Имя пользователя для входа в систему
Пробелы, двоеточия и кавычки не допускаются.
Это поле не может оставаться пустым.
Длина ограничивается 32 символами.
В регистрационном имени администратора длиной до 8 символов должны содержаться нецифровые символы (т.е. символы, не являющиеся числами). Если же оно состоит только из цифр, то его длина должна составлять не менее 9 символов.
Пароль для входа в систему
Максимально допустимая длина пароля для администраторов и супервайзера составляет 32 символа, тогда как для пользователей длина ограничивается 128 символами.
В отношении типов символов, которые могут использоваться для задания пароля, никаких ограничений не установлено. В целях безопасности рекомендуется создавать пароли, содержащие буквы верхнего и нижнего регистров, цифры и другие символы. Чем большее число символов используется в пароле, тем более трудной является задача его подбора для посторонних лиц.

В подразделе [Политика паролей] раздела [Расширенная безопасность] вы можете установить требование в отношении обязательного включения в пароль букв верхнего и нижнего регистров, цифр и других символов, а также минимально необходимое количество символов в пароле. Для получения сведений о формировании политики паролей см. Настройка функций расширенной безопасности.

Правда о регистре символов, которую должны знать программисты / Хабр
На
конференцииNorth Bay Python в 2018 году я делал
докладоб именах пользователей. Информация из доклада по большей части была собрана мною за 12 лет поддержки
. Этот опыт дал мне гораздо больше знаний, чем я планировал получить, о том, насколько сложными могут быть «простые» вещи.
В начале доклада я, правда, упомянул, что это не будет очередное разоблачение из серии «заблуждения по поводу Х, в которые верят программисты». Таких разоблачений можно найти сколько угодно. Однако мне подобные статьи не нравятся. В них перечисляются разные вещи, якобы являющиеся ложными, однако очень редко объясняется – почему это так, и что нужно делать вместо этого. Подозреваю, что люди просто прочтут такие статьи, поздравят себя с этим достижением, и потом пойдут находить новые интересные способы делать ошибки, не упомянутые в этих статьях. Всё потому, что они на самом деле не поняли проблем, порождающих этих ошибки.
Однако мне подобные статьи не нравятся. В них перечисляются разные вещи, якобы являющиеся ложными, однако очень редко объясняется – почему это так, и что нужно делать вместо этого. Подозреваю, что люди просто прочтут такие статьи, поздравят себя с этим достижением, и потом пойдут находить новые интересные способы делать ошибки, не упомянутые в этих статьях. Всё потому, что они на самом деле не поняли проблем, порождающих этих ошибки.
Поэтому в своём докладе я постарался как можно лучше объяснить некоторые проблемы и пояснить, как их решать – такой подход мне нравится гораздо больше. Одна из тем, которой я коснулся лишь вскользь (это был всего один слайд и пара упоминаний на других слайдах) – это сложности, которые могут быть связаны с регистром символов. Для задачи, которую я обсуждал – сравнение идентификаторов без учёта регистра – есть официальный Правильный Ответ™, и в докладе я дал лучшее из известных мне решений, использующее только стандартную библиотеку Python.
Однако я кратко упомянул о более глубоких сложностях с регистром символов в Unicode, и хочу посвятить некоторое время описанию подробностей. Это интересно, и понимание этого может помочь вам принимать решения при проектировании и написании кода, обрабатывающего текст. Поэтому предлагаю вам нечто противоположное статьям «заблуждения по поводу Х, в которые верят программисты» – «правда, которую должны знать программисты».
Это интересно, и понимание этого может помочь вам принимать решения при проектировании и написании кода, обрабатывающего текст. Поэтому предлагаю вам нечто противоположное статьям «заблуждения по поводу Х, в которые верят программисты» – «правда, которую должны знать программисты».
И ещё одно: в Unicode полно терминологии. В данной статье я буду использовать в основном определения «верхний регистр» и «нижний регистр», поскольку стандарт Unicode использует эти термины. Если вам нравятся другие термины, вроде строчная/прописная буквы – всё нормально. Также я часто буду использовать термин «символ», который некоторые могут счесть некорректным. Да, в Unicode концепция «символа» не всегда совпадает с ожиданиями людей, поэтому часто лучше избегать её, используя другие термины. Однако в данной статье я буду использовать этот термин так, как он используется в Unicode – для описания абстрактной сущности, о которой можно делать заявления. Когда это важно, для уточнения я буду использовать более конкретные термины типа «кодовой позиции» [code point].
Регистров бывает больше двух
Носители европейских языков привыкли к тому, что в их языках регистр символов используется для обозначения конкретных вещей. К примеру, в английском [и русском] языках мы обычно начинаем предложения с буквы в верхнем регистре, а продолжаем чаще всего буквами в нижнем регистре. Также имена собственные начинаются с букв в верхнем регистре, и многие акронимы и аббревиатуры записываются в верхнем регистре.
И мы обычно считаем, что регистров существует всего два. Есть буква «А», и есть буква «а». Одна в верхнем, другая в нижнем регистре – не правда ли?
Однако в Unicode есть три регистра. Есть верхний, есть нижний, и есть титульный регистр [titlecase]. В английском языке так записываются названия. Например, «Avengers: Infinity War». Обычно для этого первая буква каждого слова просто пишется в верхнем регистре (и в зависимости от разных правил и стилей, некоторые слова, например, артикли, не пишутся с заглавных букв).
В стандарте Unicode дан такой пример символа в титульном регистре: U+01F2 LATIN CAPITAL LETTER D WITH SMALL Z. Выглядит он так: Dz.
Выглядит он так: Dz.
Подобные символы иногда требуются для обработки негативных последствий одного из ранних решений разработки стандарта Unicode: совместимости с существующими текстовыми кодировками в обе стороны. Для Unicode было бы удобнее составлять последовательности при помощи имеющихся у стандарта возможностей по комбинированию символов. Однако во многих уже существующих системах уже были отведены места для готовых последовательностей. К примеру, в стандарте ISO-8859-1 («latin-1») у символа «é» есть готовая форма, имеющая номер 0xe9. В Unicode предпочтительнее было бы писать эту букву при помощи отдельной «е» и знака ударения. Но для обеспечения полной совместимости в обе стороны с такими существующими кодировками, как latin-1, в Unicode также назначены кодовые позиции для готовых символов. К примеру, U+00E9 LATIN SMALL LETTER E WITH ACUTE.
Хотя кодовая позиция этого символа совпадает с его байтовым значением из latin-1, полагаться на это не стоит. Вряд ли кодирование символов в Unicode сохранит эти позиции.
И, конечно, в уже существующих кодировках есть символы, которым требовалось особое обхождение при использовании титульного регистра, из-за чего они были включены в Unicode «как есть». Если хотите посмотреть на них, поищите в своей любимой базе Unicode символы из категории Lt («Letter, titlecase»).
Есть несколько способов определить регистр
В стандарте Unicode (§4.2) перечислено три разных определения регистра. Возможно, выбор одного из трёх за вас делает ваш язык программирования; в противном случае, ваш выбор будет зависеть от конкретной цели. Вот эти определения:
- Символ находится в верхнем регистре, если он принадлежит к категории Lu («Letter, uppercase»), и в нижнем регистре, если принадлежит к категории Ll («Letter, lowercase»). В стандарте признаётся ограниченность этого определения: каждый конкретный символ приходится относить только к одной из категорий. Из-за этого многие символы, которые «должны находиться» в верхнем или нижнем регистре не удовлетворят этому требованию потому, что принадлежат к какой-то другой категории.
- Символ находится в верхнем регистре, если он унаследовал свойство Uppercase, и в нижнем регистре, если унаследовал свойство Lowercase. Это комбинация определения один с другими свойствами символов, среди которых может быть и регистр.
- Символ находится в верхнем регистре, если после применения к нему регистрового отображения в верхний регистр он не меняется. Символ находится в нижнем регистре, если после применения к нему регистрового отображения в нижний регистр он не меняется. Довольно общее определение, однако и оно может вести себя неинутитивно.
 Из-за этого многие символы, которые «должны находиться» в верхнем или нижнем регистре не удовлетворят этому требованию потому, что принадлежат к какой-то другой категории.
Из-за этого многие символы, которые «должны находиться» в верхнем или нижнем регистре не удовлетворят этому требованию потому, что принадлежат к какой-то другой категории.Если вы работаете с ограниченным подмножеством символов (конкретно, с буквами), то вам может хватить и 1-го определения. Если ваш репертуар шире – в него входят похожие на буквы символы, не являющиеся буквами, вам может подойти 2-е определение.
Программистам, манипулирующим строками в Unicode, стоит работать с такими строковыми функциями, как isLowerCase (и её функциональным родственником toLowerCase), если они не работают со свойствами символов напрямую.
Упомянутая здесь функция определяется в §3.13 стандарта Unicode. Формально в 3-м определении используются функции isLowerCase и isUpperCase из §3.13, определяемые в терминах фиксированных позиций в toLowerCase и toUpperCase соответственно.
Если в вашем языке программирования есть функции для проверки или преобразования регистра строк или отдельных символов, стоит изучить, какие из упомянутых определений используются в реализации. Если вам интересно, то методы isupper() и islower() в Python используют 2-е определение.
Нельзя понять регистр символа по его внешнему виду или названию
По внешнему виду многих символов можно понять, в каком они регистре. К примеру, «А» находится в верхнем регистре. Это понятно и по названию символа: «LATIN CAPITAL LETTER A». Однако иногда такой метод не работает. Возьмём кодовую позицию U+1D34. Выглядит она так: ᴴ. В Unicode ей назначено имя: MODIFIER LETTER CAPITAL H. Значит, она в верхнем регистре, так?
Это понятно и по названию символа: «LATIN CAPITAL LETTER A». Однако иногда такой метод не работает. Возьмём кодовую позицию U+1D34. Выглядит она так: ᴴ. В Unicode ей назначено имя: MODIFIER LETTER CAPITAL H. Значит, она в верхнем регистре, так?
На самом же деле она наследует свойство Lowercase, поэтому по определению №2 она находится в нижнем регистре, несмотря на то, что визуально напоминает заглавную Н, а в названии есть слово «CAPITAL».
У некоторых символов вообще нет регистра
Определение 135 в §3.13 стандарта Unicode гласит:
Символ С имеет регистр тогда и только тогда, когда у С есть свойство Lowercase или Uppercase, или значение параметра General_Category равно Titlecase_Letter.
Значит, очень много символов из Unicode – на самом деле, большая их часть – регистра не имеет. Не имеют смысла вопросы об их регистре, а изменения регистра на них не действуют. Однако мы можем получить ответ на этот вопрос по определению №3.
Некоторые символы ведут себя так, будто у них несколько регистров
Из этого следует, что если вы используете определение №3, и задаёте вопрос, находится ли символ без регистра в верхнем или нижнем регистре, вы получите ответ «да».
В стандарте Unicode даётся пример (таблица 4-1, строка 7) символа U+02BD MODIFIER LETTER REVERSED COMMA (который выглядит так: ʽ). У него нет унаследованных свойств Lowercase или Uppercase, он не принадлежит к категории Lt, поэтому регистра у него нет. При этом преобразование в верхний регистр его не меняет, и преобразование в нижний регистр его не меняет, поэтому по 3-му определению он отвечает «да» на оба вопроса: «принадлежишь ли ты к верхнему регистру?» и «принадлежишь ли ты к нижнему регистру?»
Кажется, что из-за этого может возникнуть никому не нужная путаница, однако смысл в том, что определение №3 работает с любой последовательностью символов Unicode, и позволяет упростить алгоритмы преобразования регистра (символы без регистра просто превращаются сами в себя).
Регистр зависит от контекста
Можно подумать, что если таблицы преобразования регистра в Unicode покрывают все символы, то это преобразование заключается просто в поиске нужного места в таблице. К примеру, в базе данных Unicode записано, что для символа U+0041 LATIN CAPITAL LETTER A нижним регистром будет U+0061 LATIN SMALL LETTER A. Просто, не так ли?
К примеру, в базе данных Unicode записано, что для символа U+0041 LATIN CAPITAL LETTER A нижним регистром будет U+0061 LATIN SMALL LETTER A. Просто, не так ли?
Один из примеров, в котором этот подход не работает – греческий язык. Символ Σ — то есть, U+03A3 GREEK CAPITAL LETTER SIGMA — сопоставлен двум разным символам при преобразовании в нижний регистр, в зависимости от того, где он находится в слове. Если он стоит на конце слова, тогда в нижнем регистре он будет ς (U+03C2 GREEK SMALL LETTER FINAL SIGMA). В любом другом месте это будет σ (U+03C3 GREEK SMALL LETTER SIGMA).
А это значит, что у регистра нет взаимной однозначности или транзитивности. Ещё один пример — ß (U+00DF LATIN SMALL LETTER SHARP S, или эсцет). В верхнем регистре это будет «SS», хотя теперь существует и другая его форма в верхнем регистре (ẞ, U+1E9E LATIN CAPITAL LETTER SHARP S). А при переводе «SS» в нижний регистр получается «ss», поэтому (используя терминологию стандарта Unicode для преобразования регистра): toLowerCase(toUpperCase(ß)) != ß.
Регистр зависит от локали
В разных языках правила преобразования регистра разные. Самый популярный пример: i (U+0069 LATIN SMALL LETTER I) и I (U+0049 LATIN CAPITAL LETTER I) в большинстве локалей преобразовываются друг в друга – в большинстве, но не во всех. В локалях az и tr (тюркские языки), i в верхнем регистре будет İ (U+0130 LATIN CAPITAL LETTER I WITH DOT ABOVE), а I в нижнем регистре будет ı (U+0131 LATIN SMALL LETTER DOTLESS I). Иногда правильная запись реально означает разницу между жизнью и смертью.
Сам Unicode не обрабатывает все возможные правила преобразования регистра для всех локалей. В базе данных Unicode есть только общие правила преобразования всех символов, не зависящие от локали. Также там есть особые правила для некоторых языков и составных форм – литовского языка, тюркских языков, некоторых особенностей греческого. Всего остального там нет. §3.13 стандарта упоминает это и рекомендует при необходимости вводить правила преобразования, зависящие от локали.
Один пример будет знаком англоговорящим – это титульный регистр определённых имён. «o’brian» нужно преобразовывать в «O’Brian» (а не в «O’brian»). Однако при этом «it’s» нужно преобразовывать в «It’s», а не в «It’S». Ещё один пример, который не обрабатывается в Unicode – это голландское буквосочетание «ij», которое при преобразовании в титульный регистр должно переходить в верхний регистр целиком, если стоит в начале слова. Таким образом, большой залив в Нидерландах в титульном регистре будет «IJsselmeer», а не «Ijsselmeer». В Unicode есть символы IJ U+0132 LATIN CAPITAL LIGATURE IJ и ij U+0133 LATIN SMALL LIGATURE IJ, если они вам нужны. По умолчанию преобразование регистра преобразует их друг в друга (хотя формы нормализации Unicode, использующие эквивалентность совместимости, разделят их на два отдельных символа).
Сравнение без учёта регистра требует приведения к сложенному регистру
Возвращаясь к материалу, представленному в докладе. Сложность работы с регистром в Unicode означает, что регистронезависимое сравнение нельзя проводить при помощи стандартных функций приведения к нижнему или верхнему регистру, имеющихся во многих языках программирования. Для таких сравнений в Unicode есть концепция приведения к сложенному регистру [case folding], а в §3.13 стандарта определяются функции toCaseFold и isCaseFolded.
Для таких сравнений в Unicode есть концепция приведения к сложенному регистру [case folding], а в §3.13 стандарта определяются функции toCaseFold и isCaseFolded.
Можно решить, что приведение к сложенному регистру похоже на приведение к нижнему регистру – но это не так. Стандарт Unicode предупреждает, что строка в сложенном регистре не обязательно будет находиться в нижнем регистре. В качестве примера приводится язык чероки – там в строке, находящейся в сложенном регистре, будут попадаться и символы в верхнем регистре.
На одном из слайдов моего доклада рекомендации Unicode Technical Report #36 реализуются на Python настолько полно, насколько это возможно. Проводится нормализация NFKC и потом для полученной строки вызывается метод casefold() (доступный только в Python 3+). И даже при этом некоторые крайние случаи выпадают, и это не совсем то, что рекомендуется для сравнения идентификаторов. Сначала плохие новости: Python не выдаёт наружу достаточно свойств Unicode для того, чтобы отфильтровать символы, которых нет в XID_Start или XID_Continue или символы, имеющие свойство Default_Ignorable_Code_Point. Насколько мне известно, он не поддерживает отображение NFKC_Casefold. Также в нём нет простого способа использовать модифицированный NFKC UAX #31§5.1.
Насколько мне известно, он не поддерживает отображение NFKC_Casefold. Также в нём нет простого способа использовать модифицированный NFKC UAX #31§5.1.
Хорошие новости: большинство этих крайних случаев не связано с какими-либо реальными рисками безопасности, создаваемыми рассматриваемыми символами. И складывание регистра в принципе не определяется как операция, сохраняющая нормализацию (отсюда и отображение NFKC_Casefold, которое повторно нормализуется до NFC после складывания регистра). Как правило, при сравнении вас не волнует, будут ли обе строки нормализованы после предварительной обработки. Вас заботит, не противоречива ли предварительная обработка, и гарантирует ли она, что только строки, которые «должны» отличаться впоследствии, будут отличаться впоследствии. Если вас это беспокоит, вы можете вручную выполнить повторную нормализацию после сложения регистра.
Пока достаточно
Эта статья, как и предыдущий доклад, не является исчерпывающей, и вряд ли можно уложить весь этот материал в единственный пост. Надеюсь, что это был полезный обзор сложностей, связанных с этой темой, и вы найдёте в нём достаточно отправных точек для того, чтобы искать дальнейшую информацию. Поэтому в принципе, можно остановиться и тут.
Надеюсь, что это был полезный обзор сложностей, связанных с этой темой, и вы найдёте в нём достаточно отправных точек для того, чтобы искать дальнейшую информацию. Поэтому в принципе, можно остановиться и тут.
Не будет ли наивной моя надежда на то, что другие люди перестанут писать разоблачения из серии «заблуждения по поводу Х, в которые верят программисты», и начнут уже писать статьи типа «правда, которую должны знать программисты»?
Основные операции | OKI
Ввод символов с помощью сенсорной панели
Если необходимо ввести символы во время настройки элемента, отображается следующий экран ввода.
Можно вводить буквы верхнего и нижнего регистра, числа и символы.
Сведения об экране ввода
Количество кнопок на экране ввода различается в зависимости от вида ввода.
|
Элемент |
Описание |
|
|---|---|---|
|
1 |
Поле ввода текста |
Отображение введенных символов. |
|
2 |
Количество введенных символов/максимально допустимое количество символов для ввода |
Указывает максимально допустимое количество символов для ввода и количество введенных символов. |
|
3 |
Кнопка «Забой» |
Удаление символа, стоящего перед курсором. |
|
4 |
Панель символов |
Ввод символов. Тип символов переключается в зависимости от режима ввода. |
|
5 |
Кнопка «Влево»/кнопка «Вправо» |
Перемещение курсора влево и вправо. |
|
6 |
Фиксация регистра прописных букв |
Переключение между символами верхнего и нижнего регистров. |
|
7 |
Кнопка режима ввода |
Переключение режима ввода текста (типы символов). |

Заметка
Стандартную клавиатуру, установленную по умолчанию, можно изменить на клавиатуру с европейским расположением клавиш. Для установки клавиатуры с европейским расположением клавиш выберите на сенсорной панели [Manage Unit (Управление)] > [Keyboard Layout (Раскладка клавиатуры)] > [AZERTY (Клавиатура с европейским расположением клавиш)].
Для установки клавиатуры с европейским расположением клавиш выберите на сенсорной панели [Manage Unit (Управление)] > [Keyboard Layout (Раскладка клавиатуры)] > [AZERTY (Клавиатура с европейским расположением клавиш)].
Ввод символов
-
Нажмите сенсорную панель.
-
Когда ввод будет завершен, нажмите [ОК] или [Далее].
Заметка
Для ввода диакритического знака нажмите и удерживайте кнопку с отображающимся символом […]. После появления диакритического знака нажмите нужный символ.
На показанном ниже экране изображение отображается при нажатии и удерживании кнопки «а».
Переключение режима ввода (числа буквенные символы)
-
Нажмите [Буква] или [Символ].

Заметка
При использовании русского языка отображается [RU], при использовании греческого языка отображается [EL]. При использовании других языков могут отображаться только параметры [Буква] и [Символы].
Переключение режима ввода (верхний регистр нижний регистр)
-
Нажмите кнопку для переключения между символами верхнего и нижнего регистров.
Удаление введенного символа
Ввод с помощью цифровой клавиатуры
Можно вводить цифры, обозначенные на каждой кнопке.
Примечание
Не удалось ввести букву алфавита.
Введите букву алфавита с помощью сенсорной панели.
Символы верхнего и нижнего регистра не повышают безопасность пароля
Глазго, 23 октября. Шотландские ученые из Университета Глазго вместе со специалистами по информационной безопасности из лаборатории Symantec выяснили, что использование символов верхнего и нижнего регистров не так уж эффективно в защитите от взлома. Об этом сообщает научно-популярное развлекательное издание N+1 со ссылкой на публикацию результатов анализа в сборнике ACM CSS 2015. По результатам исследования, большую устойчивость показало банальное удлинение пароля.
Шотландские ученые из Университета Глазго вместе со специалистами по информационной безопасности из лаборатории Symantec выяснили, что использование символов верхнего и нижнего регистров не так уж эффективно в защитите от взлома. Об этом сообщает научно-популярное развлекательное издание N+1 со ссылкой на публикацию результатов анализа в сборнике ACM CSS 2015. По результатам исследования, большую устойчивость показало банальное удлинение пароля.
Специалисты использовали для атаки интеллектуальные алгоритмы, обученные на данных десятимиллионной базы паролей. После была проверена эффективность алгоритмов на 32 миллионах других паролей.
Использовались три метода атак: N-грамм, вероятностная контекстно-свободная грамматика, экспоненциальная выдержка. Наибольшую эффективность показал третий метод. Суть этого алгоритма заключается в правильном подборе частоты некоторого процесса с помощью проверок, расстояние между которыми растет экспоненциально (скорость роста пропорциональна значению самой величины).
На основании исследований авторы предложили новую шкалу сложности паролей. Наиболее действенным способом обеспечить безопасность стал самый простой – увеличение числа символов в пароле. Программисты советуют сделать набор символом менее предсказуемым.
На многих сайтах рекомендуют (а некоторые даже требуют) введение в пароль символов верхнего и нижнего регистров – заглавных и прописных букв кириллицы или латиницы. Анализ показал, что пользователи обычно вводят заглавные буквы в начале пароля и цифры в конце, что облегчает работу алгоритма и в несколько раз ускоряет взлом.
Изменение регистра текста в Pages на Mac
В Pages можно также настроить автоматическое начало предложений с заглавной буквы. Можно также быстро перевести выбранный текст в верхний или нижний регистр, а также задать формат, в котором каждое слово начинается с заглавной буквы.
Автоматическое начало предложений с заглавной буквы
Выберите «Pages» > «Настройки» (меню «Pages» расположено у верхнего края экрана).
Нажмите «Автокоррекция» вверху окна настроек.
В разделе «Правописание» установите флажок «Автоматически писать слова с заглавной буквы».
Эта настройка применяется только к Pages и не применяется к другим приложениям на Mac.
Изменение регистра
Выберите текст, который нужно изменить, или нажмите там, где собираетесь вводить новый текст.
Чтобы изменить весь текст в текстовом блоке или ячейке таблицы, выберите этот текстовый блок или ячейку таблицы.
Вверху боковой панели «Формат» нажмите кнопку «Стиль».
Если текст расположен в текстовом блоке, таблице или фигуре, сначала нажмите вкладку «Текст» в верхней части боковой панели, затем кнопку «Стиль».
В разделе «Шрифт» нажмите , затем нажмите всплывающее меню «Прописные» и выберите один из вариантов.
Нет. Текст остается без изменений в том виде, как Вы его ввели.
Все прописные. Все буквы текста становятся прописными одинаковой высоты.
Малые прописные. Все буквы делаются прописными, причем буквы нижнего и верхнего регистра имеют разную высоту.
Для заголовков (англ. формат). Первая буква каждого слова — прописная (кроме предлогов, артиклей, союзов). Например, Семь Чудес Света.
Каждое слово с прописной. Первая буква каждого слова — прописная. Например, Семь Чудес Света.
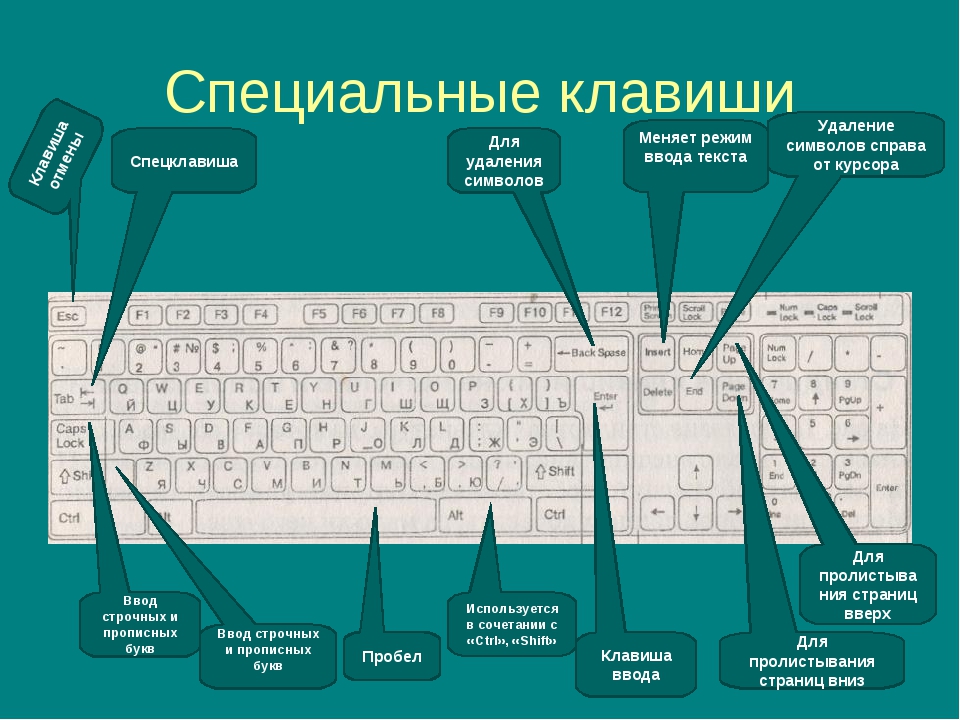
Как понять символ верхнего регистра
При первом знакомстве с клавиатурой у начинающих пользователей нередко возникает следующий вопрос: «Что такое верхний и нижний регистр на клавиатуре?» Оказывается, все очень просто. Верхний регистр означает, что в данный момент времени с клавиатуры вводятся заглавные буквы, а нижний, соответственно, – строчные. То есть каждое предложение начинается с большой буквы. Для этого используем верхний регистр. Остальная часть предложения – это «маленькие» буквы, то есть применяется нижний регистр. Это и есть ответ на вопрос о том, что такое верхний и нижний регистр на клавиатуре. Существуют различные способы перехода между этими режимами ввода, которые далее будут рассмотрены.
То есть каждое предложение начинается с большой буквы. Для этого используем верхний регистр. Остальная часть предложения – это «маленькие» буквы, то есть применяется нижний регистр. Это и есть ответ на вопрос о том, что такое верхний и нижний регистр на клавиатуре. Существуют различные способы перехода между этими режимами ввода, которые далее будут рассмотрены.
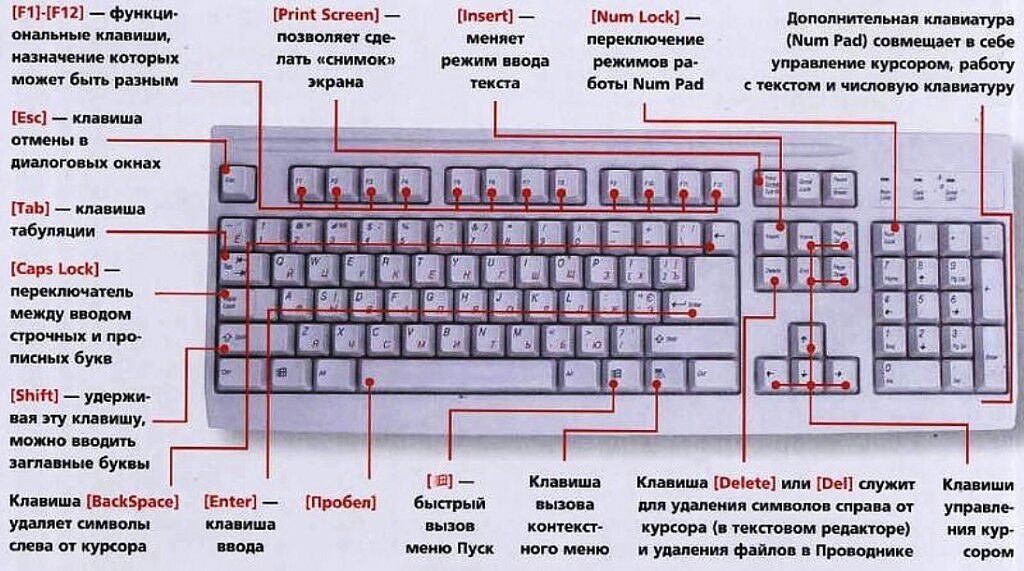
Кратковременное переключение
Теперь мы знаем, что такое верхний и нижний регистр на клавиатуре. Разберемся с основными способами переключения между «большими» и «маленькими» буквами. Существует кратковременное и постоянное переключение. Еще один способ программно реализован в офисном обеспечении. Он также будет рассмотрен в рамках данного материала. Начнем с кратковременного. На каждой компьютерной клавиатуре есть клавиша «Shift» (на некоторых из них вместо надписи может быть изображена стрелочка вверх). Если в данный момент времени вводятся заглавные буквы, то при нажатии этой клавиши в сочетании с любым текстовым символом появиться он в нижнем регистре, и наоборот. Этот способ удобно использовать в начале предложения. То есть ввели прописной символ, а затем все набирается уже в строчном формате.
Этот способ удобно использовать в начале предложения. То есть ввели прописной символ, а затем все набирается уже в строчном формате.
Длительный набор
Верхний и нижний регистр клавиатуры могут быть переключены и другим методом. Для этих целей есть специальный ключ «Caps Lock». Он обычно расположен в крайнем левом ряду клавиатуры между клавишами «Tab» и «Shift». При его нажатии происходит постоянная смена регистра. Для определения текущего режима смотрим на светодиод на клавиатуре с точно такой же надписью – «Caps Lock». Если он горит, то это означает, что вводятся заглавные буквы, иначе – строчные. Для перехода из одного режима в другой нажимаем этот ключ еще раз. Этот способ лучше всего применять тогда, когда необходимо постоянно набирать текст в одном формате (например, только прописные символы), а переключение между форматом ввода если и происходит, то не настолько часто.
Для офисных приложений
Еще один способ изменения заглавных и прописных символов реализован в офисном пакете компании «Microsoft». Наиболее часто его используют в текстовом процессоре «Ворд». В процессе ввода вы забыли случайно перейти с больших букв к маленьким или наоборот? Символы верхнего и нижнего регистров в данном случаем можно изменить следующим образом. Выделяем необходимый фрагмент текста либо с помощью левой кнопки мышки, либо с применением «Shift» и клавиш управления курсором. Далее в панели инструментов «Главная» находим подраздел «Шрифт». В нем есть кнопка для смены регистра. На ней изображены большая и маленькая буквы «а». Кликаем на ней левой кнопкой мышки один раз. Выпадет меню, в котором нужно выбрать нужный нам пункт. Например, если ввели прописные, а нужны строчные, то выбираем пункты «Изменить регистр» или «Все строчные». Независимо от выбора результат будет идентичный – все буквы в выделенном фрагменте станут «маленькими». Этот метод можно использовать только в офисном пакете компании «Микрософт», и только на тексте, который введен в компьютер.
Наиболее часто его используют в текстовом процессоре «Ворд». В процессе ввода вы забыли случайно перейти с больших букв к маленьким или наоборот? Символы верхнего и нижнего регистров в данном случаем можно изменить следующим образом. Выделяем необходимый фрагмент текста либо с помощью левой кнопки мышки, либо с применением «Shift» и клавиш управления курсором. Далее в панели инструментов «Главная» находим подраздел «Шрифт». В нем есть кнопка для смены регистра. На ней изображены большая и маленькая буквы «а». Кликаем на ней левой кнопкой мышки один раз. Выпадет меню, в котором нужно выбрать нужный нам пункт. Например, если ввели прописные, а нужны строчные, то выбираем пункты «Изменить регистр» или «Все строчные». Независимо от выбора результат будет идентичный – все буквы в выделенном фрагменте станут «маленькими». Этот метод можно использовать только в офисном пакете компании «Микрософт», и только на тексте, который введен в компьютер.
Итоги
В рамках данной статьи дан ответ на вопрос о том, что такое верхний и нижний регистр на клавиатуре. Также приведены основные способы переключения между заглавными и прописными символами. Одним, строго определенным способом пользоваться не рекомендуется – это снизит существенно продуктивность работы. Лучше всего их комбинировать и, в зависимости от ситуации, использовать тот или иной.
Также приведены основные способы переключения между заглавными и прописными символами. Одним, строго определенным способом пользоваться не рекомендуется – это снизит существенно продуктивность работы. Лучше всего их комбинировать и, в зависимости от ситуации, использовать тот или иной.
Первое, что попадает в руки пользователя компьютерной техникой – это клавиатура и мышка. Умение использовать различные функции с помощью этих атрибутов, позволяют быстро решать поставленные задачи. Если спросить новичка о том, что такое верхний регистр, то он, возможно, укажет на клавиши, расположенные вверху. На самом деле – это далеко не так.
Что такое верхний и нижний регистр на клавиатуре
Эти понятия дошли до нас со времён печатных машинок. При наборе текстов, обычный шрифт написания выполняли в стандартном положении оборудования, которое называли нижним, а заглавные буквы наносились на бумагу при изменении положения печатных штанг, путём перевода их в верхнее положение. Именно подобной функцией наделены клавиатуры современных мобильных и стационарных печатных устройств.
С помощью кнопки функционального перевода «Shift» из одного режима в другой, пользователь ПК может переходить на прописные или заглавные буквы при написании текстов, в зависимости от требований к содержанию. Цифры при этом обозначают знаки препинания или другую символику, которую используют при распечатке документов. Иными словами, верхний регистр – это такой режим печати, в котором буквы становятся заглавными, а цифры меняются на символы. Нижний – это обычное изображение цифровых и буквенных обозначений.
Где находится верхний регистр
Две клавиши перевода из одного режима печати в другой расположены на клавиатуре: одна слева внизу, а другая справа – тоже в нижней части. Это сделано для удобства быстрого набора текстов. Если буква, которую нужно написать заглавной находится справа, то используют левую сторону. При переходе нажимают одновременно, сначала «Shift», а затем требуемый знак. А при расположении нужного символа слева – наоборот. Если пользователю удобно одной рукой нажимать обе клавиши, то он делает именно так, например, чтобы отобразить запятую!
Если пользователю удобно одной рукой нажимать обе клавиши, то он делает именно так, например, чтобы отобразить запятую!
ВНИМАНИЕ! Клавиатура некоторых мобильных устройств может иметь только одну клавишу «Shift». Это связано с компактностью размеров оргтехники.
Удобство применения верхнего режима позволяет быстро переключить функцию нужного символа из одного положения – в другое. Кроме того, слева, над кнопкой «Shift» расположена клавиша с надписью «Caps Lock», которая имеет такое же функциональное назначение, но другой принцип работы.
Способы переключения регистра на клавиатуре
При наборе текстов используют два режима переключения:
Первый из перечисленных способов переключает клавиатуру только в момент нажатия на клавишу «Shift». Как только пользователь её отпускает, печать продолжается в обычном режиме – прописными буквами.
Второй способ позволяет, после нажатия кнопки «Caps Lock», перейти в верхний регистр и печатать заглавные буквы до тех пор, пока не отпадёт необходимость в использовании таковых. Отдельный индикатор клавиатуры загорается при включении такого режима и гаснет только при повторном нажатии указанной клавиши, что подтверждает переход на прописные обозначения.
Отдельный индикатор клавиатуры загорается при включении такого режима и гаснет только при повторном нажатии указанной клавиши, что подтверждает переход на прописные обозначения.
ВАЖНО! При включении «Caps Lock», использование кнопки «Shift» будет иметь противоположное действие: при нажатии – обычные символы, а после отпускания – заглавные буквы.
Длительный режим используют при написании заголовков или выделения названий статей.
Наличие навыков быстрого перехода из одного регистра в другой, позволяет пользователям ПК с удобством набирать требуемые тексты, быстро вставляя необходимые символы и заглавные буквы.
Чувствительность к регистру символов (англ. case sensitivity ) — особенность некоторых файловых систем, программ и языков программирования, состоящая в том, что если одинаковые имена отличаются регистром хотя бы одного символа (то есть заглавными или строчными буквами), то эти имена считаются разными. Например, слово «TEXT» и слово «Text» в программе, чувствительной к регистру символов — абсолютно разные слова. Файлы «Photo.jpg», «photo.jpg» и «photo.JPG» в файловой системе, чувствительной к регистру — три совершенно разных файла, которые могут одновременно находиться в одной папке.
Например, слово «TEXT» и слово «Text» в программе, чувствительной к регистру символов — абсолютно разные слова. Файлы «Photo.jpg», «photo.jpg» и «photo.JPG» в файловой системе, чувствительной к регистру — три совершенно разных файла, которые могут одновременно находиться в одной папке.
| С чувствительностью к регистру | Нечувствительны к регистру | |
|---|---|---|
| Языки программирования | Семейство Си (C, C++, Java, C# и так далее), Perl, PHP, Python, Lua | BASIC, Fortran, LISP, Pascal, SQL, большинство ассемблеров |
| Языки разметки | TeX, XML | HTML |
| Файловые системы | Файловые системы семейства Unix (UFS, ext2, ext3, ext4, XFS, ZFS и так далее) | Семейство FAT Файловые системы HFS+ и NTFS теоретически чувствительны к регистру, но эта возможность либо по умолчанию отключена (HFS+), либо недоступна через обычные API операционной системы (NTFS) [1] [2] |
| Прочее | Пароли (в большинстве случаев) | Доменные имена (базовые адреса сайтов; URL-пути и параметры чувствительны к регистру) |
Содержание
Преимущества чувствительности [ править | править код ]
- Программе не требуется преобразовывать регистр символов (что на локалях, отличных от обычной «американской», может быть нетривиальной задачей).
- Появляется больше средств выражения: например, на C++ можно написать Object object; (первое — тип, второе — название переменной).
Преимущества нечувствительности [ править | править код ]
- Удобно, когда нет жёстких норм именования и каких-либо средств помощи наподобие автодополнения.
- Распространено на старых (до начала 80-х годов) компьютерах, где бывают некачественные клавиатуры, а то и вообще нет строчных букв в кодовой таблице.
Чувствительность к регистру в человеческом языке [ править | править код ]
В человеческих языках, чувствительность к регистру возникает в ситуациях, когда аббревиатура, географическое название, имя человека или иное слово, которое принято писать с заглавными буквами, имеет другое значение в строчном регистре. Пример: (композитор) Лист и (кленовый) лист. Чувствительность к регистру присутствует в системе приставок СИ: «М» обозначает мега-, а «м» — милли-.
Чтобы избежать путаницы между сокращениями слов «байт» и «бит», последнее обычно не сокращают (например, гигабит = Гбит), или сокращают до строчной буквы б, а байт — до прописной Б (гигабайт = ГБ, или ГиБ, для двоичной системы приставок). Примечательно, что во французском языке вместо термина «байт» используется термин «октет» (фр. octet ), поэтому подобной путаницы не возникает.
Примечательно, что во французском языке вместо термина «байт» используется термин «октет» (фр. octet ), поэтому подобной путаницы не возникает.
У компьютерных программ, имеющих функцию поиска по тексту, для удобства обычно имеется параметр «учитывать регистр» или «игнорировать регистр».
Функция LCase — Access
Возвращает значение типа String, преобразованное в символы нижнего регистра
Синтаксис
LCase (string)
Обязательный Аргументстрока — это любое допустимое строковое выражение. Если строка содержит значение NULL, возвращается NULL.
Если строка содержит значение NULL, возвращается NULL.
Замечания
В нижний регистр преобразуются только буквы верхнего регистра; Все буквы нижнего регистра и символы, не вменжательные, остаются без изменений.
Пример запроса
Выражение | Результаты: |
|---|---|
|
SELECT LCase(ProductDesc) AS Lower_ProductDesc FROM ProductSales; |
Преобразует значения из поля ProductDesc в нижний регистр и отображает в столбце Lower_ProductDesc. |

Пример VBA
Примечание: В примерах ниже показано, как использовать эту функцию в модуле Visual Basic для приложений (VBA). Чтобы получить дополнительные сведения о работе с VBA, выберите Справочник разработчика в раскрывающемся списке рядом с полем Поиск и введите одно или несколько слов в поле поиска.
В этом примере функция LCase используется для возврата строчной версии строки.
Dim UpperCase, LowerCase
Uppercase = "Hello World 1234" ' String to convert.
Lowercase = Lcase(UpperCase) ' Returns "hello world 1234"
См.
 также
также
Строковые функции и их использование
Строчные буквы Определение и значение
Строчные буквы — это более короткие и уменьшенные версии букв (например, w ), в отличие от более крупных и высоких версий (например, W ), которые называются прописными буквами или заглавными буквами .
Прилагательное в нижнем регистре также может использоваться как существительное, означающее то же самое, что и в нижнем регистре , хотя оно используется гораздо реже. Прилагательное в верхнем регистре также может использоваться как существительное.В качестве прилагательного заглавная означает то же самое, что заглавная , а заглавные буквы также могут называться заглавными .
Некоторые строчных букв — это просто более короткие, уменьшенные версии своих прописных аналогов (например, строчные w и прописные W или строчные c и прописные C ), но во многих случаях две версии буквы принимают разные формы, такие как строчные a и прописные A или строчные b и прописные B .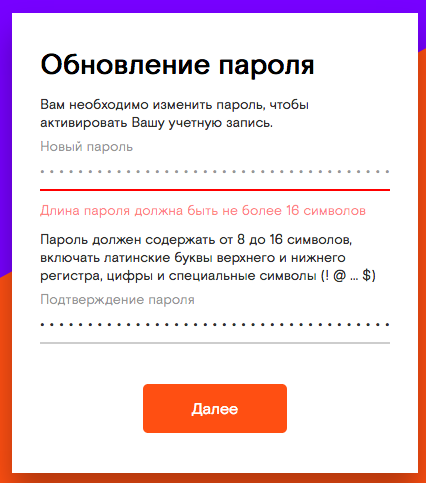
Сделать слово заглавным — значит сделать его первую букву заглавной или прописной. Слово в верхнем регистре может использоваться как глагол, означающий то же самое. Слово в нижнем регистре может использоваться как глагол, означающий превращение буквы в нижний регистр. Например, в нижнем регистре слово Polish (которое здесь пишется в верхнем регистре p ) вы должны написать его в нижнем регистре P , как polish .
В английском языке заглавные буквы используются в начале слов по нескольким причинам.Стандартным правилом английского языка считается использование заглавной буквы в начале имен собственных (существительных, относящихся к определенным людям, местам или вещам, т.е. имеющим определенные имена), например Jess , Mexico , и Nintendo . Использование заглавной или строчной буквы в начале слова может изменить способ интерпретации читателем его значения, как в случае polish (глагол, означающий сделать что-то более блестящее) и Polish (прилагательное, описывающее кого-то).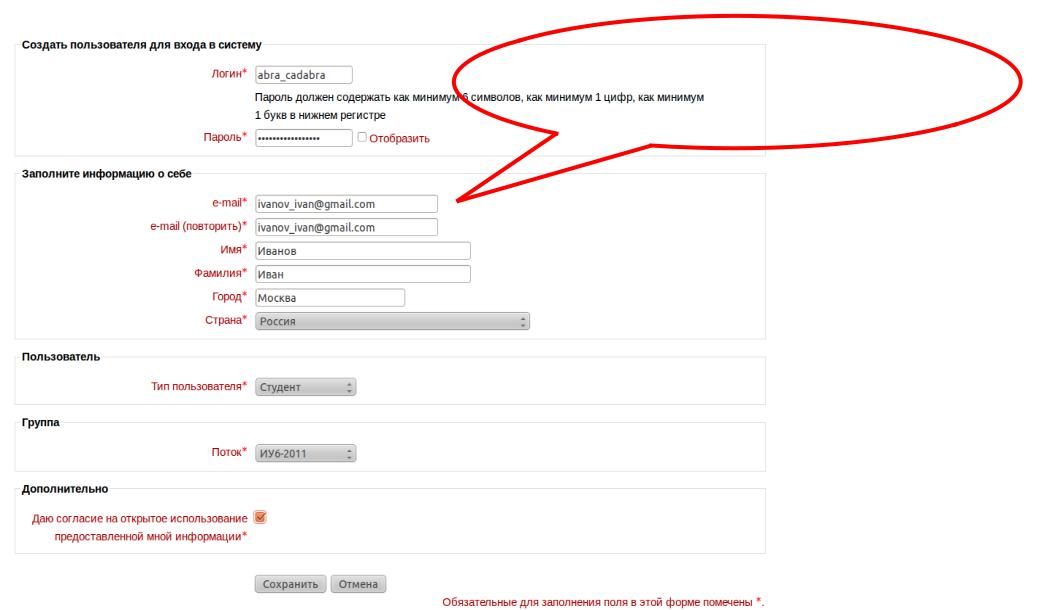 из Польши) или яблоко (фрукт) и яблоко (компания).
из Польши) или яблоко (фрукт) и яблоко (компания).
Мы также используем заглавную букву для первой буквы первого слова в предложении. Иногда мы используем заглавную букву для первой буквы каждого слова в названии, как в Всем мальчикам, которых я любил до . Иногда его называют титульный лист .
Некоторые акронимы и аббревиатуры пишутся прописными буквами, например NASA и U.S . Слово, написанное полностью заглавными буквами (например, WHAT ), считается написанным заглавными буквами или заглавными буквами .
Использование строчных букв в любом из этих случаев обычно указывает на то, что общение носит случайный или неформальный характер, например, в текстовых сообщениях или онлайн-сообщениях.
Пример: Многие люди используют в текстовых сообщениях исключительно строчные буквы, если они не хотят что-то подчеркнуть.
Определение и примеры строчных букв в английском языке
В печатном алфавите и орфографии термин в нижнем регистре (иногда пишется как два слова) обозначает строчные буквы ( a, b, c. .. ) в отличие от заглавных букв ( A, B, C … ). Термин также известен как minuscule (от латинского minusculus , «довольно маленький»), а альтернативные варианты написания включают «нижний регистр» и «нижний регистр».
.. ) в отличие от заглавных букв ( A, B, C … ). Термин также известен как minuscule (от латинского minusculus , «довольно маленький»), а альтернативные варианты написания включают «нижний регистр» и «нижний регистр».
Система письма английского языка — как и большинства западных языков — использует двойной алфавит или двухпалатный шрифт, комбинацию строчных и прописных букв. По соглашению, строчные буквы обычно используются для букв во всех словах, кроме начальной буквы в именах собственных и в словах, начинающих предложения.
Происхождение и эволюция
«Первоначально строчные буквы стояли сами по себе. Их формы произошли от написанного каролингского минускула. Верхние и строчные буквы получили свою нынешнюю форму в эпоху Возрождения. Строчный алфавит. Заглавные буквы основаны на вырезанной или точеной букве; строчные символы основаны на каллиграфической форме, написанной пером. Теперь два вида букв появляются вместе. »
»
— Ян Чихольд, Сокровищница алфавитов и букв . Нортон, 1995 г.
«Верхний и нижний регистр? Этот термин происходит от положения свободных металлических или деревянных букв, лежащих перед руками традиционного наборщика, прежде чем они использовались для образования слова — обычно используемые буквы на доступном нижнем уровне, заглавные буквы над ними , ожидая своей очереди. Даже с учетом этого различия, наборщик все равно должен был бы «помнить свои p s и q s», настолько они были похожи, когда каждая буква была извлечена из печатного блока, а затем брошена обратно в отсеки лотка.»
— Саймон Гарфилд, «Верный типу: как мы влюбились в наши письма». The Observer , 17 октября 2010 г.
Имена с необычными заглавными буквами
«Некоторые монеты по-новому смотрят на английское правописание, особенно с именами. Мы никогда раньше не видели ничего похожего на использование строчной буквы в названии бренда, как в iPod, iPhone, iSense и eBay , или такие авиакомпании, как easyJet и jetBlue , и пока неясно, как с ними обращаться, особенно когда мы хотим, чтобы одно из этих слов начиналось с предложения. Существуют прецеденты введения заглавной буквы в середине слова (например, в таких названиях, как McDonald’s и химических веществах, таких как CaSi , силикат кальция), но торговые марки значительно увеличили его повседневную заметность, как видно из AltaVista. , AskJeeves, PlayStation, YouTube и MasterCard ».
Существуют прецеденты введения заглавной буквы в середине слова (например, в таких названиях, как McDonald’s и химических веществах, таких как CaSi , силикат кальция), но торговые марки значительно увеличили его повседневную заметность, как видно из AltaVista. , AskJeeves, PlayStation, YouTube и MasterCard ».
— Дэвид Кристал, Spell It Out . Пикадор, 2012
«Торговые марки или названия компаний, которые пишутся со строчной начальной буквы, за которой следует заглавная буква ( eBay, iPod iPhone и т. Д.) не нужно писать с заглавной буквы в начале предложения или заголовка, хотя некоторые редакторы могут предпочесть перефразировать. Этот отход от прежнего использования Чикаго признает не только предпочтительное использование владельцев большинства таких имен, но и тот факт, что такие написания уже написаны с заглавной буквы (если на второй букве). Названия компаний или продуктов с дополнительными внутренними заглавными буквами (иногда называемыми «средними заглавными буквами») также следует оставить без изменений ».
— Чикагское руководство по стилю , 16-е изд.Издательство Чикагского университета, 2010 г.
Xerox или xerox?
«Удаление заглавной буквы товарного знака — одно из несомненных доказательств того, что товарный знак действительно стал универсальным …
« OED [ Oxford English Dictionary ] перечисляет« XEROX »как в верхнем, так и в нижнем регистре, а также товарный знак и общий термин:« собственное название фотокопировальных машин.. Также используется в широком смысле для обозначения любого фотокопия »(20: 676).Это определение ясно указывает на то, что слово «ксерокопия», написанное с заглавной или строчной буквы, используется населением как собственное прилагательное и как существительное ».
— Шон М. Клэнки, «Использование торговой марки в творческом письме: родоубийство или язык, верно?» в Перспективы плагиата и интеллектуальной собственности в постмодернистском мире , изд. Лиз Буранен и Элис М.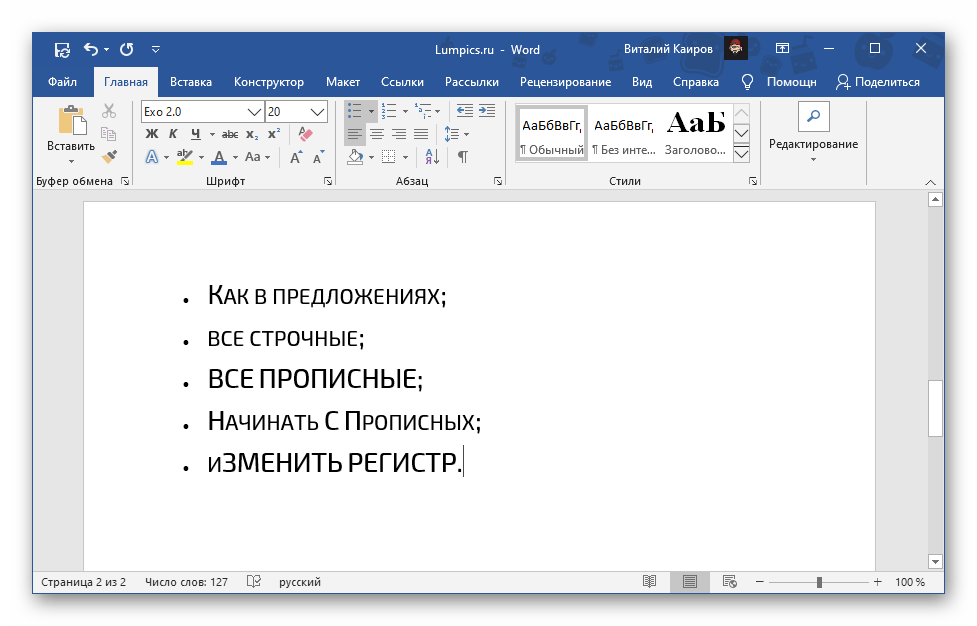 Рой. SUNY Press, 1999 г.
Рой. SUNY Press, 1999 г.
Хорошее правило заключается в том, что большинство товарных знаков являются прилагательными, а не существительными или глаголами.Используйте товарные знаки в качестве модификаторов, например, «салфетки Kleenex» или «копировальные аппараты Xerox». Точно так же товарные знаки — это не глаголы — вы можете копировать на Xerox, но вы не можете ничего «ксерокопировать» ».
— Джилл Б. Тредуэлл, Писательские отношения с общественностью . Шалфей, 2005
Определение строчных букв по Merriam-Webster
нижний · э · футляр | \ ˌLō-ər-ˈkās \письма
: , имеющий в качестве типичной формы f g или b n i , а не A F G или B N I
Должен ли я сначала учить прописные или строчные буквы?
Ширли Хьюстон
Меня несколько раз недавно спрашивали, следует ли вам сначала учить прописным или строчным буквам, поэтому в этом месяце я расскажу о дебатах и влиянии вашего выбора на чтение и правописание. Я также дам рекомендации по передовой педагогической практике.
Я также дам рекомендации по передовой педагогической практике.
Аргумент в пользу обучения верхнему регистру сначала
Сторонники принципа «сначала заглавные буквы» считают, что «заглавные буквы» легче идентифицировать, различать и рисовать. У них более простая визуальная структура, чем у строчных букв. Единственные буквы, которые могут вызвать путаницу при ориентации, — это «M» и «W». «Капители» в основном образованы прямыми штрихами (которые с точки зрения развития легче рисовать, чем кривые), и все они написаны на линиях на линованной бумаге.Заглавные буквы относительно распространены в экологической печати, например дорожные знаки.
Конечно, исследования (Worder & Boetcher, 1990) показывают, что маленькие дети обычно распознают больше прописных букв, чем строчных, предпочитают прописные буквы и пишут прописные буквы лучше, чем строчные, в возрасте от 4 до 6 лет. Но потому что так много воспитателей учат детей узнавать и использовать заглавные буквы еще до того, как они пойдут в школу?
Аргумент в пользу обучения сначала нижнему регистру
Я бы сказал, что практика обучения сначала заглавным буквам, поскольку они считаются «более легкими», является скорее «социальной традицией», чем здравой образовательной практикой. Заглавные буквы имеют минимальную связь с ранними навыками грамотности; 95% написанного текста написано строчными буквами. Когда родители детей читают им книги или когда они пытаются читать сами, дети обычно не видят текст, написанный заглавными буквами. Визуальное распознавание букв нижнего регистра будет более полезным, чем распознавание верхнего регистра. Вот почему Phonics Hero обучает строчным буквам изолированно и отдельными словами (получите доступ к бесплатным ресурсам, когда вы зарегистрируетесь в учетной записи учителя).
Заглавные буквы имеют минимальную связь с ранними навыками грамотности; 95% написанного текста написано строчными буквами. Когда родители детей читают им книги или когда они пытаются читать сами, дети обычно не видят текст, написанный заглавными буквами. Визуальное распознавание букв нижнего регистра будет более полезным, чем распознавание верхнего регистра. Вот почему Phonics Hero обучает строчным буквам изолированно и отдельными словами (получите доступ к бесплатным ресурсам, когда вы зарегистрируетесь в учетной записи учителя).
Как связать звуки с строчными буквами:
- Когда речь идет о строчных буквах, важно обращаться к буквенным звукам: «Когда ваши глаза видят эту букву, ваш рот говорит ___».
- Вместо того, чтобы начинать с порядка в алфавите, имеет смысл учить буквы, которые чаще всего появляются первыми. В играх Phonics Hero есть два порядка звуков, первые буквы, которые нужно выучить:
- Когда освоены первые буквенно-звуковые соответствия (т. е. звуки алфавита), можно ввести другие звуки, представленные буквой, например «е» кровати и «е» слова «он».
- Если вы выберете порядок «Игра со звуками», наши уроки по акустике, не требующие подготовки, расскажут, как преподавать звуки и их связь со строчными буквами. См. Путеводитель по «уроку звуков» здесь:
 е. звуки алфавита), можно ввести другие звуки, представленные буквой, например «е» кровати и «е» слова «он».
е. звуки алфавита), можно ввести другие звуки, представленные буквой, например «е» кровати и «е» слова «он».
Когда учить верхний регистр
Начало имен и предложений
Заглавные буквы выполняют особую важную задачу, и их следует учить в контексте.Они показывают начало предложения или имя. Сначала лучше всего использовать заглавные буквы в качестве первой буквы в имени ребенка. Часто они являются первой и единственной заглавной буквой в названиях продуктов и вывесках магазинов, поэтому здесь также можно привлечь внимание к ним. Имя обычно пишется полностью заглавными буквами только тогда, когда его нужно видеть с значительного расстояния. Как только ребенок научится читать или писать предложение, следует обратить внимание на необходимость использования заглавной буквы в начале.
Часто они являются первой и единственной заглавной буквой в названиях продуктов и вывесках магазинов, поэтому здесь также можно привлечь внимание к ним. Имя обычно пишется полностью заглавными буквами только тогда, когда его нужно видеть с значительного расстояния. Как только ребенок научится читать или писать предложение, следует обратить внимание на необходимость использования заглавной буквы в начале.
Помните, отучиться труднее, чем учиться
Если мы сначала учим ребенка писать слова заглавными буквами, то позже мы должны научить его, что на самом деле это была совершенно неправильная практика, и попытаться заставить его «отучиться» от нее.Учиться намного легче, чем «отучиться». Вот почему многие студенты продолжают неправильно использовать прописные буквы в словах. Многие программы, в том числе Phonics Hero, используют строчные буквы для обучения буквенно-звуковому соответствию и прописные буквы для обучения названиям букв алфавита.
Игра со строчными буквами от Phonics Hero.
Это связано с тем, что знание названий алфавита не помогает ребенку «произносить слова», но станет полезным при описании написания, например, «c», «k» или «ck» для звука / k /.
Легче писать прописные буквы?
Один из аргументов в пользу обучения заглавным буквам в первую очередь состоит в том, что их легче сформировать, но на самом деле все типы движений рук требуются как для прописных, так и для строчных букв. Прописные буквы имеют больше отправных точек и требуют большего количества штрихов / взятия карандаша, поэтому их на самом деле сложнее рисовать, чем строчные. В заглавных буквах больше диагоналей, что сложно с точки зрения развития. Следовательно, имеет смысл начинать писать строчными буквами.Если скорописному письму учат с самого начала, это имеет еще больше смысла.
Связывание прописных и строчных букв
Логика предлагает, чтобы мы сначала построили основные основы звука и формы, а затем добавили вспомогательные понятия, такие как заглавные буквы и буквенные названия.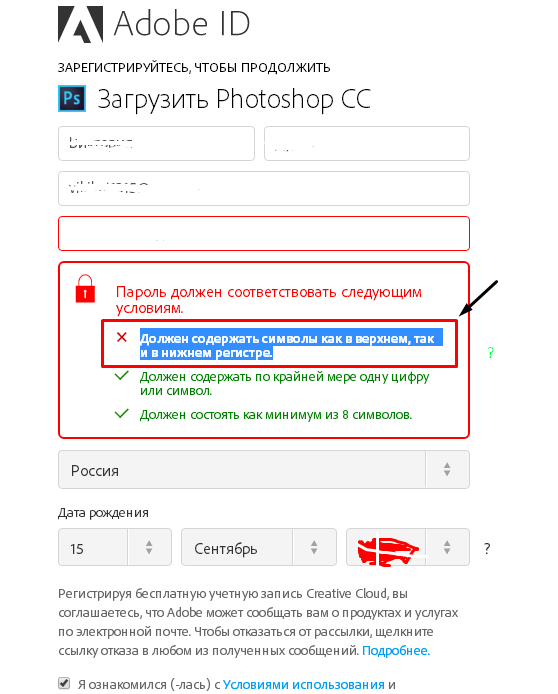 Если вам нужно научить прописные буквы писать, явно учите их как «партнеров», бок о бок. Обеспечьте настенный дисплей и настольный коврик с заглавными и строчными буквами, показанными рядом с соответствующей картинкой, которую ребенок узнает, как показано ниже.Многие алфавитные книги, такие как Азбука доктора Сьюза, делают это.
Если вам нужно научить прописные буквы писать, явно учите их как «партнеров», бок о бок. Обеспечьте настенный дисплей и настольный коврик с заглавными и строчными буквами, показанными рядом с соответствующей картинкой, которую ребенок узнает, как показано ниже.Многие алфавитные книги, такие как Азбука доктора Сьюза, делают это.
Мультисенсорные идеи для установления связи между строчными и прописными буквами:
- Играйте в настольные игры, такие как Бинго, для сопоставления букв или букв и звуков.
- Играйте в игры на подбор партнеров, которые предполагают движение, т. Е. Половина класса верхним регистром, а половина нижним. Дети должны молча найти своего партнера.
- Выполните сортировку пластиковых / магнитных букв, чтобы ребенок чувствовал в трехмерном пространстве форму букв.
- Попросите ребенка писать буквы с помощью очистителя для трубок, теста и т. Д., Произнося соответствующий звук по завершении каждой буквы.
- Попросите ребенка выполнить поиск букв / звука / нижнего / верхнего регистра в лабиринте или тексте.
- Поскольку традиционные клавиатуры показывают верхний регистр, но печатают нижний регистр (если не используется Caps Lock), их можно использовать в качестве инструментов для развития памяти ссылки верхнего / нижнего регистра.
- Попросите ребенка написать воздушным письмом, начертить буквы, затем скопировать на бумаге, чередуя строчные и прописные буквы, рисовать верхний регистр с грубым движением в воздухе, на песке и т. Д.
Автор: Ширли Хьюстон
Имея степень магистра специального образования, Ширли обучает детей и готовит учителей в Австралии более 30 лет. Работая с детьми с трудностями в обучении, Ширли отстаивает важность систематического обучения фонетике и овладения ею в обычных классах. Если вы заинтересованы в помощи Ширли в качестве инструктора по обучению грамоте в вашей школе, отправьте команде электронное письмо по адресу [email protected].
Если вы заинтересованы в помощи Ширли в качестве инструктора по обучению грамоте в вашей школе, отправьте команде электронное письмо по адресу [email protected].Обоснование строчных букв — AppyTherapy
Часто обсуждается вопрос, учить ли детей в первую очередь прописным или строчным буквам. Сторонники верхнего регистра утверждают, что:
- Прописные буквы более подходят с точки зрения развития, потому что буквы легче формировать.
- Прописные буквы легче распознать.
- Переход от верхнего регистра к нижнему регистру очень прост.
Рассмотрим четыре элемента:
1. Начальные точки Меньшее количество отправных точек упрощает решение о том, с чего начать. Все заглавные буквы начинаются сверху. Строчные буквы в основном начинаются со средней линии. Исключение составляют буквы b, h, k, l и t, которые начинаются сверху, и буквы e и f. Этот фактор способствует тому, что прописные буквы легче выучить.
Этот фактор способствует тому, что прописные буквы легче выучить.
Каждый подъем карандаша требует тщательного визуального контроля и точной моторики, чтобы аккуратно положить карандаш в начало следующего движения. Семнадцать заглавных букв требуют двух или более подъемов по сравнению с семью строчными буквами . Например, заглавная буква «E» состоит из четырех штрихов, для чего нужно поднять карандаш и поместить его в четырех разных точках. Строчная буква «е» использует один непрерывный штрих, который требует меньшего визуального внимания и упрощает и повышает эффективность формирования.Это говорит о том, что строчные буквы легче формировать.
3. Диагональные линии Дети учатся рисовать первые шесть фигур перед написанием в следующем порядке развития: вертикальная линия, горизонтальная линия, круг, крест, квадрат и, наконец, диагональная линия. Соответственно, сложнее всего формировать буквы, содержащие диагонали. Девять прописных букв содержат диагональные линии, в отличие от шесть строчных. Этот показатель также указывает на то, что строчные буквы легче писать.
Соответственно, сложнее всего формировать буквы, содержащие диагонали. Девять прописных букв содержат диагональные линии, в отличие от шесть строчных. Этот показатель также указывает на то, что строчные буквы легче писать.
4.
Группы буквСортировка букв по первому штриху и отработка их в «группе» — очень эффективный способ научиться писать буквы. Повторение одного и того же непрерывного движения от одной буквы к другой развивает моторную память и способствует ритмичному письму.
Строчные буквы имеют несколько общих черт и легко разделяются на четыре кинестетические группы:
- l, t, k, I и j начинаются вертикальной линией вниз
- c, a, d, o, g и q начинаются как c
- h, b, r, n, m и p все падают вниз, вверх и вверх
- v, w, x и y начинаются с диагональной линии вниз
Буквы s, u, f, e и z имеют общий штрих с другими буквами.
Заглавные буквы имеют две кинестетические группы:
- C, O, Q и G начинаются как C
- V, W, X и Y начинаются с диагональной линии вниз
B, D, E, F, H, I, J, K, L M, N, P, R, T и U все начинаются с хода вниз. Однако, учитывая, что они не разделяют схожее движение за пределами этой точки, чтобы направлять правильное направление хода, затрудняет объединение их в кинестетическую группу. Буквы A, S и Z не имеют общего штриха с другими буквами.
Однако, учитывая, что они не разделяют схожее движение за пределами этой точки, чтобы направлять правильное направление хода, затрудняет объединение их в кинестетическую группу. Буквы A, S и Z не имеют общего штриха с другими буквами.
Несколько строчных букв похожи по внешнему виду, в первую очередь буквы b, d, p, g и q, а также h и n; облегчая их путаницу.Тем не менее, молодые школьники, которые учатся читать, читают строчными буквами. А для детей, которые борются с визуально сбивающими с толку буквами, было бы полезно больше практики, а не меньше. Совмещение почерка с чтением помогает учащемуся распознавать эти буквы, особенно если ребенок учится кинестетически. Обучение прописным буквам просто задерживает обучение строчным или, что еще хуже, создает больше путаницы, добавляя больше букв в смесь.
Также интересно отметить, что строчные слова легче читать.В статье Джейсона Санта-Марии « Как мы читаем » объясняется, что это происходит потому, что мы воспринимаем слова как формы. В нижнем регистре есть восходящие и нисходящие элементы, которые образуют неправильную форму и облегчают идентификацию слов, тогда как заглавные буквы выглядят как «большие прямоугольные блоки, обработка которых занимает гораздо больше времени».
В нижнем регистре есть восходящие и нисходящие элементы, которые образуют неправильную форму и облегчают идентификацию слов, тогда как заглавные буквы выглядят как «большие прямоугольные блоки, обработка которых занимает гораздо больше времени».
Существует большая разница в том, насколько хорошо учащиеся адаптируются к строчным буквам после изучения прописных.Я обнаружил, что для студентов, которые предрасположены к затруднениям с письмом и которых сначала обучали прописным буквам, они путают два алфавита и, как правило, очень сопротивляются переключению с верхнего на нижний регистр. Помимо ухудшения общей разборчивости, смешивание верхнего и нижнего регистра или использование только верхнего регистра неэффективно и приводит к медленному и утомительному письму.
Когда Дэйв Томпсон, генеральный директор компании Educational Fontware и разработчик более 900 шрифтов, попросил взвесить свое мнение в дебатах о регистре букв, сказал: «Строчные буквы определенно проще.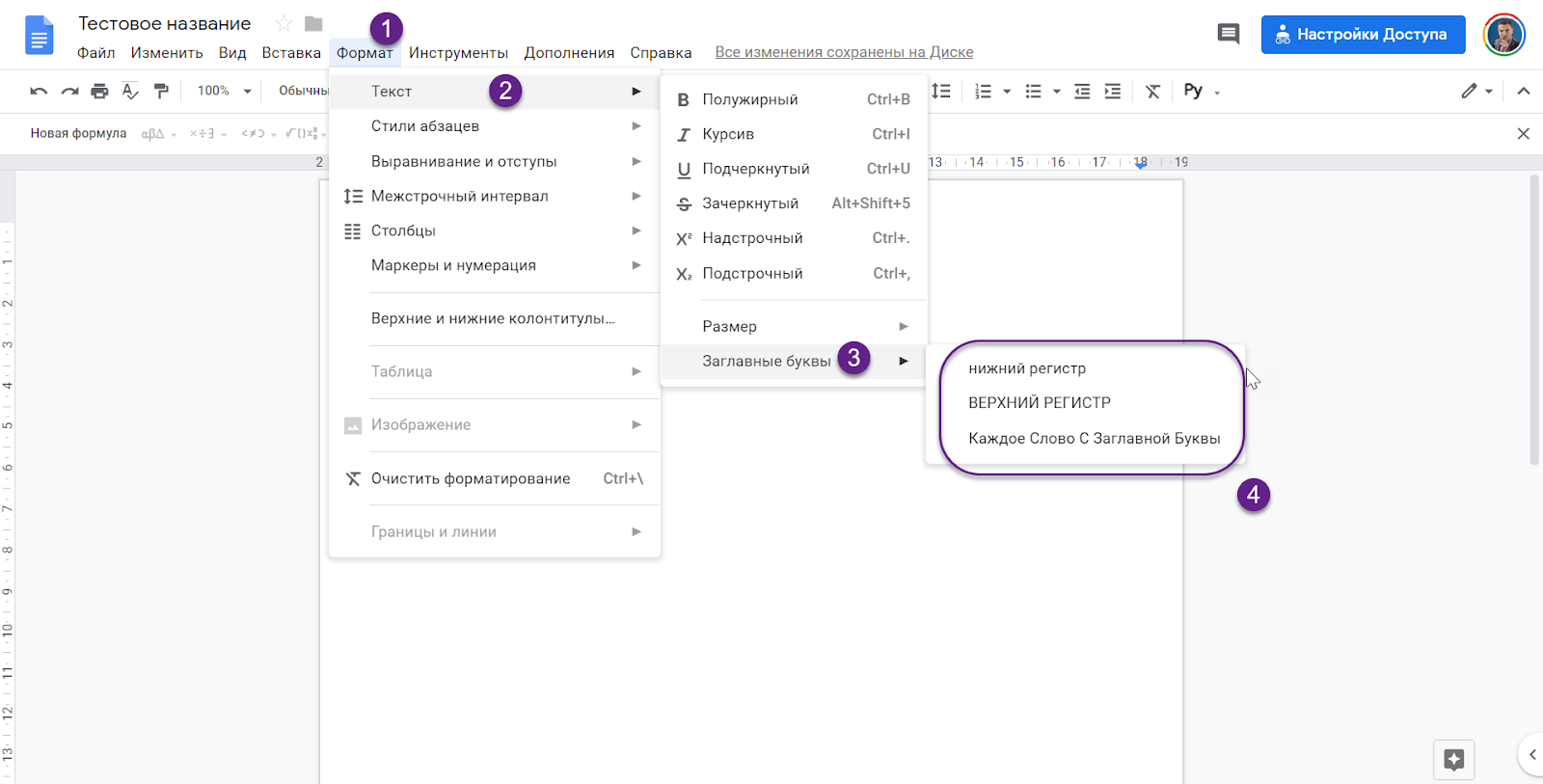 Большинство букв намного короче, что требует меньшего движения руки для самых маленьких. Меньше подъемов пера и гораздо больше сходства между маленькими (например, a, c, d, e, g, o, q начинаются с крючка против часовой стрелки или имеют крючок против часовой стрелки), чем с заглавными буквами. В нижнем регистре используется обратный ход без подъема пера для b, d, h, m, n, p и r. Заглавные буквы обычно преподаются как подъемы ручки, а не как обратный ход: B, D, M, N, P и R. Наконец, вы можете составлять слова из маленьких букв, но не заглавные буквы ».
Большинство букв намного короче, что требует меньшего движения руки для самых маленьких. Меньше подъемов пера и гораздо больше сходства между маленькими (например, a, c, d, e, g, o, q начинаются с крючка против часовой стрелки или имеют крючок против часовой стрелки), чем с заглавными буквами. В нижнем регистре используется обратный ход без подъема пера для b, d, h, m, n, p и r. Заглавные буквы обычно преподаются как подъемы ручки, а не как обратный ход: B, D, M, N, P и R. Наконец, вы можете составлять слова из маленьких букв, но не заглавные буквы ».
В заключение, поскольку все меньше и меньше учебного времени тратится на рукописный ввод, становится еще более важным расставить приоритеты по сценарию, который нужен учащимся для выполнения задач функционального письма.И, поскольку строчные буквы составляют около 95% всех букв при чтении и письме, я бы посоветовал вам сначала научить строчные буквы!
Список литературы
Мария, Джейсон Санта. «Как мы читаем». A List Apart, 2014. Интернет. 15 декабря 2016 г. Получено с http://alistapart.com/article/how-we-readhttp://alistapart.com/article/how-we-read
«Как мы читаем». A List Apart, 2014. Интернет. 15 декабря 2016 г. Получено с http://alistapart.com/article/how-we-readhttp://alistapart.com/article/how-we-read
причин печатать строчными буквами
То, как мы печатаем, часто кажется добавлением изюминки школьной форме.Мы можем сделать очень мало, но мы также можем многое сделать. Мы можем добавлять смайлики и аббревиатуры, использовать изобретательную пунктуацию, печатать как thiiiiis и выбирать строчные буквы в тех случаях, когда традиционно используются прописные буквы. Например, название и список треков в последнем альбоме Арианы Гранде — «спасибо, следующий» — написаны строчными буквами, как и ее аккаунты в Twitter и Instagram. Их чтение действительно заставляет вас чувствовать себя ближе к ней: это звучит так, как будто она говорит тихо или отправляет вам рукописную записку.
Иногда я пишу в Твиттере строчными буквами, пытаясь показаться смешным. Моя подруга пишет электронные письма исключительно строчными буквами, и получать их я как будто слышу ее настоящий голос. Одна моя знакомая недавно извинилась передо мной за то, что отправила электронное письмо, написанное строчными буквами, что было трогательно и казалось ненужным, но поскольку мы плохо знали друг друга, это также было похоже на сложный комплимент (что ей было бы достаточно удобно в первую очередь написать мне строчные буквы, но достаточно неудобно, чтобы подумать, что это достойно извинений).
Это круто печатать строчными буквами? Это хромой? Это все зависит? Хотя ввод строчными буквами кажется простым — это непринужденно, это легко — он свидетельствует о множестве сложных / тонких подходов. Вы можете носить строчные буквы как костюм. Это может быть зло, оно может быть нежным. Он может быть светлым, может быть темным. Итак, вот исчерпывающий список всех причин, по которым мы вводим строчные буквы, особенно в электронной почте и в прямых переписках.
Вы можете носить строчные буквы как костюм. Это может быть зло, оно может быть нежным. Он может быть светлым, может быть темным. Итак, вот исчерпывающий список всех причин, по которым мы вводим строчные буквы, особенно в электронной почте и в прямых переписках.
Близость
Ввод строчными буквами означает знакомство.Он гласит: «Мы знаем друг друга, и нам не нужно фантазировать». Текст в нижнем регистре может читаться как честный, неотредактированный и приближающийся к чему-то вроде потока сознания — больше похожему на настоящую речь.
Скорость
Строчные буквы набирать быстрее и проще, поэтому, когда важно быть быстрым и естественным (или выглядеть так), как в IM, строчные буквы часто используются по умолчанию.
Случайность (реальная)
Сообщения, набранные строчными буквами, могут показаться более небрежными. Ставки ниже, атмосфера спокойная.Первое общедоступное электронное письмо, которое Дэвид Хаскелл, новый главный редактор журнала New York Magazine, разослал, было полностью напечатано строчными буквами. Я спросил его, что это значило в последнее время для Slack. «Низкий ключ?» он ответил. И это было правдой; так казалось. Возможно, именно поэтому мне было комфортно болтать с ним о его намерениях за электронным письмом, что мне теперь кажется странным.
Случайность (ложь)
Точно так же ввод строчных букв (или непоследовательных строчных букв) может быть признаком того, что кто-то пытается передать непринужденность, даже если на самом деле они не чувствуют себя непринужденно. Например, если вы хотите скрыть, сколько времени вам потребовалось для написания электронного письма потенциальному романтическому партнеру, и насколько вы заботитесь о том, что о нем / вас думает получатель, может быть полезно вернуться и изменить некоторые из От «я» к «я» — непоследовательно — чтобы это выглядело более размытым. Это жалко? да. Это хорошая идея? Нет. Это видно? Да, возможно. Но это меня никогда не останавливало.
Например, если вы хотите скрыть, сколько времени вам потребовалось для написания электронного письма потенциальному романтическому партнеру, и насколько вы заботитесь о том, что о нем / вас думает получатель, может быть полезно вернуться и изменить некоторые из От «я» к «я» — непоследовательно — чтобы это выглядело более размытым. Это жалко? да. Это хорошая идея? Нет. Это видно? Да, возможно. Но это меня никогда не останавливало.
Уловки (связанные со Slack и не только)
Иногда ввод строчных букв может означать, что вы пытаетесь замести следы.Slack, приложение для офисных чатов, автоматически использует заглавные буквы в сообщениях, набранных на телефонах. Поэтому сообщение Slack с заглавной буквы часто является признаком того, что кого-то нет на рабочем месте. Что может быть неплохо — иногда вы просто едете на работу, но в других случаях возвращение назад и ручное переводе сообщений в нижний регистр может указывать на попытку убедить людей, что вы находитесь там, где не находитесь.
Лень
Для людей, которые в годы становления использовали такие программы, как Microsoft Word, которые автоматически используют заглавные буквы, такие как «я» и начало предложений, находя и удерживая кнопку переключения снова и снова в электронной почте и в прямых переписках, могут почувствовать как старомодное и бессмысленное бремя.
Бесстрастная плоскостность / юмор
Набор строчных букв также может сигнализировать о ровности, которая усиливает некоторые шутки. Использование строчных букв в этих случаях также может сделать шутку / утверждение более похожей на то, что она возникла сама по себе или со стороны чьего-то рта, хотя это граничит с чревовещанием.
Художественность
Имена в нижнем регистре могут выглядеть свежими и молодыми, как в случае с некоторыми брендами или публикациями. На самом деле это случилось со мной — я начал публикацию (раздел комиксов, называемый спиральным) со строчной буквы, пытаясь выглядеть круто и передать стилизованную атмосферу, хотя каждый раз, когда я печатал об этом в электронных письмах, я рефлекторно использовал заглавные буквы это, а затем вернуться и убрать заглавные буквы, и я почувствовал себя идиотом.В конце концов я изменил его на заглавные, и это было большим облегчением.
Гудение
Иногда ввод текста строчными буквами передает качество гудения или бесконечность — похоже на невозмутимость, но немного отличается.
Смирение
Строчные буквы также могут сделать вещи более мягкими и неуверенными — почти извиняющимися. «О, я просто подумал…» Однажды я получил электронное письмо от музыканта, который сделал микстейп с заголовком, написанным строчными буквами (имя его исполнителя тоже было строчными), а в описании он написал третьим человек: «нет, ему все равно, если кто-то нажмет на этом.и нет, он не думает, что он умер. lang или ee cummings. (последний, который, кстати, я только что узнал, не настаивал на отсутствии заглавных букв.) »
Это верно в отношении Э.Э.Каммингса, и, подтверждая это, мне понравился этот факт: одна биография Каммингса включала предисловие критика, который с уверенностью утверждал, что Каммингс на законных основаниях изменил свое имя на строчные буквы. Когда вдова Каммингса прочитала это, она написала автору письмо, в котором говорилось: «Вы не должны были позволять [критику] делать такое глупое и детское заявление о Каммингсе и его подписи.Позже биограф написал для протокола: «Имя Каммингса должно иметь обычные заглавные буквы… [и] мы надеемся, что унылый обычай в нижнем регистре исчезнет с лица земли». Каммингс подписал свое собственное имя непоследовательно, но миф о том, что он называл себя «э-э каммингс», очевидно, является продолжением его тенденции использовать «я» вместо «я» в своих стихах (а не то, что он сам выдвигал).
Когда вдова Каммингса прочитала это, она написала автору письмо, в котором говорилось: «Вы не должны были позволять [критику] делать такое глупое и детское заявление о Каммингсе и его подписи.Позже биограф написал для протокола: «Имя Каммингса должно иметь обычные заглавные буквы… [и] мы надеемся, что унылый обычай в нижнем регистре исчезнет с лица земли». Каммингс подписал свое собственное имя непоследовательно, но миф о том, что он называл себя «э-э каммингс», очевидно, является продолжением его тенденции использовать «я» вместо «я» в своих стихах (а не то, что он сам выдвигал).
Усталость
Иногда мы устаем. Или мы хотим показать / поделиться, что мы устали.да идк
Симпатичность
Набирать строчные буквы может быть мило и немного кокетливо.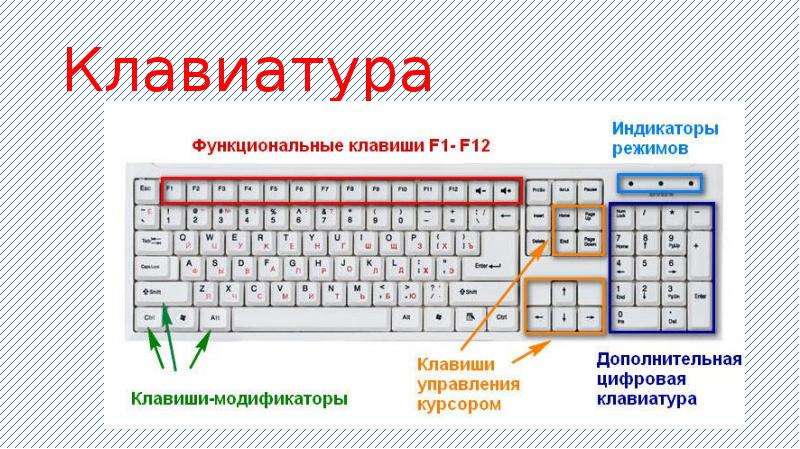 Это заставляет вас чувствовать себя милым, когда вы его печатаете. Вроде как расставить точки над i сердечками. Я бы сказал, что это в основном женское дело, но парни тоже. Я не уверен, где это подходит, но парень, с которым я ходил на пару свиданий, написал мне письмо исключительно строчными буквами. Сообщения были сложными и лаконичными, и он был привлекательным, а общее впечатление производило уверенность и скромность.Однако это сложно осуществить. Вроде как BDE, но больше на bde.
Это заставляет вас чувствовать себя милым, когда вы его печатаете. Вроде как расставить точки над i сердечками. Я бы сказал, что это в основном женское дело, но парни тоже. Я не уверен, где это подходит, но парень, с которым я ходил на пару свиданий, написал мне письмо исключительно строчными буквами. Сообщения были сложными и лаконичными, и он был привлекательным, а общее впечатление производило уверенность и скромность.Однако это сложно осуществить. Вроде как BDE, но больше на bde.
Ненависть к себе
Я включаю это неохотно, но мой друг сказал мне, что ее парень однажды попросил ее перестать использовать «я», потому что он подумал, что это сигнализирует о том, что она не уважает себя. Однако ее парню было 500 000 лет.
Оставайтесь на связи.
Ежедневная доставка информационного бюллетеня Cut
Условия использования и уведомление о конфиденциальности Отправляя электронное письмо, вы соглашаетесь с нашими Условиями и Уведомлением о конфиденциальности и получаете от нас электронную переписку.Почему есть 2 способа написать строчную букву «А»? — Проголосовали за
Назовите это родительским ответом. Что кстати, поскольку направлено на вопрос, опубликованный в сообществе Reddit Explain Like I’m Five.
Пользователь Reddit MTC36 сделал, казалось бы, простой и понятный вопрос: почему строчная буква «a», которую мы вводим, отличается от буквы «α», которую я пишу от руки? Ответ ELI5? Потому что. Просто так получилось.
Это неудовлетворительный ответ, особенно когда фильмы и телешоу заставили нас поверить в то, что независимо от того, почему Индиана Джонс носит шляпу или как был построен C3-PO, все происходит по важным причинам.(Жизненные события никогда, как отмечал философ конца 20-го века Гомер Симпсон, не были «просто кучей происшествий».)
В конечном счете, не существует единственного, побуждающего события или решения, не определяется секретное происхождение, которое создало две общепринятые формы строчной буквы «а» — «а» и «а». Формы развивались вместе с печатным словом, поскольку рукописи, книги и другие документы перешли от рукописного к механическому. Все это произошло за медленный ход времени.
К счастью, пользователь Reddit F0sh предоставляет более подробную информацию о постепенном развитии того, как мы пишем письмо:
«TL; DR состоит в том, что это, по сути, историческая случайность: было множество вариаций буквы« а », одна из которых стала стандартной для печати, в то время как менее причудливая стала стандартной для почерка, предположительно потому, что люди ленивы, когда у них есть делать вещи вручную. …
Итак, на самом деле было много разных способов написания письма, если вернуться примерно 1500 лет назад.На самом деле это не так уж и редко — если вы думаете о других буквах, таких как ‘g’, которые сегодня имеют варианты, или вы, возможно, слышали о старинной английской букве шип (þ), которая пишется как ‘y’ (отсюда ‘ye olde шоппе ‘).
Как бы то ни было, через некоторое время появилось два основных варианта: один был похож на рукописную букву «А», а второй был похож, но прямая линия справа диагональна и простиралась над петлей. Этот растягивающийся бит в конечном итоге станет тем, что мы видим сейчас на экранах наших компьютеров.Эти два символа также проясняют связь с современным верхним регистром A — между ними есть форма, состоящая из двух диагональных линий (например, A) и соединительной черты внизу ».
А для тех, кто не может насытиться глифами, пользователь callius продолжает с того места, где остановился F0sh, и дает еще более подробное объяснение:
Также важно отметить, что эти разные способы написания А не находились в «прямой конкуренции» друг с другом, говоря писарским языком.Они работали в унисон и выполняли разные функции в зависимости от используемого сценария, типа создаваемого документа, иерархии каждой части документа (заголовки были более красивыми, имена и титулы королей и епископов немного менее, а основной текст документа тем более).
В этом документе из Англии 13-го века вы можете увидеть множество As.
Итак, поехали.