Почему 8 и 256 такие важные числа в компьютерных науках?
Исторически байты не всегда были 8-битными по размеру (если уж на то пошло, компьютеры тоже не обязательно должны быть двоичными, но на практике недвоичные вычисления показали гораздо меньше действий). Именно по этой причине стандарты IETF и ISO часто используют термин октет — они не используют байт , потому что не хотят предполагать, что он означает 8 бит, когда это не так.
Действительно, когда байт был придуман, он был определен как единица измерения 1-6 бит. Размеры байтов, используемые на протяжении всей истории, включают 7, 9, 36 и машины с байтами переменного размера.
8 было смесью коммерческого успеха, это было достаточно удобное число для людей, думающих об этом (которые питали бы друг друга), и, без сомнения, по другим причинам, о которых я совершенно не знаю.
Упомянутый вами стандарт ASCII предполагает 7-битный байт и был основан на более ранних 6-битных стандартах связи.
Правка: Возможно, стоит добавить к этому, поскольку некоторые настаивают на том, что те, кто говорит, что байты всегда являются октетами, путают байты со словами.
Октет -это имя, данное единице из 8 бит (от латинского слова «восемь»). Если вы используете компьютер (или на более высоком уровне абстракции, язык программирования), где байты являются 8-битными, то это легко сделать, в противном случае вам понадобится некоторый код преобразования (или покрытие в аппаратном обеспечении). Концепция октета чаще встречается в сетевых стандартах, чем в локальных вычислениях, поскольку, будучи нейтральной к архитектуре, она позволяет создавать стандарты, которые могут использоваться для связи между машинами с разные размеры байтов, следовательно, его использование в стандартах IETF и ISO (кстати, ISO/IEC 10646 использует октет, где стандарт Unicode использует байт для того, что по существу — с некоторыми незначительными дополнительными ограничениями на последнюю часть — один и тот же стандарт, хотя стандарт Unicode подробно описывает, что они означают октет по байту, даже если байты могут быть разных размеров на разных машинах).
Исторически байт был размером, используемым для хранения символа, что, в свою очередь, основывается на практике, стандартах и стандартах де-факто, которые предшествовали компьютерам, используемым для телекса и других методов связи, начиная, возможно, с Бодо в 1870 году (я не знаю ни одного из них ранее, но открыт для исправлений).
Это отражается в том факте, что в C и C++ единица хранения байта называется char , размер которого в битах определяется CHAR_BIT в стандартном заголовке limits.h. Различные машины будут использовать 5,6,7,8,9 или более битов для определения символа. В наши дни, конечно, мы определяем символы как 21-битные и используем различные кодировки для их хранения в 8 -, 16 — или 32-битных единицах (и неавторизованные способы, такие как UTF-7 для других размеров), но исторически так было.
В языках, которые стремятся быть более согласованными между машинами, а не отражать архитектуру машины, byte , как правило, фиксируется в языке, и в наши дни это обычно означает, что он определяется в языке как 8-битный. Учитывая момент в истории, когда они были сделаны, и то, что большинство машин теперь имеют 8-битные байты, различие в значительной степени спорно, хотя реализовать компилятор, время выполнения и т. Д. Не невозможно. для таких языков на машинах с байтами разного размера просто не так просто.
Слово-это размер «natural» для данного компьютера. Это менее четко определено, поскольку затрагивает несколько перекрывающихся проблем, которые, как правило, совпадают, но могут и не совпадать. Большинство регистров на машине будут иметь такой размер, но некоторые могут и не иметь. Самый большой размер адреса обычно будет словом, хотя это может быть и не так (Z80 имел 8-битный байт и 1-байтовое слово, но допускал некоторое удвоение регистров, чтобы обеспечить некоторую 16-битную поддержку, включая 16-битную адресацию).
Опять же, мы видим здесь разницу между C и C++, где int определяется в терминах размера слова, а long определяется для использования процессора, который имеет концепцию «long word», если таковая существует, хотя, возможно, в данном случае идентична int . Минимальное и максимальное значения снова находятся в заголовке limits.h. (Действительно, с течением времени int может быть определен как меньший, чем естественный размер слова, как сочетание согласованности с тем, что распространено в других местах, сокращение использования памяти для массива int и, вероятно, другие проблемы, о которых я не знаю).
языки Java и .NET используют подход, определяющий int и long как фиксированные во всех архитектурах, и делают решение проблем с различиями проблемой для среды выполнения (особенно JITter). Примечательно, однако, что даже в .NET размер указателя (в небезопасном коде) будет варьироваться в зависимости от архитектуры, чтобы быть базовым размером слова, а не навязанным языком размером слова.
Следовательно, октет, байт и слово очень независимы друг от друга, несмотря на то, что отношение октета == байт и слово представляют собой целое число байтов (и целое двоичное круглое число, такое как 2, 4, 8 и т. Д.), распространенное сегодня.
256 бит равно байт — Все о Windows 10
На чтение 5 мин. Просмотров 101 Опубликовано
1 Байт = 8 бит, т.е. это строка 1,2,3,4,5,6,7,8 почему тогда 2 возводят в 8-ю степень и получают 256 ? И что с этим делать? Т.е. каким образом и для чего записываются данные?
P.S. Извиняюсь за столь детский вопрос, но я никак не могу понять зачем это действие нужно?
Ваши рассуждения не совсем точны.
В байте действительно 8 бит, но нумеруются они от 0 до 7, причем нумерация ведется справа налево по возрастанию. Каждый такой номер является «весом» для бита равного 1, а вес этот измеряется соответствующей степенью числа 2 (биты это двоичная система счисления, где возможны только варианты 0 или 1).
или 1+2+4+8+16+32+64+128 = 255. Но еще осталось значение 0, соответствующее случаю, когда все 8 бит байта нулевые. Следовательно, максимум кодов какие можно получить с помощью одного байта составляет 255+1 = 256 кодов (символов).
1 байт не может вместить 256 символов, одним байтом можно закодировать любой один из 256-ти символов, потому что именно столько уникальных комбинаций может принять последовательность из 8-ми двоичных бит. Один двоичный бит — это наименьшая единица количества информации, он может принять лишь два значения 0 и 1. Последовательность двух бит может принят уже 4 значения: 00, 01, 10 и 11, а из трех бит 8 значений, 000, 001 и так далее. Добавление каждого бита увеличивает количество возможных значений, которая может принять битовая последовательность в два раза, соответственно последовательность из 8 бит сможет принять 256 различных значений. Поэтому и используют степени двойки, так как 2 в степени N равно тому, сколько значений может принять последовательность из N двоичных бит.
Далее, существуют кодовые таблицы (ASCII, Win-1251 и т.п.), в которых каждым символам, таким как: большие и маленькие буквы английского и национального алфавитов, цифры, знаки препинания и спецсимволы, соответствует определенное значение байта, например для символа Q — это 81, соответственно 01010001. И всего в таблице и есть 256 символов, но при этом одним байтом можно «написать» один символ, а что-бы его потом прочитать, необходимо знать какая кодовая таблица, так называемая «кодировка», использовалась.
Но если это Ваша очепятка, и речь идет о Байтах, тогда извольте:
а) Если байт считать октетом, то 1 Байт равен 8 битам ( 1 Б = 8 б )
б) 1 КилоБайт равен 1024 Байтам ( 1 КБ=1024 Б )
в) 1 МегаБайт равен 1024 КилоБайтам ( 1 МБ = 1024 КБ)
Ответ: В 256 МегаБайт содержится 2147483648 бит.
Что такое 256-битное шифрование? Это то, что каждый центр сертификации и его реселлеры говорят при рекламе своих SSL-сертификатов.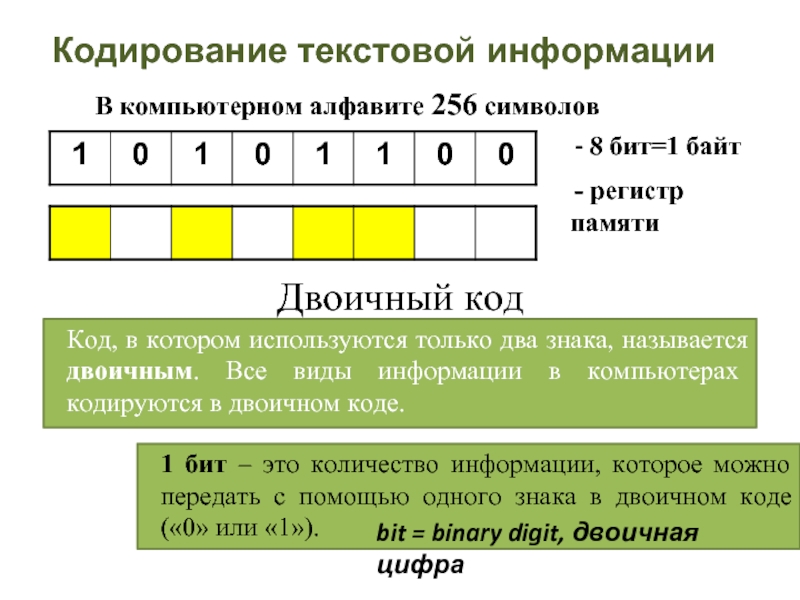 А почему бы и нет? В конце концов, шифрование является самым важным в SSL-сертификатах. Но многие пользователи, в том числе некоторые из клиентов нашей компании, не знают о действительной пользе, которую дает 256-битное шифрование.
А почему бы и нет? В конце концов, шифрование является самым важным в SSL-сертификатах. Но многие пользователи, в том числе некоторые из клиентов нашей компании, не знают о действительной пользе, которую дает 256-битное шифрование.
Итак, давайте разберем его для Вас. Давайте разгадаем технологию, которая имеет 256-битное шифрование и поймем, как она защищает всех в Интернете.
Во-первых, давайте разберем SSL-шифрование
Принято считать, что SSL-шифрование выполняется с помощью пары ключей, известной как Public / Private Key Pair. Также считается, что открытый ключ шифрует данные, а Private Key расшифровывает его. Технически это называется «Асимметричное шифрование».
Однако, это не совсем так.
Фактическое шифрование данных не выполняется с помощью этого асимметричного метода; это делается с помощью Symmetric Encryption. Теперь следующий вопрос в вашей голове должен быть следующим: «Тогда почему используется пара Public / Private Key?» Да, он используется, но только для аутентификации. Когда клиент и сервер сталкиваются друг с другом, им необходимо проверить личность друг друга. Именно здесь играет роль асимметричного шифрования. Эта проверка выполняется с помощью пары Public / Private Key. После того, как аутентификация будет выполнена, и будет выполнено TLS handshake, начнется фактическое шифрование, и будет оно выполняться через Symmetric Encryption.
Когда клиент и сервер сталкиваются друг с другом, им необходимо проверить личность друг друга. Именно здесь играет роль асимметричного шифрования. Эта проверка выполняется с помощью пары Public / Private Key. После того, как аутентификация будет выполнена, и будет выполнено TLS handshake, начнется фактическое шифрование, и будет оно выполняться через Symmetric Encryption.
Что такое 256-битное шифрование?
Сначала термин «256-бит» звучит, как язык для «ботаников». Ну, это не так. 256-битное шифрование относится к длине ключа симметричной технологии шифрования. Это означает, что ключ сделан из 256 двоичных файлов (нулей и единиц), и имеется 2 256 возможных комбинаций.
Все еще не понятно? Хорошо, давайте разберем это с помощью простого примера. Допустим, есть 2-битный ключ. Следовательно, он будет иметь 2 2 (4) значения — 00, 01, 10 и 11. Таким образом, 256-битный ключ может иметь 2 256 возможных комбинаций. Ну что, так понятнее?)
Насколько безопасно 256-битное шифрование?
«Насколько безопасно 256-битное шифрование?» «Достаточно ли 256-битного шифрования?» Это два из наиболее часто задаваемых вопросов, когда дело доходит до уровня шифрования. Проясним раз и навсегда: этого более чем достаточно. Наша уверенность вполне обоснована и причина всему называется «Математика».
Проясним раз и навсегда: этого более чем достаточно. Наша уверенность вполне обоснована и причина всему называется «Математика».
Лучший способ взломать ключ шифрования, и это «грубая форсировка», пробная версия и ошибка в простых терминах. Таким образом, если длина ключа составляет 256 бит, было бы доступно по 2 256 возможных комбинаций, и хакер должен попробовать большинство из 2 255 возможных комбинаций, прежде чем прийти к заключению (как правило, для получения правильной комбинации требуется около 50% ключей).
На бумаге 2 256 может показаться обычным числом, но не смейте недооценивать математику.
256-бит будет иметь такой вид:
115,792,089,237,316,195,423,570,985,008,687,907,853,269,984,665,640,564,039, 457,540,007,913,129,639,936 (78 цифр) возможных комбинаций.
Никакой суперкомпьютер на нашей с вами любимой планете не сможет взломать его.
Даже если вы будете использовать Tianhe-2 (MilkyWay-2), самый быстрый суперкомпьютер в мире, понадобится миллионы лет, чтобы взломать 256-битное шифрование.
Ну что, теперь вы чувствуете себя безопаснее?)
Передача в папку
Первая страница > Сканирование > Приложение > Значения различных настроек функции передачи/сохранения > Функция передачи > Передача в папку
Значения пунктов для сканирования в папку
Параметр |
Максимальное значение |
Комментарии |
|---|---|---|
Количество символов в имени пути на SMB |
256 символов (256 байт) |
— |
Количество символов в имени пользователя на SMB |
64 символа (128 байт) |
— |
Количество символов в пароле на SMB |
64 символа (128 байт) |
— |
Количество символов в имени сервера на FTP |
64 символа |
— |
Количество символов в имени пути на FTP |
256 символов (256 байт) |
— |
Количество символов в имени пользователя на FTP |
64 алфавитно-цифровых символа |
— |
Количество символов в пароле на FTP |
64 алфавитно-цифровых символа |
— |
Количество символов в имени пути на NCP |
256 символов (256 байт) |
NDS: 32 буквенно-цифровых символа (32 байта) Переплет: 47 буквенно-цифровых символов (47 байт) |
Количество символов в имени пользователя на NCP |
64 символа (128 байт) |
— |
Количество символов в пароле на NCP |
64 буквенно-цифровых символов (64 байта) |
— |
Допустимое количество одновременно указываемых адресов |
50 адресов |
Можно задавать не более 50 непосредственно вводимых адресатов. |
Количество папок для размещения сохраненных файлов |
200 папок |
— |
Допустимый размер отправляемого файла |
2000 Mб на файл |
— |

Почему исторически люди используют 255 а не 256 для поля базы данных величины?
Вы часто видите поля базы данных значение имеет величина 255 символов, что является традиционным / историческая причина? Я предполагаю, что это’s что-то сделать с подкачки / ограничения по памяти и производительности, но различие между 255 и 256 всегда смущали меня.
Учитывая, что это емкость или величины, не индексатор, почему 255 предпочтительнее, чем 256? Байт зарезервировано для какой-то цели (Терминатор или null или что-то)?
Предположительно тип varchar(0) — это бред (имеет нулевой потенциал)? В этом случае 2^8 пространства должна быть 256, конечно?
Существуют другие величины, которые обеспечивают преимущества в производительности? Например, имеет тип varchar(512) медленее, чем тип varchar(511) или varchar(510)?
Это значение одинаково для всех баз данных отношений, старых и новых?
предупреждение — Я’м разработчик не администратор БД, я использую поле размеров и типов, которые подходят моей бизнес-логики, где это известно, но я’d, как знать исторический причина этого предпочтения, даже если это’s не утратили свою актуальность (а тем более, если это еще актуально).
Редактировать:
Спасибо за ответы, там, кажется, есть консенсус, что байт используется для хранения размер, но это не’т окончательно урегулировать этот вопрос в моей голове.
Если мета-данные (длину строки) хранится в одной непрерывной памяти/диска, это имеет некоторый смысл. 1 байт метаданных и 255 байт данных string, будет очень хорошо подходите друг другу, и укладывается в 256 смежных байта памяти, которые, предположительно, ухожен.
Но…если метаданные (длина строки) хранится отдельно от собственно строковые данные (в мастер-таблице возможно), то, чтобы ограничить длину строки’s данные по одному байту, просто потому что он’ы легче хранить только 1 байт целое число метаданных кажется немного странным.
В обоих случаях, казалось бы, тонкость в том, что, вероятно, зависит от реализации БД. Практика использования 255 кажется довольно распространена, так что кто-то где-то должно быть, доказывали хороший чехол для него в начале, может кто помнит, что дело было/есть? Программисты выиграли’т принять любые новые практики без причины, и это должно было когда-то новым.
Перевод %d0%b1%d0%b0%d0%b9%d1%82 на турецкий | Glosbe
Этот отчисленный ученик умер в 82 года, в здравом уме, будучи основателем и первым директором Еврейского университета в Иерусалиме и основателем издательства Шокен Букс. Это популярное издательство в дальнейшем было поглощено издательским домом Рандом Хаус.
Bu liseden terk 82 yaşında öldüğünde, müthiş bir entelektüel, Kudüs İbrani Üniversitesi’nin kurucu ortağı ve ilk genel müdürü ve Schocken Books’un, ki ileride Random House tarafından satın alınan alkışlanacak bir markanın kurucusuydu.
ted2019
82-летний мужчина, диабетик, похищен около своего маленького милого дома среди бела дня.
82 yaşında şeker hastası adam, günün ortasında güzel ve küçük evinin önünden kaçırılıyor.
OpenSubtitles2018.v3
▪ Ежедневно в ЮАР осуждаются 82 ребенка за «изнасилование или словесное оскорбление других детей».
▪ Tüm Güney Afrika’da günde 82 çocuk “başka çocuklara tecavüz etmek veya saldırmak” suçundan mahkemeye çıkıyor.
jw2019
82 7 Иметь детей — ответственность и награда
79 7 Çocuklar Bir Sorumluluk ve Bir Mükâfat
jw2019
Какое же счастливое освобождение настанет для людей, жаждущих мирного, справедливого правления! (Псалом 36:9–11; 82:18, 19).
Böylelikle, barışçı, adil bir hükümdarlığı özleyen insanlara, mutluluk dolu ne büyük bir ferahlık gelecektir!—Mezmur 37:9-11; 83:17, 18.
jw2019
Пройдите к выходу 82 через 40 минут.
Lütfen 40 dakika içerisinde 82 nolu peronda olun.
OpenSubtitles2018.v3
Относительно 82 процентов слов, приписываемых Иисусу в Евангелиях, они проголосовали черным шаром.
Aslında, onlar İncillerde İsa’ya atfedilen sözlerin yüzde 82’si için siyah oy kullandı.
jw2019
Что это, номер 82?
OpenSubtitles2018.v3
Это оправдает владычество Иеговы и освободит послушных Богу людей — а значит, и нас — от унаследованного греха (1 Паралипоменон 29:11; Псалом 82:19; Деяния 4:24; 1 Иоанна 3:8; Евреям 2:14, 15).
Yehova bunu yaparak egemenlik hakkını pekiştirecek ve miras alınan günahın itaatli insanlardan kaldırılmasını mümkün kılacak. (I.
jw2019
(Воспользуйся вопросником «Твой гардероб» на страницах 82 и 83.)
(Özdeyişler 15:22; 82 ve 83. sayfadaki “Gardırop Değerlendirmesi” çizelgesini kullan.)
jw2019
На данный момент, мы обменяли диктатора 82 лет на фельдмаршала 79 лет, называемого пуделем Мубарака.
Şu an sadece 82 yaşında yaşlı bir diktatör ile Mübarek’in köpeği denilen 79 yaşında bir mareşalin yerini değiştirdik.
OpenSubtitles2018. v3
v3
С 75 по 82 год просто пробел.
75’le 82 arası çok hayal meyal.
OpenSubtitles2018.v3
Механик на грузовом элеваторе совершенно не слышал мастера кричащего » 82 этаж! »
Nakliye asansörünün operatörü ustabaşının » 82nci kat! » diye bağırışını tam olarak duymamıştı.
OpenSubtitles2018.v3
Играл его в Стратфорде, в 82-ом.
82‘de Stratford’da onu oynamıştım.
OpenSubtitles2018.v3
Несколько лет назад оценивалось новое лекарство от рака лёгких, и когда авторы посмотрели, у кого опухоли уменьшились, они обнаружили, что 82% пациентов были женщины.
Birkaç yıl önce yeni bir akciğer kanseri ilacı değerlendiriliyordu ve araştırmacılar küçülen tümörlere baktıklarında %82 sinin kadınların olduğunu buldurlar.
ted2019
Моего отца убили на службе в 82-ом.
1982‘de babam görevdeyken öldürüldü.
OpenSubtitles2018.v3
Это первая кость — D1.
QED
Я имею в виду, 82, это невероятно.
OpenSubtitles2018.v3
Первый альбом группы Hear Nothing See Nothing Say Nothing (1982) поднялся до 2-го места UK Indie Charts и до 40-го места в общенациональных списках и считается классикой наследия движения UK 82.
Grubun 1982’de çıkan ilk albümü, Hear Nothing See Nothing Say Nothing, UK Indie Charts listesinde 2. sıraya ve UK Albums Chart listesinde 40. sıraya çıktı.
WikiMatrix
— Может быть, ты уже знаешь, что, по Библии, имя истинного Бога — Иегова (Псалом 82:19, ПАМ).
“Belki Mukaddes Kitaba göre gerçek Tanrı’nın isminin Yehova olduğunu biliyorsun.”—İşaya 42:8.
jw2019
Библия называет Иегову единственным истинным Богом (Псалом 82:19, ПП; Иоанна 17:3).
Mukaddes Kitap Yehova’yı tek gerçek Tanrı olarak tanıtır (İşaya 42:8; Yuhanna 17:3).
jw2019
Итак, вам нужно найти 82 голоса, из наиболее вероятной комбинации: Огайо,
Bu durumda, 82 delegeye daha ihtiyacınız var.
OpenSubtitles2018.v3
Если я не ошибаюсь он построен в’82, что значит, что в шахте водопровода должно быть достаточно места.
Yanlış bilmiyorsam, bu bina 82‘de yapıldı. Yani su tesisatı boşluğu. … çok geniş olmalı.
OpenSubtitles2018.v3
Сестрам, которые получают это задание, либо назначается условная ситуация, либо они сами выбирают ее из списка, приведенного в учебнике «Школа служения», с. 82.
Bu görevi alan her hemşire Vaizlik İbadeti kitabının 82. sayfasında verilen listedeki durumlardan birini kendi seçecek veya ona listedeki durumlardan biri tayin edilecek.
jw2019
Ведь вам уже 82 года.
Siz, 82 yaşındasınız.
OpenSubtitles2018.v3
Задача 9 — разбор задания ЕГЭ по предмету Информатика
Решение №1
Итак, давайте определим, что у нас имеется.
- Имеется изображение размером 64х64 пикселя (то есть, 64 — по горизонтали, 64 — по вертикали). Переведём оба числа в степень двойки, чтобы было легко перемножать: 64×64 = 26x26 = 212 пикселей. Итого: в картинке — 212 пикселей.
- Чтобы узнать, сколько информации будут занимать все эти пиксели, нам надо узнать, сколько «весит» один пиксель. В условии задачи это не дано напрямую.
- Но дано, что в изображении могут использоваться 256 различных цветов. То есть, цвет каждого пикселя может быть одним из 256. Сколько нужно бит, чтобы закодировать 256 различных вариантов?
Давайте вспоминать:
- 1 бит кодирует 2 возможные комбинации
- 2 бита — 4 комбинации
- 3 бита — 8 комбинаций
- 4 бита — 16 комбинаций
- 5 бит — 32 комбинации
- 6 бит — 64 комбинации
- 7 бит — 128 комбинаций
- 8 бит — 256 комбинаций
Итого: чтобы закодировать 256 различных цветов, нам потребуется 8 бит. Значит, один пиксель в данном изображении будет занимать 8 бит.
Значит, один пиксель в данном изображении будет занимать 8 бит.
Вспомним, сколько у нас всего пикселей? — 212. Если 1 пиксель занимает 8 бит, то 212 пикселей будут занимать 212x8 = 212x23 = 215 бит.
Нас просят дать ответ в Кбайтах. Значит, надо перевести из бит в Кбайты. Давайте вспомним соотношения между величинами:
- 1 байт = 8 бит = 23 бит
- 1 Кбайт = 1024 байта = 210 байт
- 1 Кбайт = 8×1024 бит = 23 x 210 = 213 бит
Значит, информационный объём («размер») данного изображения составляет 4 Кбайта.
А у нас сколько? 215 бит. Сколько это Кбайт? Надо поделить на то, сколько занимает 1 Кбайт бит: 215 / 213 = 22 = 4 Кбайт. Значит, информационный объём («размер») данного изображения составляет 4 Кбайта.
Понятия:
- Бит — минимальная единица измерения информации.
 Ровно такой объём несёт информация о выборе из двух вариантов. Например, информация о том, что выпало при броске монетки (орёл или решка), составляет как раз 1 бит.
Ровно такой объём несёт информация о выборе из двух вариантов. Например, информация о том, что выпало при броске монетки (орёл или решка), составляет как раз 1 бит. - Информационный объём изображения — сколько бит (или смежных величин: байт, Кбайт и пр.) занимает изображение.
- Цветовая палитра изображения — сколько цветов может быть у 1 пиксель данного изображения. Цветовая палитра чёрно-белого изображения составляет 2 цвета.
 Ровно такой объём несёт информация о выборе из двух вариантов. Например, информация о том, что выпало при броске монетки (орёл или решка), составляет как раз 1 бит.
Ровно такой объём несёт информация о выборе из двух вариантов. Например, информация о том, что выпало при броске монетки (орёл или решка), составляет как раз 1 бит.Код Обнаружения Ошибки Для 33 Байт, Обнаружение Бит, Перевернутого В Первые 32 Байта
Вы можете обнаружить один бит флип с одним дополнительным битом в любом сообщении длины (как указано @Daniel Wagner). Бит четности может, просто поставить, указать, является ли общее число 1-бит нечетным или четным. Очевидно, что если количество битов, которые являются неправильными, четное, тогда бит четности будет терпеть неудачу, поэтому вы не сможете обнаружить 2-битные ошибки. m — 1 всего вам нужно использовать биты
m — 1 всего вам нужно использовать биты m EC. Они представляют каждую возможную различную маску, следуя шаблону «x bits on, x bits off», где x — мощность 2. Таким образом, чем больше количество бит одновременно, тем лучше соотношение данных/четности. Например, 7 полных битов позволяли кодировать только 4 бита данных после потери 3 бит EC, но 31 общий бит может кодировать 26 битов данных после потери 5 бит EC.
Теперь, чтобы действительно понять это, вероятно, будет приведен пример. Рассмотрим следующие наборы масок. Первые две строки должны быть прочитаны сверху вниз, указывая номер бит («Самый значащий байт», который я обозначил MSB):
MSB LSB
| |
v v
33222222 22221111 11111100 0000000|0
10987654 32109876 54321098 7654321|0
-------- -------- -------- -------|-
1: 10101010 10101010 10101010 1010101|0
2: 11001100 11001100 11001100 1100110|0
3: 11110000 11110000 11110000 1111000|0
4: 11111111 00000000 11111111 0000000|0
5: 11111111 11111111 00000000 0000000|0
Первое, что нужно заметить, это то, что двоичные значения от 0 до 31 представлены в каждом столбце, идущем справа налево (чтение битов в строках с 1 по 5). Это означает, что каждый вертикальный столбец отличается друг от друга (важная часть). Я поместил вертикальную дополнительную строку между номерами бит 0 и 1 по определенной причине: Столбец 0 бесполезен, поскольку в нем нет битов.
Это означает, что каждый вертикальный столбец отличается друг от друга (важная часть). Я поместил вертикальную дополнительную строку между номерами бит 0 и 1 по определенной причине: Столбец 0 бесполезен, поскольку в нем нет битов.
Чтобы выполнить исправление ошибок, мы будем побитовыми — и принятые биты данных против каждой предопределенной маски бит ЕС, а затем сравним полученную четность с битом ЕС. Для любых вычисленных паритетов, обнаруженных не для соответствия, найдите столбец, в котором установлены только эти биты. Например, если биты ошибки 1, 4 и 5 ошибочны при вычислении из принятого значения данных, то столбец # 25, содержащий 1 с только в этих масках, должен быть неправильным битом и может быть исправлен путем его перевертывания, Если только один бит с исправлением ошибок ошибочен, тогда ошибка находится в этом бите с исправлением ошибок. Здесь аналогия поможет понять, почему это работает:
Есть 32 одинаковых коробки, одна из которых содержит мрамор.
 Ваша задача — найти мрамор, используя только старинную шкалу (вид с двумя сбалансированными платформами для сравнения весов разных объектов), и вам разрешено только 5 попыток взвешивания. Решение довольно просто: вы поместили по 16 ящиков с каждой стороны шкалы, а более тяжелая сторона указала, на какой стороне находится мрамор. Отбрасывая 16 коробок на более светлой стороне, вы затем взвешиваете 8 и 8 ящиков, удерживая тяжелее, затем 4 и 4, затем 2 и 2 и, наконец, находите мрамор, сравнивая веса последних 2 ящиков 1:1: самый тяжелый коробка содержит мрамор. Вы выполнили задачу только в 5 взвешиваниях 32, 16, 8, 4 и 2 ящиков.
Ваша задача — найти мрамор, используя только старинную шкалу (вид с двумя сбалансированными платформами для сравнения весов разных объектов), и вам разрешено только 5 попыток взвешивания. Решение довольно просто: вы поместили по 16 ящиков с каждой стороны шкалы, а более тяжелая сторона указала, на какой стороне находится мрамор. Отбрасывая 16 коробок на более светлой стороне, вы затем взвешиваете 8 и 8 ящиков, удерживая тяжелее, затем 4 и 4, затем 2 и 2 и, наконец, находите мрамор, сравнивая веса последних 2 ящиков 1:1: самый тяжелый коробка содержит мрамор. Вы выполнили задачу только в 5 взвешиваниях 32, 16, 8, 4 и 2 ящиков. Аналогично, наши битовые шаблоны разделили ящики в 5 разных группах. Возвращаясь назад, пятый бит EC определяет, находится ли ошибка с левой или правой стороны. В нашем сценарии с битом # 25 это неверно, поэтому мы знаем, что бит ошибки находится в левой части группы (бит 16-31). В нашей следующей маске для EC бит №4 (по-прежнему отступаем назад) мы рассматриваем только биты 16-31, и мы обнаруживаем, что «более тяжелая» сторона снова левая, поэтому мы сузили биты 24-31. Следуя дереву решений вниз и сокращая количество возможных столбцов пополам каждый раз, к тому времени, когда мы достигнем бита EC 1, осталось только 1 бит — наш «мрамор в коробке».
Следуя дереву решений вниз и сокращая количество возможных столбцов пополам каждый раз, к тому времени, когда мы достигнем бита EC 1, осталось только 1 бит — наш «мрамор в коробке».
Примечание. Аналогия полезна, хотя и не идеальна: 1-биты не представлены мраморами — расположение битов ошибки представлено мрамором.
Теперь некоторые, играющие с этими масками и думающие о том, как устроить вещи, покажут, что есть проблема: если мы попытаемся сделать все 31 бит данных бит, тогда нам понадобится еще 5 бит для EC. Но как же тогда мы скажем, ошибочны ли сами бит EC? Только один неверный бит ЕС неверно скажет нам, что некоторый бит данных нуждается в исправлении, и мы ошибочно перевернем этот бит данных. Биты EC должны как-то кодировать для себя! Решение состоит в том, чтобы расположить биты четности внутри данных, в столбцах из битовых шаблонов выше, где установлен только один бит. Таким образом, любой бит данных будет неправильным, приведет к ошибочному действию двух битов EC, делая это так, что если только один бит EC ошибочен, мы знаем, что он сам ошибочен, а не означает, что бит данных неверен. Столбцы, удовлетворяющие однобитовому условию, равны 1, 2, 4, 8 и 16. Биты данных будут чередоваться между ними, начиная с позиции 2. (Помните, мы не используем позицию 0, поскольку она никогда не предоставит никакой информации — ни один из наших бит EC не будет установлен вообще).
Столбцы, удовлетворяющие однобитовому условию, равны 1, 2, 4, 8 и 16. Биты данных будут чередоваться между ними, начиная с позиции 2. (Помните, мы не используем позицию 0, поскольку она никогда не предоставит никакой информации — ни один из наших бит EC не будет установлен вообще).
Наконец, добавление еще одного бита для общей четности позволит обнаруживать 2-битные ошибки и надежно исправлять 1-битные ошибки, так как мы можем сравнить бит EC с ним: если бит EC говорит что-то не так, но бит четности говорит иначе, мы знаем, что есть 2 бита неправильно и не могут выполнить коррекцию. Мы можем использовать отброшенный бит # 0 как наш бит четности! Фактически, теперь мы кодируем следующий шаблон:
0: 11111111 11111111 11111111 11111111
Это дает окончательную сумму из 6 бит проверки ошибок и исправления (ECC). Расширение схемы использования разных масок неограниченно выглядит следующим образом:
32 bits - 6 ECC bits = 26 data
64 bits - 7 ECC bits = 57 data
128 bits - 8 ECC bits = 120 data
256 bits - 9 ECC bits = 247 data
512 bits - 10 ECC bits = 502 data
Теперь, если мы уверены, что получим только 1-битную ошибку, мы можем отказаться от бит четности # 0, поэтому мы имеем следующее:
31 bits - 5 ECC bits = 26 data
63 bits - 6 ECC bits = 57 data
127 bits - 7 ECC bits = 120 data
255 bits - 8 ECC bits = 247 data
511 bits - 9 ECC bits = 502 data
Это не изменится, потому что мы больше не получаем бит данных. К сожалению! 32 байта (256 бит) по вашему запросу не могут быть исправлены с ошибкой одним байтом, даже если мы знаем, что в худшем случае мы можем иметь только 1-битную ошибку, и мы знаем, что бит ECC будет правильным (что позволяет нам перемещать их из области данных и использовать их все для данных). Нам нужно еще два бита, чем у нас — нужно перейти на следующий диапазон из 512 бит, а затем оставить 246 бит данных, чтобы получить наши 256 бит данных. Так что еще один бит ECC И еще один бит данных (поскольку у нас только 255, именно то, что сказал вам Daniel).
Резюме :: Вам нужно 33 байта + 1 бит, чтобы определить, какой бит перевернулся в первые 32 байта.
Примечание: если вы собираетесь отправлять 64 байта, то вы находитесь под соотношением 32: 1, так как вы можете исправить ошибку всего за 10 бит. Но это то, что в реальных приложениях «размер кадра» вашего ECC не может продолжать расти неограниченно по нескольким причинам: 1) Количество бит, обрабатываемых одновременно, может быть намного меньше размера кадра, что приводит к валовой неэффективности (подумайте ОЗУ ECC). 2) Шанс быть способным точно корректировать бит становится все меньше и меньше, так как чем больше размер кадра, тем больше вероятность, что он будет иметь больше ошибок, а 2 ошибки будут проигрывать возможность исправления ошибок, а 3 или более могут победить даже ошибку способность обнаружения. 3) Как только обнаружена ошибка, чем больше размер кадра, тем больше размер поврежденной части, которую необходимо повторно передать.
История 256
История 256Почему 256? Почему это число так важно?
Ох! Вы имеете в виду, что не знаете всех деталей об этом устройстве, на которое смотрите вслепую в? Я имею в виду, вы сейчас смотрите на монитор компьютер . Думаю, мне не стоит удивляться. я Я ботаник, живу и дышу компьютерами с 10-го класса в 1981 году. Мне это тяжело. чтобы увидеть, что я считаю само собой разумеющимся. Итак, в интересах образования и для удовлетворения моей потребности болтать, я представляю следующее мини-эссе о достоинствах 256.Да будет жить вечно …
Волшебство # 2
2 — очень магическое число для большинства компьютерных фанатов. Все сигналы внутри компьютера имеют два (и только два) разные, следовательно, двоичные значения: 0 и 1. Их можно рассматривать как выключенные (0) и включенные (1) или ложные (0) и правда (1). В компьютерной терминологии один фрагмент информации, который может хранить либо 0, либо 1, называется немного.
Итак, бит представляет значения от 0 до 1 (2 значения). Соедините 2 бита вместе и представьте 0, 1, 2 или 3 (4 ценности).X) могут быть представлены разные значения.
Числа с основанием 2 так же важны для компьютерных фанатов, как я, как числа с основанием 10 для других людей. Так же, как вы знаете 10, 100, 1000 и т. Д., Я знаю 2, 4, 8, 16, 32, 64, 128, 256, 512, 1024, 2048, 4096, 8192, 16384, и т.д .. Да, мы странная группа.
И был свет
Теперь, когда мы знаем о двоичных значениях в компьютере, давайте поговорим об устройствах, которые их используют. ценности. В основе всех двоичных компьютеров лежит логический элемент И.Это маленький электронный переключатель (или клапан если хотите) состоит из двух входов и одного выхода и обычно реализуется с помощью транзистора. Согласно определению, если и только если оба входа логического элемента И включены, то на выходе будет «на». В противном случае, если один из входов «выключен» или если оба входа «выключены», то выход будет «выключенный».
При достаточном количестве этого маленького переключателя в сочетании с его друзьями логическими элементами OR, NOT, XOR, NAND и т. Д., вы можете создать себе компьютер.Это, конечно, не так просто, но дело в том, что логический элемент AND, базовый строительный блок компьютера, принимает 2 входа, чтобы получить выход. 2 — очень важное число для двоичной компьютер.
Бит сейчас байт?
В какой-то момент первые разработчики двоичного компьютера придумали байт в качестве следующей стандартной единицы измерения. немного выше. Байт определяется как 8-битный и может представлять значения от 0 до 255 или 2 в степени 8. разные значения. Байт представляет 256 различных значений.
Байт == 256
Вот и все. Байт — это единица хранения в компьютере, которая содержит 8 бит и может хранить 256 различных значения: от 0 до 255. Буквы обычно хранятся, например, в байтах. У вас есть компьютер с гигабайтами (1 миллиард байт) дискового пространства и мегабайты (1 миллион байт) памяти — ну, может это будущее, и вы имеют гигабайты памяти и терабайты (1 триллион байт) дискового пространства. В любом случае 256 особенное, так как он представляет собой наиболее распространенный базовый блок в компьютере.
Copyright 2002 Gray Watson.
Этот сайт в основном содержит валидный XHTML W3C и должен работать с большинством браузеров.
Ваш хост:
58.mtsnet.ru
85.140.1.58:36924
Агент: Mozilla / 5.0 (X11; Linux x86_64; rv: 33.0) Gecko / 20100101 Firefox / 33.0
наборов символов
наборов символов| Жан ЛеЛуп и Боб Понтерио СУНИ Кортланд © 2003, 2017 |
- Отправной точкой для наборов символов, которые мы находим на большинстве компьютеров, было ASCII .
(Американский стандартный код для обмена информацией).ASCII — это 7-битный
код — один бит (двоичная цифра) — это единственный переключатель, который может быть включен
или выкл, ноль или один. Наборы символов, используемые сегодня в США, обычно
8-битные наборы с 256 различными символами, что фактически удваивает набор ASCII.
Один бит может иметь 2 возможных состояния. 2 1 = 2. 0 или
1.
Два бита могут иметь 4 возможных состояния. 2 2 = 4. 00,01,10,11.
(т.е. 0-3)
Четыре бита могут иметь 16 возможных состояний.2 4 = 16.
0000,0001,0010,0011 и т. Д. (Т.е. 0-15)
Семь битов могут иметь 128 возможных состояний. 2 7 = 128.
0000000,0000001,0000010 и т. Д. (Т.е. 0-127).
Восемь битов могут иметь 256 возможных состояний. 2 8 = 256.
00000000,00000001,00000010 и т. Д. (Т.е. 0-255).
Восемь битов называются байтом . Наборы однобайтовых символов могут содержат 256 символов. Однако текущий стандарт — Unicode, который использует два байта для представления всех символов во всех системах письма в мире в едином наборе.
Исходный код ASCII представлял собой 7-битный набор символов (128 возможных символов) без акцентированные буквы. Это использовалось в телетайпах. (Восьмой бит изначально использовался для проверки четности — способа поиска ошибок.) IBM и Mac создали расширенные наборы символов для своих персональных компьютеров, используя восьмой бит для удвоить количество символов. Как конкуренты, они не использовали то же самое персонажи в одинаковых позициях в своих наборах. Таким образом родились 8-битные наборы символов и несовместимость.Например, старый Microsoft DOS / Windows использовал символ 130 для é , но старые Mac использовали символ 142. Символ 130 на Mac был Ç . Сегодняшние стандарты уменьшили количество таких проблем.
В Интернете многие кабели имели провода, предназначенные для передачи 7-битных кодов. Для отправки более сложных данных были разработаны схемы кодирования для преобразовать более сложные данные (например, 8-битные, двоичные [графики]) во что-то это могло пройти через 7-битный конвейер.Одна такая схема кодирования MIME (на самом деле много разных схем являются частью MIME — Многоцелевой Расширения электронной почты Интернета). Чтобы MIME работал, нужны два элемента: должны быть определены формат содержимого или набор символов (, какие символы или другой контент должны быть представлены ) и схема кодирования (, какие коды будут использоваться для представления этих символов ) для содержания.
Общий код, используемый для символов с диакритическими знаками — Quoted-Printable . Любые расширенные символы ( выше 127 ) кодируются с использованием строки из трех символов. Например, é — это = E9 . 8BIT (по существу несжатый символьные данные) также является действительным кодом MIME и является наиболее распространенным способом отправки символов с акцентами сегодня.
Чтобы код мог работать на двух разных типах машин с разными операционными системами и разными встроенными наборы символов, мы все должны согласовать стандартные наборы символов, в которые мы переведем.Международная организация по стандартизации (ISO) установил такие стандарты. Например, стандартный набор символов для Western Европейские языки — ISO-LATIN-I (или ISO-8859-1 ). Но пока компьютер знает, какой набор символов используется, он может быть запрограммирован на перевод и отображение этих символов, независимо от того, каким может быть собственный набор символов компьютера. é — это символ 130 в ISO-LATIN-I.
Программа электронной почты, совместимая с MIME, будет использовать заголовки электронной почты для отслеживания какой набор символов и какая схема кодировки применяются к каждому электронному письму сообщение.Веб-браузер сделает то же самое. Это позволяет программе преобразовывать и знать, как отображать символы на любой машине, поэтому вся система кодирования прозрачна (пользователь не замечает) для пользователя. Для MIME Quoted-Printable на западноевропейских языках, эти заголовки могут выглядит так:
- X-Mailer: QUALCOMM Windows Eudora версии 5.1
Mime-версия: 1.0
Content-type: text / plain; кодировка = iso-8859-1
Content-Transfer-Encoding: цитируется-печатается
И эти же заголовки MIME также используются на веб-страницах, так что веб-браузер, такой как Internet Explorer, Chrome или Firefox, знает, как отображать каждую страницу, независимо от того, где она была создана и где она просматривается.Пока компьютер знает, какой набор символов представлен, он знает, какой символ отображать.
Клавиатуры
Вы также должны в первую очередь ввести персонажей в компьютер. Windows и Mac уже давно позволяют делать это с помощью сочетаний клавиш. Лучший способ ввода символов в Windows — это выбрать раскладку клавиатуры, включающую символы, которые вы хотите ввести. Для набора текста на западноевропейских языках на американской клавиатуре самый безопасный и простой в использовании вариант, если вы уже умеете печатать на американской клавиатуре, — это международная американская клавиатура.В Windows 7, 8, 10 найдите вкладку «Клавиатуры и языки» на панели управления «Регион и язык» , чтобы изменить или добавить клавиатуру. Хотя многие программы могут иметь встроенные сочетания клавиш, преимущество использования клавиатуры в операционной системе (Windows, Mac) заключается в том, что она будет работать для всех программ.
Для получения интерактивной справки по клавиатурам см .:
Справка по клавиатуре
Неанглийские клавиатуры Windows 7; Общие для Windows и Mac; Windows 10
Учебное пособие по проблемам с символьным кодом
Подстановочные таблицы набора символов (включая коды HTML для веб-страниц)
Возврат к программе
преобразовать 256 байтов в биты
Насколько велик 256 байт? Что такое 256 байт в битах? Преобразование 256 байтов в биты.
Из БитыБайтыГигабайтыКилобайтыМегабитыМегабайтыПетабайтыТерабайты
К БитыБайтыГигабайтыКилобайтыМегабитыМегабайтыПетабайтыТерабайты
обменные единицы ↺
256 Байт =2048 бит
(точный результат)
Отобразить результат как NumberFraction (точное значение)
Байт равен 8 битам.Он может хранить до 2 8 (256) различных значений или один символ текста ASCII. Бит — основная единица информации. Он может иметь только два возможных значения: 0 или 1.Преобразование байтов в биты
(некоторые результаты округлены)
| байт | бит |
|---|---|
| 256.00 | 2048 |
| 256,01 | 2048,1 |
| 256,02 | 2048,2 |
| 256,03 | 2048,2 |
| 256,04 | 2048,3 |
| 256,05 | 2048,4 |
| 256,06 | 2048,5 |
| 256,07 | 2048,6 |
| 256,08 | 2048,6 |
| 256.09 | 2048,7 |
| 256,10 | 2048,8 |
| 256,11 | 2048,9 |
| 256,12 | 2049,0 |
| 256,13 | 2049,0 |
| 256,14 | 2049,1 |
| 256,15 | 2049,2 |
| 256,16 | 2049,3 |
| 256,17 | 2049,4 |
| 256.18 | 2049,4 |
| 256,19 | 2049,5 |
| 256,20 | 2049,6 |
| 256,21 | 2049,7 |
| 256,22 | 2049,8 |
| 256,23 | 2049,8 |
| 256,24 | 2049,9 |
| байт | бит |
|---|---|
| 256.25 | 2050 |
| 256,26 | 2050,1 |
| 256,27 | 2050,2 |
| 256,28 | 2050,2 |
| 256,29 | 2050,3 |
| 256,30 | 2050,4 |
| 256,31 | 2050,5 |
| 256,32 | 2050,6 |
| 256,33 | 2050,6 |
| 256.34 | 2050,7 |
| 256,35 | 2050,8 |
| 256,36 | 2050,9 |
| 256,37 | 2051,0 |
| 256,38 | 2051,0 |
| 256,39 | 2051,1 |
| 256,40 | 2051,2 |
| 256,41 | 2051,3 |
| 256,42 | 2051,4 |
| 256.43 | 2051,4 |
| 256,44 | 2051,5 |
| 256,45 | 2051,6 |
| 256,46 | 2051,7 |
| 256,47 | 2051,8 |
| 256,48 | 2051,8 |
| 256,49 | 2051,9 |
| байт | бит |
|---|---|
| 256.50 | 2052 |
| 256,51 | 2052,1 |
| 256,52 | 2052,2 |
| 256,53 | 2052,2 |
| 256,54 | 2052,3 |
| 256,55 | 2052,4 |
| 256,56 | 2052,5 |
| 256,57 | 2052,6 |
| 256,58 | 2052,6 |
| 256.59 | 2052,7 |
| 256,60 | 2052,8 |
| 256,61 | 2052,9 |
| 256,62 | 2053,0 |
| 256,63 | 2053,0 |
| 256,64 | 2053,1 |
| 256,65 | 2053,2 |
| 256,66 | 2053,3 |
| 256,67 | 2053,4 |
| 256.68 | 2053,4 |
| 256,69 | 2053,5 |
| 256,70 | 2053,6 |
| 256,71 | 2053,7 |
| 256,72 | 2053,8 |
| 256,73 | 2053,8 |
| 256,74 | 2053,9 |
| байт | бит |
|---|---|
| 256.75 | 2,054 |
| 256,76 | 2054,1 |
| 256,77 | 2054,2 |
| 256,78 | 2054,2 |
| 256,79 | 2054,3 |
| 256,80 | 2054,4 |
| 256,81 | 2054,5 |
| 256,82 | 2054,6 |
| 256,83 | 2054,6 |
| 256.84 | 2054,7 |
| 256,85 | 2054,8 |
| 256,86 | 2054,9 |
| 256,87 | 2055,0 |
| 256,88 | 2055,0 |
| 256,89 | 2055,1 |
| 256,90 | 2055,2 |
| 256,91 | 2055,3 |
| 256,92 | 2055,4 |
| 256.93 | 2055,4 |
| 256,94 | 2055,5 |
| 256,95 | 2055,6 |
| 256,96 | 2055,7 |
| 256,97 | 2055,8 |
| 256,98 | 2055,8 |
| 256,99 | 2055,9 |
Введение
Практически каждый, кто пользуется компьютером, слышал термины килобайт (кБ), мегабайт (МБ), гигабайт (ГБ) и даже терабайт (ТБ), обычно имея в виду размер компьютерных файлов и жестких дисков, а также скорость загрузки. .Пропускная способность или скорость соединения измеряются в битах в секунду. Но что такое бит и что такое байт и какое отношение они имеют к компьютерам?
Представьте простой комнатный светильник. Свет либо горит, либо выключен. Вы управляете текущим состоянием света, щелкая переключателем, который имеет только два положения: вниз (свет выключен) и вверх (свет включен). Самые ранние компьютеры использовали серию механических переключателей для управления потоком электричества через свои цепи, включая и выключая каждый из них. Состояния включения / выключения схем использовались для представления и даже хранения информации.Наименьшая единица информации, представляющая состояние одного переключателя, называется битом.
Бит — это двоичная цифра, имеющая только два возможных значения: ноль или единицу. Значение бита представляет текущее состояние отдельного переключателя. Если переключатель выключен, бит имеет нулевое значение. Если переключатель включен, то бит имеет значение один.
Бит может представлять только два разных значения, ноль или единицу. Для представления больших объемов информации биты объединяются в последовательности по 8, называемые байтами.
Байт — это последовательность двоичных цифр, состоящая из 8 бит.
Байт может представлять любое значение от 00000000 до 11111111, всего 256 различных возможных значений. Каждую цифру в байте можно представить как отдельный переключатель, который либо выключен (ноль), либо включен (один).
В современных компьютерах используются транзисторы, которые объединяют миллионы крошечных переключателей в микросхему размером меньше вашего большого пальца, но информация по-прежнему представляется в основном таким же образом: в виде последовательности единиц и нулей.40 байт
Примечания
- Единицы и нули битов и байтов могут использоваться для представления букв, цифр и даже различных клавиш на клавиатуре компьютера.
- Бит может использоваться для хранения логического (истина / ложь) значения. Нулевое значение представляет «ложь», а значение единицы — «истину».
Общие сведения о порядке байтов с прямым и обратным порядком байтов — лучше объяснение
Проблемы с порядком байтов меня раздражают, и я хочу избавить вас от горя, которое я испытал.Вот ключ:
- Проблема: Компьютеры говорят на разных языках, как и люди. Некоторые записывают данные «слева направо», а другие — «справа налево».
- Машина может нормально читать свои собственные данные — проблемы возникают, когда один компьютер хранит данные, а другой тип пытается их прочитать.
- Решения
- Согласитесь на общий формат (т.е. весь сетевой трафик следует в одном формате) или
- Всегда включайте заголовок, описывающий формат данных.Если заголовок отображается в обратном направлении, это означает, что данные были сохранены в другом формате и должны быть преобразованы.
Числа и данные
Самая важная концепция — распознавать разницу между числом и данными, которые его представляют.
Число — это абстрактное понятие, такое как подсчет чего-либо. У тебя десять пальцев. Идея «десять» не меняется, независимо от того, какое представление вы используете: десять, 10, diez (испанский), ju (японский), 1010 (двоичный), X (римская цифра)… все эти представления указывают на одно и то же понятие «десять».
Сравните это с данными. Данные — это физическая концепция, необработанная последовательность битов и байтов, хранящаяся на компьютере. Данные не имеют внутреннего значения и должны быть интерпретированы тем, кто их читает.
Данные похожи на человеческое письмо, которое представляет собой просто отметки на бумаге. В этих знаках нет внутреннего смысла. Если мы видим линию и круг (например, | O), мы можем интерпретировать это как «десять».
Но мы предположили, что знаки относятся к числу.Это могли быть буквы «IO», спутник Юпитера. Или, возможно, греческая богиня. Или, может быть, сокращение для ввода / вывода. Или чьи-то инициалы. Или цифру 2 в двоичном формате («10»). Список возможностей продолжается.
Дело в том, что отдельный фрагмент данных (| O) можно интерпретировать по-разному, и значение неясно, пока кто-то не прояснит намерения автора.
Компьютеры сталкиваются с той же проблемой. Они хранят данные, а не абстрактные концепции, и делают это с помощью последовательности нулей и единиц.Позже они считывают единицы и нули и пытаются воссоздать абстрактную концепцию из необработанных данных. В зависимости от сделанных предположений, 1 и 0 могут означать очень разные вещи.
Почему возникает эта проблема? Что ж, нет правила, согласно которому все компьютеры должны использовать один и тот же язык, точно так же, как нет правила, которое нужно всем людям. Каждый тип компьютера внутренне согласован (он может считывать свои собственные данные), но нет никаких гарантий относительно того, как другой компьютер типа будет интерпретировать созданные им данные.
Основные концепции
- Данные (биты и байты или пометки на бумаге) не имеют смысла; его нужно интерпретировать, чтобы создать абстрактное понятие, например число.
- Как и люди, компьютеры по-разному хранят одно и то же абстрактное понятие. (т.е. у нас есть много способов сказать «десять»: десять, 10, diez и т. д.)
Сохранение чисел как данных
К счастью, большинство компьютеров согласны с несколькими основными форматами данных (так было не всегда). Это дает нам общую отправную точку, которая немного облегчает нашу жизнь:
- Бит имеет два значения (вкл. Или выкл., 1 или 0)
- Байт — это последовательность из 8 бит
- Самый левый бит в байте — самый большой.Итак, двоичная последовательность 00001001 — это десятичное число 9. 00001001 = (2 3 + 2 0 = 8 + 1 = 9).
- Биты нумеруются справа налево. Бит 0 — самый правый и самый маленький; бит 7 — самый левый и самый большой.
Мы можем использовать эти базовые соглашения как строительный блок для обмена данными. Если мы сохраняем и читаем данные по одному байту, они будут работать на любом компьютере. Концепция байта одинакова на всех машинах, и представление о том, какой байт является первым, вторым, третьим (Байт 0, Байт 1, Байт 2…) одинакова на всех машинах.
Если компьютеры согласовывают порядок каждого байта, в чем проблема?
Ну, это нормально для однобайтовых данных, таких как текст ASCII. Однако необходимо хранить много данных, используя несколько байтов, например целые числа или числа с плавающей запятой. И нет соглашения о том, как эти последовательности должны храниться.
Байт Пример
Рассмотрим последовательность из 4 байтов, названную W X Y и Z — я избегал называть их A B C D, потому что это шестнадцатеричные цифры, что могло бы сбить с толку.Итак, каждый байт имеет значение и состоит из 8 бит.
Имя байта: W X Y Z Расположение: 0 1 2 3 Значение (шестнадцатеричное): 0x12 0x34 0x56 0x78
Например, W — это целый байт, 0x12 в шестнадцатеричном формате или 00010010 в двоичном формате. Если бы W интерпретировалось как число, это было бы «18» в десятичной системе (кстати, ничто не говорит о том, что мы должны интерпретировать его как число — это может быть символ ASCII или что-то совсем другое).
Со мной так далеко? У нас есть 4 байта, W X Y и Z, каждый со своим значением.
Общие сведения об указателях
Указатели являются ключевой частью программирования, особенно языка программирования C. Указатель — это число, которое ссылается на ячейку памяти. Мы (программист) должны интерпретировать данные в этом месте.
В C, когда вы приводите указатель к определенному типу (например, char * или int *), он сообщает компьютеру, как интерпретировать данные в этом месте. Например, объявим
void * p = 0; // p - указатель на неизвестный тип данных
// p - нулевой указатель - не разыменовывать
char * c; // c - указатель на символ, обычно однобайтный
Обратите внимание, что мы не можем получить данные из p, потому что мы не знаем его типа.p может указывать на одно число, букву, начало строки, ваш гороскоп, изображение — мы просто не знаем, сколько байтов нужно прочитать или как интерпретировать то, что там есть.
Теперь предположим, что мы пишем
c = (char *) p;
Ah — теперь этот оператор указывает компьютеру указывать на то же место, что и p, и интерпретировать данные как один символ ( char обычно является одним байтом, используйте uint8_t , если на вашем компьютере это не так). В этом случае c будет указывать на ячейку памяти 0 или байт W.Если бы мы напечатали c, мы получили бы значение в W, которое является шестнадцатеричным 0x12 (помните, что W — это целый байт).
Этот пример не зависит от типа компьютера — опять же, все компьютеры согласны с тем, что такое один байт (в прошлом это было не так).
Пример полезен, хотя он одинаков на всех компьютерах — если у нас есть указатель на один байт (char *, один байт), мы можем пройтись по памяти, считывая по байту за раз. Мы можем исследовать любую ячейку памяти, и порядок байтов компьютера не будет иметь значения — каждый компьютер будет возвращать одну и ту же информацию.
Итак, в чем проблема?
Проблемы возникают, когда компьютеры пытаются прочитать несколько байтов. Некоторые типы данных содержат несколько байтов, например длинные целые числа или числа с плавающей запятой. Один байт имеет всего 256 значений, поэтому может хранить от 0 до 255.
Теперь начинаются проблемы — когда вы читаете многобайтовые данные, где появляется самый большой байт?
- Машина с прямым порядком байтов: хранит данные , сначала большое число . При просмотре нескольких байтов первый байт (младший адрес) является самым большим.
- Машина с прямым порядком байтов: хранит данные Сначала с прямым порядком байтов . При просмотре нескольких байтов первый байт — это наименьший .
Именование имеет смысл, а? Big-endian считает, что на первом месте находится big-end. (Между прочим, именование с прямым порядком и прямым порядком байтов происходит от «Путешествий Гулливера», где лилипутанцы спорят о том, разбивать ли яйца на малом или на большом конце. Иногда компьютерные дебаты столь же значимы :-))
Опять же, порядок байтов не имеет значения, если у вас один байт.Если у вас есть один байт, это единственные данные, которые вы читаете, поэтому есть только один способ интерпретировать их (опять же, потому что компьютеры согласны с тем, что такое байт).
Теперь предположим, что наши 4 байта (W X Y Z) сохранены одинаково на машине с прямым и обратным порядком байтов. То есть ячейка памяти 0 — это W на обеих машинах, ячейка памяти 1 — это X и т. Д.
Мы можем создать такое расположение, помня, что байты не зависят от машины. Мы можем обходить память, по одному байту за раз, и устанавливать нужные нам значения. Это будет работать на любой машине:
c = 0; // указываем на точку 0 (на реальной машине работать не будет!) * c = 0x12; // Устанавливаем значение W c = 1; // указываем на позицию 1 * c = 0x34; // Устанавливаем значение X ... // повторяем для Y и Z; детали оставлены читателю
Этот код будет работать на любой машине, и мы оба установили байты W, X, Y и Z в местоположениях 0, 1, 2 и 3.
Интерпретация данных
Теперь давайте сделаем пример с многобайтовыми данными (наконец!). Быстрый обзор: «короткое целое» — это 2-байтовое (16-битное) число, которое может находиться в диапазоне от 0 до 65535 (без знака). Воспользуемся этим в примере:
шорт * с; // указатель на короткое int (2 байта) s = 0; // указываем на точку 0; * s - значение
Итак, s является указателем на короткое замыкание и теперь смотрит на позицию байта 0 (у которой есть W).8), потому что мне нужно было сдвинуть его более чем на 8 бит.
Машина с обратным порядком байтов: я не знаю, что курит мистер Биг Эндиан. Да, я согласен, что короткий — 2 байта, и я зачитаю их так же, как он: местоположение s равно 0x12, а местоположение s + 1 — 0x34. Но в моем мире первый байт — самый маленький! Значение короткого байта — 0 + 256 * байт 1, или 256 * X + W, или 0x3412.
Имейте в виду, что обе машины начинают с местоположения s и читают память, двигаясь вверх. Нет никакой путаницы в том, что означают местоположение 0 и местоположение 1.Нет сомнений в том, что короткий составляет 2 байта.
Но вы видите проблему? Машина с прямым порядком байтов думает, что s = 0x1234, а машина с прямым порядком байтов думает, что s = 0x3412. Одни и те же точные данные дают два разных числа. Наверное, не очень хорошо.
Еще один пример
Давайте для развлечения рассмотрим другой пример с 4-байтовым целым числом:
int * i; // указатель на int (4 байта на 32-битной машине) я = 0; // указывает на нулевое местоположение, поэтому * i - это значение там
Мы снова спрашиваем: какое значение у i?
- Машина с прямым порядком байтов: int составляет 4 байта, и первый является самым большим.Я прочитал 4 байта (W X Y Z), и W — самый большой. Номер 0x12345678.
- Машина с прямым порядком байтов: Конечно, целое число составляет 4 байта, но первый — самый маленький. Я тоже читаю W X Y Z, но W принадлежит второстепенным — это самое маленькое. Номер 0x78563412.
Те же данные, разные результаты — нехорошо. Вот интерактивный пример с использованием приведенных выше чисел, не стесняйтесь подключать свой собственный:
Проблема NUXI
Проблемы с порядком байтов иногда называют проблемой NUXI: UNIX, хранящийся на машине с прямым порядком байтов, может отображаться как NUXI на машине с прямым порядком байтов.
Предположим, мы хотим сохранить 4 байта (U, N, I и X) в виде двух шорт: UN и IX. Каждая буква представляет собой целый байт, как в нашем примере с WXYZ выше. Для хранения двух шорт напишем:
шорт * с; // указатель на установку шорт s = 0; // указываем на точку 0 * s = UN; // сохраняем первую короткую: U * 256 + N (вымышленный код) s = 2; // указать на следующее место * s = IX; // сохраняем вторую короткую: I * 256 + X
Этот код не относится к машине. Если мы сохраняем «ООН» на машине и просим перечитать ее, то лучше будет «UN»! Меня не волнуют проблемы с порядком байтов, если мы сохраняем значение на одной машине и читаем его на той же машине, это должно быть то же самое значение.
Однако, если мы посмотрим на память по одному байту (используя наш трюк с char *), порядок может измениться. На машине с прямым порядком байтов мы видим:
Байт: U N I X Расположение: 0 1 2 3
Что имеет смысл. U — это самый большой байт в «UN» и сохраняется первым. То же самое и с IX: I — самый большой и хранится первым.
На машине с прямым порядком байтов мы увидим:
Байт: N U X I Расположение: 0 1 2 3
И это тоже имеет смысл. «N» — это самый младший байт в «UN» и сохраняется первым.Опять же, даже несмотря на то, что байты хранятся в памяти «в обратном порядке», машина с прямым порядком байтов знает , что это обратный порядок байтов, и правильно интерпретирует их при обратном чтении значений. Также обратите внимание, что мы можем указывать шестнадцатеричные числа, такие как x = 0x1234, на любой машине. Даже машина с прямым порядком байтов знает, что вы имеете в виду, когда пишете 0x1234, и не будет заставлять вас менять значения самостоятельно (вы указываете шестнадцатеричное число для записи, и он выясняет детали и меняет местами байты в памяти под крышки.Сложный.).
Этот сценарий называется проблемой «NUXI», потому что последовательность байтов UNIX интерпретируется как NUXI на другом типе машины. Опять же, это проблема, только если вы обмениваетесь данными — каждая машина внутренне непротиворечива.
Обмен данными между конечными машинами
Компьютеры подключены — прошли те времена, когда машинам приходилось беспокоиться только о чтении собственных данных. Машины с прямым и обратным порядком байтов должны взаимодействовать друг с другом. Как они это делают?
Решение 1. Используйте общий формат
Самый простой способ — согласовать общий формат для отправки данных по сети.Стандартный сетевой порядок на самом деле является прямым порядком байтов, но некоторые люди считают, что прямой порядок байтов не победил … мы просто назовем это «сетевым порядком».
Для преобразования данных в сетевой порядок машины вызывают функцию hton (host-to-network). На машине с прямым порядком байтов это на самом деле ничего не даст, но мы не будем об этом здесь говорить (обратный порядок байтов может рассердиться).
Но важно использовать hton перед отправкой данных, даже если вы используете обратный порядок байтов. Ваша программа может быть настолько популярной, что ее компилируют на разных машинах, и вы хотите, чтобы ваш код был переносимым (не так ли?).
Точно так же есть функция ntoh (от сети к хосту), используемая для чтения данных из сети. Это необходимо, чтобы убедиться, что вы правильно интерпретируете сетевые данные в формате хоста. Вам необходимо знать тип получаемых данных, чтобы правильно их декодировать, а также функции преобразования:
htons () - «Короткое замыкание между хостом и сетью» htonl () - «От хоста к сети долго» ntohs () - «Короткая от сети к хосту» ntohl () - "От сети к хосту долго"
Помните, что один байт — это один байт, и порядок не имеет значения.
Эти функции критически важны при низкоуровневой работе в сети, например при проверке контрольных сумм в IP-пакетах. Если вы не понимаете проблемы с порядком байтов правильно, ваша жизнь будет болезненной — поверьте мне на слово. Используйте функции перевода и знайте, зачем они нужны.
Решение 2. Используйте метку порядка байтов (BOM)
Другой подход — включать магическое число, такое как 0xFEFF, перед каждым фрагментом данных. Если вы читаете магическое число, и это 0xFEFF, это означает, что данные находятся в том же формате, что и ваш компьютер, и все в порядке.
Если вы прочитали магическое число, и это 0xFFFE (наоборот), это означает, что данные были записаны в формате, отличном от вашего. Вам нужно будет его перевести.
Несколько замечаний. Во-первых, число на самом деле не волшебное, но программисты часто используют этот термин для описания выбора произвольного числа (спецификация могла быть любой последовательностью разных байтов). Это называется отметкой байтового порядка, потому что она указывает порядок байтов, в котором были сохранены данные.
Во-вторых, спецификация добавляет служебные данные ко всем передаваемым данным.Даже если вы отправляете только 2 байта данных, вам необходимо включить 2-байтовую спецификацию. Ой!
Unicode использует спецификацию при хранении многобайтовых данных (некоторые кодировки символов Unicode могут иметь 2, 3 или даже 4 байта на символ). XML избегает этого беспорядка, сохраняя данные по умолчанию в UTF-8, который хранит информацию Unicode по одному байту за раз. И почему это круто?
(повторяется в 56-й раз) «Поскольку проблемы с порядком байтов не имеют значения для отдельных байтов».
Верно.
Опять же, со спецификацией могут возникнуть другие проблемы.Что делать, если вы забыли включить спецификацию? Вы предполагаете, что данные были отправлены в том же формате, что и ваши собственные? Вы читаете данные и смотрите, смотрят ли они «назад» (что бы это ни значило), и пытаетесь ли их перевести? Что, если регулярные данные включают спецификацию случайно? Эти ситуации не доставляют удовольствия.
Почему вообще возникают проблемы с порядком байтов? Разве мы не можем просто ладить?
Ах, что за философский вопрос.
Каждая система с байтовым порядком имеет свои преимущества. Машины с прямым порядком байтов позволяют вам сначала читать младший байт, не читая остальные.Вы можете очень легко проверить, является ли число нечетным или четным (последний бит равен 0), что неплохо, если вам нравятся такие вещи. Системы с прямым порядком байтов хранят данные в памяти так же, как мы, люди, думаем о данных (слева направо), что упрощает отладку на низком уровне.
Но почему все не согласились с одной системой? Почему некоторые компьютеры должны стараться отличаться от других?
Позвольте мне ответить на вопрос вопросом: почему все не говорят на одном языке? Почему некоторые языки пишутся слева направо, а другие — справа налево?
Иногда системы связи развиваются независимо друг от друга, и в дальнейшем им необходимо взаимодействовать.
Эпилог: Расставания
ПроблемыEndian являются примером общей проблемы кодирования — данные должны представлять абстрактную концепцию, а позже концепция должна быть создана из данных. Эта тема заслуживает отдельной статьи (или серии), но вы должны лучше понимать проблемы с порядком байтов. Дополнительная информация:
Другие сообщения этой серии
- Системы счисления и основы
- Краткое руководство по GUID
- Понимание быстрого обратного квадратного корня Quake
- Простое введение в компьютерные сети
- Поменять местами две переменные с помощью XOR
- Общие сведения о порядке байтов с прямым и обратным порядком байтов
- Юникод и вы
- Немного о форматах двоичных файлов
- Алгоритмы сортировки
Определение байта
Байт — это единица измерения данных, содержащая восемь битов или последовательность из восьми нулей и единиц.Один байт может использоваться для представления 2 8 или 256 различных значений.
Изначально байт был создан для хранения одного символа, поскольку 256 значений достаточно для представления всех строчных и прописных букв, цифр и символов в западных языках. Однако, поскольку некоторые языки содержат более 256 символов, современные стандарты кодировки символов, такие как UTF-16, используют два байта или 16 бит для каждого символа. С помощью двух байтов можно представить 2 16 или 65 536 значений.
Хотя байт изначально был разработан для хранения символьных данных, он стал основной единицей измерения для хранения данных. Например, килобайт содержит 1000 байтов. Мегабайт содержит 1 000 x 1 000 или 1 000 000 байт.Небольшой текстовый файл может содержать всего несколько байтов данных. Однако во многих файловых системах минимальный размер кластера составляет 4 килобайта, что означает, что для каждого файла требуется минимум 4 КБ дискового пространства. Поэтому байты чаще используются для измерения конкретных данных в файле, а не самих файлов.Большие размеры файлов могут измеряться в мегабайтах, а объем хранилища данных часто измеряется в гигабайтах или терабайтах.
ПРИМЕЧАНИЕ: Один кибибайт содержит 1024 байта. Один мебибайт содержит 1024 x 1024 или 1 048 576 байтов.
Обновлено: 2 мая 2019 г.
TechTerms — Компьютерный словарь технических терминов
Эта страница содержит техническое определение байта. Он объясняет в компьютерной терминологии, что означает байт, и является одним из многих компьютерных терминов в словаре TechTerms.
Все определения на веб-сайте TechTerms составлены так, чтобы быть технически точными, но также простыми для понимания. Если вы найдете это определение байта полезным, вы можете сослаться на него, используя приведенные выше ссылки для цитирования. Если вы считаете, что термин следует обновить или добавить в словарь TechTerms, отправьте электронное письмо в TechTerms!
Подпишитесь на рассылку TechTerms, чтобы получать избранные термины и тесты прямо в свой почтовый ящик. Вы можете получать электронную почту ежедневно или еженедельно.
Подписаться
3.3 В, 5 В UART, 3,125 Мбит / с, с 256-байтовым FIFO
Архивный контент больше не обновляется и доступен только для исторической справки.
SC28L201 — это высокопроизводительный UART. Его функциональные и программные особенности близки к предыдущим UART от Philips, но значительно расширяют их. Его конфигурация при включении аналогична конфигурации SC26C92. Его отличия от предыдущих UART Philips: 256-символьный приемник, 256-символьный передающий FIFO, совместимость с 3,3 В и 5 В, 8 портов ввода-вывода для арбитража системы прерываний и общая более высокая скорость шины и данных. .5-микронный CMOS-процесс.
Является членом линии передачи данных IMPACT.
Программирование контактовпозволит устройству работать с интерфейсом шины Motorola или Intel, изменив функцию некоторых контактов (например, сброс инвертирован, DACKN и IACKN включены).
Универсальный асинхронный приемник / передатчик (UART) Philips Semiconductors SC28L201 — это однокристальное устройство связи CMOS-LSI, которое обеспечивает полнодуплексный асинхронный канал приемника / передатчика в одном корпусе.Он напрямую взаимодействует с микропроцессорами и может использоваться в системе, управляемой опросом или прерыванием. Использование системы прерываний обеспечивает интеллектуальные векторы прерывания.
Режим работы и формат данных канала можно программировать независимо. Кроме того, приемник и передатчик могут выбрать одну из двадцати семи фиксированных скоростей передачи; часы 16x, полученные от одного из двух программируемых счетчиков / таймеров, или внешние часы 1x или 16x. Генератор скорости передачи данных и счетчик / таймер могут работать непосредственно от кристалла или от внешних тактовых входов.Возможность независимо программировать рабочую скорость приемника и передатчика делает UART особенно привлекательным для приложений с двухскоростным каналом, таких как кластерные оконечные системы и мосты.
Каждый приемник и передатчик буферизуются 256-символьными буферами FIFO, чтобы почти исключить возможность переполнения приемника и передатчика, а также уменьшить накладные расходы на прерывания в системах, управляемых прерываниями. Кроме того, предусмотрена возможность управления потоком (Xon / Xoff и RTS / CTS) для отключения удаленного передатчика при заполнении буфера приемника.
Также на SC28L201 имеется многоцелевой 8-битный ввод / вывод для канала. Они могут использоваться как порты ввода-вывода общего назначения или им могут быть назначены определенные функции (такие как входы часов или выходы состояния и прерывания) под управлением программы. Обычно они используются для управления модемом и интерфейса DMA. Все порты имеют детекторы изменения состояния, а входные секции всегда активны, поэтому выходные сигналы доступны внутренним схемам и процессору управления.
SC28L201 доступен в упаковке TSSOP48.По поводу других вариантов упаковки обращайтесь в Philips.
.