Биты и Байты — основные единицы измерения информации

Чтобы досканально разобраться что такое Биты, что такое Байты и зачем всё это нужно, давайте сначала стоит немного остановимся на понятии «Информация», так как именно на ней построена работа вычислительной техники и сетей передачи данных, в том числе и нашего любимого Интернета.
Для человека, Информация — это некие знания или сведения, которыми обмениваются люди в процессе общения. Сначала знаниями обменивались устно, передавая друг другу, затем появилась письменность и информацию стали передавать уже с помощью рукописей, а затем уже и книг. Для вычислительных систем Информация — это данные которые собираются, обрабатываются, сохраняются и передаются дальше между звеньями системы, либо между разными компьютерными системами. Но если раньше информация помещалась в книги и её объём можно было хоть как-то наглядно оценить, например в библиотеке, то в условиях цифровых технологий она стала вирутальной и её нельзя измерить с помощью обычной и привычной метрической системы, к которой мы привыкли. Поэтому были введены единицы измерения информации — Биты и Байты.
Бит информации
В компьютере информация хранится на специальных носителях. Вот самые основные и знакомые большинству из нас:
- жесткий диск (HDD, SSD) - оптический диск (CD, DVD) - съёмные USB-диски (флешки, USB-HDD) - карты памяти (SD, microSD и т.п.)
Ваш персональный компьютер или ноутбук получает информацию, в основном в виде файлов с различным объёмом данных. Каждый из этих файлов любой носитель данных на аппаратном уровне получает, обрабатывает, хранит и передаёт в виде последовательности сигналов. Есть сигнал — единица, нет сигнала — ноль. Таким образом вся храняшаяся на жестком диске информация — документы, музыка, фильмы, игры — предствалена в виде нулей: 0 и единиц: 1. Эта система исчисления называется двоичной (используется всего два числа).
Сколько битов в Байте
Как Вы уже поняли выше, сам по себе, бит — это самая маленькая единица в системе измерения информации. Оттого и пользоваться ею совсем неудобно. В итоге, в 1956 году Владимир Бухгольц ввёл ещё одну единицу измерения — Байт, как пучок из 8 бит. Вот наглядный пример байта в двоичной системе:
00000001 10000000 11111111
Таким образом, вот эти 8 бит и есть Байт. Он представляет собой комбинацию из 8 цифр, каждая из которых может быть либо единицей, либо нулем. Всего получается 256 комбинаций. Вот как то так.
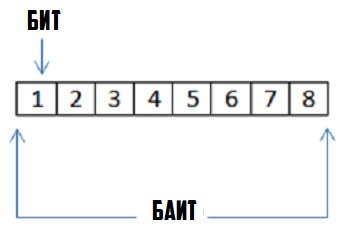
Килобайт, Мегабайт, Гигабайт
Со временем, объёмы информации росли, причём в последние годы в геометрической прогрессии. Поэтому, решено было использовать приставки метрической системы СИ: Кило, Мега, Гига, Тера и т.п.
Приставка «кило» означает 1000, приставка «мега» подразумевает миллион, «гига» — миллиард и т.д. При этом нельзя проводить аналогии между обычным килобитом и килобайтом. Дело в том, что килобайт — это отнюдь не тысяча байт, а 2 в 10-й степени, то есть 1024 байт.
Соответственно, мегабайт — это 1024 килобайт или 1048576 байт.
Для простоты можно использовать такую таблицу:
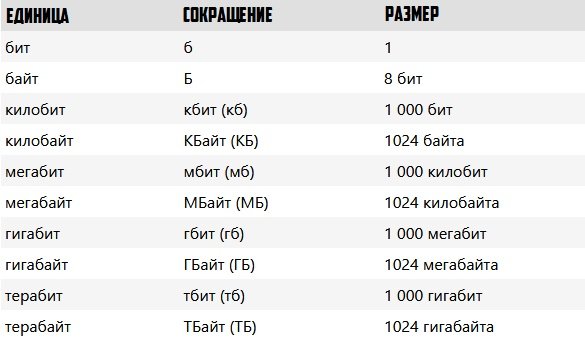
Для примера хочу привести вот такие цифры:
Стандартный лист А4 с печатным текстом занимает в средем около 100 килобайт
Обычная фотография на простой цифровой фотоаппарат — 5-8 мегабайт
Фотографии, сделанные на профессиональный фотоаппарат — 12-18 мегабайт
Музыкальный трек формата mp3 среднего качества на 5 минут — около 10 мегабайт.
Обычный фильм на 90 минут, сжатый в обычном качестве — 1,5-2 гигабайта
P.S.:
Теперь отвечу на вопросы, которые мне наиболее часто задают новички.
1. Сколько Килобит в Мегабите? Ответ — 1000 килобит (по системе СИ)
2. Сколько Килобайт в Мегабайте? Ответ — 1024 Килобайта
3. Сколько Килобит в Мегабайте? Ответ — 8192 килобита
4. Сколько Килобайт в Гигабайте? Ответ — 1 048 576 Килобайт.
Единицы измерения объема информации
Для измерения длины есть такие единицы, как миллиметр, сантиметр, метр, километр. Известно, что масса измеряется в граммах, килограммах, центнерах и тоннах. Бег времени выражается в секундах, минутах, часах, днях, месяцах, годах, веках. Компьютер работает с информацией и для измерения ее объема также имеются соответствующие единицы измерения.
Бит и байт – минимальные единицы измерения информации
Мы уже знаем, что компьютер воспринимает всю информацию через нули и единички.
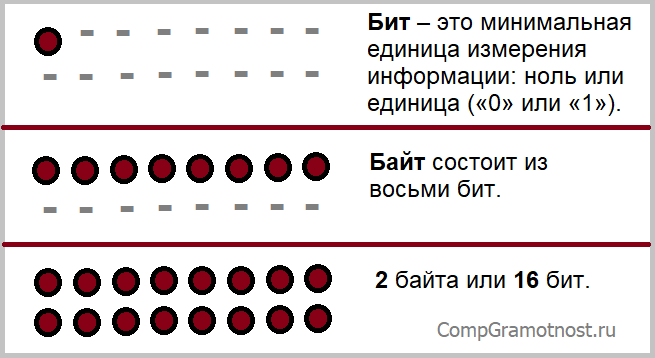
Бит – это минимальная единица измерения информации, соответствующая одной двоичной цифре («0» или «1»).
Бит – это только 0 («ноль») или только 1 («единичка»). С помощью одного бита можно записать два состояния: 0 (ноль) или 1 (один). Бит – это минимальная ячейка памяти, меньше не бывает. В этой ячейке может храниться либо нолик, либо единичка.
Байт состоит из восьми бит. Используя один байт, можно закодировать один символ из 256 возможных (256 = 28). Таким образом, один байт равен одному символу, то есть 8 битам:
1 символ = 8 битам = 1 байту.
Буква, цифра, знак препинания – это символы. Одна буква – один символ. Одна цифра – тоже один символ. Один знак препинания (либо точка, либо запятая, либо вопросительный знак и т.п.) – снова один символ. Один пробел также является одним символом.
Кроме бита и байта, конечно же, есть и другие, более крупные единицы измерения информации.
Таблица байтов:
1 байт = 8 бит
1 Кб (1 Килобайт) = 210 байт = 2*2*2*2*2*2*2*2*2*2 байт =
= 1024 байт (примерно 1 тысяча байт – 103 байт)
1 Мб (1 Мегабайт) = 220 байт = 1024 килобайт (примерно 1 миллион байт – 10
1 Гб (1 Гигабайт) = 230 байт = 1024 мегабайт (примерно 1 миллиард байт – 109 байт)
1 Тб (1 Терабайт) = 240 байт = 1024 гигабайт (примерно 1012 байт). Терабайт иногда называют тонна.
1 Пб (1 Петабайт) = 250 байт = 1024 терабайт (примерно 1015 байт).
1 Эксабайт = 260 байт = 1024 петабайт (примерно 1018 байт).
1 Зеттабайт = 270 байт = 1024 эксабайт (примерно 1021 байт).
1
В приведенной выше таблице степени двойки (210, 220, 230 и т.д.) являются точными значениями килобайт, мегабайт, гигабайт. А вот степени числа 10 (точнее, 103, 106, 109 и т.п.) будут уже приблизительными значениями, округленными в сторону уменьшения. Таким образом, 210 = 1024 байта представляет точное значение килобайта, а 103 = 1000 байт является приблизительным значением килобайта.
Такое приближение (или округление) вполне допустимо и является общепринятым.
Ниже приводится таблица байтов с английскими сокращениями (в левой колонке):
1 Kb ~ 103 b = 10*10*10 b= 1000 b – килобайт
1 Mb ~ 106 b = 10*10*10*10*10*10 b = 1 000 000 b – мегабайт
1 Gb ~ 109 b – гигабайт
1 Tb ~ 1012 b – терабайт
1 Pb ~ 1015 b – петабайт
1 Eb ~ 1018 b – эксабайт
1 Zb ~ 1021 b – зеттабайт
1 Yb ~ 1024 b – йоттабайт
Выше в правой колонке приведены так называемые «десятичные приставки», которые используются не только с байтами, но и в других областях человеческой деятельности. Например, приставка «кило» в слове «килобайт» означает тысячу байт. В случае с километром она соответствует тысяче метров, а в примере с килограммом она равна тысяче грамм.
Продолжение следует…
Возникает вопрос: есть ли продолжение у таблицы байтов? В математике есть понятие бесконечности, которое обозначается как перевернутая восьмерка: ∞.
Понятно, что в таблице байтов можно и дальше добавлять нули, а точнее, степени к числу 10 таким образом: 1027, 1030, 1033 и так до бесконечности. Но зачем это надо? В принципе, пока хватает терабайт и петабайт. В будущем, возможно, уже мало будет и йоттабайта.
Напоследок парочка примеров по устройствам, на которые можно записать терабайты и гигабайты информации.
Есть удобный «терабайтник» – внешний жесткий диск, который подключается через порт USB к компьютеру. На него можно записать терабайт информации. Особенно удобно для ноутбуков (где смена жесткого диска бывает проблематична) и для резервного копирования информации. Лучше заранее делать резервные копии информации, а не после того, как все пропало.
Флешки бывают 1 Гб, 2 Гб, 4 Гб, 8 Гб, 16 Гб, 32 Гб , 64 Гб и даже 1 терабайт.
CD-диски могут вмещать 650 Мб, 700 Мб, 800 Мб и 900 Мб.
DVD-диски рассчитаны на большее количество информации: 4.7 Гб, 8.5 Гб, 9.4 Гб и 17 Гб.
Упражнения по компьютерной грамотности
описаны в статье “Байт, килобайт, мегабайт…”
Статья закончилась, но можно еще прочитать:
Кодирование текстовой информации
Проверяем, кодирует ли компьютер текст
Кодирование цветовой информации
Получайте актуальные статьи по компьютерной грамотности прямо на ваш почтовый ящик.
Уже более 3.000 подписчиков
Важно: необходимо подтвердить свою подписку! В своей почте откройте письмо для активации и кликните по указанной там ссылке. Если письма нет, проверьте папку Спам.
Автор: Надежда Широбокова
6 июля 2010
Разбираемся с прямым и обратным порядком байтов / Habr
Перевод статьи Халида Азада — Understanding Big and Little Endian Byte OrderПроблемы с порядком байтов очень расстраивают, и я хочу избавить Вас от горя, которое довелось испытать мне. Вот ключевые тезы:
- Проблема: Компьютеры, как и люди, говорят на разных языках. Одни записывают данные “слева направо” другие “справа налево”. При этом каждое устройство отлично считывает собственные данные — проблемы начинаются, когда один компьютер сохраняет данные, а другой пытается эти данные считать.
- Решение: Принять некий общий формат (например, весь сетевой трафик передается в едином формате). Или всегда добавлять заголовок, описывающий формат хранения данных. Если считанный заголовок имеет обратный порядок, значит данные сохранены в другом формате и должны быть переконвертированы.
Числа и данные
Наиболее важная концепция заключается в понимании разницы между числами и данными, которые эти числа представляют. Число — это абстрактное понятия, как исчислитель чего-то. У Вас есть десять пальцев. Понятие “десять” не меняется, в зависимости от использованного представления: десять, 10, diez (испанский), ju (японский), 1010 (бинарное представление), Х (римские числа)… Все эти представления указывают на понятие “десяти”.
Сравним это с данными. Данные — это физическое понятие, просто последовательность битов и байтов, хранящихся на компьютере. Данные не имеют неотъемлемого значения и должны быть интерпретированы тем, кто их считывает.
Данные — это как человеческое письмо, просто набор отметок на бумаге. Этим отметкам не присуще какое-либо значение. Если мы видим линию и круг (например, |O), то можно интерпретировать это как “десять”. Но это лишь предположение, что считанные символы представляют число. Это могут быть буквы “IO” — название спутника Юпитера. Или, возможно, имя греческой богини. Или аббревиатура для ввода/вывода. Или чьи-то инициалы. Или число 2 в бинарном представлении (“10”). Этот список предположений можно продолжить. Дело в том, что один фрагмент данных (|O) может быть интерпретировано по разному, и смысл остается не ясен, пока кто-то не уточнит намерения автора.
Компьютеры сталкиваются с такой же проблемой. Они хранят данные, а не абстрактные понятия, используя при этом 1 и 0. Позднее они считывают эти 1 и 0 и пытаются воссоздать абстрактные понятия из набора данных. В зависимости от сделанных допущений, эти 1 и 0 могут иметь абсолютно разное значение.
Почему так происходит? Ну, вообще-то нет такого правила, что компьютеры должны использовать один и тот же язык, так же, как нет такого правила и для людей. Каждый компьютер одного типа имеет внутреннюю совместимость (он может считывать свои собственные данные), но нет никакой гарантии, как именно интерпретирует эти данные компьютер другого типа.
Основные концепции:
- Данные (биты и байты или отметки на бумаге) сами по себе не имеют смысла. Они должны быть интерпретированы в какое-то абстрактное понятие, например, число.
- Как и люди, компьютеры имеют различные способы хранения одного и того же абстрактного понятия (например, мы можем различными способами сказать “10”).
Храним числа как данные
К счастью, большинство компьютеров хранят данные всего в нескольких форматах (хотя так было не всегда). Это дает нам общую отправную точку, что делает жизнь немного проще:
- Бит имеет два состояния (включен или выключен, 1 или 0).
- Байт — это последовательность из 8 бит. Крайний левый бит в байте является старшим. То есть двоичная последовательность 00001001 является десятичным числом девять. 00001001 = (2^3 + 2^0 = 8 + 1 = 9).
- Биты нумеруются справа налево. Бит 0 является крайним правым и он наименьший. Бит 7 является крайним левым и он наибольший.
Мы можем использовать эти соглашения в качестве строительного блока для обмена данными. Если мы сохраняем и читаем данные по одному байту за раз, то этот подход будет работать на любом компьютере. Концепция байта одинаковая на всех машинах, понятие “байт 0” одинакова на всех машинах. Компьютеры также отлично понимают порядок, в котором Вы посылаете им байты — они понимают какой байт был прислан первым, вторым, третьим и т. д. “Байт 35” будет одним и тем же на всех машинах.
Так в чем же проблема — компьютеры отлично ладят с одиночными байтами, правда? Ну, все превосходно для однобайтных данных, таких как ASCII-символы. Однако, много данных используют для хранения несколько байтов, например, целые числа или числа с плавающей точкой. И нет никакого соглашения о том, в каком порядке должны хранится эти последовательности.
Пример с байтом
Рассмотрим последовательность из 4 байт. Назовем их W X Y и Z. Я избегаю наименований A B C D, потому что это шестнадцатеричные числа, что может немного запутывать. Итак, каждый байт имеет значение и состоит из 8 бит.
Имя байта W X Y Z
Позиция 0 1 2 3
Значение (hex) 0x12 0x34 0x56 0x78
Например, W — это один байт со значением 0х12 в шестнадцатеричном виде или 00010010 в бинарном. Если W будет интерпретироваться как число, то это будет “18” в десятеричной системе (между прочим, ничто не указывает на то, что мы должны интерпретировать этот байт как число — это может быть ASCII-символ или что-то совсем иное). Вы все еще со мной? Мы имеем 4 байта, W X Y и Z, каждый с различным значением.
Понимаем указатели
Указатели являются ключевой частью программирования, особенно в языке С. Указатель представляет собой число, являющееся адресом в памяти. И это зависит только от нас (программистов), как интерпретировать данные по этому адресу.
В языке С, когда вы кастите (приводите) указатель к конкретному типу (такому как char * или int *), это говорит компьютеру, как именно интерпретировать данные по этому адресу. Например, давайте объявим:
void *p = 0; // p указатель на неизвестный тип данных
// p нулевой указатель - не разыменовывать
char *c; // c указатель на один байт
Обратите внимание, что мы не можем получить из р данные, потому что мы не знаем их тип. р может указывать на цифру, букву, начало строки, Ваш гороскоп или изображение — мы просто не знаем, сколько байт нам нужно считать и как их интерпретировать.
Теперь предположим, что мы напишем:
c = (char *)p;
Этот оператор говорит компьютеру, что р указывает на то же место, и данные по этому адресу нужно интерпретировать как один символ (1 байт). В этом случае, с будет указывать на память по адресу 0, или на байт W. Если мы выведем с, то получим значение, хранящееся в W, которое равно шестнадцатеричному 0x12 (помните, что W — это полный байт). Этот пример не зависит от типа компьютера — опять же, все компьютеры одинаково хорошо понимают, что же такое один байт (в прошлом это было не всегда так).
Этот пример полезен, он одинаково работает на все компьютерах — если у нас есть указатель на байт (char *, один байт), мы можем проходить по памяти, считывая по одному байту за раз. Мы можем обратиться к любому месту в памяти, и порядок хранения байт не будет иметь никакого значения — любой компьютер вернет нам одинаковую информацию.
Так в чем же проблема?
Проблемы начинаются, когда компьютер пытается считать несколько байт. Многие типы данных состоят больше чем из одного байта, например, длинные целые (long integers) или числа с плавающей точкой. Байт имеет только 256 значений и может хранить числа от 0 до 255.
Теперь начинаются проблемы — если Вы читаете многобайтные данные, то где находится старший байт?
- Машины с порядком хранения от старшего к младшему (прямой порядок) хранят старший байт первым. Если посмотреть на набор байтов, то первый байт (младший адрес) считается старшим.
- Машины с порядком хранения от младшего к старшему (обратный порядок) хранят младший байт первым. Если посмотреть на набор байт, то первый байт будет наименьшим.
Такое именование имеет смысл, правда? Тип хранения от старшего к младшему подразумевает, что запись начинается со старшего и заканчивается младшим (Между прочим, английский вариант названий от старшего к младшего (Big-endian) и от младшего к старшему (Little-endian) взяты из книги “Путешествия Гулливера”, где лилипуты спорили о том, следует ли разбивать яйцо на маленьком конце (little-end) или на большом (big-end)). Иногда дебаты компьютеров такие же осмысленные 🙂
Повторюсь, порядок следования байтов не имеет значения пока Вы работаете с одним байтом. Если у Вас есть один байт, то это просто данные, которые Вы считываете и есть только один вариант их интерпретации (опять таки, потому что между компьютерами согласовано понятие одного байта).
Теперь предположим, что у нас есть 4 байта (WXYZ), которые хранятся одинаково на машинах с обоими типами порядка записи байтов. То есть, ячейка памяти 0 соответствует W, ячейка 1 соответствует X и т. д.
Мы можем создать такое соглашение, помня, что понятие “байт” является машинно-независимым. Мы можем обойти память по одному байту за раз и установить необходимые значения. Это будет работать на любой машине.
c = 0; // указывает на позицию 0 (не будет работать на реальной машине!)
*c = 0x12; // устанавливаем значение W
c = 1; // указывает на позицию 1
*c = 0x34; // устанавливаем значение X
... // то же повторяем для Y и Z
Такой код будет работать на любой машине и успешно установит значение байт W, X, Y и Z расположенных на соответствующих позициях 0, 1, 2 и 3.
Интерпретация данных
Теперь давайте рассмотрим пример с многобайтными данными (наконец-то!). Короткая сводка: “short int” это 2-х байтовое число (16 бит), которое может иметь значение от 0 до 65535 (если оно беззнаковое). Давайте используем его в примере.
short *s; // указатель на short int (2 байта)
s = 0; // указатель на позицию 0; *s это значение
Итак, s это указатель на short int, и сейчас он указывает на позицию 0 (в которой хранится W). Что произойдет, когда мы считаем значение по указателю s?
- Машина с прямым порядком хранения: Я думаю, short int состоит из двух байт, а значит я считаю их. Позиция s это адрес 0 (W или 0х12), а позиция s + 1 это адрес 1 (X или 0х34). Поскольку первый байт является старшим, то число должно быть следующим 256 * байт 0 + байт 1 или 256 * W + X, или же 0х1234. Я умножаю первый байт на 256 (2^8) потому что его нужно сдвинуть на 8 бит.
- Машина с обратным порядком хранения: Я не знаю что курит мистер “От старшего к младшему”. Я соглашусь, что short int состоит из 2 байт и я считаю их точно также: позиция s со значение 0х12 и позиция s + 1 со значением 0х34. Но в моем мире первым является младший байт! И число должно быть байт 0 + 256 * байт 1 или 256 * X + W, или 0х3412.
Обратите внимание, что обе машины начинали с позиции s и читали память последовательно. Не никакой путаницы в том, что значит позиция 0 и позиция 1. Как и нет никакой путаницы в том, что являет собой тип short int.
Теперь Вы видите проблему? Машина с порядком хранения от старшего к младшему считает, что s = 0x1234, в то время как машина с порядком хранения от младшего к старшему думает, что s = 0x3412. Абсолютно одинаковые данные дают в результате два совершенно разных числа.
И еще один пример
Давайте для “веселья” рассмотрим еще один пример с 4 байтовым целым:
int *i; // указатель на int (4 байты 32-битовой машине)
i = 0; // указывает на позицию 0, а *i значение по этому адресу
И опять мы задаемся вопросом: какое значение хранится по адресу i?
- Машина с прямым порядком хранения: тип int состоит из 4 байт и первый байт является старшим. Считываю 4 байта (WXYZ) из которых старший W. Полученное число: 0х12345678.
- Машина с обратным порядком хранения: несомненно, int состоит из 4 байт, но старшим является последний. Так же считываю 4 байта (WXYZ), но W будет расположен в конце — так как он является младшим. Полученное число: 0х78563412.
Одинаковые данные, но разный результат — это не очень приятная вещь.
Проблема NUXI
Проблему с порядком байт иногда называют проблемой NUXI: слово UNIX, сохраненное на машинах с порядком хранения от старшего к младшему, будет отображаться как NUXI на машинах с порядком от младшего к старшему.
Допустим, что мы собираемся сохранить 4 байта (U, N, I, и X), как два short int: UN и IX. Каждая буква занимает целый байт, как в случае с WXYZ. Для сохранения двух значений типа short int напишем следующий код:
short *s; // указатель для установки значения переменной типа short
s = 0; // указатель на позицию 0
*s = UN; // устанавливаем первое значение: U * 256 + N (вымышленный код)
s = 2; // указатель на следующую позицию
*s = IX; // устанавливаем второе значение: I * 256 + X
Этот код не является специфичным для какой-то машины. Если мы сохраним значение “UN” на любой машине и считаем его обратно, то обратно получим тоже “UN”. Вопрос порядка следования байт не будет нас волновать, если мы сохраняем значение на одной машине, то должны получить это же значение при считывании.
Однако, если пройтись по памяти по одному байту за раз (используя трюк с char *), то порядок байт может различаться. На машине с прямым порядком хранения мы увидим:
Byte: U N I X
Location: 0 1 2 3
Что имеет смысл. “U” является старшим байтом в “UN” и соответственно хранится первым. Такая же ситуация для “IX”, где “I” — это старший байт и хранится он первым.
На машине с обратным порядком хранения мы скорее всего увидим:
Byte: N U X I
Location: 0 1 2 3
Но и это тоже имеет смысл. “N” является младшим байтом в “UN” и значит хранится он первым. Опять же, хотя байты хранятся в “обратном порядке” в памяти, машины с порядком хранения от младшего к старшему знают что это обратный порядок байт, и интерпретирует их правильно при чтении. Также, обратите внимание, что мы можем определять шестнадцатеричные числа, такие как 0x1234, на любой машине. Машина с обратным порядком хранения байтов знает, что Вы имеете в виду, когда пишите 0x1234 и не заставит Вас менять значения местами (когда шестнадцатеричное число отправляется на запись, машина понимает что к чему и меняет байты в памяти местами, скрывая это от глаз. Вот такой трюк.).
Рассмотренный нами сценарий называется проблемой “NUXI”, потому что последовательность “UNIX” интерпретируется как “NUXI” на машинах с различным порядком хранения байтов. Опять же, эта проблема возникает только при обмене данными — каждая машина имеет внутреннюю совместимость.
Обмен данными между машинами с различным порядком хранения байтов
Сейчас компьютеры соединены — прошли те времена, когда машинам приходилось беспокоиться только о чтении своих собственных данных. Машинам с различным порядком хранения байтов нужно как-то обмениваться данными и понимать друг друга. Как же они это делают?
Решение 1: Использовать общий формат
Самый простой подход состоит в согласовании с общим форматом для передачи данных по сети. Стандартным сетевым является порядок от старшего к младшему, но некоторые люди могут расстроиться, что не победил порядок от младшего к старшему, поэтому просто назовем его “сетевой порядок”.
Для конвертирования данных в соответствии с сетевым порядком хранения байтов, машины вызывают функцию hton() (host-to-network). На машинах с прямым порядком хранения эта функция не делает ничего, но мы не будем говорить здесь об этом (это может разозлить машины с обратным порядком хранения 🙂 ).
Но важно использовать функцию hton() перед отсылкой данных даже если Вы работаете на машине с порядком хранения от старшего к младшему. Ваша программа может стать весьма популярной и будет скомпилирована на различных машинах, а Вы ведь стремитесь к переносимости своего кода (разве не так?).
Точно также существует функция ntoh() (network-to-host), которая используется для чтения данных из сети. Вы должны использовать ее, чтобы быть уверенными, что правильно интерпретируете сетевые данные в формат хоста. Вы должны знать тип данных, которые принимаете, чтобы расшифровать их правильно. Функции преобразования имеют следующий вид:
htons() - "Host to Network Short"
htonl() - "Host to Network Long"
ntohs() - "Network to Host Short"
ntohl() - "Network to Host Long"
Помните, что один байт — это один байт и порядок не имеет значения.
Эти функции имеют критическое значение при выполнении низкоуровневых сетевых операций, таких как проверка контрольной суммы IP-пакетов. Если Вы не понимаете сути проблемы с порядком хранения байтов, то Ваша жизнь будет наполнена болью — поверьте мне на слово. Используйте функции преобразования и знайте, зачем они нужны.
Решение 2: Использования маркера последовательности байтов (Byte Order Mark — BOM)
Этот подход подразумевает использование некого магического числа, например 0xFEFF, перед каждым куском данных. Если Вы считали магическое число и его значение 0xFEFF, значит данные в том же формате, что и у Вашей машины и все хорошо. Если Вы считали магическое число и его значение 0xFFFE, это значит, что данные были записаны в формате, отличающемся от формата вашей машины и Вы должны будете преобразовать их.
Нужно отметить несколько пунктов. Во-первых, число не совсем магическое, как известно программисты часто используют этот термин для описания произвольно выбранных чисел (BOM может быть любой последовательностью различных байтов). Такая пометка называется маркером последовательности байтов потому что показывает в каком порядке данные были сохранены.
Во-вторых, BOM добавляет накладные расходы для всех передаваемых данных. Даже в случае передачи 2 байт информации Вы должны добавлять к ним 2 байта маркера BOM. Пугающе, не так ли?
Unicode использует BOM, когда сохраняет многобайтные данные (некоторые кодировки Unicode могут иметь по 2, 3 и даже 4 байта на символ). XML позволяет избежать этой путаницы, сохраняя данные сразу в UTF-8 по умолчанию, который сохраняет информацию Unicode по одному байту за раз. Почему это так круто?
Повторяю в 56-й раз — потому что проблема порядка хранения не имеет значения для единичных байт.
Опять же, в случае использования BOM может возникнуть другие проблемы. Что, если Вы забудете добавить BOM? Будете предполагать, что данные были отправлены в том же формате, что и Ваши? Прочитаете данные и, увидев что они “перевернуты” (что бы это не значило), попытаетесь преобразовать их? Что, если правильные данные случайно будут содержать неправильный BOM? Эти ситуации не очень приятные.
Почему вообще существует эта проблема? Нельзя ли просто договориться?
Ох, какой же это философский вопрос. Каждый порядок хранения байтов имеет свои преимущества. Машины с порядком следования от младшего к старшему позволяют читать младший байт первым, не считывая при этом остальные. Таким образом можно легко проверить является число нечетным или четным (последний бит 0), что очень здорово, если Вам необходима такая проверка. Машины с порядком от старшего к младшему хранят данные в памяти в привычном для человека виде (слева направо), что упрощает низкоуровневую отладку.
Так почему же все просто не договорятся об использовании одной из систем? Почему одни компьютеры пытаются быть отличными от других? Позвольте мне ответить вопросом на вопрос: почему не все люди говорят на одном языке? Почему в некоторых языках письменность слева направо, а у других справа налево?
Иногда системы развиваются независимо, а в последствии нуждаются во взаимодействии.
Эпилог: Мысли на прощание
Вопросы с порядком хранения байтов являются примером общей проблемы кодирования — данные должны представлять собой абстрактные понятия, и позднее это понятие должно быть создано из данных. Эта тема заслуживает отдельной статьи (или серии статей), но Вы должны иметь лучшее понимание проблемы, связанной с порядком хранения байтов.
Биты и байты — что такое и в чем разница

 Сегодняшняя заметка посвящена самым основам информатики, которые, впрочем, иногда забываются как пользователями, так и IT-специалистами (в конце концов, в этой сфере самоучек много как нигде). Итак, углубимся в теорию о битах и байтах.
Сегодняшняя заметка посвящена самым основам информатики, которые, впрочем, иногда забываются как пользователями, так и IT-специалистами (в конце концов, в этой сфере самоучек много как нигде). Итак, углубимся в теорию о битах и байтах.Бит
Биты это количество информации, равное одному символу или сигналу, которые могут принимать только два значения (да/нет, включено/выключено, 1/0). Ноль и единица взяты из двоичной системы исчисления. Собственно, само слово bit происходит от binary digit — двоичное число. По сути, бит это своеобразная точка отсчёта, базовая единица измерения количества информации.
 С помощью лампы можно передать один бит информации.
С помощью лампы можно передать один бит информации.Пример с лампами далеко не умозрительный. Сейчас далеко не все помнят ламповые компьютеры, которые были предшественниками компьютеров, построенных на основе транзисторов. И пусть в современных компьютерах уже не используются лампы, но принцип, что одна ячейка памяти может находиться в одном из двух состояний (содержать один бит информации), остаётся актуальным.
Вопреки распространённому мнению, в русском языке нет сокращения для слова «бит». Таким образом, правильно писать не «Мб», а «Мбит» и т.п. Это касается и англоязычного написания: «Mbit» — правильно, «Mb» — нет.
Байт
Как многие знают, байт состоит из восьми битов. На самом деле, это не всегда так, и иногда в компьютерных стандартах используется термин «октет» как обозначение байта, равного именно восьми битам. Однако, мы не будем углубляться в историю компьютерной техники. Примем как данность, что байт это совокупность битов, и на текущий момент стандартом является правило «1 байт равен 8 битам». В большинстве вычислительных архитектур байт является минимальным независимо адресуемым набором данных. В этом и заключается суть байта. Байтовая адресация памяти вытеснила используемую ранее адресацию, при которой машинное слово можно было адресовать только целиком, так как этот способ затруднял обработку текстовых данных.
Сам термин byte является преднамеренным искажением слова bite (с английского «кусок», «то, что можно отделить за один укус»). Замена буквы произведена с той целью, чтобы не было путаницы с битами.
 Бит и байт
Бит и байтБайт имеет сокращение «Б» («B» в английской версии написания). Таким образом, написания «МБ», «ГБ» («MB», «GB») и тому подобные являются допустимыми и позволяют избежать путаницы с мегабитами, гигабитами и т.д.
Бит, байт и простое объяснение логических операций.
Как и в любой вычислительной технике, где применяется цифровой сигнал практически всегда встречаются такие слова как «бит» и «байт». Не является исключением и микроконтроллеры. Давайте попробуем разобраться, что же это такое.
Бит — (англ. binary digit; также игра слов: англ. bit — немного) — единица измерения информации, один разряд двоичного кода (двоичная цифра). Бит может принимать только два значения «0» или «1», да или нет, включено/выключено, и т. п. В вычислительной технике «0» и «1» передаются различными уровнями напряжения, к примеру, в микросхемах ТТЛ «0» соответствует напряжением в диапазоне от +0 до + 0,8 В, а «1» в диапазоне от 2,0 до 5,0 В»..
«Бит» часто применяется в значении «двоичный разряд»(старший бит — старший двоичный разряд байта или слова, младший бит — младший разряд слова , о которых идёт речь). Относительно к микроконтроллерам, мы часто будем сталкиваться с битами. В семействе микроконтроллерах PIC18XXXX существуют специальные БИТ-ОРИЕНТИРОВАННЫЕ КОМАНДЫ. с помощью которых можно будет сбрасывать/устанавливать определенные биты в байтах (регистрах).
Байт (англ. byte) — единица измерения количества информации. В стандартном виде байт считается равным восьми двоичным цифрам (битам). Он может принимать 256 (2 в 8 й степени) различных значений. Значениями одного байта можно кодировать довольно большие объемы информации. Например, все заглавные и строчные буквы алфавита, цифры, знаки препинания, символы и служебные коды, используемые при передаче данных.Емкость различных устройств хранения информации, в том числе и в микроконтроллерах, измеряется тоже в байтах. Так же как при работе с битами, в семействе микроконтроллерах PIC18XXXX существуют и БАЙТ-ОРИЕНТИРОВАННЫЕ КОМАНДЫ, которые позволяют изменять байт «целиком» (сбрасывать, записывать в него данные (0-255) и т.д.). Младший бит находится справа, соответственно старший слева.
Многие путают производные единицы — килобиты с килоБайтами. Заметьте я специально написал байты с большой буквы, вот на это и следует обращать внимание. Если написано кб — имеется в виду килобит, если написано кБ — то имеется ввиду килобайт. И килобайт соответственно больше в восемь раз килобита. То же самое Мегабиты ( Мб ) и МегаБайты (МБ) и т.д..
В битах (килобитах, мегабитах) в секунду и в байтах (килобайотах, мегабайтах) в секунду измеряется скорость передачи данных (к примеру скорость Вашего Интернета ).
В предыдущей главе мы выяснили, что двоичные числа, так же как и десятичные, можно складывать, умножать, вычитать и делить. Естественно, что эти операции можно производить и над байтами. А в микроконтроллерах кроме этого, предусмотрены различные команды сравнения, сдвига, в том числе и команды, выполняющие простые логические операции. Если Вы сталкивались ранее с логическими микросхемами, то соответственно сталкивались и с побитовыми логическими операциями «И», «ИЛИ», «НЕ» и исключающие ИЛИ. Для тех кто слабо понимает что это такое попробуем разобраться.
Побитовое отрицание (NOT) (или побитовое «НЕ», или дополнение) — это бинарная операция, действие которой эквивалентно применению логического отрицания к каждому биту двоичного представления операнда. Простыми словами, там где в двоичном представлении операнда был 0, после выполнения операции будет 1, и, наоборот, где была 1, там будет 0. В семействе микроконтроллерах PIC18XXXX есть такая команда «COMF«, которая инвертирует содержимое регистра (байта). Обозначение:
Пример:
| 1 | 0 | 1 | 1 | 1 | 0 | 0 | 1 |
| 0 | 1 | 0 | 0 | 0 | 1 | 1 | 0 |
Побитовое И (AND)— это бинарная операция, действие которой эквивалентно применению логического «И» к каждой паре битов, которые стоят на одинаковых позициях в сравниваемых байтах . Другими словами, если оба соответствующих бита байтов равны 1, то результат двоичного разряда будет 1; если же хотя бы один бит из пары равен 0, то результат двоичного разряда будет 0. По отношению к микроконтроллерам существуют команда «ANDWF», к стати первые три буквы AND как раз и говорят об операции «И» над регистром (байтом) «F» и «W» (пока не будем вникать и назовем его то же байт, по сути так и есть). Обозначение: a & b
Пример:
| 1 | 0 | 0 | 1 | 1 | 1 | 0 | 1 |
| 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 |
| 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 |
Побитовое ИЛИ (OR) — это бинарная операция, действие которой эквивалентно применению логического «ИЛИ» к каждой паре битов, которые стоят на одинаковых позициях в сравниваемых байтах. Другими словами, если оба соответствующих бита байтов равны 0, то результат двоичного разряда будет 0; если же хотя бы один бит из пары равен 1, то результат двоичного разряда будет 1. Опять же по отношению к микроконтроллерам существуют команда «IORWF». Обозначение: a | b
Пример:
| 1 | 0 | 0 | 0 | 1 | 1 | 1 | 1 |
| 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 |
| 1 | 0 | 1 | 0 | 1 | 1 | 1 | 1 |
Сложение по модулю два (XOR) (исключающее ИЛИ) — это бинарная операция, результат действия которой равен 1, если число складываемых единичных битов нечетно, если же их число четно, то результат ,будет 0. По отношению к микроконтроллерам существуют команда «XORWF«. Обозначение: a^b
Пример:
| 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 |
| 1 | 0 | 0 | 0 | 1 | 1 | 1 | 0 |
| 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 |
К логическим битовым операциям можно также отнести битовые сдвиги. Их несколько — это логический, циклический и арифметический. Нас интересует только циклический сдвиг. При циклическом сдвиге, значение последнего бита по направлению сдвига копируется в первый бит .
В семействе микроконтроллерах PIC18XXXX есть такие команды, как RLCF, RLNCF— сдвиг регистра влево через перенос и без переноса и RRCF, RRNC — то же самое только сдвиг регистра (байта) происходит вправо. Более подробно мы остановимся, когда будет рассматривать команды микроконтроллера.
Байты и биты – чем отличаются, что измеряют [+ВИДЕО]
В этой статье расскажу Вам про такие единицы измерения компьютерной информации как Байты и Биты — меня часто спрашивали читатели про эту сладкую парочку в комментариях.
Как известно, каждый компьютер или любой другой гаджет работает с огромным количеством информации. И для определения её объёмов были созданы специальные измерительные единицы. Каждый среднестатистический пользователь ПК наверняка знает о том, что существуют такие термины, как биты и байты.
Для того, чтобы научиться максимально быстро преобразовывать байты в гигабайты, а гигабайты в терабайты, необходимо изначально изучить особенности минимальных единиц измерения.
Оглавление:Работа с данными
Информация — это всё то, что мы можем видеть, слышать, или же читать. При этом, объёмы этой самой информации постоянно растут и хранить, а также систематизировать её становится всё сложнее. Сам же компьютер обрабатывает информационные блоки с помощью устройств, расположенных внутри системного блока. Между тем или иным узлом информация передаётся за счёт наличия кабелей.
Даже с помощью таких внешних устройств, как клавиатура или мышка, Вы всё равно вносите дополнительную информацию в свой компьютер, которую необходимо будет обрабатывать и в дальнейшем хранить. В быту данные, важные для нас, хранятся в записной книжке, блокноте или ежедневнике.
С компьютером всё обстоит иначе. Он вынужден фиксировать любую информацию и для хранения использует специальные носители, включая жёсткий диск. Несмотря на его компактные размеры, на самом деле в устройстве может храниться невероятное количество данных, включая миллионы документов, тысячи аудиозаписей и видеороликов.
При этом, воспринимать информацию компьютер способен не так, как наш мозг, а в кодовом эквиваленте «0» или «1». На этом и базируется двоичная система, в которой участвуют всего две цифры. Именно одна из них называется битом, который является самым маленьким носителем компьютерной информации. При этом, само устройство может как хранить биты, так и передавать их.


Читайте также на сайте:
Что такое байт
Наверняка каждый из нас слышал про азбуку Морзе, которая до сих пор активно используется в некоторых сферах деятельности. В её основе положено использование двух типов сигналов: точек и тире. Их комбинации можно расшифровать в буквы, слова и целые предложения.
Что же касается компьютерной системы шифра, то она состоит из 8 цифр, ведь из них можно получить сразу 256 комбинаций, чего хватит для кодирования цифр и букв нескольких алфавитов. Именно эти восемь цифр называют байтами.
Другими словами, в одном байте содержится 8 бит. Эту информацию нет необходимости знать в обязательном порядке, однако её понимание позволит досконально оценить размеры информации на том или ином носителе.
Подробнее узнать о трансформации привычных нам знаков в двоичный код можно с помощью калькулятора, который является базовой программой операционной системы Виндоус. Вам нужно будет лишь запустить его и перейти в режим «Программист».
После этого Вы сможете ввести любое число и нажать на кнопку «Bin». В результате отобразится кодовый шифр для указанного числа. К примеру, для 100 это будет «1100100».

Чтобы понять, каким двоичным кодом отображаются буквы и слова, можно воспользоваться таблицей символов, которая также присутствует в каждой операционной системе Windows. Для этого вам нужно будет зайти в меню Пуск, после чего открыть стандартные программы и перейти в раздел «Служебные».
Там выберете символьную таблицу. Перед Вами откроется окно с различными знаками. При этом, Вы также можете выбрать стиль набора. Далее выделите один символ, и увидите его код в служебной строке…
Производные от битов бит и байтов
Как уже было сказано выше, в настоящий момент компьютеры обрабатывают невероятное количество информации, соответственно, использовать многомиллионные обозначения байтов не очень удобно. Именно поэтому, как и в математике, применяются различные приставки, значение которых известно многим со школьного курса. Хотя, в компьютерной системе есть свои особенности. В частности, 1 килобайт, это не 1000, а 1 024 байта.
Схема преобразований выглядит следующим образом:
- 1 килобайт – 1 024 байта.
- 1 мегабайт – 1 048 576 байтов.
- 1 гигабайт – 1 073 741 842 байта.
- 1 терабайт – 1 099 511 627 776 байтов.
Воспользовавшись этой таблицей Вы с лёгкостью сможете пересчитывать объёмы информации, хранящиеся на том или ином устройстве. Для наглядности, можно привести пример: один печатный лист формата А4 – это в среднем 100 килобайт, 1 фильм среднего качества – 1.5 гигабайта, фото среднего качества – 2 мегабайта.
Теперь Вы знаете, чем отличаются, а также, что измеряют Байты и Биты. До новых полезных компьютерных программ и интересных приложений для Андроид.
ПОЛЕЗНОЕ ВИДЕО
…
Рекомендую ещё посмотреть обзоры…
Я только обозреваю программы! Любые претензии — к их производителям!
Ссылки в комментариях публикуются после модерации.
^Наверх^
Обсуждение:Байт — Википедия
А кому нужна ссылка на йоттабайт? Gato 14:11, 27 февраля 2006 (UTC)
- энциклопедичность предполагает некоторую избыточность материала 🙂 К тому же, как я понимаю, приведен полный список десятичных и двоичных префиксов. «И это — правильно»©М.С. —jno 15:30, 27 февраля 2006 (UTC)
- Тогда я бы вынес список всех общеупотребимых единиц измерения в отдельную статью, заодно там можно привести оценки «плотности» для разных видов информации (текст, графика, видео, … ), оценки суточного трафика через сеть и все такое. А Йоттабайты никому не нужны. Пока еще только до терабайтов и петабайтов дошли.
Имхо здесь «избыточность» больше связана с гордостью автора за свою работу 🙂 Gato 08:53, 28 февраля 2006 (UTC)- Кто ж против статьи про единицы измерения? Однако, петабайты уже пройденный этап. Скажем, в России Транстелеком уже перешагнул петабайтный «рубеж» трафика. Так что, ежели какому журналисту потребуется новое слово, которое станет модным в ближайшие пару лет, то — вот оно! 🙂 Кстати, там, в Йоттабайте, есть интересная такая табличка… Вот ее бы вынести в статью, а все эти XXXбайты сделать редиректами туда. —jno 11:02, 28 февраля 2006 (UTC)
- Подумаю.
А табличку надо перерисовать. Кошмарный цвет. Кто, вообще, сказал, что нежно-лиловый — это красиво? Тогда уж надо было дополнить его цветом розовых зайчиков… 😉 Gato 12:22, 28 февраля 2006 (UTC)
- Подумаю.
- Кто ж против статьи про единицы измерения? Однако, петабайты уже пройденный этап. Скажем, в России Транстелеком уже перешагнул петабайтный «рубеж» трафика. Так что, ежели какому журналисту потребуется новое слово, которое станет модным в ближайшие пару лет, то — вот оно! 🙂 Кстати, там, в Йоттабайте, есть интересная такая табличка… Вот ее бы вынести в статью, а все эти XXXбайты сделать редиректами туда. —jno 11:02, 28 февраля 2006 (UTC)
- Тогда я бы вынес список всех общеупотребимых единиц измерения в отдельную статью, заодно там можно привести оценки «плотности» для разных видов информации (текст, графика, видео, … ), оценки суточного трафика через сеть и все такое. А Йоттабайты никому не нужны. Пока еще только до терабайтов и петабайтов дошли.
Кстати, а зачем нужна ссылка на Гугол ? К байту никакого отношения не имеет, даже косвенного… —Учаснег 14:45, 5 августа 2008 (UTC)
Не совсем понимаю таблицу[править код]
Не совсем понимаю таблицу. Например, «Название — килобайт, степень — 10^3». В статье четко сказано: «килобайт равен 1024 байтам». Тогда откуда такие данные в таблице? 91.144.150.167 08:36, 1 февраля 2008 (UTC)Al
статья не совсем корректно построена. Вначале говориться о байтах а потом рассуждается о примерах со словами разной длинны, хотя по логике надо говорить о байтах разной длинны. При этом же присутствует оговорка о том, что отождествлять слово и байт некорректно!
Сами предупреждаем сами нарушаем. надо быть более последовательными. 212.122.1.130 05:56, 8 февраля 2008 (UTC) Прохожий
2^0 — это не байт, а бит! байт — это 8 бит, т.е. 2^3 ? — разве не так? 81.28.5.18 16:48, 30 октября 2012 (UTC)
- Не так. Раздел про производные единицы от байтов, а не битов. 2^0=1 — это 1 (ОДИН) байт. — AVBtalk 17:36, 30 октября 2012 (UTC)
В Обозначении сами авторы не понимают что пишут:
«Межгосударственный (СНГ) стандарт ГОСТ 8.417-2002[1] («Единицы величин») в «Приложении А» для обозначения байта регламентирует использование русской заглавной буквы «Б». Кроме того, констатируется традиция использования приставок СИ вместе с наименованием «байт» для указания множителей, являющихся степенями двойки (1 Кбайт(кибибайт) = 1024 байт, 1 Мбайт(мебибайт) = 1024 Кбайт(кибибайт), 1 Гбайт(гибибайт) = 1024 Мбайт и т. д., причём вместо строчной «к» используется заглавная «К», которая означает не «кило-«, а «киби-«), и упоминается, что подобное использование приставок СИ не является корректным.»—212.93.100.25 18:56, 25 апреля 2013 (UTC)
В статье машинное слово его длина для БЭСМ-6 — 48 бит. Где правда? 85.141.4.194 16:31, 26 марта 2008 (UTC)kiolp
- Поправил это место. Vadim Rumyantsev 21:43, 12 октября 2008 (UTC)
Непонятна ЭТИМОЛОГИЯ слова «БАЙТ». ArkadiyVyatich 21:09, 13 октября 2008 (UTC)
- Это преднамеренное искажение слова «Bite» — англ. «укус», (чтобы не путать с «bit»). Несколько стоящих в ряд единиц напоминают след зубов при укусе. — Эта реплика добавлена с IP 80.70.233.97 (о) 13:00, 24 апреля 2017 (UTC)
В статье не сказано, как правильно склонять в родительном падеже мн. числа: «байт» или «байтов»? (то же относится к битам). Традиция словоупотребления (первый вариант) здесь, кажется, не согласуется с правилами русского языка (второй вариант). Melancholic 15:42, 13 марта 2009 (UTC)
- Цитирую, я сам вопрос про склонение раньше муссировал:
Согласно ответа Института русского языка имени В. В. Виноградова Российской Академии Наук байт, как и бит, склонять необходимо. —vlom 11:59, 9 июля 2008 (UTC)
- Я задал там уточняющий вопрос (про «16 килобайт») и получил следующий ответ: «По данным «Русского орфографического словаря» (М., 2005), кроме обычной формы родительного падежа — битов, байтов, килобайтов — существует счетная форма, которая используется в сочетании с числительными: 8 байт, 16 килобайт. Счетная форма является разговорной«. «Точно так же с килограммами. Обычная форма родительного падежа употребляется, если нет числительного, а в сочетании с числительным могут быть варианты: 16 килограммов (стилистически нейтральная обычная форма) и 16 килограмм (разговорная счетная форма)». — AVB 19:34, 12 июля 2008 (UTC)
- (К сожалению, я не сохранил ссылку на ответ). Можно эту информацию вставить в статью. — AVBtalk 01:53, 14 марта 2009 (UTC)
Статья неверна. На самом деле 1 кб = 1024 байт (2 в 10той степени)! и так далее. Возьмите калькулятор да посчитайте. 195.248.93.28 08:47, 31 июля 2009 (UTC)
sizeof(char) в с и с++ всегда тождественно 1. char — это минимальная эффективно адресуемая единица информации на целевой платформе, а вот размер всех остальных типов измеряется в char-ах. Если char будет 32 бита и для типа int этого будет достаточно, то sizeof(int) == sizeof(char) == 1 «в терминах языка С» (в котором так-то нельзя применить опретор == указанным образом, но это уже не по теме обсуждаемой неточности)
77.72.138.82 07:53, 18 ноября 2010 (UTC)
Статья некореткная!!! Написали бы нормально!!! Я так и не понял сколько бит 1 байт!!! Что за степени были нарысованы в таблице!!! 95.134.108.14 17:33, 12 февраля 2011 (UTC)НЕДОВОЛЬНЫЙ ЧИТАТЕЛЬ95.134.108.14 17:33, 12 февраля 2011 (UTC)
Уже много лет занимаюсь программированием и машинными кодами. И ни где, кроме этой статьи не видел, чтобы Байт(англ. Byte) был равен не 8-ми битам. Во всей документации, которую видел, приводятся следующие понятия:
Байт(Byte) -8 бит;
Слово(Word) -16 бит;
Двойное слово(DubleWord или DWord) -32 бит;
Четверное слово(QuadroWord или QWord) -64бит.
Двойное Четверное Слово (DQWord) -128бит
И эти цифры у всех программистов и научной литературе, как дважды два. А от куда автор взял другие цифры?
Отец Евгений 13:23, 22 февраля 2011 (UTC)
- Извините за избыточно личный вопрос, но Вы действительно занимаетесь программированием более сорока лет?
") Если нет, то обратите внимание например на PDP-8, или на PDP-10 — 8 бит в байте — это, как и изложено в статье, давний, крайне широко распространённый, но не единственный стандарт. Marlagram 00:26, 24 февраля 2011 (UTC)
Если нет, то обратите внимание например на PDP-8, или на PDP-10 — 8 бит в байте — это, как и изложено в статье, давний, крайне широко распространённый, но не единственный стандарт. Marlagram 00:26, 24 февраля 2011 (UTC) - Человек много лет занимающийся «программированием и машинными кодами» и при этом не читавший Кнута? Это не смешно, это грустно.77.37.205.84 17:11, 10 марта 2011 (UTC)
") Если нет, то обратите внимание например на PDP-8, или на PDP-10 — 8 бит в байте — это, как и изложено в статье, давний, крайне широко распространённый, но не единственный стандарт. Marlagram 00:26, 24 февраля 2011 (UTC)
Если нет, то обратите внимание например на PDP-8, или на PDP-10 — 8 бит в байте — это, как и изложено в статье, давний, крайне широко распространённый, но не единственный стандарт. Marlagram 00:26, 24 февраля 2011 (UTC)— Единицей памяти является байт, состоящий из восьми информационных и одного контрольного битов. Два смежных байта образуют слово.
"АССЕМБЛЕР И ПРОГРАММИРОВАНИЕ ДЛЯ IBM" ПИТЕР АБЕЛЬ (http://lib.ru/CTOTOR/IBMPC/abel.txt)
Возможно, стоит упомянуть о 9том байте, который используется для контроля четности?
upd: В статье имеется ввиду байт, как единица информации, а не байт в памяти. Вопрос снимаю.
А ка быть с «In the International System of Units (SI), B is the symbol of the bel, a unit of logarithmic power ratios named after Alexander Graham Bell. The usage of B for byte therefore conflicts with this definition. It is also not consistent with the SI convention that only units named after persons should be capitalized. However, there is little danger of confusion because the bel is a rarely used unit. It is used primarily in its decadic fraction, the decibel (dB), for signal strength and sound pressure level measurements, while a unit for one tenth of a byte, i.e. the decibyte, is never used.»? Ведь Б — это Белл…—212.93.100.50 20:04, 19 июля 2013 (UTC)
- Бел (bel) — это внесистемная величина! Бел —89.201.121.4 10:21, 15 июня 2017 (UTC)
Пожалуйста, проверьте следующие ссылки на внешние ресурсы:
- Ссылка заменена на рабочую. —VladVD (обс.) 17:13, 18 ноября 2016 (UTC)