Перевод денег по фотографии: новый сервис банка «Открытие»
Смартфон, фото, деньги. Как сделать денежный перевод, просто сфотографировав получателя
Фото: Банк Открытие«Открытие» стал первым в мире банком, запустившим сервис денежных переводов с карты на карту по фотографии получателя.
Теперь для перевода денег с одной банковской карты на другую достаточно сделать фото на смартфон или взять из фотогалереи изображение человека, которому вы хотите отправить деньги. Звучит фантастично? Тем не менее для перевода денег по фото нужно всего лишь установить на смартфон мобильное приложение «Открытие. Переводы». Дальше в дело вступает магия, или на самом деле биометрия. Технологию биометрической идентификации лиц от VisionLabs адаптировали для p2p-переводов при поддержке Open Garage, IT и digital-подразделения банка.
Биометрия — не просто модный тренд. Она стала одной из самых востребованных и быстро развивающихся технологий последних лет, а свои решения в 2016–2017 годах представили практически все лидеры IT-рынка: Apple, Samsung, Intel, Nvidia и другие. Локомотивом внедрения биометрических решений в нашу жизнь стали производители смартфонов, которые оснастили сканерами не только премиальные девайсы, но и массовые бюджетные аппараты. Так, например, именно благодаря им в результате распространения сканеров отпечатка пальцев в смартфонах, а также их прозрачной интеграции в операционные системы биометрия стала популярным средством защиты денег в мобильных банковских приложениях и в приложениях платежных систем.
Локомотивом внедрения биометрических решений в нашу жизнь стали производители смартфонов, которые оснастили сканерами не только премиальные девайсы, но и массовые бюджетные аппараты. Так, например, именно благодаря им в результате распространения сканеров отпечатка пальцев в смартфонах, а также их прозрачной интеграции в операционные системы биометрия стала популярным средством защиты денег в мобильных банковских приложениях и в приложениях платежных систем.
Аутентификация пользователей с помощью сканера отпечатков стала первой биометрической технологией, получившей массовое распространение. Теперь вместо того, чтобы вводить пин-код, который коварно забывается в самый нужный момент, вы прикладываете палец к сканеру мобильного телефона и затем оплачиваете покупку или входите в личный кабинет онлайн-банка.
В 2017 году к биометрии, основанной на сканировании отпечатков пальцев, прибавилась и технология распознавания визуальных образов.
Использование нейросетей и deep machine learning, всего того, что сейчас называют искусственным интеллектом, привело к настоящему прорыву в области компьютерного зрения. Появились и первые биометрические внедрения этой технологии в повседневную жизнь. Хайп вокруг iPhone X был спровоцирован в первую очередь технологией Face ID, используемой в этом смартфоне. Она позволяет идентифицировать пользователя по его визуальному образу с вероятностью ошибки одна к миллиону.
Появились и первые биометрические внедрения этой технологии в повседневную жизнь. Хайп вокруг iPhone X был спровоцирован в первую очередь технологией Face ID, используемой в этом смартфоне. Она позволяет идентифицировать пользователя по его визуальному образу с вероятностью ошибки одна к миллиону.
Так как современный смартфон превратился в настоящий многофункциональный гаджет, в том числе и в платежный инструмент, неудивительно, что биометрическое распознавание лиц пришло и в банковский сектор. Сочетание простоты использования и надежности превращает биометрию в идеальное средство идентификации человека.
Как это работает
В меню мобильного приложения «Открытие. Переводы» вы выбираете «перевод по фото», делаете снимок получателя на камеру смартфона или просто берете его фотографию из галереи смартфона. Дальше начинается самое интересное. Фотография автоматически передается в банк, где происходит машинная идентификация получателя платежа с использованием биометрической системы распознавания лиц и базы клиентов банка (пока с помощью перевода по фотографии можно отправлять платежи только держателям карт банка «Открытие»). После этого вам остается только ввести сумму перевода и перевести деньги. Отправлять деньги можно с карты любого банка. В том случае, если карты, с которой отправляются денежные средства, нет в приложении, можно просто ввести ее реквизиты.
После этого вам остается только ввести сумму перевода и перевести деньги. Отправлять деньги можно с карты любого банка. В том случае, если карты, с которой отправляются денежные средства, нет в приложении, можно просто ввести ее реквизиты.
Фото: Банк Открытие
Преимущество способа заключается в том, что больше не нужно помнить 16 цифр номера банковской карты человека, которому отправляются деньги. Номер карты в самый ответственный момент можно забыть или просто не знать. Так, можно перевести деньги незнакомцу, чей номер телефона или карты вы просто не знаете, или быстро сфотографировать коллегу за обедом, чтобы не искать его контакт в телефонной книжке. Есть сотни самых неожиданных сценариев использования приложения, когда проще и удобнее отправить деньги по фотографии человека.
Да, получателем перевода по фотографии пока что может быть только клиент «Открытия». Однако в 2018 году такие переводы планируется сделать доступными и для клиентов других банков.
Да, за сохранность денег можно не волноваться, так как переводы проводятся по международному стандарту безопасности PCI DSS и подтверждаются 3D-secure кодом. История переводов сохраняется в приложении, так что всегда есть возможность проверить, куда и с какой карты были отправлены деньги, а также сохранить чек о выполненной операции.
История переводов сохраняется в приложении, так что всегда есть возможность проверить, куда и с какой карты были отправлены деньги, а также сохранить чек о выполненной операции.
Помимо перевода денег по фотографии получателя с помощью приложения «Открытие. Переводы», можно отправлять деньги «классическим» способом, по номеру телефона или по номеру карты — в последнем случае получатель может пользоваться картой любого российского банка.
Приложение доступно на платформах iOS и Android. Подробнее можно посмотреть здесь.
Добавить BFM.ru в ваши источники новостей?
перевод, произношение, транскрипция, примеры использования
Вы не возражаете, чтобы сфотографировать нас вместе?
Её фотография была хорошо заметна на его письменном столе.
На данной фотографии вы видите наиболее активных представителей этой группы.
He looks very young in this photo. Mind you, it was taken years ago.
На этой фотографии он такой молодой! Впрочем, она была снята много лет назад.
The photo shows the American and Soviet leaders standing side by side on the lawn of the White House.
На фото изображены руководители США и СССР, стоящие рядом на лужайке перед Белым домом.
His photo stirred up bitter memories.
Его фото всколыхнуло горькие воспоминания.
His photo’s on the cover of Newsweek again.
Его фотография опять на обложке (журнала) «Ньюсуик».
You aren’t allowed to take photos inside the theater.
Вам не разрешается фотографировать внутри театра.
This photo was taken in Paris, if I remember rightly.
Эта фотография была сделана в Париже, если я правильно помню.
That photo makes me look ancient!
На этой фотографии мне лет сто, не меньше!
He looks much fatter than in his photo.
Он выглядит гораздо толще, чем на фотографии.
Stand on this side of me so Dad can get a photo.
Стань от меня с этой стороны, чтобы папа мог сделать фотографию.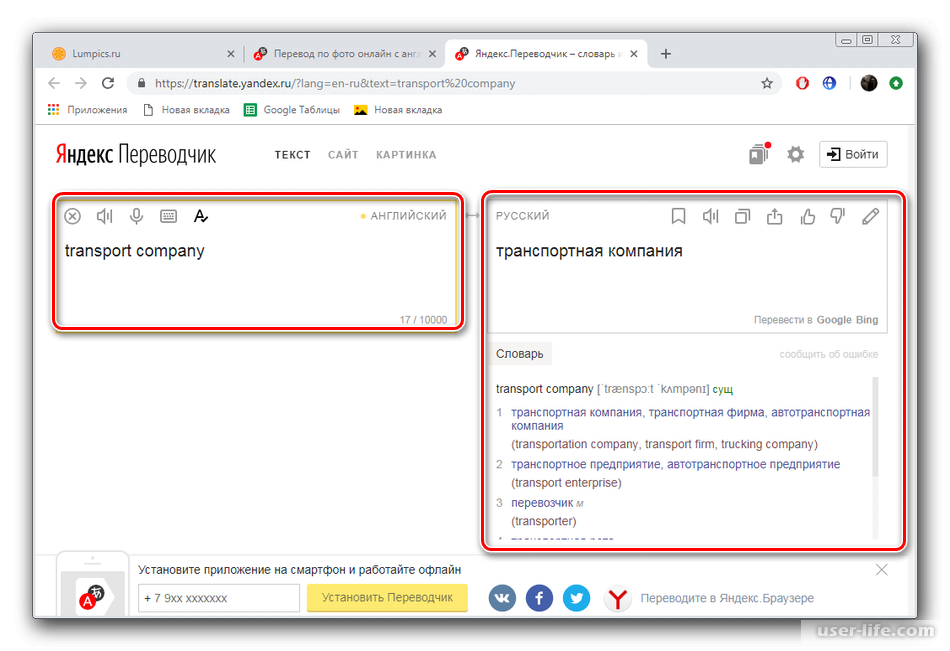
The photo makes her look much older than she really is.
На этой фотографии она выглядит намного старше, чем есть на самом деле.
The photo had been retouched to remove the wrinkles around his eyes.
Фотографию отретушировали, чтобы убрать ему морщины вокруг глаз.
The photo doesn’t do her justice.
Эта фотография не передаёт всей её красоты.
Stick the photo onto the corkboard.
Прикрепите эту фотографию к доске объявлений.
She enclosed a photo with the card.
Она приложила к открытке фотографию.
Sue ripped his photo up into tiny bits.
Сью разорвала его фото на маленькие кусочки.
The photo shows a smiling, youthful Burgos.
На фотографии изображён молодой, улыбающийся Бургос.
She used glue to stick the photo in the album.
Она прикрепила фотографию в альбом с помощью клея.
The photo shows four men grouped round a jeep.
На фото показаны четверо мужчин, собравшихся вокруг джипа.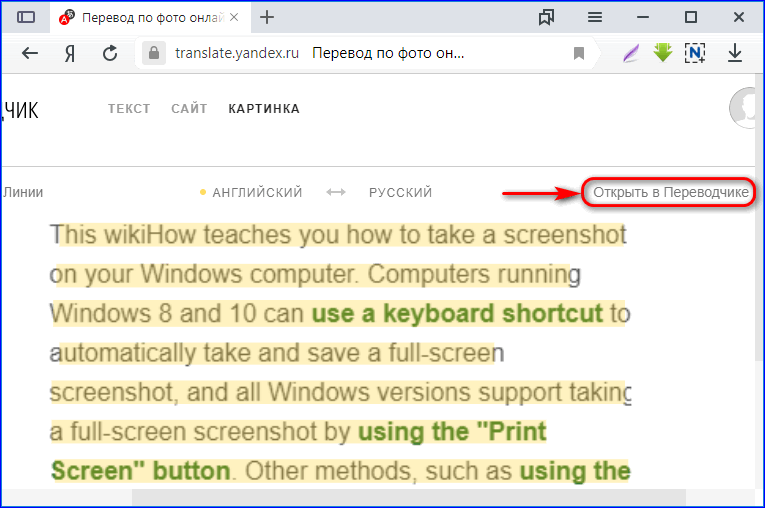
Perhaps this photo will help to jog your memory.
Возможно, это фото поможет освежить вашу память.
She fished around in her purse and pulled out a photo.
Она пошарила в сумочке и вытащила оттуда фотографию.
The cutline wrongly identified the people in the photo.
Люди, изображённые на фотографии, были подписаны неправильно.
We gave them a framed family photo for their anniversary.
На годовщину мы подарили им семейную фотографию в рамке.
Could the bride’s family all gather together for a photo?
Не могла бы вся семья невесты собраться вместе для фотографии?
She photoed the historic mansion for a decorating magazine.
Она сфотографировала этот старинный особняк для журнала, посвящённого ремонту.
Air Перевод — Фото Переводчик — Приложение
Используй камеру чтобы сканировать и переводить текста или документы. Определение объектов и локаций в один тап. Сделай фото и переводи что угодно! Сканирование текстов и документов еще никогда не было так просто. Просто сделай фото и наша искусственная система определит текст автоматически. Камера может сканировать большие документы на разных языках и переводить их на другие языки. Air Translate находка для бизнеса, путешествий и обучения. Переводи дорожные знаки, картинки, заголовки, документы, книги, инструкции, заметки, рекламу и многое многое другое. Распознавай объекты, локации, места, животных, растения, еду и другое. Слушай, читай, изменяй, переводи и делись этим за секунды! Изучай новые языки с помощью камеры! Проигрывай и слушай переводы, связывай их с фотографиями и запоминай новые слова. Все твои переводы сохраняются в историю так что ты можешь просматривать и практиковать их когда угодно! Твой прогресс не заставит ждать! Поддерживает языки:
Африкаанс, албанский, арабский, бангла, белорусский, болгарский, каталанский, китайский, хорватский, чешский, датский, голландский, английский, эсперанто, эстонский, филиппинский, финский, французский, галисийский, грузинский, немецкий, греческий, гуджарати, гаитянский креольский, иврит , Хинди, венгерский, исландский, индонезийский, ирландский, итальянский, японский, каннада, корейский, латышский, литовский, македонский, малайский, мальтийский, маратхи, норвежский, персидский, польский, португальский, румынский, русский, сербский, словацкий, словенский, испанский , Суахили, шведский, тагальский, тамильский, телугу, тайский, турецкий, украинский, урду, вьетнамский, валлийский, зулусский SUBSCRIPTION DETAILS
Choose from different subscription options.
Просто сделай фото и наша искусственная система определит текст автоматически. Камера может сканировать большие документы на разных языках и переводить их на другие языки. Air Translate находка для бизнеса, путешествий и обучения. Переводи дорожные знаки, картинки, заголовки, документы, книги, инструкции, заметки, рекламу и многое многое другое. Распознавай объекты, локации, места, животных, растения, еду и другое. Слушай, читай, изменяй, переводи и делись этим за секунды! Изучай новые языки с помощью камеры! Проигрывай и слушай переводы, связывай их с фотографиями и запоминай новые слова. Все твои переводы сохраняются в историю так что ты можешь просматривать и практиковать их когда угодно! Твой прогресс не заставит ждать! Поддерживает языки:
Африкаанс, албанский, арабский, бангла, белорусский, болгарский, каталанский, китайский, хорватский, чешский, датский, голландский, английский, эсперанто, эстонский, филиппинский, финский, французский, галисийский, грузинский, немецкий, греческий, гуджарати, гаитянский креольский, иврит , Хинди, венгерский, исландский, индонезийский, ирландский, итальянский, японский, каннада, корейский, латышский, литовский, македонский, малайский, мальтийский, маратхи, норвежский, персидский, польский, португальский, румынский, русский, сербский, словацкий, словенский, испанский , Суахили, шведский, тагальский, тамильский, телугу, тайский, турецкий, украинский, урду, вьетнамский, валлийский, зулусский SUBSCRIPTION DETAILS
Choose from different subscription options.

Перевод и переводчик с чешского на русский по фото, фотографии и картинке
Иногда нам присылают на перевод фотографии и фото с какими-то фразами, надписями или целыми текстами на чешском языке. Ведь у нас как раз профессиональные чеш переводчики для этих целей и работают. Они постоянно и каждодневно переводят разные тексты, стандартные документы и сложнейшую документацию с/на официальный язык Чехии. Так что и с вашим заданием справятся. Конечно, если вы позвоните нам или напишите. В самом низу этой статьи говорится, как это можно сделать.
Как перевести с чешского на русский по фото и фотографии?
Вряд ли у вас получится сделать это в каком-то онлайн сервисе (на сайте, в программе, приложении или тому подобном). Они обычный текст перевести толком не могут. А если вначале нужно еще его распознать с какого-то изображения или картинки, так и вовсе ситуация становится практически неразрешимой.
Перевод с фото или фотографии достойно и качественно вам сделает лишь живой и реальный чешский переводчик. Наши специалисты перевода чеш документов и документации такими заказами также занимаются. Они быстро распознают, что написано в присланном вами файле, а затем всё точно и грамотно переведут. Не зря ведь они изучали официальный язык Чехии в университете, а затем еще много лет занимались переводческой деятельности. Сейчас они максимально подготовлены к предоставлению таких вот услуг. Так что звоните нам или пишите, чтобы их получить.
Переводчик с чешского по фотографии или фото
Так вот у нас именно что живые и опытные чешские переводчики в Бюро работают. Профессиональные и грамотные специалисты перевода чеш текстов и документов. Так что они запросто переведут любые фразы и надписи с присланных вами картинок, фото, изображений и фотографий. Присылайте их нам или хотя бы позвоните проконсультироваться.
Так что они запросто переведут любые фразы и надписи с присланных вами картинок, фото, изображений и фотографий. Присылайте их нам или хотя бы позвоните проконсультироваться.
Как заказать перевод с чешского по фото, фотографии или картинке?
С любыми вопросами и уточнениями звоните по номеру ниже. Или сразу присылайте ваши фото и картинки через онлайн-заказ на этой странице или письмом на нашу электронную почту, чей адрес можно и здесь найти и в разделе Контакты нашего сайта.
А цену перевода с чешского на русский по вашим фотографиям или изображениям узнавайте по этому номеру Бюро чеш профессиональных переводчиков Гектор:
+7-922-181-08-30
Как разработать Pix2Pix GAN для преобразования изображения в изображение
Последнее обновление 18 января 2021 г.
Генеративная состязательная сеть Pix2Pix, или GAN, представляет собой подход к обучению глубокой сверточной нейронной сети для задач преобразования изображения в изображение.
Тщательная конфигурация архитектуры как типа GAN с условным изображением позволяет как создавать большие изображения по сравнению с предыдущими моделями GAN (например, 256 × 256 пикселей), так и способность хорошо работать с множеством различных изображений для -задачи по переводу изображений.
В этом руководстве вы узнаете, как разработать генерирующую состязательную сеть Pix2Pix для преобразования изображения в изображение.
После прохождения этого руководства вы будете знать:
- Как загрузить и подготовить спутниковое изображение в набор данных преобразования изображения в изображение карт Google.
- Как разработать модель Pix2Pix для перевода спутниковых снимков в изображения карты Google.
- Как использовать окончательную модель генератора Pix2Pix для перевода специальных спутниковых изображений.
Начните свой проект с моей новой книги «Генеративные состязательные сети с Python», включая пошаговые руководства и файлы исходного кода Python для всех примеров.
Приступим.
- Обновлено январь / 2021 : Обновлено, поэтому замораживание слоев работает с нормой партии.
Как разработать генерирующую состязательную сеть Pix2Pix для преобразования изображения в изображение
Фотография сделана Европейской южной обсерваторией, некоторые права защищены.
Обзор учебного пособия
Это руководство разделено на пять частей; их:
- Что такое Pix2Pix GAN?
- Набор данных преобразования изображений со спутника на карту
- Как разработать и обучить модель Pix2Pix
- Как переводить изображения с помощью модели Pix2Pix
- Как перевести карты Google на спутниковые изображения
Что такое Pix2Pix GAN?
Pix2Pix — это модель генерирующей состязательной сети или GAN, разработанная для универсального преобразования изображения в изображение.
Подход был представлен Филипом Изола и др. в своей статье 2016 года под названием «Преобразование изображения в изображение с использованием сетей с условным соперничеством», представленной на CVPR в 2017 году.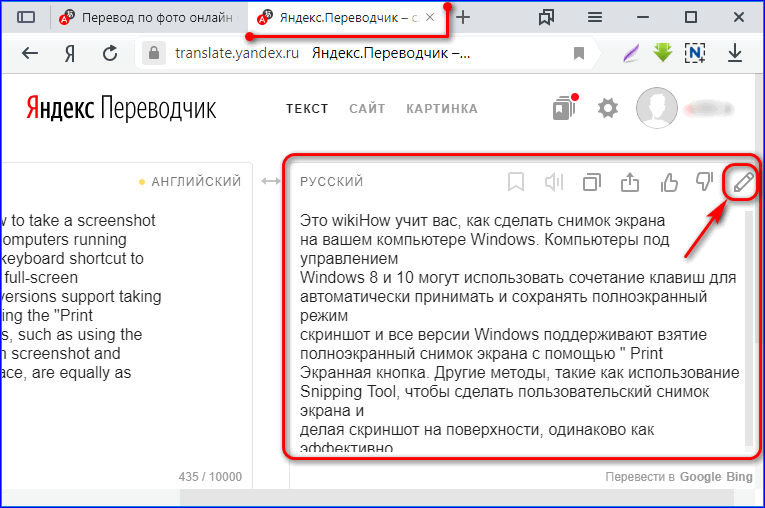
Архитектура GAN состоит из модели генератора для вывода новых вероятных синтетических изображений и модели дискриминатора, которая классифицирует изображения как реальные (из набора данных) или поддельные (сгенерированные). Модель дискриминатора обновляется напрямую, тогда как модель генератора обновляется через модель дискриминатора.Таким образом, две модели обучаются одновременно в состязательном процессе, в котором генератор пытается лучше обмануть дискриминатор, а дискриминатор пытается лучше идентифицировать поддельные изображения.
Модель Pix2Pix — это тип условного GAN, или cGAN, где создание выходного изображения зависит от входного, в данном случае исходного изображения. Дискриминатору предоставляется как исходное изображение, так и целевое изображение, и он должен определять, является ли цель правдоподобным преобразованием исходного изображения.
Генератор обучается через состязательную потерю, которая побуждает генератор генерировать правдоподобные изображения в целевой области.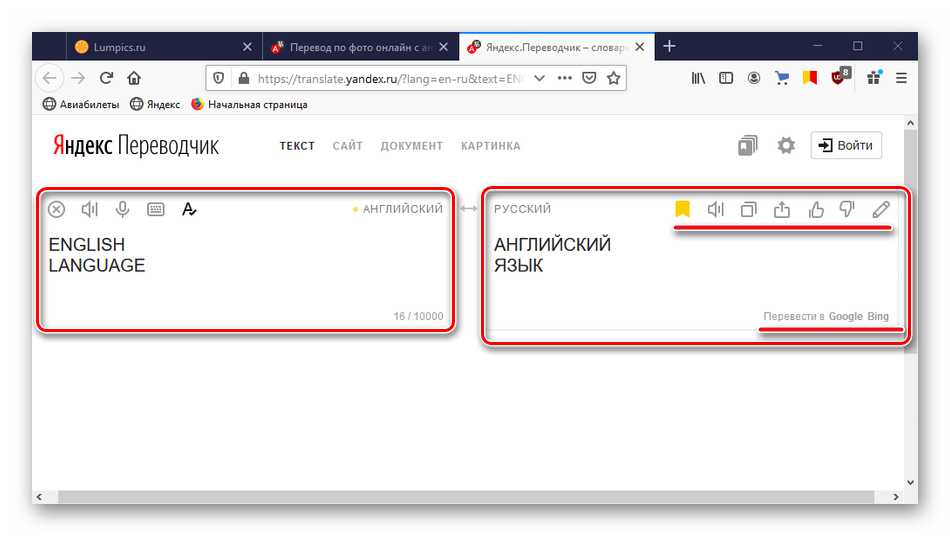 Генератор также обновляется с помощью потерь L1, измеряемых между сгенерированным изображением и ожидаемым выходным изображением. Эта дополнительная потеря побуждает модель генератора создавать правдоподобные переводы исходного изображения.
Генератор также обновляется с помощью потерь L1, измеряемых между сгенерированным изображением и ожидаемым выходным изображением. Эта дополнительная потеря побуждает модель генератора создавать правдоподобные переводы исходного изображения.
Pix2Pix GAN был продемонстрирован на ряде задач преобразования изображения в изображение, таких как преобразование карт в спутниковые фотографии, черно-белые фотографии в цветные и эскизы продуктов в фотографии продуктов.
Теперь, когда мы знакомы с Pix2Pix GAN, давайте подготовим набор данных, который мы можем использовать для преобразования изображения в изображение.
Хотите разрабатывать сети GAN с нуля?
Пройдите мой бесплатный 7-дневный ускоренный курс по электронной почте (с образцом кода).
Нажмите, чтобы зарегистрироваться, а также получите бесплатную электронную версию курса в формате PDF.
Загрузите БЕСПЛАТНЫЙ мини-курс
Набор данных преобразования изображений со спутника на карту
В этом уроке мы будем использовать так называемый набор данных « maps », который использовался в статье Pix2Pix.
Это набор данных, состоящий из спутниковых снимков Нью-Йорка и соответствующих страниц с картами Google. Проблема перевода изображений связана с преобразованием спутниковых фотографий в формат карт Google или, наоборот, изображений карт Google в спутниковые фотографии.
Набор данных представлен на веб-сайте pix2pix и может быть загружен в виде 255-мегабайтного zip-файла.
Загрузите набор данных и распакуйте его в текущий рабочий каталог. Будет создан каталог под названием « карты » со следующей структурой:
карты ├── поезд └── val
карты ├── поезд └── val |
Папка поезда содержит 1097 изображений, тогда как набор данных проверки содержит 1099 изображений.
Изображения имеют цифровое имя файла и находятся в формате JPEG. Каждое изображение имеет ширину 1200 пикселей и высоту 600 пикселей и содержит как спутниковое изображение слева, так и изображение Google Maps справа.
Пример изображения из набора данных Maps, включая изображение со спутника и Google Maps.
Мы можем подготовить этот набор данных для обучения модели Pix2Pix GAN в Keras. Мы просто будем работать с изображениями в наборе обучающих данных. Каждое изображение будет загружено, масштабировано и разделено на элементы спутниковой карты и карты Google.Результатом будет 1097 пар цветных изображений с шириной и высотой 256 × 256 пикселей.
Это реализует функция load_images () ниже. Он перечисляет список изображений в заданном каталоге, загружает каждое с целевым размером 256 × 512 пикселей, разбивает каждое изображение на элементы спутника и карты и возвращает массив каждого из них.
# загружаем все изображения из каталога в память
def load_images (путь, размер = (256,512)):
src_list, tar_list = список (), список ()
# перечисляем имена файлов в каталоге, предполагаем, что все изображения
для имени файла в listdir (путь):
# загрузить и изменить размер изображения
пикселей = load_img (путь + имя файла, target_size = размер)
# преобразовать в массив numpy
пикселей = img_to_array (пиксели)
# разделить на спутник и карту
sat_img, map_img = пикселей [:,: 256], пикселей [:, 256:]
src_list. добавить (sat_img)
tar_list.append (map_img)
возврат [asarray (src_list), asarray (tar_list)]
добавить (sat_img)
tar_list.append (map_img)
возврат [asarray (src_list), asarray (tar_list)]
# загрузить все изображения из каталога в память def load_images (path, size = (256,512)): src_list, tar_list = list (), list () # перечислить имена файлов в каталоге, предположим, что все являются изображениями для имени файла в listdir (путь): # загрузить и изменить размер изображения пикселей = load_img (путь + имя_файла, target_size = size) # преобразовать в массив numpy пикселей = img_to_array (пикселей) # разбить на спутник и карту sat_img, map_img = пикселей [:,: 256], пикселей [:, 256:] src_list.append (sat_img) tar_list.append (map_img) return [asarray (src_list), asarray (tar_list)] |
Мы можем вызвать эту функцию, указав путь к набору обучающих данных. После загрузки мы можем сохранить подготовленные массивы в новый файл в сжатом формате для дальнейшего использования.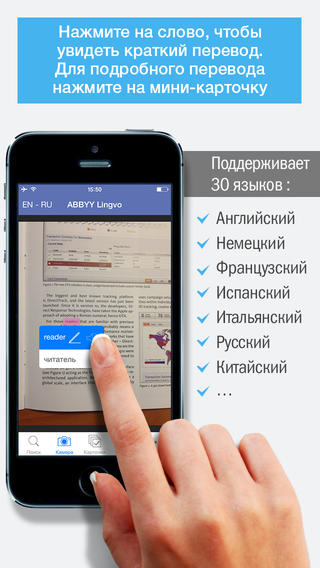
Полный пример приведен ниже.
# загружать, разделять и масштабировать набор данных карт, готовый к обучению
из os import listdir
из numpy import asarray
из numpy import vstack
из кераса.preprocessing.image import img_to_array
из keras.preprocessing.image import load_img
из numpy import savez_compressed # загружаем все изображения из каталога в память
def load_images (путь, размер = (256,512)):
src_list, tar_list = список (), список ()
# перечисляем имена файлов в каталоге, предполагаем, что все изображения
для имени файла в listdir (путь):
# загрузить и изменить размер изображения
пикселей = load_img (путь + имя файла, target_size = размер)
# преобразовать в массив numpy
пикселей = img_to_array (пиксели)
# разделить на спутник и карту
sat_img, map_img = пикселей [:,: 256], пикселей [:, 256:]
src_list.добавить (sat_img)
tar_list.append (map_img)
возврат [asarray (src_list), asarray (tar_list)] # путь к набору данных
путь = ‘карты / поезд /’
# загрузить набор данных
[src_images, tar_images] = load_images (путь)
print (‘Загружено:’, src_images. shape, tar_images.shape)
# сохранить как сжатый массив numpy
filename = ‘maps_256.npz’
savez_compressed (имя файла, src_images, tar_images)
print (‘Сохраненный набор данных:’, имя файла)
shape, tar_images.shape)
# сохранить как сжатый массив numpy
filename = ‘maps_256.npz’
savez_compressed (имя файла, src_images, tar_images)
print (‘Сохраненный набор данных:’, имя файла)
1 2 3 4 5 6 7 8 9 10 11 12 13 140002 14 18 19 20 21 22 23 24 25 26 27 28 29 31 | # загрузить, разделить и масштабировать набор данных карт, готовый для обучения из os import listdir from numpy import asarray from numpy import vstack from keras.preprocessing.image import img_to_array from keras.preprocessing.image import load_img from numpy import savez_compressed # загрузить все изображения из каталога в память def load_images (путь, размер = ( |
# перечислить имена файлов в каталоге, предположим, что все являются изображениями
для имени файла в listdir (путь):
# загрузить и изменить размер изображения
пикселей = load_img (путь + имя файла , target_size = size)
# преобразовать в массив numpy
пикселей = img_to_array (пикселей)
# разделить на спутник и карту
sat_img, map_img = пикселей [:,: 256], пикселей [:, 256:]
src_list. append (sat_img)
append (sat_img)
tar_list.append (map_img)
return [asarray (src_list), asarray (tar_list)]
# путь к набору данных
path = ‘maps / train /’
#
load dataset2 [src_images, tar_images] = load_images (путь)print (‘Loaded:’, src_images.shape, tar_images.shape)
# сохранить как сжатый массив numpy
filename = ‘maps_256.npz’
savez, src_images, tar_images)
print (‘Сохраненный набор данных:’, имя файла)
При выполнении примера загружаются все изображения в наборе обучающих данных, суммируются их формы, чтобы изображения были загружены правильно, а затем массивы сохраняются в новый файл с именем maps_256.npz в формате сжатого массива NumPy.
Загружено: (1096, 256, 256, 3) (1096, 256, 256, 3) Сохраненный набор данных: maps_256.npz
Загружено: (1096, 256, 256, 3) (1096, 256, 256, 3) Сохраненный набор данных: maps_256. |
 npz
npzЭтот файл можно загрузить позже с помощью функции load () NumPy и получения каждого массива по очереди.
Затем мы можем построить несколько пар изображений, чтобы убедиться, что данные были обработаны правильно.
# загружаем подготовленный набор данных от нагрузки импорта numpy из matplotlib import pyplot # загрузить набор данных data = load (‘maps_256.npz’) src_images, tar_images = данные [‘arr_0’], data [‘arr_1’] print (‘Загружено:’, src_images.shape, tar_images.shape) # сюжет исходных изображений n_samples = 3 для i в диапазоне (n_samples): pyplot.subplot (2, n_samples, 1 + i) pyplot.axis (‘выключено’) pyplot.imshow (src_images [i] .astype (‘uint8’)) # построить целевое изображение для i в диапазоне (n_samples): пиплот.подзаговор (2, n_samples, 1 + n_samples + i) pyplot.axis (‘выключено’) pyplot.imshow (tar_images [i] .astype (‘uint8’)) pyplot.show ()
1 2 3 4 5 6 7 8 9 10 11 12 13 140002 14 18 19 | # загрузить подготовленный набор данных из numpy import load из matplotlib import pyplot # загрузить набор данных data = load (‘maps_256. src_images, tar_images = data [‘ arr_0 ‘], data [‘ arr_1 ‘] print (‘ Loaded: ‘, src_images.shape, tar_images.shape) # построить исходные изображения n_samples для i в диапазоне (n_samples): pyplot.subplot (2, n_samples, 1 + i) pyplot.axis (‘off’) pyplot.imshow (src_images [i] .astype (‘uint8’) )) # построить целевое изображение для i в диапазоне (n_samples): pyplot.subplot (2, n_samples, 1 + n_samples + i) pyplot.ось (‘off’) pyplot.imshow (tar_images [i] .astype (‘uint8’)) pyplot.show () |
 npz ‘)
npz ‘)Выполнение этого примера загружает подготовленный набор данных и суммирует форму каждого массива, подтверждая наши ожидания немногим более тысячи пар изображений 256 × 256.
Загружено: (1096, 256, 256, 3) (1096, 256, 256, 3)
Загружено: (1096, 256, 256, 3) (1096, 256, 256, 3) |
Также создается график из трех пар изображений, показывающий спутниковые изображения вверху и изображения карты Google внизу.
Мы видим, что спутниковые изображения довольно сложны и, хотя изображения карты Google намного проще, они имеют цветовую кодировку для таких вещей, как основные дороги, вода и парки.
График из трех пар изображений, показывающий спутниковые изображения (вверху) и изображения Google Map (внизу).
Теперь, когда мы подготовили набор данных для перевода изображений, мы можем разработать нашу модель Pix2Pix GAN.
Как разработать и обучить модель Pix2Pix
В этом разделе мы разработаем модель Pix2Pix для перевода спутниковых фотографий в изображения Google Maps.
Та же архитектура и конфигурация модели, описанные в документе, использовались для решения ряда задач по переводу изображений. Эта архитектура описана как в основной части документа, с дополнительными подробностями в приложении к документу, так и в полностью работающей реализации, представленной как открытый исходный код с фреймворком глубокого обучения Torch.
Реализация в этом разделе будет использовать структуру глубокого обучения Keras, основанную непосредственно на модели, описанной в документе и реализованной в базе кода автора, предназначенной для получения и создания цветных изображений размером 256 × 256 пикселей.
Архитектура состоит из двух моделей: дискриминатора и генератора.
Дискриминатор — это глубокая сверточная нейронная сеть, которая выполняет классификацию изображений. В частности, условная классификация изображений. Он принимает как исходное изображение (например, спутниковое фото), так и целевое изображение (например, изображение Google Maps) в качестве входных данных и прогнозирует вероятность того, является ли целевое изображение реальным или поддельным переводом исходного изображения.
Дизайн дискриминатора основан на эффективном воспринимающем поле модели, которое определяет отношение между одним выходом модели и количеством пикселей во входном изображении.Это называется моделью PatchGAN и тщательно спроектировано таким образом, чтобы каждый выходной прогноз модели соответствовал квадрату или фрагменту входного изображения размером 70 × 70. Преимущество этого подхода заключается в том, что одна и та же модель может применяться к входным изображениям разных размеров, например. больше или меньше 256 × 256 пикселей.
больше или меньше 256 × 256 пикселей.
Выход модели зависит от размера входного изображения, но может представлять собой одно значение или квадратную карту активации значений. Каждое значение представляет собой вероятность того, что пятно во входном изображении является реальным.Эти значения могут быть усреднены для получения общей вероятности или классификационной оценки, если это необходимо.
Функция define_discriminator () ниже реализует модель дискриминатора 70 × 70 PatchGAN в соответствии с дизайном модели, описанной в статье. Модель берет два входных изображения, которые объединены вместе, и предсказывает исправление вывода предсказаний. Модель оптимизирована с использованием бинарной кросс-энтропии, и используется взвешивание, так что обновления модели дают половину (0,5) обычного эффекта.Авторы Pix2Pix рекомендуют это взвешивание обновлений модели, чтобы замедлить изменения дискриминатора по сравнению с моделью генератора во время обучения.
# определяем модель дискриминатора
def define_discriminator (image_shape):
# инициализация веса
init = RandomNormal (стандартное отклонение = 0,02)
# вход исходного изображения
in_src_image = Вход (shape = image_shape)
# ввод целевого изображения
in_target_image = Вход (shape = image_shape)
# объединить изображения по каналам
merged = Concatenate () ([in_src_image, in_target_image])
# C64
d = Conv2D (64, (4,4), strides = (2,2), padding = ‘same’, kernel_initializer = init) (объединено)
d = LeakyReLU (альфа = 0. 2) (г)
# C128
d = Conv2D (128, (4,4), strides = (2,2), padding = ‘same’, kernel_initializer = init) (d)
d = BatchNormalization () (d)
d = LeakyReLU (альфа = 0,2) (d)
# C256
d = Conv2D (256, (4,4), strides = (2,2), padding = ‘same’, kernel_initializer = init) (d)
d = BatchNormalization () (d)
d = LeakyReLU (альфа = 0,2) (d)
# C512
d = Conv2D (512, (4,4), strides = (2,2), padding = ‘same’, kernel_initializer = init) (d)
d = BatchNormalization () (d)
d = LeakyReLU (альфа = 0.2) (г)
# второй последний выходной слой
d = Conv2D (512, (4,4), padding = ‘same’, kernel_initializer = init) (d)
d = BatchNormalization () (d)
d = LeakyReLU (альфа = 0,2) (d)
# вывод патча
d = Conv2D (1, (4,4), padding = ‘same’, kernel_initializer = init) (d)
patch_out = Активация (‘сигмоид’) (d)
# определить модель
model = Модель ([in_src_image, in_target_image], patch_out)
# скомпилировать модель
opt = Адам (lr = 0,0002, beta_1 = 0,5)
model.compile (loss = ‘binary_crossentropy’, optimizer = opt, loss_weights = [0.
2) (г)
# C128
d = Conv2D (128, (4,4), strides = (2,2), padding = ‘same’, kernel_initializer = init) (d)
d = BatchNormalization () (d)
d = LeakyReLU (альфа = 0,2) (d)
# C256
d = Conv2D (256, (4,4), strides = (2,2), padding = ‘same’, kernel_initializer = init) (d)
d = BatchNormalization () (d)
d = LeakyReLU (альфа = 0,2) (d)
# C512
d = Conv2D (512, (4,4), strides = (2,2), padding = ‘same’, kernel_initializer = init) (d)
d = BatchNormalization () (d)
d = LeakyReLU (альфа = 0.2) (г)
# второй последний выходной слой
d = Conv2D (512, (4,4), padding = ‘same’, kernel_initializer = init) (d)
d = BatchNormalization () (d)
d = LeakyReLU (альфа = 0,2) (d)
# вывод патча
d = Conv2D (1, (4,4), padding = ‘same’, kernel_initializer = init) (d)
patch_out = Активация (‘сигмоид’) (d)
# определить модель
model = Модель ([in_src_image, in_target_image], patch_out)
# скомпилировать модель
opt = Адам (lr = 0,0002, beta_1 = 0,5)
model.compile (loss = ‘binary_crossentropy’, optimizer = opt, loss_weights = [0. 5])
вернуть модель
5])
вернуть модель
1 2 3 4 5 6 7 8 9 10 11 12 13 140002 14 18 19 20 21 22 23 24 25 26 27 28 29 30 000 3435 36 37 38 | # определение модели дискриминатора def define_discriminator (image_shape): # инициализация веса init = RandomNormal (stddev = 0.02) # исходное изображение input in_src_image = Input (shape = image_shape) # целевое изображение input in_target_image = Input (shape = image_shape) # объединять изображения по каналам merged (объединить) (объединить) [in_src_image, in_target_image]) # C64 d = Conv2D (64, (4,4), strides = (2,2), padding = ‘same’, kernel_initializer = init) (объединено) d = LeakyReLU (альфа = 0,2) (d) # C128 d = Conv2D (128, (4,4), strides = (2,2), padding = ‘same’, kernel_initializer = init) (d) d = BatchNormalization () (d) d = LeakyReLU (альфа = 0. # C256 d = Conv2D (256, (4,4), strides = (2,2), padding = ‘same’, kernel_initializer = init) (d) d = BatchNormalization ( ) (d) d = LeakyReLU (alpha = 0.2) (d) # C512 d = Conv2D (512, (4,4), strides = (2,2), padding = ‘same’, kernel_initializer = init) (d) d = BatchNormalization () (d) d = LeakyReLU (alpha = 0.2) (d) # второй последний выходной слой d = Conv2D (512, (4,4), padding = ‘same’, kernel_initializer = init) (d) d = BatchNormalization () (d) d = LeakyReLU (alpha = 0.2) (d) # вывод патча d = Conv2D (1, (4,4), padding = ‘same’, kernel_initializer = init) (d) patch_out = Activation (‘sigmoid’) (d) # определить модель model = Model ([in_src_image, in_target_image], patch_out) # compile model opt = Adam (lr = 0.0002, beta_1 = 0.5) model.compile (loss = ‘binary_crossentropy’, optimizer = opt, loss_weights = [0. модель возврата |
 5])
5])Модель генератора сложнее модели дискриминатора.
Генератор представляет собой модель кодера-декодера, использующую архитектуру U-Net. Модель берет исходное изображение (например, спутниковое фото) и генерирует целевое изображение (например, изображение Google Maps). Для этого сначала используется понижающая дискретизация или кодирование входного изображения до уровня узкого места, а затем повышающая дискретизация или декодирование представления узкого места до размера выходного изображения. Архитектура U-Net означает, что между уровнями кодирования и соответствующими уровнями декодирования добавляются пропускные соединения, образуя U-образную форму.
Изображение ниже проясняет пропускные соединения, показывая, как первый уровень кодера соединяется с последним уровнем декодера и так далее.
Архитектура генератора U-Net модели
, взятая из преобразования изображения в изображение с помощью условно состязательных сетей
Кодер и декодер генератора состоят из стандартизованных блоков сверточного, пакетного уровней нормализации, исключения и активации. Эта стандартизация означает, что мы можем разрабатывать вспомогательные функции для создания каждого блока слоев и многократно вызывать его для создания частей модели, кодирующих и декодирующих.
Эта стандартизация означает, что мы можем разрабатывать вспомогательные функции для создания каждого блока слоев и многократно вызывать его для создания частей модели, кодирующих и декодирующих.
Функция define_generator () ниже реализует модель генератора кодировщика-декодера U-Net. Он использует вспомогательную функцию define_encoder_block () для создания блоков слоев для кодера и функцию decoder_block () для создания блоков слоев для декодера. В выходном слое используется функция активации tanh, что означает, что значения пикселей в сгенерированном изображении будут в диапазоне [-1,1].
# определить блок кодировщика
def define_encoder_block (layer_in, n_filters, batchnorm = True):
# инициализация веса
init = RandomNormal (stddev = 0.02)
# добавить слой понижающей дискретизации
g = Conv2D (n_filters, (4,4), strides = (2,2), padding = ‘same’, kernel_initializer = init) (layer_in)
# условно добавить пакетную нормализацию
если батчнорм:
g = BatchNormalization () (g, обучение = True)
# дырявая активация relu
г = LeakyReLU (альфа = 0,2) (г)
вернуть г # определяем блок декодера
def decoder_block (layer_in, skip_in, n_filters, dropout = True):
# инициализация веса
init = RandomNormal (стандартное отклонение = 0,02)
# добавить слой с повышающей дискретизацией
g = Conv2DTranspose (n_filters, (4,4), strides = (2,2), padding = ‘same’, kernel_initializer = init) (layer_in)
# добавить пакетную нормализацию
g = BatchNormalization () (g, обучение = True)
# условно добавить отсев
если бросил:
g = выпадение (0. 5) (g, обучение = True)
# объединить с пропустить соединение
g = Concatenate () ([g, skip_in])
# активация relu
g = Активация (‘relu’) (g)
вернуть г # определить модель автономного генератора
def define_generator (image_shape = (256,256,3)):
# инициализация веса
init = RandomNormal (стандартное отклонение = 0,02)
# ввод изображения
in_image = Вход (shape = image_shape)
# модель кодировщика
e1 = define_encoder_block (in_image, 64, batchnorm = False)
e2 = define_encoder_block (e1, 128)
e3 = define_encoder_block (e2, 256)
e4 = define_encoder_block (e3, 512)
e5 = define_encoder_block (e4, 512)
e6 = define_encoder_block (e5, 512)
e7 = define_encoder_block (e6, 512)
# бутылочное горлышко, без партии norm и relu
b = Conv2D (512, (4,4), strides = (2,2), padding = ‘same’, kernel_initializer = init) (e7)
b = Активация (‘relu’) (b)
# модель декодера
d1 = decoder_block (b, e7, 512)
d2 = decoder_block (d1, e6, 512)
d3 = decoder_block (d2, e5, 512)
d4 = decoder_block (d3, e4, 512, dropout = False)
d5 = decoder_block (d4, e3, 256, dropout = False)
d6 = decoder_block (d5, e2, 128, dropout = False)
d7 = decoder_block (d6, e1, 64, dropout = False)
# выход
g = Conv2DTranspose (3, (4,4), strides = (2,2), padding = ‘same’, kernel_initializer = init) (d7)
out_image = Активация (‘tanh’) (г)
# определить модель
model = Модель (in_image, out_image)
вернуть модель
5) (g, обучение = True)
# объединить с пропустить соединение
g = Concatenate () ([g, skip_in])
# активация relu
g = Активация (‘relu’) (g)
вернуть г # определить модель автономного генератора
def define_generator (image_shape = (256,256,3)):
# инициализация веса
init = RandomNormal (стандартное отклонение = 0,02)
# ввод изображения
in_image = Вход (shape = image_shape)
# модель кодировщика
e1 = define_encoder_block (in_image, 64, batchnorm = False)
e2 = define_encoder_block (e1, 128)
e3 = define_encoder_block (e2, 256)
e4 = define_encoder_block (e3, 512)
e5 = define_encoder_block (e4, 512)
e6 = define_encoder_block (e5, 512)
e7 = define_encoder_block (e6, 512)
# бутылочное горлышко, без партии norm и relu
b = Conv2D (512, (4,4), strides = (2,2), padding = ‘same’, kernel_initializer = init) (e7)
b = Активация (‘relu’) (b)
# модель декодера
d1 = decoder_block (b, e7, 512)
d2 = decoder_block (d1, e6, 512)
d3 = decoder_block (d2, e5, 512)
d4 = decoder_block (d3, e4, 512, dropout = False)
d5 = decoder_block (d4, e3, 256, dropout = False)
d6 = decoder_block (d5, e2, 128, dropout = False)
d7 = decoder_block (d6, e1, 64, dropout = False)
# выход
g = Conv2DTranspose (3, (4,4), strides = (2,2), padding = ‘same’, kernel_initializer = init) (d7)
out_image = Активация (‘tanh’) (г)
# определить модель
model = Модель (in_image, out_image)
вернуть модель
1 2 3 4 5 6 7 8 9 10 11 12 13 140002 14 18 19 20 21 22 23 24 25 26 27 28 29 30 000 3435 36 37 38 39 40 41 42 43 44 45 46 47 00030002 4700030002 47000351 52 53 54 55 56 57 58 59 60 61 | # определение блока кодера def define_encoder_block (layer_in, n_filters, batchnorm = True): # инициализация веса init = RandomNormal (stddev = 0.02) # добавить слой понижающей дискретизации g = Conv2D (n_filters, (4,4), strides = (2,2), padding = ‘same’, kernel_initializer = init) (layer_in) # условно добавить пакетную нормализацию если batchnorm: g = BatchNormalization () (g, training = True) # Alucky Relu Activation g = LeakyReLU (alpha = 0.2) (g) return g # определить декодер block def decoder_block (layer_in, skip_in, n_filters, dropout = True): # инициализация веса init = RandomNormal (stddev = 0.02) # добавить слой с повышающей дискретизацией g = Conv2DTranspose (n_filters, (4,4), strides = (2,2), padding = ‘same’, kernel_initializer = init) (layer_in) # добавить пакетную нормализацию g = BatchNormalization () (g, training = True) # условно добавить выпадение если выпадение: g = выпадение (0,5) (g, обучение = True) # слияние с пропуском соединения g = Concatenate () ([g, skip_in]) # повторная активация g = Activation (‘relu’) (g) return g # определение модели автономного генератора def define_generator (image_shape = ( 256,256,3)): # инициализация веса init = RandomNormal (stddev = 0.02) # image input in_image = Input (shape = image_shape) # модель кодировщика e1 = define_encoder_block (in_image, 64, batchnorm = False) e2 = define_encoder_block 9 = define_encoder_block (e2, 256) e4 = define_encoder_block (e3, 512) e5 = define_encoder_block (e4, 512) e6 = define_encoder_block (e5, 512) ck 9_b = define_encoder , без пакетной нормы и relu b = Conv2D (512, (4,4), strides = (2,2), padding = ‘same’, kernel_initializer = init) (e7) b = Activation (‘relu’ ) (b) # модель декодера d1 = decoder_block (b, e7, 512) d2 = decoder_block (d1, e6, 512) d3 = decoder_block (d2, e5, 512) d4 = decoder_block (d3, e4, 512, dropout = False) d5 = decoder_block (d4, e3, 256, dropout = False) d6 = decoder_block (d5, e2, 128, dropout = False) d7 = decoder_block (d6, e1, 64, dropout = False) # output g = Conv2DTranspose (3, (4,4), strides = (2,2), padding = ‘same ‘, kernel_initializer = init) (d7) out_image = Activation (‘ tanh ‘) (g) # define model model = Model (in_image, out_image) return model |
Модель дискриминатора обучается непосредственно на реальных и сгенерированных изображениях, тогда как модель генератора — нет.
Вместо этого модель генератора обучается с помощью модели дискриминатора. Он обновлен, чтобы минимизировать потери, прогнозируемые дискриминатором для сгенерированных изображений, помеченных как « реальные ». Таким образом, рекомендуется создавать более реальные изображения. Генератор также обновляется, чтобы минимизировать потерю L1 или среднюю абсолютную ошибку между сгенерированным изображением и целевым изображением.
Генератор обновляется посредством взвешенной суммы как состязательных потерь, так и потерь L1, где авторы модели рекомендуют взвешивать 100: 1 в пользу потерь L1.Это сделано для того, чтобы генератор сильно побуждал генерировать правдоподобные переводы входного изображения, а не просто правдоподобные изображения в целевой области.
Это может быть достигнуто путем определения новой логической модели, состоящей из весов в существующей модели автономного генератора и дискриминатора. Эта логическая или составная модель включает в себя установку генератора поверх дискриминатора. Исходное изображение предоставляется как вход для генератора и дискриминатора, хотя выход генератора подключен к дискриминатору как соответствующее изображение « target ».Затем дискриминатор предсказывает вероятность того, что генератор был реальным переводом исходного изображения.
Дискриминатор обновляется автономно, поэтому веса повторно используются в этой составной модели, но помечены как не обучаемые. Составная модель обновляется двумя целями, одна из которых указывает, что сгенерированные изображения были реальными (кросс-энтропийная потеря), заставляя большие обновления веса в генераторе генерировать более реалистичные изображения, и выполненный реальный перевод изображения, который сравнивается с выход модели генератора (потеря L1).
Функция define_gan () ниже реализует это, принимая уже определенные модели генератора и дискриминатора в качестве аргументов и используя функциональный API Keras для их соединения в составную модель. Обе функции потерь указаны для двух выходных данных модели, а веса, используемые для каждого, указаны в аргументе loss_weights функции compile () .
# определить комбинированную модель генератора и дискриминатора для обновления генератора def define_gan (g_model, d_model, image_shape): # сделать веса в дискриминаторе необучаемыми для слоя в d_model.слои: если не isinstance (слой, BatchNormalization): layer.trainable = Ложь # определяем исходное изображение in_src = Вход (shape = image_shape) # подключаем исходное изображение ко входу генератора gen_out = g_model (in_src) # подключаем вход источника и выход генератора ко входу дискриминатора dis_out = d_model ([in_src, gen_out]) # src image как вход, сгенерированное изображение и вывод классификации model = Модель (in_src, [dis_out, gen_out]) # скомпилировать модель opt = Адам (lr = 0.0002, beta_1 = 0,5) model.compile (loss = [‘binary_crossentropy’, ‘mae’], optimizer = opt, loss_weights = [1,100]) вернуть модель
1 2 3 4 5 6 7 8 9 10 11 12 13 140002 14 18 | # определить комбинированную модель генератора и дискриминатора, для обновления генератора def define_gan (g_model, d_model, image_shape): # сделать веса в дискриминаторе не обучаемыми для слоя в d_model.Layers: if not isinstance (layer, BatchNormalization): layer.trainable = False # определить исходное изображение in_src = Input (shape = image_shape) # подключить исходное изображение ко входу генератора gen_out = g_model (in_src) # подключите вход источника и выход генератора к входу дискриминатора dis_out = d_model ([in_src, gen_out]) # src изображение в качестве входа, сгенерированное изображение и выход классификации model = Model (in_src, [dis_out, gen_out]) # скомпилировать модель opt = Adam (lr = 0.0002, beta_1 = 0,5) model.compile (loss = [‘binary_crossentropy’, ‘mae’], optimizer = opt, loss_weights = [1,100]) return model |
Затем мы можем загрузить наш набор данных парных изображений в формате сжатого массива NumPy.
Это вернет список из двух массивов NumPy: первый для исходных изображений и второй для соответствующих целевых изображений.
# загрузить и подготовить обучающие изображения def load_real_samples (имя файла): # загружаем сжатые массивы данные = загрузка (имя файла) # распаковать массивы X1, X2 = данные [‘arr_0’], данные [‘arr_1’] # масштаб от [0,255] до [-1,1] Х1 = (Х1 — 127.5) / 127,5 Х2 = (Х2 — 127,5) / 127,5 возврат [X1, X2]
# загрузить и подготовить обучающие изображения def load_real_samples (filename): # загрузить сжатые массивы data = load (filename) # распаковать массивы X1, X2 = data [‘arr_0’], data [ ‘arr_1’] # масштаб от [0,255] до [-1,1] X1 = (X1 — 127,5) / 127,5 X2 = (X2 — 127,5) / 127.5 возврат [X1, X2] |
Для обучения дискриминатора потребуются пакеты реальных и поддельных изображений.
Функция generate_real_samples () ниже подготовит пакет случайных пар изображений из обучающего набора данных и соответствующую метку дискриминатора class = 1 , чтобы указать, что они реальны.
# выбираем партию случайных выборок, возвращаем изображения и выбираем def generate_real_samples (набор данных, n_samples, patch_shape): # распаковать набор данных trainA, trainB = набор данных # выбираем случайные экземпляры ix = randint (0, trainA.форма [0], n_samples) # получить выбранные изображения X1, X2 = поезд A [ix], поезд B [ix] # генерировать «настоящие» метки классов (1) y = единицы ((n_samples, patch_shape, patch_shape, 1)) return [X1, X2], y
# выбрать пакет случайных выборок, вернуть изображения и цель def generate_real_samples (dataset, n_samples, patch_shape): # распаковать набор данных trainA, trainB = dataset # выбрать случайные экземпляры ix = 0, поезд А.shape [0], n_samples) # извлекать выбранные изображения X1, X2 = trainA [ix], trainB [ix] # генерировать метки реальных классов (1) y = единицы ((n_samples, patch_shape , patch_shape, 1)) return [X1, X2], y |
Функция generate_fake_samples () ниже использует модель генератора и пакет реальных исходных изображений для создания эквивалентного пакета целевых изображений для дискриминатора.
Они возвращаются с меткой class-0, чтобы указать дискриминатору, что они поддельные.
# генерировать пакет изображений, возвращает изображения и цели def generate_fake_samples (g_model, samples, patch_shape): # создать поддельный экземпляр X = g_model.predict (образцы) # создать фальшивые метки классов (0) y = нули ((len (X), patch_shape, patch_shape, 1)) возврат X, y
# генерировать пакет изображений, возвращать изображения и цели def generate_fake_samples (g_model, samples, patch_shape): # генерировать поддельный экземпляр X = g_model.предсказать (образцы) # создать ‘поддельные’ метки классов (0) y = нули ((len (X), patch_shape, patch_shape, 1)) return X, y |
Обычно модели GAN не сходятся; вместо этого находится равновесие между моделями генератора и дискриминатора. Таким образом, мы не можем легко судить, когда следует прекратить тренировку. Следовательно, мы можем сохранить модель и использовать ее для периодического генерирования примеров преобразования изображения в изображение во время обучения, например, каждые 10 эпох обучения.
Затем мы можем просмотреть сгенерированные изображения в конце обучения и использовать качество изображения для выбора окончательной модели.
Функция summarize_performance () реализует это, беря модель генератора в момент обучения и используя ее для генерации числа, в данном случае трех, переводов случайно выбранных изображений в наборе данных. Затем исходное, сгенерированное изображение и ожидаемая цель отображаются в виде трех рядов изображений, а график сохраняется в файл. Кроме того, модель сохраняется в файл в формате H5, что упрощает загрузку в дальнейшем.
Имена файлов изображений и моделей включают номер итерации обучения, что позволяет нам легко различать их в конце обучения.
# сгенерировать образцы и сохранить как график и сохранить модель def summarize_performance (шаг, g_model, набор данных, n_samples = 3): # выбираем образец входных изображений [X_realA, X_realB], _ = generate_real_samples (набор данных, n_samples, 1) # создать партию поддельных образцов X_fakeB, _ = generate_fake_samples (g_model, X_realA, 1) # масштабировать все пиксели от [-1,1] до [0,1] X_realA = (X_realA + 1) / 2.0 X_realB = (X_realB + 1) / 2.0 X_fakeB = (X_fakeB + 1) / 2.0 # построить реальные исходные изображения для i в диапазоне (n_samples): pyplot.subplot (3, n_samples, 1 + i) pyplot.axis (‘выключено’) pyplot.imshow (X_realA [i]) # сюжет сгенерировал целевое изображение для i в диапазоне (n_samples): pyplot.subplot (3, n_samples, 1 + n_samples + i) pyplot.axis (‘выключено’) pyplot.imshow (X_fakeB [i]) # построить реальное целевое изображение для i в диапазоне (n_samples): пиплот.подзаговор (3, n_samples, 1 + n_samples * 2 + i) pyplot.axis (‘выключено’) pyplot.imshow (X_realB [i]) # сохранить график в файл filename1 = ‘plot_% 06d.png’% (шаг + 1) pyplot.savefig (имя_файла1) pyplot.close () # сохраняем модель генератора filename2 = ‘model_% 06d.h5’% (шаг + 1) g_model.save (имя_файла2) print (‘> Сохранено:% s и% s’% (имя_файла1, имя_файла2))
1 2 3 4 5 6 7 8 9 10 11 12 13 140002 14 18 19 20 21 22 23 24 25 26 27 28 29 30 0003 | # сгенерировать образцы и сохранить как график и сохранить модель def summarize_performance (step, g_model, dataset, n_samples = 3): # выбрать образец входных изображений [X_realA, X_realB], _ = generate_real_samples (dataset, n_samples, 1) # создать пакет поддельных образцов X_fakeB, _ = generate_fake_samples (g_model, X_realA, 1) # масштабировать все пиксели от [-1,1] до [0,1] X_realA = (X_realA + 1) / 2.0 X_realB = (X_realB + 1) / 2.0 X_fakeB = (X_fakeB + 1) / 2.0 # построить реальные исходные изображения для i в диапазоне (n_samples): pyplot.subplot (3, n_samples, 1 + i) pyplot.axis (‘off’) pyplot.imshow (X_realA [i]) # plot сгенерированное целевое изображение для i в диапазоне (n_samples): pyplot.subplot (3, n_samples, 1 + n_samples + i) pyplot.axis (‘off’) pyplot.imshow (X_fakeB [i]) # построить реальное целевое изображение для i в диапазоне (n_samples): pyplot.subplot (3, n_samples, 1 + n_samples * 2 + i) pyplot.axis (‘off ‘) pyplot.imshow (X_realB [i]) # сохранить график в файл filename1 =’ plot_% 06d.png ‘% (step + 1) pyplot.savefig (filename1) pyplot.close () # сохранить модель генератора filename2 = ‘model_% 06d.h5’% (step + 1) g_model.save (filename2) print (‘> Сохранено:% s и% s’% (filename1, filename2)) |
Наконец, мы можем обучить модели генератора и дискриминатора.
Функция train () ниже реализует это, принимая заданный генератор, дискриминатор, составную модель и загруженный набор данных в качестве входных данных. Количество эпох установлено на 100, чтобы сократить время обучения, хотя в статье использовалось 200. Размер партии 1 используется, как рекомендовано в статье.
Обучение включает фиксированное количество итераций обучения. В наборе обучающих данных 1097 изображений. Одна эпоха — это одна итерация по этому количеству примеров, при этом размер пакета, равный единице, означает 1097 шагов обучения. Генератор сохраняется и оценивается каждые 10 эпох или каждые 10970 обучающих шагов, а модель будет работать в течение 100 эпох, или всего 109 700 обучающих шагов.
Каждый шаг обучения включает в себя сначала выбор пакета реальных примеров, а затем использование генератора для создания пакета совпадающих поддельных образцов с использованием реальных исходных изображений.Затем дискриминатор обновляется пакетом реальных изображений, а затем — поддельными изображениями.
Затем модель генератора обновляется, предоставляя реальные исходные изображения в качестве входных данных и предоставляя метки классов 1 (реальные) и реальные целевые изображения в качестве ожидаемых выходных данных модели, необходимой для расчета потерь. Генератор имеет две оценки потерь, а также оценку взвешенной суммы, полученную при вызове train_on_batch () . Нас интересует только взвешенная сумма баллов (первое возвращаемое значение), поскольку она используется для обновления весов модели.
Наконец, потеря для каждого обновления сообщается на консоль на каждой итерации обучения, а производительность модели оценивается каждые 10 периодов обучения.
# поезд pix2pix модель def train (d_model, g_model, gan_model, набор данных, n_epochs = 100, n_batch = 1): # определяем выходную квадратную форму дискриминатора n_patch = d_model.output_shape [1] # распаковать набор данных trainA, trainB = набор данных # подсчитываем количество пакетов за период обучения bat_per_epo = интервал (len (trainA) / n_batch) # рассчитываем количество итераций обучения n_steps = bat_per_epo * n_epochs # вручную перечислить эпохи для i в диапазоне (n_steps): # выбрать партию реальных образцов [X_realA, X_realB], y_real = generate_real_samples (набор данных, n_batch, n_patch) # создать партию поддельных образцов X_fakeB, y_fake = generate_fake_samples (g_model, X_realA, n_patch) # обновить дискриминатор для реальных образцов d_loss1 = d_model.train_on_batch ([X_realA, X_realB], y_real) # обновить дискриминатор для сгенерированных образцов d_loss2 = d_model.train_on_batch ([X_realA, X_fakeB], y_fake) # обновить генератор g_loss, _, _ = gan_model.train_on_batch (X_realA, [y_real, X_realB]) # подвести итоги print (‘>% d, d1 [%. 3f] d2 [%. 3f] g [%. 3f]’% (i + 1, d_loss1, d_loss2, g_loss)) # подвести итоги работы модели если (i + 1)% (bat_per_epo * 10) == 0: summarize_performance (я, g_model, набор данных)
1 2 3 4 5 6 7 8 9 10 11 12 13 140002 14 18 19 20 21 22 23 24 25 26 27 | # train pix2pix model def train (d_model, g_model, gan_model, dataset, n_epochs = 100, n_batch = 1): # определение выходной квадратной формы дискриминатора n_patch = d_model.output_shape [1] # распаковать набор данных trainA, trainB = dataset # вычислить количество пакетов на тренировочную эпоху bat_per_epo = int (len (trainA) / n_batch) # вычислить количество итераций обучения n_steps = bat_per_epo * n_epochs # вручную перечислить эпохи для i в диапазоне (n_steps): # выбрать партию реальных выборок [X_realA, X_realB], y_real_patch_realBase, y_real_patch_real_sample = (сгенерировать) # создать пакет поддельных образцов X_fakeB, y_fake = generate_fake_samples (g_model, X_realA, n_patch) # обновить дискриминатор для реальных образцов d_loss1 = d_model.train_on_batch ([X_realA, X_realB], y_real) # обновить дискриминатор для сгенерированных образцов d_loss2 = d_model.train_on_batch ([X_realA, X_fakeB], y_fake) # обновить генератор 9_dellossan, train_on_batch (X_realA, [y_real, X_realB]) # суммируем производительность print (‘>% d, d1 [%. 3f] d2 [%. 3f] g [%. 3f]’% (i + 1, d_loss1 , d_loss2, g_loss)) # суммировать производительность модели if (i + 1)% (bat_per_epo * 10) == 0: summarize_performance (i, g_model, dataset) |
Объединив все это вместе, ниже приведен полный пример кода для обучения Pix2Pix GAN преобразованию спутниковых фотографий в изображения Google Maps.
# пример pix2pix gan для спутника для преобразования изображения в изображение от нагрузки импорта numpy из numpy импортных нулей из множества импортных из numpy.random import randint от keras.optimizers импорт Адам из keras.initializers import RandomNormal из keras.models импорт модели from keras.models import Input из keras.layers импортировать Conv2D из keras.layers import Conv2DTranspose from keras.layers import LeakyReLU из кераса.активация импорта слоев из keras.layers import Concatenate из keras.layers import Dropout из keras.layers import BatchNormalization from keras.layers import LeakyReLU из matplotlib import pyplot # определяем модель дискриминатора def define_discriminator (image_shape): # инициализация веса init = RandomNormal (стандартное отклонение = 0,02) # вход исходного изображения in_src_image = Вход (shape = image_shape) # ввод целевого изображения in_target_image = Вход (shape = image_shape) # объединить изображения по каналам merged = Concatenate () ([in_src_image, in_target_image]) # C64 d = Conv2D (64, (4,4), strides = (2,2), padding = ‘same’, kernel_initializer = init) (объединено) d = LeakyReLU (альфа = 0.2) (г) # C128 d = Conv2D (128, (4,4), strides = (2,2), padding = ‘same’, kernel_initializer = init) (d) d = BatchNormalization () (d) d = LeakyReLU (альфа = 0,2) (d) # C256 d = Conv2D (256, (4,4), strides = (2,2), padding = ‘same’, kernel_initializer = init) (d) d = BatchNormalization () (d) d = LeakyReLU (альфа = 0,2) (d) # C512 d = Conv2D (512, (4,4), strides = (2,2), padding = ‘same’, kernel_initializer = init) (d) d = BatchNormalization () (d) d = LeakyReLU (альфа = 0.2) (г) # второй последний выходной слой d = Conv2D (512, (4,4), padding = ‘same’, kernel_initializer = init) (d) d = BatchNormalization () (d) d = LeakyReLU (альфа = 0,2) (d) # вывод патча d = Conv2D (1, (4,4), padding = ‘same’, kernel_initializer = init) (d) patch_out = Активация (‘сигмоид’) (d) # определить модель model = Модель ([in_src_image, in_target_image], patch_out) # скомпилировать модель opt = Адам (lr = 0,0002, beta_1 = 0,5) model.compile (loss = ‘binary_crossentropy’, optimizer = opt, loss_weights = [0.5]) модель возврата # определить блок кодировщика def define_encoder_block (layer_in, n_filters, batchnorm = True): # инициализация веса init = RandomNormal (стандартное отклонение = 0,02) # добавить слой понижающей дискретизации g = Conv2D (n_filters, (4,4), strides = (2,2), padding = ‘same’, kernel_initializer = init) (layer_in) # условно добавить пакетную нормализацию если батчнорм: g = BatchNormalization () (g, обучение = True) # дырявая активация relu g = LeakyReLU (альфа = 0.2) (г) вернуть г # определяем блок декодера def decoder_block (layer_in, skip_in, n_filters, dropout = True): # инициализация веса init = RandomNormal (стандартное отклонение = 0,02) # добавить слой с повышающей дискретизацией g = Conv2DTranspose (n_filters, (4,4), strides = (2,2), padding = ‘same’, kernel_initializer = init) (layer_in) # добавить пакетную нормализацию g = BatchNormalization () (g, обучение = True) # условно добавить отсев если бросил: g = выпадение (0,5) (g, обучение = верно) # объединить с пропустить соединение g = Concatenate () ([g, skip_in]) # активация relu g = Активация (‘relu’) (g) вернуть г # определить модель автономного генератора def define_generator (image_shape = (256,256,3)): # инициализация веса init = RandomNormal (stddev = 0.02) # ввод изображения in_image = Вход (shape = image_shape) # модель кодировщика e1 = define_encoder_block (in_image, 64, batchnorm = False) e2 = define_encoder_block (e1, 128) e3 = define_encoder_block (e2, 256) e4 = define_encoder_block (e3, 512) e5 = define_encoder_block (e4, 512) e6 = define_encoder_block (e5, 512) e7 = define_encoder_block (e6, 512) # бутылочное горлышко, без партии norm и relu b = Conv2D (512, (4,4), strides = (2,2), padding = ‘same’, kernel_initializer = init) (e7) b = Активация (‘relu’) (b) # модель декодера d1 = decoder_block (b, e7, 512) d2 = decoder_block (d1, e6, 512) d3 = decoder_block (d2, e5, 512) d4 = decoder_block (d3, e4, 512, dropout = False) d5 = decoder_block (d4, e3, 256, dropout = False) d6 = decoder_block (d5, e2, 128, dropout = False) d7 = decoder_block (d6, e1, 64, dropout = False) # выход g = Conv2DTranspose (3, (4,4), strides = (2,2), padding = ‘same’, kernel_initializer = init) (d7) out_image = Активация (‘tanh’) (г) # определить модель model = Модель (in_image, out_image) модель возврата # определить комбинированную модель генератора и дискриминатора для обновления генератора def define_gan (g_model, d_model, image_shape): # сделать веса в дискриминаторе необучаемыми для слоя в d_model.слои: если не isinstance (слой, BatchNormalization): layer.trainable = Ложь # определяем исходное изображение in_src = Вход (shape = image_shape) # подключаем исходное изображение ко входу генератора gen_out = g_model (in_src) # подключаем вход источника и выход генератора ко входу дискриминатора dis_out = d_model ([in_src, gen_out]) # src image как вход, сгенерированное изображение и вывод классификации model = Модель (in_src, [dis_out, gen_out]) # скомпилировать модель opt = Адам (lr = 0.0002, beta_1 = 0,5) model.compile (loss = [‘binary_crossentropy’, ‘mae’], optimizer = opt, loss_weights = [1,100]) модель возврата # загрузить и подготовить обучающие изображения def load_real_samples (имя файла): # загружаем сжатые массивы данные = загрузка (имя файла) # распаковать массивы X1, X2 = данные [‘arr_0’], данные [‘arr_1’] # масштаб от [0,255] до [-1,1] X1 = (X1 — 127,5) / 127,5 Х2 = (Х2 — 127,5) / 127,5 return [X1, X2] # выбираем партию случайных выборок, возвращаем изображения и выбираем def generate_real_samples (набор данных, n_samples, patch_shape): # распаковать набор данных trainA, trainB = набор данных # выбираем случайные экземпляры ix = randint (0, trainA.форма [0], n_samples) # получить выбранные изображения X1, X2 = поезд A [ix], поезд B [ix] # генерировать «настоящие» метки классов (1) y = единицы ((n_samples, patch_shape, patch_shape, 1)) return [X1, X2], y # генерировать пакет изображений, возвращает изображения и цели def generate_fake_samples (g_model, samples, patch_shape): # создать поддельный экземпляр X = g_model.predict (образцы) # создать фальшивые метки классов (0) y = нули ((len (X), patch_shape, patch_shape, 1)) вернуть X, y # сгенерировать образцы и сохранить как график и сохранить модель def summarize_performance (шаг, g_model, набор данных, n_samples = 3): # выбираем образец входных изображений [X_realA, X_realB], _ = generate_real_samples (набор данных, n_samples, 1) # создать партию поддельных образцов X_fakeB, _ = generate_fake_samples (g_model, X_realA, 1) # масштабировать все пиксели от [-1,1] до [0,1] X_realA = (X_realA + 1) / 2.0 X_realB = (X_realB + 1) / 2.0 X_fakeB = (X_fakeB + 1) / 2.0 # построить реальные исходные изображения для i в диапазоне (n_samples): pyplot.subplot (3, n_samples, 1 + i) pyplot.axis (‘выключено’) pyplot.imshow (X_realA [i]) # сюжет сгенерировал целевое изображение для i в диапазоне (n_samples): pyplot.subplot (3, n_samples, 1 + n_samples + i) pyplot.axis (‘выключено’) pyplot.imshow (X_fakeB [i]) # построить реальное целевое изображение для i в диапазоне (n_samples): пиплот.подзаговор (3, n_samples, 1 + n_samples * 2 + i) pyplot.axis (‘выключено’) pyplot.imshow (X_realB [i]) # сохранить график в файл filename1 = ‘plot_% 06d.png’% (шаг + 1) pyplot.savefig (имя_файла1) pyplot.close () # сохраняем модель генератора filename2 = ‘model_% 06d.h5’% (шаг + 1) g_model.save (имя_файла2) print (‘> Сохранено:% s и% s’% (имя_файла1, имя_файла2)) # поезд модели pix2pix def train (d_model, g_model, gan_model, набор данных, n_epochs = 100, n_batch = 1): # определяем выходную квадратную форму дискриминатора n_patch = d_model.output_shape [1] # распаковать набор данных trainA, trainB = набор данных # подсчитываем количество пакетов за период обучения bat_per_epo = интервал (len (trainA) / n_batch) # рассчитываем количество итераций обучения n_steps = bat_per_epo * n_epochs # вручную перечислить эпохи для i в диапазоне (n_steps): # выбрать партию реальных образцов [X_realA, X_realB], y_real = generate_real_samples (набор данных, n_batch, n_patch) # создать партию поддельных образцов X_fakeB, y_fake = generate_fake_samples (g_model, X_realA, n_patch) # обновить дискриминатор для реальных образцов d_loss1 = d_model.train_on_batch ([X_realA, X_realB], y_real) # обновить дискриминатор для сгенерированных образцов d_loss2 = d_model.train_on_batch ([X_realA, X_fakeB], y_fake) # обновить генератор g_loss, _, _ = gan_model.train_on_batch (X_realA, [y_real, X_realB]) # подвести итоги print (‘>% d, d1 [%. 3f] d2 [%. 3f] g [%. 3f]’% (i + 1, d_loss1, d_loss2, g_loss)) # подвести итоги работы модели если (i + 1)% (bat_per_epo * 10) == 0: summarize_performance (я, g_model, набор данных) # загрузить данные изображения набор данных = load_real_samples (‘maps_256.нпз ‘) print (‘Загружено’, набор данных [0] .shape, набор данных [1] .shape) # определить форму ввода на основе загруженного набора данных image_shape = набор данных [0] .shape [1:] # определить модели d_model = define_discriminator (image_shape) g_model = define_generator (image_shape) # определить составную модель gan_model = define_gan (g_model, d_model, image_shape) # модель поезда поезд (d_model, g_model, gan_model, набор данных)
1 2 3 4 5 6 7 8 9 10 11 12 13 140002 14 18 19 20 21 22 23 24 25 26 27 28 29 30 000 000 34 35 36 37 38 39 40 41 42 43 44 45 46 48 00030002 47000351 52 53 54 55 56 57 58 59 60 61 62 63 9 0002 6465 66 67 68 69 70 71 72 73 74 75 76 77 81 82 83 84 85 86 87 88 89 90 91 92 93 000 93 000 97 98 99 100 101 102 103 104 105 106 107 108 109 1102 109 1102 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 13 136 137 1382 138 137 138 142 143 144 145 146 147 148 149 150 151 152 153 153 153 158 159 160 161 162 163 164 165 166 167 168 169 000 000 170002 1700009 175 176 177 178 179 180 181 182 183 9000 3 184 185 186 187 188 189 190 191 192 193 194 195 000 1 0003 0003 1 200201 202 203 204 205 206 207 208 209 210 211 212 0003 212 0003 211 212 0003 217 218 219 220 221 222 223 224 225 226 227 228 000 227 228 000 0003 228 000 0003 228 000 234 235 236 237 238 239 240 241 242 9 0003 243 244 | # пример pix2pix gan для спутника для преобразования изображения в изображение из numpy import load from numpy import zeros from numpy import ones from numpy.random import randint from keras.optimizers import Adam from keras.initializers import RandomNormal from keras.models import Model from keras.models import Input from keras.layers import Conv2D import from keras.layers Conv2DTranspose из keras.layers import LeakyReLU from keras.layers import Activation from keras.layers import Concatenate from keras.layers import Dropout from keras.Layers import BatchNormalization from keras.layers import LeakyReLU from matplotlib import pyplot # определить модель дискриминатора def define_discriminator (image_shape): # инициализация веса # исходное изображение input in_src_image = Input (shape = image_shape) # целевое изображение input in_target_image = Input (shape = image_shape) # объединять изображения по каналам merged = Concatenate, () in_target_image]) # C64 d = Conv2D (64, (4,4), strides = (2,2), padding = ‘same’, kernel_initializer = init) (объединено) d = LeakyReLU (alpha = 0.2) (d) # C128 d = Conv2D (128, (4,4), strides = (2,2), padding = ‘same’, kernel_initializer = init) (d) d = BatchNormalization ( ) (d) d = LeakyReLU (alpha = 0.2) (d) # C256 d = Conv2D (256, (4,4), strides = (2,2), padding = ‘same’, kernel_initializer = init) (d) d = BatchNormalization () (d) d = LeakyReLU (alpha = 0.2) (d) # C512 d = Conv2D (512, (4,4), шаги = ( 2,2), padding = ‘same’, kernel_initializer = init) (d) d = BatchNormalization () (d) d = LeakyReLU (alpha = 0.2) (d) # второй последний выходной слой d = Conv2D (512, (4,4), padding = ‘same’, kernel_initializer = init) (d) d = BatchNormalization () (d) d = LeakyReLU (alpha = 0.2) (d) # вывод патча d = Conv2D (1, (4,4), padding = ‘same’, kernel_initializer = init) (d) patch_out = Activation ( ‘sigmoid’) (d) # определить модель model = Model ([in_src_image, in_target_image], patch_out) # скомпилировать модель opt = Adam (lr = 0.0002, beta_1 = 0,5) model.compile (loss = ‘binary_crossentropy’, optimizer = opt, loss_weights = [0,5]) return model # определить блок кодировщика def define_encoder_block (layer_in, n_filters, batchnorm = True): # инициализация веса init = RandomNormal (stddev = 0,02) # добавить слой понижающей дискретизации g = Conv2D (n_filters, (4,4), strides = (2,2), padding = ‘same’, kernel_initializer = init) (layer_in) # условно добавить пакетную нормализацию , если batchnorm: g = BatchNormalization () (g, training = True) # активация утечки relu g = LeakyReLU (alpha = 0.2) (g) return g # определение блока декодера def decoder_block (layer_in, skip_in, n_filters, dropout = True): # инициализация веса init = RandomNormal (std0003 = 0,02) # добавить слой с повышающей дискретизацией g = Conv2DTranspose (n_filters, (4,4), strides = (2,2), padding = ‘same’, kernel_initializer = init) (layer_in) # добавить пакетную нормализацию g = BatchNormalization () (g, training = True) # условно добавить выпадение если выпадение: g = выпадение (0.5) (g, training = True) # слияние с пропуском соединения g = Concatenate () ([g, skip_in]) # повторная активация g = Activation (‘relu’) (g) return g # определение модели автономного генератора def define_generator (image_shape = (256,256,3)): # инициализация веса init = RandomNormal (stddev = 0.02) # image input in_image Ввод (shape = image_shape) # модель кодировщика e1 = define_encoder_block (in_image, 64, batchnorm = False) e2 = define_encoder_block (e1, 128) e3 = define_encoder_block2 9 = define_encoder_block4 (e2 (e3, 512) e5 = define_encoder_block (e4, 512) e6 = define_encoder_block (e5, 512) e7 = define_encoder_block (e6, 512) # узкое место, нет batch norm2D и relu (512, (4,4), шаги = (2,2), паддин g = ‘same’, kernel_initializer = init) (e7)b = Активация (‘relu’) (b) # модель декодера d1 = decoder_block (b, e7, 512) d2 = decoder_block (d1 , e6, 512) d3 = decoder_block (d2, e5, 512) d4 = decoder_block (d3, e4, 512, dropout = False) d5 = decoder_block (d4, e3, 256, dropout = False) d6 = decoder_block (d5, e2, 128, dropout = False) d7 = decoder_block (d6, e1, 64, dropout = False) # output g = Conv2DTranspose (3, (4,4), шаги = (2,2), padding = ‘same’, kernel_initializer = init) (d7) out_image = Activation (‘tanh’) (g) # определить модель model = Model (in_image, out_image) return model # определить комбинированную модель генератора и дискриминатора, для обновления генератора def define_gan (g_model, d_model, image_shape): # сделать веса в дискриминаторе не обучать в состоянии для слоя в d_model.Layers: if not isinstance (layer, BatchNormalization): layer.trainable = False # определить исходное изображение in_src = Input (shape = image_shape) # подключить исходное изображение ко входу генератора gen_out = g_model (in_src) # подключите вход источника и выход генератора к входу дискриминатора dis_out = d_model ([in_src, gen_out]) # src изображение в качестве входа, сгенерированное изображение и выход классификации model = Model (in_src, [dis_out, gen_out]) # скомпилировать модель opt = Adam (lr = 0.0002, beta_1 = 0,5) model.compile (loss = [‘binary_crossentropy’, ‘mae’], optimizer = opt, loss_weights = [1,100]) return model # загрузить и подготовить обучающие изображения def load_real_samples (filename): # загрузить сжатые массивы data = load (filename) # распаковать массивы X1, X2 = data [‘arr_0’], data [‘arr_1’] # масштаб от [ 0,255] до [-1,1] X1 = (X1 — 127,5) / 127,5 X2 = (X2 — 127.5) / 127,5 return [X1, X2] # выбор пакета случайных выборок, возврат изображений и цель def generate_real_samples (dataset, n_samples, patch_shape): # unpack dataset trainA = набор данных # выбрать случайные экземпляры ix = randint (0, trainA.shape [0], n_samples) # получить выбранные изображения X1, X2 = trainA [ix], trainB [ix] # сгенерировать ‘реальные’ метки класса (1) y = единицы ((n_samples, patch_shape, patch_shape, 1)) return [X1, X2], y # генерировать пакет изображений, возвращает изображения и цели def generate_fake_samples (g_model, samples, patch_shape): # генерировать поддельный экземпляр X = g_model.предсказать (образцы) # создать ‘поддельные’ метки классов (0) y = нули ((len (X), patch_shape, patch_shape, 1)) return X, y # создать образцы и сохранить как график и сохраните модель def summarize_performance (step, g_model, dataset, n_samples = 3): # выберите образец входных изображений [X_realA, X_realB], _ = generate_real_samples (dataset, n_samples, 1) # создать пакет поддельных образцов X_fakeB, _ = generate_fake_samples (g_model, X_realA, 1) # масштабировать все пиксели от [-1,1] до [0,1] X_realA = (X_realA + 1 ) / 2.0 X_realB = (X_realB + 1) / 2.0 X_fakeB = (X_fakeB + 1) / 2.0 # построить реальные исходные изображения для i в диапазоне (n_samples): pyplot.subplot (3, n_samples, 1 + i) pyplot.axis (‘off’) pyplot.imshow (X_realA [i]) # plot сгенерированное целевое изображение для i в диапазоне (n_samples): pyplot.subplot (3, n_samples, 1 + n_samples + i) pyplot.axis (‘off’) pyplot.imshow (X_fakeB [i]) # построить реальное целевое изображение для i в диапазоне (n_samples): pyplot.subplot (3, n_samples, 1 + n_samples * 2 + i) pyplot.axis (‘off ‘) pyplot.imshow (X_realB [i]) # сохранить график в файл filename1 =’ plot_% 06d.png ‘% (step + 1) pyplot.savefig (filename1) pyplot.close () # сохранить модель генератора filename2 = ‘model_% 06d.h5’% (step + 1) g_model.save (filename2) print (‘> Сохранено:% s и% s’% (filename1, filename2)) # train pix2pix models def train (d_model, g_model, gan_model, dataset, n_epochs = 100, n_batch = 1): # определить выходную квадратную форму дискриминатора n_patch = d_model.output_shape [1] # распаковать набор данных trainA, trainB = dataset # вычислить количество пакетов за период обучения bat_per_epo = int (len (trainA) / n_batch) # вычислить количество обучающих итераций n_steps = bat_per_epo * n_epochs # вручную перечислить эпохи для i in range (n_3000 batch): # 9000 batch реальных образцов [X_realA, X_realB], y_real = generate_real_samples (dataset, n_batch, n_patch) # сгенерировать партию поддельных образцов X_fakeB, y_fake = generate_fake_samples (g_model_ 9_real) 0002 # обновить дискриминатор для реальных отсчетов d_loss1 = d_model.train_on_batch ([X_realA, X_realB], y_real) # обновить дискриминатор для сгенерированных выборок d_loss2 = d_model.train_on_batch ([X_realA, X_fakeB], y_fake) # обновить генератор 9_dellossan, train_on_batch (X_realA, [y_real, X_realB])# суммируем производительность print (‘>% d, d1 [%. 3f] d2 [%. 3f] g [%. 3f]’% (i + 1, d_loss1 , d_loss2, g_loss)) # суммировать производительность модели if (i + 1)% (bat_per_epo * 10) == 0: summarize_performance (i, g_model, dataset) # загрузить данные изображения набор данных = load_real_samples (‘maps_256.npz ‘)print (‘ Loaded ‘, dataset [0] .shape, dataset [1] .shape) # определить входную форму на основе загруженного набора данных image_shape = dataset [0] .shape [1:] # определить модели d_model = define_discriminator (image_shape) g_model = define_generator (image_shape) # определить составную модель gan_model = define_gan (g_model d_model, train_model, train_model, train_model) d_model, g_model, gan_model, набор данных) |
Пример можно запустить на аппаратном обеспечении ЦП, хотя рекомендуется аппаратное обеспечение ГП.
Пример может занять около двух часов на современном оборудовании с графическим процессором.
Примечание : Ваши результаты могут отличаться из-за стохастической природы алгоритма или процедуры оценки или различий в числовой точности. Вы можете повторить пример несколько раз и сравнить средний результат.
Сообщается о потерях на каждой итерации обучения, включая потерю дискриминатора на реальных примерах (d1), потерю дискриминатора на сгенерированных или поддельных примерах (d2) и потерю генератора, которая представляет собой средневзвешенное значение состязательных и L1 потерь (g).
Если потери дискриминатора стремятся к нулю и остаются там в течение длительного времени, рассмотрите возможность повторного запуска обучающего прогона, поскольку это пример ошибки обучения.
> 1, d1 [0,566] d2 [0,520] г [82,266] > 2, d1 [0,469] d2 [0,484] г [66,813] > 3, d1 [0,428] d2 [0,477] г [79,520] > 4, d1 [0,362] d2 [0,405] г [78,143] > 5, d1 [0,416] d2 [0,406] г [72,452] … > 109596, d1 [0,303] d2 [0,006] г [5,792] > 109597, d1 [0,001] d2 [1,127] g [14.343] > 109598, d1 [0,000] d2 [0,381] г [11,851] > 109599, d1 [1,289] d2 [0,547] г [6,901] > 109600, d1 [0,437] d2 [0,005] г [10,460] > Сохранено: plot_109600.png и model_109600.h5
> 1, d1 [0,566] d2 [0,520] г [82,266] > 2, d1 [0,469] d2 [0,484] г [66,813] > 3, d1 [0,428] d2 [0,477] г [79,520 ] > 4, d1 [0,362] d2 [0,405] г [78,143] > 5, d1 [0,416] d2 [0,406] г [72.452] … > 109596, d1 [0,303] d2 [0,006] г [5,792] > 109597, d1 [0,001] d2 [1,127] г [14,343] > 109598, d1 [0,000] d2 [0,381] г [11,851] > 109599, d1 [1,289] d2 [0,547] г [6,901] > 109600, d1 [0,437] d2 [0,005] г [10.460] > Сохранено: plot_109600.png и модель_109600.h5 |
Модели сохраняются каждые 10 эпох и сохраняются в файл с номером итерации обучения. Кроме того, изображения генерируются каждые 10 эпох и сравниваются с ожидаемыми целевыми изображениями.Эти графики можно оценить в конце прогона и использовать для выбора окончательной модели генератора на основе качества сгенерированного изображения.
В конце прогона у вас будет 10 сохраненных файлов модели и 10 графиков сгенерированных изображений.
После первых 10 эпох создаются изображения карты, которые выглядят правдоподобно, хотя линии улиц не совсем прямые, а изображения содержат некоторое размытие. Тем не менее, большие конструкции находятся в нужных местах и в большинстве случаев окрашены в нужные цвета.
График спутника на карту Google, переведенные изображения с помощью Pix2Pix после 10 эпох обучения
Изображения, сгенерированные примерно после 50 периодов обучения, начинают выглядеть очень реалистично, по крайней мере, в смысле, а качество остается хорошим до конца тренировочного процесса.
Обратите внимание на первый пример сгенерированного изображения ниже (правый столбец, средняя строка), который содержит больше полезных деталей, чем реальное изображение карты Google.
График спутника на карту Google, переведенные изображения с помощью Pix2Pix после 100 эпох обучения
Теперь, когда мы разработали и обучили модель Pix2Pix, мы можем изучить, как их можно использовать автономно.
Как переводить изображения с помощью Pix2Pix Model
Обучение модели Pix2Pix приводит к созданию множества сохраненных моделей и образцов сгенерированных изображений для каждой из них.
Больше эпох обучения не обязательно означает более качественную модель. Следовательно, мы можем выбрать модель на основе качества сгенерированных изображений и использовать ее для выполнения специального преобразования изображения в изображение.
В этом случае мы будем использовать модель, сохраненную в конце прогона, например после 100 эпох или 109 600 повторений обучения.
Хорошей отправной точкой является загрузка модели и использование ее для специальных переводов исходных изображений в обучающем наборе данных.
Сначала мы можем загрузить набор обучающих данных. Мы можем использовать ту же функцию с именем load_real_samples () для загрузки набора данных, которая использовалась при обучении модели.
# загрузить и подготовить обучающие изображения def load_real_samples (имя файла): # загрузить сжатые файлы данные = загрузка (имя файла) # распаковать массивы X1, X2 = данные [‘arr_0’], данные [‘arr_1’] # масштаб от [0,255] до [-1,1] Х1 = (Х1 — 127.5) / 127,5 Х2 = (Х2 — 127,5) / 127,5 возврат [X1, X2]
# загрузить и подготовить обучающие изображения def load_real_samples (filename): # загрузить сжатые файлы data = load (filename) # распаковать массивы X1, X2 = data [‘arr_0’], data [ ‘arr_1’] # масштаб от [0,255] до [-1,1] X1 = (X1 — 127,5) / 127,5 X2 = (X2 — 127,5) / 127.5 возврат [X1, X2] |
Эту функцию можно вызвать следующим образом:
… # загрузить набор данных [X1, X2] = load_real_samples (‘maps_256.npz’) print (‘Загружено’, X1.shape, X2.shape)
… # загрузить набор данных [X1, X2] = load_real_samples (‘maps_256.npz’) print (‘Loaded’, X1.shape, X2.shape) |
Затем мы можем загрузить сохраненную модель Keras.
… # модель нагрузки модель = load_model (‘модель_109600.h5’)
… # загрузить модель model = load_model (‘model_109600.h5’) |
Затем мы можем выбрать случайную пару изображений из набора обучающих данных для использования в качестве примера.
… # выбрать случайный пример ix = randint (0, len (X1), 1) src_image, tar_image = X1 [ix], X2 [ix]
… # выбрать случайный пример ix = randint (0, len (X1), 1) src_image, tar_image = X1 [ix], X2 [ix] |
Мы можем предоставить исходное спутниковое изображение в качестве входных данных для модели и использовать его для прогнозирования изображения карты Google.
… # генерировать изображение из источника gen_image = model.predict (src_image)
… # генерировать изображение из источника gen_image = model.предсказать (src_image) |
Наконец, мы можем построить исходное, сгенерированное изображение и ожидаемое целевое изображение.
Функция plot_images () ниже реализует это, обеспечивая красивый заголовок над каждым изображением.
# сюжетное исходное, сгенерированное и целевое изображения def plot_images (src_img, gen_img, tar_img): images = vstack ((src_img, gen_img, tar_img)) # масштаб от [-1,1] до [0,1] изображения = (изображения + 1) / 2.0 title = [‘Источник’, ‘Создано’, ‘Ожидается’] # строить изображения построчно для i в диапазоне (len (изображения)): # определить подзаговор pyplot.subplot (1, 3, 1 + я) # выключить ось pyplot.axis (‘выключено’) # построить необработанные данные пикселей pyplot.imshow (изображения [i]) # показать заголовок pyplot.title (заголовки [i]) pyplot.show ()
1 2 3 4 5 6 7 8 9 10 11 12 13 140002 14 | # источник графика, сгенерированные и целевые изображения def plot_images (src_img, gen_img, tar_img): images = vstack ((src_img, gen_img, tar_img)) # масштаб от [-1,1] до [0 , 1] изображений = (images + 1) / 2.0 title = [‘Source’, ‘Generated’, ‘Expected’] # построчно построить изображения для i в диапазоне (len (images)): # определить подзаголовок pyplot.subplot ( 1, 3, 1 + i) # выключить ось pyplot.axis (‘off’) # построить необработанные данные пикселей pyplot.imshow (images [i]) # показать заголовок pyplot .title (заголовки [i]) pyplot.show () |
Эту функцию можно вызывать с каждым из наших исходных, сгенерированных и целевых изображений.
… # построить все три изображения plot_images (src_image, gen_image, tar_image)
… # построить все три изображения plot_images (src_image, gen_image, tar_image) |
Объединяя все это вместе, ниже приведен полный пример выполнения специального преобразования изображения в изображение с примером из набора обучающих данных.
# пример загрузки модели pix2pix и ее использования для преобразования изображения в изображение из кераса.модели импортировать load_model от нагрузки импорта numpy из numpy import vstack из matplotlib import pyplot из numpy.random import randint # загрузить и подготовить обучающие изображения def load_real_samples (имя файла): # загружаем сжатые массивы данные = загрузка (имя файла) # распаковать массивы X1, X2 = данные [‘arr_0’], данные [‘arr_1’] # масштаб от [0,255] до [-1,1] X1 = (X1 — 127,5) / 127,5 Х2 = (Х2 — 127,5) / 127,5 return [X1, X2] # сюжетное исходное, сгенерированное и целевое изображения def plot_images (src_img, gen_img, tar_img): images = vstack ((src_img, gen_img, tar_img)) # масштаб от [-1,1] до [0,1] изображения = (изображения + 1) / 2.0 title = [‘Источник’, ‘Создано’, ‘Ожидается’] # строить изображения построчно для i в диапазоне (len (изображения)): # определить подзаговор pyplot.subplot (1, 3, 1 + я) # выключить ось pyplot.axis (‘выключено’) # построить необработанные данные пикселей pyplot.imshow (изображения [i]) # показать заголовок pyplot.title (заголовки [i]) pyplot.show () # загрузить набор данных [X1, X2] = load_real_samples (‘maps_256.npz’) print (‘Загружено’, X1.shape, X2.shape) # модель нагрузки model = load_model (‘модель_109600.h5 ‘) # выбрать случайный пример ix = randint (0, len (X1), 1) src_image, tar_image = X1 [ix], X2 [ix] # генерировать изображение из источника gen_image = model.predict (src_image) # построить все три изображения plot_images (src_image, gen_image, tar_image)
1 2 3 4 5 6 7 8 9 10 11 12 13 140002 14 18 19 20 21 22 23 24 25 26 27 28 29 30 000 3435 36 37 38 39 40 41 42 43 44 45 46 47 | # пример загрузки модели pix2pix и ее использования для преобразования изображения в изображение из keras.models import load_model from numpy import load from numpy import vstack from matplotlib import pyplot from numpy.random import randint # загрузить и подготовить обучающие изображения def load_real_samples (# имя_файла загрузить сжатые массивы data = load (filename) # распаковать массивы X1, X2 = data [‘arr_0’], data [‘arr_1’] # масштабировать от [0,255] до [-1,1] X1 = (X1 — 127.5) / 127,5 X2 = (X2 — 127,5) / 127,5 return [X1, X2] # источник графика, сгенерированные и целевые изображения def plot_images (src_img, gen_img, tar_img): изображений = vstack ((src_img, gen_img, tar_img)) # масштаб от [-1,1] до [0,1] изображений = (images + 1) / 2,0 заголовков = [‘Источник’, ‘Создано ‘,’ Expected ‘] # построчно строить изображения для i in range (len (images)): # определять подзаголовок pyplot.subplot (1, 3, 1 + i) # выключить ось pyplot.axis (‘off’) # построить необработанные данные пикселей pyplot.imshow (images [i]) # показать заголовок pyplot.title (title [i]) pyplot.show () # загрузить набор данных [X1, X2] = load_real_samples (‘maps_256.npz’) print (‘Loaded’, X1. shape, X2.shape) # загрузить модель model = load_model (‘model_109600.h5’) # выбрать случайный пример ix = randint (0, len (X1), 1) src_image, tar_image = X1 [ix], X2 [ix] # генерировать изображение из источника gen_image = model.pred (src_image) # построить все три изображения plot_images (src_image, gen_image, tar_image) |
При выполнении примера будет выбрано случайное изображение из набора обучающих данных, оно переведено на карту Google и построено сравнение результата с ожидаемым изображением.
Примечание : Ваши результаты могут отличаться из-за стохастической природы алгоритма или процедуры оценки или различий в числовой точности. Вы можете повторить пример несколько раз и сравнить средний результат.
В этом случае мы видим, что сгенерированное изображение захватывает большие дороги с оранжевым и желтым цветом, а также зеленые парковые зоны. Созданное изображение не идеально, но очень близко к ожидаемому.
График спутника для преобразования изображения карты Google с помощью окончательной модели Pix2Pix GAN
Мы также можем использовать модель для перевода данного автономного изображения.
Мы можем выбрать изображение из набора данных проверки в разделе maps / val и обрезать спутниковый элемент изображения.Затем его можно сохранить и использовать в качестве входных данных для модели.
В этом случае мы будем использовать « maps / val / 1.jpg ».
Пример изображения из части проверки набора данных Maps
Мы можем использовать программу обработки изображений, чтобы создать грубую обрезку спутникового элемента этого изображения для использования в качестве входных данных и сохранить файл как satellite.jpg в текущем рабочем каталоге.
Пример обрезанного спутникового изображения для использования в качестве входных данных для модели Pix2Pix.
Мы должны загрузить изображение как массив пикселей NumPy размером 256 × 256, изменить масштаб значений пикселей до диапазона [-1,1], а затем расширить размеры одного изображения, чтобы представить один входной образец.
Функция load_image () ниже реализует это, возвращая пиксели изображения, которые могут быть предоставлены непосредственно загруженной модели Pix2Pix.
# загрузить изображение def load_image (имя файла, размер = (256,256)): # загрузить изображение желаемого размера пикселей = load_img (имя файла, target_size = размер) # преобразовать в массив numpy пикселей = img_to_array (пиксели) # масштаб от [0,255] до [-1,1] пикселей = (пикселей — 127,5) / 127,5 # изменить форму до 1 образца пикселей = expand_dims (пикселей, 0) возврат пикселей
# загрузить изображение def load_image (filename, size = (256,256)): # загрузить изображение с предпочтительным размером пикселей = load_img (filename, target_size = size) # преобразовать в массив numpy пикселей = img_to_array (пикселей) # масштаб от [0,255] до [-1,1] пикселей = (пикселей — 127.5) / 127,5 # изменить форму до 1 образца пикселей = expand_dims (пикселей, 0) вернуть пиксели |
Затем мы можем загрузить наш обрезанный спутниковый снимок.
… # загрузить исходное изображение src_image = load_image (‘satellite.jpg’) print (‘Загружено’, src_image.shape)
… # загрузить исходное изображение src_image = load_image (‘satellite.jpg ‘) print (‘ Загружено ‘, src_image.shape) |
Как и раньше, мы можем загрузить нашу сохраненную модель генератора Pix2Pix и сгенерировать перевод загруженного изображения.
… # модель нагрузки модель = load_model (‘модель_109600.h5’) # генерировать изображение из источника gen_image = model.predict (src_image)
… # загрузить модель model = load_model (‘model_109600.h5 ‘) # генерировать изображение из источника gen_image = model.predict (src_image) |
Наконец, мы можем снова масштабировать значения пикселей до диапазона [0,1] и построить график результата.
… # масштаб от [-1,1] до [0,1] gen_image = (gen_image + 1) / 2.0 # построить изображение pyplot.imshow (gen_image [0]) pyplot.axis (‘выключено’) pyplot.show ()
… # масштаб от [-1,1] до [0,1] gen_image = (gen_image + 1) / 2.0 # построить изображение pyplot.imshow (gen_image [0]) pyplot .axis (‘выкл.’) pyplot.show () |
Если связать все это вместе, ниже приведен полный пример выполнения специального перевода изображения с одним файлом изображения.
# пример загрузки модели pix2pix и использования ее для одноразового перевода изображений из кераса.модели импортировать load_model из keras.preprocessing.image import img_to_array из keras.preprocessing.image import load_img от нагрузки импорта numpy из numpy import expand_dims из matplotlib import pyplot # загрузить изображение def load_image (имя файла, размер = (256,256)): # загрузить изображение желаемого размера пикселей = load_img (имя файла, target_size = размер) # преобразовать в массив numpy пикселей = img_to_array (пиксели) # масштаб от [0,255] до [-1,1] пикселей = (пикселей — 127.5) / 127,5 # изменить форму до 1 образца пикселей = expand_dims (пикселей, 0) вернуть пиксели # загрузить исходное изображение src_image = load_image (‘satellite.jpg’) print (‘Загружен’, src_image.shape) # модель нагрузки модель = load_model (‘модель_109600.h5’) # генерировать изображение из источника gen_image = model.predict (src_image) # масштаб от [-1,1] до [0,1] gen_image = (gen_image + 1) / 2.0 # построить изображение pyplot.imshow (gen_image [0]) pyplot.axis (‘выключено’) пиплот.показать ()
1 2 3 4 5 6 7 8 9 10 11 12 13 140002 14 18 19 20 21 22 23 24 25 26 27 28 29 30 0003 | # пример загрузки модели pix2pix и использования ее для одноразовой трансляции изображений из keras.модели import load_model from keras.preprocessing.image import img_to_array from keras.preprocessing.image import load_img from numpy import load from numpy import expand_dims 000 из matplot 000 pyplot def load_image (filename, size = (256,256)): # загрузить изображение с предпочтительным размером пикселей = load_img (filename, target_size = size) # преобразовать в массив numpy пикселей = img_to_array (пикселей) # масштаб от [0,255] до [-1,1] пикселей = (пикселей — 127.5) / 127,5 # изменить форму до 1 образца пикселей = expand_dims (пикселей, 0) вернуть пиксели # загрузить исходное изображение src_image = load_image (‘satellite.jpg’) print (‘ Loaded ‘, src_image.shape) # загрузить модель model = load_model (‘ model_109600.h5 ‘) # создать изображение из источника gen_image = model.predict (src_image) # масштаб от [-1, 1] до [0,1] gen_image = (gen_image + 1) / 2.0 # построить изображение pyplot.imshow (gen_image [0]) pyplot.axis (‘off’) pyplot.show () |
При выполнении примера загружается изображение из файла, создается его перевод и отображается результат.
Созданное изображение является разумным переводом исходного изображения.
Улицы не выглядят прямыми, а детали зданий немного нечеткие. Возможно, при дальнейшем обучении или выборе другой модели можно будет создавать изображения более высокого качества.
Участок спутникового изображения, переведенный на карты Google с помощью окончательной модели Pix2Pix GAN
Как перевести карты Google на спутниковые изображения
Теперь, когда мы знакомы с тем, как разработать и использовать модель Pix2Pix для перевода спутниковых изображений на карты Google, мы можем также изучить обратное.
То есть мы можем разработать модель Pix2Pix для преобразования изображений карты Google в правдоподобные спутниковые изображения. Для этого требуется, чтобы модель изобрела или представила себе правдоподобные здания, дороги, парки и многое другое.
Мы можем использовать один и тот же код для обучения модели с одной небольшой разницей. Мы можем изменить порядок наборов данных, возвращаемых функцией load_real_samples () ; например:
# загрузить и подготовить обучающие изображения def load_real_samples (имя файла): # загружаем сжатые массивы данные = загрузка (имя файла) # распаковать массивы X1, X2 = данные [‘arr_0’], данные [‘arr_1’] # масштаб от [0,255] до [-1,1] X1 = (X1 — 127,5) / 127,5 Х2 = (Х2 — 127.5) / 127,5 # возврат в обратном порядке возврат [X2, X1]
# загрузить и подготовить обучающие изображения def load_real_samples (filename): # загрузить сжатые массивы data = load (filename) # распаковать массивы X1, X2 = data [‘arr_0’], data [ ‘arr_1’] # масштаб от [0,255] до [-1,1] X1 = (X1 — 127,5) / 127,5 X2 = (X2 — 127,5) / 127.5 # возврат в обратном порядке возврат [X2, X1] |
Примечание : порядок X1 и X2 обратный.
Это означает, что модель будет принимать изображения карты Google в качестве входных данных и учиться генерировать спутниковые изображения.
Запустите пример, как раньше.
Примечание : Ваши результаты могут отличаться из-за стохастической природы алгоритма или процедуры оценки или различий в числовой точности. Вы можете повторить пример несколько раз и сравнить средний результат.
Как и раньше, о потере модели сообщается на каждой итерации обучения. Если потери дискриминатора стремятся к нулю и остаются на этом уровне в течение длительного времени, рассмотрите возможность повторного запуска обучающего прогона, поскольку это пример сбоя обучения.
> 1, d1 [0,442] d2 [0,650] г [49,790] > 2, d1 [0,317] d2 [0,478] г [56,476] > 3, d1 [0,376] d2 [0,450] г [48,114] > 4, d1 [0,396] d2 [0,406] г [62,903] > 5, d1 [0,496] d2 [0,460] г [40,650] … > 109596, d1 [0.311] d2 [0,057] г [25,376] > 109597, d1 [0,028] d2 [0,070] г [16,618] > 109598, d1 [0,007] d2 [0,208] г [18,139] > 109599, d1 [0,358] d2 [0,076] г [22,494] > 109600, d1 [0,279] d2 [0,049] г [9,941] > Сохранено: plot_109600.png и model_109600.h5
> 1, d1 [0,442] d2 [0,650] г [49,790] > 2, d1 [0,317] d2 [0,478] г [56,476] > 3, d1 [0,376] d2 [0,450] г [48,114 ] > 4, d1 [0.396] d2 [0,406] г [62,903] > 5, d1 [0,496] d2 [0,460] г [40,650] … > 109596, d1 [0,311] d2 [0,057] г [25,376] > 109597, d1 [0,028] d2 [0,070] г [16,618] > 109598, d1 [0,007] d2 [0,208] г [18,139] > 109599, d1 [0,358] d2 [0,076] г [22,494] > 109600, d1 [0,279] d2 [0,049] g [9,941] > Сохранено: plot_109600.png и model_109600.h5 |
Сложнее судить о качестве сгенерированных спутниковых изображений, тем не менее, правдоподобные изображения создаются всего через 10 эпох.
График карты Google Map со спутниковым переводом изображений с помощью Pix2Pix после 10 эпох обучения
Как и раньше, качество изображения улучшится и будет изменяться в процессе обучения. Окончательная модель может быть выбрана на основе качества сгенерированного изображения, а не общего количества эпох обучения.
Модель не представляет особых трудностей в создании разумных водных ресурсов, парков, дорог и т. Д.
График карты Google Map со спутниковым переводом изображений с помощью Pix2Pix после 90 эпох обучения
Расширения
В этом разделе перечислены некоторые идеи по расширению учебника, которые вы, возможно, захотите изучить.
- Автономный спутник . Разработайте пример перевода автономных изображений карт Google в спутниковые изображения, как мы сделали для спутниковых изображений в карты Google.
- Новый образ . Найдите спутниковый снимок совершенно нового места, переведите его на карту Google и сравните результат с реальным изображением на картах Google.
- Дополнительная подготовка . Продолжите обучение модели еще на 100 эпох и оцените, приведет ли дополнительное обучение к дальнейшему улучшению качества изображения.
- Увеличение изображения . Используйте небольшое увеличение изображения во время обучения, как описано в статье Pix2Pix, и оцените, приводит ли это к лучшему качеству сгенерированных изображений.
Если вы изучите какое-либо из этих расширений, я хотел бы знать.
Разместите свои выводы в комментариях ниже.
Дополнительная литература
В этом разделе представлены дополнительные ресурсы по теме, если вы хотите углубиться.
Официальный
API
Сводка
В этом руководстве вы узнали, как разработать генерирующую состязательную сеть Pix2Pix для преобразования изображения в изображение.
В частности, вы выучили:
- Как загрузить и подготовить спутниковое изображение в набор данных преобразования изображения в изображение карт Google.
- Как разработать модель Pix2Pix для перевода спутниковых снимков в изображения карты Google.
- Как использовать окончательную модель генератора Pix2Pix для перевода специальных спутниковых изображений.
Есть вопросы?
Задайте свои вопросы в комментариях ниже, и я постараюсь ответить.
Развивайте генерирующие состязательные сети уже сегодня!
Разрабатывайте модели GAN за считанные минуты
…с всего несколькими строками кода Python Узнайте, как это сделать в моей новой электронной книге:
Генеративные состязательные сети с Python
Он предоставляет учебные пособия для самообучения и сквозные проекты на:
DCGAN , условные GAN , перевод изображений , Pix2Pix , CycleGAN
и многое другое …
Наконец-то привнесите модели GAN в свои проекты Vision
Пропустить академики. Только результаты.Посмотрите, что внутриAmazon.com: Устройство мгновенного двустороннего языкового переводчика Langogo Summit, карманный переводчик в реальном времени с Bluetooth, голосовой переводчик на 104 языка, встроенные данные, 4,0-дюймовый дисплей с переводом фотографий, серый: офисные продукты
Я изучал различные устройства языкового переводчика последние три года, пытаясь выбрать лучшее. Я решил, что это устройство Langogo Summit. У него было несколько особенностей по сравнению с конкурентами, которые сделали его привлекательной покупкой.Мне также потребовалось некоторое время, чтобы решить, потому что это один из самых дорогих переводчиков.Я купил Summit по нескольким причинам. Мне нужно было устройство, которое было бы ориентировано не только на языковой перевод, но и на повышение производительности.
Это устройство имеет несколько функций языкового перевода:
Интересные особенности
1 — Простой перевод: Я кое-что говорю. Summit переводит на выбранный вами язык. Другой человек говорит. Summit переведите обратно на ваш родной язык.Это отлично подходит для коротких вопросов-ответов. Или предположим, что вы гуляете по городу и ходите по магазинам и вам нужен маршрут, или у вас есть вопросы о товарах, маршрутах или еде. Это то, на что способны большинство языковых переводчиков, но Summit идет немного дальше.
2 — Режим переводчика: это функция, которая меня больше всего интересовала, поскольку я предполагал использовать ее для разговоров, как личных, так и деловых. Вы выбираете язык, на который хотите перевести, и кладете Summit Pro на ровную поверхность между обоими динамиками.Summit Pro теперь улавливает оба голоса, используя массив из 4 микрофонов, и переводит в реальном времени на разговорный язык. Оба человека могут читать текст на Саммите, и он обращен к обоим людям. Чтобы пойти дальше, вы можете подключить наушники bluetooh (вам понадобятся отдельные наушники, так как вы не можете использовать подключенные наушники или проводные наушники, если вы не находитесь буквально лицом к лицу), а затем Summit Pro будет говорить на переведенном языке на ухо говорящего.
3 — Перевод речи: вы можете использовать эту функцию во время собрания или лекции, когда вы просто слушаете говорящего.Например, я носитель английского языка. Если бы я посещал лекцию, проводимую на другом языке, я могу настроить свой Langogo Summit на этот язык, и он переведет лекцию на английский.
4 — Интеллектуальная запись: Langogo не предоставляет бесплатные данные, как другие популярные устройства языкового переводчика, но есть возможность приобрести данные или использовать свою собственную SIM-карту. Что Langogo действительно дает вам, так это подписку на Notta.ai на 1 год. Это чрезвычайно полезно при записи встречи или лекции.По окончании лекции Langogo предложит расшифровать все записанное содержание для ваших заметок. У вас также есть возможность перевести текст на другой язык.
Дополнительные возможности:
5 — Перевод фотографий: Summit оснащен камерой, так что вы можете делать снимки знаков, документов и любого текста, с которым вы сталкиваетесь. Он переведет текст на выбранный вами язык. Это не очень быстро, но исправно. Есть приложения для смартфонов, которые работают намного быстрее, но это хорошее дополнение для этого устройства.
6 — Замечания по идее: есть функция быстрой записи, и вы можете назначить боковую кнопку для этой функции или перевода. Обычно, если у вас возникает идея на лету, вы можете сказать себе короткую записку. Summit Pro превратит его в короткую заметку с флажком вместе с записью голоса. Затем это отобразится на главном экране для немедленных действий. Я перечисляю это как дополнительную функцию, а не как убедительную, поскольку Summit Pro в первую очередь является языковым переводчиком, а не средством записи заметок, но на самом деле это одна из моих любимых функций.
7 — Тарифный план e-SIM: И последнее, но не менее важное, это проблемный тарифный план e-SIM. Это одна из функций, на которую я очень надеялся. На этом устройстве есть Wi-Fi. Я могу использовать функцию точки доступа на моем телефоне, чтобы передавать данные Summit Pro. Это нормально, но я не всегда ожидаю добавления данных на свой телефон во время заграничных поездок. Я хотел, чтобы Summit Pro работал независимо от моего телефона. Существует возможность вставить SIM-карту, которую вы можете приобрести сразу после приземления в пункте назначения.Это тоже нормально. Я снова представил себе, как использовать это независимо, где бы я ни был, как дома, так и за границей. Я купил тарифный план на передачу данных, но он не сработал. Я написал в службу поддержки Langogo вместе со снимком экрана с тарифным планом, который я приобрел на устройстве. Я отправил этот запрос о помощи 31 мая 2021 года. Я выполнил их инструкции и все еще не могу заставить работать тарифный план электронной SIM-карты. Они говорят, что их техники работают над этим, и они свяжутся со мной. Это после того, как было отправлено несколько писем с вопросом о статусе.На сегодняшний день, 5 июня 2021 года, у меня все еще нет разрешения. Я думал вернуть это устройство, но плюсы перевешивают этот большой минус. Мне придется решить использовать точку доступа на моем телефоне или приобрести карту данных во время путешествия. Я не доволен этим, но служба поддержки Langogo не предоставила решения.
Разное:
a) Возможно, это устройство еще слишком новое или недостаточно популярное, но доступных аксессуаров не так много. Я заказал защитные пленки для этого устройства, но просто знаю, что они предоставляют две защитные пленки в коробке, одна из которых уже установлена, вам нужно только снять верхнюю часть позже.
b) Нет доступных для покупки чехлов для защиты. Он очень добротный, имеет сенсорную пластиковую заднюю часть и металлические стороны. Это здоровенное устройство, которое я ценю, но было бы неплохо иметь чехол.
***** Я предоставлю обновленную информацию, если услышу ответ или предложу решение.
15 июня 2021 г.
Langogo не смог решить мою проблему с электронной SIM-картой. После недели взад и вперед, включая и выключая устройство, я не мог заставить его работать. Каким-то чудом я проснулся однажды утром, и это работало около двух минут, а затем прекратилось.Ничего не сделал, снова заработал. Я заменил его на новое устройство Summit, и оно тоже не могло работать.
Я решил оставить это устройство, несмотря на эту очень неприятную проблему. Остальные особенности были убедительными. Я купил кольцо iRing, чтобы оно всегда держалось в руке. Я действительно разочарован тем, что встроенная электронная SIM-карта не работает, но надеюсь, что сторонняя SIM-карта будет работать. Помните, что в этом устройстве также есть лоток для SIM-карт. Я действительно просто хотел избежать этого.
Я обновлю, когда получу SIM-карту для передачи данных на пробу.
pris en photo — Перевод на английский — примеры французский
Предложения: Prendre en фотоЭти примеры могут содержать грубые слова, основанные на вашем поиске.
Эти примеры могут содержать разговорные слова, основанные на вашем поиске.
Участники, снятые на пленку, и , предоставлены на фото во время конкурса.
Всадников будут снимать на видео и сфотографировать во время соревнований.Il n’aime toujours pas être , фото .
C’est pourquoi mon chauffeur les a pris en photo .
Фотография , фотография un sénateur soi-disant en train de bâiller.
Фотограф сделал снимок уважаемого сенатора, который, как говорили, зевал.Vous pouvez être pris en photo avec les deux.
Ансамбль Louis et moi avons même été с фото .
Un homme m’a , фото .
Il n’a jamais été pris en photo , ni identifié.
На l’a , фото avec le Président.
Il n’a même jamais été pris en photo .
Impossible de sortir de son bureau sans uneir été pris en photo .
Вы не выйдете из этого офиса, если Джимми не сделает снимок , щелкните.Une copy. Je l’ai pris en photo avec mon Portable.
Afin de Confirm le délit, le policier a pris en photo l’écran de télévision avec son téléléphone Portable…
Китайский полицейский сделал снимок своим телефоном в качестве доказательства воровства …После того, как это было сделано , есть на фото , оно было выпущено на вилле без разрешения.
После того, как были сфотографированы , их отпустили в городе, чтобы они не повторили свое преступление.Près de la sortie il y a même un très grand toucan docile qui adore être pris en photo en s’assoyant sur l’avant-bras des visiteurs.
На выходе есть даже большой и ручной тукан, которому нравится, когда фотографируют , сидя на предплечье посетителя.Apparemment, ils auraient tous deux quitté le restaurant séparément, dans des voitures séparées, afin de ne pas être , ансамбль фото .
По всей видимости, они оба вышли из ресторана по отдельности, чтобы их не сфотографировали вместе, и сели в разные машины, чтобы отправиться домой.La troisième fois, je t’ai , фото .
iOS 15 — Как перевести текст в фотографиях
Apple представила бета-версию iOS 15 для разработчиков, и мы много работали, чтобы представить пользователям все основные моменты обновления.Одна из последних функций iOS — это новые общесистемные возможности перевода, которые позволяют пользователям переводить практически любой текст на самые популярные языки мира. Раньше приложение для перевода от Apple могло переводить любой продиктованный или напечатанный текст или текст веб-страницы в браузере. Благодаря обновлению iOS 15 и оптическому распознаванию символов вам больше не нужно вводить текст. Давайте углубимся в текстовую функцию Переводчика iOS 15.
iOS 15 улучшила его за счет использования оптического распознавания текста, которое помогает пользователям выбирать текст, доступный в изображениях, снятых на вашем iPhone.Он также может переводить текст в видоискатель. Эта функция очень похожа на функцию перевода изображений Google.
Как это работает?Функция перевода текста iOS 15 работает иначе. Он работает иначе, чем Google Translate. Вам нужно делать снимки в приложении при использовании Google Translate. Вы можете сделать снимок с текстом, открыть Фотопленку, а затем дважды коснуться любого текста, доступного на изображении, и текст будет переведен в следующем окне.
В iOS 15, macOS 15 и iPadOS 15 была представлена новая функция, называемая «живым текстом». Он позволяет пользователям выбирать, переводить и искать текст на любом изображении. Функция Live Text работает не только при фотосъемке, но также может использоваться с любой фотографией, доступной в приложении «Фото». Вы можете выбрать любое изображение и поделиться текстом. Когда в правом нижнем углу экрана появляется индикатор, вы можете выбрать текст, доступный на картинке.
Если на изображении есть адрес или номер телефона, пользователи могут нажать на текст, чтобы найти место или позвонить.Даже если есть вывеска ресторана, пользователи могут искать это место на картах и узнавать, как туда добраться.
Живой текст также помогает искать слова, имеющиеся на фотографии. Вы можете выполнить поиск по фразе или словам, получить результаты фотографии и нажать на нее, чтобы перейти непосредственно к этой фотографии, доступной в библиотеке.
Кроме того, Apple также добавила функцию поиска для поиска сцен и объектов. Когда вы наводите указатель мыши на камеру или просматриваете фотографии искусства, природы, книг, домашних животных и достопримечательностей, на вашем устройстве отображается вся соответствующая информация, доступная со ссылками для получения дополнительных сведений.
Live text может распознавать и переводить на семь языков, включая английский, французский, китайский, немецкий, итальянский, португальский и испанский. Эта функция совместима с процессором A12 Bionic и последующими чипами, установленными в iPhone XS и более поздних моделях.
Как использовать новую общесистемную функцию перевода текста iOS 15:Метод 1
- Первый способ перевести текст — открыть приложение «Камера» и навести его на любой текст, который нужно перевести.
- Как только вы наведете телефон на узнаваемый текст, вы увидите значок в углу видоискателя. Вы можете нажать на него, чтобы выбрать текст, который нужно перевести, скопировать или вырезать.
Метод 2
Вы можете сделать снимок или даже перейти в фотопленку и найти текст на старых изображениях, фотографиях или снимках экрана с помощью функции живого перевода. Однако единственное требование — в нем должен быть богатый детектируемый текст.
Как перевести текст в автономном режимеНет необходимости подключаться к Интернету каждый раз, когда вы хотите использовать новые или существующие функции перевода.Чтобы загрузить языки для автономного перевода, вы можете открыть приложение основных настроек на телефоне, смахнуть до «Перевести», перейти в раздел «Загрузить языки» и загрузить то, что вам нравится.
Итак, вот как можно переводить тексты онлайн и офлайн в фотографиях. Следуйте инструкциям, упомянутым выше, и все будет хорошо.
Испытывая трудности с вашим устройством, ознакомьтесь с нашей страницей « How To », чтобы узнать, как решить некоторые из этих проблем.
Генеративные состязательные сети для преобразования изображения в изображение
Арун Соланки
Dr.Арун Соланки — доцент кафедры компьютерных наук и инженерии Университета Гаутамы Будды, Большая Нойда, Индия. Он получил докторскую степень. Кандидат компьютерных наук и инженерии Университета Гаутамы Будды. Он курировал более 60 M.Tech. Диссертации под его руководством. Его исследовательские интересы включают экспертные системы, машинное обучение и поисковые системы. Д-р Соланки — младший редактор журнала Международный журнал веб-обучения и технологий обучения от IGI Global.Он был приглашенным редактором специальных выпусков журнала «Последние патенты в области компьютерных наук» издательства Bentham Science Publishers. Д-р Соланки — редактор книг «Экологичное строительство» и «Умная автоматизация» и «Справочник новых тенденций и приложений машинного обучения», выпущенных IGI Global.
Партнерские отношения и экспертиза
Доцент кафедры компьютерных наук и инженерии, Университет Гаутамы Будды, Большая Нойда, Индия
Ананд Найяр
Др.Ананд Найяр получил докторскую степень (компьютерные науки) в Университете Деш Бхагат в 2017 году в области беспроводных сенсорных сетей и разведки роя. В настоящее время он работает в аспирантуре факультета информационных технологий Университета Дуй Тан, Дананг, Вьетнам. Он опубликовал более 100 научных работ в различных престижных журналах. Он является автором, соавтором и редактором более 30 книг. На его счету 10 австралийских патентов и 1 индийский дизайн в области беспроводной связи, искусственного интеллекта, Интернета вещей и обработки изображений.Награжден более чем 30 наградами за преподавание и исследования, в том числе награды «Молодой ученый», «Лучший ученый», «Премия молодому исследователю», «Премия за выдающийся исследователь», «За выдающиеся достижения в преподавании». Он исполняет обязанности заместителя редактора по беспроводным сетям (Springer), компьютерным коммуникациям (Elsevier), IET-Quantum Communications, IET Wireless Sensor Systems, IET Networks, IJDST, IJISP, IJCINI. Он исполняет обязанности главного редактора американского журнала IGI-Global под названием «Международный журнал интеллектуальных транспортных средств и интеллектуального транспорта (IJSVST)».
Принадлежность и опыт
Преподаватель, исследователь и ученый, Высшая школа, Университет Дуй Тан, Дананг, Вьетнам
Мохд Навед
Д-р Мохд Навед — консультант и академик по машинному обучению, в настоящее время преподает в качестве доцента и руководителя ( Analytics & IB) в Университете Джаганнатха в сотрудничестве с Xcelerator Ninja (Индия) для различных программ UG & PG в области аналитики и машинного обучения. Он бывший специалист по анализу данных и выпускник Делийского университета.Он имеет докторскую степень Международного университета Нойды. Он активно занимается академическими исследованиями по различным темам в области искусственного интеллекта и технологий 21 века. Его интервью были опубликованы в различных национальных и международных журналах.
Связи и опыт
Доцент и руководитель отдела (аналитика и IB), Университет Джаганнатха; Различные программы UG и PG, аналитика и машинное обучение Xcelerator Ninja, Индия
Демонстрация преобразования изображения в изображение — Affine Layer
Интерактивный перевод изображений с pix2pix-tensorflow
Модель pix2pix работает путем обучения на парах изображений, таких как метки фасадов зданий и фасадов зданий, а затем пытается сгенерировать соответствующее выходное изображение из любого входного изображения, которое вы ему даете.Идея прямо из статьи о pix2pix, которую стоит хорошо прочитать.края2 кошки
Обучен примерно на 2k стоковых фотографиях кошек и автоматически сгенерированных краях из этих фотографий. Создает объекты кошачьего цвета, некоторые с кошмарными мордами. Лучшее, что я когда-либо видел, — это наблюдатель кошек.Некоторые картинки выглядят особенно жутко, я думаю, потому что легче заметить, когда животное неправильно смотрит, особенно вокруг глаз. Автоматически определяемые края не очень хороши и во многих случаях кошачьи глаза не обнаруживаются, что немного усложняет обучение модели преобразования изображений.
фасады
Обучение работе с базой данных от фасадов до маркированных фасадов зданий. Кажется, не совсем понятно, что делать с большой пустой областью, но если вы поместите на нее достаточно окон, это часто дает разумные результаты. Нарисуйте цветные прямоугольники «стены», чтобы стирать предметы.
У меня не было названий разных частей фасадов зданий, поэтому я просто догадался, как они называются.
края2 туфли
Обучается по базе данных из ~ 50 тыс. Изображений обуви, собранных в Zappos, а также автоматически сгенерированных из этих изображений краев.Если вы действительно хорошо рисуете края обуви, вы можете попробовать создать новый дизайн. Имейте в виду, что он тренируется на реальных объектах, поэтому, если вы можете рисовать больше трехмерных объектов, он, кажется, работает лучше.края2 сумки
Подобно предыдущему, обучен на базе данных из ~ 137k изображений сумок, собранных с Amazon, и автоматически генерирует края из этих изображений. Если вы нарисуете здесь туфлю вместо сумочки, вы получите туфлю очень странной фактуры.
Реализация
Модели были обучены и экспортированы с помощью pix2pix.py скрипт из pix2pix-tensorflow. Интерактивная демонстрация сделана на javascript с использованием Canvas API и запускает модель с использованием deeplearn.js. Предварительно обученные модели доступны в разделе «Наборы данных» на GitHub. Все версии, выпущенные вместе с оригинальной реализацией pix2pix, должны быть доступны. Модели, используемые для реализации javascript, доступны по адресу pix2pix-tensorflow-models.Доменно-ориентированный метод преобразования изображения в изображение
Метод преобразования изображения в изображение нацелен на изучение междоменных сопоставлений из парных / непарных данных.Хотя этот метод широко использовался для задач визуального предсказания, таких как классификация и сегментация изображений, и достиг отличных результатов, нам все же не удалось выполнить гибкие переводы при попытке изучить различные сопоставления, особенно для изображений, содержащих несколько экземпляров. Чтобы решить эту проблему, мы предлагаем генеративную структуру DAGAN (Domain-specific Generative Adversarial etwork), которая позволяет доменам изучать различные взаимосвязи отображения. Мы предположили, что изображение составлено с фоном и доменом экземпляра, а затем отправлено их в разные сети перевода.Наконец, мы интегрировали переведенные домены в единое изображение со сглаженными надписями для сохранения реалистичности. Мы изучили структуру с учетом экземпляров на наборах данных, созданных YOLO, и подтвердили, что она способна генерировать изображения с равным или лучшим разнообразием по сравнению с текущими моделями перевода.
1. Введение
Методы преобразования изображения в изображение [1, 2] в последние годы привлекают повышенное внимание. Этот тип генеративной модели может применяться для решения многих задач, связанных со зрением, таких как восстановление произведений искусства, синтез изображений и повышение разрешения [3, 4].С развитием методов глубокого обучения было выдвинуто и решено множество интересных проблем по этой теме [5], таких как уменьшение шума [6] и повышение яркости [7]. Примерами этой технологии являются генерация нескольких выходных документов [8–10] и повышение реалистичности изображения. Однако почти все исследования сосредоточены на переводе полных изображений, а не доменов. В этой работе с предварительно сохраненными матрицами идентичности мы предлагаем генеративный фреймворк DAGAN, который может гибко транслировать домен экземпляра исходного изображения.Как показано на рисунке 1, мы используем матрицы идентичности для успешного отделения экземпляров от исходных изображений и перевода соответственно. Результаты демонстрируют, что наша модель может выполнять переводы с учетом предметной области и генерировать разнообразные и реалистичные поколения.
Мотивированные исследованиями, касающимися вариационных автокодировщиков (VAE) и генеративных состязательных сетей (GAN), существующие модели перевода [10–12] могут сравнивать несколько карт одного изображения для получения возможных результатов перевода. При рассмотрении этих решений, особенно в условиях непарности в недавних исследованиях, общим решением является рассмотрение проблемы преобразования изображения в изображение (I2I) как процесса изучения совместного распределения исходного и целевого доменов [9].Используя VAE и схему разделения веса, изображение можно представить с помощью общих, но низкоразмерных скрытых кодов. Таким образом, нейронные сети могут быть обучены создавать изображения, содержащие стили или особенности обоих доменов.
Одним из основных ограничений моделей текущего исследования является то, что мы не можем полностью контролировать перевод изображений. Мы по-прежнему не можем управлять уровнем и областями перевода. Например, если изображение содержит несколько экземпляров, можно ли преобразовать определенный экземпляр в стиль, отличный от других экземпляров? Это похоже на то, что обычно выполняется с использованием коммерческого программного обеспечения, такого как Photoshop, но до сих пор выполнение перевода с учетом предметной области все еще является сложной задачей.
Чтобы решить эту проблему, мы предполагаем, что изображения состоят из разных доменов, и для каждого домена мы построили модель субтрансляции. В то же время мы следовали конвейеру «сегрегации ⟶ интеграции», когда поколения моделей трансляции предметных областей, наконец, были интегрированы в полный образ. Вообще говоря, мы использовали структуру UNIT [11] (неконтролируемый перевод изображения в изображение) в качестве основы для наших общих работ по переводу, а затем обработали полное изображение как комбинацию экземпляров и фоновых доменов.Во-первых, матрицы идентичности использовались для записи информации о местоположении доменов экземпляров, которые необходимо было преобразовать индивидуально, и мы успешно отделили экземпляры от данного изображения и назначили исходное местоположение (области экземпляров) со средним значением пикселя исходного изображения [13 ]. Затем мы перевели сегрегированный фоновый и экземплярный домены соответственно. Наконец, мы использовали матрицы идентичности для интеграции выходных данных фоновых сетей с реконструированными / переведенными экземплярами.
Наш вклад в эту работу резюмируется следующим образом: (1) Мы создали платформу I2I с учетом домена, DAGAN, и применили фоновую и инстансную сеть для облегчения переводов для обоих доменов. Затем мы специально разработали два разных режима для части экземпляра, которые помогли пользователям гибко контролировать переводы во время обучения. (2) С помощью обучения сглаживанию меток мы сделали реинтегрированные изображения более реалистичными и удобными. (3) По сравнению с текущими исследованиями перевода изображений, DAGAN обеспечивает переводы с учетом предметной области, но поддерживает качество поколений.Обширные качественные эксперименты с тестами показывают, что наш фреймворк выгодно отличается от существующих методов перевода. Результаты нашего метода сохраняют реалистичность и большое разнообразие.
2. Связанные работы
С момента внедрения в [14, 15] модели GAN достигли обнадеживающих результатов во многих задачах видения [5, 6]. Чаще всего GAN [16, 17] используется для принудительного сопоставления сгенерированных изображений с целевыми доменами с помощью состязательных процессов. Такую генеративную модель можно обучить для создания реалистичных изображений из случайных векторов шума.Кроме того, в исследованиях [18–20] изучалась возможность комбинирования VAE с GAN. Общая архитектура VAE состоит из сетей кодировщика и декодера, где кодировщик изучает интерпретируемое представление z (называемое скрытым пространством) из заданных изображений x . Имея надежное представление ввода, мы можем контролировать направление обработки изображения, выбирая добавленные векторы визуальных атрибутов. Этот вид операций помогает декодерам производить более качественные реконструкции или преобразования.Суть VAE заключается в том, что он упорядочивает кодировщик, применяя вариационное апостериорное значение как можно ближе к истинному апостериорному. Методы, представленные в этой работе, были построены на условных моделях VAE и GAN как в фоновой части, так и в части экземпляра, и мы стремимся изучать визуальные атрибуты из целевых областей. Совместно оптимизируя цели сети экземпляров и фоновой сети, мы узнали об общем скрытом пространстве C , где при преобразовании происходит компромисс между исходным и целевым доменами.
Что касается исследования практического применения в этой области, мы пришли к выводу, что эти общие задачи перевода нацелены на изучение взаимосвязи отображения от данного изображения к целевым доменам, но сохранение атрибутов контента и семантической согласованности в обучении создает большие проблемы. Работая с Pix2Pix [1], авторы построили модели, используя парные данные для обеспечения сопоставления. Хотя результаты преобразования Pix2Pix очень реалистичны, учитывая отсутствие обучающих пар, решения, использующие непарные данные, являются более общими и применимыми в промышленных приложениях.Zhu et al. В работе [2] использовались циклические GAN в тех же условиях (с непарными данными) для успешного получения изображений высокого качества. В целом, циклические GAN используют высокие частоты, чтобы скрыть информацию и сделать ее незаметной для людей, чтобы генератор мог восстанавливать образцы позже [21]. Путем циклических потерь, которые поощряют обратные переводы (двунаправленные), Чжу принудительно применял отображение во время обучения. В работе UNIT [11] Лю представил другую точку зрения на проблему обучения переводу. Перевод можно рассматривать как процесс изучения совместных дистрибутивов, поэтому они создают общее пространство для обеих областей.Идея UNIT вдохновила на многие дальнейшие исследования [9, 10], но, оглядываясь назад на это исследование, хотя многие проблемы были решены и поколения идеально подходят для своих новых дистрибутивов, мы по-прежнему не можем выполнять гибкие переводы, где бы мы ни хотели. Например, мы не можем изменить фон, но сохранить специфику области экземпляра или выполнить специальный перевод экземпляра. Подводя итог, мы все еще не можем управлять масштабом и направлением преобразований.
В этой работе с помощью матриц идентичности мы отделяем части фона и экземпляра от исходных изображений.В целом, мы следуем предположениям UNIT и настраиваем общее скрытое пространство для поддержания стабильности моделей. С улучшением структуры и стратегий обучения мы позволили предлагаемой модели гибко преобразовывать различные домены из непарных входных данных.
3. Предлагаемые модели
Предлагаемая структура направлена на выполнение с учетом экземпляра перевода заданного изображения A и целевого B . Если предположить, что каждое изображение состоит из областей фона (bgr) и экземпляра (ins), то изображение A и B можно представить следующим образом: A : {,} и B : { ,}.Как показано на рисунке 2, перед обучением всей сети мы вырезали области экземпляров и из A, и B и сохранили значения местоположения обеих областей в виде матриц идентичности, называемых метками. Обрезанные области затем заменяются средним значением остальной части изображения. После обучения как фоновой, так и сети экземпляров с помощью меток (не используемых во время обучения) мы можем восстановить переведенные изображения (этот шаг называется интеграцией).
В разделе 3.1 мы обсуждаем фон и части изображения, а в разделе 3.2, мы дополнительно модифицируем домен экземпляра для получения различных транслированных выходных данных.
3.1. Фоновая сеть
После отделения области экземпляра от входного изображения остальная часть (называемая областью фона) обрабатывается путем заполнения средними значениями пикселей. Фоновую модель можно рассматривать как независимую часть всей платформы перевода, и эта модель будет изучать визуальный перевод между двумя доменами. Следуя этому предположению, мы устанавливаем кодировщик (обозначен значком) и генератор (обозначен значком) для каждой стороны (здесь для каждого параметра, фигурирующего в этой работе, мы отметили тип домена его нижним индексом):
Подобно UNIT, мы Предположим, что с помощью кодировщика и мы можем отобразить заданный целевой фон в общее скрытое пространство:, где и.Тогда, и представляют собой скрытые коды доменов и, соответственно. В нашей работе мы разделили вес двух последних слоев и и первого слоя и. В то же время мы добавляем два дискриминатора, и, которые гарантируют, что перевод между двумя фоновыми доменами может быть выполнен в состязательном процессе, где и выделяются с помощью while, а отличаются с помощью. Рисунок 3 наглядно иллюстрирует фоновую модель.
3.2. Сеть экземпляра
Мы разработали два режима для сети экземпляра: , реконструкция, и , с несколькими выходами, .В целом, цель модели экземпляра состоит в том, чтобы поддерживать область экземпляра относительно независимой от фоновых областей, чтобы не влиять на область экземпляра с преобразованием фона.
Во-первых, мы применяем аналогичную архитектуру DCGAN (Deep Convolution Generative Adversarial Networks) [22] для простых реконструкций экземпляров, выводя векторы шума из распределения Гаусса N (0, 1). Это позволяет всей структуре (включая фон) успешно преобразовать область фона в другой стиль, но оставить экземпляр без изменений.Затем, вдохновленные [23] и исходя из предположения, что изображения состоят из кодов стиля и содержимого, мы адаптируем часть экземпляра в модель с несколькими выходами.
3.2.1. Режим реконструкции
Этот режим направлен на сохранение части экземпляра неизменной, а окончательные интегрированные изображения как можно более реалистичными (используемые функции потерь будут обсуждаться в следующих разделах). Учитывая размер экземпляра, у нас есть три сверточных слоя как в генераторе, так и в дискриминаторе, который принимает в качестве входного вектора шум нормального распределения Z ∼ N (0, 1).Процесс показан на рисунке 4.
3.2.2. Многоканальный режим
После обрезки исходного изображения область экземпляра может считаться независимым изображением. При таких условиях мы можем выполнить любые переводческие работы в этом домене. Общий подход к достижению разнообразных результатов состоит в том, чтобы рассматривать изображения как комбинацию стиля и информации о содержании. В принципе, мы можем перевести изображения в любой стиль, если добавим подходящие атрибуты / коды стилей.Подобно настройке в MUNIT [9] (Мультимодальный неконтролируемый преобразование изображения в изображение), мы создали несколько генераций экземпляров путем случайной выборки кодов стилей, взятых из целевого экземпляра, а затем повторно объединили их с кодами содержимого. Предполагая, что нам даны домен экземпляра и целевой экземпляр; сначала мы сопоставляем и со стилем и пространством содержимого, соответственно (режим ожидания,, и, представляющие коды стиля и содержимого), где соответствующие кодировщики представлены как, и:
Как и настройка общего пространства в фоновой части, пространство содержимого также совместно используется обоими экземплярами.Затем мы интегрировали коды контента и коды стилей, выбранные случайным образом, а также из и. С семантикой цикла, состоящей из принудительного обучения, мы добились множественных двунаправленных преобразований экземпляров. Подробная архитектура показана на рисунке 5.
4. Функции потерь и обучение
Учитывая разницу в модели между фоновой частью и частью экземпляра, используемые функции потерь, особенно для различных режимов, должны быть соответствующим образом скорректированы. Мы совместно решаем фоновые проблемы и проблемы трансляции экземпляров в целом, используя полную целевую функцию, а затем мы обсудили функции потерь, используемые для обеих частей (обозначенных и):
4.1. Потеря экземпляра
Мы разработали два режима, которые делают часть экземпляра гибкой трансформацией. Первый режим направлен на то, чтобы экземпляры оставались неизменными при переводе фона, а второй режим концентрируется на создании диапазона переводов экземпляров. Теоретически, обрезав данные изображения, мы можем гибко добавлять к этим экземплярам любой код для управления их стилем.
4.1.1. Режим реконструкции
Как показано на рисунке 3, сеть экземпляров в этом режиме состоит из векторов шума, двух генераторов и двух дискриминаторов, каждый из которых имеет три уровня (представленные значками,, и).Состязательный проигрыш выражается следующим образом, где M обозначает размер партии при обучении:
4.1.2. Режим с несколькими выходами
Как показано на рисунке 5, набор {} кодер-генератор составляет единую часть. В этом режиме учитывается потеря реконструкции и потеря состязательности.
4.2. Потеря реконструкции
Вообще говоря, экземпляры обрабатываются при преобразовании как изображения в скрытые коды для целевых направлений, как показано на рисунке 5.Однако, в отличие от [14, 24], коды стилей не выводятся из нормального распределения N (0, 1). Мы используем два кодировщика, стиль и контент, что приводит к тому, что переведенные экземпляры в большей или меньшей степени обладают атрибутами целевого домена. Цель использования такого рода потерь — гарантировать, что изображения сохраняют способность восстанавливаться с точки зрения как скрытых кодов, так и сематической согласованности после обучения:
Тогда и может быть представлено следующим образом:
4.3. Adversarial Loss
Основное использование GAN заключается в их способности максимально соответствовать целевому распределению в состязательном процессе.Мы используем генераторы и, чтобы различать переводы и реальные экземпляры:
Термин представляет собой сумму и; кроме того, определяется аналогично:
4.4. Потеря фона
Фоновая часть состоит из,, и. Как упоминалось в предыдущих разделах, и фоновая часть, и часть экземпляра независимы друг от друга до их интеграции. Визуальные домены в этой части по-прежнему следуют за потоком реконструкции и перевода. Согласно компонентам в фоновой части, мы использовали и для представления VAE, GAN и потери семантической согласованности.Три весовых параметра — и — применяются для измерения воздействия каждого компонента. Например, это можно сформулировать следующим образом:
Архитектура VAE нацелена на изучение скрытой модели путем аппроксимации предельной логарифмической вероятности обучающих данных (алгоритм ELBO [19] (нижняя граница скрытых кодов)). Его целевая функция —
. В этой функции весовые параметры и управляют влиянием целевой функции, а KL (что означает kullback leibler divergence ) измеряет, насколько хорошо соответствует предварительное распределение, которое обозначает распределение общего пространства контента.Чтобы лучше выполнять выборку из пробелов, мы моделируем {} с нормальным распределением и с распределениями Лапласа, соответственно:
Целевая функция GAN направлена на преобразование и восстановление изображений в состязательном процессе:
Целевая функция сематической согласованности гарантирует, что изображения может быть отображен обратно в исходное скрытое пространство, но обладает характеристиками целевых доменов. Существенная модификация этой функции заключается в использовании нормы для прямого сравнения семантических различий вместо использования терминов KL для измерения расстояния в скрытых пространствах (например, UNIT [11]).
5. Методы обучения
Предлагаемая структура имеет тенденцию разделять изображение на его фон и составляющие экземпляра, а затем подавать эти части в независимые сети перевода. Наконец, используя сохраненные ярлыки, мы объединяем обе переведенные части. Такое решение поднимает другой вопрос: как сделать интеграции реалистичными? Если мы просто кадрируем, переводим, соответственно, и интегрируем, интеграция выглядит странно и неудобно, поскольку фоновая часть и части экземпляра переводятся в совершенно разных направлениях (как показано на рисунке 6).
Чтобы сохранить реалистичность изображений после интеграции и сделать их более удобными для просмотра, для дальнейшего улучшения предлагаемой структуры используется метод, называемый «сглаживание меток» [25].
5.1. Методы. Экземпляр) режим с несколькими выходами:
Позвольте и представить фоновую и экземплярную сети.Затем выходные данные, произведенные моделями, будут интегрированы (представлены значками и) следующим образом:
Мы добавляем еще одну пару дискриминаторов {и}, чтобы различать B, , и, после интегрирования. Поскольку интеграции не совсем такие же, как у оригиналов, A и B , мы добавляем параметр для сглаживания обучающих данных. Параметры представлены следующим образом:
Затем, чтобы добавить в процесс различения, мы используем {, и} для оценки отношения
Хотя параметры сглаживания могут способствовать менее достоверным результатам (по сравнению с исходными изображениями) и влиять на стиль выходов, эта настройка делает интеграцию намного более реалистичной, поэтому изображение явно не похоже на комбинацию двух совершенно разных изображений.Подробный метод дискриминации показан на рисунке 7. Сравнение результатов до и после применения метода сглаживания будет представлено в разделе результатов.
6. Эксперименты и обсуждения
6.1. Наборы данных
Фреймворк протестирован на паре тестов: cityscape [26] GTA [27] (двунаправленный перевод). Перед загрузкой обучающих изображений в предложенные рамки мы вырезаем экземпляры из исходных изображений. Ограниченные ресурсами памяти, размер всех экземпляров изменяется до 64 64, а размер фоновых частей изменяется до 256 256.
6.2. Car Translation (Cityscape GTA)
Пройдя обучение в YOLO [28], мы достигли всех значений местоположения автомобилей и сохранили эту информацию в связанных коробках. Для большей наглядности мы обрезали экземпляры размером 300–300 (позже размер этих экземпляров был изменен до 64–64).
Как показано на рисунке 8, мы ясно видим, что во время реконструкции домены экземпляра реконструируются хорошо, будучи почти идентичными их входным данным. На рисунке 9 мы видим, что переведенные фоновые домены сразу имеют стиль и атрибуты целевых доменов.В то время как на рисунке 10 коды стилей, взятые из другого пространства, позволили части экземпляра произвести четыре разных перевода, что определенно доказывает, что, сопоставляя фиксированный контент с разной информацией о стиле, мы можем успешно создавать разные переводы.
При рассмотрении окончательных интеграций, состоящих как из фонового, так и из экземпляров доменов, мы ясно замечаем, что, хотя обе части производят высококачественные переводы, несглаженные интеграции (вторая и четвертая строки на рисунке 11) выглядят несогласованными, например Автомобиль совершенно другого стиля был прикреплен к фону, как показано на рисунке 11.Когда мы применяем сглаженные метки в конце обучения, оба сглаженных перевода хорошо сочетаются друг с другом и выглядят как полное изображение. Хотя некоторые результаты все еще сохраняют границы, границы очень близки к переведенному контенту и цвету (см. 3-ю, 4-ю и 5-ю карты в интеграции городов, представленной на рисунке 12). Основываясь на сравнении с рисунком 11, мы заключаем, что применение сглаживающих меток — возможный и полезный метод интеграции переводов.
Напротив, мы также экспериментировали с MUNIT [9] и DRIT [8].Как показано на рисунках 13 и 14, хотя обе модели достигли хороших характеристик перевода в Cityscape ↔ GTA, они по-прежнему не могли управлять переводами на уровне экземпляра, что означает, что мы не можем отделить экземпляр (например, объекты и области) от других, это означает, что мы можем рассматривать только все элементы как единое целое.
Когда дело доходит до наших поколений, с предварительно записанной информацией о местоположении и методами сглаживания мы делаем возможным перевод на уровне домена / экземпляра. Экземпляры «автомобиля» были выбраны в качестве объектов, а оставшиеся домены были переведены в стиль городского пейзажа / GTA, в результате чего автомобили можно было обслуживать или переводить в другое место назначения.
7. Качественная оценка
7.1. Анкета
Широко используемый метод оценки реалистичности сгенерированных изображений — распространение анкеты. Мы выбрали два метода трансляции, DRIT [8] и MUNIT [9], в качестве базовых и произвольно выбрали 100 изображений в качестве входных данных для сравнения поколений из методов. При проведении анкетирования каждому участнику будут предоставлены пять изображений: реальное, имеющее целевой стиль, поколения (из исходных входных данных) из DRIT, MUNIT и наше (включая сглаженное).По сравнению с настоящим, участники должны выбрать наиболее реалистичное поколение из четырех групп.
Мы собрали 20 студентов в качестве пользователей с факультета информатики. Ожидается, что каждый человек ответит на вопрос: «По сравнению с реальным из четырех результатов, какое изображение вы считаете наиболее реалистичным?» В ходе анкетирования мы подсчитали количество людей, сделавших выбор, и суммировали их на Рисунке 15.
7.2. Метрики
7.2.1. Расстояние схожести участков усвоенного перцептивного изображения (расстояние LPIPS)
Поскольку наше исследование фокусируется на гибких переводах с учетом экземпляров, мы использовали расстояние LPIPS [9, 11] для измерения разнообразия поколений, которое, как было доказано, хорошо коррелирует с человеческими предпочтениями . Подобно MUNIT [9], мы использовали обученный AlexNet [25] в качестве экстрактора признаков и выбрали 150 целевых изображений как одну входную пару и выбрали 15 выходных пар для каждой входной пары.
7.2.2. Условная начальная оценка (CIS)
В [9] этот вид модифицированной метрики может лучше измерить разнообразие результатов.Мы использовали отлаженный Inception-v3 [29] для наших наборов данных в качестве классификатора и рассчитали рейтинг CIS на основе 200 входных пар и 400 переводов на пару.
Мы завершаем сравнение функций с другими методами в таблице 1. Можно ясно видеть, что, в отличие от существующих работ, наш метод позволяет гибкие переводы с различными выходными данными при непарных настройках обучения.
| |||||||||||||||||||||||||||||||
На рис. 15 и в таблице 2 показаны результаты сравнения реализма и разнообразия с другими методами.Что касается реализма, наш метод не превосходит все предыдущие исследования, но мы отметили, что реализм результатов значительно улучшился после применения техники сглаживания, и нет большой разницы в реализме между MUNIT [11] и сглаженным методом.
| ||||||||||||||||||||||||||||||
Кроме того, сравнение разнообразия показывает, что предложенная структура (со сглаживанием) занимает второе место. с точки зрения ЛПИПС и СНГ.DRIT [8] обеспечивает наилучшее разнообразие, но не учитывает предметную область. В целом наш метод отличается большим разнообразием и дает реалистичные результаты.
8. Выводы и дальнейшая работа
В этой работе мы представили гибкую структуру для преобразования изображения в изображение с учетом предметной области. Благодаря плавному обучению мы добились отличных переводов и лучшей интеграции с точки зрения разнообразия и реализма. Текущее исследование сосредоточено на переводе полного изображения, но не учитывает переводы на уровне предметной области и гибкость моделей.
С помощью предлагаемой структуры мы позволили сетям изучить отображение на уровне экземпляра. По сравнению с поколениями из других базовых уровней, наш метод показал себя неплохо и позволил пользователям выбирать области и стили, которые они хотят изменить.
В то же время, наблюдая за промежуточными результатами во время обучения, мы заметили, что этап предварительной обработки, который заменяет обрезанную область экземпляра средним значением пикселя, имеет большое влияние на окончательный перевод. Хотя эта операция не меняет полностью распределение изображений и идеально подходит для областей фона, она по-прежнему представляет собой серьезную проблему для более поздних переводческих работ.
Из результатов нашего эксперимента мы ясно видим, что среднесрочные результаты из данного или целевого доменов также узнали распределение замененной области из другого домена, и это плохо повлияло на последующие поколения, особенно при выполнении операций интеграции. В таких условиях нам нужна более плавная замена или восстановление при обрезке экземпляров.
С другой стороны, наша структура обеспечила преобразование 1: n для фонового домена и доменов экземпляра.Однако, как упоминалось ранее, изображения представляют собой интеграцию содержимого и информации о стиле, и их можно разделить с помощью методов глубокого обучения. Мы также можем выполнять переводы с несколькими выходами в фоновых доменах, как мы это делали в экземплярах. Тогда мы сможем достичь m : n поколений, которые больше подходят для промышленного бизнеса.
Доступность данных
Коды, использованные для подтверждения выводов этого исследования, были предоставлены правительством Кореи (MSIT) по лицензии, и поэтому не могут быть доступны бесплатно.Запросы на доступ к этим данным следует направлять в Сюй Инь, факультет компьютерной инженерии, Университет Инха, Инчхон, 082, Южная Корея.
Конфликт интересов
Авторы заявляют об отсутствии конфликта интересов.