Эффективные инструменты обработки PDF — ABBYY FineReader Engine
СтранаАвстралияАвстрияАзербайджанАландские ОстроваАлбанияАлжирАмериканское СамоаАнгильяАнголаАндорраАнтарктикаАнтигуа и БарбудаАргентинаАрменияАрубаАфганистанБагамские ОстроваБангладешБарбадосБахрейнБеларусьБелизБельгияБенинБермудские ОстроваБолгарияБоливияБонайре, Саба и Синт-ЭстатиусБосния и ГерцеговинаБотсванаБразилияБританская территория в Индийском океанеБруней-ДаруссаламБуркина-ФасоБурундиБутанВануатуВатиканВеликобританияВенгрияВенесуэлаВиргинские Острова (Великобритания)Виргинские Острова (США)Внешние малые острова CШАВьетнамГабонГаитиГайанаГамбияГанаГваделупаГватемалаГвинеяГвинея-БисауГерманияГернсиГибралтарГондурасГонконгГосударство ПалестинаГренадаГренландияГрецияГрузияГуамДанияДемократическая Республика КонгоДжерсиДжибутиДоминикаДоминиканская РеспубликаЕгипетЗамбияЗападная СахараЗимбабвеИзраильИндияИндонезияИорданияИракИранИрландияИсландияИспанияИталияЙеменКабо-ВердеКазахстанКаймановы ОстроваКамбоджаКамерунКанадаКатарКенияКипрКирибатиКитайКНДРКокосовые ОстроваКолумбияКоморские ОстроваКонгоКоста-РикаКот-д’ИвуарКубаКувейтКыргызстанКюрасаоЛаосЛатвияЛесотоЛиберияЛиванЛивияЛитваЛихтенштейнЛюксембургМаврикийМавританияМадагаскарМайоттаМакаоМакедонияМалавиМалайзияМалиМальдивские ОстроваМальтаМароккоМартиникаМаршалловы ОстроваМексикаМикронезияМозамбикМолдоваМонакоМонголияМонтсерратМьянмаНамибияНауруНепалНигерНигерияНидерландыНикарагуаНиуэНовая ЗеландияНовая КаледонияНорвегияОАЭОманОстров БувеОстров МэнОстров НорфолкОстров РождестваОстров Святой ЕленыОстров Херд и острова МакдональдОстрова КукаОстрова Свальбард и Ян-МайенОстрова Тёркс и КайкосОстрова Уоллис и ФутунаПакистанПалауПанамаПапуа-Новая ГвинеяПарагвайПеруПиткэрнПольшаПортугалияПуэрто-РикоРеспублика КореяРеюньонРоссийская ФедерацияРуандаРумынияСальвадорСамоаСан-МариноСан-Томе и ПринсипиСаудовская АравияСвазилендСвятой ВарфоломейСеверные Марианские островаСейшельские ОстроваСенегалСен-МартенСен-Пьер и МикелонСент-Винсент и ГренадиныСент-Китс и НевисСент-ЛюсияСербияСингапурСинт-МартенСирияСловакияСловенияСоединенные Штаты АмерикиСоломоновы ОстроваСомалиСуданСуринамСьерра-ЛеонеТаджикистанТаиландТайваньТанзанияТимор-ЛештиТогоТокелауТонгаТринидад и ТобагоТувалуТунисТуркменистанТурцияУгандаУзбекистанУкраинаУругвайФарерские ОстроваФиджиФилиппиныФинляндияФолклендские ОстроваФранцияФранцузская ГвианаФранцузская ПолинезияФранцузские Южные территорииХорватияЦентральноафриканская РеспубликаЧадЧерногорияЧехияЧилиШвейцарияШвецияШри-ЛанкаЭквадорЭкваториальная ГвинеяЭритреяЭстонияЭфиопияЮжная АфрикаЮжная Джорджия и Южные Сандвичевы островаЮжный СуданЯмайкаЯпония
ОтрасльБанкиНефть и газГосударственный секторОбразованиеРитейлЭнергетикаТелекоммуникацииПромышленностьСтрахованиеАудит и консалтингИнформационные технологииМедицинаПроизводство продуктов массового потребленияТранспорт / ЛогистикаКультура и искусствоАвтомобильная промышленностьСтроительствоЮридические компанииМедиа / СМИФармацевтикаBPOНедвижимостьКадровые агентстваТуризмСельское хозяйство, Лесное хозяйство и РыболовствоДругое
В каком продукте вы заинтересованы?FineReader Engine 12 for WindowsFineReader Engine 12 for LinuxFineReader Engine 12 for Mac
Я даю свое согласие на получение по электронной почте сообщений от компании ABBYY, которые содержат новости о продуктах и технологиях компании ABBYY, приглашения на мероприятия и вебинары, описания технологий и иные материалы, относящиеся к продуктам и услугам компании ABBYY.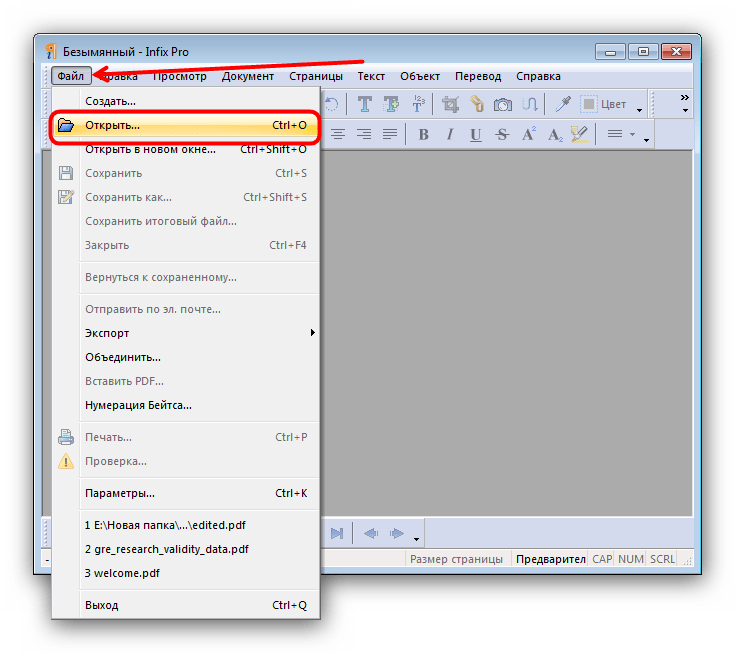
Я проинформирован о том, что я имею право в любое время полностью или частично отозвать вышеуказанное согласие. Для этого нажмите на ссылку «Отписаться» внутри любого письма, полученного от ABBYY, или заполните форму Права доступа ABBYY к персональным данным.
Я хочу получать информацию о новых продуктах, ценовых изменениях, а также о специальных предложениях компании ABBYY. Данное согласие на обработку персональных данных может быть отозвано в любой момент. Для этого нажмите на ссылку «Отписаться» внутри любого письма, полученного от ABBYY.
Данное согласие на обработку персональных данных может быть отозвано в любой момент. Для этого нажмите на ссылку «Отписаться» внутри любого письма, полученного от ABBYY.
Я хочу получать информацию о новых продуктах, ценовых изменениях, а также о специальных предложениях компании ABBYY. Данное согласие на обработку персональных данных может быть отозвано в любой момент. Для этого нажмите на ссылку «Отписаться» внутри любого письма, полученного от ABBYY.
Я даю согласие на использование моих персональных данных для целей, описанных в правовой политике.
(PDF) Обработка данных (Data processing)
ОБРАБОТКА ДАННЫХ (DATA PROCESSING)
Alexander V. Ilyin, Vladimir D. Ilyin
ОБРАБОТКА ДАННЫХ (англ. Data processing), выполнение операций
контроля, преобразования и др. над данными при решении задач учёта,
над данными при решении задач учёта,
обработки результатов эксперимента и др. Реализуется человеком,
компьютерными программами или человеком во взаимодействии с
программами (см. Интерактивный режим). Термин О. д. как правило,
употребляется применительно к решению задач с помощью программ,
установленных в компьютерах и компьютерных устройствах (смартфонах,
ц и ф р о в ы х фотокамерах и д р .) . При э т о м О. д. н а з ы в а ю т
автоматизированной, если в процессе решения человек взаимодействует
с программой (напр., программа медицинской экспертной системы,
взаимодействуя с врачом в интерактивном режиме, выполняет
автоматизир. О. д., помогая врачу в постановке диагноза). Если
программа получает решение без участия человека, то О. д. называют
автоматической (напр., автоматич. О. д. выполняют программы,
установленные в цифровых фото- и видеокамерах). О. д., выполняемую
человеком без помощи компьютерных программ, называют ручной (напр. ,
,
переписчик населения выполняет ручную О. д.).
До сер. 1960-х компьютерные программы условно делили на два
класса: для деловой О.д., с преобладанием операций ввода-вывода и
манипулирования данными (сортировки, организации и др.) при
относительно несложных вычислениях, и научной О. д., характерными
призн а ками которой были т р удоём к ие расчеты. С ра з витием
информационных технологий и программно-аппаратных средств
компьютеров и компьютерных устройств различия между научной и
деловой О. д. становились всё более размытыми. С 1980-х специфика О.
д. учитывается только при разработке специализир. компьютерных
систем (напр., суперкомпьютеров для науч. О. д.).
А. В. Ильин, В. Д. Ильин.
Не удается найти страницу | Autodesk Knowledge Network
(* {{l10n_strings.REQUIRED_FIELD}})
{{l10n_strings.CREATE_NEW_COLLECTION}}*
 ADD_COLLECTION_DESCRIPTION}} {{l10n_strings.COLLECTION_DESCRIPTION}}
{{addToCollection.description.length}}/500
{{l10n_strings.TAGS}}
{{$item}}
{{l10n_strings.PRODUCTS}}
{{l10n_strings.DRAG_TEXT}}
ADD_COLLECTION_DESCRIPTION}} {{l10n_strings.COLLECTION_DESCRIPTION}}
{{addToCollection.description.length}}/500
{{l10n_strings.TAGS}}
{{$item}}
{{l10n_strings.PRODUCTS}}
{{l10n_strings.DRAG_TEXT}}
{{article. content_lang.display}}
content_lang.display}}
Использование OCR для преобразования PDF в электронные счета — Business Central
-
 000Z» data-article-date-source=»ms.date»>04/01/2021
000Z» data-article-date-source=»ms.date»>04/01/2021 - Чтение занимает 7 мин
В этой статье
Из PDF-файлов или файлов изображений, получаемых от торговых партнеров, с помощью внешнего сервиса OCR (оптическое распознавание символов) можно создавать электронные документы, подходящие для преобразования в записи документов в Business Central. Например, при получении от поставщика счета в формате PDF можно отправить его в службу OCR на странице
В качестве альтернативы для отправки файла со страницы Входящие документы можно отправить файл в службу OCR по электронной почте. Затем, когда вы получите документ обратно, автоматически создается соответствующая запись входящего документа. Это описано во второй процедуре.
Спустя несколько секунд файл будет возвращен из службы OCR в виде электронного счета, который может быть преобразован в счет покупки для этого поставщика.
Поскольку процесс сканирования основан на оптическом распознавании, существует вероятность, что служба сканирования интерпретирует символы в ваших PDF-файлах или файлах изображений неправильно, например, при первой обработке документов от определенного поставщика. Он может не распознать логотип компании как наименование поставщика, или неправильно интерпретировать итоговую сумму в квитанции из-за ее расположения. Чтобы избежать подобных ошибок в дальнейшем, можно исправить данные, в отдельной версии страницы Входящие документы. После этого корректировки отправляются обратно в службу OCR, чтобы ошибки были правильно распознаны в следующий раз при обработке PDF-файла или файла изображения от этого поставщика. Дополнительные сведения см. в разделе Обучение службы OCR для предотвращения ошибок.
Перемещение файлов в службу OCR и обратно обрабатывается специальной операцией очереди заданий, которые создаются автоматически при включении соединения со связанной службой.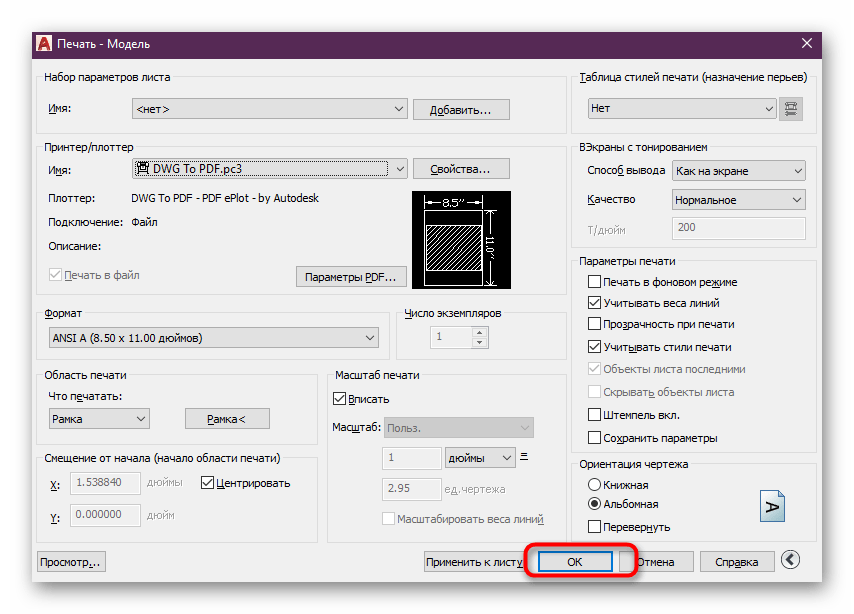 Дополнительные сведения см. в разделе Настройка входящих документов.
Дополнительные сведения см. в разделе Настройка входящих документов.
Отправка PDF-файла или файла изображения в службу OCR со страницы
Входящие документыВыберите значок, введите Входящие документы, а затем выберите связанную ссылку.
Создайте новую запись входящего документа и прикрепите файл. Дополнительные сведения см. в разделе Создание записей входящих документов.
На странице Входящие документы выберите одну или несколько строк, а затем выберите действие Отправить в очередь работ.
Значение в поле Статус OCR будет изменено на Готово. Прикрепленный PDF-файл или файл изображения отправляется в службу OCR очередью заданий по расписанию при условии отсутствия ошибок.
В качестве альтернативы на странице Входящие документы выберите одну или несколько строк, а затем выберите действие Отправить в службу сканирования.


Значение в поле Статус OCR изменяется на Отправлено при условии отсутствия ошибок.
Отправка PDF-файла или файла изображения в службу OCR по электронной почте
Из приложения электронной почты вы можете отправить сообщение электронной почты поставщику службы OCR с прикрепленным PDF-файлом или файлом изображения. Дополнительные сведения об адресе электронной почты получателя см. на веб-сайте поставщика службы OCR.
Поскольку запись входящего документа для файла отсутствует, при получении готового электронного документа из службы OCR на странице Входящие документы автоматически будет создана новая запись. Дополнительные сведения см. в разделе Создание записей входящих документов.
Примечание
Если вы используете планшет или телефон, вы можете отправить файл в службу OCR сразу после создания фотографии документа или создать входящий документ напрямую. Дополнительные сведения см. в разделе Создание записи входящего документа по фотографии.
Чтобы получить созданный электронный документ из службы OCR.
Электронный документ, созданный службой OCR из файла PDF или изображения, автоматически получается а странице Входящие документы с помощью записи очереди работ, которая была настроена при включении службы OCR.
Если очередь заданий не используются или если необходимо получить готовый документ OCR быстрее, чем запланировано в расписании очереди заданий, можно нажать кнопку Получить из службы OCR. Будут получены все документы, уже обработанные службой OCR.
Примечание
Если в службе OCR настроено требование ручной проверки обработанных документов, поле Статус OCR будет содержать значение Ожидает проверки. В этом случае выполните следующие действия, чтобы выполнить вход на веб-сайт службы OCR для проверки OCR-документа вручную.
В поле Статус OCR выберите гиперссылку Ожидает проверки.
На веб-сайте службы OCR выполните вход с помощью учетных данных вашей учетной записи службы OCR. Это те учетные данные, которые использовались при настройке этой службы. Дополнительные сведения см. в разделе Настройка службы распознавания.
Отображается информация для документа OCR, которая показывает как исходное содержимое PDF-файла или графического файла, так и итоговые значения поля OCR.
Просмотрите различные значения полей и вручную измените или введите значения в полях, которые служба OCR пометила, как распознанные неуверенно.
Нажмите кнопку ОК. Процесс OCR завершается, и итоговый электронный документ отправляется на страницу Входящие документы в Business Central в соответствии с расписанием очереди работ.
Повторите шаг 4 для любого документа OCR, который требуется проверить.

Теперь можно переходить к созданию записей документов для полученных электронных документов в Business Central вручную или автоматически. Дополнительные сведения см. в следующей процедуре. Также можно связать новую запись входящего документа с существующим учтенным или неучтенным документом, чтобы обеспечить простой доступ к исходному файлу из Business Central. Дополнительные сведения см. в разделе Обработка входящих документов.
Дополнительные сведения см. в следующей процедуре. Также можно связать новую запись входящего документа с существующим учтенным или неучтенным документом, чтобы обеспечить простой доступ к исходному файлу из Business Central. Дополнительные сведения см. в разделе Обработка входящих документов.
Создание счета покупки из электронного документа, полученного из службы OCR
В следующей процедуре описывается создание записи счета покупки на основе счета поставщика, полученного как электронный документ из службы OCR. Такая же процедура используется при создании, например, строки финансового журнала из расходной квитанции или возврата продажи из клиента.
- Выберите строку для входящего документа, а затем выберите действие Создать документ.
Счет покупки будет создан Business Central на основе информации в электронном документе поставщика, полученном из сервиса OCR. Информация будет вставлена в новый счет покупки на основании сопоставления, которое вы определили в виде перекрестной ссылки или сопоставления текста со счетом.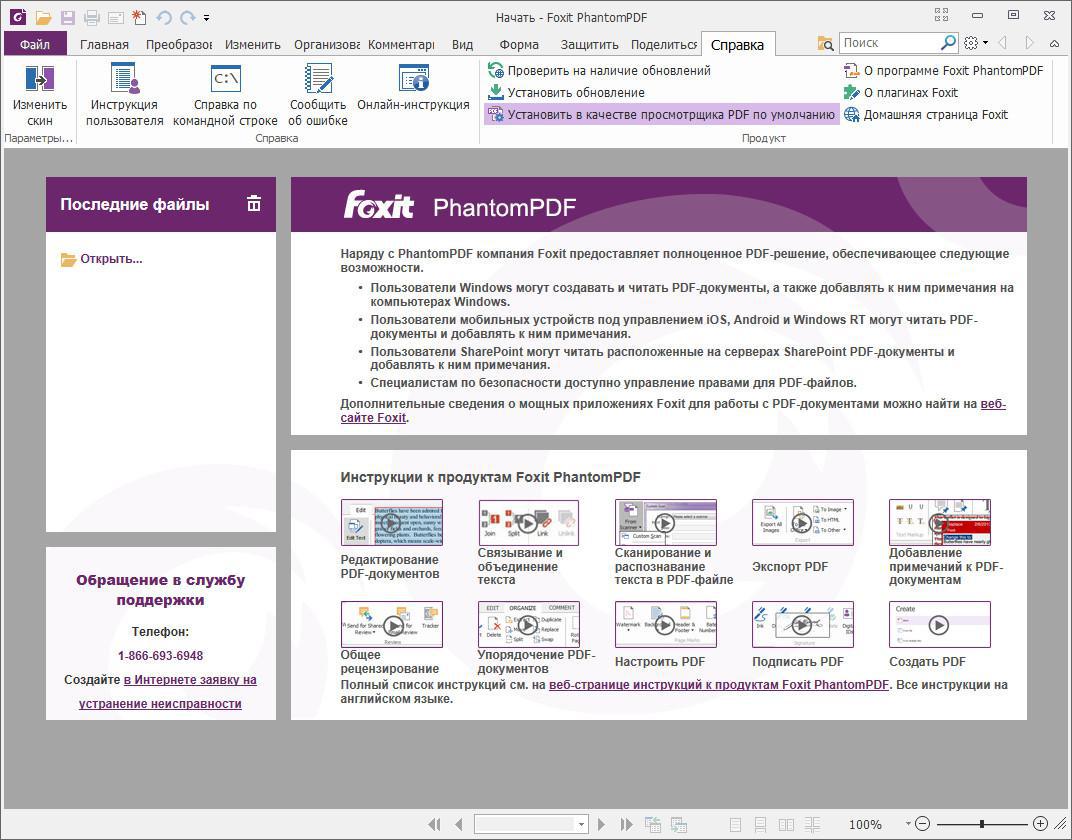
Любые ошибки проверки, обычно связанные с некорректностью или отсутствием данных в Business Central, будут представлены на экспресс-вкладке Ошибки и предупреждения. Дополнительные сведения см. в разделе Обработка ошибок при получении электронных документов.
Сопоставление текста во входящем документе с конкретным счетом поставщика
Для входящих документов обычно используется действие Определить соответствие текста счетам для задания, что определенный текст в счете поставщика, полученного из службы OCR, сопоставляется определенному счету поставщика. После этого любая часть описания входящего документа, которая существует в качестве сопоставления текста, означает, что поле № в получающемся документе или строках журнала типа «Счет ГК», заполняются данными соответствующего поставщика.
В дополнение к сопоставлению со счетом поставщика или другими счетами ГК, также возможно сопоставление с банковским счетом. Это удобно, например, для электронных документов для расходов, которые уже оплачены при создании строки финансового журнала, которая готова к учету на банковском счете.
Выберите соответствующую строку входящего документа, а затем выберите действие Определить соответствие текста счетам. Откроется страница Сопоставление текста со счетами.
В поле Текст сопоставления введите текст, который присутствует на счетах поставщика, для которых вы хотите создавать документы покупки или строки журнала. Можно ввести до 50-ти символов.
В поле Номер поставщика введите поставщика, для которого будет создаваться документ покупки или строка журнала.
В поле Номер дебетового счета введите дебетовый счет ГК, который будет вставляться в создаваемый документ покупки или строку журнала типа «Счет ГК».
В поле Номер кредитового счета введите кредитовый счет ГК, который будет вставляться в создаваемый документ покупки или строку журнала типа «Счет ГК».
Повторите шаги 2–5 для всего текста во входящих документах, для которых вы хотите автоматически создавать документы.

Обработка ошибок при получении электронных документов
- На странице Входящие документы выберите строку, для электронного документа, полученного из службы OCR с ошибками. Это отображается значением «Ошибка» в поле Статус OCR.
- Выберите действие Правка, чтобы открыть страницу Входящие документы.
- На экспресс-вкладке Ошибки и предупреждения выберите сообщение, затем выберите действие Открыть связанную запись.
- Откроется страница, содержащая неверные или отсутствующие данные — например, карточка клиента с отсутствующим значением поля.
- Исправьте ошибку или ошибки, как описано в каждом сообщении об ошибке.
- Продолжите обработку входящего электронного документа, повторно выбрав действие Создать вручную.
- Повторите шаги 5 и 6 для всех оставшихся ошибок, пока электронный документ не будет получен успешно.
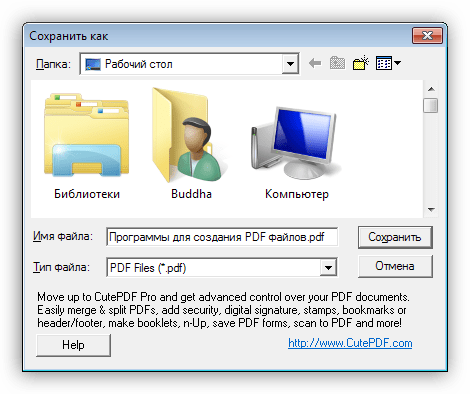
Обучение службы OCR для предотвращения ошибок
Поскольку процесс сканирования основан на оптическом распознавании, существует вероятность, что служба сканирования интерпретирует символы в ваших PDF-файлах или файлах изображений неправильно, например, при первой обработке документов от определенного поставщика. Он может не распознать логотип компании как наименование поставщика, или неправильно интерпретировать итоговую сумму в расходной квитанции из-за ее расположения. Чтобы избежать подобных ошибок в дальнейшем, можно исправить данные, полученные от службы распознавания, и отправить обратную связь в службу.
Страница Корректировка данных OCR, которое можно открыть со страницы Входящий документ, показывает поля экспресс-вкладки Финансовая информация в двух столбцах: один содержит редактируемые данные сканирования, а другой — данные сканирования, доступные только для чтения. При нажатии кнопки Отправить отзыв OCR содержимое страницы Корректировка данных OCR отправляется в службу сканирования.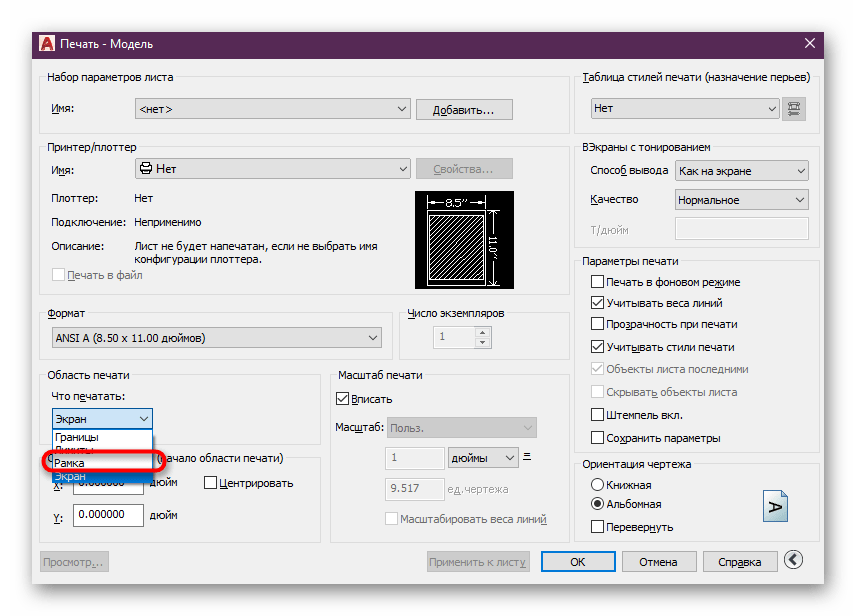 При следующей обработке службой PDF-файлов или файлов изображений, содержащих такие же данные, ваши исправления будут учтены, чтобы избежать повторения ошибок.
При следующей обработке службой PDF-файлов или файлов изображений, содержащих такие же данные, ваши исправления будут учтены, чтобы избежать повторения ошибок.
- Выберите значок, введите Входящие документы, а затем выберите связанную ссылку.
- Откройте запись входящего документа, содержащую данные, полученные от службы OCR, которые необходимо исправить.
- На странице Входящий документ выберите действие Исправить данные OCR.
- На странице Корректировка данных OCR перезапишите данные в доступном для редактирования столбце для каждого поля с неправильным значением.
- Чтобы отменить внесенных с момента открытия страницы Корректировка данных OCR исправления, выберите действие Сбросить данные OCR.
- Для отправки исправлений в службу OCR выберите действие Отправить отзыв OCR.
- Для сохранения исправлений закройте страницу Корректировка данных OCR.

Поля на экспресс-вкладке Финансовые сведения на странице Входящий документ будут обновлены с внесением новых значений, введенных на шаге 4.
См. также
Обработка входящих документов
Входящие документы
Покупки
Работа с Business Central
Выбор текста | Выделите текст, который нужно скопировать или удалить. См. раздел Выделение и копирование текста в файле PDF. |
Выбор прямоугольником | Выделите в изображении прямоугольную область, которую нужно скопировать или удалить. |
Выбор для вымарывания | Выделите текст, который нужно скрыть навсегда. Можно изменять выбор, пока Вы редактируете документ, но после закрытия документа вымарывание становится необратимым. Чтобы защитить исходный документ, создайте дубликат и вымарывайте содержимое в нем. |
Зарисовка | Схематически нарисуйте фигуру одним движением. Если рисунок будет распознан как стандартная фигура, он будет заменен этой фигурой; чтобы использовать свой рисунок, выберите его в показанной палитре. |
Рисовать | Нарисуйте фигуру одним росчерком. Надавите пальцем сильнее, чтобы провести более жирную и темную линию. Этот инструмент отображается только на компьютерах с трекпадом Force Touch. |
Фигуры | Нажмите фигуру, затем перетяните ее в нужное место. Изменить размер фигуры можно с помощью синих манипуляторов. Используя зеленые манипуляторы, можно изменить ее форму. Вы можете увеличивать и выделять фигуры, используя следующие инструменты.
См. раздел Поворот и изменение фигур, добавленных в файл PDF. |
Текст | Введите текст, затем перетяните текст в нужное место. |
Подпись | Если подписи есть в списке, выберите нужную и перетяните туда, где ее нужно поставить. Чтобы изменить размер выделения, используйте синие манипуляторы. Создание новой подписи.
Заполнение форм PDF. |
Заметка | Введите текст. Чтобы изменить цвет заметки, нажмите ее, удерживая клавишу Control, и выберите цвет. См. раздел Добавление примечаний и облачков текста в файл PDF. |
Стиль фигуры | Измените толщину и тип линий фигуры и добавьте тень. |
Цвет границы | Измените цвет линий фигуры. |
Цвет заливки | Измените цвет внутренней области фигуры. |
Стиль текста | Измените гарнитуру, стиль и цвет шрифта. |
Добавить пометку , , | Добавьте пометки к объекту, нарисовав их на находящемся поблизости iPhone или iPad . Если поблизости находятся оба устройства, нажмите , затем выберите устройство. Инструмент может быть выделен, чтобы показать, что устройство подключено. Чтобы отключить устройство, не используя его, снова нажмите инструмент. Устройства должны соответствовать системным требованиям функции «Непрерывность». См. статью службы поддержки Apple Системные требования для использования функции «Непрерывность» на устройствах iPhone, iPad, iPod touch, Apple Watch и компьютере Mac. |

 Возьмите белый лист с подписью и держите его перед камерой так, чтобы подпись оказалась на одном уровне с синей линией в окне приложения. Когда подпись появится в окне, нажмите «Готово». Если получившееся изображение Вам не понравилось, нажмите «Очистить» и повторите попытку.
Возьмите белый лист с подписью и держите его перед камерой так, чтобы подпись оказалась на одном уровне с синей линией в окне приложения. Когда подпись появится в окне, нажмите «Готово». Если получившееся изображение Вам не понравилось, нажмите «Очистить» и повторите попытку. Чтобы переместить заметку, перетяните ее.
Чтобы переместить заметку, перетяните ее.
Как мы научили ABBYY FineReader PDF редактировать целые абзацы / Хабр
Сегодня мы обновили ABBYY FineReader 15 и выпустили его под брендом ABBYY FineReader PDF, потому что он объединяет все инструменты для работы с PDF. По этому поводу публикуем первый пост из серии материалов о фичах программы. В нем мы расскажем об одной интересной возможности, которая не первый месяц есть в программе, но, возможно, не все о ней знали.
Давно ли вы открывали PDF-файлы? Готовы поспорить, что совсем недавно. Скорее всего, на вашем компьютере точно найдется пара сканов, а может, еще и макет презентации, аналитическое исследование или техническая инструкция. Для каких задач обычно используют эти документы? По данным опроса ABBYY, 62% респондентов ищут информацию в PDF, 60% — копируют текст из документа, а 52% — редактируют: вносят в файл правки, исправляют ошибки и опечатки.
Даже сейчас не все знают, что можно редактировать текст в PDF. Да, изменение таких файлов устроено не так, как редактирование обычного текстового документа. ABBYY FineReader PDF с многофункциональным текстовым редактором для работы с PDF и сканами позволяет быстро внести изменения прямо в PDF, без утомительной конвертации файла в другие форматы. При редактировании текст в PDF плавно перетекает со строчки на строчку, как в MS Word. Можно добавить или удалить несколько слов, изменить целые абзацы или даже поменять их местами.
ABBYY FineReader PDF с многофункциональным текстовым редактором для работы с PDF и сканами позволяет быстро внести изменения прямо в PDF, без утомительной конвертации файла в другие форматы. При редактировании текст в PDF плавно перетекает со строчки на строчку, как в MS Word. Можно добавить или удалить несколько слов, изменить целые абзацы или даже поменять их местами.
В этом посте мы раскроем технические подробности редактирования многострочных фрагментов текста в FineReader: как мы изменили движок программы, как редактирование устроено изнутри и как оно выглядит для пользователя. Поехали!
Форматом PDF пользуются по всему миру: его содержимое одинаково отображается на любых компьютерах, смартфонах и планшетах с разными операционными системами. Это удобно и помогает избежать неловких ситуаций. Например, когда вы написали текст в MS Word, отправили коллегам, а они открывают его LibreOffice’ом или Wordpad’ом, и все поехало и начинается веселье. PDF, конечно, в этом плане удобнее, но с текстом здесь все сложно. В 70% всех существующих PDF-документов текст есть, а в 30% — нет, так как это изображения.
В 70% всех существующих PDF-документов текст есть, а в 30% — нет, так как это изображения.
Поговорим сначала о PDF, в которых текст есть. Чтобы редактировать PDF, надо понимать, как в нем записан текст. Открывали когда-нибудь PDF в блокноте? Если да, то вы видели такое:
Чтобы все это отображалось понятно для пользователя, нужно проделать большую работу.
Задача: понять PDF
Содержимое каждой страницы в PDF-файле хранится в виде потоков команд для отрисовки документа – это могут быть текст, изображения или векторная графика. Структуру файла определяют PDF-объекты, например, страница, картинка, комментарий (а абзацы, строчки текста и буквы – это всего лишь части объекта). Символ в PDF представляется
глифом. То, как они записаны, определяется
шрифтом. Каждый символ хранится отдельно: у него есть шрифт, код символа в шрифте и координаты его расположения на странице. То, где глифы расположены, определяется как раз потоком команд. Кроме того, буквы объединены в потоки текста (text run), но они не смысловые.
То, где глифы расположены, определяется как раз потоком команд. Кроме того, буквы объединены в потоки текста (text run), но они не смысловые.
В PDF нет ни строк, ни абзацев, которые есть в документах текстовых форматов. Даже порядок текста не всегда определен. То есть вы видите текст, но на самом деле текста не существует. Это хаос из трудно понятных инструкций (как на изображении выше), которые нужно правильно отобразить в конкретных местах документа, с соответствующим форматированием.
«А как же текст?» – спросите вы.
Текст в PDF все же существует, и его даже получится редактировать. Для этого мы учим наши технологии понимать структуру текста, например, определять и выделять строки. Расскажем об этом подробнее.
Библиотеки PDF и как мы их поменяли
Чтобы сделать возможным редактирование целых абзацев, мы сильно поменяли нашу внутреннюю подсистему (библиотеку), которую мы называем PdfTools. Она занимается тем, что открывает PDF-файлы, парсит потоки команд (т.е. понимает, где расположен текст, где картинки, и воссоздает структуру документа) и помогает пользователям оперировать этими данными: прочитать, изменить, сохранить в PDF.
Подсистема PdfTools содержит все необходимые инструменты, чтобы прочитать содержимое и обернуть его в объекты (страница, картинка, комментарий), с которыми удобно работать программе. С этими объектами уже могут работать наши продукты, в частности ABBYY FineReader PDF и другие.
Как было раньше. В FineReader 14 мы умели редактировать текст только в рамках одной строчки. После редактирования необходимо было выполнить «рендеринг» — расставить глифы на свои новые места.
Вообще рендеринг — это визуализация. Но мы вкладываем в это слово иное понятие — расположение объектов в PDF на своих местах. Для PDF-специалистов это и есть визуализация, которую больше никто не видит. Когда мы говорим о визуализации в привычном понимании, то используем слово «растеризация».
Весь этот процесс располагался в подсистеме PdfTools. Она помогала нам собирать содержимое PDF в строчки и редактировать их. Например, надо поставить на 5-ое месте глиф «А». FineReader передавал подсистеме PdfTools, что на пятое место нужно поставить глиф «А» с заданным размером и шрифтом, а PdfTools вставляла «А» и перемещала на нужное место в строчке все глифы, которые следовали за буквой «А». Построчное редактирование довольно легкое: текст просто смещался вправо или, например, влево, если он записан на иврите или арабском языке. Это позволяло внести небольшие корректировки, например, исправить опечатку, но не давало возможность сделать более глобальные изменения в тексте PDF-документа.
Что решили изменить. Когда появилась задача многострочного редактирования, мы поняли, что в рамках одной библиотеки PdfTools это будет проблематично делать. Нам необходимо было научиться автоматически находить в тексте PDF более крупные фрагменты, например, «видеть» абзацы, понимать, где находятся их границы, какое форматирование должно быть у целого фрагмента текста и что происходит при переходе с одной строки на другую. Чтобы определить все эти параметры, мы решили привлечь для решения этой задачи и другие наши OCR-технологии — Document Analysis (DA) и Synthesis, которые умеют строить структуру документа.
Document Analysis и Synthesis
Чтобы определять в тексте блоки, ABBYY FineReader PDF использует технологию Document Analysis. Она позволяет найти абзацы, таблицы, картинки. Программа подсвечивает найденные блоки небольшими бледными рамками, чтобы пользователю удобнее было вносить правки:
Далее мы усовершенствовали другую подсистему нашей программы – Synthesis. Мы уже рассказывали на Хабре, зачем она нужна. Если вкратце, именно она определяет структуру и все характеристики распознанного текста: какие используются шрифты и размеры, какое начертание (bold, italic, underline), где заголовки, списки, отступы и многие другие параметры, которые можно настраивать в том же MS Word. Мы доработали Synthesis для того, чтобы при распознавании и воссоздании страницы очень точно восстанавливать исходные параметры текста.
Особенности подчеркнутого текста
В PDF нет такого атрибута текста как подчеркивание, привычного, например, пользователям MS Word. Подчеркивание в PDF – это векторная графика, никак не связанная с текстом. Без дополнительной доработки продукта при редактировании «подчеркнутого» текста символы бы перемещались привычным образом, а линии, обозначающие подчеркивания, оставались бы на месте. ABBYY FineReader PDF умеет определять и редактировать подчеркнутый текст привычным пользователю образом.
Редактирование таблиц в PDF
Изменилось и редактирование таблиц. Раньше программа «видела» таблицу, как отдельные строки, и редактировала ее так же. Теперь при работе с таблицами ABBYY FineReader PDF определяет содержимое каждой ячейки, умеет извлекать из них текст и работать с ним. Это удобно, когда надо исправить ошибку в цифре, поменять точку на запятую и при этом сохранить структуру таблицы, сделать это быстро и без конвертации PDF-документа в другие форматы.
Как отредактировать скан?
Возможность многострочного редактирования доступна и для сканов. Кстати, пользователю даже не надо задумываться, скан перед ним или нет. ABBYY FineReader PDF сам определит это и запустит нужные механизмы. Например, в дате договора — опечатка, или ФИО контрагента поменялось: оно стало длиннее и должно «перетечь» на следующую строчку.
В программе скан сначала распознается, а потом происходит подготовка к редактированию. Когда скан распознали, то текст получается не в нашем исходном документе, а в его виртуальном «двойнике». И именно в нем происходят все операции по редактированию.
Когда пользователь закончил редактировать документ, программа автоматически собирает все изменения со страницы и заменяет эти фрагменты в исходном документе. Наша задача — встроить текст обратно в PDF-документ, не повредив все то остальное, что уже есть в нем.
Редактирование скана позволяет не тратить время на конвертацию документа в другие форматы и обратно. Это удобно, когда нужно быстро внести забытую правку в дату или другой фрагмент текста.
Пример многострочного редактирования. Текст автоматически перераспределяется по строкам по мере добавления слов и предложений внутри абзаца.
Вместо заключения
Исправить опечатку в листовке, поменять местами текстовые блоки в инструкции, изменить целый абзац в скане договора или добавить несколько новых, поправить форматирование всего текста – все эти задачи теперь возможно решить:
- быстро,
- без конвертации документа,
- с помощью одной программы.
Попробовать можно прямо сейчас – скачайте
триал-версию ABBYY FineReader PDFбесплатно.
В следующем посте через неделю мы расскажем о том, как научили ABBYY FineReader PDF еще одной интересной фиче и для чего может пригодиться новая функциональность.
Пишите в комментариях, о каких еще технологических особенностях нашей программы вам было бы интересно узнать?
«ОФД-Я» — оператор фискальных данных
Политика ООО «Ярус» в отношении обработки персональных данных
ООО «Ярус»
Юридический и фактический адрес:
Фактический адрес: 115280 г. Москва, ул. Ленинская Слобода, д. 19, стр.4
Юридический адрес: 117292, г. Москва, Нахимовский просп., д. 52/27, помещение Б
1. Общие положения
1.1. Настоящий документ (далее — Политика) определяет цели и общие принципы обработки персональных данных, а также реализуемые меры защиты персональ ных данных в ООО «Ярус» (далее — Оператор). Политика является общедоступным документом Оператора и предусматривает возможность ознакомления с ней любых лиц.
1.2. Политика разработана в соответствии и на основании Конституции Российской Федерации, Федерального закона от 27.07.2006 N 152-ФЗ «О персональных данных», Федерального закона от 22.05.2003 N 54-ФЗ «О применении контрольно-кассовой техники при осуществлении наличных денежных расчетов и(или) расчетов с использованием электронных средств платежа», а также иных нормативных правовых актов Российской Федерации, локальных актов ООО «Ярус».
1.3. Политика неукоснительно исполняется руководителями и работниками всех структурных подразделений и филиалов ООО «Ярус».
1.4. Действие Политики распространяется на все персональные данные субъектов, получаемые и обрабатываемые ООО «Ярус» с применением средств автоматизации и без применения таких средств.
2. Определения
2.1. Персональные данные — любая информация, относящаяся к прямо или косвенно определенному, или определяемому физическому лицу (субъекту персональных данных).
2.2. Обработка персональных данных – любое действие (операция) или совокупность действий (операций) с персональными данным, совершаемых с использованием средств автоматизации или без использования таких средств. К таким действиям (операциям) можно отнести: сбор, получение, запись, систематизацию, накопление, хранение, уточнение (обновление, изменение), извлечение, использование, передачу (распространение, предоставление, доступ), обезличивание, блок ирование, удаление, уничтожение персональных данных.
2.3. Субъект персональных данных — любое лицо, персональные данные которого обрабатываются оператором персональных данных.
2.4. Оператор персональных данных — ООО «Ярус».
3. Обработка персональных данных
3.1. О бработка персональных данных осуществляется с учетом следующих требований:
— обработке подлежат только персональные данные, которые отвечают целям их обработки;
— содержание и объем обрабатываемых персональных данных должны соответствовать заявленным целям обработки;
— обрабатываемые персональные данные не должны быть избыточными по отношению к заявленным целям их обработки;
— при обработке персональных данных должны быть обеспечены точность и достаточность сведений по отношению к целям обработки персональных данных.
3.2. Содержание и объем обрабатываемых персональных данных определяются исходя из уставных целей деятельности Оператора, на основании и во исполнение требований законодательства РФ, в т. ч. Федерального закона от 22.05.2003 N 54-ФЗ «О применении контрольно-кассовой техники при осуществлении наличных денежных расчетов и(или) расчетов с использованием электронных средств платежа».
3.3. К основным категориям субъектов персональных данных, чьи данные обрабатываются и/или могут обрабатываться Оператором в соответствии с целями их получения, относятся физические лица:
- лица, состоящие и состоявшие в трудовых и гражданско-правовых отношениях с Оператором и/или контрагентами Оператора;
- кандидаты на замещение вакантных должностей;
- лица, имеющие граж данско-правовой характер договорных отношений с Оператором, или находящиеся на этапе преддоговорных или выполненных отношений подобного характера;
- лица, сообщившие свои персональные данные в процессе взаимодействия с Оператором, в том числе путем подключения к сервисам Оператора и/или подписания юридических документов с Оператором.
3.4. Для указанных категорий субъектов могут обрабатываться сведения, в том числе запрашиваемые на сервисах Оператора, включая, но не ограничиваясь: фамилия, имя, отчество; год, месяц, дата рождения; место рождения, адрес; семейное положение; социальное положение; имущественное положение; образование; профессия; доходы; ИНН, СНИЛС, контактная информация (телефон, адрес, адрес электронной почты и т. п.), а также иные сведения, необх одимые для целей обработки.
3.5. Оператор вправе обрабатывать персональные данные субъектов, в том числе следующими способами:
сбор, запись, систематизация, накопление, хранение, уточнение (обновление, изменение), извлечение, использование, передачу (распр остранение, предоставление, доступ), обезличивание, блокирование, удаление, уничтожение персональных данных.
3.6. Оператор осуществляет обработку персональных данных с использованием средств автоматизации и без использования средств автоматизации.
3.7. Обработка и хранение персональных данных осуществляются не дольше, чем этого требуют цели обработки персональных данных, если отсутствуют законные основания для дальнейшей обработки.
4. Меры по обеспечению безопасности персональных данных
4.1. Оператор принимает технические и организационные меры обеспечения безопасности с целью защиты персональных данных от случайного или незаконного уничтожения, потери или изменения, а также от несанкционированного разглашения или доступа к персональным данным.
4.2. Для предотвращения несанкционированного доступа к персональным данным Оператором применяются следующие организационно — технические меры:
- назначение должностных лиц, ответственных за организацию обработки и защиты персональных данных;
- ограничение состава лиц, имеющих доступ к персональным данным;
- организация учета, хранения и обращения носителей информации;
- проверка готовности и эффективности использования средств защиты информации;
- разграничение доступа пользователей к информационным ресурсам и программно-аппаратным средствам обработки информации;
- регистрация и учет действий пользователей информационных систем персональных данных;
- использование средств защиты и средств восстановления системы защиты персональных данных;
- организация пропускного режима на территорию Оператора, охраны помещений с техническими средствами обработки персональных данных.
5. Права субъектов персональных данных
5.1. Субъект персональных данных принимает решение о предоставлении его персональных данных и дает согласие на их обработку свободно, своей волей и в своем интересе. Согласие на обработку персональных данных может быть дано субъектом персональных данных или его представителем в любой позволяющей подтвердить факт его получения форме, если иное не установлено законодательством РФ.
5.2. Субъект персональных данных имеет право отозвать согласие на обработку персональных данных, направив соответствующий письменный запрос Оператору.
5.3. Субъект персональных данных имеет право на получение информации, касающейся обработки его персональных да нных, в том числе содержащей:
- подтверждение факта обработки персональных данных Оператором;
- правовые основания и цели обработки персональных данных;
- цели и применяемые Оператором способы обработки персональных данных;
- наименование и место нахождения Оператора, сведения о лицах (за исключением сотрудников/работников Оператора), которые имеют доступ к персональным данным или которым могут быть раскрыты персональные данные на основании договора с Оператором или на основании федерального закона;
- обрабатываемые персональные данные, относящиеся к соответствующему субъекту персональных данных, источник их получения, если иной порядок представления таких данных не предусмотрен федеральным законом;
- сроки обработки персональных данных, в том числе сроки их хранения;
- порядок осуществления субъектом персональных данных прав, предусмотренных Федеральным законом «О персональных данных»;
- информацию об осуществленной или о предполагаемой трансграничной передаче данных;
- наименование или фамилию, имя, отчество и адрес лица, осуществляющего обработку персональных данных по поручению Оператора , если обработка поручена или будет поручена такому лицу;
- иные сведения, предусмотренные Федеральным законом «О персональных данных» или другими федеральными законами.
5.4. Субъект персональных данных вправе требовать от Оператора уточнения его персональных данных, их блокирования или уничтожения в случае, если персональные данные являются неполными, устаревшими, неточными, незаконно полученными или не являются необходимыми для заявленной цели обработки, а также принимать предусмотренные законом меры по защите своих прав.
5.5. Если субъект персональных данных считает, что Оператор осуществляет обработку его персональных данных с нарушением требований законодательства РФ или иным образом нарушает его права и свободы, субъект персональных данных вправе обжаловать действия или бездействие Оператора в уполномоченный орган или в судебном порядке.
6. Доступ к Политике
6.1. Действующая редакция Политики на бумажном носителе хранится по месту нахождени я исполнительного органа Оператора по адресу: 115280 г. Москва, ул. Ленинская Слобода, д.19, стр.4
6.2. Электронная версия действующей редакции Политики общедоступна на сайте Оператора в сети Интернет: здесь
7. Актуализация и утверждение Политики
7.1. Политика утверждается и вводится в действие руководителем ООО «Ярус».
7.2 Оператор имеет право вносить изменения в настоящую Политику.
8. Ответственность
8.1. Лица, виновные в нарушении норм, регулирующих обработку и защиту персональных данных, несут ответственность, предусмотренную законодательством РФ, локальными актами Оператора и договорами, регламентирующими правоотношения Оператора с субъектом персональных данных и/или третьими лицами.
9. Заключительные положения
9.1. Оператор вправе вносить изменения и дополнения в настоящую Политику в отношении обработки персональных данных в любое время без предварительного уведомления Пользователей.
При этом субъект персональных данных обязан самостоятельно отслеживать изменения и дополнения в настоящую Политику. В случае несогласия с условиями настоящей Политики и/или отдельных ее положений, а также изменений и дополнений к ней, Оператор просит воздержаться от посещения и использования сервисов Оператора и не предоставлять свои персональные данные. В противном случае Оператор вправе обрабатывать персональные данные в соответствии с Политикой и не несет какой-либо ответственности в связи с этим.
| Страницы | Добавление, изменение или удаление страниц в документе. Свойства позволяют изменять размер страницы, ее поворот и многое другое. |
| Автоматическая раскладка | Несмотря на то, что формат PDF является фиксированным, иногда вам нужно вставить содержимое таким образом, чтобы оно текло по странице. RadPdfProcessing позволяет легко добиться этого с помощью блоков, таблиц и списков. |
| Изображения | Декодируется по запросу для повышения производительности. API позволяет получить данные закодированного изображения. Вы также можете контролировать качество изображения при сохранении документа. |
| Геометрия | Позволяет описывать геометрию 2D-формы. |
| Форма XObjects | Form XObjects позволяет описывать составные объекты (состоящие из текста, изображений, векторных элементов и т. Д.)) в файле PDF и повторно используйте это содержимое в документе для уменьшения размера документа и повышения производительности рендеринга. |
| Интерактивные формы | Создавайте и изменяйте PDF-файлы, содержащие текстовые поля, кнопки, списки и другие интерактивные элементы управления, позволяя пользователю PDF-файла интерактивно заполнять некоторые данные в PDF-документе и / или подписывать заполненный документ цифровой подписью. Вы также можете выровнять поля. |
| Цифровая подпись | Функция цифровой подписи позволяет подписывать и проверять документ PDF (ограниченная поддержка в.NET Standard). |
| Клипса | Вы можете определить контур других элементов содержимого, таких как изображения и пути. |
| Закладки (контуры) | Добавляйте, удаляйте или изменяйте закладки в документе PDF. |
| Аннотации | Свяжите объект с местом на странице документа PDF. |
| Пункты назначения | Определяет конкретный вид документа. |
| Цвета и цветовые пространства | Поддержка обоих типов. |
| Шрифты | Поддержка стандартных шрифтов PDF, Type0, Type1, CIDFontType2, TrueType и других. |
| Текстовые и графические свойства | Предоставляет возможности для изменения свойств различных элементов в элементах документа, чтобы вы могли добиться уникального внешнего вида. |
| Защита паролем | Поддержка документов, зашифрованных с помощью алгоритма шифрования (RC4 / AES-128) |
| Объединить документы и страниц документа | Вы можете объединить страницы из нескольких документов в один документ. |
| PdfStreamWriter | API предоставляет функциональные возможности для экспорта файлов PDF с непревзойденной производительностью и минимальным объемом памяти. Чрезвычайно полезно, когда вам нужно добавить контент в существующий документ, объединить или разделить документы. |
| Импорт PDF и экспорт в PDF или обычный текст | Вы можете импортировать или экспортировать файлы PDF и преобразовывать файлы PDF в простой текст. |
Обработка PDF с помощью Python.Способ извлечения текста из вашего pdf… | Ахмед Хемири
Фотография Джеймса Харрисона на UnsplashВведение
Python, интерпретируемый язык высокого уровня с относительно простым синтаксисом, идеален даже для тех, кто не имеет опыта программирования. Популярные библиотеки Python хорошо интегрированы и предоставляют решение для работы с неструктурированными источниками данных, такими как Pdf, и могут использоваться, чтобы сделать его более разумным и полезным.
PDF — один из самых важных и широко используемых цифровых носителей.используется для представления и обмена документами. PDF-файлы содержат полезную информацию, ссылки и кнопки, поля форм, аудио, видео и бизнес-логику.
1- Почему Python для обработки PDF-файлов
Как вы знаете, обработка PDF-файлов относится к аналитике текста.
Большая часть библиотеки или фреймворков текстовой аналитики разработана только на Python. Это дает возможность использовать текстовую аналитику. Еще одна вещь: вы никогда не сможете обработать PDF-файл напрямую в существующих фреймворках машинного обучения или обработки естественного языка.Если они не доказывают явный интерфейс для этого, мы должны сначала преобразовать PDF в текст.
2- Python Librairies для обработки PDF
Как специалист по данным, вы не можете придерживаться формата данных.
PDF-файлы — хороший источник данных, большинство организаций публикует свои данные только в PDF-файлах.
По мере роста ИИ нам требуется больше данных для прогнозирования и классификации; следовательно, игнорирование PDF-файлов в качестве источника данных для вас может быть ошибкой. На самом деле обработка PDF-файлов немного сложна, но мы можем использовать приведенный ниже API, чтобы упростить ее.
В этом разделе мы откроем для себя Top Python PDF Library:
PDFMiner
PDFMiner — это инструмент для извлечения информации из документов PDF. В отличие от других инструментов, связанных с PDF, он полностью ориентирован на получение и анализ текстовых данных. PDFMiner позволяет получить точное расположение текста на странице, а также другую информацию, такую как шрифты или линии. Он включает конвертер PDF, который может преобразовывать файлы PDF в другие текстовые форматы (например, HTML).Он имеет расширяемый анализатор PDF, который можно использовать не только для анализа текста, но и для других целей.
PyPDF2
PyPDF2 — это библиотека PDF на чистом Python, способная разделять, объединять, обрезать и преобразовывать страницы файлов PDF. Он также может добавлять пользовательские данные, параметры просмотра и пароли в файлы PDF. Он может извлекать текст и метаданные из PDF-файлов, а также объединять файлы целиком.
pdfrw
pdfrw — это библиотека и утилита Python, которая читает и записывает файлы PDF:
- Версия 0.4 протестирован и работает на Python 2.6, 2.7, 3.3, 3.4, 3.5 и 3.6
- Операции включают подмножество, объединение, вращение, изменение метаданных и т. Д.
- Самый быстрый доступный синтаксический анализатор PDF на чистом Python
- Используется годами принтером при допечатной подготовке
- Может использоваться с rst2pdf для точного воспроизведения векторных изображений
- Может использоваться либо отдельно, либо вместе с reportlab для повторного использования существующих PDF-файлов в новых
- Разрешенная лицензия
Slate
Slate — это пакет Python, который упрощает процесс извлечения текста из файлов PDF.Это зависит от пакета PDFMiner.
3- Среда установки
Шаг 1: Выберите версию Python для установки с Python.org .
Шаг 2: Загрузите установщик исполняемого файла Python.
Шаг 3: Запустите исполняемый установщик.
Шаг 4: Убедитесь, что Python был установлен в Windows.
Шаг 5: Убедитесь, что Pip был установлен.
Шаг 6: Добавьте путь Python к переменным среды (необязательно).
Шаг 7 : Установите расширение Python для своей среды IDE.
Я работаю с Python 3.7 в коде Visual Studio. Для получения дополнительных сведений о том, как настроить среду и выбрать интегратор Python для начала кодирования с помощью VS Code, см. Начало работы с Python в документации VS Code.
Шаг 7: Теперь вы сможете выполнять скрипты Python в своей среде IDE.
Шаг 8 : Установите pdfminer.шесть
pip install pdfminer.six
Шаг 9 : Установите PyPDF2
pip install PyPDF2
Готово! Теперь вы можете запустить для обработки PDF-документов с помощью Python.
4- Решение для извлечения текста из нескольких и больших документов PDFРешение для извлечения текста из PDF-файлов основано на трех основных шагах:
- Объединение нескольких и больших PDF-документов в один PDF-документ.
- Разделение объединенного PDF-документа на набор документов (разбиение по страницам)
- Обработка разделенных документов и извлечение текста.
Полная версия предлагаемого решения выпущена на Github.
Пожалуйста, проверьте это через:
Разветвление и Создание репозитория — лучший способ поддержать проект.
Обработка PDF / A, PDF Tools AG
Документы PDF / A могут быть получены из различных источников. Программное обеспечение, которое их создает, должно следовать правилам PDF / A (включая исправление):
- Шрифты, используемые для текстов, должны быть встроенными.
- Цветовые профили должны быть определены для входных изображений (отсканированных, преобразованных).
- Значимые метаданные должны быть доступны и встроены как XMP.
Создание PDF / A из приложения Windows
PDF-документы могут быть созданы с помощью PDF Producer (другие названия: PDF Creator, PDF Converter и т. Д.) Из любого приложения Windows с использованием функции печати. Документы MS Office обычно конвертируются таким образом. С другой стороны, преобразование писем с вложениями более сложное.
В этом случае больше подходит конвертер документов 3-Heights®. Кроме того, документы PDF можно создавать напрямую с помощью функции «Сохранить в PDF», например, в Microsoft Office 2007 (необходимо загрузить надстройку) или Microsoft Office 2010.
Наши 3-Heights® PDF Desktop Producer и 3-Heights® Document Converter подходят для создания PDF / A.
Динамическое создание и настройка PDF / A
Документы PDF создаются программой непосредственно из приложения (например, из приложения).грамм. веб сервер). Таким образом, в дополнение к статическому контенту, динамический контент также может быть интегрирован из базы данных. В самом ближайшем будущем мы сможем предложить PDF Creator, который сможет создавать PDF / A из таких источников.
Конвертер изображений в PDF / A
Преобразование файлов изображений в файлы PDF / A в большинстве случаев является простой операцией преобразования файлов. Для сложных задач (таких как управление цветом) преобразование можно настроить более сложным образом.
Сканирование / OCR
Сканирование, распознавание шрифтов и преобразование в документы, соответствующие PDF / A, — это особая область, которая требует более высокого уровня знаний (смешанное растровое содержимое, процессы сжатия).
Для преобразования изображений или отсканированных документов в формат PDF / A вы можете использовать наш конвертер изображений 3-Heights® в PDF.
Возможные функции обработки PDF:
Большинство функций обработки PDF не гарантирует соответствия PDF / A целевого документа, даже если все исходные документы соответствуют PDF / A.
Конвертер PDF в PDF / A
Основные цели преобразования в PDF / A:
- Подготовка к архивированию
- Подготовка к применению электронной цифровой подписи
- Подготовка к обмену документами (внутренним / внешним)
Преобразование PDF в PDF / A — нетривиальное дело.Заданы следующие задачи:
- Устранение зависимости от исходного носителя
- Встраивание типов шрифтов
- Создание статического внешнего вида интерактивного контента
- Устранение прозрачности (выравнивание прозрачности)
- Удаление неавторизованного содержимого, например JavaScript
Конвертер PDF в PDF / A 3-Heights® идеально подходит для преобразования PDF в PDF / A.
Добавление цифровой подписи к документу PDF / A равносильно постепенному изменению документа.Однако документ должен соответствовать формату PDF / A, прежде чем его можно будет подписать. Исходное содержание документа остается неизменным, а структура данных цифровой подписи добавляется в конец файла.
Сама цифровая подпись также должна соответствовать PDF / A. Также возможно добавить несколько цифровых подписей (например, подпись автора, подпись тестировщика, подпись выпускающего).
Изменение документа после добавления цифровой подписи
Все изменения, сделанные после того, как документ был подписан цифровой подписью, также должны быть инкрементными и соответствовать PDF / A.Типичные модификации включают редактирование (удаление, изменение и добавление текста, аннотаций и т. Д.), А также обновление содержимого. В настоящее время нет инструментов обработки, соответствующих PDF / A, которые могут работать с документами, уже имеющими цифровую подпись.
Наши следующие продукты могут применять цифровые подписи, соответствующие PDF / A:
Цели валидации PDF / A
Задача валидации — определить, соответствует ли документ PDF / A стандарту ISO.
Области применения
- Входящий и исходящий контроль
- Проверки до и после определенных этапов обработки
- Контроль обработки (принять / отклонить)
- Создание «Отчета о соответствии»
Вызов
Валидаторы должны быть протестированы и сертифицированы независимой организацией на основе общепринятого набора тестов.
Для целей проверки PDF Tools AG предлагает вам 3-Heights® PDF Validator.
Обычные программы просмотра PDF
Большинство программ отображения несовместимы с PDF / A, что означает, что они не принимают во внимание требования стандарта к отображению. Компонент отображения PDF / A должен предлагать следующие функции:
- Предупреждение, если файл содержит элементы, не соответствующие формату PDF / A.
- Использование встроенных шрифтов вместо предварительно установленных шрифтов с тем же именем.
- Использование встроенных цветовых профилей вместо альтернативных цветовых пространств.
- Согласованное отображение изображений интерактивных элементов, содержащихся в файле, вместо их динамического воссоздания.
- Опция отключения гиперссылки.
Отдельные автономные документы PDF / A можно архивировать напрямую. При архивировании большого количества похожих документов PDF / A (например, счетов за коммунальные услуги) часто бывает, что одни и те же стили, логотипы или другие элементы фирменного стиля нужно архивировать снова и снова для каждого отдельного документа.Повторное сохранение общих ресурсов (шрифтов, изображений) нежелательно и снижает приемлемость PDF / A.
Решением в данном случае является усовершенствованная система архивирования, которая разделяет общие ресурсы и сохраняет их только один раз для всех документов. Когда один из документов извлекается, общие ресурсы и сам документ снова объединяются в полный документ PDF / A.
Этот процесс также может применяться к документам с цифровой подписью. Однако в этом случае документ должен быть настроен на принятие разделения общих ресурсов при добавлении начальной подписи.
Пакет инструментов PDF Prep Tool Suite от PDF Tools AG был разработан для этой цели.
Краткое содержание: обзор процессов PDF / A
Шаги, описанные выше, вписываются в общий процесс:
Сервер автоматизации PDF — Рабочий процесс Сервер PDF для управления документами PDF
- Главная »Сервер автоматизации PDF
Сервер автоматизации PDF
Оптимизация документа рабочие процессы и распространение в вашей организации с помощью PDF Automation Server ™
PDF Automation Server — Рабочий процесс PDF-сервер для управления PDF-документами
Главная »PDF Automation ServerPDF Automation Server — это модульный серверный продукт, который предоставляет богатый набор PDF-файлов функции обработки для различных сред.Используйте PAS как важный инструмент для оптимизации обработки PDF-файлов, документооборота и оркестровки веб-сервисов в вашей организации.
Модуль REST APIИспользуйте вызовы REST API для простой интеграции в существующие рабочие процессы
Попробуйте Live REST Calls HTML5 Модуль PDFКонвертируйте документы и обслуживайте PDF-файлы конечных пользователей прямо в браузер
Попробовать образцы Live PDF Модуль WorfklowСоздавайте и проектируйте автоматизированные рабочие процессы с помощью простого в использовании интерфейса перетаскивания.
Подробнее Надежный REST APIPDF Automation Server предоставляет полный набор функций обработки и преобразования PDF-файлов в надежной серверной среде REST, которую можно легко интегрировать в существующие рабочие процессы документооборота и работать со сторонними продуктами интеграции и оркестровки.
REST API Подробности
HTML Модуль разметки PDFСервер автоматизации PDF предоставляет модуль для включения разметки документов PDF в браузере.PAS может конвертировать документы в HTML на лету и может передавать их в модуль HTML / Javascript в браузере, который позволяет конечным пользователям перемещаться, добавлять и редактировать аннотации в PDF. При сохранении пометки отправляются обратно на сервер для обратного объединения в документ PDF.
HTML PDF-разметка Подробные сведения о модуле разметки
Модуль рабочего процессаАвтоматизируйте свой бизнес и документооборот с помощью простого в использовании графического интерфейса. Проектируйте и создавайте сложные блок-схемы автоматизации, которые легко интегрируются в сторонние сервисы.
Подробная информация о модуле рабочего процесса
Модуль пакетных заданийPAS может одновременно получать документы в различных форматах из нескольких источников, включая электронную почту, ftp-серверы и локальные или сетевые папки. Затем процессы могут быть определены независимо для каждого источника документа для выполнения ряда функций с документами, включая преобразование, объединение данных, сборку, шифрование, печать, предварительную проверку и многое другое.
См. Снимки экрана
Подробная информация о модуле пакетных заданий
Интеграция с платформами оркестрации через REST
Все серверы рабочих процессов могут легко интегрироваться с сервером автоматизации PDF через его модуль REST API.Большинство корпоративного программного обеспечения предоставляют модули для обработки рабочих процессов, которые могут выполнять вызовы REST к внешним службам. С помощью PDF Automation Server вы можете добавить функциональность PDF в процессы документооборота. Кроме того, существует ряд программных продуктов, таких как серверы ESB и BPM, единственной функцией которых является выполнение рабочих процессов. Эти серверы могут совершать звонки в сторонние системы через REST API, включая звонки на наш сервер автоматизации PDF.
Образцы интеграции Mule ESB
ПРОВЕРЕННАЯ ТЕХНОЛОГИЯ PDFPAS построен с использованием ведущей в отрасли технологии PDF от Qoppa, разработанной более 10 лет и используемой тысячами клиентов по всему миру.Технология PDF от Qoppa является продуманной, надежной, лидером по производительности и не требует программного обеспечения сторонних производителей. PAS — это многоплатформенный продукт, его можно развернуть в Windows, Linux, Unix (AIX, HP-UX, Solaris и т. Д.), Z / OS, Mac OS X и других.
ПРОФЕССИОНАЛЬНАЯ ТЕХНИЧЕСКАЯ ПОДДЕРЖКАНаша команда поддержки и разработчиков обеспечивает техническую поддержку на уровне экспертов, так что вы быстро получите реальные ответы на свои вопросы. Мы считаем, что клиенты на первом месте, и стремимся отвечать нашим клиентам в течение 24 часов.
Сопутствующие товары / услуги
Этапы обработки PDF-файлов — следующая эволюция в обработке технических знаков — блог Global Graphics
Передовой опыт работы с заданиями, содержащими как реальный графический контент, так и «технические знаки», развился за последние пару десятилетий. Технические отметки включают в себя такие вещи, как линии разреза / высечки, линии сгиба, размеры, легенды и т. Д. В языковом файле описания страницы (в наши дни обычно в формате PDF). В большинстве случаев, особенно для пакетов, складных картонных коробок и гофрированных материалов, они исходят из файла САПР и объединяются с графикой.
Люди захотят по-разному взаимодействовать с техническими знаками на разных этапах рабочего процесса:
- Ваши специалисты по САПР захотят увидеть технические отметки и убедиться, что они не были изменены по сравнению с исходными данными САПР.
- Утверждение владельца бренда может не захотеть видеть технические отметки, но утверждающие руководители допечатной подготовки и производства определенно захотят видеть на своих мониторах как технические отметки, так и графику вместе с возможностью делать слои видимыми или невидимыми по своему желанию.
- В некоторых рабочих процессах технические отметки из PDF могут использоваться для изготовления физического штампа или для управления лазерным резаком; в других вместо этого будет использоваться оригинальный файл САПР.
- На цифровой печатной машине вы можете напечатать небольшой тираж только технических знаков или комбинацию технических знаков и графики, чтобы гарантировать, что отделка должным образом совпадает с отпечатками.
- Основной тираж, будь то на обычной печатной машине (флексографской, офсетной и т. Д.) Или цифровой, очевидно, будет включать графику, но не будет включать большинство технических знаков.Вы можете включить в распечатку легенду для надежной идентификации этого задания, но вам, очевидно, потребуется отключить печать любых меток, которые перекрываются с активной областью или выходят за обрез, например, метки обрезки и сгиба.
- Иногда вы можете захотеть сделать еще один небольшой тираж с техническими отметками после основного тиража, чтобы гарантировать, что чистовая обработка не выйдет из строя.
Таким образом, во всем процессе есть много мест, где может потребоваться включить или выключить как технические знаки, так и графику.Как вы это делаете в своем RIP?
Исторически первым методом, который использовался для включения технических знаков, первоначально в PostScript, а теперь и в PDF, было указание каждого вида технических знаков в «техническом разделении», закодированном как плашечный цвет в задании. Большинство операторов пытались использовать имя для этого плашечного цвета, которое указывало бы на его намерение, но не было никаких стандартов, поэтому вы могли закончить с ‘Cut’ (или ‘CUT’, ‘cut’ и т. Д.), ‘Cut-line’ , ‘cut line’, ‘cutline’, ‘die’ и т. д. И это просто размышления о названии на английском.Выбранные имена обычно имеют большое значение для человека-оператора, но не могут надежно использоваться для автоматизированной обработки из-за большого количества вариаций.
В результате многие задания, поступающие в преобразователь, по крайней мере из-за пределов этой компании, должны быть проверены, а имена мест заменены, или допечатная подготовка и RIP настроены на использование имен из этого задания. Эта ручная обработка требует времени и может привести к ошибкам.
Но давайте предположим, что вы прошли этот этап; как вы настраиваете свой RIP для достижения того, что вам нужно, с этим техническим разделением?
Самый очевидный механизм отключения некоторых технических отметок — это указать RIP-обработчику визуализировать соответствующие плашечные цвета как их собственные цветоделения, но не отображать их на отпечатке.Это очень простая модель, которая хорошо работает, если работа была построена правильно, со всеми техническими отметками, установленными для наложения. Когда кто-то забывает и оставляет линию разреза или сгиба как нокаут (чего, конечно, никогда не бывает!), Вы получите белую линию через настоящую графику, если техническая отметка будет поверх них.
Следующим этапом эволюции этого будет настройка RIP, чтобы он говорил, что назначенное разделение пятен никогда не должно нарушать любое другое разделение. Это вариант конфигурации в RIP-процессоре Harlequin, но, возможно, он не будет широко доступен где-либо еще.
Или вы можете указать RIP полностью игнорировать один или несколько назначенных плашечных цветов, чтобы они вообще не влияли на любые другие отметки на странице. Опять же, это вариант конфигурации в Harlequin RIP, и это один из лучших способов управления техническими пометками, которые сохраняются в файле PDF в качестве технического разделения.
В качестве альтернативы, поскольку технические отметки (как и многие другие части этикетки или задания на упаковку) обычно фиксируются в слое PDF (или в дополнительной группе содержимого, если использовать технический термин), вы можете включать и выключать эти слои.Опять же, в Harlequin RIP есть богатые элементы управления для управления слоями PDF.
Но ни один из этих методов не избавляет от необходимости вручную проверять каждый файл и настраивать допечатную подготовку и RIP для названий мест или слоев, которые использовались для технических отметок.
И здесь на помощь приходит новый стандарт ISO, 19593-1: 2018. Он определяет «этапы обработки PDF», механизм, позволяющий однозначно идентифицировать технические отметки в файлах PDF, а также их предполагаемую функцию, от резки до фальцовки и фальцовки, до области за обрез, белый цвет и лак, шрифт Брайля, размеры, надписи и т. д.Он делает это, опираясь на обычную практику сохранения технических знаков в слоях PDF, но добавляет некоторые идентификационные метаданные, которые не зависят от поставщика, языка или обычной практики составителя, допечатной подготовки или печатного цеха.
Итак, теперь вы можете посмотреть файл PDF и окончательно увидеть, что слой под названием «вырезать» содержит линии разреза. Название «вырезать» теперь просто для удобства; реальная информация находится в метаданных, которые полностью и надежно машиночитаемы. Другими словами, не имеет значения, был ли этот слой назван «Schnittlinie» или как-нибудь еще; ручной шаг по идентификации имен, которые кто-то где-то поместил в файл вверх по течению, и выяснения, что каждое из них означает, полностью исключен.
Мы реализовали поддержку шагов обработки PDF в версии 12.1r0 Harlequin RIP и работали с рядом поставщиков, чьи продукты создают файлы с шагами обработки в них (включая гибридное программное обеспечение, Esko и Callas), чтобы все работало без проблем. Мы также проработали широкий спектр текущих и возможных вариантов использования, чтобы убедиться, что наша реализация может удовлетворить реальные потребности. В качестве примера мы добавили возможность управлять всей графикой на странице PDF, которая не находится в слоях этапа обработки, как если бы они были просто еще одним слоем.
На практике это означает, что Harlequin можно настроить для доставки практически всего, что вам нужно, например:
Самая важная вещь, которую дают нам шаги обработки PDF, — это то, что вы можете создать конфигурацию для одного из этих вариантов использования (или для многих других вариантов) и знать, что она будет работать для всех заданий, которые отправляются вам с помощью шагов обработки PDF; Вам не нужно будет изменять конфигурацию для следующего задания только потому, что оператор использовал другие названия точек.
Конечно, всем потребуется время, чтобы перейти от использования имен точек к этапам обработки PDF.Но я думаю, вы согласитесь, что преимущества этого в плане повышения эффективности и снижения вероятности ошибок очевидны и значительны.
Для получения дополнительной информации прочтите пресс-релиз здесь.
Как выполнять пакетную обработку файлов PDF
Повторяющиеся задачи, включающие один или несколько документов, можно автоматизировать с помощью инструмента пакетной обработки.
Преобразуйте несколько файлов в другой формат документа, распечатайте их в пакетном режиме или запустите OCR для многих файлов PDF на основе изображений, чтобы сделать их текст полностью доступным для поиска.Вы также можете создавать настраиваемые пакетные последовательности, чтобы упростить задачи, которые вы выполняете наиболее часто.
Запустить пакетный процесс
Пакетный процесс — это отдельная задача, которую можно автоматизировать для нескольких файлов, например Распечатать.
- В меню Файл щелкните Пакетная обработка
- Щелкните правой кнопкой мыши действие в списке Действия , а затем щелкните Выполнить…
- В области Параметры с помощью кнопок выберите папку, содержащую необходимые файлы, и выберите папку, в которой будут сохранены новые файлы.
- Нажмите Выполнить для выполнения пакетного процесса
Выполнить пакетную последовательность
Пакетная последовательность состоит из последовательности пакетных процессов; е.грамм. создайте файл PDF, примените защиту паролем и затем распечатайте.
- В меню Файл щелкните Пакетная обработка
- Щелкните правой кнопкой мыши последовательность в списке Последовательности действий , а затем щелкните Выполнить…
- В области Параметры используйте кнопки для выберите папку, содержащую необходимые файлы, и выберите папку, в которой будут сохранены новые файлы
- Отметьте Запрос перезаписи , чтобы получать предупреждение, когда файл необходимо перезаписать
- Нажмите Запустить , чтобы выполнить пакетную последовательность
Создать Новая пакетная последовательность
- В меню Файл щелкните Пакетная обработка
- В списке Действия щелкните правой кнопкой мыши действие, которое необходимо выполнить, а затем щелкните Добавить в последовательность , а затем Создать…
- В списке Действия Последовательности дважды щелкните Новая последовательность , чтобы назвать последовательность
- Нажмите Введите 906 24, чтобы зафиксировать новое имя
- Еще раз в списке Действия щелкните правой кнопкой мыши другое действие, а затем выберите Добавить в последовательность , за которым следует имя вашей настраиваемой последовательности.Повторите эту задачу для всех необходимых действий.
- Щелкните левой кнопкой мыши действие в своей последовательности, а затем щелкните Свойства , чтобы настроить параметры по умолчанию для действия
- Щелкните левой кнопкой мыши последовательность действий, чтобы выбрать ее, а затем щелкните Выполнить . Или нажмите Закрыть , чтобы выйти из инструмента.
Редактировать пакетную последовательность
1. В меню Файл щелкните Пакетная обработка.
2. Щелкните левой кнопкой мыши последовательность действий, чтобы выбрать ее, а затем щелкните одно из следующего:
- Клонировать : продублируйте пакетную последовательность, чтобы использовать ее в качестве шаблона для другой последовательности
- Удалить : навсегда удалить пакетную последовательность
- Переименовать : установить новое имя для пакетной последовательности
3.Щелкните Перемещение вниз или Перемещение вверх , чтобы изменить порядок действий.
Дополнительные параметры обработки PDF с полным API
Полный API в основном используется для ситуаций обработки PDF, которые не поддерживаются стандартным API. Рекомендуется использовать стандартный API для решения вашей ситуации, когда это возможно. Стандартный API прост в использовании, загружается по умолчанию и лучше всего работает в большинстве ситуаций.Основы
Открытие документа
Чтобы открыть документ PDF.
Сохранение документа
Чтобы сохранить документ PDF.
Блокировка документа
Для доступа к документу PDF в многопоточной среде.
Доступ к странице PDF
Доступ к странице PDF.
Доступ к содержимому страницы PDF
Доступ к содержимому страницы PDF.
Аннотации
Импорт аннотаций
Чтобы импортировать XFDF в FDF, затем объедините данные из FDF в PDF.
Экспорт аннотаций
Чтобы извлечь данные из PDF в FDF, затем экспортируйте FDF как XFDF.
Свойства стиля
Для установки свойства стиля аннотации, такого как цвет, внутренний цвет, стиль границы, отступы и т. Д., Для аннотации.
Добавить заметку
Чтобы добавить заметку (текстовую аннотацию) в документ PDF.
Добавить аннотацию ссылки
Чтобы добавить аннотацию гиперссылки или ссылки внутри документа на страницу документа PDF.
Удалить аннотацию
Для удаления аннотации из документа.
Формы
Импорт форм
Чтобы импортировать XFDF в FDF, затем объедините данные из FDF в PDF.
Экспорт форм
Чтобы извлечь данные из PDF в FDF, затем экспортируйте FDF как XFDF.
Изменить в полях формы
Чтобы изменить значения для существующих полей формы.
Создать
Создать эскиз
Для создания эскиза изображения страницы PDF.
Манипуляции со страницами
Создание страницы PDF
Для создания новой пустой страницы PDF в документе PDF.