Данные (в информатике) — это… Что такое Данные (в информатике)?
В вычислительной технике данные обычно различают от программ. Программа является набором инструкций, которые детализируют вычисление или задачу, которая производится компьютером. Данные — это всё отличное от программного кода.
С точки зрения программиста данные — это часть программы, совокупность значений определенных ячеек памяти, преобразование которых осуществляет код. С точки зрения компилятора, процессора, операционной системы, это совокупность ячеек памяти, обладающих определёнными свойствами (возможность чтения и записи (необязательно), невозможность исполнения).
Контроль за доступом к данным в современных компьютерах осуществляется аппаратно.
В соответствии с принципом фон Неймана, одна и та же область памяти может выступать как в качестве данных, так и в качестве исполнимого кода.
Типы данных
Традиционно выделяют два типа данных — двоичные (бинарные) и текстовые.
Двоичные данные обрабатываются только специализированным программным обеспечением, знающим их структуру, все остальные программы передают данные без изменений.
Текстовые данные воспринимаются передающими системами как текст, записанный на каком-либо языке. Для них может осуществляться перекодировка (из кодировки отправляющей системы в кодировку принимающей), заменяться символы переноса строки, изменяться максимальная длина строки, изменяться количество пробелов в тексте.
Передача текстовых данных как бинарных приводит к необходимости изменять кодировку в прикладном программном обеспечении (это умеет большинство прикладного ПО, отображающего текст, получаемый из разных источников), передача бинарных данных как текстовых может привести к их необратимому повреждению.
Данные в ООП
Могут обрабатываться функциями объекта, которому принадлежат сами, либо функциями других объектов, имеющими для этого возможность.
Данные в языках разметки
Имеют различное отображение в зависимости от выбранного способа представления
Данные в XML
Множество данных может иметь надмножество, называемое метаданными
Wikimedia Foundation. 2010.
2010.
Данные — это… Что такое Данные?
Да́нные (калька от англ. data
Изначально — данные величины, то есть величины, заданные заранее, вместе с условием задачи. Противоположность — переменные величины.
В информатике данные — это результат фиксации, отображения информации на каком-либо материальном носителе, то есть зарегистрированное на носителе представление сведений независимо от того, дошли ли эти сведения до какого-нибудь приёмника и интересуют ли они его.[1]
Данные — это и текст книги или письма, и картина художника, и ДНК.
Данные, являющиеся результатом фиксации некоторой информации, сами могут выступать как источник информации. Информация, извлекаемая из данных, может подвергаться обработке, и результаты обработки фиксируются в виде новых данных.
Данные могут рассматриваться как записанные наблюдения, которые не используются, а пока хранятся.
Информация, отображаемая данными, может быть непонятна приемнику (шифрованный текст, текст на неизвестном языке и пр.).
Синонимы: сведения, информация
С точки зрения программиста, данные — это часть программы, совокупность значений определённых ячеек памяти, преобразование которых осуществляет код. С точки зрения компилятора, процессора, операционной системы, это совокупность ячеек памяти, обладающих определёнными свойствами (возможность чтения и записи (необяз.), невозможность исполнения).
Контроль за доступом к данным в современных компьютерах осуществляется аппаратно.
В соответствии с принципом фон Неймана, одна и та же область памяти может выступать как в качестве данных, так и в качестве исполнимого кода.
Типы данных
Традиционно выделяют два типа данных — двоичные (бинарные) и текстовые.
Двоичные данные обрабатываются только специализированным программным обеспечением, знающим их структуру, все остальные программы передают данные без изменений.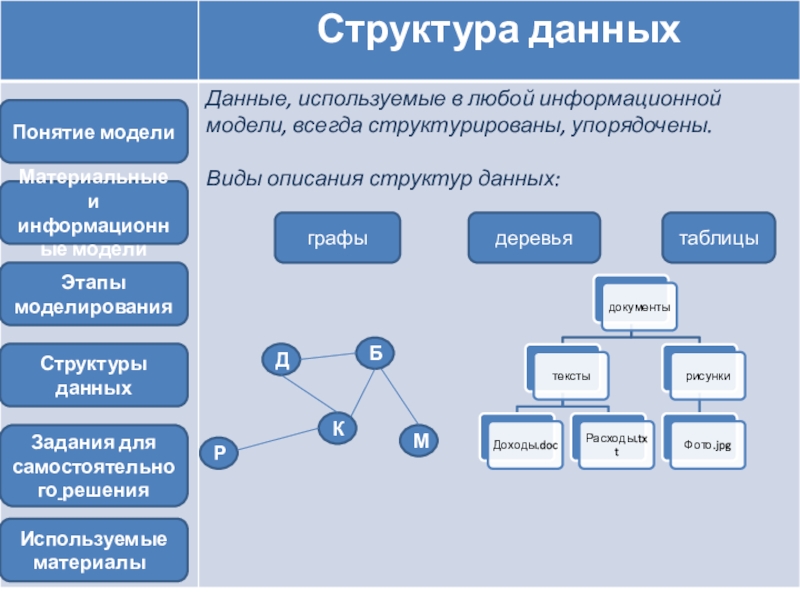
Текстовые данные воспринимаются передающими системами как текст, записанный на каком-либо языке. Для них может осуществляться перекодировка (из кодировки отправляющей системы в кодировку принимающей), заменяться символы переноса строки, изменяться максимальная длина строки, изменяться количество пробелов в тексте.
Передача текстовых данных как бинарных приводит к необходимости изменять кодировку в прикладном программном обеспечении (это умеет большинство прикладного ПО, отображающего текст, получаемый из разных источников), передача бинарных данных как текстовых может привести к их необратимому повреждению.
Данные в объектно-ориентированном программировании
Данные в языках разметки
Имеют различное отображение в зависимости от выбранного способа представления.
Данные в XML
В теории множеств
В отличие от операций над элементами множества, представляют собой множество (название и элементы множества)
В лингвистике
В отличие от операций (действие, процесс) по работе с данными (сказуемое с возможными его обстоятельствами и дополнениями), выражаются подлежащим (с возможными его определениями).
Метаданные
Множество данных может иметь надмножество, называемое метаданными. Другими словами, метаданные — это данные о данных.
Операции с данными
Для повышения качества данные преобразуются из одного вида в другой с помощью методов обработки. Обработка данных включает операции:
- ввод (сбор) данных — накопление данных с целью обеспечения достаточной полноты для принятия решений;
- формализация данных — приведение данных, поступающих из разных источников, к одинаковой форме, для повышения их доступности;
- фильтрация данных — это отсеивание «лишних» данных, в которых нет необходимости для повышения достоверности и адекватности;
- сортировка данных — это упорядочивание данных по заданному признаку с целью удобства их использования;
- архивация — это организация хранения данных в удобной и легкодоступной форме;
- защита данных — включает меры, направленные на предотвращение утраты, воспроизведения и модификации данных;
- транспортировка данных — приём и передача данных между участниками информационного процесса;
- преобразование данных — это перевод данных из одной формы в другую или из одной структуры в другую.


Примечания
- ↑ Максимович Г. Ю. Информационные системы : Учебное пособие / Ю. Г. Максимович, А. Г. Романенко, О. Ф. Самойлюк; Под общей ред. К. И. Курбакова. — М.: Изд-во Рос. экон. акад., 1999. — 198 с.
См. также
Данные — это… Что такое Данные?
Да́нные (калька от англ. data[источник не указан 101 день]) — представление фактов и идей в формализованном виде, пригодном для передачи и обработки в некотором информационном процессе.
Изначально — данные величины, то есть величины, заданные заранее, вместе с условием задачи. Противоположность — переменные величины.
В информатике данные — это результат фиксации, отображения информации на каком-либо материальном носителе, то есть зарегистрированное на носителе представление сведений независимо от того, дошли ли эти сведения до какого-нибудь приёмника и интересуют ли они его.
Данные — это и текст книги или письма, и картина художника, и ДНК.
Данные, являющиеся результатом фиксации некоторой информации, сами могут выступать как источник информации. Информация, извлекаемая из данных, может подвергаться обработке, и результаты обработки фиксируются в виде новых данных.
Данные могут рассматриваться как записанные наблюдения, которые не используются, а пока хранятся.
Информация, отображаемая данными, может быть непонятна приемнику (шифрованный текст, текст на неизвестном языке и пр.).
Синонимы: сведения, информация
С точки зрения программиста, данные — это часть программы, совокупность значений определённых ячеек памяти, преобразование которых осуществляет код. С точки зрения компилятора, процессора, операционной системы, это совокупность ячеек памяти, обладающих определёнными свойствами (возможность чтения и записи (необяз.), невозможность исполнения).
Контроль за доступом к данным в современных компьютерах осуществляется аппаратно.
В соответствии с принципом фон Неймана, одна и та же область памяти может выступать как в качестве данных, так и в качестве исполнимого кода.
Типы данных
Традиционно выделяют два типа данных — двоичные (бинарные) и текстовые.
Двоичные данные обрабатываются только специализированным программным обеспечением, знающим их структуру, все остальные программы передают данные без изменений.
Текстовые данные воспринимаются передающими системами как текст, записанный на каком-либо языке. Для них может осуществляться перекодировка (из кодировки отправляющей системы в кодировку принимающей), заменяться символы переноса строки, изменяться максимальная длина строки, изменяться количество пробелов в тексте.
Передача текстовых данных как бинарных приводит к необходимости изменять кодировку в прикладном программном обеспечении (это умеет большинство прикладного ПО, отображающего текст, получаемый из разных источников), передача бинарных данных как текстовых может привести к их необратимому повреждению.
Данные в объектно-ориентированном программировании
Могут обрабатываться функциями объекта, которому принадлежат сами, либо функциями других объектов, имеющими для этого возможность.
Данные в языках разметки
Имеют различное отображение в зависимости от выбранного способа представления.
Данные в XML
В теории множеств
В отличие от операций над элементами множества, представляют собой множество (название и элементы множества)
В лингвистике
В отличие от операций (действие, процесс) по работе с данными (сказуемое с возможными его обстоятельствами и дополнениями), выражаются подлежащим (с возможными его определениями).
Метаданные
Множество данных может иметь надмножество, называемое метаданными. Другими словами, метаданные — это данные о данных.
Операции с данными
Для повышения качества данные преобразуются из одного вида в другой с помощью методов обработки. Обработка данных включает операции:
- ввод (сбор) данных — накопление данных с целью обеспечения достаточной полноты для принятия решений;
- формализация данных — приведение данных, поступающих из разных источников, к одинаковой форме, для повышения их доступности;
- фильтрация данных — это отсеивание «лишних» данных, в которых нет необходимости для повышения достоверности и адекватности;
- сортировка данных — это упорядочивание данных по заданному признаку с целью удобства их использования;
- архивация — это организация хранения данных в удобной и легкодоступной форме;
- защита данных — включает меры, направленные на предотвращение утраты, воспроизведения и модификации данных;
- транспортировка данных — приём и передача данных между участниками информационного процесса;
- преобразование данных — это перевод данных из одной формы в другую или из одной структуры в другую.

Примечания
- ↑ Максимович Г. Ю. Информационные системы : Учебное пособие / Ю. Г. Максимович, А. Г. Романенко, О. Ф. Самойлюк; Под общей ред. К. И. Курбакова. — М.: Изд-во Рос. экон. акад., 1999. — 198 с.
См. также
Данные — это… Что такое Данные?
Да́нные (калька от англ. data[источник не указан 101 день]) — представление фактов и идей в формализованном виде, пригодном для передачи и обработки в некотором информационном процессе.
Изначально — данные величины, то есть величины, заданные заранее, вместе с условием задачи. Противоположность — переменные величины.
В информатике данные — это результат фиксации, отображения информации на каком-либо материальном носителе, то есть зарегистрированное на носителе представление сведений независимо от того, дошли ли эти сведения до какого-нибудь приёмника и интересуют ли они его.[1]
Данные — это и текст книги или письма, и картина художника, и ДНК.
Данные, являющиеся результатом фиксации некоторой информации, сами могут выступать как источник информации. Информация, извлекаемая из данных, может подвергаться обработке, и результаты обработки фиксируются в виде новых данных.
Данные могут рассматриваться как записанные наблюдения, которые не используются, а пока хранятся.
Информация, отображаемая данными, может быть непонятна приемнику (шифрованный текст, текст на неизвестном языке и пр.).
Синонимы: сведения, информация
С точки зрения программиста, данные — это часть программы, совокупность значений определённых ячеек памяти, преобразование которых осуществляет код. С точки зрения компилятора, процессора, операционной системы, это совокупность ячеек памяти, обладающих определёнными свойствами (возможность чтения и записи (необяз.), невозможность исполнения).
Контроль за доступом к данным в современных компьютерах осуществляется аппаратно.
В соответствии с принципом фон Неймана, одна и та же область памяти может выступать как в качестве данных, так и в качестве исполнимого кода.
Типы данных
Традиционно выделяют два типа данных — двоичные (бинарные) и текстовые.
Двоичные данные обрабатываются только специализированным программным обеспечением, знающим их структуру, все остальные программы передают данные без изменений.
Текстовые данные воспринимаются передающими системами как текст, записанный на каком-либо языке. Для них может осуществляться перекодировка (из кодировки отправляющей системы в кодировку принимающей), заменяться символы переноса строки, изменяться максимальная длина строки, изменяться количество пробелов в тексте.
Передача текстовых данных как бинарных приводит к необходимости изменять кодировку в прикладном программном обеспечении (это умеет большинство прикладного ПО, отображающего текст, получаемый из разных источников), передача бинарных данных как текстовых может привести к их необратимому повреждению.
Данные в объектно-ориентированном программировании
Могут обрабатываться функциями объекта, которому принадлежат сами, либо функциями других объектов, имеющими для этого возможность.
Данные в языках разметки
Имеют различное отображение в зависимости от выбранного способа представления.
Данные в XML
В теории множеств
В отличие от операций над элементами множества, представляют собой множество (название и элементы множества)
В лингвистике
В отличие от операций (действие, процесс) по работе с данными (сказуемое с возможными его обстоятельствами и дополнениями), выражаются подлежащим (с возможными его определениями).
Метаданные
Множество данных может иметь надмножество, называемое метаданными. Другими словами, метаданные — это данные о данных.
Операции с данными
Для повышения качества данные преобразуются из одного вида в другой с помощью методов обработки. Обработка данных включает операции:
- ввод (сбор) данных — накопление данных с целью обеспечения достаточной полноты для принятия решений;
- формализация данных — приведение данных, поступающих из разных источников, к одинаковой форме, для повышения их доступности;
- фильтрация данных — это отсеивание «лишних» данных, в которых нет необходимости для повышения достоверности и адекватности;
- сортировка данных — это упорядочивание данных по заданному признаку с целью удобства их использования;
- архивация — это организация хранения данных в удобной и легкодоступной форме;
- защита данных — включает меры, направленные на предотвращение утраты, воспроизведения и модификации данных;
- транспортировка данных — приём и передача данных между участниками информационного процесса;
- преобразование данных — это перевод данных из одной формы в другую или из одной структуры в другую.
Примечания
- ↑ Максимович Г. Ю. Информационные системы : Учебное пособие / Ю. Г. Максимович, А. Г. Романенко, О. Ф. Самойлюк; Под общей ред. К. И. Курбакова. — М.: Изд-во Рос. экон. акад., 1999. — 198 с.
См. также
|
<<Назад | Содержание | Далее>>
Данными называют информацию, когда делают акцент на том, что она поступает в качестве входных параметров некоторого алгоритма обработки. Данные – от слова “дано”, так же как в записи условия задачи мы записываем “дано” и “найти”. Этот термин часто употребляется, когда
речь идет о компьютерных системах. Одни и те же данные,
записанные в компьютерной памяти, могут быть отображены в
зависимости от выбранной программы обработки или как графическая
информация, или как символьная, или как звуковая, или как
числовая. Данные – это любые зарегистрированные сигналы. Слово “информация” чаще используется в более узком смысле, чем просто все, что отражается в материальном объекте в результате воздействия на него другого материального объекта. Предполагается, что получение информации дает получившему ее возможность принимать решения, действовать, осуществлять выбор или пополнить (и/или реструктурировать) свою систему знаний. Если полученные данные не приводят ни к чему из перечисленного, то с субъективной точки зрения считается, что для получателя они информации не несут, хотя и занимают определенный объем его памяти. Говоря об информации и ее свойствах, обычно имеют в виду один из трех аспектов: Технический — точность,
надежность, скорость передачи сигналов, объем, занимаемый в
памяти зарегистрированными сигналами, способы регистрации
сигналов. Прагматический — насколько эффективно информация влияет на поведение получателя. В этом аспекте говорят о полезности и ценности информации. В определенных случаях ценность информации становится отрицательной, а сама информация становится дезинформацией. Это информация в аспекте управления поведением. Семантический — передача смысла с помощью кодов. Семантической называется информация, активизирующая образы, уже имеющиеся в тезаурусе получателя (узнаваемая) или вносящая изменения в его тезаурус (систему знаний). Это информация в аспекте знаний.
<<Назад | Содержание | Далее>> |

 В этом аспекте информация = данные, и никак не
учитывается ее полезность для получателя или ее смысловое
содержание. Это информация в самом широком общем для всей
материи смысле, информация в аспекте восприятия,
хранения, передачи.
В этом аспекте информация = данные, и никак не
учитывается ее полезность для получателя или ее смысловое
содержание. Это информация в самом широком общем для всей
материи смысле, информация в аспекте восприятия,
хранения, передачи.Информация — это продукт взаимодействия данных и адекватных им методов.
Данные — это зарегистрированные сигналы.
Данные и методы
Обратим внимание на то, что данные несут в себе информацию о событиях, произошедших в материальном мире, поскольку они являются регистрацией сигналов, возникших в результате этих событий. Однако данные не тождественны информации. Наблюдая излучения далеких звезд, человек получает определенный поток данных, но станут ли эти данные информацией, зависит еще от очень многих обстоятельств (рис.1).
Рис. 1. Связь между данными и информацией
Понятие об информации
Несмотря на то, что с понятием информации мы сталкиваемся ежедневно, строгого и общепризнанного ее определения до сих пор не существует, поэтому вместо определения обычно используют понятие об информации. Понятия, в отличие от определений, не даются однозначно, а вводятся на примерах, причем каждая научная дисциплина делает это по-своему, выделяя в качестве основных компонентов те, которые наилучшим образом соответствуют ее предмету и задачам.
Понятия, в отличие от определений, не даются однозначно, а вводятся на примерах, причем каждая научная дисциплина делает это по-своему, выделяя в качестве основных компонентов те, которые наилучшим образом соответствуют ее предмету и задачам.
Дадим такое определение информации:
Информация — это продукт взаимодействия данных и адекватных им методов.
Рассмотрим данное выше определение информации и обратим внимание на следующие обстоятельства.
1. Динамический характер информации.
Информация не является статичным объектом — она динамически меняется и существует только в момент взаимодействия данных и методов. Все прочее время она пребывает в состоянии данных.
2. Требование адекватности методов.
Одни и те же данные могут в момент потребления поставлять разную информацию в зависимости от степени адекватности взаимодействующих с ними методов.
3. Диалектический характер взаимодействия данных и методов.
Свойства информации
Итак, информация является динамическим объектом, образующимся в момент взаимодействия объективных данных и субъективных методов. Как и всякий объект, она обладает свойствами (объекты различимы именно по своим свойствам).
Как и всякий объект, она обладает свойствами (объекты различимы именно по своим свойствам).
С точки зрения информатики наиболее важными представляются следующие свойства: объективность, полнота, достоверность, адекватность, доступность и актуальность информации.
1. Объективность и субъективность информации.
Понятие объективности информации является относительным. Это понятно, если учесть, что методы являются субъективными. Более объективной принято считать ту информацию, в которую методы вносят меньший субъективный элемент.
2. Полнота информации.
Полнота информации во многом характеризует качество информации и определяет достаточность данных для принятия решений или для создания новых данных на основе имеющихся. Чем полнее данные, тем шире диапазон методов, которые можно использовать, тем проще подобрать метод, вносящий минимум погрешностей в ход информационного процесса.
3. Достоверность информации.
4. Адекватность информации –
это степень соответствия реальному объективному состоянию дела. Неадекватная информация может образовываться при создании новой информации на основе неполных или недостоверных данных.
Неадекватная информация может образовываться при создании новой информации на основе неполных или недостоверных данных.
5. Доступность информации
— мера возможности получить ту или иную информацию. На степень доступности информации влияют одновременно как доступность данных, так и доступность адекватных методов для их интерпретации.
6. Актуальность информации
— это степень соответствия информации текущему моменту времени.
Операции с данными
В ходе информационного процесса данные преобразуются из одного вида в другой с помощью методов. Обработка данных включает в себя множество различных операций.
В структуре возможных операций с данными можно выделить следующие основные:
- сбор данных — накопление информации с целью обеспечения достаточной полноты для принятия решений;
- формализация данных — приведение данных, поступающих из разных источников, к одинаковой форме;
- фильтрация данных — отсеивание «лишних» данных, в которых нет необходимости для принятия решений;
- сортировка данных — упорядочение данных по заданному признаку с целью
удобства использования; повышает доступность информации;
- архивация данных — организация хранения данных в удобной и легкодоступной форме;
- защита данных — комплекс мер, направленных на предотвращение утраты, воспроизведения и модификации данных;
- транспортировка данных — прием и передача (доставка и поставка) данных между удаленными участниками информационного процесса; при этом источник данных в информатике принято называть сервером, а потребителя — клиентом;
- преобразование данных — перевод данных из одной формы в другую или из
одной структуры в другую.
Основные структуры данных
Работа с большими наборами данных автоматизируется проще, когда данные упорядочены, то есть образуют заданную структуру. Существует три основных типа структур данных: линейная, иерархическая и табличная.
1. Линейные структуры (списки данных, векторы данных)
Линейные структуры — это хорошо знакомые нам списки. Список — это простейшая структура данных, отличающаяся тем, что каждый элемент данных однозначно определяется своим номером в массиве. Проставляя номера на отдельных страницах рассыпанной книги, мы создаем структуру списка.
Разделителем может быть и какой-нибудь специальный символ. Нам хорошо известны разделители между словами — это пробелы. В русском и во многих европейских языках общепринятым разделителем предложений является точка.
Таким образом, линейные структуры данных (списки) — это упорядоченные структуры, в которых адрес элемента однозначно определяется его номером.
2. Табличные структуры (таблицы данных, матрицы данных)
С таблицами данных мы тоже хорошо знакомы, достаточно вспомнить всем известную таблицу умножения. Табличные структуры отличаются от списочных тем, что элементы данных определяются адресом ячейки, который состоит не из одного параметра, как в списках, а из нескольких. Для таблицы умножения, например, адрес ячейки определяется номерами строки и столбца. Нужная ячейка находится на их пересечении, а элемент выбирается из ячейки.
Табличные структуры отличаются от списочных тем, что элементы данных определяются адресом ячейки, который состоит не из одного параметра, как в списках, а из нескольких. Для таблицы умножения, например, адрес ячейки определяется номерами строки и столбца. Нужная ячейка находится на их пересечении, а элемент выбирается из ячейки.
Таким образом, табличные структуры данных (матрицы) — это упорядоченные структуры, в которых адрес элемента определяется номером строки и номером столбца, на пересечении которых находится ячейка, содержащая искомый элемент.
3. Иерархические структуры данных
Нерегулярные данные, которые трудно представить в виде списка или таблицы, часто представляют в виде иерархических структур. С подобными структурами мы очень хорошо знакомы по обыденной жизни. Иерархическую структуру имеет система почтовых адресов. Подобные структуры также широко применяют в научных систематизациях и всевозможных классификациях
В иерархической структуре адрес каждого элемента определяется путем доступа (маршрутом), ведущим от вершины структуры к данному элементу. Вот, например, как выглядит путь доступа к команде, запускающей программу Калькулятор (стандартная программа компьютеров, работающих в операционной системе Windows 98):
Вот, например, как выглядит путь доступа к команде, запускающей программу Калькулятор (стандартная программа компьютеров, работающих в операционной системе Windows 98):
ПускПрограммыСтандартныеКалькулятор.
Дихотомия данных.
Основным недостатком иерархических структур данных является увеличенный размер пути доступа. Очень часто бывает так, что длина маршрута оказывается больше, чем длина самих данных, к которым он ведет. Поэтому в информатике применяют методы для регуляризации иерархических структур с тем, чтобы сделать путь доступа компактным. Один из методов получил название дихотомии.
В иерархической структуре, построенной методом дихотомии, путь доступа к любому элементу можно представить как путь через рациональный лабиринт с поворотами налево (0) или направо (1) и, таким образом, выразить путь доступа в виде компактной двоичной записи.
2. Кодирование данных двоичным кодом. Понятие файла
Для автоматизации работы с данными, относящимися к различным типам, очень важно унифицировать их форму представления — для этого обычно используется прием кодирования, то есть выражение данных одного типа через данные другого типа.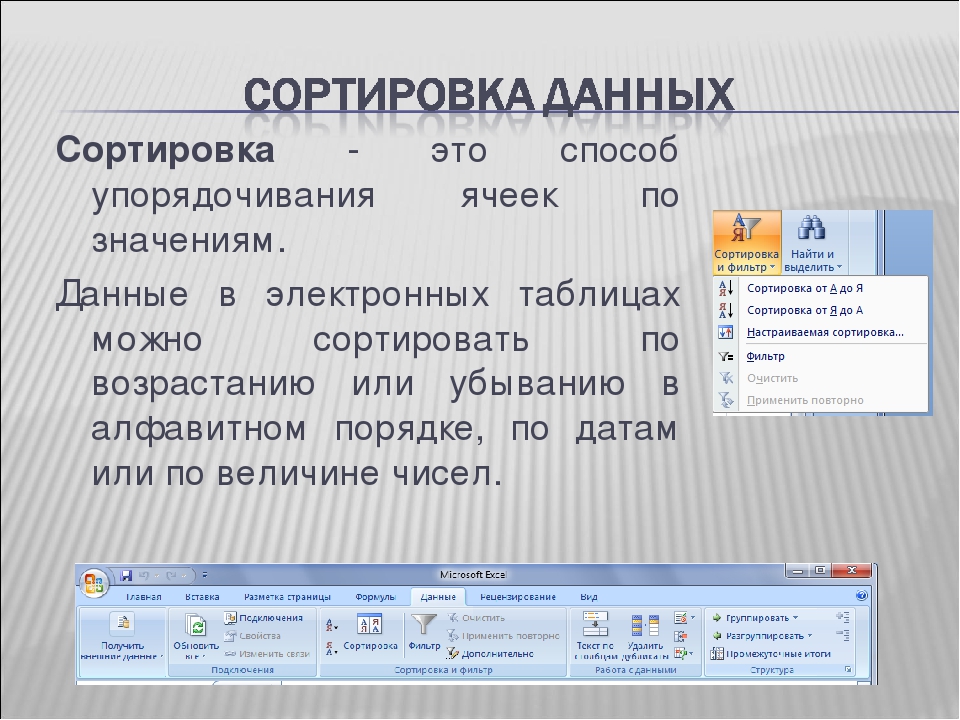
Та же проблема универсального средства кодирования достаточно успешно реализуется в отдельных отраслях техники, науки и культуры. В качестве примеров можно привести систему записи математических выражений, телеграфную азбуку, морскую флажковую азбуку, систему Брайля для слепых и многое другое.
Своя система существует и в вычислительной технике — она называется двоичным кодированием и основана на представлении данных последовательностью всего двух знаков: 0 и 1. Эти знаки называются двоичными цифрами, по-английски — binary digit или, сокращенно, bit (бит).
Одним битом могут быть выражены два понятия: 0 или 1 (да или нет, черное или белое, истина или ложь и т. п.). Если количество битов увеличить до двух, то уже можно выразить четыре различных понятия:
00 01 10 11
Тремя битами можно закодировать восемь различных значений:
000 001 010 011 100 101 110 111
Увеличивая на единицу количество разрядов в системе двоичного кодирования, мы увеличиваем в два раза количество значений, которое может быть выражено в данной системе, то есть общая формула имеет вид:
N=2m,
где N— количество независимых кодируемых значений; m — разрядность двоичного кодирования, принятая в данной системе.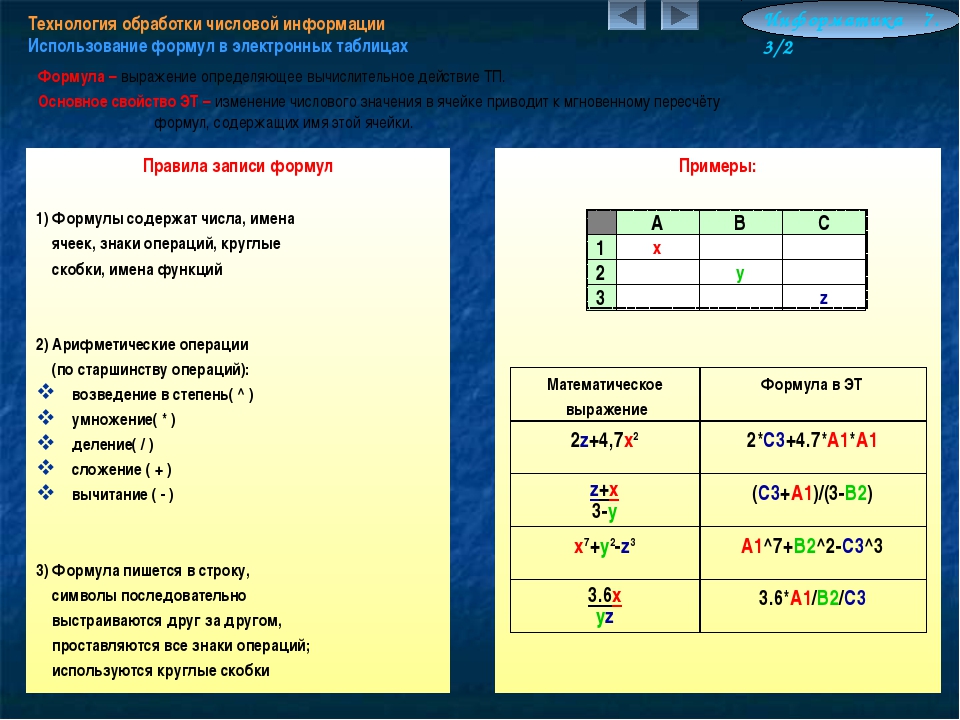
Кодирование целых и действительных чисел
Целые числа кодируются двоичным кодом достаточно просто — достаточно взять целое число и делить его пополам до тех пор, пока в остатке не образуется ноль или единица. Совокупность остатков от каждого деления, записанная справа налево вместе с последним остатком, и образует двоичный аналог десятичного числа.
19:2 = 9 + 1 9:2=4+1 4:2=2+0 2:2=1
Таким образом, 1910= 10112.
Для кодирования целых чисел от 0 до 255 достаточно иметь 8 разрядов двоичного кода (8 бит). Шестнадцать бит позволяют закодировать целые числа от 0 до 65535, а 24 бита — уже более 16,5 миллионов разных значений.
Для кодирования действительных чисел используют 80-разрядное кодирование. При этом число предварительно преобразуется в нормализованную форму.
3,1415926 = 0,31415926• 101, 300 000 = 0,3 •106
123 456 789 = 0,123456789 • 1010
Первая часть числа называется мантиссой, а вторая — характеристикой (или порядком). Большую часть из 80 бит отводят для хранения мантиссы (вместе со знаком) и некоторое фиксированное количество разрядов отводят для хранения характеристики (тоже со знаком).
Кодирование текстовых данных
Если каждому символу алфавита сопоставить определенное целое число (например, порядковый номер), то с помощью двоичного кода можно кодировать и текстовую информацию. Восьми двоичных разрядов достаточно для кодирования 256 различных символов. Этого хватит, чтобы выразить различными комбинациями восьми битов все символы английского и русского языков, как строчные, так и прописные, а также знаки препинания, символы основных арифметических действий и некоторые общепринятые специальные символы, например символ «§».
Для английского языка, захватившего де-факто нишу международного средства общения, противоречия уже сняты. Институт стандартизации США (ANSI — American National Standard Institute) ввел в действие систему кодирования ASCII (American Standard Code for Information Interchange — стандартный код информационного обмена США). В системе ASCII закреплены две таблицы кодирования — базовая и расширенная. Базовая таблица закрепляет значения кодов от 0 до 127, а расширенная относится к символам с номерами от 128 до 255.
Первые 32 кода базовой таблицы, начиная с нулевого, отданы производителям аппаратных средств (в первую очередь производителям компьютеров и печатающих устройств). В этой области размещаются так называемые управляющие коды, которым не соответствуют никакие символы языков, и, соответственно, эти коды не выводятся ни на экран, ни на устройства печати, но ими можно управлять тем, как производится вывод прочих данных.
Начиная с кода 32 по код 127 размещены коды символов английского алфавита, знаков препинания, цифр, арифметических действий и некоторых вспомогательных символов.
Перечислим некоторые распространенные в России кодировки:
1. КОИ-7 (код обмена информацией, семизначный, СССР).
2. Windows-1251
3. КОИ-8 (код обмена информацией, восьмизначный)
4. кодировка ГОСТ и кодировка ГОСТ-альтернативная
Универсальная система кодирования текстовых данных
Если проанализировать организационные трудности, связанные с созданием единой системы кодирования текстовых данных, то можно прийти к выводу, что они вызваны ограниченным набором кодов (256). В то же время очевидно, что если, например, кодировать символы не восьмиразрядными двоичными числами, а числами с большим количеством разрядов, то и диапазон возможных значений кодов станет намного больше. Такая система, основанная на 16-разрядном кодировании символов, получила название универсальной — UNICODE. Шестнадцать разрядов позволяют обеспечить уникальные коды для 65 536 различных символов — этого поля достаточно для размещения в одной таблице символов большинства языков планеты.
В то же время очевидно, что если, например, кодировать символы не восьмиразрядными двоичными числами, а числами с большим количеством разрядов, то и диапазон возможных значений кодов станет намного больше. Такая система, основанная на 16-разрядном кодировании символов, получила название универсальной — UNICODE. Шестнадцать разрядов позволяют обеспечить уникальные коды для 65 536 различных символов — этого поля достаточно для размещения в одной таблице символов большинства языков планеты.
Кодирование графических данных
Если рассмотреть с помощью увеличительного стекла черно-белое графическое изображение, напечатанное в газете или книге, то можно увидеть, что оно состоит из мельчайших точек, образующих характерный узор, называемый растром. Растр — это метод кодирования графической информации, издавна принятый в полиграфии
Поскольку линейные координаты и индивидуальные свойства каждой точки (яркость) можно выразить с помощью целых чисел, то можно сказать, что растровое кодирование позволяет использовать двоичный код для представления графических данных.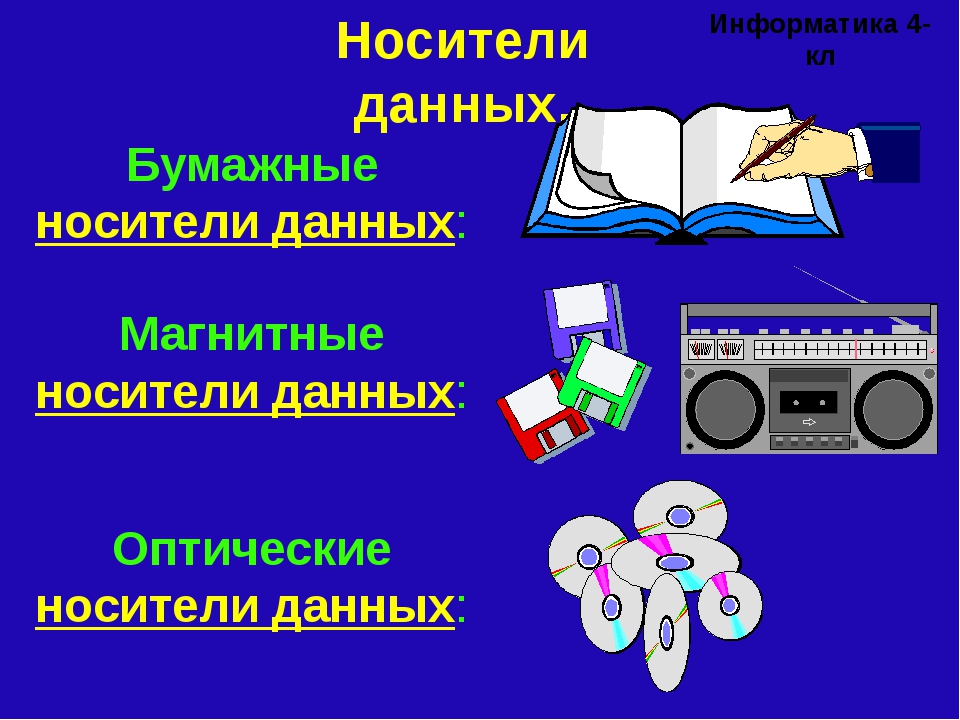 Общепринятым на сегодняшний день считается представление черно-белых иллюстраций в виде комбинации точек с 256 градациями серого цвета, и, таким образом, для кодирования яркости любой точки обычно достаточно восьмиразрядного двоичного числа.
Общепринятым на сегодняшний день считается представление черно-белых иллюстраций в виде комбинации точек с 256 градациями серого цвета, и, таким образом, для кодирования яркости любой точки обычно достаточно восьмиразрядного двоичного числа.
Для кодирования цветных графических изображений применяется принцип декомпозиции произвольного цвета на основные составляющие. В качестве таких составляющих используют три основные цвета: красный (Red, R), зеленый (Green, G) и синий (Blue, В). Такая система кодирования называется системой RGB по первым буквам названий основных цветов.
Режим представления цветной графики с использованием 24 двоичных разрядов называется полноцветным (True Color).
Кодирование цветной графики 16-разрядными двоичными числами называется режимом High Color.
Файлы и файловая структура
Единицы представления данных
Существует множество систем представления данных. С одной из них, принятой в информатике и вычислительной технике, двоичным кодом, мы познакомились выше. Наименьшей единицей такого представления является бит (двоичный разряд).
Наименьшей единицей такого представления является бит (двоичный разряд).
Совокупность двоичных разрядов, выражающих числовые или иные данные, образует некий битовый рисунок. Практика показывает, что с битовым представлением удобнее работать, если этот рисунок имеет регулярную форму. В настоящее время в качестве таких форм используются группы из восьми битов, которые называются байтами.
Выше мы видели, что во многих случаях целесообразно использовать не восьмиразрядное кодирование, а 16-разрядное, 24-разрядное, 32-разрядное и более. Группа из 16 взаимосвязанных бит (двух взаимосвязанных байтов) в информатике называется словом. Соответственно, группы из четырех взаимосвязанных байтов (32 разряда) называются удвоенным словом, а группы из восьми байтов (64 разряда) — учетверенным словом.
Единицы измерения данных
Наименьшей единицей измерения является байт. Поскольку одним байтом, как правило, кодируется один символ текстовой информации, то для текстовых документов размер в байтах соответствует лексическому объему в символах (пока исключение представляет рассмотренная выше универсальная кодировка UNICODE).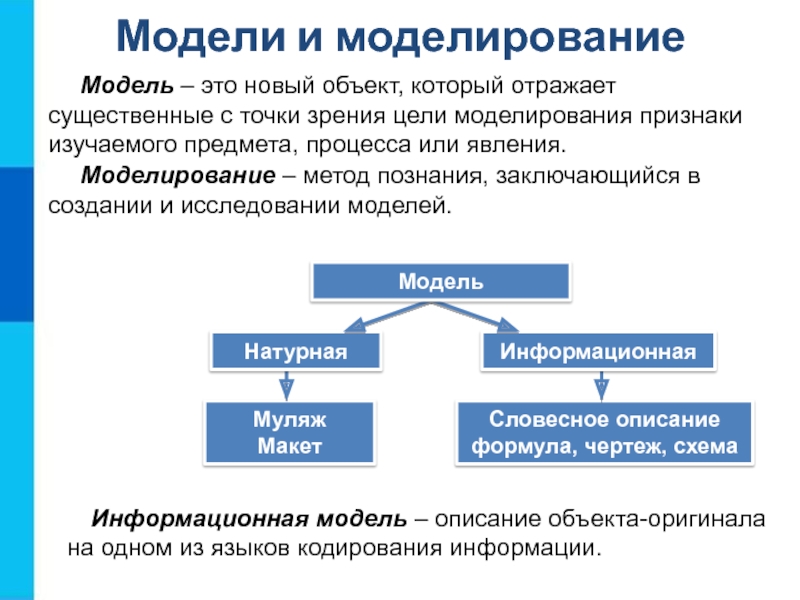
1 Кбайт (kb) = 210 = 1024 байт (b)
1 Мбайт = 1024 Кбайт = 220 байт
1 Гбайт = 1024 Мбайт = 230 байт
1 Тбайт = 1024 Гбайт = 240 байт
Единицы хранения данных
В качестве единицы хранения данных принят объект переменной длины, называемый файлом. Файл — это последовательность произвольного числа байтов, обладающая уникальным собственным именем. Обычно в отдельном файле хранят данные, относящиеся к одному типу. В этом случае тип данных определяет тип файла.
В определении файла особое внимание уделяется имени. Оно фактически несет в себе адресные данные, без которых данные, хранящиеся в файле, не станут информацией из-за отсутствия метода доступа к ним.
Понятие о файловой структуре
Требование уникальности имени файла очевидно — без этого невозможно гарантировать однозначность доступа к данным. В средствах вычислительной техники требование уникальности имени обеспечивается автоматически — создать файл с именем, тождественным уже имеющемуся, не может ни пользователь, ни автоматика.
Хранение файлов организуется в иерархической структуре, которая в данном случае называется файловой структурой. В качестве вершины структуры служит имя носителя, на котором сохраняются файлы. Далее файлы группируются в каталоги (папки), внутри которых могут быть созданы вложенные каталоги (папки). Путь доступа к файлу начинается с имени устройства и включает все имена каталогов (папок), через которые проходит. В качестве разделителя используется символ «\» (обратная косая черта).
Уникальность имени файла обеспечивается тем, что полным именем файла считается собственное имя файла вместе с путем доступа к нему. Понятно, что в этом случае на одном носителе не может быть двух файлов с тождественными полными именами.
Предмет и задачи информатики
Теперь можно сформулировать определение информатики:
Информатика — это техническая наука, систематизирующая приемы создания, хранения, воспроизведения, обработки и передачи данных средствами вычислительной техники, а также принципы функционирования этих средств и методы управления ими.
Предмет информатики составляют следующие понятия:
• аппаратное обеспечение средств вычислительной техники;
• программное обеспечение средств вычислительной техники;
• средства взаимодействия аппаратного и программного обеспечения;
• средства взаимодействия человека с аппаратными и программными средствами.
3. Программное обеспечение (ПО) и его классификация
Программы — это упорядоченные последовательности команд. Конечная цель любой компьютерной программы — управление аппаратными средствами. Даже если на первый взгляд программа никак не взаимодействует с оборудованием, не требует никакого ввода данных с устройств ввода и не осуществляет вывод данных на устройства вывода, все равно ее работа основана на управлении аппаратными устройствами компьютера.
Программное и аппаратное обеспечение в компьютере работают в неразрывной связи и в непрерывном взаимодействии. Несмотря на то что мы рассматриваем эти две категории отдельно, нельзя забывать, что между ними существует диалектическая связь и раздельное их рассмотрение является по меньшей мере условным.
Состав программного обеспечения вычислительной системы называют программной конфигурацией. Между программами, как и между физическими узлами и блоками существует взаимосвязь — многие программы работают, опираясь на другие программы более низкого уровня, то есть мы можем говорить о межпрограммном интерфейсе. Возможность существования такого интерфейса тоже основана на существовании технических условий и протоколов взаимодействия, а на практике он обеспечивается распределением программного обеспечения на несколько взаимодействующих между собой уровней.
Уровни программного обеспечения представляют собой пирамидальную конструкцию. Каждый следующий уровень опирается на программное обеспечение предшествующих уровней. Такое членение удобно для всех этапов работы с вычислительной системой, начиная с установки программ до практической эксплуатации и технического обслуживания. Обратите внимание на то, что каждый вышележащий уровень повышает функциональность всей системы. Так, например, вычислительная система с программным обеспечением базового уровня не способна выполнять большинство функций, но позволяет установить системное программное обеспечение.
Базовый уровень
Самый низкий уровень программного обеспечения представляет базовое программное обеспечение. Оно отвечает за взаимодействие с базовыми аппаратными средствами. Как правило, базовые программные средства непосредственно входят в состав базового оборудования и хранятся в специальных микросхемах, называемых постоянными запоминающими устройствами (ПЗУ — Read Only Memory — ROM). Программы и данные записываются («прошиваются») в микросхемы ПЗУ на этапе производства и не могут быть изменены в процессе эксплуатации.
В тех случаях, когда изменение базовых программных средств во время эксплуатации является технически целесообразным, вместо микросхем ПЗУ применяют перепрограммируемые постоянные запоминающие устройства (ППЗУ — Erasable and Programmable Read Only Memory, EPROM). В этом случае изменение содержания ПЗУ можно выполнять как непосредственно в составе вычислительной системы (такая технология называется флэш-технологией), так и вне нее, на специальных устройствах, называемых программаторами.
Системный уровень.
Системный уровень — переходный. Программы, работающие на этом уровне, обеспечивают взаимодействие прочих программ компьютерной системы с программами базового уровня и непосредственно с аппаратным обеспечением, то есть выполняют «посреднические» функции.
От программного обеспечения этого уровня во многом зависят эксплуатационные показатели всей вычислительной системы в целом. Так, например, при подключении к вычислительной системе нового оборудования на системном уровне должна быть установлена программа, обеспечивающая для других программ взаимосвязь с этим оборудованием. Конкретные программы, отвечающие за взаимодействие с конкретными устройствами, называются драйверами устройств — они входят в состав программного обеспечения системного уровня.
Другой класс программ системного уровня отвечает за взаимодействие с пользователем. Именно благодаря им он получает возможность вводить данные в вычислительную систему, управлять ее работой и получать результат в удобной для себя форме. Эти программные средства называют средствами обеспечения пользовательского интерфейса. От них напрямую зависит удобство работы с компьютером и производительность труда на рабочем месте.
Эти программные средства называют средствами обеспечения пользовательского интерфейса. От них напрямую зависит удобство работы с компьютером и производительность труда на рабочем месте.
Совокупность программного обеспечения системного уровня образует ядро операционной системы компьютера. Полное понятие операционной системы мы рассмотрим несколько позже, а здесь только отметим, что если компьютер оснащен программным обеспечением системного уровня, то он уже подготовлен к установке программ более высоких уровней, к взаимодействию программных средств с оборудованием и, самое главное, к взаимодействию с пользователем. То есть наличие ядра операционной системы — непременное условие для возможности практической работы человека с вычислительной системой.
Служебный уровень.
Программное обеспечение этого уровня взаимодействует как с программами базового уровня, так и с программами системного уровня. Основное назначение служебных программ (их также называют утилитами) состоит в автоматизации работ по проверке, наладке и настройке компьютерной системы. Во многих случаях они используются для расширения или улучшения функций системных программ. Некоторые служебные программы (как правило, это программы обслуживания) изначально включают в состав операционной системы, но большинство служебных программ являются для операционной системы внешними и служат для расширения ее функций.
Во многих случаях они используются для расширения или улучшения функций системных программ. Некоторые служебные программы (как правило, это программы обслуживания) изначально включают в состав операционной системы, но большинство служебных программ являются для операционной системы внешними и служат для расширения ее функций.
В разработке и эксплуатации служебных программ существует два альтернативных направления: интеграция с операционной системой и автономное функционирование. В первом случае служебные программы могут изменять потребительские свойства системных программ, делая их более удобными для практической работы. Во втором случае они слабо связаны с системным программным обеспечением, но предоставляют пользователю больше возможностей для персональной настройки их взаимодействия с аппаратным и программным обеспечением.
Прикладной уровень.
Программное обеспечение прикладного уровня представляет собой комплекс прикладных программ, с помощью которых на данном рабочем месте выполняются конкретные задания.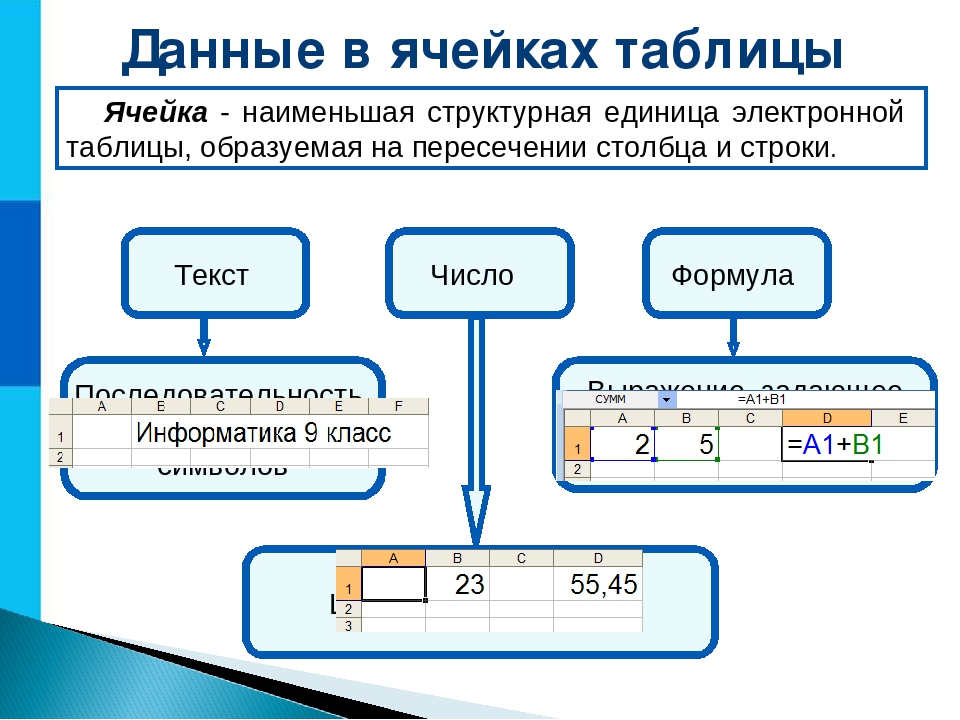 Спектр этих заданий необычайно широк: от производственных до творческих и развлекательно-обучающих. Огромный функциональный диапазон возможных приложений средств вычислительной техники обусловлен наличием прикладных программ для разных видов деятельности.
Спектр этих заданий необычайно широк: от производственных до творческих и развлекательно-обучающих. Огромный функциональный диапазон возможных приложений средств вычислительной техники обусловлен наличием прикладных программ для разных видов деятельности.
Поскольку между прикладным программным обеспечением и системным существует непосредственная взаимосвязь (первое опирается на второе), то можно утверждать, что универсальность вычислительной системы, доступность прикладного программного обеспечения и широта функциональных возможностей компьютера напрямую зависят от типа используемой операционной системы, от того, какие системные средства содержит ее ядро, как она обеспечивает взаимодействие триединого комплекса человек — программы — оборудование.
Классификация прикладных программных средств
Существует несколько различных классификаций ПО. Одна из них базируется на вышеперечисленных уровнях программного обеспечения: в такой классификации рассматривают базовое, системное, служебное и прикладное ПО. Мы остановимся на другой, несколько отличающейся классификации.
Все многообразие ПО разделим на 3 основные группы:
1. Системное ПО
2. Инструментальное ПО
3. Прикладное ПО
Рассмотрим каждую из этих групп в отдельности.
Системное ПО
Системное ПО (systems software) предназначено для обеспечения работы аппаратуры компьютера, обеспечения логического интерфейса между устройствами, поддержания протоколов хранения информации и выполнения служебных функций.
Из этого определения, вообще говоря, следует, что в данной классификации в системное ПО включаются программные средства базового, системного и служебного уровня.
Состав системного ПО
1. BIOS (basic input/output system, базовая система ввода/вывода) – относится к базовому уровню ПО, BIOS образует комплекс программ, находящихся в ПЗУ. Основное назначение программ этого пакета состоит в том, чтобы проверить состав и работоспособность компьютерной системы и обеспечить взаимодействие с клавиатурой, монитором, жестким диском и дисководом гибких дисков. Программы, входящие в BIOS, позволяют наблюдать диагностические сообщения, сопровождающие запуск компьютера, и вмешиваться в ход запуска с помощью клавиатуры.
2. ОС (operating system, operational system, операционная система) – системный уровень. ОС представляет собой комплекс системных и служебных программных средств. ОС, с одной стороны, опирается на базовое ПО, входящее в систему BIOS, с другой стороны, она сама является опорой для ПО более высоких уровней.
Приложениями ОС называют программы, предназначенные для работы под управлением данной системы.
Таким образом, ОС – это программа, которая распоряжается различными ресурсами ЭВМ и предоставляет их пользователю. ОС дает пользователям возможность запускать свои программы, управлять периферийным устройствами, обеспечивает работу файловой системы и т.д. // DOS (disk operating system), MS Windows, Linux, Unix…
3. Драйверы (driver) – системный уровень. Драйверы – это программы, предназначенные для осуществления логического интерфейса между устройствами.
4. Сервисные программы и утилиты – служебный уровень. Предназначены для настройки, мониторинга и адаптации ОС. // Проверка системы, проверка дисков, дефрагментация дисков, мониторы установки…
5. Файловые оболочки/ навигаторы – служебный уровень. С помощью программ данного класса выполняется большинство операций, связанных с обслуживанием файловой структуры: копирование, перемещение и переименование файлов, создание каталогов (папок), удаление файлов и каталогов, поиск файлов и навигация в файловой структуре. Базовые программные средства, предназначенные для этой цели, обычно входят в состав программ системного уровня и устанавливаются вместе с операционной системой. Однако для повышения удобства работы с компьютером большинство пользователей устанавливают дополнительные служебные программы. // Проводник Windows, Volkov Commander, Norton Commander, Windows Commander…
6. Сетевое ПО(network applications) – служебный уровень. Конгломерат драйверов, программ, реализующих транспортный протокол; позволяет работать в сети.
7. Средства администрирования – позволяют ограничить или разрешить доступ пользователю к файлам ЭВМ.
Прикладное ПО
Прикладное ПО (application software) предназначено для облегчения работы пользователей ЭВМ в различных предметных областях.
Прикладное ПО относится к прикладному уровню ПО.
Состав прикладного ПО:
1. Офисное ПО (office software) – предназначено для автоматизации и подготовки ежедневных документов:
- текстовые редакторы и процессоры // MS Office Word
Текстовые редакторы. Основные функции этого класса прикладных программ заключаются во вводе и редактировании текстовых данных. Дополнительные функции состоят в автоматизации процессов ввода и редактирования. Для операций ввода, вывода и сохранения данных текстовые редакторы вызывают и используют системное программное обеспечение. Впрочем, это характерно и для всех прочих видов прикладных программ, и в дальнейшем мы не будем специально указывать на этот факт. С этого класса прикладных программ обычно начинают знакомство с программным обеспечением и на нем отрабатывают первичные навыки взаимодействия с компьютерной системой.
Текстовые процессоры. Основное отличие текстовых процессоров от текстовых редакторов в том, что они позволяют не только вводить и редактировать текст, но и форматировать его, то есть оформлять. Соответственно, к основным средствам текстовых процессоров относятся средства обеспечения взаимодействия текста, графики, таблиц и других объектов, составляющих итоговый документ, а к дополнительным — средства автоматизации процесса форматирования.
- электронные таблицы // MS Office Excel
Электронные таблицы предоставляют комплексные средства для хранения различных типов данных и их обработки. В некоторой степени они аналогичны системам управления базами данных, но основной акцент смещен не на хранение массивов данных и обеспечение к ним доступа, а на преобразование данных, причем в соответствии с их внутренним содержанием.
Основное свойство электронных таблиц состоит в том, что при изменении содержания любых ячеек таблицы может происходить автоматическое изменение содержания во всех прочих ячейках, связанных с измененными соотношением, заданным математическими или логическими выражениями (формулами). Простота и удобство работы с электронными таблицами снискали им широкое применение в сфере бухгалтерского учета, в качестве универсальных инструментов анализа финансовых, сырьевых и товарных рынков, доступных средств обработки результатов технических испытаний, то есть всюду, где необходимо автоматизировать регулярно повторяющиеся вычисления достаточно больших объемов числовых данных.
- презентационные пакеты //MS Office Power Point
2. Деловое ПО (business software) – предназначено для автоматизации бизнес – процессов.
- бухгалтерское и финансовое ПО // 1C: Бухгалтерия…
- генераторы отчетов (report generator, reporter, report writer)
- средства управления базами данных (database software) // InterBase, MS Access, Oracle…
Базами данных (database) называют огромные массивы данных, организованных в табличные структуры.
Основными функциями систем управления базами данных являются:
а) создание пустой (незаполненной) структуры базы данных;
б) предоставление средств ее заполнения или импорта данных из таблиц другой базы;
в) обеспечение возможности доступа к данным, а также предоставление средств поиска и фильтрации.
Многие системы управления базами данных дополнительно предоставляют возможности проведения простейшего анализа данных и их обработки. В результате возможно создание новых таблиц баз данных на основе имеющихся. В связи с широким распространением сетевых технологий к современным системам управления базами данных предъявляется также требование возможности работы с удаленными и распределенными ресурсами, находящимися на серверах всемирной компьютерной сети.
- ERP-systems (enterprise resource planning, планирование ресурсов предприятий) – комплексная автоматизация бизнес-процессов и распределения ресурсов
- DSS-systems(Decision Support System, система поддержки принятия решений)
- Экспертные системы/ Справочно-правовые системы
Предназначены для анализа данных, содержащихся в базах знаний, и выдачи рекомендаций по запросу пользователя. Такие системы применяют в тех случаях, когда исходные данные хорошо формализуются, но для принятия решения требуются обширные специальные знания. Характерными областями использования экспертных систем являются юриспруденция, медицина, фармакология, химия. По совокупности признаков заболевания медицинские экспертные системы помогают установить диагноз и назначить лекарства, дозировку и программу лечебного курса. По совокупности признаков события юридические экспертные системы могут дать правовую оценку и предложить порядок действий как для стороны обвинения, так и для стороны защиты.
Коммуникационное ПО
- почтовые программы(male clients) // MS Outlook, The Bat…
- Браузеры(browser) // Internet Explorer, Opera, Netscape Navigator…
К этой категории относятся программные средства, предназначенные для просмотра электронных документов, выполненных в формате HTML (документы этого формата используются в качестве Web-документов). Современные браузеры воспроизводят не только текст и графику. Они могут воспроизводить музыку, человеческую речь, обеспечивать прослушивание радиопередач в Интернете, просмотр видеоконференций, работу со службами электронной почты, с системой телеконференций (групп новостей) и многое другое.
Статьи к прочтению:
Информатика. Выпуск 2. Информация и ее кодирование.
Похожие статьи:
1 Понятие информация — Сайт программирования!
Понятие«информация».
Слово «информация» происходит от латинского слова informatio, что в переводеозначает сведение, разъяснение, ознакомление. Понятие «информация» являетсябазовым в курсе информатики, невозможно дать его определение через другие,более «простые» понятия. В геометрии, например, невозможно выразить содержаниебазовых понятий «точка», «луч», «плоскость» через более простые понятия.Содержание основных, базовых понятий в любой науке должно быть пояснено напримерах или выявлено путем их сопоставления с содержанием других понятий.
В случае с понятием «информация» проблема его определения еще более сложная,так как оно является общенаучным понятием. Данное понятие используется вразличных науках (информатике, кибернетике, биологии, физике и др.), при этом вкаждой науке понятие «информация» связано с различными системами понятий.
Информация в физике. В физике мерой беспорядка, хаоса длятермодинамической системы является энтропия системы, тогда как информация(антиэнтропия) является мерой упорядоченности и сложности системы. По мереувеличения сложности системы величина энтропии уменьшается, и величинаинформации увеличивается. Процесс увеличения информации характерен дляоткрытых, обменивающихся веществом и энергией с окружающей средой,саморазвивающихся систем живой природы (белковых молекул, организмов, популяцийживотных и так далее).
Таким образом, в физике информация рассматривается как антиэнтропия илиэнтропия с обратным знаком.
Информация в биологии. В биологии, которая изучает живую природу,понятие «информация» связывается с целесообразным поведением живых организмов.Такое поведение строится на основе получения и использования организмоминформации об окружающей среде.
Понятие «информация» в биологии используется также в связи с исследованиямимеханизмов наследственности. Генетическая информация передается по наследству ихранится во всех клетках живых организмов. Гены представляют собой сложныемолекулярные структуры, содержащие информацию о строении живых организмов.Последнее обстоятельство позволило проводить научные эксперименты поклонированию, то есть созданию точных копий организмов из одной клетки.
Информация в кибернетике. В кибернетике (науке об управлении) понятие«информация» связано с процессами управления в сложных системах (живыхорганизмах или технических устройствах). Жизнедеятельность любого организма илинормальное функционирование технического устройства зависит от процессовуправления, благодаря которым поддерживаются в необходимых пределах значения ихпараметров. Процессы управления включают в себя получение, хранение,преобразование и передачу информации.
Социально значимые свойства информации. Человек — существосоциальное, для общения с другими людьми он должен обмениваться с нимиинформацией, причем обмен информацией всегда производится на определенном языке— русском, английском и так далее. Участники дискуссии должны владеть темязыком, на котором ведется общение, тогда информация будет понятной всемучастникам обмена информацией.
—
Информация должна быть полезной, тогда дискуссия приобретаетпрактическую ценность. Бесполезная информация создает информационный шум,который затрудняет восприятие полезной информации. Примерами передачи иполучения бесполезной информации могут служить некоторые конференции и чаты вИнтернете.
Широко известен термин «средства массовой информации» (газеты, радио,телевидение), которые доводят информацию до каждого члена общества. Такаяинформация должна быть достоверной и актуальной. Недостовернаяинформация вводит членов общества в заблуждение и может быть причинойвозникновения социальных потрясений. Неактуальная информация бесполезна ипоэтому никто, кроме историков, не читает прошлогодних газет.
Для того чтобы человек мог правильно ориентироваться в окружающем мире,информация должна быть полной и точной. Задача получения полной иточной информации стоит перед наукой. Овладение научными знаниями в процессеобучения позволяют человеку получить полную и точную информацию о природе,обществе и технике.
Единицы измерения количестваинформации.
Информация и знания. Человек получает информацию из окружающего мирас помощью органов чувств, анализирует ее и выявляет существенные закономерностис помощью мышления, хранит полученную информацию в памяти. Процесссистематическог
о научного познания окружающего мира приводит к накоплениюинформации в форме знаний (фактов, научных теорий и так далее). Таким образом,с точки зрения процесса познания информация может рассматриваться как знания.
Информацию, которую получает человек, можно считать мерой уменьшениянеопределенности знаний. Если некоторое сообщение приводит к уменьшениюнеопределенности наших знаний, то можно говорить, что такое сообщение содержитинформацию.
Уменьшение неопределенности знаний. Подход к информации как мереуменьшения неопределенности знаний позволяет количественно измерять информацию,что чрезвычайно важно для информатики. Рассмотрим вопрос об определенииколичества информации более подробно на конкретных примерах.
Пусть у нас имеется монета, которую мы бросаем на ровную поверхность. Сравной вероятностью произойдет одно из двух возможных событий — монета окажетсяв одном из двух положений: «орел» или «решка».
Можно говорить, что события равновероятны, если при возрастающем числе опытовколичества выпадений «орла» и «решки» постепенно сближаются. Например, если мыбросим монету 10 раз, то «орел» может выпасть 7 раз, а решка — 3 раза, еслибросим монету 100 раз, то «орел» может выпасть 60 раз, а «решка» — 40 раз, еслибросим монету 1000 раз, то «орел» может выпасть 520 раз, а «решка» — 480 и такдалее.
В итоге при очень большой серии опытов количества выпадений «орла» и «решки»практически сравняются.
Перед броском существует неопределенность наших знаний (возможны два события),и, как упадет монета, предсказать невозможно. После броска наступает полнаяопределенность, так как мы видим (получаем зрительное сообщение), что монета вданный момент находится в определенном положении (например, «орел»). Этосообщение приводит к уменьшению неопределенности наших знаний в два раза, таккак до броска мы имели два вероятных события, а после броска — только одно, тоесть в два раза меньше.
В окружающей действительности достаточно часто встречаются ситуации, когдаможет произойти некоторое количество равновероятных событий. Так, при бросанииравносторонней четырехгранной пирамиды существуют 4 равновероятных события, апри бросании шестигранного игрального кубика — 6 равновероятных событий.
Чем больше количество возможных событий, тем больше начальнаянеопределенность и соответственно тем большее количество информации будетсодержать сообщение о результатах опыта.
Единицы измерения количества информации. Для количественноговыражения любой величины необходимо определить единицу измерения. Так, дляизмерения длины в качестве единицы выбран метр, для измерения массы — килограмми так далее. Аналогично, для определения количества информации необходимоввести единицу измерения.
За единицу количества информации принимается такое количество информации,которое содержит сообщение, уменьшающее неопределенность в два раза. Такаяединица названа «бит».
Если вернуться к опыту с бросанием монеты, то здесь неопределенность как разуменьшается в два раза и, следовательно, полученное количество информации равно1 биту.
Минимальной единицей измерения количества информации является бит, аследующей по величине единицей является байт, причем 1 байт = 23 бит= 8 бит.
В информатике система образования кратных единиц измерения количестваинформации несколько отличается от принятых в большинстве наук. Традиционныеметрические системы единиц, например Международная система единиц СИ, вкачестве множителей кратных единиц используют коэффициент 10n, где n= 3, 6, 9 и так далее, что соответствует десятичным приставкам Кило (103),Мега (106), Гига (109) и так далее.
Компьютер оперирует числами не в десятичной, а в двоичной системе счисления,поэтому в кратных единицах измерения количества информации используетсякоэффициент 2n.
Так, кратные байту единицы измерения количества информации вводятся следующимобразом:
1 Кбайт = 210 байт = 1024 байт-
1 Мбайт = 210 Кбайт = 1024 Кбайт-
1 Гбайт = 210 Мбайт = 1024 Мбайт. —
Количество возможных событий и количество информации. Существуетформула, которая связывает между собой количество возможных событий N иколичество информации I: N=2I.
По этой формуле можно легко определить количество возможных событий, еслиизвестно количество информации. Например, если мы получили 4 бита информации,то количество возможных событий составляло: N = 24= 16.
Наоборот, для определения количества информации, если известно количе
ствособытий, необходимо решить показательное уравнение относительно I. Например, вигре «Крестики-нолики» на поле 8×8 перед первым ходом существует возможныхсобытия (64 различных варианта расположения «крестика»), тогда уравнениепринимает вид: 64 = 2I.
Так как 64 = 26, то получим: 26 = 2I.
Таким образом, I = 6 битов, то есть количество информации, полученное вторымигроком после первого хода первого игрока, составляет 6 битов.
Алфавитный подход к определению количества информации.
При определении количества информации на основе уменьшения неопределенностинаших знаний мы рассматриваем информацию с точки зрения содержания, еепонятности и новизны для человека. С этой точки зрения в опыте по бросаниюмонеты одинаковое количество информации содержится и в зрительном образеупавшей монеты, и в коротком сообщении «Орел», и в длинной фразе «Монета упалана поверхность земли той стороной вверх, на которой изображен орел».
Однако при хранении и передаче информации с помощью технических устройствцелесообразно отвлечься от содержания информации и рассматривать ее какпоследовательность знаков (букв, цифр, кодов цветов точек изображения и такдалее).
Набор символов знаковой системы (алфавит) можно рассматривать как различныевозможные состояния (события). Тогда, если считать, что появление символов всообщении равновероятно, по формуле можно рассчитать, какое количествоинформации несет каждый символ.
Так, в русском алфавите, если не использовать букву ё, количество событий(букв) будет равно 32. Тогда: 32 = 2I,откуда I = 5 битов.
Каждый символ несет 5 битов информации (его информационная емкость равна 5битов). Количество информации в сообщении можно подсчитать, умножив количествоинформации, которое несет один символ, на количество символов.
Количество информации, которое содержит сообщение, закодированное с помощьюзнаковой системы, равно количеству информации, которое несет один знак,умноженному на количество знаков.
Что такое данные? — Определение с сайта WhatIs.com
В вычислениях данные — это информация, переведенная в форму, эффективную для перемещения или обработки. По сравнению с современными компьютерами и средствами передачи данные — это информация, преобразованная в двоичную цифровую форму. Допускается использование данных как предмет единственного или множественного числа. Необработанные данные — это термин, используемый для описания данных в их самом основном цифровом формате.
Концепция данных в контексте вычислений уходит корнями в работы Клода Шеннона, американского математика, известного как отец теории информации.Он положил начало двоично-цифровым концепциям, основанным на применении двухзначной булевой логики к электронным схемам. Форматы двоичных цифр лежат в основе процессоров, полупроводниковой памяти и дисковых накопителей, а также многих периферийных устройств, распространенных сегодня в вычислительной технике. Ранний компьютерный ввод как для управления, так и для данных принимал форму перфокарт, за которыми следовали магнитная лента и жесткий диск.
Вначале важность данных в бизнес-вычислениях стала очевидной из-за популярности терминов «обработка данных» и «электронная обработка данных», которые на какое-то время стали охватывать весь спектр того, что сейчас известно как информационные технологии.За всю историю корпоративных вычислений произошла специализация, и вместе с ростом корпоративной обработки данных возникла отдельная профессия, связанная с данными.
Как хранятся данныеКомпьютеры представляют данные, включая видео, изображения, звуки и текст, в виде двоичных значений с использованием шаблонов всего из двух чисел: 1 и 0. Бит — это наименьшая единица данных, представляющая только одно значение. Байт состоит из восьми двоичных цифр. Хранение и память измеряются в мегабайтах и гигабайтах.
Единицы измерения данных продолжают расти по мере увеличения количества собираемых и сохраняемых данных. Например, относительно новый термин «бронтобайт» — это хранилище данных, равное 10-27-й степени байтов.
Данные могут храниться в файловых форматах, как в системах мэйнфреймов, использующих ISAM и VSAM. Другие форматы файлов для хранения, преобразования и обработки данных включают значения, разделенные запятыми. Эти форматы продолжали находить применение на различных типах машин, даже когда подходы, ориентированные на структурированные данные, получили распространение в корпоративных вычислениях.
Более широкая специализация развивалась как база данных, система управления базами данных, а затем возникла технология реляционных баз данных для организации информации.
Диапазон цифровых данных с течением времени вырос с битов и байтов до бронтобайтов, и в будущем объем данных будет еще больше. Типы данныхРост Интернета и смартфонов за последнее десятилетие привел к резкому росту создания цифровых данных. Данные теперь включают текстовую, аудио- и видеоинформацию, а также записи журнала и веб-активности.По большей части это неструктурированные данные.
Термин «большие данные» используется для описания данных размером в петабайт или больше. Сокращенный дубль изображает большие данные с тремя аспектами — объемом, разнообразием и скоростью. По мере распространения электронной коммерции через Интернет развивались бизнес-модели, основанные на больших данных, которые рассматривают данные как сам по себе актив. Такие тенденции также вызвали большее беспокойство по поводу использования данных в социальных сетях и конфиденциальности данных.
Данные имеют значение не только в вычислительных приложениях, ориентированных на обработку данных.Например, во взаимном подключении электронных компонентов и сетевой связи термин «данные» часто отличается от «управляющей информации», «управляющих битов» и подобных терминов для идентификации основного содержимого блока передачи. Более того, в науке термин «данные» используется для описания совокупности фактов. То же самое и в таких областях, как финансы, маркетинг, демография и здоровье.
Управление данными и их использование
С увеличением количества данных в организациях, дополнительный упор был сделан на обеспечение качества данных за счет уменьшения дублирования и гарантии использования наиболее точных текущих записей.Многие этапы современного управления данными включают в себя очистку данных, а также процессы извлечения, преобразования и загрузки (ETL) для интеграции данных. Данные для обработки стали дополняться метаданными, иногда называемыми «данными о данных», которые помогают администраторам и пользователям понимать базу данных и другие данные.
Аналитика, объединяющая структурированные и неструктурированные данные, стала полезной, поскольку организации стремятся извлечь выгоду из такой информации. Системы для такой аналитики все чаще стремятся к производительности в реальном времени, поэтому они созданы для обработки входящих данных, потребляемых с высокой скоростью приема, и для обработки потоков данных для немедленного использования в операциях.
Со временем идея базы данных для операций и транзакций была расширена до базы данных для отчетов и прогнозного анализа данных. Главный пример — хранилище данных, которое оптимизировано для обработки вопросов об операциях для бизнес-аналитиков и руководителей предприятий. Повышенное внимание к поиску закономерностей и прогнозированию бизнес-результатов привело к развитию методов интеллектуального анализа данных.
Специалисты по обработке данныхПрофессия администратора баз данных является ответвлением ИТ.Эти эксперты по базам данных работают над проектированием, настройкой и обслуживанием базы данных.
Специалисты по работе с данными прочно укоренились, поскольку система управления реляционными базами данных (СУБД) стала широко использоваться в корпорациях, начиная с 1980-х годов. Росту реляционной базы данных частично способствовал язык структурированных запросов (SQL). Позже базы данных, отличные от SQL, известные как базы данных NoSQL, возникли как альтернатива установленным СУБД.
Сегодня компании нанимают профессионалов в области управления данными или назначают их ответственными за управление данными, что включает в себя выполнение политик использования данных и безопасности, как указано в инициативах по управлению данными.
Особое название — data science — появилось для описания профессионалов, занимающихся интеллектуальным анализом и анализом данных. Преимущество представления науки о данных в запоминающейся манере даже привело к появлению художника по данным; то есть человек, умеющий создавать графики и визуализировать данные творческими способами.
Что такое данные?
Обновлено: 06.03.2020, Computer Hope
В общем, данные — это любой набор символов, который собирается и переводится для какой-то цели, обычно для анализа.Если данные не помещаются в контекст, они ничего не делают с человеком или компьютером.
Есть несколько типов данных. Вот некоторые из наиболее распространенных типов данных:
В памяти компьютера цифровые данные представляют собой последовательность битов (двоичных цифр), которые имеют значение один или ноль. Данные обрабатываются ЦП, который использует логические операции для создания новых данных (вывода) из исходных данных (ввода).
Примеры компьютерных данных
Джо, Смит, 1234 Circle, SLC, UT, 8404,8015553211
0143 0157 0155 0160 0165 0164 0145 0162 0040 0150 0157 0160 0145
01100011011011110110110101110000011101010111010001100101011100100010000001101000000101
Как данные хранятся на компьютере?
Данные и информация хранятся на компьютере с помощью жесткого диска или другого запоминающего устройства.
Мобильные данные
В смартфонах и других мобильных устройствах термин «данные» используется для описания любых данных, передаваемых устройством через Интернет по беспроводной сети. См. Наше определение тарифного плана для получения дополнительной информации.
Грамматическое использование
Слово данные технически является существительным множественного числа, например, «данные обрабатываются». Единственная форма данных — это данные , от латинского слова, означающего «что-то данное».
Хотя использование данных как существительного во множественном числе технически правильно, в современном использовании данные также принимаются как существительное в единственном числе, например: «Данные обрабатываются.«
Как вы произносите данные?
Произношение «данные» может варьироваться в зависимости от части мира человека, говорящего это слово. Во всем мире это произносится как day-ta, dat-ta, dah-ta или dar-ta. В Америке это чаще всего произносится как day-ta и dat-ta.
Поскольку произношение данных отличается в зависимости от региона, все ранее упомянутые варианты произношения считаются правильными. Однако мы рекомендуем использовать произношение, которое чаще всего используется в вашем районе проживания.
Условия искусственного интеллекта, Калибровка, Сбор данных, Условия базы данных, Манипулирование данными, Интеллектуальный анализ данных, Обработка данных, Восстановление данных, Информация, Инструкция, Массаж, Необработанные данные, Санитарные данные, Исходные данные, Условия электронных таблиц
Что такое данные? — Типы, источники и определение — Видео и стенограмма урока
Сравнение аналоговых и цифровых данных
Существует два основных способа представления данных: аналоговый и цифровой. Аналоговые данные являются непрерывными — они «аналогичны» фактическим фактам, которые они представляют. Цифровые данные дискретны и разбиты на ограниченное количество элементов. Природа аналоговая, а компьютеры — цифровые.
Многие аспекты нашего природного мира имеют непрерывный характер. Например, подумайте о спектре цветов. Это сплошная радуга бесконечного множества оттенков. Компьютерные системы, с другой стороны, не непрерывны, а конечны. Все данные хранятся в двоичных цифрах, и существует ограничение на количество данных, которые мы можем представить. Например, цветное изображение на компьютере имеет ограниченное количество цветов — число может быть очень большим, но все же конечным.
Рассмотрим подробнее пример цвета. Самые первые мониторы представляли собой текстовые терминалы только с одним цветом. На черном фоне появился белый или светло-зеленый текст. В более новых мониторах использовалось больше цветов, достаточное для представления основных изображений, но все же было довольно ограничено. Современные дисплеи имеют миллионы цветов и выглядят намного естественнее. Но количество цветов конечно.
Типы данных
Компьютерные системы работают с различными типами цифровых данных.На заре компьютерных технологий данные состояли в основном из текста и чисел; однако в современных вычислениях существует множество различных типов мультимедийных данных, таких как аудио, изображения, графика и видео. Но, в конечном итоге, все типы данных хранятся в виде двоичных цифр. Для каждого типа данных существуют очень специфические методы преобразования между двоичным языком компьютеров и тем, как мы интерпретируем данные с помощью наших органов чувств, таких как зрение и звук.
Базы данных
Мы не можем говорить о данных без упоминания базы данных.База данных — это организованный набор данных. Вместо того, чтобы иметь все данные в списке со случайным порядком, база данных предоставляет структуру для организации данных. Одна из наиболее распространенных структур данных — это таблица базы данных. Таблица состоит из строк и столбцов. Каждая строка обычно называется записью, а каждый столбец — полем.
Это пример простой таблицы клиентов базы данных. У каждого покупателя есть уникальный идентификатор (Customer ID), имя и номер телефона — это поля.Первая строка называется строкой заголовка и указывает имя каждого поля. После строки заголовка каждая запись представляет собой уникального клиента.
Хотя этот пример очень прост, вы можете легко представить, что еще может храниться в такой базе данных. Например, вы можете хранить почтовые адреса клиентов, платежную информацию, историю прошлых покупок и т. Д. Для организации с тысячами клиентов это быстро превращается в большую базу данных.
Чтобы эффективно использовать большую базу данных, вы можете использовать систему управления базами данных. Система управления базами данных — это специализированное программное обеспечение для ввода, хранения, извлечения и управления всеми данными.
Данные и информация
Теперь давайте рассмотрим разницу между данными и информацией. Они оба связаны, но различать их полезно, особенно при работе с компьютерными системами. Данные — это базовые ценности. Они могут быть неструктурированными и не иметь контекста.Например, список текстовых записей и список чисел будет считаться данными.
Информация помогает нам отвечать на вопросы. Для этого данные должны быть организованы или обработаны удобным образом. Например, список текстовых номеров может быть списком имен клиентов, а список номеров может быть их телефонными номерами. Знание того, что представляют данные — и какое имя принадлежит какому номеру — дает структуру и контекст для данных, что приводит к информации.
Различие между данными и информацией полезно, но зависит от точки зрения пользователя.Например, если вы хотите сделать коммерческие звонки, список имен и номеров телефонов клиентов не очень информативен — вы хотите знать, что они покупали в прошлом, в каком виде бизнеса они находятся, насколько велика их организация. есть и т. д. Итак, с этой точки зрения список имен и телефонных номеров — это просто данные, и вам нужны дополнительные данные, чтобы получить информацию, которая вас действительно интересует.
Резюме урока
Давайте рассмотрим. Данные являются основными ценностями или фактами.Компьютеры используют множество различных типов данных, хранящихся в цифровом формате, например текст, числа и мультимедиа. Данные организованы в таблицы базы данных, а системы управления базами данных используются для работы с большими базами данных. Правильное понимание данных позволяет систематизировать их в виде полезной информации.
Термины и определения данных
| Условия | Определения |
|---|---|
| Данные | основных ценностей или фактов; термин «данные» считается в научном сообществе множественным числом |
| Аналог | данных являются непрерывными — они «аналогичны» фактическим фактам, которые они представляют |
| Цифровой | данные дискретны и разбиты на ограниченное количество элементов |
| База данных | организованный сбор данных |
| Система управления базами данных | специализированное программное обеспечение для ввода, хранения, извлечения и управления всеми данными |
Результаты обучения
По завершении этого урока вы узнаете, как:
- Определить данные
- Контраст аналоговых и цифровых данных
- Описание базы данных и определение цели системы управления базой данных
- Обсудите разницу между данными и информацией
типов данных и способы анализа данных [обновлено}
С момента изобретения компьютеров люди использовали термин «данные» для обозначения компьютерной информации, и эта информация либо передавалась, либо сохранялась.Но это не единственное определение данных; существуют и другие типы данных. Итак, что это за данные? Данные могут быть текстами или числами, записанными на бумаге, или это могут быть байты и биты в памяти электронных устройств, или это могут быть факты, которые хранятся в уме человека. И в этой статье мы подробно рассмотрим следующие темы:
— Что такое данные?
— Типы и использование данных
— Два способа анализа данных
— Причины стать специалистом по анализу данных
— 5 лучших вакансий, связанных с данными
Что такое данные?
Теперь, если мы говорим о данных в основном в области науки, то ответ на вопрос «что такое данные» будет заключаться в том, что данные — это разные типы информации, которые обычно форматируются определенным образом.Все программное обеспечение делится на две основные категории: программы и данные. Программы — это набор инструкций, которые используются для управления данными. Итак, теперь, после полного понимания того, что такое данные и наука о данных, давайте узнаем несколько фантастических фактов.
Программа аспирантуры по аналитике данных
В партнерстве с Purdue University Просмотреть курсТипы и использование данных
Рост в области технологий, особенно в смартфонах, привел к тому, что текст, видео и аудио включены в данные, а также записи в Интернет и журналы.Большая часть этих данных неструктурирована.
Термин «большие данные» используется в определении данных для описания данных в диапазоне петабайт или выше. Большие данные также описываются как 5V: разнообразие, объем, ценность, достоверность и скорость. В настоящее время электронная коммерция в Интернете широко распространилась, бизнес-модели, основанные на больших данных, эволюционировали, и они рассматривают данные как сам актив. Кроме того, большие данные дают множество преимуществ, таких как снижение затрат, повышение эффективности, увеличение продаж и т. Д.
Значение данных выходит за рамки обработки данных в вычислительных приложениях.Когда доходит до науки о данных, совокупность фактов называется наукой о данных. Соответственно, финансы, демография, здоровье и маркетинг также имеют разное значение данных, что в конечном итоге дает разные ответы на вопрос, что такое данные.
Как анализировать данные?
В идеале есть два способа анализа данных:
- Анализ данных в качественных исследованиях
- Анализ данных в количественных исследованиях
1. Анализ данных в качественных исследованиях
Анализ данных и исследование субъективной информации работают несколько лучше, чем числовая информация, поскольку качественная информация состоит из слов, изображений, изображений, объектов, а иногда и изображений.Получение знаний из таких запутанных данных — запутанная процедура; таким образом, он обычно используется для поисковых исследований, а также для анализа данных.
Бесплатный курс: Введение в науку о данных
Изучите основы науки о данныхПоиск закономерностей в качественных данных
Хотя существует несколько различных способов обнаружения закономерностей в печатных данных, словесная стратегия является наиболее зависимым и широко используемым глобальным методом исследования и анализа данных.В основном процесс анализа данных в качественных исследованиях выполняется вручную. Здесь специалисты, как правило, читают доступную информацию и находят однообразные или часто употребляемые слова.
2. Анализ данных в количественных исследованиях
Подготовка данных для анализа
Первым этапом исследования и анализа данных является их проверка с целью преобразования номинальной информации во что-то важное. Подготовка данных включает следующее.
- Проверка данных
- Редактирование данных
- Кодирование данных
Для количественных статистических исследований использование описательного анализа регулярно дает высшие числа. Однако анализ никогда не может показать обоснованность этих цифр. Тем не менее, важно подумать о том, какой метод лучше всего использовать для исследования и анализа данных, соответствующих вашему обзорному опросу, и того, что нужно рассказать специалистам по историям.
Следовательно, предприятия, готовые оправдать себя в гиперконкурентном мире, должны обладать замечательной способностью исследовать сложную исследовательскую информацию, выводить важные фрагменты знаний и приспосабливаться к новым потребностям рынка.
Основные причины стать специалистом по данным: работа в области данных
Ниже упоминаются способы использования данных, которые объясняют, как стать специалистом по данным — это правильный выбор.
- Наука о данных используется для выявления рисков и мошенничества. Первоначально наука о данных использовалась в финансовом секторе, и она продолжает оставаться наиболее важным приложением науки о данных.
- Далее идет сектор здравоохранения. Здесь наука о данных используется для анализа медицинских изображений, генетики и геномики.Это также применимо к разработке лекарств. И, наконец, это большое преимущество для того, чтобы стать виртуальным помощником для пациентов.
- Еще одно применение науки о данных — это поиск в Интернете. Все поисковые системы используют алгоритмы науки о данных, чтобы показать желаемый результат.
- Многие другие приложения науки о данных или искусственного интеллекта включают таргетированную рекламу, расширенное распознавание изображений, распознавание скорости, планирование маршрута авиакомпании, дополненную реальность, игры и т. Д.
Пройдите курс Data Science с Simplilearn, чтобы удовлетворить свои потребности и стать успешным специалистом по данным.
Бесплатный курс: разработчик Big Data Hadoop и Spark
Изучите основы больших данных от ведущих экспертов — для FREEEnrol NowТоп 5 вакансий в данных
Ниже приведены названия нескольких востребованных должностей.
1. Специалист по данным
Это одна из самых востребованных вакансий на данный момент, как видно из предыдущего раздела.
2. BIA
АналитикиBusiness Intelligence помогают компаниям принимать плодотворные решения с помощью данных и предоставления необходимых рекомендаций.
3. Разработчик баз данных
В-третьих, в списке топ-5 вакансий по данным стоит «разработчик баз данных». В основном они сосредоточены на улучшении баз данных и разработке новых приложений для лучшего использования данных.
4. Администратор базы данных
Работа администратора базы данных состоит в том, чтобы настроить базы данных, а затем поддерживать и защищать их в любое время.
5. Диспетчер аналитики данных
В настоящее время все больше и больше компаний начинают полагаться на менеджеров данных для извлечения наиболее полезной информации из огромных объемов данных.
Таким образом, объем данных огромен. Мы перечислили всего пять; есть много других, например, сертификационный курс Data Engineer, администратор безопасности данных. Это показывает, что карьера в любой области науки о данных и бизнес-аналитики является многообещающей.
В чем разница между данными и информацией?
Слова Данные и Информация могут выглядеть одинаково, и многие люди используют эти слова очень часто, но у обоих есть много различий.
В этом руководстве мы рассмотрим следующие темы:
Разница между данными и информацией
что такое данные : Данные — это простые факты. Слово «данные» во множественном числе означает «данные». Когда данные обрабатываются, организуются, структурируются или представляются в определенном контексте, чтобы сделать их полезными, они называются информацией.
Недостаточно иметь данные (например, статистику по экономике). Сами данные довольно бесполезны, но когда эти данные интерпретируются и обрабатываются для определения их истинного значения, они становятся полезными и могут называться Информацией.
Информация — это данные, которые были обработаны таким образом, чтобы быть значимыми для человека, который их получает. это любая вещь, о которой сообщается.
Данные — это термин, который может быть новым для начинающих, но он очень интересен и прост для понимания. Это может быть что угодно, например имя человека, место или число и т. Д. Данные — это имя, присвоенное основным фактам и объектам, таким как имена и числа. Основными примерами данных являются вес, цены, затраты, количество проданных товаров, имена сотрудников, наименования продуктов, адреса, налоговые коды, регистрационные знаки и т. Д.
Данные — это сырье, которое может обрабатывать любая вычислительная машина. Данные могут быть представлены в форме:
Числа и слова, которые могут быть сохранены на языке компьютера
Изображения, звуки, мультимедиа и анимированные данные, как показано.
Информация : Информация — это данные, преобразованные в более полезную или понятную форму. Это набор данных, который был организован для непосредственного использования человечеством, поскольку информация помогает людям в процессе принятия решений.Примеры: расписание, список заслуг, табель успеваемости, таблицы с заголовками, печатные документы, платежные ведомости, квитанции, отчеты и т. Д. Информация получается путем объединения элементов данных в понятную форму. Например, оценки, полученные учащимися, и их номера баллов формируют данные, табель успеваемости / табель — это информация. Другими формами информации являются платежные ведомости, графики, отчеты, рабочий лист, гистограммы, счета-фактуры и отчеты по счетам и т. Д. Можно отметить, что информация может дополнительно обрабатываться и / или обрабатываться для формирования знаний.Информация, содержащая мудрость, известна как знание.
Необходимость информацииСовременная цивилизация стала настолько сложной и изощренной, что чтобы выжить, нужно быть конкурентоспособным. Это заставляет людей быть в курсе всех типов событий в обществе. С началом реформ в сфере образования в обществе человечество окружено огромным количеством доступных данных. Современная система управления бизнесом также приспособилась к массовому сбору данных из различных источников, которые необходимо перестроить таким образом, чтобы их можно было использовать с минимально возможным временем.Для этого требуется большой объем регистрации либо на этапе данных, либо на этапе информации. Ни один офис не может быть без файлов. Если вы пойдете в любой отдел по сбору налогов или муниципальное управление, вы найдете много файлов, сложенных тут и там.
Современные правила, нормы и законы требуют, чтобы каждая транзакция происходила в письменной форме, может быть соглашение, заявление, ваучер, счет, письмо, служебная записка, заказ и т. Д. Для бумажных файлов требуется много места для хранения, а для хранения бумажных документов требуется несколько другие проблемы, такие как риск пожара, порча и порча из-за старения микроорганизмов и влажности и т. д.В наши дни информация необходима для того, чтобы человек мог зарабатывать себе на жизнь, управлять системой или процессом или управлять бизнесом.
Объем информации очень быстро растет. Нынешний век информации требует, чтобы компьютерная грамотность сопровождалась информационной грамотностью, поскольку зависимость работодателей теперь сосредоточена на профессионалах, обладающих актуальной информацией и всеми видами навыков обработки информации, чтобы принять вызов постоянно меняющегося сценария информации в этом мире. Мировая информационная грамотность помогает собирать соответствующую информацию, оценивать информацию и принимать обоснованное решение.Влияние информационной революции распространилось на каждого человека в обществе, и это намного быстрее, чем промышленная революция.
Переход от индустриальной эпохи к информационной эпохе положил конец повторяющимся усилиям рабочих, заменив их компьютерным программным обеспечением, роботы с искусственным интеллектом заменили людей, а многопроцессорные компьютеры заменили офисных работников пишущими машинками.
Информация необходима для:• Чтобы получить знания об окружающей среде и обо всем, что происходит в обществе и вселенной.
• Поддерживать систему в актуальном состоянии.
• Знать о правилах, постановлениях и законах общества, местного самоуправления, провинциального и центрального правительства, ассоциаций, клиентов и т. Д., Поскольку незнание — это не счастье.
• На основе трех вышеупомянутых, чтобы прийти к конкретному решению для планирования текущих и предполагаемых действий в процессе формирования, запуска и защиты процесса или системы
ЗнаниеЧеловеческий разум целенаправленно организовал информацию и оценил ее для получения знания.Другими словами, способность человека вспоминать или использовать свою информацию и опыт называется знанием. Например, «386» — это данные, «ваши оценки 386» — это информация, а «Это результат вашей тяжелой работы» — это знания.
Показана взаимосвязь между данными, информацией и знаниями.
Знания бывают двух типов:• Факты на основе или Информация на основе Знания : Знания, полученные из основ и путем экспериментов.Знания основаны на информации, содержащейся в фундаментальной науке, полученной в результате экспериментов, правил и положений, согласованных экспертами.
• Эвристические знания : Это знание передовой практики, опыт и здравое суждение, подобное гипотезе. Именно знания, лежащие в основе «опыта», практических правил, правил точного предположения, обычно позволяют достичь желаемых результатов, но не гарантируют их.
Сегодня управление знаниями играет важную роль в развитии организации.
Типы данных — Константы, переменные и типы данных — GCSE Computer Science Revision
Данные классифицируются по типам, например, набор целых чисел (также известный как целые числа) или набор печатных символов.
Различные типы данных по-разному представлены внутри компьютера, и для их хранения требуется разный объем памяти. С ними также можно выполнять различные операции. Все значения, принадлежащие к одному типу данных, будут представлены одинаково.
Наиболее часто поддерживаемые типы данных в языках программирования:
| Тип данных | Пример | Размер |
|---|---|---|
| Целое число (целое число) | 4, 27, 65535 | от 1 до 8 байтов |
| Плавающая точка (десятичное число) | 4.2, 27.4, 5.63 | 4-8 байтов |
| Символ | a, F, 3, $, £, # | 1 байт |
| Строка | abc, hello world | Ограничено объемом, который может быть сохранен в основной памяти |
| Boolean | true or false | 1 бит |
Некоторые операции, которые могут быть применены к значениям одного типа данных очевидно, не имеют смысла в применении к значениям другого типа.Например, мы можем вычислить квадратный корень из целого числа 4, но не из строки «hello world».
Типы данных могут отличаться на разных языках. Основные типы данных сгруппированы по иерархии. Это либо чисел, , символов, , либо логических . Существует несколько типов числовых значений, включая различие между целыми числами и числами с плавающей запятой.
8 общих структур данных, которые должен знать каждый программист | by Vijini Mallawaarachchi
Краткое знакомство с 8 часто используемыми структурами данных
Структуры данных — это специализированные средства организации и хранения данных на компьютерах таким образом, чтобы мы могли более эффективно выполнять операции с сохраненными данными.Структуры данных имеют широкую и разнообразную область применения в областях компьютерных наук и разработки программного обеспечения.
Изображение автораСтруктуры данных используются почти во всех разработанных программах или программных системах. Более того, структуры данных относятся к основам компьютерных наук и программной инженерии. Это ключевая тема, когда речь заходит о собеседовании по программной инженерии. Следовательно, как разработчики, мы должны хорошо разбираться в структурах данных.
В этой статье я кратко объясню 8 часто используемых структур данных, которые должен знать каждый программист.
Массив — это структура фиксированного размера, которая может содержать элементы одного и того же типа данных. Это может быть массив целых чисел, массив чисел с плавающей запятой, массив строк или даже массив массивов (например, 2-мерные массивы ). Массивы индексируются, что означает, что возможен произвольный доступ.
Рис. 1. Визуализация базовой терминологии массивов (Изображение автора)Операции с массивами
- Ход : Просмотрите элементы и распечатайте их.
- Поиск : поиск элемента в массиве. Вы можете искать элемент по его значению или по индексу
- Обновление : обновить значение существующего элемента по заданному индексу
Вставка элементов в массив и удаление элементов из массива не может быть выполнено напрямую прочь, поскольку массивы имеют фиксированный размер. Если вы хотите вставить элемент в массив, сначала вам нужно будет создать новый массив с увеличенным размером (текущий размер + 1), скопировать существующие элементы и добавить новый элемент.То же самое касается удаления с новым массивом уменьшенного размера.
Приложения массивов- Используется в качестве строительных блоков для построения других структур данных, таких как списки массивов, кучи, хеш-таблицы, векторы и матрицы.
- Используется для различных алгоритмов сортировки, таких как сортировка вставкой, быстрая сортировка, пузырьковая сортировка и сортировка слиянием.
Связанный список — это последовательная структура, состоящая из последовательности элементов в линейном порядке, которые связаны друг с другом.Следовательно, вы должны обращаться к данным последовательно, и произвольный доступ невозможен. Связанные списки обеспечивают простое и гибкое представление динамических наборов.
Давайте рассмотрим следующие термины, касающиеся связанных списков. Вы можете получить четкое представление, обратившись к рисунку 2.
- Элементы в связанном списке известны как узлы .
- Каждый узел содержит ключ и указатель на его последующий узел, известный как следующий .
- Атрибут с именем head указывает на первый элемент связанного списка.
- Последний элемент связанного списка известен как хвост .
Ниже приведены различные типы доступных связанных списков.
- Односвязный список — Обход элементов может выполняться только в прямом направлении.
- Двусвязный список — Обход элементов может выполняться как в прямом, так и в обратном направлении. Узлы состоят из дополнительного указателя, известного как prev , указывающего на предыдущий узел.
- Списки с круговой связью — Связанные списки, в которых предыдущий указатель головы указывает на хвост, а следующий указатель хвоста указывает на голову.
Операции связанного списка
- Поиск : найти первый элемент с ключом k в заданном связанном списке простым линейным поиском и возвращает указатель на этот элемент
- Insert : Insert a key to связанный список. Вставку можно сделать 3 разными способами; вставить в начало списка, вставить в конец списка и вставить в середину списка.
- Удалить : Удаляет элемент x из заданного связанного списка. Вы не можете удалить узел за один шаг. Удаление может быть выполнено 3 различными способами; удалить из начала списка, удалить из конца списка и удалить из середины списка.
- Используется для управления таблицей символов в конструкции компилятора.
- Используется для переключения между программами с помощью Alt + Tab (реализовано с помощью кругового связного списка).
Стек — это структура LIFO (Last In First Out — к элементу, помещенному последним, можно получить доступ первым), которая обычно встречается во многих языках программирования. Эта структура называется «стопкой», потому что она напоминает стопку тарелок в реальном мире.
Изображение congerdesign с сайта PixabayОперации со стеком
Ниже приведены 2 основные операции, которые можно выполнить со стеком. Пожалуйста, обратитесь к рисунку 3, чтобы лучше понять операции со стеком.
- Нажмите : вставьте элемент в верхнюю часть стопки.
- Pop : удалить самый верхний элемент и вернуть его.
Кроме того, для стека предусмотрены следующие дополнительные функции для проверки его состояния.
- Peek : вернуть верхний элемент стека, не удаляя его.
- isEmpty : проверьте, пуст ли стек.
- isFull : проверьте, заполнен ли стек.
Приложения стеков
- Используется для оценки выражений (например: алгоритм маневровой станции для анализа и оценки математических выражений).
- Используется для реализации вызовов функций в рекурсивном программировании.
Очередь представляет собой структуру FIFO (первым пришел — первым ушел — элемент, помещенный первым, может быть доступен первым), которая обычно встречается во многих языках программирования.Эта структура называется «очередь», потому что она напоминает реальную очередь — люди, ожидающие в очереди.
Изображение Sabine Felidae с сайта PixabayОперации с очередями
Ниже приведены 2 основные операции, которые можно выполнять с очередью. Пожалуйста, обратитесь к рисунку 4, чтобы лучше понять операции с очередями.
- Enqueue : Вставить элемент в конец очереди.
- Dequeue : удалить элемент из начала очереди.
Приложения очередей
- Используется для управления потоками в многопоточности.
- Используется для реализации систем очередей (например, очередей с приоритетом).
Хеш-таблица — это структура данных, в которой хранятся значения, с каждым из которых связаны ключи. Кроме того, он эффективно поддерживает поиск, если мы знаем ключ, связанный со значением. Следовательно, он очень эффективен при вставке и поиске независимо от размера данных.
Прямая адресация использует взаимно-однозначное соответствие между значениями и ключами при сохранении в таблице. Однако при большом количестве пар ключ-значение при таком подходе возникает проблема. Таблица будет огромной с таким количеством записей, и ее будет непрактично или даже невозможно сохранить, учитывая объем памяти, доступный на обычном компьютере. Чтобы избежать этой проблемы, мы используем хеш-таблицы .
Хеш-функция
Специальная функция, называемая хэш-функцией ( h ), используется для решения вышеупомянутой проблемы при прямой адресации.
При прямом доступе значение с ключом k сохраняется в слоте k . Используя хеш-функцию, мы вычисляем индекс таблицы (слота), в которую попадает каждое значение. Значение, вычисленное с помощью хэш-функции для данного ключа, называется хеш-значением , которое указывает индекс таблицы, в которую отображается значение.
h (k) = k% m
- h: Хеш-функция
- k: Ключ, по которому должно быть определено хеш-значение
- m: Размер хеш-таблицы ( количество доступных слотов).Простое значение, не близкое к точной степени 2, является хорошим выбором для м .
Рассмотрим хеш-функцию h (k) = k% 20 , где размер хеш-таблицы равен 20. Учитывая набор ключей, мы хотим вычислить хеш-значение каждого, чтобы определить индекс, в котором он должен находиться в хеш-таблице. Предположим, у нас есть следующие ключи, хэш и индекс хеш-таблицы.
- 1 → 1% 20 → 1
- 5 → 5% 20 → 5
- 23 → 23% 20 → 3
- 63 → 63% 20 → 3
Из двух последних примеров, приведенных выше, мы можем видите, что коллизия может возникнуть, когда хеш-функция генерирует один и тот же индекс для более чем одного ключа.Мы можем разрешить конфликты, выбрав подходящую хэш-функцию h и используя такие методы, как цепочка и открытая адресация .
Приложения хеш-таблиц
- Используется для реализации индексов базы данных.
- Используется для реализации ассоциативных массивов.
- Используется для реализации «установленной» структуры данных.
Дерево — это иерархическая структура, в которой данные организованы иерархически и связаны между собой. Эта структура отличается от связанного списка, тогда как в связанном списке элементы связаны в линейном порядке.
На протяжении последних десятилетий были разработаны различные типы деревьев, чтобы соответствовать определенным приложениям и соответствовать определенным ограничениям. Некоторыми примерами являются двоичное дерево поиска, B-дерево, treap, красно-черное дерево, расширенное дерево, AVL-дерево и n-арное дерево.
Двоичные деревья поиска
Двоичное дерево поиска (BST) , как следует из названия, представляет собой двоичное дерево, в котором данные организованы в иерархическую структуру. Эта структура данных хранит значения в отсортированном порядке.
Каждый узел в двоичном дереве поиска содержит следующие атрибуты.
- ключ : значение, хранящееся в узле.
- слева : указатель на левый дочерний элемент.
- справа : указатель на правого дочернего элемента.
- p : указатель на родительский узел.
Бинарное дерево поиска обладает уникальным свойством, которое отличает его от других деревьев. Это свойство известно как свойство двоичного дерева поиска .
Пусть x будет узлом в двоичном дереве поиска.
- Если y — это узел в левом поддереве x, тогда y.key ≤ x.key
- Если y — это узел в правом поддереве x, то y .key ≥ x.key
Приложения деревьев
- Двоичные деревья : Используется для реализации синтаксических анализаторов выражений и решателей выражений.
- Дерево двоичного поиска : используется во многих поисковых приложениях, где данные постоянно вводятся и уходят.
- Куча : используется JVM (виртуальной машиной Java) для хранения объектов Java.
- Treaps : используется в беспроводных сетях.
Ознакомьтесь с моими статьями ниже о 8 полезных древовидных структурах данных и самобалансирующихся деревьях двоичного поиска.
A Heap — это особый случай двоичного дерева, в котором родительские узлы сравниваются со своими дочерними узлами с их значениями и располагаются соответствующим образом.
Давайте посмотрим, как мы можем представлять кучи. Кучи могут быть представлены как деревьями, так и массивами.На рисунках 7 и 8 показано, как мы можем представить двоичную кучу с помощью двоичного дерева и массива.
Рис. 7. Двоичное представление кучи в виде дерева (изображение автора) Рис 8. Представление кучи в виде массива (изображение автора)Кучи могут быть двух типов.
- Мин. Куча — ключ родительского элемента меньше или равен ключу его дочерних элементов. Это называется свойством min-heap . Корень будет содержать минимальное значение кучи.
- Max Heap — ключ родительского элемента больше или равен ключу его дочерних элементов.Это называется свойством max-heap . Корень будет содержать максимальное значение кучи.
Приложения кучи
- Используется в алгоритме heapsort .
- Используется для реализации очередей приоритетов, поскольку значения приоритета могут быть упорядочены в соответствии со свойством кучи, где куча может быть реализована с использованием массива.
- Функции очереди могут быть реализованы с использованием кучи в течение O (log n) времени.
- Используется для поиска наименьшего (или наибольшего) значения kᵗʰ в заданном массиве.
Ознакомьтесь с моей статьей ниже о реализации кучи с использованием модуля python heapq.
Граф состоит из конечного набора из вершины или узлов и набора из ребер , соединяющих эти вершины.
Порядок графа — это количество вершин в графе. Размер графа — это количество ребер в графе.
Два узла называются соседними , если они соединены друг с другом одним и тем же ребром.
Направленные графы
Граф G называется ориентированным графом , если все его ребра имеют направление, указывающее, какая вершина является начальной, а какая конечной.
Мы говорим, что (u, v) — это инцидент из или оставляет вершину u и инцидент или входит в вершину v .
Петли : края от вершины к самой себе.
Ненаправленные графы
Граф G называется неориентированным графом , если все его ребра не имеют направления.Между двумя вершинами он может проходить в обоих направлениях.
Если вершина не связана ни с одним другим узлом в графе, она называется изолированной .
Рис. 9. Визуализация терминологии графов (изображение автора)Вы можете узнать больше об алгоритмах графов из моей статьи 10 графических алгоритмов, визуально объясненных.
Приложения графиков
- Используется для представления социальных сетей. Каждый пользователь является вершиной, и когда пользователи соединяются, они создают ребро.
- Используется для представления веб-страниц и ссылок поисковыми системами. Веб-страницы в Интернете связаны друг с другом гиперссылками. Каждая страница — это вершина, а гиперссылка между двумя страницами — край. Используется для ранжирования страниц в Google.
- Используется для представления местоположений и маршрутов в GPS. Локации — это вершины, а маршруты, соединяющие локации, — это ребра. Используется для расчета кратчайшего маршрута между двумя точками.