развернуть. ОТВЕТ: (c) ————————————————— ———————- (38) Какое из них является лучшим определением «редукции»? (а) Выполнение вычисления, которое преобразует множество данных в одно значение. (б) Вычисление суммы или произведения массива. (c) Вычисление скалярного произведения двух массивов. (d) Добавление двух массивов (покомпонентно) для получения нового массива. ОТВЕТ: (а) ————————————————— ———————- (39) Какая из этих арифметических операций обычно занимает меньше всего количество времени на выполнение? (а) Сложение с плавающей запятой (b) Деление с плавающей запятой (c) Квадратный корень с плавающей запятой (d) Возведение числа с плавающей запятой в степень с плавающей запятой ОТВЕТ: (а) ————————————————— ———————- (40) Какая из этих арифметических операций обычно занимает больше всего количество времени на выполнение? (а) Сложение с плавающей запятой (b) Деление с плавающей запятой (c) Квадратный корень с плавающей запятой (d) Возведение числа с плавающей запятой в степень с плавающей запятой ОТВЕТ: (d) ————————————————— ———————- (41) Что из этого * НЕ * предотвратит конвейерную обработку? (а) Выполнение множества операций сложения, вычитания и умножения.(b) Преждевременный выход из цикла. (c) Вызов функции или подпрограммы. (d) Выполнение ввода-вывода внутри цикла. ОТВЕТ: (а) ————————————————— ———————- (42) Что из этого лучше всего описывает векторный регистр? (а) Набор регистров, которые выполняют одну и ту же инструкцию. в то же время. (б) Набор регистров, которые выполняют одну и ту же инструкцию. при этом по разным данным. (c) Один регистр, который может выполнять одну и ту же инструкцию на многих данных очень быстро по очереди.(d) Набор одиночных регистров, которые могут выполнять одну и ту же инструкцию. на многих данных очень быстро по очереди. ОТВЕТ: (б) ————————————————— ———————- (43) Что из этого является примером зависимости управления? (a) ЕСЛИ (a> b) ТО c = d КОНЕЦ ЕСЛИ (b) ЕСЛИ (1> 2) ТО д = г КОНЕЦ ЕСЛИ (c) b = a c = b (г) b = a c = d ОТВЕТ: (а) ————————————————— ———————- (44) Что из этого является примером зависимости ветвления? (a) ЕСЛИ (a> b) ТО c = d КОНЕЦ ЕСЛИ (b) ЕСЛИ (1> 2) ТО д = г КОНЕЦ ЕСЛИ (c) b = a c = b (г) b = a c = d ОТВЕТ: (а) ————————————————— ———————- (45) Что из этого является примером зависимости с переносом цикла? (а) DO i = 2, n д (я) = а (я-1) + Ь (я) КОНЕЦ ДЕЛАТЬ (б) DO i = 2, n д (я) = а (я-1) + д (я) КОНЕЦ ДЕЛАТЬ (в) DO i = 2, n д (я) = д (я-1) + Ь (я) КОНЕЦ ДЕЛАТЬ (г) DO i = 2, n д (я) = д (я) + Ь (я) КОНЕЦ ДЕЛАТЬ ОТВЕТ: (c) ————————————————— ———————- (46) Примером какой зависимости является это? DO i = 2, n ЕСЛИ (x (i) / = 0) ТО у (я) = ЖУРНАЛ (х (я)) КОНЕЦ ЕСЛИ КОНЕЦ ДЕЛАТЬ (филиал (б) Данные (c) с петлей (d) Выход ОТВЕТ: (а) ————————————————— ———————- (47) Примером какой зависимости является это? д = х + у г = г + ш q = f — g (филиал (б) Данные (c) с петлей (d) Выход ОТВЕТ: (d) ————————————————— ———————- (48) Что из этого * НЕ * является сокращением? (а) сумма = 0 DO i = 1, n сумма = сумма + а (я) КОНЕЦ ДЕЛАТЬ (б) product = 1 DO i = 1, n product = product * a (i) КОНЕЦ ДЕЛАТЬ (c) максимум = a (1) DO i = 2, n ЕСЛИ (максимум 0) ТО а (я) = а (я) + 1 КОНЕЦ ЕСЛИ КОНЕЦ ДЕЛАТЬ ОТВЕТ: (d) ————————————————— ———————- (49) Какая стратегия оптимизации представлена этим преобразованием кода? а = б с = а + г СТАНОВИТСЯ а = б с = b + d (а) Копирование распространения (б) Постоянное сворачивание (c) Удаление мертвого кода (г) Снижение силы ОТВЕТ: (а) ————————————————— ———————- (50) Какая стратегия оптимизации представлена этим преобразованием кода? а = 2 b = 4 с = а * б СТАНОВИТСЯ с = 6 (а) Копирование распространения (б) Постоянное сворачивание (c) Удаление мертвого кода (г) Снижение силы ОТВЕТ: (б) ————————————————— ———————- (51) Какая стратегия оптимизации представлена этим преобразованием кода? а = б ОСТАНАВЛИВАТЬСЯ c = d СТАНОВИТСЯ а = б ОСТАНАВЛИВАТЬСЯ (а) Копирование распространения (б) Исключение общего подвыражения (c) Удаление мертвого кода (г) Снижение силы ОТВЕТ: (c) ————————————————— ———————- (52) Какая стратегия оптимизации представлена этим преобразованием кода? а = Ь ** 3 СТАНОВИТСЯ а = б * б * б (а) Переименование переменной (б) Постоянное сворачивание (c) Удаление мертвого кода (г) Снижение силы ОТВЕТ: (d) ————————————————— ———————- (53) Какая стратегия оптимизации представлена этим преобразованием кода? а = б + с * г е = е * с * д СТАНОВИТСЯ т = с * д а = Ь + т е = е * т (а) Переименование переменной (б) Исключение общего подвыражения (c) Удаление мертвого кода (г) Снижение силы ОТВЕТ: (б) ————————————————— ———————- (54) Какая стратегия оптимизации представлена этим преобразованием кода? а = б + с * г е = е * с * д а = д + г СТАНОВИТСЯ г = Ь + с * г е = е * с * д а = д + г (а) Переименование переменной (б) Исключение общего подвыражения (c) Удаление мертвого кода (г) Снижение силы ОТВЕТ: (а) ————————————————— ———————- (55) Какая стратегия оптимизации представлена этим преобразованием кода? DO i = 1, n д (я) = г (я) + е * 3 КОНЕЦ ДЕЛАТЬ СТАНОВИТСЯ т = е * 3 DO i = 1, n д (я) = г (я) + т КОНЕЦ ДЕЛАТЬ (a) Инвариантный код цикла подъема (b) Отключение (c) Итерационный пилинг (d) Обмен петлей ОТВЕТ: (а) ————————————————— ———————- (56) Какая стратегия оптимизации представлена этим преобразованием кода? DO i = 1, n DO j = 2, n ЕСЛИ (f (i) / = 0) ТО а (я, j) = а (я, j) / f (я) ЕЩЕ а (я, j) = 0 КОНЕЦ ЕСЛИ КОНЕЦ ДЕЛАТЬ КОНЕЦ ДЕЛАТЬ СТАНОВИТСЯ DO i = 1, n ЕСЛИ (f (i) / = 0) ТО DO j = 2, n а (я, j) = а (я, j) / f (я) КОНЕЦ ДЕЛАТЬ ЕЩЕ DO j = 2, n а (я, j) = 0 КОНЕЦ ДЕЛАТЬ КОНЕЦ ЕСЛИ КОНЕЦ ДЕЛАТЬ (a) Инвариантный код цикла подъема (b) Отключение (c) Итерационный пилинг (d) Обмен петлей ОТВЕТ: (б) ————————————————— ———————- (57) Какая стратегия оптимизации представлена этим преобразованием кода? DO i = 1, n ЕСЛИ (i == 1) ТО а (я) = 3 * Ь (я) ЕЩЕ а (я) = 3 * Ь (я — 1) КОНЕЦ ЕСЛИ КОНЕЦ ДЕЛАТЬ СТАНОВИТСЯ а (1) = 3 * Ь (1) DO i = 2, n а (я) = 3 * Ь (я — 1) КОНЕЦ ДЕЛАТЬ (a) Инвариантный код цикла подъема (b) Отключение (c) Итерационный пилинг (d) Обмен петлей ОТВЕТ: (c) ————————————————— ———————- (58) Какая стратегия оптимизации представлена этим преобразованием кода? DO i = 1, ni DO j = 1, nj q (i, j) = r (i, j) * 2 КОНЕЦ ДЕЛАТЬ КОНЕЦ ДЕЛАТЬ СТАНОВИТСЯ DO j = 1, nj DO i = 1, ni q (i, j) = r (i, j) * 2 КОНЕЦ ДЕЛАТЬ КОНЕЦ ДЕЛАТЬ (a) Инвариантный код цикла подъема (b) Отключение (c) Итерационный пилинг (d) Обмен петлей ОТВЕТ: (d) ————————————————— ———————- (59) Какая стратегия оптимизации представлена этим преобразованием кода? DO i = 1, n д (я) = г (я) * 2 ЕСЛИ (i> (n / 2)) ТО s (i) = t (i) / 5 КОНЕЦ ЕСЛИ КОНЕЦ ДЕЛАТЬ СТАНОВИТСЯ DO i = 1, n / 2 д (я) = г (я) * 2 КОНЕЦ ДЕЛАТЬ DO i = n / 2 + 1, n д (я) = г (я) * 2 s (i) = t (i) / 5 КОНЕЦ ДЕЛАТЬ (а) Разделение индексного набора (б) Раскрутка (c) Петлевой сплав (d) Петлевое деление ОТВЕТ: (а) ————————————————— ———————- (60) Какая стратегия оптимизации представлена этим преобразованием кода? DO i = 1, n д (я) = г (я) * 2 КОНЕЦ ДЕЛАТЬ СТАНОВИТСЯ ДО i = 1, n, 4 д (я) = г (я) * 2 д (я + 1) = г (я + 1) * 2 д (я + 2) = г (я + 2) * 2 д (я + 3) = г (я + 3) * 2 КОНЕЦ ДЕЛАТЬ (а) Разделение индексного набора (б) Раскрутка (c) Петлевой сплав (d) Петлевое деление ОТВЕТ: (б) ————————————————— ———————- (61) Какая стратегия оптимизации представлена этим преобразованием кода? DO i = 1, n д (я) = г (я) * 2 КОНЕЦ ДЕЛАТЬ DO i = 1, n s (i) = r (i) / 2 КОНЕЦ ДЕЛАТЬ СТАНОВИТСЯ DO i = 1, n д (я) = г (я) * 2 s (i) = r (i) / 2 КОНЕЦ ДЕЛАТЬ (а) Разделение индексного набора (б) Раскрутка (c) Петлевой сплав (d) Петлевое деление ОТВЕТ: (c) ————————————————— ———————- (62) Какая стратегия оптимизации представлена этим преобразованием кода? DO i = 1, n д (я) = г (я) * 2 s (i) = r (i) / 2 КОНЕЦ ДЕЛАТЬ СТАНОВИТСЯ DO i = 1, n д (я) = г (я) * 2 КОНЕЦ ДЕЛАТЬ DO i = 1, n s (i) = r (i) / 2 КОНЕЦ ДЕЛАТЬ (а) Разделение индексного набора (б) Раскрутка (c) Петлевой сплав (d) Петлевое деление ОТВЕТ: (d) ————————————————— ———————- (63) Что из перечисленного * НЕ * является причиной того, что встраивание может улучшить представление? (а) Это сокращает количество обычных звонков и, следовательно, время потратил на выполнение звонков.(b) Если встроенная процедура находилась внутри цикла, то компилятор может быть возможность оптимизировать цикл, что было бы невозможно внутри рутина, в которой нет цикла. (c) Уменьшает время компиляции. ОТВЕТ: (c) ————————————————— ———————- (64) Что из этого * НЕ * способствует времени выполнения? (а) Время компиляции (б) Количество пользователей в системе, на которой выполняется (c) Операционная система (d) Аппаратное обеспечение ОТВЕТ: (а) ————————————————— ———————- (65) Какого рода информацию дает профилирование подпрограмм? (а) Сколько времени было потрачено на каждое упражнение (б) Сколько времени было потрачено на вычисления (c) Сколько времени было потрачено на ввод-вывод (d) Сколько времени было потрачено на перемещение данных между памятью и ЦП. ОТВЕТ: (а) ————————————————— ———————- (66) Что из этого верно? (a) Потоки используют разделяемую память, а процессы — нет.(b) Процессы используют разделяемую память, а потоки — нет. (c) И потоки, и процессы используют общую память. (d) Ни потоки, ни процессы не используют разделяемую память. ОТВЕТ: (а) ————————————————— ———————- (67) Что из этого * НЕ * связано с потоками? (а) Общая память (б) Процессоры обмениваются данными через память (c) Одни темы расходятся от других. (d) Передача сообщений ОТВЕТ: (d) ————————————————— ———————- (68) Что из этого является свойством Закона Амдала? (а) Ускорение ограничено той частью кода, которая не распараллеливание.(b) Ускорение ограничено частью кода, которая не является ни тем, ни другим. ни последовательный, ни параллельный. (c) Ускорение ограничено той частью кода, которая выполняет ввод-вывод. (d) Ускорение ограничено частью кода, который проходит Сообщения. ОТВЕТ: (а) ————————————————— ———————- (69) Что означает «линейное ускорение»? (а) Ускорение кода равно количеству процессоров. (б) Ускорение кода меньше количества процессоров. (c) Ускорение кода больше, чем количество процессоров.(d) Ускорение кода обратно пропорционально количество процессоров. ОТВЕТ: (а) ————————————————— ———————- (70) Что такое «крупнозернистый» и «мелкозернистый» параллелизм? (а) «Крупнозернистый» — это когда в программе небольшое количество крупных части, которые будут запускаться параллельно; «мелкое зерно» — это когда у него есть большое количество мелких деталей. (б) «Крупнозернистый» — это когда в программе большое количество мелких части, которые будут запускаться параллельно; «мелкое зерно» — это когда у него есть небольшое количество крупных штук.(c) «Крупнозернистый» — это когда программа имеет большое количество крупных части, которые будут запускаться параллельно; «мелкое зерно» — это когда у него есть небольшое количество мелких кусочков. (г) «Крупнозернистый» — это когда в программе есть небольшое количество мелких части, которые будут запускаться параллельно; «мелкое зерно» — это когда у него есть большое количество крупных штук. ОТВЕТ: (а) ————————————————— ———————- (71) Какой из этих факторов * НЕ * способствует параллельным накладным расходам? (а) Управление потоками / процессами (б) Связь между потоками / процессами (c) Синхронизация (d) Расчеты ОТВЕТ: (d) ————————————————— ———————- (72) Что такое балансировка нагрузки? (а) Обеспечение того, чтобы все переработчики имели примерно одинаковое количество работа, которую нужно сделать (б) Обеспечение того, чтобы у всех переработчиков было много работы (c) Обеспечение того, чтобы у всех переработчиков был разный объем работы. (d) Обеспечение того, чтобы все переработчики завершили свою работу примерно в в то же время ОТВЕТ: (d) ————————————————— ———————- (73) Балансировка нагрузки — это легко или сложно? (а) Легко (б) сложно (c) Всегда одинаковая сложность независимо от приложения. или алгоритм (d) Сложность зависит от приложения и алгоритма. ОТВЕТ: (d) ————————————————— ———————- (74) Что из этого лучше всего описывает «разветвление»? (а) Поток порождает «дочерний» поток.(б) «Дочерний» поток завершает работу, оставляя только своего родителя. (c) Поток порождает «дочерний» процесс. (d) Все потоки закрываются в конце программы. ОТВЕТ: (а) ————————————————— ———————- (75) Что из этого лучше всего описывает «присоединение»? (а) Поток порождает «дочерний» поток. (б) «Дочерний» поток завершает работу, оставляя только своего родителя. (c) Поток порождает «дочерний» процесс. (d) Все потоки закрываются в конце программы. ОТВЕТ: (б) ————————————————— ———————- (76) Что из этого * НЕ * является частью OpenMP? (а) Директивы компилятора (б) Функции (c) Переменные среды (d) Передача сообщений ОТВЕТ: (d) ————————————————— ———————- (77) Что означает переменная среды OpenMP OMP_NUM_THREADS указывать? (а) Сколько потоков следует использовать в параллельной секции.(б) Сколько процессов должна использовать параллельная секция. (c) Сколько сообщений должна обмениваться параллельная секция. (d) Сколько итераций должен иметь параллельный цикл. ОТВЕТ: (а) ————————————————— ———————- (78) В каком порядке выполняются итерации параллельного цикла. они казнены? (а) От первого к последнему (б) От последнего к первому (c) В заранее заданной случайной последовательности (d) В недетерминированной случайной последовательности ОТВЕТ: (d) ————————————————— ———————- (79) Что из перечисленного лучше всего описывает ключевое различие между частными а общие данные? (a) Частные данные видны только одному потоку, а общие данные доступны для всех потоков.(б) Личные данные видны всем потокам, а общие данные доступны только одному потоку. (c) Личные данные видны только одному потоку за раз, в то время как общие данные доступны для всех потоков. (d) Личные данные видны всем потокам, а общие данные доступны только одному потоку одновременно. ОТВЕТ: (а) ————————————————— ———————- (80) Может ли параллельный цикл иметь только общие данные без личных данных вообще? (а) Да.(b) Нет, потому что индексная переменная цикла (также называемая счетчиком) должно быть приватным. (c) Нет, потому что массив, с которым работает цикл, должен быть частным. (d) Нет, потому что любые скалярные переменные, используемые для промежуточных вычислений должно быть приватным. ОТВЕТ: (б) ————————————————— ———————- (81) Может ли параллельный цикл содержать только частные данные без общих данных вообще? (а) Да. (b) Нет, потому что индексная переменная цикла (также называемая счетчиком) должны быть разделены.(c) Нет, потому что массив, с которым работает цикл, должен быть общим. (d) Нет, потому что любые скалярные переменные, используемые для промежуточных вычислений должны быть разделены. ОТВЕТ: (а) ————————————————— ———————- (82) Какое из этих утверждений о стратегиях планирования НЕВЕРНО? (а) У статики меньше всего накладных расходов. (b) Динамический предназначен для циклов с итерациями, которые сильно изменяются. объем работы, так что циклы трудно сбалансировать. (c) Управляемый — это компромисс между статикой и динамикой.(d) Лучшая стратегия всегда может быть известна до тестирования всех трех. ОТВЕТ: (а) ————————————————— ———————- (83) Что из этого лучше всего описывает синхронизацию? (а) Каждый поток ожидает, пока все другие потоки закончат конкретный параллельный цикл перед переходом к следующему параллельному циклу. (b) Только один поток одновременно может выполнять определенную часть код. (c) Только главный поток может выполнять определенную часть кода. (d) Каждый поток выполняет один и тот же блок кода синхронно, все выполнение одной и той же инструкции в одно и то же время.ОТВЕТ: (а) ————————————————— ———————- (84) Какое из этих утверждений о барьерах является * ЛОЖНЫМ *? (а) Синхронизация сил барьера. (b) Параллельная петля имеет неявный барьер на конце. (c) Заграждение может быть размещено в любом месте на любом параллельном участке. (d) Параллельная петля имеет неявный барьер в начале. ОТВЕТ: (d) ————————————————— ———————- (85) Какой из них лучше всего описывает критические секции? (а) Каждый поток ожидает, пока все другие потоки закончат конкретный параллельный цикл перед переходом к следующему параллельному циклу.(b) Только один поток одновременно может выполнять определенную часть код. (c) Только главный поток может выполнять определенную часть кода. (d) Каждый поток выполняет один и тот же блок кода синхронно, все выполнение одной и той же инструкции в одно и то же время. ОТВЕТ: (б) ————————————————— ———————- (86) Что из этого лучше всего описывает состояние гонки? (а) Значение, помещенное в конкретную переменную, недетерминировано, потому что несколько разных потоков пытаются изменить его на в то же время.(b) Значение, помещенное в конкретную переменную, недетерминировано, потому что каждый поток имеет свою собственную частную копию. (c) Несколько потоков пытаются заполнить разные элементы тот же массив одновременно. (d) Несколько потоков пытаются заполнить разные массивы в в то же время. ОТВЕТ: (а) ————————————————— ———————- (87) Какое из этих утверждений о распределенной обработке верно? (а) Некоторые данные передаются. (b) Процессы обмениваются данными посредством копий из памяти в память.(c) Единственная важная стоимость связи — это полоса пропускания. (d) Все данные являются личными. ОТВЕТ: (d) ————————————————— ———————- (88) Какое из этих определений лучше всего? (а) Задержка — это время, необходимое для подключения, и пропускная способность. время на байт. (б) Пропускная способность — это время, необходимое для подключения и задержка. время на байт. (c) Задержка — это долларовые затраты на подключение, а пропускная способность — это долларовая стоимость за байт.(d) Пропускная способность — это долларовые затраты на подключение, а задержка — это долларовая стоимость за байт. ОТВЕТ: (а) ————————————————— ———————- (89) Что из этого лучше всего описывает, почему так важна балансировка нагрузки? (а) Поскольку несбалансированная нагрузка приводит к простоям некоторых процессоров в некоторых случаях, что увеличивает общее время выполнения по сравнению с сбалансированная нагрузка. (б) Потому что некоторые процессоры будут перегреваться, если им дать слишком много работа, которую нужно сделать. (c) Поскольку балансировка нагрузки — это проблема обычно применимого решение, которое следует использовать в большинстве случаев.(d) Поскольку балансировка нагрузки увеличивает количество процессоров, которые может работать над проблемой. ОТВЕТ: (а) ————————————————— ———————- (90) Какая процедура MPI должна вызываться перед любой другой подпрограммой MPI? (а) MPI_Init (б) MPI_Comm_size (c) MPI_Comm_rank (d) MPI_Finalize ОТВЕТ: (а) ————————————————— ———————- (91) Какая процедура MPI должна вызываться после всех других подпрограмм MPI? (а) MPI_Init (б) MPI_Comm_size (c) MPI_Comm_rank (d) MPI_Finalize ОТВЕТ: (d) ————————————————— ———————- (92) Какая процедура MPI определяет количество используемых процессов. по текущему пробегу? (а) MPI_Init (б) MPI_Comm_size (c) MPI_Comm_rank (d) MPI_Finalize ОТВЕТ: (б) ————————————————— ———————- (93) Какая процедура MPI определяет, какой из процессов является текущий процесс? (а) MPI_Init (б) MPI_Comm_size (c) MPI_Comm_rank (d) MPI_Finalize ОТВЕТ: (c) ————————————————— ———————- (94) Что из этого лучше всего описывает сокрытие общения? (а) Осуществление общения при одновременном выполнении вычисления, чтобы исключить временные затраты на коммуникация.(б) Осуществление общения при одновременном выполнении вычисления, чтобы исключить временные затраты на вычисление. (c) Выполнение связи перед выполнением вычислений, чтобы исключить временные затраты на общение. (c) Выполнение связи перед выполнением вычислений, чтобы исключить временные затраты на вычисления. ОТВЕТ: (а) ————————————————— ———————- (95) Что из этого * НЕ * является хорошим способом решения системы линейных уравнения? (а) Переверните матрицу, затем умножьте.(b) Используйте стандартную переносную библиотеку решателей. (c) Используйте версию стандартной переносимой библиотеки решателей, которая оптимизирован для платформы, на которой вы работаете. (d) Используйте информацию о линейной системе, чтобы выбрать наиболее возможен эффективный алгоритм решателя. ОТВЕТ: (а) ————————————————— ———————- (96) Какие из этих свойств матрицы * НЕ * * помогут вам ускорить решение системы линейных уравнений? (а) Симметрия (б) Трехдиагональность (c) Редкость (d) Асимметрия ОТВЕТ: (d) ————————————————— ———————-
1.6 Иерархия памяти — Разработка LibreTexts
- Последнее обновление
- Сохранить как PDF
Memory Hierarchy — это усовершенствованная система организации памяти, позволяющая минимизировать время доступа. Иерархия памяти была разработана на основе поведения программы, известного как локальность ссылок.На рисунке ниже наглядно показаны различные уровни иерархии памяти:
Эта структура иерархии памяти делится на 2 основных типа:
- Внешняя память или вторичная память —
Состоит из магнитного диска, оптического диска, магнитной ленты, т. Е. Периферийных запоминающих устройств, которые доступны процессору через модуль ввода-вывода. - Внутренняя память или основная память —
Состоит из основной памяти, кэш-памяти и регистров ЦП.Это напрямую доступно процессору.
Из рисунка выше мы можем вывести следующие характеристики структуры иерархии памяти:
- Емкость:
Это общий объем информации, который может хранить память. По мере того, как мы перемещаемся по иерархии сверху вниз, емкость увеличивается. - Время доступа:
Это временной интервал между запросом чтения / записи и доступностью данных. По мере того, как мы перемещаемся по иерархии сверху вниз, время доступа увеличивается. - Производительность:
Раньше, когда компьютерная система проектировалась без использования иерархии памяти, разрыв в скорости между регистрами ЦП и основной памятью увеличивался из-за большой разницы во времени доступа. Это приводит к снижению производительности системы и, следовательно, требует улучшения. Это усовершенствование было сделано в виде дизайна иерархии памяти, благодаря которому производительность системы увеличивается. Один из наиболее важных способов повышения производительности системы — это минимизация того, насколько далеко вниз по иерархии памяти нужно идти, чтобы манипулировать данными. - Стоимость за бит:
По мере продвижения снизу вверх в Иерархии стоимость за бит увеличивается, т. Е. Внутренняя память стоит дороже, чем внешняя.
Адаптировано из:
«Структура иерархии памяти и ее характеристики» от RishabhJain12, Geeks for Geeks под лицензией CC BY-SA 4.0