На что влияет кэш процессора L1 L2 L3
Компьютерные процессоры сделали значительный рывок в развитии за последние несколько лет. Размер транзисторов с каждым годом уменьшается, а производительность растет. При этом закон Мура уже становится неактуальным. Что касается производительности процессоров, то следует учитывать, не только количество транзисторов и частоту, но и объем кэша.
Возможно, вы уже слышали о кэш памяти когда искали информацию о процессорах. Но, обычно, мы не обращаем много внимания на эти цифры, они даже не сильно выделяются в рекламе процессоров. Давайте разберемся на что влияет кэш процессора, какие виды кэша бывают и как все это работает.
Содержание статьи:
Что такое кэш процессора?

Если говорить простыми словами, то кэш процессора это просто очень быстрая память. Как вы уже знаете, у компьютера есть несколько видов памяти. Это постоянная память, которая используется для хранения данных, операционной системы и программ, например, SSD или жесткий диск. Также в компьютере используется оперативная память. Это память со случайным доступом, которая работает намного быстрее, по сравнению с постоянной. И наконец у процессора есть ещё более быстрые блоки памяти, которые вместе называются кэшем.
Если представить память компьютера в виде иерархии по её скорости, кэш будет на вершине этой иерархии. К тому же он ближе всего к вычислительным ядрам, так как является частью процессора.
Кэш память процессора представляет из себя статическую память (SRAM) и предназначен для ускорения работы с ОЗУ. В отличие от динамической оперативной памяти (DRAM), здесь можно хранить данные без постоянного обновления.
Как работает кэш процессора?
Как вы, возможно, уже знаете, программа — это набор инструкций, которые выполняет процессор. Когда вы запускаете программу, компьютеру надо перенести эти инструкции из постоянной памяти в процессору. И здесь вступает в силу иерархия памяти. Сначала данные загружаются в оперативную память, а потом передаются в процессор.
В наши дни процессор может обрабатывать огромное количество инструкций в секунду. Чтобы по максимуму использовать свои возможности, процессору необходима супер быстрая память. Поэтому был разработан кэш.
Контроллер памяти процессора выполняет работу по получению данных из ОЗУ и отправке их в кэш. В зависимости от процессора, используемого в вашей системе, этот контроллер может быть размещен в северном мосту материнской плате или в самом процессоре. Также кэш хранит результаты выполнения инструкций в процессоре. Кроме того, в самом кэше процессора тоже есть своя иерархия.
Уровни кэша процессора — L1, L2 и L3
Веся кэш память процессора разделена на три уровни: L1, L2 и L3. Эта иерархия тоже основана на скорости работы кэша, а также на его объеме.
- L1 Cache (кэш первого уровня) — это максимально быстрый тип кэша в процессоре. С точки зрения приоритета доступа, этот кэш содержит те данные, которые могут понадобиться программе для выполнения определенной инструкции;
- L2 Cache (кэш второго уровня процессора)
- L3 Cache (кэш третьего уровня) — это самый большой и самый медленный кэш. Его размер может быть в районе от 4 до 50 мегабайт. В современных CPU на кристалле выделяется отдельное место под кэш L3.
На данный момент это все уровни кэша процессора, компания Intel пыталась создать кэш уровня L4, однако, пока эта технология не прижилась.
Для чего нужен кэш в процессоре?
Пришло время ответить на главный вопрос этой статьи, на что влияет кэш процессора? Данные поступают из ОЗУ в кэш L3, затем в L2, а потом в L1. Когда процессору нужны данные для выполнения операции, он пытается их найти в кэше L1 и если находит, то такая ситуация называется попаданием в кэш. В противном случае поиск продолжается в кэше L2 и L3. Если и теперь данные найти не удалось, выполняется запрос к оперативной памяти.
Теперь мы знаем, что кэш разработан для ускорения передачи информации между оперативной памятью и процессором. Время, необходимое для того чтобы получить данные из памяти называется задержкой (Latency). Кэш L1 имеет самую низкую задержку, поэтому он самый быстрый, кэш L3 — самую высокую. Когда данных в кэше нет, мы сталкиваемся с еще более высокой задержкой, так как процессору надо обращаться к памяти.
Раньше, в конструкции процессоров кєши L2 и L3 были были вынесены за пределы процессора, что приводило к высоким задержкам. Однако уменьшение техпроцесса, по которому изготавливаются процессоры позволяет разместить миллиарды транизисторов в пространстве, намного меньшем, чем раньше. Как результат, освободилось место, чтобы разместить кэш как можно ближе к ядрам, что ещё больше уменьшает задержку.
Как кэш влияет на производительность?
Влияние кэша на произвоидтельность компьютера напрямую зависит от его эффективности и количества попаданий в кэш. Ситуации, когда данных в кэше не оказывается очень сильно снижают общую производительность.
Представьте, что процессор загружает данные из кэша L1 100 раз подряд. Если процент попаданий в кэш будет 100%, процессору понадобиться 100 наносекунд чтобы получить эти данные. Однако, как только процент попаданий уменьшится до 99%, процессору нужно будет извлечь данные из кэша L2, а там уже задержка 10 наносекунд. Получится 99 наносекунд на 99 запросов и 10 наносекунд на 1 запрос. Поэтому уменьшение процента попаданий в кэш на 1% снижает производительность процессора 10%.
В реальном времени процент попаданий в кэш находится между 95 и 97%. Но как вы понимаете, разница в производительности между этими показателями не в 2%, а в 14%. Имейте в виду, что в примере, мы предполагаем, что прощенные данные всегда есть в кэше уровня L2, в реальной жизни данные могут быть удалены из кэша, это означает, что их придется получать из оперативной памяти, у которой задержка 80-120 наносекунд. Здесь разница между 95 и 97 процентами ещё более значительная.
Низкая производительность кэша в процессорах AMD Bulldozer и Piledriver была одной из основных причин, почему они проигрывали процессорам Intel. В этих процессорах кэш L1 разделялся между несколькими ядрами, что делало его очень не эффективным. В современных процессорах Ryzen такой проблемы нет.
Можно сделать вывод, чем больше объем кэша, тем выше производительность, поскольку процессор сможет получить в большем количестве случаев нужные ему данные быстрее. Однако, стоит обращать внимание не только на объем кэша процессора, но и на его архитектуру.
Выводы
Теперь вы знаете за что отвечает кэш процессора и как он работает. Дизайн кэша постоянно развивается, а память становится быстрее и дешевле. Компании AMD и Intel уже провели множество экспериментов с кэшем, а в Intel даже пытались использовать кэш уровня L4. Рынок процессоров развивается куда быстрее, чем когда-либо. Архитектура кэша будет идти в ногу с постоянно растущей мощностью процессоров.
Кроме того, многое делается для устранения узких мест, которые есть у современных компьютеров. Уменьшение задержки работы с памятью одна из самых важных частей этой работы. Будущее выглядит очень многообещающе.
Кэш-память процессора. Уровни и принципы функционирования
Одним из немаловажных факторов повышающих производительность процессора, является наличие кэш-памяти, а точнее её объём, скорость доступа и распределение по уровням.
Уже достаточно давно практически все процессоры оснащаются данным типом памяти, что ещё раз доказывает полезность её наличия. В данной статье, мы поговорим о структуре, уровнях и практическом назначении кэш-памяти, как об очень немаловажной характеристике процессора.
Что такое кэш-память и её структура
Кэш-память – это сверхбыстрая память используемая процессором, для временного хранения данных, которые наиболее часто используются. Вот так, вкратце, можно описать данный тип памяти.
Кэш-память построена на триггерах, которые, в свою очередь, состоят из транзисторов. Группа транзисторов занимает гораздо больше места, нежели те же самые конденсаторы, из которых состоит оперативная память. Это тянет за собой множество трудностей в производстве, а также ограничения в объёмах. Именно поэтому кэш память является очень дорогой памятью, при этом обладая ничтожными объёмами. Но из такой структуры, вытекает главное преимущество такой памяти – скорость. Так как триггеры не нуждаются в регенерации, а время задержки вентиля, на которых они собраны, невелико, то время переключения триггера из одного состояния в другое происходит очень быстро. Это и позволяет кэш-памяти работать на таких же частотах, что и современные процессоры.
Также, немаловажным фактором является размещение кэш-памяти. Размещена она, на самом кристалле процессора, что значительно уменьшает время доступа к ней. Ранее, кэш память некоторых уровней, размещалась за пределами кристалла процессора, на специальной микросхеме SRAM где-то на просторах материнской платы. Сейчас же, практически у всех процессоров, кэш-память размещена на кристалле процессора.
Для чего нужна кэш-память процессора?
Как уже упоминалось выше, главное назначение кэш-памяти – это хранение данных, которые часто используются процессором. Кэш является буфером, в который загружаются данные, и, несмотря на его небольшой объём, (около 4-16 Мбайт) в современных процессорах, он дает значительный прирост производительности в любых приложениях.
Чтобы лучше понять необходимость кэш-памяти, давайте представим себе организацию памяти компьютера в виде офиса. Оперативная память будет являть собою шкаф с папками, к которым периодически обращается бухгалтер, чтобы извлечь большие блоки данных (то есть папки). А стол, будет являться кэш-памятью.
Есть такие элементы, которые размещены на столе бухгалтера, к которым он обращается в течение часа по несколько раз. Например, это могут быть номера телефонов, какие-то примеры документов. Данные виды информации находятся прямо на столе, что, в свою очередь,увеличивает скорость доступа к ним.
Точно так же, данные могут добавиться из тех больших блоков данных (папок), на стол, для быстрого использования, к примеру, какой-либо документ. Когда этот документ становится не нужным, его помещают назад в шкаф (в оперативную память), тем самым очищая стол (кэш-память) и освобождая этот стол для новых документов, которые будут использоваться в последующий отрезок времени.
Также и с кэш-памятью, если есть какие-то данные, к которым вероятнее всего будет повторное обращение, то эти данные из оперативной памяти, подгружаются в кэш-память. Очень часто, это происходит с совместной загрузкой тех данных, которые вероятнее всего, будут использоваться после текущих данных. То есть, здесь присутствует наличие предположений о том, что же будет использовано «после». Вот такие непростые принципы функционирования.
Уровни кэш-памяти процессора
Современные процессоры, оснащены кэшем, который состоит, зачастую из 2–ух или 3-ёх уровней. Конечно же, бывают и исключения, но зачастую это именно так.
В общем, могут быть такие уровни: L1 (первый уровень), L2 (второй уровень), L3 (третий уровень). Теперь немного подробнее по каждому из них:
Кэш первого уровня (L1) – наиболее быстрый уровень кэш-памяти, который работает напрямую с ядром процессора, благодаря этому плотному взаимодействию, данный уровень обладает наименьшим временем доступа и работает на частотах близких процессору. Является буфером между процессором и кэш-памятью второго уровня.
Мы будем рассматривать объёмы на процессоре высокого уровня производительности Intel Core i7-3770K. Данный процессор оснащен 4х32 Кб кэш-памяти первого уровня 4 x 32 КБ = 128 Кб. (на каждое ядро по 32 КБ)
Кэш второго уровня (L2) – второй уровень более масштабный, нежели первый, но в результате, обладает меньшими «скоростными характеристиками». Соответственно, служит буфером между уровнем L1 и L3. Если обратиться снова к нашему примеру Core i7-3770 K, то здесь объём кэш-памяти L2 составляет 4х256 Кб = 1 Мб.
Кэш третьего уровня (L3) – третий уровень, опять же, более медленный, нежели два предыдущих. Но всё равно он гораздо быстрее, нежели оперативная память. Объём кэша L3 в i7-3770K составляет 8 Мбайт. Если два предыдущих уровня разделяются на каждое ядро, то данный уровень является общим для всего процессора. Показатель довольно солидный, но не заоблачный. Так как, к примеру, у процессоров Extreme-серии по типу i7-3960X, он равен 15Мб, а у некоторых новых процессоров Xeon, более 20.
Мифы о кэше процессора, в которые верят программисты / Habr
Как компьютерный инженер, который пять лет занимался проблемами кэша в Intel и Sun, я немного разбираюсь в когерентности кэша. Это одна из самых трудных концепций, которые пришлось изучить ещё в колледже. Но как только вы действительно её освоили, то приходит гораздо лучшее понимание принципов проектирования систем.С другой стороны, неправильные представления о кэшах часто приводят к ложным утверждениям, особенно когда речь идёт о параллелизме и состоянии гонки. Например, часто говорят о трудности параллельного программирования, потому что
Такие заблуждения в основном безвредны (и могут быть даже полезны), но также ведут к плохим решениям при проектировании. Например, разработчики могут подумать, что они избавлены от вышеупомянутых ошибок параллелизма при работе с одноядерными системами. В действительности даже одноядерные системы подвержены риску ошибок параллелизма, если не используются соответствующие конструкции параллелизма.
Или ещё пример. Если переменные volatile действительно каждый раз пишутся/считываются из основной памяти, то они будут чудовищно медленными — ссылки в основной памяти в 200 раз медленнее, чем в кэше L1. На самом деле volatile-reads (в Java) часто настолько же производительны, как из кэша L1, и это развенчивает миф, будто volatile принуждает читает/записывать только в основную память. Если вы избегали volatile из-за проблем с производительностью, возможно, вы стали жертвой вышеуказанных заблуждений.
Но если у разных ядер собственный кэш, хранящий копии одних и тех же данных, не приведёт ли это к несоответствию записей? Ответ: аппаратные кэши в современных процессорах x86, как у Intel, всегда синхронизируются. Эти кэши не просто тупые блоки памяти, как многие разработчики, похоже, думают. Наоборот, очень сложные протоколы и встроенная логика взаимодействия между кэшами обеспечивает согласованность во всех потоках. И всё это происходит на аппаратном уровне, то есть нам, разработчикам программного обеспечения/компиляторов/систем, не нужно об этом думать.
Кратко объясню, что имеется в виду под «синхронизированными» кэшами. Здесь много нюансов, но в максимальном упрощении: если два разных потока в любом месте системы читают с одного и того же адреса памяти, то они никогда не должны одновременно считывать разные значения.
В качестве простого примера, как непротиворечивые кэши могут нарушить вышеупомянутое правило, просто обратитесь к первому разделу этого учебника. Ни один современный процессор x86 не ведёт себя так, как описано в учебнике, но глючный процессор, безусловно, может. Наша статья посвящена одной простой цели: предотвращению таких несоответствий.
Наиболее распространённый протокол для обеспечения согласованности между кэшами известен как протокол MESI. У каждого процессора своя реализация MESI, и у разных вариантов есть свои преимущества, компромиссы и возможности для уникальных багов. Однако у всех них есть общий принцип: каждая строка данных в кэше помечена одним из следующих состояний:
- Модифицированное состояние (M).
- Эти данные модифицированы и отличаются от основной памяти.
- Эти данные являются источником истины, а все остальные источники устарели.
- Эксклюзивное (E).
- Эти данные не модифицированы и синхронизированы с основной памятью.
- Ни в одном другом кэше того же уровня нет этих данных.
- Общее (S).
- Эти данные не модифицированы и синхронизированы.
- В других кэшах того же уровня тоже (возможно) есть те же данные.
- Недействительное (I).
- Эти данные устарели и не должны использоваться.
Если мы применяем и обновляем вышеуказанные состояния, то можно добиться согласованности кэша. Рассмотрим несколько примеров для процессора с четырьмя ядрами, у каждого из которых собственный кэш L1, а также глобальный кэш L2 на кристалле.
Предположим, что поток на core-1 хочет записать в память по адресу 0xabcd. Ниже приведены некоторые возможные последовательности событий.
Попадание в кэш
- В L1-1 есть данные в состоянии E или M.
- L1-1 производит запись. Всё готово.
- Ни в одном другом кэше нет данных, так что немедленная запись будет безопасной.
- Состояние строки кэша изменяется на M, поскольку она теперь изменена.
Промах локального кэша, попадание одноуровневого кэша
- В L1-1 есть данные в состоянии S.
- Это значит, что в другом одноуровневом кэше могут быть эти данные.
- Та же последовательность применяется, если в L1-1 вообще нет этих данных.
- L1-1 отправляет Request-For-Ownership в кэш L2.
- L2 смотрит по своему каталогу и видит, что в L1-2 сейчас есть эти данные в состоянии S.
- L2 отправляет snoop-invalidate в L1-2.
- L1-2 помечает данные как недействительные (I).
- L1-2 отправляет запрос Ack в L2.
- L2 отправляет Ack вместе с последними данными в L1-1.
- L2 проверяет, что в L1-1 эти данные хранятся в состоянии E.
- В L1-1 теперь последние данные, а также разрешение войти в состояние E.
- L1-1 осуществляет запись и изменяет состояние этих данных на M.
Теперь предположим, что поток на core-2 хочет считать с адреса 0xabcd. Ниже приведены некоторые возможные последовательности событий.
Попадание кэша
- L1-2 имеет данные в состоянии S, E или M.
- L1-2 считывает данные и возвращает в поток. Готово.
Промах локального кэша, промах кэша верхнего уровня
- L1-2 имеет данные в состоянии I (недействительное), то есть не может их использовать.
- L1-2 отправляет запрос Request-for-Share в кэш L2.
- В L2 тоже нет данных. Он считывает данные из памяти.
- L2 возвращает данные из памяти.
- L2 отправляет данные в L1-2 с разрешением войти в состояние S.
- L2 проверяет, что в L1-2 эти данные хранятся в состоянии S.
- L1-2 получает данные, сохраняет их в кэше и отправляет в поток.
Промах локального кэша, попадание кэша верхнего уровня
- В L1-2 есть данные в состоянии I.
- L1-2 отправляет запрос Request-for-S в кэш L2.
- L2 видит, что в L1-1 данные в состоянии S.
- L2 отправляет Ack в L1-2, вместе с данными и разрешением войти в состояние S.
- L1-2 получает данные, сохраняет их в кэше и отправляет в поток.
Промах локального кэша, попадание одноуровневого кэша
- В L1-2 есть данные в состоянии I.
- L1-2 отправляет запрос Request-for-S в кэш L2.
- L2 видит, что в L1-1 данные в состоянии E (или M).
- L2 отправляет snoop-share в L1-1
- L1-1 понижает состояние до S.
- L1-1 отправляет Ack в L2 вместе с модифицированными данными, если это применимо.
- L2 отправляет Ack в L1-2 вместе с данными и разрешением войти в состояние S.
- L1-2 получает данные, сохраняет их в кэше и отправляет в поток.
Выше приведены лишь некоторые из возможных сценариев. На самом деле существует много вариаций и нет двух одинаковых реализаций протокола. Например, в некоторых конструкциях используется состояние O/F. В некоторых есть кэши обратной записи, а другие используют сквозную запись. Некоторые используют snoop-трансляции, а другие — snoop-фильтр. В некоторых инклюзивные кэши, а в других — эксклюзивные. Вариации бесконечны, а мы даже не затронули буферы хранения (store-buffers)!
Кроме того, в приведённом примере рассматривается простой процессор всего с двумя уровнями кэширования. Но обратите внимание, что этот же протокол можно применить рекурсивно. Легко добавляется кэш L3, который, в свою очередь, координирует несколько кэшей L2, используя тот же протокол, что приведён выше. У вас может быть многопроцессорная система с «домашними агентами», которые координируют работу нескольких кэшей L3 на совершенно разных чипах.
В каждом сценарии каждому кэшу нужно взаимодействовать только с кэшем верхнего уровня (для получения данных/разрешений) и его потомками (для предоставления/отмены данных/разрешений). Всё это происходит невидимо для программного потока. С точки зрения софта подсистема памяти выглядит как единый, консистентный монолит… с очень переменными задержками.
Мы обсудили удивительную мощность и согласованность системы памяти компьютера. Остался один вопрос: если кэши настолько последовательны, то зачем вообще нужны volatile в языках вроде Java?
Это очень сложный вопрос, на который лучше ответить в другом месте. Позвольте только немного намекнуть. Данные в регистрах CPU не синхронизируются с данными в кэше/памяти. Программный компилятор выполняет всевозможные оптимизации, когда дело доходит до загрузки данных в регистры, записи их обратно в кэш и даже переупорядочивания инструкций. Всё это делается при условии, что код будет выполняться в одном потоке. Поэтому любые данные, подверженные риску состояния гонки, следует защищать вручную с помощью параллельных алгоритмов и языковых конструкций вроде atomic и volatile.
В случае квалификатора volatile в Java решение отчасти состоит в том, чтобы заставить все операции чтения/записи идти в обход локальных регистров, а вместо этого немедленно обращаться к кэшу для чтения/записи. Как только данные считаны/записаны в кэш L1, вступает в силу протокол аппаратного согласования. Он обеспечивает гарантированную согласованность во всех глобальных потоках. Таким образом, если несколько потоков читают/записывают в одну переменную, все они синхронизированы друг с другом. Вот как достигается координация между потоками всего за 1 наносекунду.
Кэш-память процессора. Уровни и принципы функционирования
Одним из немаловажных факторов повышающих производительность процессора, является наличие кэш-памяти, а точнее её объём, скорость доступа и распределение по уровням.
Уже достаточно давно практически все процессоры оснащаются данным типом памяти, что ещё раз доказывает полезность её наличия. В данной статье, мы поговорим о структуре, уровнях и практическом назначении кэш-памяти, как об очень немаловажной характеристике процессора.
Что такое кэш-память и её структура
Кэш-память – это сверхбыстрая память используемая процессором, для временного хранения данных, которые наиболее часто используются. Вот так, вкратце, можно описать данный тип памяти.
Кэш-память построена на триггерах, которые, в свою очередь, состоят из транзисторов. Группа транзисторов занимает гораздо больше места, нежели те же самые конденсаторы, из которых состоит оперативная память. Это тянет за собой множество трудностей в производстве, а также ограничения в объёмах. Именно поэтому кэш память является очень дорогой памятью, при этом обладая ничтожными объёмами. Но из такой структуры, вытекает главное преимущество такой памяти – скорость. Так как триггеры не нуждаются в регенерации, а время задержки вентиля, на которых они собраны, невелико, то время переключения триггера из одного состояния в другое происходит очень быстро. Это и позволяет кэш-памяти работать на таких же частотах, что и современные процессоры.
Также, немаловажным фактором является размещение кэш-памяти. Размещена она, на самом кристалле процессора, что значительно уменьшает время доступа к ней. Ранее, кэш память некоторых уровней, размещалась за пределами кристалла процессора, на специальной микросхеме SRAM где-то на просторах материнской платы. Сейчас же, практически у всех процессоров, кэш-память размещена на кристалле процессора.
Для чего нужна кэш-память процессора?
Как уже упоминалось выше, главное назначение кэш-памяти – это хранение данных, которые часто используются процессором. Кэш является буфером, в который загружаются данные, и, несмотря на его небольшой объём, (около 4-16 Мбайт) в современных процессорах, он дает значительный прирост производительности в любых приложениях.
Чтобы лучше понять необходимость кэш-памяти, давайте представим себе организацию памяти компьютера в виде офиса. Оперативная память будет являть собою шкаф с папками, к которым периодически обращается бухгалтер, чтобы извлечь большие блоки данных (то есть папки). А стол, будет являться кэш-памятью.
Есть такие элементы, которые размещены на столе бухгалтера, к которым он обращается в течение часа по несколько раз. Например, это могут быть номера телефонов, какие-то примеры документов. Данные виды информации находятся прямо на столе, что, в свою очередь,увеличивает скорость доступа к ним.
Точно так же, данные могут добавиться из тех больших блоков данных (папок), на стол, для быстрого использования, к примеру, какой-либо документ. Когда этот документ становится не нужным, его помещают назад в шкаф (в оперативную память), тем самым очищая стол (кэш-память) и освобождая этот стол для новых документов, которые будут использоваться в последующий отрезок времени.
Также и с кэш-памятью, если есть какие-то данные, к которым вероятнее всего будет повторное обращение, то эти данные из оперативной памяти, подгружаются в кэш-память. Очень часто, это происходит с совместной загрузкой тех данных, которые вероятнее всего, будут использоваться после текущих данных. То есть, здесь присутствует наличие предположений о том, что же будет использовано «после». Вот такие непростые принципы функционирования.
Уровни кэш-памяти процессора
Современные процессоры, оснащены кэшем, который состоит, зачастую из 2–ух или 3-ёх уровней. Конечно же, бывают и исключения, но зачастую это именно так.
В общем, могут быть такие уровни: L1 (первый уровень), L2 (второй уровень), L3 (третий уровень). Теперь немного подробнее по каждому из них:
Кэш первого уровня (L1) – наиболее быстрый уровень кэш-памяти, который работает напрямую с ядром процессора, благодаря этому плотному взаимодействию, данный уровень обладает наименьшим временем доступа и работает на частотах близких процессору. Является буфером между процессором и кэш-памятью второго уровня.
Мы будем рассматривать объёмы на процессоре высокого уровня производительности Intel Core i7-3770K. Данный процессор оснащен 4х32 Кб кэш-памяти первого уровня 4 x 32 КБ = 128 Кб. (на каждое ядро по 32 КБ)
Кэш второго уровня (L2) – второй уровень более масштабный, нежели первый, но в результате, обладает меньшими «скоростными характеристиками». Соответственно, служит буфером между уровнем L1 и L3. Если обратиться снова к нашему примеру Core i7-3770 K, то здесь объём кэш-памяти L2 составляет 4х256 Кб = 1 Мб.
Кэш третьего уровня (L3) – третий уровень, опять же, более медленный, нежели два предыдущих. Но всё равно он гораздо быстрее, нежели оперативная память. Объём кэша L3 в i7-3770K составляет 8 Мбайт. Если два предыдущих уровня разделяются на каждое ядро, то данный уровень является общим для всего процессора. Показатель довольно солидный, но не заоблачный. Так как, к примеру, у процессоров Extreme-серии по типу i7-3960X, он равен 15Мб, а у некоторых новых процессоров Xeon, более 20.
Логическая организация кэш-памяти процессора / Habr
На днях решил систематизировать знания, касающиеся принципов отображения оперативной памяти на кэш память процессора. В результате чего и родилась данная статья.Кэш память процессора используется для уменьшения времени простоя процессора при обращении к RAM.
Основная идея кэширования опирается на свойство локальности данных и инструкций: если происходит обращение по некоторому адресу, то велика вероятность, что в ближайшее время произойдет обращение к памяти по тому же адресу либо по соседним адресам.
Логически кэш-память представляет собой набор кэш-линий. Каждая кэш-линия хранит блок данных определенного размера и дополнительную информацию. Под размером кэш-линии понимают обычно размер блока данных, который в ней хранится. Для архитектуры x86 размер кэш линии составляет 64 байта.
Так вот суть кэширования состоит в разбиении RAM на кэш-линии и отображении их на кэш-линии кэш-памяти. Возможно несколько вариантов такого отображения.
DIRECT MAPPING
Основная идея прямого отображения (direct mapping) RAM на кэш-память состоит в следующем: RAM делится на сегменты, причем размер каждого сегмента равен размеру кэша, а каждый сегмент в свою очередь делится на блоки, размер каждого блока равен размеру кэш-линии.
Блоки RAM из разных сегментов, но с одинаковыми номерами в этих сегментах, всегда будут отображаться на одну и ту же кэш-линию кэша:
Адрес каждого байта представляет собой сумму порядкового номера сегмента, порядкового номера кэш-линии внутри сегмента и порядкового номера байта внутри кэш-линии. Отсюда следует, что адреса байт различаются только старшими частями, представляющими собой порядковые номера сегментов, а порядковые номера кэш-линий внутри сегментов и порядковые номера байт внутри кэш-линий — повторяются.
Таким образом нет необходимости хранить полный адрес кэш-линии, достаточно сохранить только старшую часть адреса. Тэг (tag) каждой кэш-линии как раз и хранит старшую часть адреса первого байта в данной кэш-линии.
b — размер кэш-линии.
m — количество кэш-линий в кэше.
Для адресации b байт внутри каждой кэш-линии потребуется: log2b бит.
Для адресации m кэш-линий внутри каждого сегмента потребуется: log2m бит.
m = Объем кэш-памяти/Размер кэш линии.
Для адресации N сегментов RAM: log2N бит.
N = Объем RAM/Размер сегмента.
Для адресации байта потребуется: log2N + log2m + log2b бит.
Этапы поиска в кэше:
1. Извлекается средняя часть адреса (log2m), определяющая номер кэш-линии в кэше.
2. Тэг кэш-линии с данным номером сравнивается со старшей частью адреса (log2N).
Если было совпадение по одному из тэгов, то произошло кэш-попадание.
Если не было совпадение ни по одному из тэгов, то произошел кэш-промах.
FULLY ASSOCIATIVE MAPPING
Основная идея полностью ассоциативного отображения (fully associative mapping) RAM на кэш-память состоит в следующем: RAM делится на блоки, размер которых равен размеру кэш-линий, а каждый блок RAM может сохраняться в любой кэш-линии кэша:
Адрес каждого байта представляет собой сумму порядкового номера кэш-линии и порядкового номера байта внутри кэш-линии. Отсюда следует, что адреса байт различаются только старшими частями, представляющими собой порядковые номера кэш-линий. Порядковые номера байт внутри кэш-линий повторяются.
Тэг (tag) каждой кэш-линии хранит старшую часть адреса первого байта в данной кэш-линии.
b — размер кэш-линии.
m — количество кэш-линий, умещающихся в RAM.
Для адресации b байт внутри каждой кэш-линии потребуется: log2b бит.
Для адресации m кэш-линий: log2m бит.
m = Размер RAM/Размер кэш-линии.
Для адресации байта потребуется: log2m + log2b бит.
Этапы поиска в кэше:
1. Тэги всех кэш-линий сравниваются со старшей частью адреса одновременно.
Если было совпадение по одному из тэгов, то произошло кэш-попадание.
Если не было совпадение ни по одному из тэгов, то произошел кэш-промах.
SET ASSOCIATIVE MAPPING
Основная идея наборно ассоциативного отображения (set associative mapping) RAM на кэш-память состоит в следующем: RAM делится также как и в прямом отображении, а сам кэш состоит из k кэшей (k каналов), использующих прямое отображение.
Кэш-линии, имеющие одинаковые номера во всех каналах, образуют set (набор, сэт). Каждый set представляет собой кэш, в котором используется полностью ассоциативное отображение.
Блоки RAM из разных сегментов, но с одинаковыми номерами в этих сегментах, всегда будут отображаться на один и тот же set кэша. Если в данном сете есть свободные кэш-линии, то считываемый из RAM блок будет сохраняться в свободную кэш-линию, если же все кэш-линии сета заняты, то кэш-линия выбирается согласно используемому алгоритму замещения.
Структура адреса байта в точности такая же, как и в прямом отображении: log2N + log2m + log2b бит, но т.к. set представляет собой k различных кэш-линий, то поиск в кэше немного отличается.
Этапы поиска в кэше:
1. Извлекается средняя часть адреса (log2m), определяющая номер сэта в кэше.
2. Тэги всех кэш-линий данного сета сравниваются со старшей частью адреса (log2N) одновременно.
Если было совпадение по одному из тэгов, то произошло кэш-попадание.
Если не было совпадение ни по одному из тэгов, то произошел кэш-промах.
Т.о количество каналов кэша определяет количество одновременно сравниваемых тэгов.
Что такое кэш память процессора: влияние на скорость работы
Рад приветствовать своих читателей, которые заинтересовались вопросом, что такое кэш память процессора. Эта тема достойна внимания узкопрофильных специалистов. Но я постараюсь в доступной форме изложить базовые знания, которые позволят вам получить представление о системах, ускоряющих работу ЦПУ.
Для начала вспомним, что вообще такое кэш. Как известно компьютер использует различные данные, к которым он обращается с разной периодичностью. Все они изначально хранятся в памяти жесткого диска, но в процессе работы востребованная в данный момент информация извлекаются оттуда и переносятся «поближе» в ОЗУ, откуда их проще и быстрее загружать.
Точно так же из оперативки можно отобрать именно те данные, которые нужны ЦП для решения приоритетных задач. Именно их стоит разместить в непосредственной близости к процессору, и для этого в его микросхеме выделено специальное место – SRAM, обеспечивающее максимально высокую скорость считывания. Это и есть кэш память процессора.
Собственная память процессора
Только что мы отследили иерархию носителей информации с разным уровнем приоритетности: от HDD к ОЗУ, и далее к SRAM. Но внутри cash процессора существует свое разделение, выполненное по аналогичному принципу: более востребованные данные располагаются в секторе меньшего объема, но с большей скоростью считывания.
В самом теле процессора встроен кэш первого (начального уровня), обозначаемый L1 и имеющий объем несколько Кбайт. Обычно он состоит из нескольких блоков, каждый из которых обслуживает отдельное ядро процессора. Далее идет более вместительный кэш второго уровня L2 с меньшей скоростью записи-считывания, который может состоять из одного или нескольких блоков. В современных процессорах имеется и кэш уровня L3 и даже L4.
Последний используется в специальных моделях, предназначенных для работы в мощных серверах. В процессоре вашего ПК так же имеется кэш память. И я подскажу, где посмотреть размер L1, L2 или L3 (если таковая присутствует).
Первый способ – в интернете, по точному названию вашего процессора, которое отображается в свойствах «Моего компьютера».
Второй вариант – загрузить одну из полезных программ CPU-Z или AIDA64 и там среди прочей информации о ЦП вы найдете сведения об уровнях и размерах cash.
Кроме того, различают три вида кэша процессора, каждый из которых имеет определенную специализацию:
- для обработки машинного кода – кэш инструкций;
- для считывания и записи информации – кэш данных;
- буфер ассоциативной трансляции (TLB) – для перевода логических адресов в физические (при работе с кодом и данными).
Схемы записи информации в кэш
Многоуровневая структура памяти процессора обуславливает принцип работы работы с кэшем. Но все-таки первым, к кому обращается ЦП, является реестр. Если нужной информации там не обнаружено, то в зону поиска включается L1.
Для упрощения процедуры поиска информации она разделяется на отдельные блоки. Каждый из которых индексируется тематическим тегом и битом актуальности. Такая метка предназначена для основной и для кэш памяти. Порядок выполнения запроса по тегу такой:
- сначала изучается содержимое L1, и, если обнаруживаются нужные данные, то это событие называется попаданием. Я полагаю, вы догадываетесь, что объем кэша на каждом из уровней позволяет хранить больше разной информации. И влияет на коэффициент попаданий, который в идеале должен быть на уровне 90%;
- при отсутствии нужных тегов в L1 поиск продолжается в L2, далее, при неудачной попытке, в L3;
- если и там не обнаружено данных с нужным тегом, то ЦПУ уже обращается к RAM. Последней «инстанцией», где можно найти всю используемую информацию, является жесткий диск.
Все запросы процессора изначально обрабатываются контроллером кэша. Который уже обращается к SRAM или другим тирам памяти.
Политика записи
После обнаружения нужных данных, необходимо переместить их поближе к процессору, обеспечив наиболее быстрый доступ. И здесь возможны варианты, обусловленные архитектурой кэша и политикой записи.
- При сквозной записи информация заносится в кэш всех ниже расположенных уровней. Например, если данные обнаружены по тегу в ОЗУ, то они заносятся в L3, L2 и L1. Подобная схема работы кэша является инклюзивной и обладает большей эффективностью. Но она целесообразна, если старший уровень памяти существенно превышает низший по объему.
- Отложенная запись подразумевает сразу перенос нужных данных в L1. А уже если в этом кэше потребуется разместить более актуальную информацию. То они будут перемещены на уровень выше (в нашем случае в L2). Из кэша второго уровня, соответственно данные попадают в L3. Такая архитектура памяти называется эксклюзивной и применяется в случаях небольшой разницы в объемах кэша соседствующих уровней.
Алгоритмы замещения
Далее рассмотрим порядок, в соответствии с которым записываются данные в кэш. Обычно это блок информации определенного размера, который или располагается в свободном месте. Или, в случае отсутствия такового, замещает собой ранее записанные данные. Что убирать или какой информацией жертвовать в этом случае определяют алгоритмы замещения, которые бывают следующих типов:
- Least Recently Used (LRU) – убирают то, что дольше всего было невостребованным;
- Least Frequently Used (LFU) – замещают, информацию которую использовали реже остальной;
- Most Recently Used (MRU) – вытесняют буфер, используемый последним;
- Adaptive Replacement Cache (ARC) – совмещение LRU и LFU алгоритмов;
Польза от кэша процессора
Как видите кэш процессора это сложное устройство, усовершенствованием работы которого постоянно занимаются ведущие фирмы производители. Такое внимание уделяется ему не случайно. Ведь быстрая и емкая SRAM память дает возможность существенно повысить быстродействие системы. Особенно ярко проявляется это в случае, когда частота ОЗУ является слабым местом, не позволяющим работать современным процессорам в полную силу.
Какую пользу вы можете извлечь из полученной сегодня информации. Во-первых, повысился уровень вашей компьютерной грамотности. А во-вторых вы теперь знаете, что при выборе процессора стоит взглянуть и на такой параметр как уровни и объем кэш-памяти. На этом я заканчиваю статью о том, что такое кэш память процессора.
Удачи!
На что влияет кэш процессора
Любой компьютер работает как вычислительная машина, в которую вводят исходные данные и от которой требуют вывода результатов определённых вычислений. Для хранения исходных и выходных данных используются жёсткие диски (HDD) и/или твердотельные накопители (SSD), оперативная память (ОЗУ/RAM) и кэш процессора (CPU Cache).
Читайте также: Принцип работы современного компьютерного процессора
Влияние кэша на обработку данных
Несмотря на то, что ОЗУ передаёт информацию с накопителей процессору, и наоборот, сравнительно быстро даже очень производительная ОЗУ не сможет обеспечить такую скорость передачи данных, чтобы CPU не простаивал. Для того чтобы позволить минимизировать время, когда CPU ожидает запрошенную информацию, в само устройство процессора была добавлена сверхбыстрая или сверхоперативная память, называемая кэшем. О его устройстве, назначении и влиянии пойдёт речь в этой статье.
Устройство кэша процессора
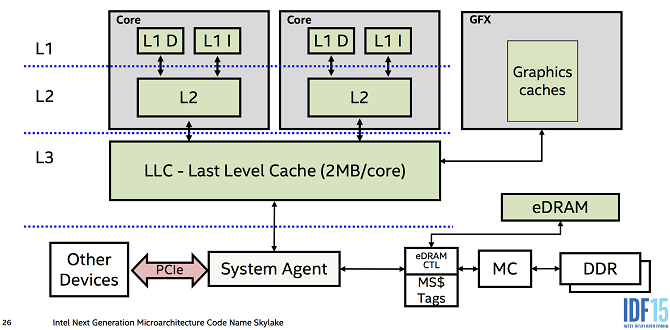
Кэш состоит из двух частей: контроллер и память. С памятью всё просто: там хранится информация, необходимая для вычислений, и результаты обработки информации. Контроллер выполняет функцию обработчика запросов и поисковика запрошенных данных в памяти кэша для произведения вычислений или же передачи/приёма исходящих и входящих данных оперативной памяти.
Память кэша процессора делится на несколько уровней: от L1 до L3. В некоторых моделях был L4, хотя от четвёртого уровня, который использовался в таких CPU, как Core i7-5775C и Core i5-5675C, решили отказаться из-за высокой розничной стоимости.
- L1 — кэш-память первого уровня, обладает минимальным объёмом, не превышающим нескольких сотен килобайт, и самой большой скоростью, позволяющей выдавать информацию сразу после запроса. У каждого ядра присутствует своя схема L1. Информация хранящаяся в кэше первого уровня, является необходимой или чаще всего запрашиваемой для вычислений процессора.
- L2 — кэш-память второго уровня, несколько больше по объёму, может достигать пару мегабайт, при этом уже не такая быстрая. В ней временно хранятся важные данные, которые пользуются меньшим приоритетом при вычислениях. Как и в случае с L1, у каждого ядра своя отдельная схема памяти L2.
- L3 — кэш-память третьего уровня, наибольшая по объёму, достигает десятка, и даже чуть больше, мегабайт, но притом самая медленная. Содержит данные, вероятность запроса которых относительно мала, при этом третий уровень является общим для всех ядер, что улучшает взаимодействие между ними.
Общий принцип работы кэша таков: процессор даёт запрос контроллеру достать из памяти какие-то данные. Контроллер, следуя сложным алгоритмам, последовательно обращается к уровням, то есть от L1 до L3, в поисках нужной информации. Алгоритмы контроллера должны фактически предугадывать, какая информация потребуется процессору для дальнейших вычислений. Если данных нет на L1, то идёт поиск по L2, а потом по L3, при этом создаётся соответствующая задержка, при которой CPU ожидает необходимую информацию. Только когда запрашиваемых данных нет в памяти кэша, происходит запрос к RAM, и CPU действительно простаивает, общение между уровнями кэша не превышает больше десятка наносекунд, даже в случае поиска информации на последнем уровне L3.
В общем виде схему работы памяти кэша и его контроллера по отношению к процессору и оперативной памяти можно изобразить так:

Как видите, между CPU и RAM стоит кэш, представленный контроллером и ячейками памяти по уровням. Получение информации из любой ячейки гораздо быстрее, чем «длинный путь» до оперативной памяти.
Читайте также: Устройство современного процессора компьютера
Влияние кэша
Строго говоря, у процессора нет необходимости в кэше. Однако при этом пользователи сталкивались с длительным временем ожидания, пока RAM передаст нужные данные CPU, и так для каждого сегмента любой операции. Каждый период ожидания начинался от пары секунд, заканчиваясь несколькими минутами. Так что кэш процессора влияет в первую очередь на комфорт пользователя во время работы с компьютером, сильно уменьшая время ожидания.
Обобщая вышесказанное, выходит, что кэш влияет на производительность процессора, лишая его надобности каждый раз делать запрос оперативной памяти на одни и те же данные, храня их у CPU «под боком». В таком случае CPU больше не нуждается в постоянном обновлении информации для однотипных вычислений, и делает их максимально быстро. При этом процессор становится условно независимым от частоты ОЗУ, так как что разница между 1066 МГц и 2400 МГц будет не в 2,25 раза, а в пределах 5% для передачи информации между CPU и RAM.
Как узнать, какой объём кэша у процессора
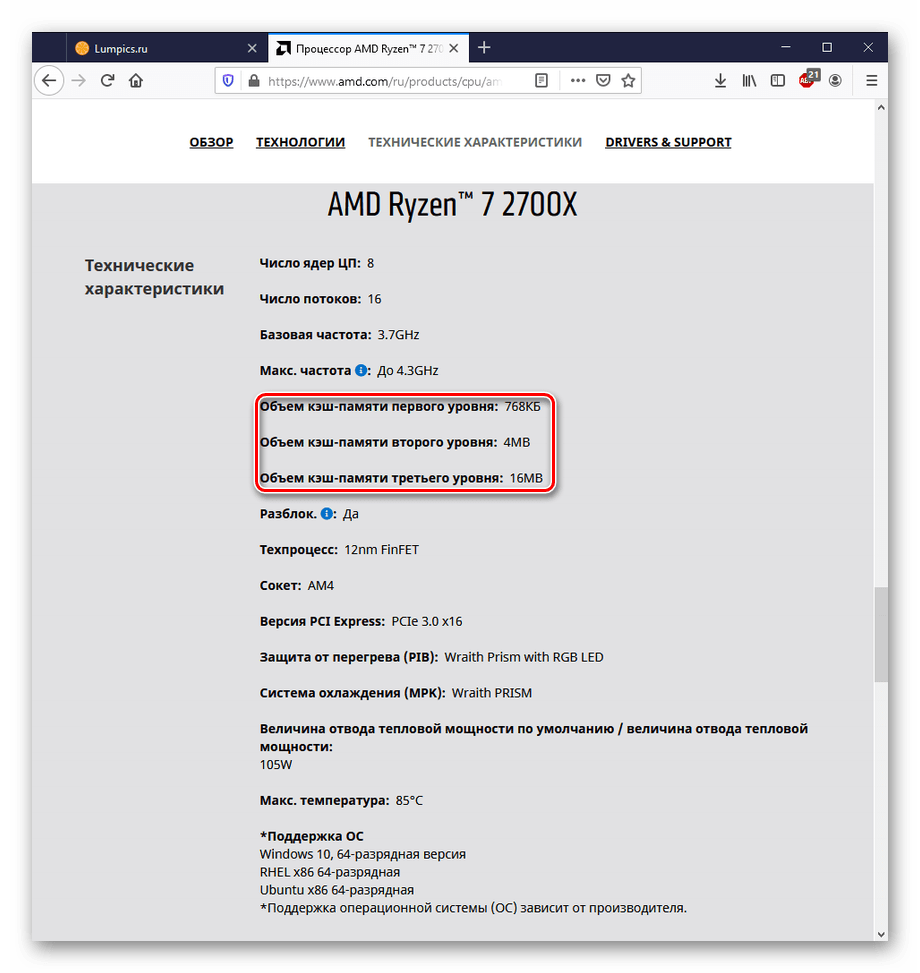
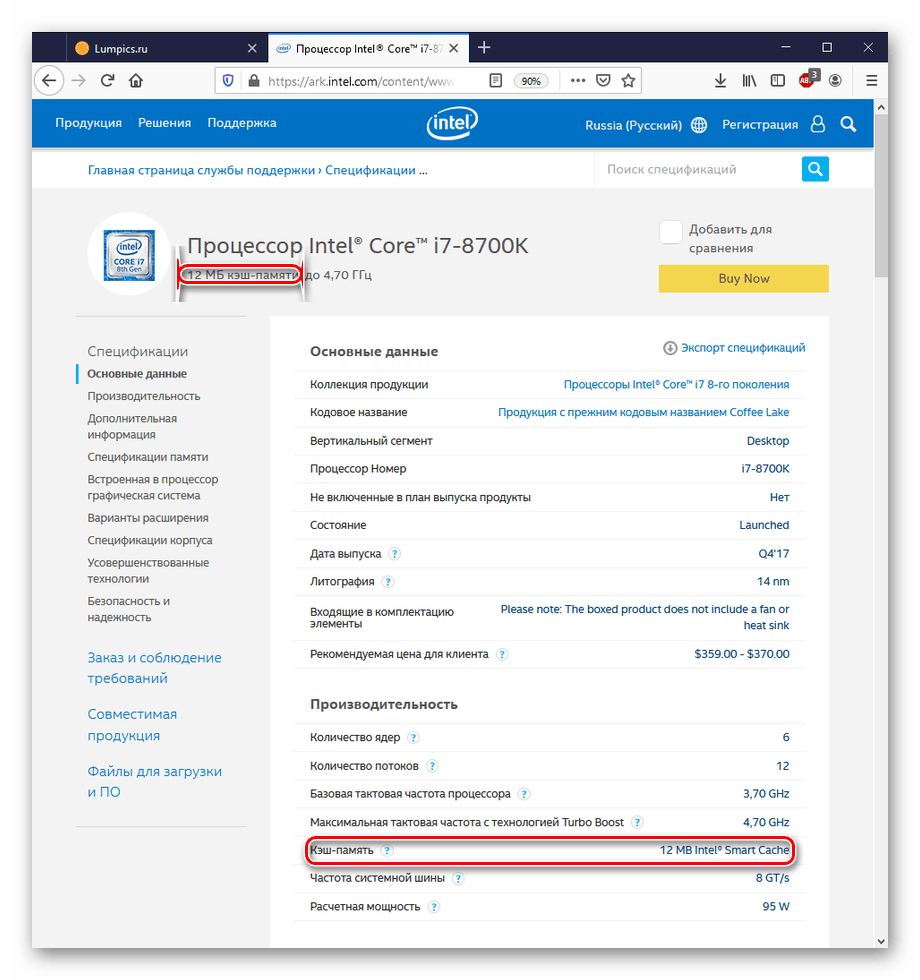
В случае если вы хотите приобрести процессор, лучше всего будет просмотреть значения объёма уровней кэша на официальном сайте производителя:
- Пример отображения технических характеристик на сайте AMD.
- Пример отображения технических характеристик на сайте Intel.
Перейти на официальный сайт AMD
Перейти на официальный сайт Intel
Если вы хотите узнать, какой объём кэша у вашего процессора, следует воспользоваться системным монитором «Диспетчер задач» — нужные значения указаны на вкладке «Производительность».

Заключение
Следует подытожить, что кэш процессора первостепенно влияет на его производительность и общий комфорт пользователя при работе с ПК, не вынуждая юзера длительное время просто просиживать за компьютером, ожидая пока компоненты системы передадут друг другу необходимую информацию для вычислений. При этом кэш лишил пользователей острой надобности в подборе и использовании самых быстрых и с тем дорогостоящих HDD или SSD вкупе с высокочастотной оперативной памятью для минимизации и без того больших простоев. Так что чем больше и сегментированнее кэш (AMD в своё время сделала общий L1 для своей новой линейки процессоров, и те вышли очень малопроизводительными), тем быстрее работает CPU, что удобнее для юзера, и наоборот.
 Мы рады, что смогли помочь Вам в решении проблемы.Опишите, что у вас не получилось.
Наши специалисты постараются ответить максимально быстро.
Мы рады, что смогли помочь Вам в решении проблемы.Опишите, что у вас не получилось.
Наши специалисты постараются ответить максимально быстро.