Что такое gpu в компьютере и его температура
Нередко причиной частых выключений является графический процессор. Что такое GPU в компьютере и его температура разберём как можно подробнее. Вопрос на самом деле не сложный.
Сложности начинаются в тот момент, когда приходится проводить необходимое техническое обслуживание. Особенно, если делать его самостоятельно.
Что такое GPU?
За вывод изображения отвечает монитор компьютера или ноутбука. Но вот сигналы на монитор передаются с помощью видеокарты. Она и является графическим процессором или Graphical Processor Unit (либо же, GPU, если сокращённо).
Назначение графической карты
Обработка требующегося изображения производится именно через видео карту компьютера. Она получает команды от оперативной памяти о том, что и как нужно вывести на монитор. После обработки указанных команд на монитор передаётся сигнал о том, какие элементы и как подсветить.
Проще всего рассмотреть на примере игр, которые дают наибольшую нагрузку на GPU и требует его высокого качества. Итак, сама игра запускается на каком-либо движке, который определяет алгоритмы обработки команд процессором.
Во время обработки поступают сигналы о том, какой видео ряд должен идти на мониторе. Эти сигналы через RAM, или, что чаще, напрямую, подаются на видео карту. Процессор графического элемента обрабатывает их и передаёт изображение монитору. Такой алгоритм характерен не только играм, но и самой ОС.
Примечание: указанный пример предельно упрощён. Фактически же каждая игра даёт настолько огромный поток данных для обработки, что задействуются все элементы компьютера.
Почему так важна температура?
Во время работы процессор греется. Происходит это из-за того, что вычислительные действия производятся с выделением теплового излучения (принцип работы кремниевых микросхем имеет такой недостаток).
Эту температуру принято компенсировать с помощью:
- специальных мембран, которые располагаются над процессором;
- термопасты, которая усиливает проводимость тепла от мембраны до кулера;
- кулера или элемента охлаждения, который снижает температуру мембраны рассеиванием тепла либо активным нагнетанием холодного воздуха с помощью вентилятора.
Звучит сложно. На деле же всё просто: вентилятор дует, чем и охлаждает железку, которая не даёт перегореть самому вычислительному элементу.
Что будет если карта перегреется?
Существует 2 сценария по которым будут развиваться события если карта перегреется. Зависят они как от изготовителя карты, так и от настроек системы/драйвера. Оба этих случая могут иметь печальные последствия, поэтому следить за температурой нужно.
- Срабатывает «защита от перегрева». Если в драйверах установлено предельное значение температуры, то устройство по его достижению работает около минуты, после чего отключается. Это сделано, чтобы избежать повреждений процессора, связанных с перегревом. В такой ситуации компьютер сразу выключается или перезапускается, а ОС сообщает о некорректном завершении работы.
- Расслаивается или сгорает чип. Если высокая нагрузка будет продолжительной, и температура станет критической, а защита не сработает, то видеокарта сгорит. Перегорание характерно любой электронике при нарушении температурного режима. Пожара, конечно, не будет. Но вот дальнейшая эксплуатация GPU станет невозможной. Повреждения будут слишком большими.
Для пользователя предпочтительнее первый сценарий. Лучше лишиться данных за некоторое время, чем лишится дорогой видеокарты. При этом отсутствие нагрузки за время выключения и повторного включения позволяет чипу остыть. Не стоит опасаться обычного использования и даже игр.
Чтобы видеокарта перегрелась нужно чтобы компьютер не чистился порядка 3х лет и при этом постоянно нагружался программами или играми, которые имеют высокие системные требования. Тогда пересохнет и перестанет передавать тепло термопаста, что и повлечёт за собой перегрев.
Как измерить температуру?
Почему важна температура мы рассмотрели. Фактически, это показатель нормальной работы комплектующих. Высокая температура – другой разговор. Она свидетельствует о неспособности системы охлаждения справляться с нагрузкой.
Поэтому нужно будет искать информацию о нормальной рабочей температуре карты. А также следить за текущей температурой компонента.
Программы
Простейшим решением является использование программ. Благо, список таких приложений не маленький. Остановиться следует только на самых распространённых или полезных:
FurMark. Тест стабильности видеокарты. Он позволяет следить за температурой при этом предельно нагружая видеокарту. Работать такое приложение может только в активном режиме и ему требуется время. Зато, нагрузив с его помощью видео карту можно проверить активна ли защита, и способно ли охлаждение справится с нагрузкой.
Если тест прерывается – помните, что Furmark даёт предельно возможную нагрузку. Не факт, что пользователь сможет нагрузить компонент также.
PiriForm Speccy. Программа, работающая от встроенных элементов контроля. На большинстве внутренних элементов компьютера есть свои датчики. Speccy считывает их значения и передаёт пользователю. Состояние, которое показывает программа актуальна в данный момент времени.

GPU Temp. Сокращение от GPU Temperature. Приложение, которое решает только 1 вопрос: контроль температурного режима видео карты (на самом деле ещё и контроль, что за видеокарта установлена в системе).
Обладает функцией графика, который выводит на экран информацию о нагреве в процессе работы. Можно оставить работать в фоновом режиме, а потом проверить температуру под нагрузкой.

Что такое gpu в компьютере и для чего это нужно?
Автор Дмитрий Костин На чтение 3 мин. Опубликовано
Доброго всем времени суток, мои дорогие друзья и гости моего блога. Сегодня я бы хотел поговорить немного об аппаратной части наших компьютеров. Скажите пожалуйста, вы слышали про такое понятие как GPU? Оказывается просто многие впервые слышат такую аббревиатуру.
Как бы банально это не звучало, но сегодня мы живем в эру компьютерных технологий, и порой сложно найти человека, который понятия не имеет, как работает компьютер. Так, например, кому-то достаточно осознания, что компьютер работает благодаря центральному процессору (CPU).
Кто-то пойдет дальше и узнает, что есть ещё и некий GPU. Такая замысловатая аббревиатура, но похожая на предыдущую. Так давайте же разберемся, что такое GPU в компьютере, какие они бывают и какие различия есть у него с CPU.

Небольшая разница
Простыми словами, GPU — это графический процессор, иногда его именуют видеокартой, что отчасти является ошибкой. Видеокарта — это готовое компонентное устройство, в состав которого как раз и входит нами описываемый процессор. Он способен обрабатывать команды для формирования трёхмерной графики. Стоит отметить, что он является для этого ключевым элементом, от его мощности зависит быстродействие и различные возможности видеосистемы в целом.

Графический процессор имеет свои отличительные особенности по сравнению с его собратом CPU. Основное различие кроется в архитектуре, на которой он построен. Архитектура GPU построена таким образом, что позволяет обрабатывать большие массивы данных более эффективно. CPU, в свою очередь, обрабатывает данные и задачи последовательно. Естественно, не стоит воспринимать эту особенность как минус.
Виды графических процессоров
Существует не так много видов графических процессоров, один из них именуется, как дискретный, и применяется на отдельных модулях. Такой чип достаточно мощный, поэтому для него требуется система охлаждения из радиаторов, кулеров, в особо нагруженных системах может применяться жидкостное охлаждение.
Сегодня мы можем наблюдать значительный шаг в развитие графических компонентов, это обуславливается появлением большого количества видов GPU. Если раньше любой компьютер приходилось снабжать дискретной графикой, чтобы иметь доступ к играм или другим графическим приложениям, то сейчас такую задачу может выполнять IGP — интегрированный графический процессор.

Интегрированной графикой сейчас снабжают практически каждый компьютер (за исключением серверов), будь то, ноутбук или настольный компьютер. Сам видео-процессор встроен в CPU, что позволяет значительно снизить энергопотребление и саму цену устройства. Кроме того, такая графика может быть и в других подвидах, например: дискретная или гибридно-дискретная.
Первый вариант подразумевает наиболее дорогое решение, распайку на материнской плате или же отдельный мобильный модуль. Второй вариант называется гибридным неспроста, фактически он использует видеопамять небольшого размера, которая распаяна на плате, но при этом способен расширять её за счёт оперативной памяти.
Естественно, такие графические решения не могут поравняться с полноценными дискретными видеокартами, но уже сейчас показывает достаточно хорошие показатели. В любом случае, разработчикам есть куда стремиться, возможно за таким решением будущее.
Ну а на этом у меня, пожалуй, все. Надеюсь, что статья вам понравилась! Жду вас снова у себя на блоге в гостях. Удачи вам. Пока-пока!
В чем разница между CPU и GPU
Современные смартфоны работают за счет разных компонентов, но главными считаются именно центральный и графический процессор (CPU и GPU).
Несмотря на схожее название и то, что в целом их главная роль — обрабатывать огромные массивы данных, между GPU и CPU существует огромная разница. Но прежде, чем углубиться в их различия, рассмотрим что же у них общего.
Ядра графического и центрального процессоров представляют собой блоки, каждый из которых выполняет определенные задачи. Размер и объем блоков может быть разным. Это зависит от архитектуры процессора. И у GPU, и у CPU есть АЛУ. Это арифметико-логическое устройство, которое необходимо для выполнения математических операций. Другие блоки имеют доступ к памяти (для загрузки и сохранения данных), выполняют задачи декодеров или кэша. На этом сходства заканчиваются. Теперь поговорим о различиях между CPU и GPU.
Что такое CPU
Центральный процессор компьютера или смартфона можно сравнить с человеческим мозгом. Это довольно гибкий компонент, выполняющий целый спектр задач и отвечающий за работоспособность устройства. CPU выполняет все логические и арифметические задачи. Именно это гарантирует работу операционной системы Android и устанавливаемых на смартфон приложений.
Процессоры часто встречаются в конфигурациях с несколькими ядрами: от четырех до восьми для мобильных устройств и до 16 для стационарных компьютеров и серверного оборудования. Конструкция многоядерных процессоров позволяет одновременно запускать несколько приложений и потоков задач, что значительно повышает производительность и эффективность использования энергии.
Каждое ядро работает на тактовой частоте, обычно это от 2 до 3 ГГц для мобильных устройств, и до 5 ГГц для компьютеров. Кроме того, CPU может иметь разные объемы высокоскоростной закрытой памяти, которая используется для хранения инструкций и данных (т.е. кэш). Кэш-память может быть либо индивидуальной для каждого ядра или делится между ними. Она необходима для ускорения выполнения задач и переключения между ними.
Процессор обрабатывает различные типы данных и обеспечивает общую функциональность устройства.

Внутри большинства современных процессоров находится несколько АЛУ, выполняющих математические операции. Кроме того, CPU обрабатывает и перестраивает виртуальную память для всех запускаемых пользователем приложений. Именной по этой причине процессор является самым необходимым инструментом для запуска операционной системы.
Следующее составное устройство CPU — модуль предсказания переходов. Его использование позволяет предварительно загружать и исполнять инструкции, которые могут понадобится в ближайшем будущем. Это значительно экономит время и позволяет оптимально использовать вычислительные ресурсы процессора.
Что такое GPU
GPU имеет отличный от CPU характер рабочей нагрузки. Поэтому графические процессоры не используют модули предсказания переходов. Именно в этом и кроется ключ понимания различий между GPU и CPU.
Если центральный процессор необходим для выполнения различных задач, то видеокарта имеет строго определенное предназначение — рендеринг и обработка трехмерной графики. GPU намного быстрее и энергоэффективнее решает эти задачи. Однако графический процессор не столь гибок в своем диапазоне рабочих нагрузок.
Ядра видеокарты имеют один или несколько АЛУ, но в отличие от тех, что используются CPU они разработаны совершенно иначе. Они способны обрабатывать 8, 16 или 32 операции одновременно. Кроме того, ядра GPU могут состоять из десятков или сотен отдельных блоков АЛУ, благодаря чему графический процессор выполняет тысячи операций. Это особенно полезно во время обработки теней на дисплеях с высоким разрешением.
GPU это отдельное устройство компьютера или смартфона, разработанное для графического рендеринга и применяемое в качестве ускорителя трехмерной графики.

Из-за того, что GPU предназначен для обработки компьютерной графики, он рассчитан на массивные параллельные вычисления. Поэтому видеокарты имеют очевидное преимущество при больших объемах обрабатываемой информации.
По сравнению с центральными процессорами, графические имеют особую архитектуру, нацеленную на увеличение скорости расчета текстур и сложных графических объектов. Кроме того, у GPU более ограниченный набор команд.
Что касается тактовой частоты, то у GPU данный показатель, как правило, ниже чем у CPU. При это зачастую речь идет о сотнях МГц. Это обусловлено ограничениями тепла и мощности, поскольку для параллельной обработки массивных объемов данных требуется гораздо больше транзисторов.
Параллельные вычисления могут использоваться не только в качестве ускорителя трехмерной графики. С его помощью рендеринг видеороликов, разные алгоритмы криптографии и машинного обучения (вроде обнаружения объектов) будут работать намного быстрее на GPU, а не на CPU.

В чем разница между CPU и GPU
В качестве последней аналогии представьте себе CPU в качестве швейцарского ножа, а GPU в виде мачете. Первый полезен для выполнения самых разных задач: от перерезания веревки до вскрытия консервов. Согласитесь, что попытаться открыть банку фасоли мачете — не самая лучшая идея. Но если вам нужно будет пройти через густые заросли джунглей, то вы наверняка предпочтете именно мачете, а не швейцарский нож.
Центральный процессор подходит для самых разных типов вычислений, тем более что по сравнению с видеокартой у него более широкий набор команд. Его ядра более гибкие, благодаря чему CPU позволяет нескольким задачам включаться и выключаться одновременно. Графический процессор имеет ограниченный набор команд и фокусируется на выполнении одной, строго определенной задачи. При этом GPU выполняет гораздо больше вычислений за один такт.
Несмотря на то, что графический и центральный процессор имеют примерно схожую структуру (оба построены из транзисторов), обрабатывают данные и числа, главная между ними разница в том, что каждый выполняет строго определенные.
Источник: www.androidauthority.com
Секреты невозможных вычислений на GPU / ComBox Technology corporate blog / Habr
Наш опыт использования вычислительного кластера из 480 GPU AMD RX 480 при решении математических задач. В качестве задачи мы взяли доказательство теоремы из статьи профессора Чуднова А.М. “Циклические разложения множеств, разделяющие орграфы и циклические классы игр с гарантированным выигрышем“. Задача заключается в поиске минимального числа участников одной коалиции в коалиционных играх Ним-типа, гарантирующее выигрыш одной из сторон.Развитие CPU
Первый процессор, получивший действительно массовое распространение – это 8086 от компании Intel, разработанный в 1978 году. Тактовая частота работы 8086 составляла всего 8 МГц. Спустя несколько лет появились первые процессоры внутри которых было 2, 4 и даже 8 ядер. Каждое ядро позволяло выполнять свой код независимо от других. Для сравнения — современный процессор Intel Core i9-7980XE работает на частоте 2,6 ГГц и содержит 18 ядер. Как видите — прогресс не стоит на месте!
Развитие GPU
Одновременно с развитием центральных процессоров развивались и видеокарты. В основном их характеристики важны для компьютерных игр, там новые технологии проявляются особенно красочно и рендеринг 3D картинки постепенно приближается к фотографическому качеству. В начале развития компьютерных игр расчет картинки выполнялся на CPU, но вскоре был достигнут предел изобретательности разработчиков 3D-графики, ухитрявшихся оптимизировать даже очевидные вещи (хороший пример тому —
Что содержит в себе GPU
Архитектура GPU отличается от CPU большим количеством ядер и минималистичным набором команд, направленных в основном на векторные вычисления. На уровне архитектуры решены вопросы параллельной работы большого числа ядер и одновременного доступа к памяти. Современные GPU содержат от 2-х до 4-х тысяч шейдерных блоков, которые объединены в вычислительные юниты (Compute Unit). При параллельных вычислениях особенно остро стоит проблема одновременного доступа к памяти. Если каждый из потоковых процессоров попытается выполнить запись в ячейку памяти то эти команду упрутся в блокировку и их необходимо будет поставить в очередь, что сильно снизит производительность. Поэтому потоковые процессоры выполняют команды небольшими группами: пока одна группа производит вычисления, другая загружает регистры и т.д. Также можно объединить ядра в рабочие группы, обладающие общей памятью и внутренними механизмами синхронизации.
Еще одной важной особенностью GPU является наличие векторных регистров и векторных АЛУ, которые могут выполнять операции одновременно для нескольких компонентов вектора. Это в первую очередь нужно для 3D графики, но поскольку наш мир трехмерный, ничто не мешает использовать это для многих физических вычислений. При наличии свободных векторных АЛУ их можно использовать и для вычисления скалярных величин.
Они такие разные, CPU и GPU
Для полноценной работы вычислительной системы важны оба типа устройств. К примеру, мы выполняем пошаговую программу, некий последовательный алгоритм. Там нет возможности выполнить пятый шаг алгоритма, так данные для него рассчитываются на шаге четыре. В таком случае эффективнее использовать CPU с большим кэшем и высокой тактовой частотой. Но есть целые классы задач, хорошо поддающихся распараллеливанию. В таком случае эффективность GPU очевидна. Самый частый пример — вычисление пикселей отрендеренного изображения. Процедура для каждого пикселя почти одинаковая, данные о 3D объектах и текстурах находятся в ОЗУ видеокарты и каждый потоковый процессор может независимо от других посчитать свою часть изображения.
Поведение воздушного потока в каждой точке можно описать одинаковыми математическими уравнениями и решать эти уравнения параллельно на большом количестве ядер.
GPU в руках программистов
Для выполнения вычислений на GPU используется специальный язык и компилятор. Существует несколько фреймворков для выполнения общих вычислений на GPU: OpenCL, CUDA, С++AMP, OpenACC. Широкое распространение получили первые два, но использование CUDA ограничено только GPU от компании nVidia.
OpenCL был выпущен в 2009 году компанией Apple. Позднее корпорации Intel, IBM, AMD, Google и nVidia присоединились к консорциуму Khronos Group и заявили о поддержке общего стандарта. С тех пор новая версия стандарта появляется каждые полтора-два года и каждый привносит все более серьезные улучшения.
На сегодняшний день язык OpenCL C++ версии 2.2 соответствует стандарту C++14, поддерживает одновременное выполнение нескольких программ внутри устройства, взаимодействие между ними через внутренние очереди и конвейеры, позволяет гибко управлять буферами и виртуальной памятью.
Реальные задачи
Интересная задача из теории игр, в решении которой мы принимали участие — доказательство теоремы из статьи профессора Чуднова А.М. “Циклические разложения множеств, разделяющие орграфы и циклические классы игр с гарантированным выигрышем“. Задача заключается в поиске минимального числа участников одной коалиции в коалиционных играх Ним-типа, гарантирующее выигрыш одной из сторон.
С математической точки зрения это поиск опорной циклической последовательности. Если представить последовательность в виде списка нулей и единиц, то проверку на опорность можно реализовать логическими побитовыми операциями. С точки же зрения программирования такая последовательность представляет собой длинный регистр, например, 256 бит. Самый надежный способ решения этой задачи — перебор всех вариантов за исключением невозможных по очевидным причинам.
Цели решения задачи — вопросы эффективной обработки сигналов (обнаружение, синхронизация, координатометрия, кодирование и т.д.).
Сложность решения этой задачи в переборе огромного числа вариантов. Например, если мы ищем решение для n=25, то это 25 бит, а если n=100, то это уже 100 бит. Если взять количество всех возможных комбинаций, то для n=25 это 2^25=33 554 432, а для n=100 это уже 2^100=1 267 650 600 228 229 401 496 703 205 376 комбинаций. Возрастание сложности просто колоссальное!
Такая задача хорошо распараллеливается, а значит она идеально подходит для нашего GPU кластера.
Программисты vs математики
Изначально математики решали эту задачу на Visual Basic в Excel, так удалось получить первичные решения, но невысокая производительность скриптовых языков не позволила продвинуться далеко вперед. Решение до n=80 заняло полтора месяца… Склоняем голову перед этими терпеливыми людьми.
Первым этапом мы реализовали алгоритм задачи на языке Си и запустили на CPU. В процессе выяснилось, что при работе с битовыми последовательностями многое можно оптимизировать.
Далее мы оптимизировали область поиска и исключили дублирование. Также хороший результат дал анализ генерируемого компилятором ассемблерного кода и оптимизация кода под особенности компилятора. Всё это позволило добиться существенного прироста скорости вычислений.
Следующим этапом оптимизации стало профилирование. Замер времени выполнения различных участков кода показал, что в некоторых ветках алгоритма сильно возрастала нагрузка на память, а также выявилось излишнее ветвление программы. Из-за этого “маленького” недочёта почти треть мощности CPU была не задействована.
Очень важным аспектом решения подобных задач является аккуратность написания кода. Правильных ответов на эту задачу никто не знает и тестовых векторов соответственно нет. Есть лишь первая часть диапазона решений, которые были найдены математиками. Достоверность новых решений можно гарантировать только аккуратностью написания кода.
Вот и наступил этап подготовки программы для решения на GPU и код был модифицирован для работы в несколько потоков. Управляющая программа теперь занималась диспетчеризацией задач между потоками. В многопоточной среде скорость вычисления увеличилась в 5 раз! Этого удалось добиться за счет одновременной работы 4 потоков и объединения функций.
На этом этапе решение производило верные расчеты до n=80 за 10 минут, тогда как в Exсel’e эти расчеты занимали полтора месяца! Маленькая победа!
GPU и OpenCL
Было принято решение использовать OpenCL версии 1.2, чтобы обеспечить максимальную совместимость между различными платформами. Первичная отладка производилась на CPU от Intel, потом на GPU от Intel. Уже потом перешли на GPU от AMD.
В версии стандарта OpenCL 1.2 поддерживаются целочисленные переменные размерностью 64 бита. Размерность в 128 бит ограничено поддерживается AMD, но компилируется в два 64-х битных числа. Из соображений совместимости и для оптимизации производительности было решено представлять число размерностью 256 бит как группу 32-х битных чисел, логические побитовые операции над которыми производятся на внутреннем АЛУ GPU максимально быстро.
Программа на OpenCL содержит ядро — функцию, которая является точкой входа программы. Данные для обработки загружаются с CPU в ОЗУ видеокарты и передаются в ядро в виде буферов — указателей на массив входных и выходных данных. Почему массив? Мы же выполняем высокопроизводительные вычисления, нам нужно много задач, выполняемых одновременно. Ядро запускается на устройстве во множестве экземпляров. Каждое ядро знает свой идентификатор и берет именно свой кусочек входных данных из общего буфера. Тот случай, когда самое простое решение — самое эффективное. OpenCL — это не только язык, но и всеобъемлющий фреймворк, в котором досконально продуманы все мелочи научных и игровых вычислений. Это здорово облегчает жизнь разработчику. Например, можно запустить много потоков, диспетчер задач разместит их на устройстве сам. Те задачи, которые не встали на немедленное исполнение, будут поставлены в очередь ожидания и запущены по мере освобождения вычислительных блоков. У каждого экземпляра ядра есть свое пространство в выходном буфере, куда он и помещает ответ по завершению работы.
Основная задача диспетчера OpenCL — обеспечить параллельное выполнение нескольких экземпляров ядра. Здесь применён накопленный десятилетиями научный и практический опыт. Пока часть ядер загружает данные в регистры, другая часть в это время работает с памятью или выполняет вычисления — в результате ядро GPU всегда полностью загружено.
Компилятор OpenCL хорошо справляется с оптимизацией, но разработчику влиять на быстродействие проще. Оптимизация под GPU идет в двух направлениях — ускорение выполнения кода и возможность его распараллеливания. Насколько хорошо распараллеливается код компилятором зависит от нескольких вещей: количество занимаемых scratch регистров (которые располагаются в самой медленной памяти GPU — глобальной), размер скомпилированного кода (надо поместиться в 32 кб кэша), количество используемых векторных и скалярных регистров.
ComBox A-480 GPU или один миллион ядер
Эта самая интересная часть проекта, когда от Excel мы перешли на вычислительный кластер состоящий из 480 видеокарт AMD RX 480. Большого, быстрого, эффективного. Полностью готового к выполнению поставленной задачи и получению тех результатов, которых мир еще никогда не видел.
Хочется отметить что на всех этапах совершенствования и оптимизации кода мы запускали поиск решения с самого начала и сравнивали ответы новой версии с предыдущими. Это позволяло быть уверенными, что оптимизация кода и доработки не вносят ошибки в решения. Тут нужно понимать, что правильных ответов в конце учебника нет, и никто в мире их не знает.
Запуск на кластере подтвердил наши предположения по скорости решений: поиск последовательностей для n>100 занимал около часа. Было удивительно видеть как на кластере ComBox A-480 новые решения находились за минуты, в то время как на CPU это занимало многие часы.
Всего через два часа работы вычислительного кластера мы получили все решения до n=127. Проверка решений показала, что полученные ответы достоверны и соответствуют изложенным в статье теоремам профессора Чуднова А.М.
Эволюция скорости
Если посмотреть прирост производительности в ходе решения задачи, то результаты были примерно такими:
- полтора месяца до n=80 в Excel;
- час до n=80 на Core i5 с оптимизированной программой на С++;
- 10 минут до n=80 на Core i5 с использованием многопоточности;
- 10 минут до n=100 на одном GPU AMD RX 480;
- 120 минут до n=127 на ComBox A-480.
Перспективы и будущее
Многие задачи стоящие на стыке науки и практики ожидают своего решения, чтобы сделать нашу жизнь лучше. Рынок аренды вычислительных мощностей только формируется, а потребность в параллельных вычислениях продолжает расти.
Возможные области применения параллельных вычислений:
- задачи автоматического управления транспортными средствами и дронами;
- расчеты аэродинамических и гидродинамических характеристик;
- распознавание речи и визуальных образов;
- обучение нейронных сетей;
- задачи астрономии и космонавтики;
- статистический и корреляционный анализ данных;
- фолдинг белок-белковых соединений;
- ранняя диагностика заболеваний с применением ИИ.
Отдельное направление — облачные вычисления на GPU. Например, такие гиганты как Amazon, IBM и Google сдают свои вычислительные мощности на GPU в аренду. Сегодня с уверенностью можно сказать что будущее высокопроизводительных параллельных вычислений будет принадлежать GPU кластерам.
Что такое TDP для CPU и GPU

Вы часто видите измерения TDP на листах спецификаций, и это важная информация для людей с настольными ПК. Мы расскажем, что означает для номер TDP.
Что означает TDP
TDP — это аббревиатура, используемая людьми для обозначения следующего: расчетная тепловая мощность, расчетная тепловая точка и расчетная тепловая характеристика. К счастью, все это означает одно и то же. Наиболее распространенным является расчетная тепловая характеристика, поэтому мы будем использовать ее здесь.
Расчетная тепловая мощность — это измерение максимального количества тепла, выделяемого процессором или графическим процессором при интенсивной рабочей нагрузке.
Компоненты выделяют тепло при работе компьютера, и чем сильнее он работает, тем горячее он становится. То же самое с Вашим телефоном. Во время игры Вы заметите, что задняя часть Вашего телефона нагревается, так как компоненты потребляют больше электроэнергии.
Некоторые энтузиасты ПК также называют TDP максимальной мощностью, которую может использовать компонент. И некоторые компании, такие как NVIDIA, говорят, что это и то, и другое:
«TDP — это максимальная мощность, которую подсистема может потреблять для применения в «реальном мире», а также максимальное количество тепла, выделяемое компонентом, которое система охлаждения может рассеивать в реальных условиях».
Однако в большинстве случаев TDP означает количество тепла, которое генерирует компонент, и система охлаждения должна отводить его. Он выражается в ваттах, которые обычно являются мерой мощности (например, электричества), но могут также относиться к теплу.
TDP часто используется в качестве замены для энергопотребления, потому что оба часто оказываются эквивалентными или близкими. Однако это не всегда так, поэтому Вам не следует использовать TDP для определения размера блока питания Вашего ПК.
TDP для процессоров. AMD и Intel
Если TDP основан на количестве тепла, выделяемого во время большой рабочей нагрузки, кто решает, что это за рабочая нагрузка или на какой тактовой частоте должна работать микросхема? Поскольку не существует стандартизированного метода оценки TDP, производители микросхем придумали свои собственные методы. Это означает, что энтузиасты ПК имеют совершенно разные мнения о TDP для Advanced Micro Devices (AMD) по сравнению с процессорами Intel.
В целом, энтузиасты утверждают, что цифры AMD TDP более реалистичны. Между тем Intel часто публикует рейтинги TDP, которые ниже, чем у людей, работающих с их системами, что делает TDP менее надежным в качестве замены для энергопотребления.
Anandtech недавно объяснил, как Intel достигает своих рейтингов TDP, и почему они, кажется, всегда отключены. Процессоры работают на своих уровнях буста (более высоких скоростях) под нагрузкой в течение длительных периодов времени. Проблема в том, что Intel основывает свои рейтинги TDP, когда процессор работает на базовой частоте, а не на повышенной. Таким образом, процессор Intel часто работает быстрее, чем Intel говорит, что Вы можете ожидать из коробки. Если системный кулер не справляется с этими более высокими уровнями нагрева, процессор замедляется, чтобы защитить себя от повреждений. Это приводит к снижению производительности системы. Однако при использовании более качественного кулера эти проблемы возникают реже.
Между тем, на стороне AMD есть много сообщений на форуме, в которых люди утверждают, что даже при умеренном разгоне стандартные кулеры AMD более чем достаточны.
Все дело в охлаждении
Вы можете управлять TDP Вашей системы, если используете лучшее решение для охлаждения процессора. Если Вы не выполняете какие-либо специализированные настройки Вашей системы или не играете долго в AAA игры, стандартного кулера, поставляемого с Вашим процессором, будет достаточно. Геймеры, однако, должны подобрать лучшее решение для охлаждения.
Надлежащий кулер — это только часть системы отвода тепла Вашего ПК. Правильный поток воздуха также является ключевой характеристикой.
TDP, T-Junction и Max Temps
TDP поможет Вам выбрать правильный тип системы охлаждения для Вашего процессора. Однако он не говорит о том, сколько тепла может выдержать компонент. Для этого Вам нужно взглянуть на одну из двух вещей.
Если у вас есть процессор Intel, вам нужно проверить T-Junction. Intel говорит, что это «максимальная температура, допустимая на кристалле процессора». «Матрица» относится к крошечным областям схемы на кремниевой пластине. Например, для Core i9-9900K TDP составляет 95 Вт, а T-Junction составляет 100 градусов Цельсия. Чтобы найти T-Junction для Вашего процессора, перейдите на сайт Intel Ark и найдите модель Вашего процессора.
AMD, тем временем, использует более простой термин «Max Temps». Ryzen 5 3600 имеет TDP 65 Вт, Ryzen 5 3600X имеет TDP 95 Вт, и оба имеют максимальную температуру 95 градусов Цельсия.
Это хорошие цифры, чтобы узнать, нужно ли Вам устранять неполадки на компьютере, который перегревается. В целом, однако, в первую очередь лучше сосредоточиться на TDP.
Видеокарты
Для основных потребителей TDP более важен для процессоров. Видеокарты имеют TDP, но они также включают в себя встроенные решения для охлаждения. Вы можете приобрести кулеры для GPU, но их сложнее установить и, как правило, в них нет необходимости, если только Вы не сильно разогнали видеокарту. Если Вы хотите узнать TDP Вашей видеокарты, TechPowerUP является надежным источником.
TDP является важной спецификацией, особенно для процессоров. Но не запутайтесь в его значении. TDP поможет Вам выбрать правильное решение для охлаждения Ваших компонентов.
Вычисления на графических процессорах | Персональный блог | Дайджест новостей
Вычисления на графических процессорах
Технология CUDA (англ. Compute Unified Device Architecture) — программно-аппаратная архитектура, позволяющая производить вычисления с использованием графических процессоров NVIDIA, поддерживающих технологию GPGPU (произвольных вычислений на видеокартах). Архитектура CUDA впервые появились на рынке с выходом чипа NVIDIA восьмого поколения — G80 и присутствует во всех последующих сериях графических чипов, которые используются в семействах ускорителей GeForce, ION, Quadro и Tesla.
CUDA SDK позволяет программистам реализовывать на специальном упрощённом диалекте языка программирования Си алгоритмы, выполнимые на графических процессорах NVIDIA и включать специальные функции в текст программы на Cи. CUDA даёт разработчику возможность по своему усмотрению организовывать доступ к набору инструкций графического ускорителя и управлять его памятью, организовывать на нём сложные параллельные вычисления.
История
В 2003 г. Intel и AMD участвовали в совместной гонке за самый мощный процессор. За несколько лет в результате этой гонки тактовые частоты существенно выросли, особенно после выхода Intel Pentium 4.
После прироста тактовых частот (между 2001 и 2003 гг. тактовая частота Pentium 4 удвоилась с 1,5 до 3 ГГц), а пользователям пришлось довольствоваться десятыми долями гигагерц, которые вывели на рынок производители (с 2003 до 2005 гг.тактовые частоты увеличились 3 до 3,8 ГГц).
Архитектуры, оптимизированные под высокие тактовые частоты, та же Prescott, так же стали испытывать трудности, и не только производственные. Производители чипов столкнулись с проблемами преодоления законов физики. Некоторые аналитики даже предрекали, что закон Мура перестанет действовать. Но этого не произошло. Оригинальный смысл закона часто искажают, однако он касается числа транзисторов на поверхности кремниевого ядра. Долгое время повышение числа транзисторов в CPU сопровождалось соответствующим ростом производительности — что и привело к искажению смысла. Но затем ситуация усложнилась. Разработчики архитектуры CPU подошли к закону сокращения прироста: число транзисторов, которое требовалось добавить для нужного увеличения производительности, становилось всё большим, заводя в тупик.
Причина, по которой производителям GPU не столкнулись с этой проблемой очень простая: центральные процессоры разрабатываются для получения максимальной производительности на потоке инструкций, которые обрабатывают разные данные (как целые числа, так и числа с плавающей запятой), производят случайный доступ к памяти и т.д. До сих пор разработчики пытаются обеспечить больший параллелизм инструкций — то есть выполнять как можно большее число инструкций параллельно. Так, например, с Pentium появилось суперскалярное выполнение, когда при некоторых условиях можно было выполнять две инструкции за такт. Pentium Pro получил внеочередное выполнение инструкций, позволившее оптимизировать работу вычислительных блоков. Проблема заключается в том, что у параллельного выполнения последовательного потока инструкций есть очевидные ограничения, поэтому слепое повышение числа вычислительных блоков не даёт выигрыша, поскольку большую часть времени они всё равно будут простаивать.
Работа GPU относительно простая. Она заключается в принятии группы полигонов с одной стороны и генерации группы пикселей с другой. Полигоны и пиксели независимы друг от друга, поэтому их можно обрабатывать параллельно. Таким образом, в GPU можно выделить крупную часть кристалла на вычислительные блоки, которые, в отличие от CPU, будут реально использоваться.
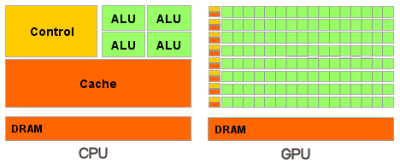
GPU отличается от CPU не только этим. Доступ к памяти в GPU очень связанный — если считывается тексель, то через несколько тактов будет считываться соседний тексель; когда записывается пиксель, то через несколько тактов будет записываться соседний. Разумно организуя память, можно получить производительность, близкую к теоретической пропускной способности. Это означает, что GPU, в отличие от CPU, не требуется огромного кэша, поскольку его роль заключается в ускорении операций текстурирования. Всё, что нужно, это несколько килобайт, содержащих несколько текселей, используемых в билинейных и трилинейных фильтрах.
Первые расчёты на GPU
Самые первые попытки такого применения ограничивались использованием некоторых аппаратных функций, таких, как растеризация и Z-буферизация. Но в нынешнем веке, с появлением шейдеров, начали ускорять вычисления матриц. В 2003 г. на SIGGRAPH отдельная секция была выделена под вычисления на GPU, и она получила название GPGPU (General-Purpose computation on GPU) — универсальные вычисления на GPU).
Наиболее известен BrookGPU — компилятор потокового языка программирования Brook, созданный для выполнения неграфических вычислений на GPU. До его появления разработчики, использующие возможности видеочипов для вычислений, выбирали один из двух распространённых API: Direct3D или OpenGL. Это серьёзно ограничивало применение GPU, ведь в 3D графике используются шейдеры и текстуры, о которых специалисты по параллельному программированию знать не обязаны, они используют потоки и ядра. Brook смог помочь в облегчении их задачи. Эти потоковые расширения к языку C, разработанные в Стэндфордском университете, скрывали от программистов трёхмерный API, и представляли видеочип в виде параллельного сопроцессора. Компилятор обрабатывал файл .br с кодом C++ и расширениями, производя код, привязанный к библиотеке с поддержкой DirectX, OpenGL или x86.
Появление Brook вызвал интерес у NVIDIA и ATI и в дальнейшем, открыл целый новый его сектор — параллельные вычислители на основе видеочипов.
В дальнейшем, некоторые исследователи из проекта Brook перешли в команду разработчиков NVIDIA, чтобы представить программно-аппаратную стратегию параллельных вычислений, открыв новую долю рынка. И главным преимуществом этой инициативы NVIDIA стало то, что разработчики отлично знают все возможности своих GPU до мелочей, и в использовании графического API нет необходимости, а работать с аппаратным обеспечением можно напрямую при помощи драйвера. Результатом усилий этой команды стала NVIDIA CUDA.
Области применения параллельных расчётов на GPU
При переносе вычислений на GPU, во многих задачах достигается ускорение в 5-30 раз, по сравнению с быстрыми универсальными процессорами. Самые большие цифры (порядка 100-кратного ускорения и даже более!) достигаются на коде, который не очень хорошо подходит для расчётов при помощи блоков SSE, но вполне удобен для GPU.
Это лишь некоторые примеры ускорений синтетического кода на GPU против SSE-векторизованного кода на CPU (по данным NVIDIA):
• Флуоресцентная микроскопия: 12x.
• Молекулярная динамика (non-bonded force calc): 8-16x;
• Электростатика (прямое и многоуровневое суммирование Кулона): 40-120x и 7x.
Таблица, которую NVIDIA, показывает на всех презентациях, в которой показывается скорость графических процессоров относительно центральных.
Перечень основных приложений, в которых применяются вычисления на GPU: анализ и обработка изображений и сигналов, симуляция физики, вычислительная математика, вычислительная биология, финансовые расчёты, базы данных, динамика газов и жидкостей, криптография, адаптивная лучевая терапия, астрономия, обработка звука, биоинформатика, биологические симуляции, компьютерное зрение, анализ данных (data mining), цифровое кино и телевидение, электромагнитные симуляции, геоинформационные системы, военные применения, горное планирование, молекулярная динамика, магнитно-резонансная томография (MRI), нейросети, океанографические исследования, физика частиц, симуляция свёртывания молекул белка, квантовая химия, трассировка лучей, визуализация, радары, гидродинамическое моделирование (reservoir simulation), искусственный интеллект, анализ спутниковых данных, сейсмическая разведка, хирургия, ультразвук, видеоконференции.
Преимущества и ограничения CUDA
С точки зрения программиста, графический конвейер является набором стадий обработки. Блок геометрии генерирует треугольники, а блок растеризации — пиксели, отображаемые на мониторе. Традиционная модель программирования GPGPU выглядит следующим образом:
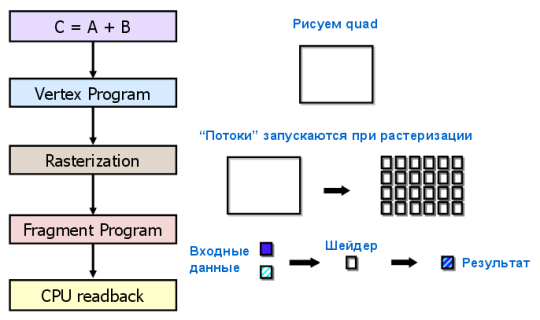
Чтобы перенести вычисления на GPU в рамках такой модели, нужен специальный подход. Даже поэлементное сложение двух векторов потребует отрисовки фигуры на экране или во внеэкранный буфер. Фигура растеризуется, цвет каждого пикселя вычисляется по заданной программе (пиксельному шейдеру). Программа считывает входные данные из текстур для каждого пикселя, складывает их и записывает в выходной буфер. И все эти многочисленные операции нужны для того, что в обычном языке программирования записывается одним оператором!
Поэтому, применение GPGPU для вычислений общего назначения имеет ограничение в виде слишком большой сложности обучения разработчиков. Да и других ограничений достаточно, ведь пиксельный шейдер — это всего лишь формула зависимости итогового цвета пикселя от его координаты, а язык пиксельных шейдеров — язык записи этих формул с Си-подобным синтаксисом. Ранние методы GPGPU являются хитрым трюком, позволяющим использовать мощность GPU, но без всякого удобства. Данные там представлены изображениями (текстурами), а алгоритм — процессом растеризации. Нужно особо отметить и весьма специфичную модель памяти и исполнения.
Программно-аппаратная архитектура для вычислений на GPU компании NVIDIA отличается от предыдущих моделей GPGPU тем, что позволяет писать программы для GPU на настоящем языке Си со стандартным синтаксисом, указателями и необходимостью в минимуме расширений для доступа к вычислительным ресурсам видеочипов. CUDA не зависит от графических API, и обладает некоторыми особенностями, предназначенными специально для вычислений общего назначения.
Преимущества CUDA перед традиционным подходом к GPGPU вычислениям
CUDA обеспечивает доступ к разделяемой между потоками памяти размером в 16 Кб на мультипроцессор, которая может быть использована для организации кэша с широкой полосой пропускания, по сравнению с текстурными выборками;
• более эффективная передача данных между системной и видеопамятью;
• отсутствие необходимости в графических API с избыточностью и накладными расходами;
• линейная адресация памяти, и gather и scatter, возможность записи по произвольным адресам;
• аппаратная поддержка целочисленных и битовых операций.
Основные ограничения CUDA:
• отсутствие поддержки рекурсии для выполняемых функций;
• минимальная ширина блока в 32 потока;
• закрытая архитектура CUDA, принадлежащая NVIDIA.
Слабыми местами программирования при помощи предыдущих методов GPGPU является то, что эти методы не используют блоки исполнения вершинных шейдеров в предыдущих неунифицированных архитектурах, данные хранятся в текстурах, а выводятся во внеэкранный буфер, а многопроходные алгоритмы используют пиксельные шейдерные блоки. В ограничения GPGPU можно включить: недостаточно эффективное использование аппаратных возможностей, ограничения полосой пропускания памяти, отсутствие операции scatter (только gather), обязательное использование графического API.
Основные преимущества CUDA по сравнению с предыдущими методами GPGPU вытекают из того, что эта архитектура спроектирована для эффективного использования неграфических вычислений на GPU и использует язык программирования C, не требуя переноса алгоритмов в удобный для концепции графического конвейера вид. CUDA предлагает новый путь вычислений на GPU, не использующий графические API, предлагающий произвольный доступ к памяти (scatter или gather). Такая архитектура лишена недостатков GPGPU и использует все исполнительные блоки, а также расширяет возможности за счёт целочисленной математики и операций битового сдвига.
CUDA открывает некоторые аппаратные возможности, недоступные из графических API, такие как разделяемая память. Это память небольшого объёма (16 килобайт на мультипроцессор), к которой имеют доступ блоки потоков. Она позволяет кэшировать наиболее часто используемые данные и может обеспечить более высокую скорость, по сравнению с использованием текстурных выборок для этой задачи. Что, в свою очередь, снижает чувствительность к пропускной способности параллельных алгоритмов во многих приложениях. Например, это полезно для линейной алгебры, быстрого преобразования Фурье и фильтров обработки изображений.
Удобнее в CUDA и доступ к памяти. Программный код в графических API выводит данные в виде 32-х значений с плавающей точкой одинарной точности (RGBA значения одновременно в восемь render target) в заранее предопределённые области, а CUDA поддерживает scatter запись — неограниченное число записей по любому адресу. Такие преимущества делают возможным выполнение на GPU некоторых алгоритмов, которые невозможно эффективно реализовать при помощи методов GPGPU, основанных на графических API.
Также, графические API в обязательном порядке хранят данные в текстурах, что требует предварительной упаковки больших массивов в текстуры, что усложняет алгоритм и заставляет использовать специальную адресацию. А CUDA позволяет читать данные по любому адресу. Ещё одним преимуществом CUDA является оптимизированный обмен данными между CPU и GPU. А для разработчиков, желающих получить доступ к низкому уровню (например, при написании другого языка программирования), CUDA предлагает возможность низкоуровневого программирования на ассемблере.
Недостатки CUDA
Один из немногочисленных недостатков CUDA — слабая переносимость. Эта архитектура работает только на видеочипах этой компании, да ещё и не на всех, а начиная с серии GeForce 8 и 9 и соответствующих Quadro, ION и Tesla. NVIDIA приводит цифру в 90 миллионов CUDA-совместимых видеочипов.
Альтернативы CUDA
• OpenCL
Фреймворк для написания компьютерных программ, связанных с параллельными вычислениями на различных графических и центральных процессорах. В фреймворк OpenCL входят язык программирования, который базируется на стандарте C99, и интерфейс программирования приложений (API). OpenCL обеспечивает параллелизм на уровне инструкций и на уровне данных и является реализацией техники GPGPU. OpenCL является полностью открытым стандартом, его использование не облагается лицензионными отчислениями.
Цель OpenCL состоит в том, чтобы дополнить OpenGL и OpenAL, которые являются открытыми отраслевыми стандартами для трёхмерной компьютерной графики и звука, пользуясь возможностями GPU. OpenCL разрабатывается и поддерживается некоммерческим консорциумом Khronos Group, в который входят много крупных компаний, включая Apple, AMD, Intel, nVidia, Sun Microsystems, Sony Computer Entertainment и другие.
• CAL/IL(Compute Abstraction Layer/Intermediate Language)
ATI Stream Technology — это набор аппаратных и программных технологий, которые позволяют использовать графические процессоры AMD, совместно с центральным процессором, для ускорения многих приложений (не только графических).
Областями применения ATI Stream являются приложения, требовательные к вычислительному ресурсу, такие, как финансовый анализ или обработка сейсмических данных. Использование потокового процессора позволило увеличить скорость некоторых финансовых расчётов в 55 раз по сравнению с решением той же задачи силами только центрального процессора.
Технологию ATI Stream в NVIDIA не считают очень сильным конкурентом. CUDA и Stream — это две разные технологии, которые стоят на различных уровнях развития. Программирование для продуктов ATI намного сложнее — их язык скорее напоминает ассемблер. CUDA C, в свою очередь, гораздо более высокоуровневый язык. Писать на нём удобнее и проще. Для крупных компаний-разработчиков это очень важно. Если говорить о производительности, то можно заметить, что её пиковое значение в продуктах ATI выше, чем в решениях NVIDIA. Но опять всё сводится к тому, как эту мощность получить.
• DirectX11 (DirectCompute)
Интерфейс программирования приложений, который входит в состав DirectX — набора API от Microsoft, который предназначен для работы на IBM PC-совместимых компьютерах под управлением операционных систем семейства Microsoft Windows. DirectCompute предназначен для выполнения вычислений общего назначения на графических процессорах, являясь реализацией концепции GPGPU. Изначально DirectCompute был опубликован в составе DirectX 11, однако позже стал доступен и для DirectX 10 и DirectX 10.1.
NVDIA CUDA в российской научной среде.
По состоянию на декабрь 2009 г., программная модель CUDA преподается в 269 университетах мира. В России обучающие курсы по CUDA читаются в Московском, Санкт-Петербургском, Казанском, Новосибирском и Пермском государственных университетах, Международном университете природы общества и человека «Дубна», Объединённом институте ядерных исследований, Московском институте электронной техники, Ивановском государственном энергетическом университете, БГТУ им. В. Г. Шухова, МГТУ им. Баумана, РХТУ им. Менделеева, Российском научном центре «Курчатовский институт», Межрегиональном суперкомпьютерном центре РАН, Таганрогском технологическом институте (ТТИ ЮФУ).
GPU в компьютере что это?
Главный чип на материнской плате – это центральный процессор (CPU – Central Processor Unit). Центральный, потому что управляет всеми остальными подсистемами, с помощью системы шин и чипсета.
Подсистема, которая управляет визуализацией и выводом информации на экран называется видеосистемой. Она интегрируется в материнскую плату через слот в виде видеокарты. Видеокарта – инженерное решение и представляет собой плату с собственным процессором (тем самым GPU) и оперативной памятью.
GPU NVidia Nv45 на видеокарте
Процессор на видеокарте называют GPU (Graphic Processor Unit), чтобы подчеркнуть:
- Что это процессор.
- Что он не центральный, то есть подчиненный для CPU.
- Что он ориентирован на обработку специальных данных – графики.
Расположение GPU на материнской плате
Поскольку обработка графики – это специализация в обработке данных, GPU – это специализированный CPU. Логически специализация выражается отделением GPU от CPU, физически – тем, что GPU устроен иначе.
CPU содержит десятки ядер, GPU — тысячи
Такая физическая реализация GPU обоснована необходимостью обрабатывать тысячи параллельных задач, связанных с отрисовкой. Центральный процессор ориентирован на обработку данных – долгие и последовательные задачи.
Современный ЦП (CPU) может включать в себя графический процессор.
Четрыехядерный процессор с дополнительным графическим ядром GPU
Такое решение позволяет компьютеру обойтись без видеокарты за счет встроенного в центральный процессор GPU. Это снижает потребляемую энергию от 30 до 180%. Стоимость процессора при этом возрастает не более чем на 20%.
Главный минус такой реализации – низкая производительность. Такое решение подходит для офисных компьютеров, где работают с документами и базами данных, но современную компьютерную игру на нем не запустишь, Фотошоп будет притормаживать, а Автокад может зависнуть намертво.
Как узнать GPU в компьютере
Для пользователя GPU прочно ассоциируется с видеокартой, хотя это только процессор. Знать, какой графический адаптер установлен в компьютере полезно в трех случаях:
- при установке или обновлении драйверов;
- при оценке компьютера на соответствие системным требованиям программного обеспечения;
- чтобы хвастаться перед друзьями.
Ели на компьютере установлены все драйвера, то самый быстры способ – посмотреть в диспетчере устройств, в разделе видеоадаптеры:
Просмотр GPU в диспетчере устройств
Если драйвера не установлены диспетчер устройств покажет только надпись о неизвестных устройствах:
GPU в диспетчере устройств в случае отсутствия драйверов
В этом случае скачайте утилиту CPU-Z, запустите и перейдите на вкладку «Графика» (Graphics в англ. версии):
Просмотр GPU в программе CPU-Z