Регистр — это… Что такое Регистр?
РЕГИСТР — (фр., от лат. regesta, regestum внесенное. 1) всякая общественная или частная книга, в которую записывают факты и деяния, память о которых нужно сохранить. 2) объем голоса у певцов. 3) в органах: всякий самостоятельный голос. Словарь иностранных… … Словарь иностранных слов русского языка
РЕГИСТР — (позднелатинское registrum список, перечень), 1) участок диапазона певческого голоса или музыкального инструмента, характеризующийся единым тембром. У певческого голоса различают грудной, головной, смешанный регистр; у мужских голосов бывает так… … Современная энциклопедия
Регистр — (позднелатинское registrum список, перечень), 1) участок диапазона певческого голоса или музыкального инструмента, характеризующийся единым тембром. У певческого голоса различают грудной, головной, смешанный регистр; у мужских голосов бывает так… … Иллюстрированный энциклопедический словарь
РЕГИСТР — РЕГИСТР, регистра, муж. (от новолат. registrum из regestum внесенное, записанное). 1. Список чего нибудь, реестр; Указатель, книга для записей (спец.). || Указатель (спец.). Регистр лиц, упомянутых в книге. 2. Степень высоты и силы голоса (муз.) … Толковый словарь Ушакова
(от новолат. registrum из regestum внесенное, записанное). 1. Список чего нибудь, реестр; Указатель, книга для записей (спец.). || Указатель (спец.). Регистр лиц, упомянутых в книге. 2. Степень высоты и силы голоса (муз.) … Толковый словарь Ушакова
регистр — а, м. registre, нем. Register <ср. лат. registrum <лат. regerere регистрировать, записывать. 1. Список, перечень чего л.; книга для записи, учета чего л. БАС 1. И того дня взяли резолюцию и в регистр записали, что ежели какия суда, с… … Исторический словарь галлицизмов русского языка
РЕГИСТР — (от ср. век. лат. registrum список перечень),1) список, перечень, учетный документ, имеющий правовое значение.2) Название органа, осуществляющего функции надзора в какой либо специальной области управления (напр., в Великобритании Ллойда регистр) … Большой Энциклопедический словарь
РЕГИСТР — в музыке 1) участок диапазона певческого голоса или музыкального инструмента, характеризующийся единым тембром.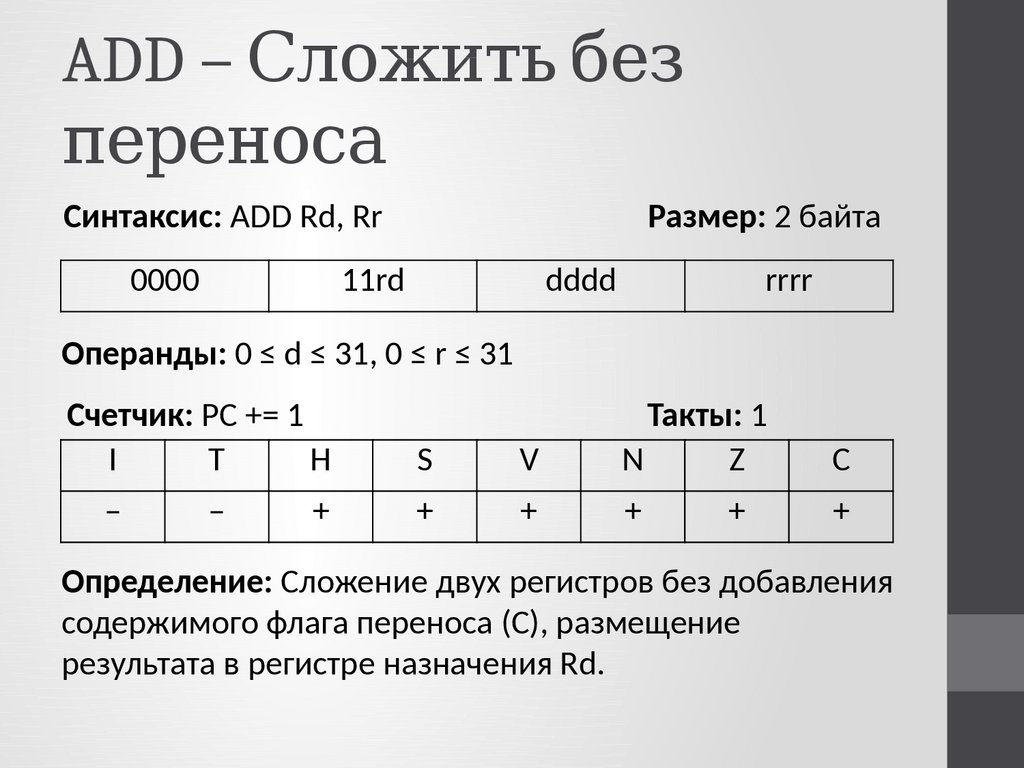 У певческого голоса различают грудной, головной и смешанный регистр. Мужские голоса извлекают и звуки т. н. фальцетного регистра (см.… … Большой Энциклопедический словарь
У певческого голоса различают грудной, головной и смешанный регистр. Мужские голоса извлекают и звуки т. н. фальцетного регистра (см.… … Большой Энциклопедический словарь
РЕГИСТР — систематизированный документ учета материальных ценностей, служащий одновременно и средством отчетности. Словарь финансовых терминов … Финансовый словарь
регистр — номенклатура, список, перечень, реестр; указатель, фальцет, медиум, бурдон, авиарегистр, престант Словарь русских синонимов. регистр сущ., кол во синонимов: 14 • авиарегистр (1) • … Словарь синонимов
РЕГИСТР — (от лат. registrum список, перечень) 1) список, указатель, книга записей, учетный документ, имеющий правовое значение; 2) особый орган, осуществляющий функции надзора в специальной области управления. Например, Регистр Ллойда в Великобритании… … Экономический словарь
Что такое Регистр, определение термина в Бизнес словарь, Ударение в слове Регистр
регистрация, регистратура, детский, ниша, пароль, качество, название,
А. А. Чиртик, HTML: Популярный самоучитель, 2008
Правильность отражения хозяйственных операций в регистрах бухгалтерского учёта обеспечивают лица, составившие и подписавшие их.С. М. Бычкова, Бухгалтерский финансовый учет, 2008
Налоговую остаточную стоимость можно подтвердить регистрами
О. И. Соснаускене, Учет автотранспорта и затрат на его содержание на предприятии
Всё уходит в высокий регистр, но тут же резко обрывается, и наступает гробовая тишина.С. П. Костырко, Простодушное чтение, 2010
С. А. Варламов, Бухгалтерский учет в торговле, 2013
Начинается всё с долгого барабанного боя. .. грохочущего на самых низких
.. грохочущего на самых низких Джордж Марек, Рихард Штраус. Последний романтик
Документы, приложенные к мемориальным ордерам, являются основанием для записей в регистрах аналитического учёта.В. И. Радачинский, Теория бухгалтерского учета. Ответы на экзаменационные вопросы, 2009
Отметим, что при поискеА. А. Гладкий, Составление строительных смет на компьютере
Главное здесь — намеренно изменить темп речи на ощутимо иной: замедляться, ускоряться, выходить в разные регистры, особенно если это неродной для тебя темп.
Александра Пожарская, Эту речь невозможно забыть. Секреты ораторского мастерства, 2014
Марина Виннер, Социальные сети без страха для тех, кому за…, 2011
Таким образом, по каждой строке регистра видно состояние расчётов с каждым дебитором (кредитором) или состояние расчётов по каждому расчётному документу.
Л. В. Згонник, Антикризисное управление, 2015
Единственное, о чём нужно помнить, — что при вводе адреса сайта не имеет значения регистр вводимых знаков (прописные они или строчные — всё равно).Г. Г. Кондратьев, Популярный самоучитель работы в Интернете, 2005
Ключевым моментом наличия такой системы учёта являются действующие в данных странах регистры населения.А. С. Челноков, Россия не для русских? Косовский сценарий в Москве, 2013
— У вас, деточка, хорошие верхний и средний регистры, но этим никого не удивишь.
Мария Очаковская, Экспонат руками не трогать, 2012
Содержимое данного регистра удобно применять при формировании бухгалтерских проводок для автоматического контроля корректности корреспонденций.А. А. Гладкий, 1С. Бухгалтерия для начинающих, 2013
Главнейшие его особенности — владение всеми регистрами голоса, чистота и ровность звучания и тембра, филигранная техника дыхания.Ф. С. Капица, История мировой культуры, 2010
Однако интонационные регистры меняет виртуозно — иногда скачком, иногда плавно, подключая то язвительность, то сочувствие, то философическую рефлексию.
Марк Амусин, Огонь столетий (сборник), 2015
Необходимо изменить учётные регистры, документы оперативного учёта и планирования, для того чтобы иметь соответствующую информацию.Д. А. Шевчук, Бюджетирование: самоучитель
И что удивительно — при звуках скрипки в басовом регистре они начинают как бы «пританцовывать» в такт, ритмично вибрируя грудными плавниками.Т. Д. Жданова, Сотворенная природа глазами биологов, 2012
Ко всему этому было добавлено соглашение, по которому финские суда нельзя было вносить в судовые регистры нейтральных и невоюющих стран.
Карл Густав Маннергейм, Линия жизни. Как я отделился от России
Если выбран «Обычный текст», то параметр «Формат» может задавать различные регистры (прописные буквы или строчные).А. Н. Остапчук, ПК для ветеринарного врача, 2006
В конце месяца данные разработочных таблиц итогами записывают в регистры синтетического и аналитического учёта.В. Э. Керимов, Бухгалтерский учет, 2015
Его умеренный оптимизм — эмоциональный регистр, нетипичный для описания отношения к городу.
Коллектив авторов, Микроурбанизм. Город в деталях, 2014
Менялся и звуковой регистр.Л. Г. Зорин, Ироническая трилогия, 2001-2005
При заполнении данного поля необходимо учитывать регистр символов (т.А. А. Гладкий, Поиск персонала с помощью компьютера. Как сэкономить на кадровом агентстве, 2007
Например, есть кнопка для быстрого удаления форматирования, изменения регистра, перечеркивания текста.
И. Краинский, Word 2007. Популярный самоучитель
В результате была создана единая классификационная система и составлен международный регистр наименований сортов тюльпанов.О. В. Городец, Тюльпаны. Лучшие сорта для вашего сада, 2016
Каждый операнд векторной команды хранится в особом векторном регистре большой ёмкости.Ф. А. Новиков, Толковый словарь современной компьютерной лексики, 2004
Все показатели хранятся до тех пор, пока единица наблюдения находится в регистре и не закончила своего существования.
Н. В. Коник, Общая теория статистики: конспект лекции
Было написано множество научных работ о том, как использовать некоторые регистры и картотеки.Филипп Ванденберг, Сикстинский заговор, 1988
Устройство декоративных экранов над регистрами систем отопления из полимерных и синтетических материалов не проводится.И. Д. Еналеева, Охрана труда в сфере общественного питания, 2006
Для этого на каждый заказ в бухгалтерии открывается отдельный регистр, в котором учитываются затраты по заказу в течение всего срока его выполнения.
Владислав Гагарский, Хватит платить за все! Снижение издержек в компании, 2012
По видам учётных записей регистры подразделяются на хронологические и систематические.В. И. Радачинский, Теория бухгалтерского учета. Ответы на экзаменационные вопросы, 2009
Слово «подстаканник» русскими буквами в английском регистре!Дмитрий Емец, Ладья света, 2013
Информация, которая обычно содержится в регистре: сведения медицинского страхования, пенсионного фонда, правоохранительных органов и т.
А. В. Белозерова, Демография и статистика населения. Шпаргалка, 2009
Адрес операнда в командах цикла определяется как указанный в команде относительный адрес плюс содержимое базового регистра плюс содержимое индексного регистра.Ф. А. Новиков, Толковый словарь современной компьютерной лексики, 2004
Эти регистры служат основанием для отражения амортизации и износа основных средств на соответствующих счетах бухгалтерского учёта.С. М. Бычкова, Бухгалтерский финансовый учет, 2008
Правда, она всё время видоизменялась, как это бывает с любой темой в любых вариациях, — менялись её интонации, регистр звучания, мажорные и минорные лады.
Д. И. Рубина, Альт перелетный (сборник)
В своё время когнитивная психология разделила человеческую память на три блока: сенсорный регистр, кратковременную и долговременную память.Д. А. Шевчук, Методика изучения иностранного языка (ускоренное изучение)
При вводе пароля следует также соблюдать регистр символов, и если у вас будет нажата клавиша Caps Lock, то система предупредит вас об этом.Юрий Зозуля, Windows 7 на 100%, 2010
Но нет, никаких трактиров, пивных и прочих заведений со столь инфернальным названием в регистрах не значилось.
Борис Акунин, Чёрный город (с иллюстрациями), 2012
Однако в моих доме и классе речь шла, пожалуй, о его брате, который, как свидетельствует школьный регистр, погиб на войне, будучи летчиком-истребителем.Рудольф Риббентроп, Мой отец Иоахим фон Риббентроп. «Никогда против России!», 2015
У этого регистра есть собственная логика, основанная на том факте, что речь идёт о создании нового мира, на который делается ставка.Ален Бадью, Философия и событие. Беседы с кратким введением в философию Алена Бадью, 2010
Информация из первичных документов переносится в регистры бухгалтерского учёта.
С. М. Бычкова, Бухгалтерский финансовый учет, 2008
Перед записями в регистры синтетического учёта первичные документы систематизируют и накапливают.С. М. Бычкова, Бухгалтерский финансовый учет, 2008
Запись в учётные регистры осуществляют ручным или машинным способом.С. М. Бычкова, Бухгалтерский финансовый учет, 2008
Записи в учётных регистрах должны быть краткими, аккуратными, чёткими, разборчивыми.
С. М. Бычкова, Бухгалтерский финансовый учет, 2008
Регистр в музыке. Значение и определение слова
Регистр в музыке – это, прежде всего, ряд звуков певческого голоса. Также это может быть участок диапазона каких-либо музыкальных инструментов. Это краткое определение регистра в музыке. А каково значение этого слова? И как объяснить тему «Регистры в музыке» на уроке сольфеджио?
Значение слова
Слово «регистр» в переводе с позднелатинского (registrum) означает «перечень, список». От латинского (regestum) – это «вписанное, внесенное».
Регистр в музыке – это отрезок диапазона какого-либо инструмента или певческого голоса. Он характеризуется одним тембром.
В пении – это объем голоса (бывает нижний, средний, верхний). В органе – это специальные приспособления, благодаря которым можно по-разному изменять звуки (как ослаблять, так и усиливать).
Регистр. Определение в музыке
Употребляется в разных смыслах. Во-первых — это ряд звуков певческого голоса. Во-вторых – это отрезки диапазона каких-либо музыкальных инструментов. И, в-третьих, это устройства, используемые на некоторых инструментах.
Следует подробнее остановиться на каждом.
- Рассматривая регистр как последовательность звуков человеческого (певческого) голоса, нужно учитывать, что они поются одинаковым способом. Из этого следует, что у них один и тот же тембр. У каждого человека доля участия головных и грудных полостей может быть различной, поэтому существуют головной, грудной и смешанный регистры. Некоторые голоса могут воспроизводить звуки так называемого фальцетного регистра. Зачастую это удается мужским голосам, особенно тенорам. У певцов при переходе из одного регистра в другой могут возникнуть определенные трудности со звукоизвлечением. В основном это происходит с теми, у кого голос не поставлен или не обладает достаточной силой звука.
 Чтобы добиться качественного результата и беспрепятственно переходить из одного регистра в другой, нужно стараться на протяжении всего диапазона следить за максимально ровным звучанием голоса.
Чтобы добиться качественного результата и беспрепятственно переходить из одного регистра в другой, нужно стараться на протяжении всего диапазона следить за максимально ровным звучанием голоса. - Что касается второго значения, то регистр в музыке – это одинаковые отрезки диапазона различных музыкальных инструментов, которые совпадают тембрально. А вот если исполнить мелодию на одном и том же инструменте в разных регистрах, то тембр звука будет значительно отличаться.
- Для изменения тембра и силы звука используются специальные устройства и приспособления. Так, например, для изменения звука на клавесине защипывается струна ближе к колку или заменяется комплект струн.
 Чтобы добиться качественного результата и беспрепятственно переходить из одного регистра в другой, нужно стараться на протяжении всего диапазона следить за максимально ровным звучанием голоса.
Чтобы добиться качественного результата и беспрепятственно переходить из одного регистра в другой, нужно стараться на протяжении всего диапазона следить за максимально ровным звучанием голоса.Как объяснить тему «Регистры в музыке» на уроке сольфеджио?
Чтобы тема «Регистры в музыке» для детей была понятна, педагогу нужно заранее ее продумать и тщательно к ней подготовиться. В первую очередь, необходимо подготовить наглядные пособия и раздаточный материал. Это могут быть карточки с медведем и птичкой. Их надо сделать столько, сколько детей в классе.
Их надо сделать столько, сколько детей в классе.
Начать занятие можно с проверки домашнего задания. Затем спеть с ребятами распевки и упражнения. После этого можно приступать к изложению новой темы. Раздать заранее подготовленные карточки. Сыграть пьесы «Воробей» Руббаха и «Медведь» Ребикова и попросить поднять карточки с тем персонажем, кого изображает музыка. После этого нужно сказать, что пьеса «Медведь» написана в нижнем регистре, а «Воробей» — в высоком. Есть еще и средний. В этом регистре мы поем наши песенки. Потом учитель раздает детям красные и синие карандаши, карточки с нарисованным медведем и птичкой, и говорит, что будет играть звуки на пианино, а ученики должны определить, какой это регистр. Когда будут звучать высокие звуки, то в корзину к птичкам дети рисуют синий кружок, если низкие, то в лукошко к медведю — красный. Можно сыграть около 5-7 звуков. В конце урока необходимо задать вопросы для закрепления, выставить оценки за урок и определить домашнее задание.
Заключение
Итак, регистр в музыке – это ряд звуков певческого голоса, участок диапазона каких-либо музыкальных инструментов, а также это устройства, используемые на некоторых инструментах.
Обязательные реквизиты регистра бухгалтерского учета
]]>Подборка наиболее важных документов по запросу Обязательные реквизиты регистра бухгалтерского учета (нормативно–правовые акты, формы, статьи, консультации экспертов и многое другое).
Судебная практика: Обязательные реквизиты регистра бухгалтерского учетаСтатьи, комментарии, ответы на вопросы: Обязательные реквизиты регистра бухгалтерского учета Открыть документ в вашей системе КонсультантПлюс:Статья: Рекомендация Р-115/2020-КпР «Своевременность документального оформления фактов хозяйственной жизни»
(Фонд «Национальный негосударственный регулятор бухгалтерского учета «Бухгалтерский методологический центр» (Фонд «НРБУ «БМЦ»), утверждена Комитетом по рекомендациям (КпР) 23.
 06.2020)
06.2020)(«Официальный сайт Бухгалтерского методологического центра», 2021)В соответствии с частью 1 статьи 10 Федерального закона данные, содержащиеся в первичных учетных документах, подлежат своевременной регистрации и накоплению в регистрах бухгалтерского учета. В соответствии с частью 2 той же статьи не допускаются пропуски или изъятия при регистрации объектов бухгалтерского учета в регистрах бухгалтерского учета. При этом в соответствии с пунктом 4 части 4 статьи 10 Федерального закона обязательным реквизитом регистра бухгалтерского учета является помимо прочего хронологическая и (или) систематическая группировка объектов бухгалтерского учета. Федеральный закон не содержит каких-либо положений, уточняющих значение слова «своевременной», помимо отмеченных выше положений статей 1 и 13. Исходя из этого под своевременной регистрацией факта хозяйственной жизни в бухгалтерском учете следует понимать его регистрацию настолько скоро, чтобы это обеспечило включение всех количественных показателей, неколичественных данных и другой информации, на которую повлиял регистрируемый факт, в бухгалтерскую (финансовую) отчетность организации, как годовую, так и промежуточную.
 Нормативные акты: Обязательные реквизиты регистра бухгалтерского учета
Нормативные акты: Обязательные реквизиты регистра бухгалтерского учетаAssembler: 12. Команды расширения — IndigoBits
В программах довольно часто нужно переслать меньшее по длине значение в большую по длине переменную или регистр. В качестве примера предположим, что нам нужно загрузить 16-разрядное беззнаковое значение, хранящееся в переменной count, в 32-разрядный регистр ЕСХ. Самое простое решение этой задачи заключается в том, что вначале нужно обнулить регистр ЕСХ, а затем загрузить 16-разрядное значение переменной count в регистр СХ:
mov ecx, 0 mov cx, unsignedVal ; ECX = FFFFFFF0h (-16)
А что делать, если нужно загрузить в регистр ЕСХ отрицательное значение, например, -16? для получения правильного результата нам нужно было не обнулять регистр ЕСХ, а загрузить в него значение FFFFFFFFh, и только затем загрузить в регистр СХ переменную signedVal. Код будет выглядеть так:
Код будет выглядеть так:
mov ecx, 0FFFFFFFFh mov cx, signedVal ; ECX = FFFFFFF0h (-16)
Тобишь, для решения задачи, вначале нужно проанализировать знак числа и в зависимости от результата загрузить в регистр либо 0, либо -1.
Для выполнения расширения можно использовать готовые команды:
Команда CBW (Convert byte to word)
Выполняет преобразование значения, находящегося в регистре al, до размера слова, и помещает его в ах, при этом свободные старшие биты ах заполняются знаковым битом al (al -> ax).
Результат выполнения для отрицательного и положительного числа Mov al, -1; al = 10000001b Cbw; ax = 11111111 10000001b Mov al, 1; al = 00000001b Cbw; ax = 00000000 00000001b
Команда CWD (Convert word to double)
Выполняет преобразование значения, находящегося в регистре ax, до размера двойного слова, и помещает его в пару регистров dx:ах, при этом свободные биты dx заполняются знаковым битом aх. (ax -> dx:ax)
(ax -> dx:ax)
Mov ax, -1; ax = 10000000 00000001b Cwd; dx 11111111 11111111 ax = 10000000 00000001b Mov ax, 1; ax = 00000000 00000001b Cwd; dx = 00000000 00000000 ax = 0000000 00000001b
Команда CWDE (Convert word to double extended)
Выполняет преобразование значения, находящегося в регистре ax, до размера двойного слова, и помещает его в регистр eах, при этом свободные старшие биты eax заполняются знаковым битом aх. (ax -> eax)
Mov ax, -1; ax = 10000000 00000001b Cwde; eax = 11111111 11111111 10000000 00000001b Mov ax, 1; ax = 00000000 00000001b Cwde; eax = 00000000 00000000 00000000 00000001b
Команда CDQ (Convert double to quadruple)
Выполняет преобразование значения, находящегося в регистре eax, до размера учетверенного слова, и помещает его в пару регистров edx:eах, при этом свободные биты edx заполняются знaковым битом eax. (eax -> edx:eax)
Mov eax, -1; eax = 10000000 00000000 00000000 00000001b Cdq; ;edx = 11111111 11111111 11111111 11111111b ;eax = 10000000 00000000 00000000 00000001b Mov eax, 1; eax = 00000000 00000000 00000000 00000001b Cdq; ;edx = 00000000 00000000 00000000 00000000b ;eax = 00000000 00000000 00000000 00000001b
Команда MOVZX
Команда MOVZX копирует содержимое исходного операнда в больший по размеру регистр получателя данных. При этом оставшиеся неопределенными биты регистра-получателя (как правило, старшие 16 или 24 бита) сбрасываются в ноль. Эта команда используется только при работе с беззнаковыми целыми числами.
При этом оставшиеся неопределенными биты регистра-получателя (как правило, старшие 16 или 24 бита) сбрасываются в ноль. Эта команда используется только при работе с беззнаковыми целыми числами.
Команда MOVSX
Команда MOVSX (Move With Sign-Extend, или Переместить и дополнить знаком) копирует содержимое исходного операнда в больший по размеру регистр получателя данных, также как и команда MOVZX. При этом оставшиеся неопределенными биты регистра- получателя (как правило, старшие 16 или 24 бита) заполняются значением знакового бита исходного операнда. Эта команда используется только при работе со знаковыми целыми числами.
Команды MOVSX и MOVZX применимы к следующим операндам:
MOVSX/MOVZX 16-разрядный регистр (16r), 8-разрядный регистр или поле памяти(8r/8m)
MOVSX/MOVZX 32-разрядный регистр (32r), 8-разрядный регистр или поле памяти(8r/8m)
MOVSX/MOVZX 32-разрядный регистр (32r), 16-разрядный регистр или поле памяти(16r/16m)
Регистры сведений.
 История одного «велосипеда» / Хабр
История одного «велосипеда» / ХабрВ свое время, когда я достаточно много занимался собеседованиями кандидатов на должность разработчика 1С, я нашел для себя пару-тройку совсем простых вопросов. Послушав ответы на эти вопросы можно было моментально представить себе уровень кандидата.
Один из вопросов звучал безобидно и просто: «Что такое регистр сведений?» Тем удивительнее было наблюдать, как многие буквально спотыкались об него. Впечатление было такое, как будто человек шел, шел и не заметил стеклянную дверь. Тогда-то я впервые задумался о том, что не так с этим изобретением.
На момент разработки принципиальной схемы будущей платформы 1С:Предприятие 8, уже существовала хорошо проработанная и стройная теория реляционных баз данных. Ее основные понятия: записи (кортежи), таблицы (отношения), индексы, ключи были прекрасно «подогнаны» друг к другу. Все логично и ничего лишнего. Одна лишь проблема. Все это было несколько «абстрактно» для простого человека. Поэтому идея «обернуть» понятия таблиц и связей типа один-ко-многим во что-нибудь более близкое простому человеку сработала на «ура». Назвав таблицы с реквизитом типа «Дата» документами, а таблицы без такового справочниками, создатели получили эффект, наверное, больший, чем сами ожидали. В самом деле, каждый легко мог представить себе что такое справочник и что такое документ. Потому что раньше так или иначе имел с ними дело. В одночасье базы данных стали близкими для широкого круга.
Назвав таблицы с реквизитом типа «Дата» документами, а таблицы без такового справочниками, создатели получили эффект, наверное, больший, чем сами ожидали. В самом деле, каждый легко мог представить себе что такое справочник и что такое документ. Потому что раньше так или иначе имел с ними дело. В одночасье базы данных стали близкими для широкого круга.
Но все это произошло до появления восьмой версии, да и в общем-то и до появления 1С как таковой. Разработчики восьмерки, стремясь всенепременно изобрести что-нибудь свое, выделили в отдельный класс то, что в сущности является всего-лишь одной из возможных опций таблицы (или справочника, если вам так удобнее называть). Всякая запись (кортеж) служит для отображения связей между сущностями. Но характер этих связей может быть разным. Иногда это одна основная сущность и множество сущностей, подчиненных основной. Например, основная сущность «товар», а «наименование», «модель», «размер», «цвет» — это все сущности-атрибуты, подчиненные основной. Еще пример: «контрагент», как основная сущность, и «наименование», «адрес», «телефон», как подчиненные.
Еще пример: «контрагент», как основная сущность, и «наименование», «адрес», «телефон», как подчиненные.
В реальном мире есть как отношения подчинения, так и отношения равноправия. Поэтому в одной записи могут оказаться несколько сущностей с равными правами. Например, если мы хотим отражать в базе данных информацию о том, какие товары по каким ценам мы берем у тех или иных поставщиков (контрагентов), тогда у нас появляются записи вида: «товар», «контрагент», «цена». Здесь «цена» несомненно подчиненная сущность. Но подчинена она уже не какой-то одной а сразу двум другим сущностям.
В теории (да и в практике тоже) баз данных это обыгрывается элементарно. Первичный ключ может быть простым, если у нас отношения подчинения (первый случай) или составным, если у нас отношения равноправия (второй случай). Это решение логично, изящно и настолько просто, что попытки найти здесь «свой путь», несомненно должны проходить по разряду «изобретений велосипеда».
Создатели платформы 1С:Предприятие 8 могли бы просто дать возможность указывать явным образом первичный ключ в справочнике, но они пошли по пути «велосипедостроительства» и создали отдельный класс для таблиц с составным первичным ключом, назвав его регистром сведений. Тут можно возразить, что я только что хвалил создание новых классов. Наличие поля типа «дата» тоже, по сути, опция. Почему же тогда нельзя создать новый класс по опции составного первичного ключа? Тут все дело в результате. «Справочники» и «документы» понятны всем практически «с лету». Это я вам, как преподаватель с двадцатилетним стажем, могу со всей ответственностью заявить. А вот «регистры» окутаны туманом. А «регистры сведений» непроницаемым туманом. Нет, человек с некоторым уровнем развития всяко может догадаться, что «регистр сведений» — это некое место, где хранятся «сведения». Но его следующим, законным вопросом будет: а что мы тогда храним в «документах» и «справочниках»? Не «сведения»? А что?
Тут можно возразить, что я только что хвалил создание новых классов. Наличие поля типа «дата» тоже, по сути, опция. Почему же тогда нельзя создать новый класс по опции составного первичного ключа? Тут все дело в результате. «Справочники» и «документы» понятны всем практически «с лету». Это я вам, как преподаватель с двадцатилетним стажем, могу со всей ответственностью заявить. А вот «регистры» окутаны туманом. А «регистры сведений» непроницаемым туманом. Нет, человек с некоторым уровнем развития всяко может догадаться, что «регистр сведений» — это некое место, где хранятся «сведения». Но его следующим, законным вопросом будет: а что мы тогда храним в «документах» и «справочниках»? Не «сведения»? А что?
А все дело в том, что «регистры» уже существовали в предыдущей версии. Такое ощущение, что разработчики восьмерки, отважившись на создание нового класса, ровно на этом месте исчерпали весь запас своей креативности. Новый класс они зачем-то отнесли к семейству «регистров», переименовав тру-регистры в «регистры накопления», а неофитов назвав «регистрами сведений». Более того. У тру-регистров (у регистров накопления) поля разделены на «измерения» и «ресурсы». Что по сути есть поля группировки и поля агрегирования (суммирования). У регистров сведений не стали придумывать ничего нового (конечно! зачем плодить сущности без нужды! ха-ха!) и также разделили поля на «измерения» и «ресурсы». Только здесь «измерения» — это и есть составной уникальный ключ, а «ресурсы» это все прочее. Так в одном случае набор «измерений» уникален и в этом его предназначение, а в другом наборы «измерений» повторяются и в этом тоже заключается предназначение, но уже другое. Одни «ресурсы» суммируются и вообще похожи на ресурсы реального мира, которые могут накапливаться, а могут исчерпываться. А другие «ресурсы»… ну, мы просто экономим слова, говорят нам разработчики. Кажется, если бы мы решили все запутать, у нас вряд ли получилось бы лучше, чем у них. Но и это еще не все.
Более того. У тру-регистров (у регистров накопления) поля разделены на «измерения» и «ресурсы». Что по сути есть поля группировки и поля агрегирования (суммирования). У регистров сведений не стали придумывать ничего нового (конечно! зачем плодить сущности без нужды! ха-ха!) и также разделили поля на «измерения» и «ресурсы». Только здесь «измерения» — это и есть составной уникальный ключ, а «ресурсы» это все прочее. Так в одном случае набор «измерений» уникален и в этом его предназначение, а в другом наборы «измерений» повторяются и в этом тоже заключается предназначение, но уже другое. Одни «ресурсы» суммируются и вообще похожи на ресурсы реального мира, которые могут накапливаться, а могут исчерпываться. А другие «ресурсы»… ну, мы просто экономим слова, говорят нам разработчики. Кажется, если бы мы решили все запутать, у нас вряд ли получилось бы лучше, чем у них. Но и это еще не все.
Есть такая задача, которая называется «получение последних значений». Например, у вас в базе имеется следующая информация о закупочных ценах:
01. 01.2019, ООО Ромашка, Ложка, 150 р.
01.2019, ООО Ромашка, Ложка, 150 р.
01.02.2019, ООО Ромашка, Вилка, 120 р.
01.03.2019, ООО Ромашка, Вилка, 125 р.
01.02.2020, ООО Незабудка, Ложка, 165 р.
01.03.2020, ООО Незабудка, Ложка, 167 р.
01.08.2021, ООО Василек, Ложка, 190 р.
01.08.2021, ООО Василек, Вилка, 155 р.
01.08.2021, ООО Одуванчик, Ложка, 191 р.
Тогда последние цены конкретных товаров у конкретных поставщиков будут следующие:
01.01.2019, ООО Ромашка, Ложка, 150 р.
01.03.2019, ООО Ромашка, Вилка, 125 р.
01.03.2020, ООО Незабудка, Ложка, 167 р.
01.08.2021, ООО Василек, Ложка, 190 р.
01.08.2021, ООО Василек, Вилка, 155 р.
01.08.2021, ООО Одуванчик, Ложка, 191 р.
А последние цены просто товаров, без учета поставщиков:
01.08.2021, Ложка, 190 р.
01.08.2021, Вилка, 155 р.
01.08.2021, Ложка, 191 р.
Получается такое в результате достаточно нехитрой операции группировки и получения максимальных дат, а затем соединения с исходной таблицей. Может применяться к любому набору данных, в котором есть поле типа «Дата».
Может применяться к любому набору данных, в котором есть поле типа «Дата».
Разработчики восьмерки почему-то решили, что единственным местом, откуда эта операция может вызываться должен быть как раз регистр сведений. Только не обычный в их понимании, а особенный, который они выделили в отдельный подкласс и назвали «периодическим». Кавычки здесь более чем уместны, потому что никаких периодов там нет. Разработчики воспользовались словом, не вполне отдавая себе отчет в том, что оно означает. Но, по сравнению с остальным, это, в сущности, мелочь. «Периодический» регистр сведений отличается от обычного тем, что в состав первичного ключа помимо измерений входит т.н. «период» (который, конечно не период, а просто поле типа «Дата»).
Идея разработчиков заключалась в том, что последние записи должны быть уникальными. И надо сказать, что они верно поняли задачу. Но лучше бы они ее не решали. Если верить Эйнштейну (а у нас нет оснований ему не верить, раз мы пользуемся его формулами практически каждый день), то в реальном мире никакие два события не происходят в точности одновременно. Поэтому, имея поле типа «Дата», которое отмечает точку на временной оси, мы уже имеем уникальность. Достаточно позаботиться о том, чтобы ваша учетная система соответствовала реальному миру в фундаментальных аспектах (а время это именно такой аспект) и создать механизм обеспечивающий уникальность значения типа «Дата» как минимум в рамках информационной базы. Тогда наш результат из вышеприведенного примера естественным образом избавился бы от дублирующих значений:
Поэтому, имея поле типа «Дата», которое отмечает точку на временной оси, мы уже имеем уникальность. Достаточно позаботиться о том, чтобы ваша учетная система соответствовала реальному миру в фундаментальных аспектах (а время это именно такой аспект) и создать механизм обеспечивающий уникальность значения типа «Дата» как минимум в рамках информационной базы. Тогда наш результат из вышеприведенного примера естественным образом избавился бы от дублирующих значений:
01.08.2021 00:00:00 78364732678365738465734, Вилка, 155 р.
01.08.2021,00:00:00 78364732678365753438478, Ложка, 191 р.
Но разработчики посчитали, что достаточно будет хранить даты с точностью до секунды. И перед ними встала другая задача. Какой результат выдавать, в случае если запрос к их регистру сведений строится по неполному набору ключевых полей, как это было показано выше. Можно было бы выдавать результат:
01.08.2021, Ложка, 190 р.
01.08.2021, Вилка, 155 р.
01.08.2021, Ложка, 191 р.
Но это внезапно ломало концепцию уникальности последних записей. Можно было бы вызывать исключительную ситуацию при попытке построить запрос к регистру сведений. И, повторюсь, все-таки лучшим решением было обеспечение уникальности значений типа «Дата». Что же сделали разработчики, столкнувшись с очередной трудностью? А ничего! Вот просто ничего. В текущей реализации запрос к регистру сведений по неполному набору «измерений» вернет:
01.01.2019, Ложка, 150 р.
01.03.2019, Вилка, 125 р.
01.03.2020, Ложка, 167 р.
01.08.2021, Ложка, 190 р.
01.08.2021, Вилка, 155 р.
01.08.2021, Ложка, 191 р.
Как видите, результат не только потерял уникальность, он еще и перестал выдавать последние записи. Он лишен вообще какого-либо смысла. Такое ощущение, что малые дети начали что-то делать, потом у них возникли трудности, они расстроились и бросили все, как есть.
На самом деле все это не так смешно, как я здесь описываю. Потому что в реальности происходит следующее. Вы сталкиваетесь с задачей получения последних записей по неполному набору «измерений». Открываете документацию. В описании виртуальной таблицы среза последних читаете:
«Предназначена для получения наиболее поздних записей регистра сведений на указанную дату (включительно). Включает только активные записи. По каждой комбинации измерений будет найдена наиболее поздняя запись, но не более поздняя, чем указанная дата.»
Делаете вывод, что ваш запрос вернет вам последние записи, а в результате получаете бессмыслицу. Проблема здесь не только в том, что вы теряете время. Хотя и это тоже важно, если учесть, что разработчиков в 1С десятки тысяч. Гораздо серьезнее следующее. Если вы полностью доверяете разработчикам платформы, то вы не станете дотошно проверять результат и можете элементарно пропустить эту ошибку. А если вы уже обожглись на чем-то другом и теперь проверяете все досконально, то и тут нет ничего хорошего. Потому что невозможно нормально работать, если знаешь, что от разработчиков платформы можно в любой момент ожидать чего угодно.
В какой мере были знакомы архитекторы будущей 1С:Предприятие 8 с теорией баз данных мы теперь наверное и не узнаем. Я допускаю крайний вариант — ни в какой. Это было время пионеров. Можно было предложить практически что угодно. В том числе и очевидно нелепые решения. И это проходило, потому что пользователям было трудно дать оценку нового для них продукта, а конкуренты остались где-то далеко позади. Нам же остается утешать себя тем, что зато сегодня мы имеем очень хороший пример очень плохой архитектуры.
определение и синонимы слова registro в словаре итальянский языка
REGISTRO — определение и синонимы слова registro в словаре итальянский языкаEducalingo использует cookies для персонализации рекламы и получения статистики по использованию веб-трафика. Мы также передаем информацию об использовании сайта в нашу социальную сеть, партнерам по рекламе и аналитике.
ПРОИЗНОШЕНИЕ СЛОВА REGISTRO
ГРАММАТИЧЕСКАЯ КАТЕГОРИЯ СЛОВА REGISTRO
существительное
прилагательное
ЧТО ОЗНАЧАЕТ СЛОВО REGISTRO
Нажмите, чтобы посмотреть исходное определение слова «registro» в словаре итальянский языка. Нажмите, чтобы посмотреть автоматический перевод определения на русский языке.Значение слова registro в словаре итальянский языка
Первое определение регистра в словаре — это книга, ноутбук и сим. где вещи и факты записываются в том порядке, в котором они происходят, по памяти или документации: r. доходов и расходов. Другое определение регистра — это государственный орган, который занимается проблемой и сохранением документов, относящихся к определенной категории товаров: r. судостроение. Реестр также является публичным документом, в котором акты, касающиеся товаров и лиц, имеющих юридическое значение, отмечены, чтобы сделать их общедоступными и доказать их существование: r. кадастровый, автомобильный.La prima definizione di registro nel dizionario è libro, quaderno e sim. dove si scrivono cose e fatti nell’ordine in cui avvengono, per memoria o documentazione: il r. delle entrate e delle spese. Altra definizione di registro è ente pubblico che si occupa dell’emissione e conservazione dei documenti che riguardano una determinata categoria di beni: r. navale. Registro è anche documento pubblico dove vengono annotati atti riguardanti beni e persone di rilevanza giuridica per renderli pubblici e per provarne l’esistenza: r. catastale, automobilistico.
Нажмите, чтобы посмотреть исходное определение слова «registro» в словаре итальянский языка. Нажмите, чтобы посмотреть автоматический перевод определения на русский языке.
СЛОВА, РИФМУЮЩИЕСЯ СО СЛОВОМ REGISTRO
Синонимы и антонимы слова registro в словаре итальянский языка
СИНОНИМЫ СЛОВА «REGISTRO»
Указанные слова имеют то же или сходное значение, что у слова «registro», и относятся к той же грамматической категории.синонимы слова registro
Перевод слова «registro» на 25 языков
ПЕРЕВОД СЛОВА REGISTRO
Посмотрите перевод слова registro на 25 языков с помощью нашего многоязыкового переводчика c итальянский языка. Переводы слова registro с итальянский языка на другие языки, представленные в этом разделе, были выполнены с помощью автоматического перевода, в котором главным элементом перевода является слово «registro» на итальянский языке.Переводчик с итальянский языка на
китайский язык 注册1,325 миллионов дикторов
Переводчик с итальянский языка на
испанский язык registro570 миллионов дикторов
Переводчик с итальянский языка на
английский язык register510 миллионов дикторов
Переводчик с итальянский языка на
хинди язык रजिस्टर380 миллионов дикторов
Переводчик с итальянский языка на
арабский язык تسجيل280 миллионов дикторов
Переводчик с итальянский языка на
русский язык регистр278 миллионов дикторов
Переводчик с итальянский языка на
португальский язык registrar270 миллионов дикторов
Переводчик с итальянский языка на
бенгальский язык রেজিস্টার260 миллионов дикторов
Переводчик с итальянский языка на
французский язык s´inscrire220 миллионов дикторов
Переводчик с итальянский языка на
малайский язык mendaftar190 миллионов дикторов
Переводчик с итальянский языка на
немецкий язык registrieren180 миллионов дикторов
Переводчик с итальянский языка на
японский язык 登録130 миллионов дикторов
Переводчик с итальянский языка на
корейский язык 레지스터85 миллионов дикторов
Переводчик с итальянский языка на
яванский язык ndhaftar85 миллионов дикторов
Переводчик с итальянский языка на
вьетнамский язык đăng ký80 миллионов дикторов
Переводчик с итальянский языка на
тамильский язык பதிவு75 миллионов дикторов
Переводчик с итальянский языка на
маратхи язык नोंदणी75 миллионов дикторов
Переводчик с итальянский языка на
турецкий язык kayıt70 миллионов дикторов
итальянский registro
65 миллионов дикторов
Переводчик с итальянский языка на
польский язык zarejestrować50 миллионов дикторов
Переводчик с итальянский языка на
украинский язык регістр40 миллионов дикторов
Переводчик с итальянский языка на
румынский язык registru30 миллионов дикторов
Переводчик с итальянский языка на
греческий язык μητρώο15 миллионов дикторов
Переводчик с итальянский языка на
африкаанс язык registreer14 миллионов дикторов
Переводчик с итальянский языка на
шведский язык registrera10 миллионов дикторов
Переводчик с итальянский языка на
норвежский язык registrer5 миллионов дикторов
Тенденции использования слова registro
ТЕНДЕНЦИИ ИСПОЛЬЗОВАНИЯ ТЕРМИНА «REGISTRO»
ЧАСТОТНОСТЬ
Слово используется очень часто
На показанной выше карте показана частотность использования термина «registro» в разных странах. Тенденции основных поисковых запросов и примеры использования слова registro Список основных поисковых запросов, которые пользователи ввели для доступа к нашему онлайн-словарю итальянский языка и наиболее часто используемые выражения со словом «registro».
ЧАСТОТА ИСПОЛЬЗОВАНИЯ ТЕРМИНА «REGISTRO» С ТЕЧЕНИЕМ ВРЕМЕНИ
На графике показано годовое изменение частотности использования слова «registro» за последние 500 лет. Формирование графика основано на анализе того, насколько часто термин «registro» появляется в оцифрованных печатных источниках на итальянский языке, начиная с 1500 года до настоящего времени.
Примеры использования в литературе на итальянский языке, цитаты и новости о слове registro
ЦИТАТЫ СО СЛОВОМ «REGISTRO»
Известные цитаты и высказывания со словом registro. Henri de Toulouse-LautrecDipingo le cose come stanno. Io non commento. Io registro.
Perché cos’è la storia se non… un registro dei crimini e dei dolori che l’uomo ha inflitto agli altri uomini? É un colossale libello sulla natura umana.
La paura della sessualità è il nuovo registro dell’universo di paura, sponsorizzato dalla malattia, in cui ognuno vive.
Ho fatto dare a quella stella il tuo nome. È ufficiale sul registro astronomico mondiale. Ti amo.
Non lasciarti sfuggire alcun pensiero, e tieni il tuo taccuino come le autorità tengono il registro dei forestieri.
Io non diventerò mai famosa. Il mio nome non sarà mai scritto in grande sul registro di coloro che Fanno le Cose. Io non faccio niente. Non una singola cosa. Ero solita mangiarmi le unghie ma ora non faccio più neanche quello.
КНИГИ НА ИТАЛЬЯНСКИЙ ЯЗЫКЕ, ИМЕЮЩЕЕ ОТНОШЕНИЕ К СЛОВУ
«REGISTRO» Поиск случаев использования слова registro в следующих библиографических источниках. Книги, относящиеся к слову registro, и краткие выдержки из этих книг для получения представления о контексте использования этого слова в литературе на итальянский языке.A teacher’s diary of a year of upper-school life, narrating classroom episodes, teacher/pupil relationships, problems, hopes, indifference.
2
Cessione e conferimento d’aziendaComplesso aziendale e complesso di beni L’esclusione dal campo di applicazione dell’IVA non rende le cessioni d’azienda fiscalmente irrilevanti: le cessioni d’azienda scontano l’imposta di registro. Vige, con alcune eccezioni, il » principio di …
3
Cessione, conferimento, affitto e donazione d’azienda2 IMPOSTA DI REGISTRO L’art. 4 della Tariffa, Parte prima, allegata al DPR 26.4. 86 n. 131 prevede l’applicazione dell’imposta di registro, nella misura fissa di 168 ,00 euro, per i conferimenti di aziende o di complessi aziendali relativi a …
In linea generale, per queste (registro, successioni, donazioni) opera la riscossione frazionata: quindi, in caso di accertamenti impugnati, l’ufficio non è legittimato ad iscrivere a ruolo la totalità delle somme, ma deve attenersi alle graduazioni …
Alfio Cissello, Pasquale Saggese, 2010
5
Sing!: Tecnica Vocale, Stile VocaleSia la voce femminile che la voce maschile hanno due distinti «registri» o «qualità» sonore: il registro grave e il registro acuto. Il registro grave viene anche chiamato: voce di petto, voce grave, voce del parlato, modale, voce da contralto e belt …
Elisabeth Howard, Alfred Publishing, 2007
6
Registrami mil registro. Da Windows 3.0 a Windows 7. Il …Abbiamo appena detto che il registro di sistema è costituito da più files, ma parlare del registro come fosse un file sarebbe un pò riduttivo, la definizione che meglio rappresenta il registro di sistema è la seguente : » IL REGISTRO DI SISTEMA …
7
Le massime del registro: notariato ed ipoteche55 della tariffa annessa alla legge sulle tasse di registro, nuovo testo unico del 20 maggio 1897, è cosi concepito : « Costituzione e surrogazione d’ipoteca o pegno in garanzia di obbligazioni anteriormente contratte dallo stesso costituente o …
8
Collezione delle leggi, dei regolamenti e delle decisioni …Vedi U[fizio di registro. Ulllzi d’lnslnuazione. — Vedi Uffizio di registro. Uflizio di registro. — L’ultimo giorno utile per la denunzia si compie coll’ora stabilita per la chiusura dell’ufficio di registro. — Art. 32. Le copie che si presentano per effetto della …
ITALY. Ministero delle Finanze, 1862
9
Dizionario generale del bollo e registro ipoteche, e diritti …Un registro per le trascrizioni dein atti di pignoramento dei beni immobili, e delle sentenze che ne avranno ordinata la vendita; V. Un registro per le denunzie dei vincoli fedecommrssari; VI. Un registro chiamato repertorio, e contenente il nome …
7.1 REGISTRO RIEPILOGATIVO I registri delle fatture emesse, dei corrispettivi e degli acquisti (di cui agli artt. 23, 24 e 25 del DPR 633/72) possono essere suddivisi in più registri o “sezionali” (per tipo di attività, per territorio, per intermediari, …
Eutekne , Odetto Gianluca, Peirolo Marco, Gianluca Odetto, Marco Peirolo, 2010
НОВОСТИ, В КОТОРЫХ ВСТРЕЧАЕТСЯ ТЕРМИН «REGISTRO»
Здесь показано, как национальная и международная пресса использует термин registro в контексте приведенных ниже новостных статей.Leonforte. Cc dice NO su registro unioni di fatto
Fu un giovedì di luglio, turbato da fulmini e saette, che il Consiglio comunale di Leonforte chiamato a pronunciarsi sul registro delle unioni di … «Vivi Enna, Июл 15»
Programmi per Pulire il Registro
Il registro di windows è un componente molto importante e delicato del sistema in quanto è un registro dove vengono salvate delle chiavi, … «Tuttotech, Июл 15»
Registro tumori comunale, Miceli (M5S): il centro destra ha deciso …
«Un dato è certo: il centro destra rendese ha decretato l’inutilità del registro tumori comunale e, di conseguenza, lo ha cancellato dal dibattito … «CN24TV, Июл 15»
M5S: Il Consiglio comunale di Formigine approva il “registro delle …
Istituire un idoneo strumento denominato “registro delle unioni civili” al quale possano iscriversi in maniera volontaria cittadine e cittadini legati … «Sassuolo 2000, Июл 15»
Negoziazione assistita e separazione dei coniugi: niente imposta di …
19, l. n. 74 del 1987 in tema di “imposta di registro, di bollo e da ogni … 898, sono esenti dall’imposta di bollo, di registro e da ogni altra tassa”. «Altalex, Июл 15»
Registro anagrafe condominiale, intesa tra ingegneri e amministratori
“La Legge 220/2012 — ha ricordato il Presidente del CNI — ha istituito il registro dell’anagrafe condominiale che per l’Amministratore di … «EdilPortale, Июл 15»
MONOLITE, SCHIAVONE È SODDISFATTO: «REGISTRO L …
MONOLITE, SCHIAVONE È SODDISFATTO: «REGISTRO L’APERTURA DEL COMUNE, ANCHE GUGLIOTTI VUOLE ABBATTERLO». «ViViCastellaneta | la città a portata di click!, Июл 15»
Registro delle imprese, conservazione dei dati e “oblio”: questione …
Dedusse che tali dati, risultanti dal registro stesso, venivano trattati da società di informazione professionale e che, nonostante la propria … «IPSOA Editore, Июл 15»
IMPERIA. GLI IMPERIESI “SNOBBANO” IL REGISTRO DELLE …
GLI IMPERIESI “SNOBBANO” IL REGISTRO DELLE UNIONI CIVILI. A OTTO MESI DALL’ISTITUZIONE SOLO UNA COPPIA ISCRITTA/ ECCO … «IMPERIAPOST, Июл 15»
L’utilizzo del web marketing nelle imprese iscritte al registro delle …
La ricerca fotografa l’utilizzo del Web marketing nelle imprese iscritte al Registro delle imprese della provincia di Chieti, con un “Focus on: sulle … «Chietitoday, Июл 15»
ССЫЛКИ
« EDUCALINGO. Registro [онлайн]. Доступно на <https://educalingo.com/ru/dic-it/registro>. Дек 2021 ».
Select … Заявление о регистре — Visual Basic
- Статья .
- 4 минуты на чтение
Оцените свой опыт
да Нет
Любой дополнительный отзыв?
Отзыв будет отправлен в Microsoft: при нажатии кнопки «Отправить» ваш отзыв будет использован для улучшения продуктов и услуг Microsoft.Политика конфиденциальности.
Представлять на рассмотрение
Спасибо.
В этой статье
Выполняет одну из нескольких групп операторов в зависимости от значения выражения.
Синтаксис
Выберите [Case] testexpression
[Список выражений регистра
[ заявления ] ]
[Case Else
[elsestatements]]
Конец Выбрать
Детали
| Срок | Определение |
|---|---|
экспрессия теста | Обязательно.Выражение. Должен соответствовать одному из элементарных типов данных ( Boolean , Byte , Char , Date , Double , Decimal , Integer , Long , Object , SByte , Short , Single , String , UInteger , ULong и UShort ). |
список выражений | Требуется в заявлении Case .Список предложений выражений, представляющих значения соответствия для testexpression . Пункты нескольких выражений разделяются запятыми. Каждое предложение может принимать одну из следующих форм: — выражение1 Используйте ключевое слово Используйте ключевое слово Форма, определяющая только выражение Выражения в |
ведомости | Необязательно. Один или несколько операторов после Case , которые выполняются, если testexpression совпадает с любым предложением в списке выражений . |
прочие | Необязательно. Один или несколько операторов после Case Else , которые выполняются, если testexpression не соответствует ни одному предложению в списке выражений ни одного из операторов Case . |
Выбор конца | Завершает определение конструкции Select ... Case . |
Примечания
Если testexpression соответствует любому предложению Case списка выражений , операторы, следующие за этим оператором Case , выполняются до следующего оператора Case , Case Else или End Select . Затем управление передается оператору, следующему за End Select .Если testexpression соответствует предложению списка выражений более чем в одном предложении Case , выполняются только операторы, следующие за первым совпадением.
Оператор Case Else используется для введения elsestatements для запуска, если не найдено совпадение между тестовым выражением и предложением списка выражений ни в одном из других операторов Case . Хотя это и не обязательно, рекомендуется иметь оператор Case Else в конструкции Select Case для обработки непредвиденных значений testexpression .Если ни одно предложение Case списка выражений не соответствует testexpression и нет оператора Case Else , управление передается оператору, следующему за End Select .
В каждом предложении Case можно использовать несколько выражений или диапазонов. Например, допустима следующая строка.
Варианты 1–4, 7–9, 11, 13, Is> maxNumber
Примечание
Ключевое слово Is , используемое в операторах Case и Case Else не то же самое, что оператор Is, который используется для сравнения ссылок на объекты.
Вы можете указать диапазоны и несколько выражений для символьных строк. В следующем примере Case соответствует любой строке, которая в точности равна «яблокам», имеет значение между «орехами» и «суп» в алфавитном порядке или содержит то же значение, что и текущее значение testItem .
Футляр "яблоки", "орехи" К "супу", testItem
Настройка Option Compare может повлиять на сравнение строк. В Option Compare Text строки «Яблоки» и «яблоки» сравниваются как равные, но в Option Compare Binary - нет.
Примечание
A Case Оператор с несколькими предложениями может демонстрировать поведение, известное как короткое замыкание . Visual Basic оценивает предложения слева направо, и если одно дает совпадение с testexpression , остальные предложения не оцениваются. Короткое замыкание может улучшить производительность, но может привести к неожиданным результатам, если вы ожидаете, что каждое выражение в списке выражений будет вычислено. Дополнительные сведения о коротком замыкании см. В разделе Логические выражения.
Если коду в блоке операторов Case или Case Else не требуется запускать какие-либо другие операторы в блоке, он может выйти из блока с помощью оператора Exit Select . Это немедленно передает управление оператору, следующему за End Select .
Select Case Конструкции могут быть вложенными. Каждая вложенная конструкция Select Case должна иметь соответствующий оператор End Select и должна полностью содержаться в одном блоке операторов Case или Case Else внешней конструкции Select Case , внутри которой она вложена.
Пример
В следующем примере используется конструкция Select Case для записи строки, соответствующей значению переменной number . Второй оператор Case содержит значение, которое соответствует текущему значению number , поэтому выполняется оператор, который записывает «Между 6 и 8 включительно».
Размерное число в виде целого числа = 8
Выберите номер дела
Случай с 1 по 5
Debug.WriteLine («От 1 до 5 включительно»)
'Следующее - единственное предложение Case, которое оценивается как True.Корпус 6, 7, 8
Debug.WriteLine («От 6 до 8 включительно»)
Случай с 9 по 10
Debug.WriteLine («Равно 9 или 10»)
Case Else
Debug.WriteLine («Не от 1 до 10 включительно»)
Конец Выбрать
См. Также
149 Синонимов и антонимов VALUE
1 сумма денег, за которую что-то найдет покупателя- Реальная стоимость этого дома близка к миллиону долларов
- Защита присущих демократической системе ценностей
- значение хорошего образования невозможно переоценить
- нация, которая ценит индивидуализм и самостоятельность
- проказник,
- умалять,
- плакать,
- декри,
- не рекомендуется,
- амортизировать,
- пренебрежительное отношение,
- поцелуй прочь,
- минимизировать,
- положено,
- списать
- оценивает своих акций в 150000 долларов или около того
Строка.prototype.includes () - JavaScript | MDN
Метод включает () Метод выполняет поиск с учетом регистра, чтобы определить, может ли одна строка
быть найденным в другой строке, возвращая true или false как
подходящее.
включает (searchString)
включает (searchString, position)
Параметры
-
searchString Строка, которую нужно искать в пределах
str.-
позицияДополнительно Позиция в строке, с которой следует начать поиск
searchString. (По умолчанию0.)
Возвращаемое значение
истинно , если строка поиска найдена где-нибудь в пределах
заданная строка; в противном случае ложно в противном случае.
Этот метод позволяет определить, включает ли строка другую строку.
Чувствительность к регистру
включает () метод чувствителен к регистру. Например, следующие
выражение возвращает false :
'Blue Whale'. Включает ('синий')
Этот метод был добавлен в спецификацию ECMAScript 2015 и не может быть пока доступен во всех реализациях JavaScript.
Однако вы легко можете полифилить этот метод:
if (! String.prototype.includes) {
Нить.prototype.includes = function (search, start) {
'использовать строго';
if (поиск экземпляра RegExp) {
throw TypeError ('первый аргумент не должен быть RegExp');
}
если (начало === undefined) {начало = 0; }
вернуть this.indexOf (поиск, начало)! == -1;
};
}
Использование
включает () const str = 'Быть или не быть, вот в чем вопрос.'
console.log (str.includes ('Быть'))
console.log (str.includes ('вопрос'))
console.log (str.includes ('несуществующий'))
консоль.журнал (str.includes ('Быть', 1))
console.log (str.includes ('БЫТЬ'))
console.log (str.includes (''))
Таблицы BCD загружаются только в браузере
Изменить регистр текста в Google Таблицах
Изменение регистра текста в Google Таблицах может показаться сложной задачей, поскольку в стандартном меню такой опции нет. Тем не менее, задача вполне разрешима. В этом сообщении в блоге я рассказываю о различных способах использования заглавных букв в ваших словах или их перевода в нижний, верхний регистр и регистр предложений.
Форматировать текст в Google Документах
Когда вы не можете найти простой способ изменить регистр в Google Таблицах, первая альтернатива, которая может прийти в голову, - это Google Docs - служба, в меню которой есть эта опция. Но поскольку вы находитесь в Таблицах, вам сначала нужно передать свои данные в Документы:
- Выберите свои записи в таблицах:
- Вы можете выбрать требуемый диапазон данных вручную.
- Выбрать все записи из одного столбца с помощью Ctrl + Shift + стрелка вниз
- Или выделите весь используемый диапазон с помощью Ctrl + A
- После выбора записей скопируйте их, нажав Ctrl + C
- Откройте новый документ Google и нажмите Ctrl + V, чтобы вставить туда скопированные данные.
- Затем выберите его еще раз, перейдите в Формат> Текст> Заглавные буквы , и там вы увидите 3 способа изменения регистра в Документах Google: нижний регистр, ВЕРХНИЙ регистр, регистр заголовка :
- Выберите нужный вариант, чтобы изменить регистр текста, а затем просто скопируйте и вставьте данные обратно в Google Таблицы:
Если вы спросите меня, этот способ может подойти, если у вас есть небольшой набор данных и несколько лишних минут для перемещения записей туда и обратно. Но если ни то, ни другое не касается вас, лучше использовать одну из альтернатив, предлагаемых Google Sheets, чтобы сразу же изменить регистр текста.
Функции Google Таблиц для изменения регистра
Функции - единственный стандартный способ изменить регистр в Google Таблицах. Будьте готовы подготовить дополнительные столбцы, в которые вам нужно будет ввести формулы и увидеть результат.
Функция ПРОПИСН - все слова должны быть прописными
Функция PROPER используется в Google Таблицах для использования заглавной буквы во всех словах в ячейке:
ПРАВИЛЬНЫЙ (text_to_capitalize)
Требуется только один аргумент: текст, в котором вы хотите изменить регистр, или ссылку на ячейку с этим текстом.
Поскольку мои данные находятся в столбце, я буду ссылаться на его ячейки, используя функцию Google Sheets PROPER в соседнем пустом столбце:
= НАДЛЕЖАЩИЙ (A2)
Как только я ввожу формулу, Google Таблицы предлагает скопировать ее для меня и сделать первые буквы во всех ячейках заглавными:
Вы можете нажать Ctrl + Enter или щелкнуть значок галочки, чтобы позволить электронным таблицам сделать это.
И вот, весь столбец в Google Таблицах, в котором первая буква каждого слова написана с заглавной буквы:
Вы можете пойти дальше и построить формулу массива, которая будет использовать каждое слово во всем столбце сразу с заглавной буквы:
= ArrayFormula (ПРАВИЛЬНЫЙ (A2: A9))
ВЕРХНИЙ функция
Следующее, что изменит регистр, - это функция ВЕРХНИЙ в Google Таблицах. Как вы уже догадались, каждый символ в ячейке пишется с заглавной буквы. Весь текст будет написан в верхнем регистре.
Также требуется только один аргумент - текст для преобразования в верхний регистр:
ВЕРХНИЙ (текст)
Я собираюсь ввести его в B2, ссылаясь на A2, а затем скопирую его также в столбец:
= ВЕРХНИЙ (A2)
Сделать текст в Google Таблицах заглавными буквами во всем столбце сразу с помощью одной формулы, поможет та же самая ArrayFormula:
= ArrayFormula (ВЕРХНИЙ (A2: A9))
Функция НИЖНИЙ
И последнее, но не менее важное, это функция НИЖНИЙ. Да, переводит весь текст в нижний регистр 🙂
Как и две вышеупомянутые функции, для этой также требуется всего одна вещь: текст или ссылка на ячейку с текстом:
НИЖНИЙ (текст)
Давайте изменим регистр в том же столбце верхнего регистра Google Sheets из приведенного выше примера. На этот раз я переведу его в нижний регистр:
= НИЖНИЙ (A2)
И даже если вы это уже знаете, я все равно покажу вам, как это выглядит, когда ArrayFormula автоматически заполняет все ячейки в указанном вами диапазоне с результатом:
= ArrayFormula (НИЖНИЙ (A2: A9))
Применение регистра с использованием функций
Падеж - еще один способ представления вашего текста. Если вы хотите, чтобы ваши ячейки отображались в виде предложений, это означает, что вы хотите, чтобы Google Таблицы делали только первую букву каждой ячейки заглавной, не меняя регистр других букв.
К сожалению, в электронных таблицах нет специальной функции, как, например, для правильного ввода текста.
Тем не менее, существует комбинация других функций для Google Таблиц, которые создают формулу, которая в конечном итоге использует только первую букву в ячейках.Я не собираюсь врать - это не самый простой способ и определенно требует обучения.
Позвольте мне сначала показать вам формулу, а затем я объясню, как она работает:
= JOIN (".", ArrayFormula (REPLACE (TRIM (SPLIT (A2, ".")), 1,1, UPPER (LEFT (TRIM (SPLIT (A2, ".")), 1)))) )
Я продублировал содержимое некоторых ячеек (так что есть предложения) и выделил их серым цветом, чтобы вы могли лучше понять, что происходит до изменения регистра (см. Ячейки A2, A6, A9 на скриншоте выше):
- Если в ячейке несколько предложений, SPLIT (A2, ".") делит их на отдельные ячейки точкой.
- Затем TRIM складывает эти предложения и удаляет все лишние пробелы.
- Часть в конце формулы - UPPER (LEFT (TRIM (SPLIT (A2, ".")), 1)) - не только разделяет содержимое, но также извлекает и делает заглавными только первую букву ( LEFT больше одного) каждого предложения.
- REPLACE - хорошо - заменяет первые строчные буквы всех предложений их эквивалентами в верхнем регистре.
- Когда предложения разбиты, Google Таблицы видит их как массив ячеек. Чтобы убедиться, что все разделенные предложения обработаны, я оборачиваю все в ArrayFormula .
- И, наконец, JOIN собирает эти отдельные предложения обратно в свои ячейки.
Если эта формула еще заставляет откладывать дела на потом - я тебя чувствую. Последний метод, которым я поделюсь с вами, намного проще. На самом деле это мой любимый вариант, так как для изменения регистра текста мне нужно всего лишь выбрать диапазон и нажать две кнопки.Приходите посмотреть.
Надстройка для смены регистра для Google Таблиц
Независимо от того, какую формулу вы используете, все они - простые и сложные - требуют размещения дополнительного столбца. А если позже вы превратите эти формулы в редактируемые значения, это потребует еще больше времени и усилий.
К счастью, у нас есть простейшее решение без формул для изменения регистра текста в Google Таблицах: надстройка Power Tools. Это коллекция из более чем 30 утилит для работы с электронными таблицами, в которую входит инструмент «Изменить регистр».
Наконечник. Посмотрите это видео, чтобы лучше узнать инструмент, не стесняйтесь читать краткое введение прямо под ним.Изменить регистр в Google Таблицах с помощью этого дополнения очень просто:
- Выберите диапазон.
- Выберите нужный корпус:
- Нажмите Выполните .
Смотрите сами, за несколько секунд поменяю корпус всеми 5 способами:
Примечание. Когда вы решите применить Sentence case , будет использоваться только первая буква каждой ячейки / предложения.Он не будет опускать другие буквы, чтобы не повредить какие-либо сокращения или имена, которые у вас могут быть. Если вы все равно хотите уменьшить все остальные буквы, вам нужно сначала применить в нижнем регистре .
В дополнение к 4 случаям, которые могут быть покрыты формулами - регистр предложений, вводить каждое слово с заглавной буквы (правильный регистр), верхний и нижний регистр - мы также делаем возможным ПЕРЕКЛЮЧЕНИЕ ТЕКСТА. Это означает изменение всех букв с верхнего регистра на нижний и наоборот.
Надстройка даже имеет пару дополнительных настроек:
- Игнорировать сокращения. позаботится об акронимах, если таковые имеются, для параметра Заглавные буквы в каждом слове .
- Игнорировать формулы будет пропускать ячейки с формулами (для всех 5 случаев), чтобы не преобразовывать их в значения.
При выборе надстройки - нет лишних столбцов, нет формул, нет необходимости преобразовывать формулы в значения. Процесс максимально прост и понятен.
Вы можете установить Power Tools из Google Store и попробовать изменить регистр текста в Google Таблицах самостоятельно. Эти инструкции также помогут вам.
Какой бы способ вы ни выбрали, если у вас есть какие-либо вопросы по этому поводу, задавайте их в разделе комментариев ниже.
Вас также может заинтересовать:
Случай для эффекта Мэтью
Существуют большие различия между отдельными детьми в их словарном запасе при поступлении в школу (например, Hart & Risley, 1995), и эти различия в словарном запасе распространяются и на школьные годы. Например, Бимиллер и Сломин (2001) сообщили, что во втором классе у детей из нижнего квартиля по словарному запасу было примерно вдвое меньше известных слов по сравнению с учащимися из верхнего квартиля.Более того, согласно модели эффекта Мэтью, предложенной Становичем (1986, 2000), эти индивидуальные различия в словарном запасе могут даже увеличиваться со временем. Термин Эффект Матфея относится к библейскому тексту и первоначально был предложен для описания прогресса научных исследований (Merton, 1968), в котором накапливаются преимущества и недостатки, так что богатые становятся еще богаче, а бедные - беднее. Что касается чтения, общая предпосылка модели эффекта Мэтью заключается в том, что индивидуальные различия в навыках чтения (в широком смысле) могут накапливаться со временем (Станович, 1986, 2000), так что начальный уровень чтения ребенка будет положительно связан с его или ее. скорость роста навыка чтения.Этот паттерн, при котором темпы роста различаются в зависимости от уровня навыков, даже если абсолютный уровень навыков повышается для всех, считается относительным эффектом Мэтью (Rigney, 2010). Накопление достоинств и недостатков, конечно, лишь один из возможных вариантов развития. Компенсаторная модель предсказывает, что начальный уровень чтения будет отрицательно связан со скоростью роста навыков чтения, так что различия в навыках чтения со временем будут уменьшаться, что фактически противоположно эффекту Мэтью (Pfost, Hattie, Dorfler, & Artelt, 2014). .Третья возможность - это стабильная модель достижений, при которой высококвалифицированные и низкоквалифицированные читатели имеют одинаковые темпы роста по мере развития (Pfost et al., 2014).
Это исследование касается одного конкретного предсказания модели эффекта Мэтью, а именно, что навыки чтения в целом и навыки чтения слов в частности могут быть связаны со скоростью увеличения словарного запаса. Словарный запас тесно связан с множеством академических, профессиональных и социальных результатов (Dollinger, Matyja, & Huber, 2008; Gertner, Rice, & Hadley, 1994; Rohde & Thompson, 2007).Правдивость этого предсказания модели эффекта Мэтью значительна, поскольку она может помочь направлять вмешательства для детей из группы риска плохого развития словарного запаса. Настоящее исследование включает детей, отобранных в результате крупного эпидемиологического исследования, в которое входят дети с языковыми и когнитивными нарушениями.
Роль чтения в развитии словарного запаса
Предположение о том, что навыки чтения могут быть связаны со скоростью роста словарного запаса, основано на предположении, что развитие чтения потенциально может иметь значительное влияние на знакомство ребенка с новыми словами.Фактически, есть эмпирические доказательства того, что у детей старшего возраста и взрослых большая часть усвоения новых слов происходит через знакомство с письменными текстами (Nagy, Herman, & Anderson, 1985; Sternberg, 1987). Поскольку печатные материалы обычно содержат гораздо больше редко встречающихся слов, чем разговорная речь (Cunningham, 2005), чтение текста может предоставить ключевые возможности для развития словарного запаса. Мы прогнозируем, что изучение слов посредством чтения повлияет на словарный запас, измеряемый как в устных, так и в письменных задачах, потому что слова, выученные в процессе чтения текста, будут, по крайней мере, частично доступны человеку как для письменного, так и для устного использования языка (Nelson, Michal, & Perfetti, 2005). .
Однако знакомство с новыми словами в тексте не происходит равномерно в процессе развития чтения. До формального обучения грамоте дети явно приобретают новый словарный запас через устную речь. Во время раннего развития чтения дети редко сталкиваются со словами в печатном тексте, которых еще нет в их словарном запасе, поэтому большая часть лексических знаний слов, особенно фонологических и семантических представлений, будет получена из опыта устной речи. По мере того, как дети становятся более опытными в чтении и переходят к более сложным печатным материалам, они с большей вероятностью будут сталкиваться со словами во время чтения, которые они не слышали при прослушивании.Этот переход, вероятно, происходит у многих учеников примерно в третьем или четвертом классе (Chall, 1987). Бимиллер (2005), например, сообщил, что начиная с третьего класса, но не в младших классах, 95% детей могли читать больше слов, чем они могли объяснить.
Существование эффекта Мэтью для словарного запаса
Согласно одному из предсказаний модели эффекта Мэтью, на развитие словарного запаса после третьего или четвертого класса будет влиять способность к чтению и связанный с этим опыт чтения, обеспечиваемый этими навыками чтения.Это исследование исследует довольно простой прогноз относительно развития словарного запаса и чтения в средних и старших классах школы. Мы прогнозируем, что лучшие читатели в это время с большей вероятностью столкнутся с новыми, низкочастотными словами, чем слабые читатели, и что это повлияет на скорость роста словарного запаса. Этот прогноз основан на представлении о том, что сильные читатели будут больше заниматься чтением, чем слабые. Это предположение согласуется с предложением Становича (1986) о том, что объем опыта чтения является ключевой переменной-посредником между навыками чтения (в широком понимании) и словарным запасом, с кумулятивными преимуществами, возникающими из-за «влияния объема чтения на рост словарного запаса в сочетании с большим объемом чтения. различия в навыках в объеме чтения »(стр.381). Существуют эмпирические данные, подтверждающие предположение, что навыки чтения и количество опыта чтения тесно связаны. Например, Аллингтон (1983) сообщил, что сильные читатели 1-го класса читают во время обучения чтению в три раза больше слов, чем слабые читатели. Надь и Андерсон (1984) предположили, что мотивированный ученик средней школы может читать в классе в 100 раз больше слов в год, чем менее квалифицированный или мотивированный ученик. Что касается чтения для удовольствия, Джуэл (1988) сообщил, что средние и сильные читатели в третьем и четвертом классах читают дома больше раз в неделю, чем слабые читатели, а Мартин-Чанг и Гулд (2008) сообщили о корреляции между скоростью чтения ( слов в минуту) и личный опыт чтения студентов бакалавриата.
Небольшое количество исследований ранее изучали эффект Мэтью со словарным запасом в качестве переменной результата. Aarnoutse и van Leeuwe (2000) сообщили, что слабые читатели продемонстрировали больший эффект в увеличении словарного запаса, чем сильные читатели в младших классах начальной школы, что заставило авторов усомниться в влиянии чтения Мэтью на словарный запас. Словарный запас измерялся в письменном формате; таким образом, способность к чтению могла сбить с толку словарный запас. Напротив, Каин и Окхилл (2011) сообщили, что у читателей со слабыми навыками понимания прочитанного наблюдались более низкие темпы роста словарного запаса в возрасте от 8 до 16 лет по сравнению с хорошо понимающими, и пришли к выводу, что существует эффект Мэтью для навыков чтения на словарный запас. .В этом случае словарный запас измерялся как по чтению слов, так и по лексике на слух. Аналогичным образом Кемпе, Эрикссон-Густавссон и Самуэльссон (2011) сообщили об эффекте Мэтью на рост словарного запаса в 1–3 классах, который измерялся устно с помощью Шкалы интеллекта Векслера для детей - третье издание (Wechsler, 1991). Кроме того, Stothard, Snowling, Bishop, Chipchase и Kaplan (1998) сообщили о снижении баллов по Британской шкале словарного запаса (Dunn, Dunn, Whetton, & Pintilie, 1982) в возрасте от 8 до 15 лет для детей, которые были классифицированы как наличие стойких специфических языковых нарушений и общей задержки, но не для детей, чей язык находится в ожидаемом диапазоне, или для детей, чьи ранние языковые проблемы разрешились к возрасту 5 лет.Ни в одном из этих исследований не использовалась шкала развития, чтобы уравнять сложность задания в разных возрастных группах. Кроме того, ни одно из вышеупомянутых исследований не контролировало скорость изучения словарного запаса до обучения грамоте. Разумно ожидать, что различные факторы, которые способствуют этим индивидуальным различиям в усвоении слов в раннем детстве, могут продолжать оказывать влияние на усвоение слов при чтении. На самом деле, есть существенные различия в успеваемости читателей (например,g., Hart & Risley, 1995), что повлияет на уровень словарного запаса, когда дети начнут учить новые слова с помощью письменной речи. Кроме того, можно ожидать, что эти индивидуальные различия в навыках изучения слов будут зависеть от навыков чтения, учитывая существенное совпадение между нарушениями чтения слов и языковых навыков (Catts, Adlof, Hogan, & Ellis Weismer, 2005). Чтобы изучить конкретное влияние опыта чтения на словарный запас, было бы разумно контролировать общие достижения ребенка в усвоении слов.Таким образом, доказательства влияния Матфея на словарный запас неоднозначны и, возможно, смешиваются со способностями к изучению слов в целом.
Вышеупомянутое обсуждение касается влияния навыков чтения на рост словарного запаса, что является лишь одним из предсказаний модели эффекта Мэтью. Другие предсказания модели также были проверены, с такими же двусмысленными результатами (Pfost et al., 2014). В некоторых исследованиях приводятся данные, подтверждающие наличие эффекта Мэтью в отношении способности к чтению (Juel, 1988), но другие сообщают о стабильной модели достижений (Aarnoutse & van Leeuwe, 2000; Catts, Adlof, & Fey, 2003; Scarborough & Parker, 2003; Shaywitz et al. al., 1995) или компенсаторный эффект (Parrila, Auonola, Leskinen, Nurmi, & Kirby, 2005; Shaywitz et al., 1995). Разнообразие результатов этих исследований, несомненно, связано с большим разнообразием переменных результатов и возраста читателей, а также с характеристиками группы выборки и методологий исследования. Действительно, в некоторых исследованиях делаются разные выводы на основе изученной переменной результата (Bast & Reitsma, 1998; Shaywitz et al., 1995), рассматриваемой подгруппы детей (Jacobson, 1999; Morgan, Farkas, & Hibel, 2008). ; Филлипс, Норрис, Осмонд и Мейнард, 2002; Стотхард и др., 1998), и даже язык, на котором дети учились читать (Parrila et al., 2005). Кроме того, недавний метаанализ (Pfost et al., 2014) пришел к выводу, что психометрические свойства показателей также важны: исследования, в которых использовались показатели без эффектов потолка или потолка и с хорошей надежностью, с большей вероятностью сообщали о присутствии Мэтью эффект. Наконец, изучаемые группы населения могли различаться по количеству или виду полученного вмешательства. Следовательно, хотя модель эффекта Мэтью была очень полезной основой для исследователей, преподавателей и клиницистов, доказательства ее остались неуловимыми (Pfost et al., 2014; Скарборо и Паркер, 2003).
Там, где сообщается об эффекте Мэтью, существует более одного возможного паттерна, потому что влияние начального навыка чтения на последующие темпы роста может не обязательно быть одинаковым во всем континууме навыка чтения (Protopapas, Sideridis, Mouzaki, & Simos, 2011 ; Ригни, 2010). С одной стороны, сильные читатели могут показывать увеличивающийся выигрыш по сравнению со средними читателями, в то время как слабые читатели демонстрируют меньший выигрыш по сравнению со средними читателями.Мы называем это двусторонним эффектом Мэтью . С другой стороны, сильные читатели могут показывать больший выигрыш по сравнению со средними читателями, тогда как слабые читатели имеют прирост, аналогичный по размеру таковым у средних читателей. Возможна и обратная картина, когда слабые читатели показывают более медленные темпы роста, чем средние читатели, а сильные читатели показывают более высокие темпы роста (например, Morgan et al., 2008). Эти последние две возможности были названы односторонними эффектами Мэтью (Morgan et al., 2008), и мы их так и описываем.
Очевидно, что выбор переменных результата и предиктора имеет решающее значение при тестировании эффекта Мэтью. Предложение Становича (1986) о чтении и словарном запасе рассматривало чтение в широком смысле. В этом исследовании чтение слов (не слов и отдельных слов) используется для практического применения навыков чтения. Обоснование использования навыка чтения слов в качестве переменной-предиктора проста в том, что ожидается, что он будет меньше путаться со словарным запасом, чем оценки понимания прочитанного, потому что оценки понимания прочитанного и словарного запаса сильно коррелированы (например,г., Пирсон, Хиберт и Камил, 2007). Таким образом, использование оценок за чтение слов позволяет более четко интерпретировать данные. Точно так же словарный запас можно определять по-разному, в том числе в рецептивных и выразительных измерениях. Набор данных, используемый в этом исследовании, ранее был проанализирован на предмет восприимчивой / экспрессивной размерности с использованием пересмотренного модифицированного параллельного анализа и подтверждающего факторного анализа (Tomblin & Zhang, 2006). Этот анализ пришел к выводу, что меры, использованные в исследовании, «вряд ли смогут отразить достоверные различия между людьми в отношении рецептивных и экспрессивных модальностей» (стр.1206). Следовательно, несмотря на использование разных заданий для измерения рецептивного и экспрессивного словарного запаса в этом исследовании, измеряемая латентная черта, по-видимому, не отличается. Таким образом, в этом исследовании словарный запас операционализируется как совокупный балл, включающий как рецептивные, так и выразительные меры.
Вопросы для изучения
В этом исследовании будет проверено конкретное предсказание о том, что скорость увеличения словарного запаса связана с навыками чтения, путем изучения роста устного словарного запаса на эпидемиологической выборке между четвертым и десятым классами среди детей с широким диапазоном способностей к чтению. , установлен в четвертом классе.Первый конкретный вопрос этого исследования: есть ли доказательства того, что умение читать слова в четвертом классе связано со скоростью изменения словарного запаса между четвертым и десятым классами после учета индивидуальных различий в уровне усвоения словарного запаса до чтения? инструкция? В текущем исследовании словарный запас в детском саду используется как мера этих индивидуальных различий в изучении слов до формального обучения чтению. Гипотеза, основанная на модели Становича (1986), заключается в том, что будет существовать взаимосвязь между навыками чтения в четвертом классе и скоростью увеличения словарного запаса в годы между четвертым и десятым классами.
Второй конкретный вопрос этого исследования: если существует связь между навыками чтения и увеличением словарного запаса, одинакова ли эта связь как для сильных, так и для слабых читателей? Другими словами, если эффект Мэтью существует, это односторонний или двусторонний эффект Мэтью? В этом исследовании не было гипотезы по второму вопросу, потому что ни одно предыдущее исследование не рассматривало этот конкретный вопрос, и может быть какая-то причина ожидать двустороннего или одностороннего эффекта Мэтью.Как указал Шефелбин (1990), читатели с более низким начальным словарным запасом обязательно будут иметь обедненный семантический контекст для вывода нового значения слова, что может привести к более низким темпам роста словарного запаса. С другой стороны, те же самые читатели с меньшей вероятностью столкнутся с эффектами потолка, потому что любой конкретный текст с большей вероятностью будет включать слова, которые для них в новинку. Однако этот аргумент Шефелбина (1990) касается влияния начального словарного запаса на рост словарного запаса.Это контрастирует с текущим исследованием, в котором рассматривается взаимосвязь навыков чтения и увеличения словарного запаса.
Метод
Образец
Данные, проанализированные в настоящем исследовании, были взяты из выборки из 604 участников, которые первоначально принимали участие в эпидемиологическом исследовании языковых нарушений (Tomblin et al., 1997). Первоначальная эпидемиологическая выборка участвовала в 1993–1994 учебном году и состояла из 7 218 учащихся детских садов, представляющих всех имеющихся учащихся детских садов, которые говорили на одном языке по-английски в выбранных школах в сельских, городских и пригородных районах Айовы и Иллинойса.В этой исходной выборке использовалась стратифицированная кластерная выборка со стратификацией по месту жительства и кластерной выборкой по школе (Tomblin, 2014). Всем студентам, которые не прошли первоначальный скрининг, была предоставлена диагностическая батарея языковых и когнитивных показателей, как и репрезентативная выборка студентов, прошедших скрининг, так что группа, прошедшая скрининговую батарею, и группа, которая не прошла, были одинакового размера. Каждый из этих участников был привлечен к участию в лонгитюдном исследовании, и все, кто согласился, стали участниками лонгитюдного исследования.В эту выборку были включены все дети, завершившие лонгитюдное исследование и у которых имелся словарный запас ( n = 485). Дети в четвертом классе в среднем составляли 10,0 лет ( SD = 0,40), а в 10-м классе - 15,8 лет ( SD = 0,37).
Первоначальная выборка из 485 детей включала избыточную выборку детей с плохими языковыми способностями. Поскольку эта передискретизация систематически применялась к выборке населения, было возможно получить систему взвешивания, которая скорректировала бы это; то есть оценки были взвешены путем умножения баллов каждого ребенка на константу, равную ожидаемой распространенности этой диагностической категории и пола, разделенной на фактическую распространенность этих детей в выборке.Таким образом, дети с плохим языком получили пропорционально меньший вес в анализах, чем дети, которые демонстрировали типичный язык, процедура взвешивания была описана в других опубликованных работах с участием этой выборки (Catts et al., 1999, 2005). Итоговая выборка из 485 детей содержала равное соотношение мальчиков и девочек (по 50% каждого). Уровень образования матерей распределялся следующим образом: 4% имели менее 4-летнее среднее образование, 28% имели аттестат средней школы, 41% имели высшее образование, 15% были выпускниками колледжей и 12% имели послевузовское образование. образование.
Как показано на, стандартизированные языковые показатели в четвертом классе и IQ успеваемости, измеренные во втором классе до взвешивания, были ниже ожидаемых средних значений для генеральной совокупности. Однако после взвешивания образцов они очень репрезентативны для нормальной популяции. В текущем исследовании используются данные всех участников с взвешенными показателями для всех анализов.
Таблица 1.
Описательная статистика выборки в отношении показателей устной речи в четвертом классе и IQ успеваемости, полученного во втором классе.
| Тест (источник; ожидаемое среднее значение по совокупности) | Средневзвешенное значение ( SD ) | Невзвешенное среднее ( SD ) |
|---|---|---|
| Шкала интеллекта Векслера для детей - пересмотренная: шкала успеваемости (Wechsler, 1991; 100) | 100 (15) | 95,39 (14,80) |
| Пибоди-тест по словарному запасу - пересмотренный (Данн и Данн, 1981; 100) | 102,83 (15,52) | 95,40 (16,07) |
| Клиническая оценка основ языка - третье издание: вспоминая предложения (Semel, Wiig, & Secord, 1996; 10) | 10.34 (3,1) | 8,86 (3,14) |
| Клиническая оценка основ языка - третье издание: концепции и устные указания (Semel, Wiig, & Secord, 1996; 10) | 10,34 (3,2) | 8,50 (3,08 ) |
Задачи
Все задачи выполнялись в рамках более крупного продольного исследования (полное описание см. В Tomblin & Nippold, 2014). Администрирование задач было стандартизировано, и каждый экзаменатор прошел детальное обучение и мониторинг со стороны менеджера по сбору данных, при этом как минимум 5% экзаменов оценивались вслепую как экзаменатором, так и менеджером по сбору данных, чтобы обеспечить единообразие в выставлении оценок. как в администрации (Томблин, 2014).Оценка всех заданий производилась относительно возраста ребенка на момент тестирования.
Словарь
Для настоящего исследования были проанализированы следующие показатели словарного запаса: в детском саду подтесты по идентификации изображений и устной лексике Теста на развитие языка - начальное: второе издание (Newcomer & Hammill, 1988) и в старших классах , Пересмотренный словарный тест в картинках Пибоди (PPVT-R; Dunn & Dunn, 1981), а также экспрессивный субтест Комплексного рецептивного и экспрессивного словарного теста (CREVT; Wallace & Hammill, 1994).Меры рецептивного словарного запаса представляли собой задачи по идентификации изображений, а меры выразительного словарного запаса - это задачи по созданию определений. Каждый из них является хорошо зарекомендовавшим себя стандартизированным показателем, и информация об их достоверности, относящаяся к этому набору данных, была опубликована (Tomblin, Nippold, Fey, & Zhang, 2014).
Чтение
В рамках настоящего исследования были проанализированы следующие показатели чтения: подтесты Word Attack (WA) и Word Identification (WI) в пересмотренном тесте Woodcock Reading Mastery Test (Woodcock, 1987), которые включают чтение неслов (WA). ) и прицельные слова (WI).Эти меры считаются надежной оценкой навыков чтения слов (Cooter, 1989).
Анализ
Совокупные баллы способностей к развитию
Анализ роста когнитивных способностей, таких как словарный запас, требует, чтобы успеваемость детей оценивалась по континууму в течение интересующего периода развития. Основная проблема при создании шкалы развития состоит в том, что способности детей должны оцениваться с помощью различных элементов в разные моменты времени развития; таким образом, в процессе разработки элементы должны быть значимым образом приравнены друг к другу.В этом исследовании оценки способностей к развитию были рассчитаны с использованием модели Раша теории ответов на вопросы (IRT). Полученные результаты часто рассматриваются как хорошо подходящие для моделирования кривой роста (O'Malley, Francis, Foorman, Fletcher, & Swank, 2002). В рамках IRT вероятность того, что элемент будет пройден в тесте, зависит от уровня способностей участника, сложности элемента, а также от его различения и вероятности угадывания. При калибровке (Mislevy & Bock, 1998) предположение может быть установлено как константа, а вероятность для заданных пунктов может быть рассчитана на основе введения тестовых заданий участникам.Таким образом, сложность задания можно рассчитать, считая способности экзаменуемого постоянными. Это называется калибровкой объекта (Mislevy & Bock, 1998). Задания, которые применялись в более чем одном классе и которые имели общий процент успешных ответов от 10% до 90%, использовались в качестве якорей (Vale, 1986) для калибровки этого задания. Эти элементы привязки затем использовались для калибровки сложности элемента по возрастным уровням. Например, если задания 8 и 9 были даны ученикам четвертых классов, а задания 9 и 10 - восьмиклассникам, то пункты 8 и 10 могут быть откалиброваны через их наложение с заданием 9 по всем классам.предоставляет список конкретных заданий из PPVT-R и CREVT для каждого уровня обучения, использованного при калибровке задания, что приводит к оценке словарных способностей по шкале Раша для четвертого-десятого классов. Сложность и различающие оценки для этих заданий, а также оценки выразительной и восприимчивой лексики для каждого экзаменуемого на каждом уровне обучения были рассчитаны с использованием компьютерной программы Bilog (Mislevy & Bock, 1998). Параметры элемента были определены с использованием оценки предельного максимального правдоподобия.Значение 0 на шкале было установлено для среднего шестилетнего ребенка. Полученные в результате оценки способностей позволили измерить способности испытуемых с течением времени.
Таблица 2.
Пункты из Пересмотренного словарного теста Peabody Picture (PPVT-R) и Комплексного рецептивного экспрессивного словарного теста (CREVT), используемых при калибровке заданий.
| Образцы для испытаний | Класс | ||||
|---|---|---|---|---|---|
| 4-й | 8-й | 10-й | Количество элементов | ||
| PPVT-R | |||||
| 80–83 | 908 | 4 | |||
| 85 | X | 1 | |||
| 86–94 | X | 9 | |||
| X | X | 14 | |||
| CREVT | |||||
| 2 и 3 | 2 | ||||
| 4–10 | X | 7 | |||
| 11–15 | X | X | X | 5 | 9 0045|
| 16 и 17 | X | X | X | 2 | |
| 18–24 | X | X | 7 | ||
Весовые баллы Как описано выше, при анализе этого исследования использовались взвешенные баллы для корректировки высокого уровня языковых и / или когнитивных нарушений.Эта процедура взвешенной оценки возможна благодаря доступности данных из тщательно отобранного пула участников эпидемиологической выборки. Это гарантирует, что данные, проанализированные в этом исследовании, являются репрезентативными для эпидемиологической выборки, включая детей с языковыми нарушениями в анамнезе и без них.
Составные баллы
Составные баллы были получены для словарного запаса каждого участника, как обсуждалось ранее. Комбинированный показатель представлял собой среднее значение оценок способности к развитию восприимчивой и выразительной лексики.Эти составные баллы использовались для построения кривых роста словарного запаса.
Аналогичным образом, общий балл за чтение слов был рассчитан на основе оценок WA и WI в четвертом классе. Комбинация этих оценок использовалась для объединения ранее развившегося навыка чтения неслов с более поздним развивающимся навыком бесконтекстного распознавания слов (Tunmer & Chapman, 2012). В контексте данного исследования эти навыки использовались для индексации базовых навыков чтения в четвертом классе. Мы ожидаем, что эти навыки также косвенно указывают на объем и разнообразие навыков чтения, которые эти дети получат после четвертого класса.Это предположение подтверждается метаанализом, проведенным Молом и Басом (2011), который показал умеренную корреляцию между воздействием печати и показателями WI и WA в течение младших школьных лет. Поскольку оценки чтения слов были частью анализа только в один момент времени, оценки развития не требовались.
Многоуровневое моделирование . Для проверки вопросов в этом исследовании использовалось многоуровневое моделирование, метод, который, как ожидается, даст сопоставимые результаты с анализом скрытой кривой роста (Chou, Bentler, & Pentz, 1998).Многоуровневое моделирование взвешенных данных в этом исследовании заключалось в подборе словарных способностей каждого участника для четвертого, восьмого и десятого классов с параметрами точки пересечения и линейного наклона. Эти параметры служили случайными эффектами в сочетании с фиксированным эффектом чтения слов в четвертом классе, а также с ковариатой словарного запаса детского сада и их взаимодействием со временем (возрастом) в смешанном модельном анализе с использованием программного обеспечения Proc Mixed (SAS Institute, 2011). .
Особый интерес представлял вопрос, различается ли наклон словарного запаса в соответствии с вариациями в чтении слов в четвертом классе.Тем не менее, можно утверждать, что любая связь между чтением слов и увеличением словарного запаса в более поздние школьные годы возникла просто потому, что те, кто хорошо усваивает слова, становятся сильными читателями. В той степени, в которой это так, основание для отношений не может быть связано с особым влиянием чтения на словарный запас. Чтобы решить эту проблему, мы также включили словарные способности детей в детском саду в этот анализ в качестве ковариаты в этой модели как по наклону, так и по точке пересечения. Это обеспечивает проверку того, связано ли чтение слов со словарным запасом, после проверки успеваемости детей в усвоении слов в течение лет, предшествовавших формальному обучению чтению.Это считалось прямой проверкой долговременной взаимосвязи между навыком чтения слов и развитием словарного запаса.
Поскольку чтение слов было связано со скоростью увеличения словарного запаса, мы вычислили размер эффекта в форме f 2 , что отражает величину вариации индивидуальных различий в словарном запасе, объясняемую чтением в четвертом классе после контроль словарного запаса детского сада. Этот показатель влияния чтения на рост словарного запаса касается различий в наклонах.Ключевой особенностью дифференцированных темпов роста является то, что индивидуальные различия накапливаются с течением времени; таким образом, влияние переменной-предиктора - в данном случае чтения в четвертом классе - на переменную результата, вероятно, усилится. Поэтому мы измерили степень связи между способностью читать слова четвертым классом и словарным запасом 10-го класса после проверки словарного запаса четвертого класса.
Индивидуальные различия в росте словарного запаса . В вопросе 2 спрашивалось, одинаково ли влияние чтения слов в четвертом классе на рост словарного запаса распределяется по всему диапазону способностей к чтению слов.Для этого были сопоставлены темпы роста между тремя группами детей, разделенными на категории в зависимости от того, обладают ли они способностью читать слова в четвертом классе: высокой, средней или низкой. Кривые роста словарного запаса были построены для участников с высоким навыком чтения слов (те, кто набрал 80-й процентиль и выше), средним навыком чтения слов (те, кто набрал в диапазоне 40-60-го процентиля) и низким навыком чтения слов ( набравшие 20-й процентиль и ниже). Затем мы использовали смешанное моделирование, чтобы сопоставить среднюю группу с высокими и низкими группами в отношении темпов роста.
Результаты
Кривые роста словарного запаса
Как и ожидалось, среднее значение совокупных оценок способностей к развитию словарного запаса показало увеличение словарных знаний в каждом временном интервале, начиная с детского сада (). Средний словарный запас детей четвертого класса составил 2,26 ( SD = 0,56) и 3,59 ( SD = 0,61) к 10-му классу. показывает, что форма функции роста была явно нелинейной, с более высокими темпами увеличения словарного запаса в младших классах.Однако между четвертым и десятым классами изменение было гораздо более линейным; таким образом, подходила линейная модель увеличения словарного запаса в этот период развития. показывает кривые среднего увеличения словарного запаса для читателей с низким, средним и высоким навыком чтения в 4 классе.
Распределение баллов развития словарного запаса в каждом интервале наблюдения от детского сада до 10 класса для всех детей в продольном исследовании
Баллы словарного запаса участников, сгруппированных по навыкам чтения слов (читатели высокого уровня, читатели в 80-м процентиле и выше; читатели среднего уровня, читатели в диапазоне 40–60 процентилей; читатели низкого уровня, читатели 20-го процентиля или ниже).
Как и ожидалось, словарный запас при поступлении в детский сад коррелировал со словарным запасом на четвертом ( r = 0,39, n = 485, p <0,0001), восьмом ( r = 0,52 ) n = 485, p <0,0001) и 10-й класс ( r = 0,55, n = 485, p <0,0001). Эти корреляции показывают, что словарный запас в начале чтения связан с последующим словарным запасом, и поэтому вполне вероятно, что существуют факторы, влияющие на рост словарного запаса у детей, которые не являются результатом их чтения.В последующем анализе словарный запас ребенка в детском саду будет использоваться для представления этих навыков изучения словарного запаса, не связанных с чтением, и будет использоваться в качестве ковариаты, чтобы лучше изолировать последующий рост словарного запаса, связанный со способностью к чтению.
Многоуровневое моделирование с использованием программного обеспечения Proc Mixed использовалось для проверки различий в росте словарного запаса во времени, когда возраст ребенка на момент тестирования использовался в качестве эталонного времени. Результаты этого моделирования показаны на.Эти результаты показывают, что средний словарный запас (средний словарный запас в возрасте 9 лет) до ввода ковариат (безусловная модель) составлял 2,16 балла оценки способности к развитию, а средняя скорость роста составляла 0,24 балла в год. Показаны графики смоделированных значений из случайной выборки детей с разными уровнями чтения четвертого класса (). Поскольку использовалась линейная модель, эти функции роста не имеют нелинейного качества данных в и, но в остальном эти смоделированные данные аналогичны полученным данным.
Таблица 3.
Тесты случайных (уровень 1) и фиксированных эффектов для увеличения словарного запаса с использованием словаря детского сада в качестве ковариаты.
| Модель | Эффекты | Параметр | Значение F | p Уровень | |||||
|---|---|---|---|---|---|---|---|---|---|
| Безусловный | |||||||||
| Перехват | 2,162 | 52 | Возраст | 0.240 | 2446,87 | <.0001 | |||
| Условный | |||||||||
| Перехват | 1,450 | ||||||||
| KV | 0,146 | 19,60 | 4GR | 0,008 | 17,97 | <.0001 | |||
| Возраст | 0,114 | 12,56 | .0004 | ||||||
| Возраст × KV | 0.016 | 6,64 | 0,01 | ||||||
| Возраст × 4GR | 0,001 | 15,88 | <.0001 | ||||||
Функции линейного роста для случайных выборок читателей для читателей с высоким (80 процентилем и выше) ), средние (40–60 процентиль) и низкие (20 процентиль или ниже) группы навыков чтения слов в четвертом классе.
Наш первый вопрос касался того, в какой степени чтение в четвертом классе связано с развитием словарного запаса (скорость изменения показателей словарного запаса).Это было протестировано в рамках условно-смешанной модели, как также показано в. показывает, что после контроля уровня словарного запаса в детском саду скорость увеличения словарного запаса между четвертым и десятым классами была достоверно связана с уровнем чтения детей в четвертом классе, F (1, 485) = 15,88, p <. 0001. Значение параметра для этого эффекта было 0,001, что указывает на то, что более высокая способность читать слова в четвертом классе связана с более высокими темпами роста словарного запаса, что можно увидеть в.Следует подчеркнуть, что этот эффект был оценен после того, как в модель были введены источники дисперсии, связанные с чтением в детском саду по общему словарному запасу и изменению словарного запаса между четвертым и десятым классами. Индивидуальные различия в словарном запасе детского сада также оказали значительное влияние на перехват словарного запаса в четвертом классе, F (1, 485) = 19,60, p <0,0001, и на рост словарного запаса F ( 1, 485) = 6,64, p =.01. Таким образом, дети с более высоким словарным запасом в детском саду, вероятно, будут иметь больший словарный запас в четвертом классе и демонстрировать более высокие темпы увеличения словарного запаса после учета влияния способности четвертого класса к чтению.
Параметр наклона оказался равным 0,001. Это значение представляет собой скорость изменения показателей словарного запаса в год с четвертого по десятый класс, что можно отнести к изменению на 1 балл в навыке чтения слов в четвертом классе. Среднее изменение словарного запаса за 6 лет составило 1.38; однако некоторые дети изменились на 3,62 пункта, а некоторые фактически снизились на целых -0,018. Относительный размер влияния умения читать в четвертом классе на рост словарного запаса по сравнению с общим ростом словарного запаса может быть представлен с помощью Коэна f 2 , который отражает долю дисперсии одной переменной в контексте многомерная регрессионная модель. Используя метод, разработанный Selya, Rose, Dierker, Hedeker, and Mermelstein (2012), мы подсчитали, что индивидуальные различия в умении читать четвертые классы составляют 8% ( f 2 =.08) дисперсии темпов прироста словарного запаса с четвертого по десятый класс. Коэна f 2 этого размера обычно считаются малыми и средними по величине.
Приведенный выше размер эффекта отражает степень, в которой чтение четвертого класса объясняет различия в наклонах роста словарного запаса у детей. Хотя размер этого эффекта несколько невелик, мы должны учитывать, что различия в темпах роста, вероятно, будут нарастать с течением времени. Таким образом, даже небольшие различия в темпах роста могут привести к значительным долгосрочным последствиям для абсолютного словарного запаса.Чтобы изучить этот совокупный эффект дифференциального роста, мы вычислили величину эффекта чтения слов в четвертом классе на словарный запас 10-го класса после контроля словарного запаса четвертого класса. Таким образом, это отражает усиление влияния чтения на словарный запас между четвертым и десятым классами. Это привело к η 2 частичному = 0,26. Значения в квадрате этой величины рассматриваются как большие, и, таким образом, мы можем видеть, что величина эффекта от небольшого до умеренного увеличения дифференциального словарного запаса может привести к большому эффекту при наличии достаточного времени.
Мы также можем интерпретировать величину этого эффекта, сравнивая размер этого эффекта с чем-то более знакомым. В этом случае мы можем сравнить влияние уровня образования матери на развитие словарного запаса в тот же период. Известно, что социально-экономический статус связан с ранним уровнем словарного запаса (например, Hart & Risley, 1995), и мы ожидаем, что влияние материнского образования будет распространяться и на школьные годы. Используя тот же подход для вычисления f 2 , мы оценили размер эффекта материнского образования на рост словарного запаса между четвертым и десятым классами и обнаружили, что он составил f 2 =.08. Таким образом, умение читать в четвертом классе влияет на словарный запас так же, как и на образование матери.
Приведенный выше анализ ставит вопрос о том, можно ли спутать материнское образование с умением читать в четвертом классе и является ли это причиной схожести размеров эффекта. В этом случае можно утверждать, что именно домашняя среда ребенка объясняет дифференцированный рост словарного запаса. Однако в нашем тесте на влияние чтения на словарный запас между четвертым и десятым классами мы контролировали словарный запас в детском саду, и одной из причин этого был контроль социально-экономических факторов, влияющих на рост словарного запаса.Мы проверили это предположение, введя в одну модель и образование матери, и словарный запас детского сада, и обнаружили, что образование матери не было значимым предиктором, F (4, 474) = 0,24, p = 0,91, увеличения словарного запаса после включения словарный запас детского сада. Таким образом, включение словаря детского сада действительно служило косвенной переменной для образования матерей.
Второй вопрос: различались ли темпы роста словарного запаса у трех групп читателей.Это было решено путем выполнения многоуровневого анализа моделирования, в котором три группы читателей (высокие, средние и низкие) были определены в соответствии с их чтением слов в четвертом классе. представляет собой график функций увеличения словарного запаса для читателей с высоким, средним и низким уровнем навыков (как определено ранее). Была показана модель дивергенции. Значительное влияние чтения в четвертом классе на рост подтверждает, что рост словарного запаса дифференцирован в соответствии с чтением в четвертом классе; однако эта разница может быть сосредоточена в одной области способностей к чтению.Контрасты в групповом росте словарного запаса между читателями низкого уровня и читателями среднего уровня показали, что наклон роста читателей низкого уровня был -0,02 ( SE = 0,0158) ниже, чем у группы среднего уровня, которая существенно не различалась, t (289) = 1,25, p = 0,21. Напротив, крутизна роста читателей высокого уровня по сравнению со читателями среднего уровня была на 0,04 ( SE = 0,0160) выше, что значительно отличалось: t (289) = 2.18, p = 0,03. Эти результаты предполагают, что связь между умением читать в четвертом классе и последующим ростом словарного запаса несколько варьировалась в зависимости от уровня чтения; то есть эффект был односторонним, а не двусторонним, эффектом Мэтью. В этом случае читатели из верхних 20 процентилей показали расхождение в росте словарного запаса по сравнению с читателями на среднем или низком уровне распределения способностей к чтению.
Обсуждение
Связь чтения с увеличением словарного запаса
Первый конкретный вопрос этого исследования заключался в том, были ли доказательства того, что умение читать слова в четвертом классе связано со скоростью изменения словарного запаса между четвертым и десятым классами после учет индивидуальных различий в приобретении словарного запаса до обучения чтению.Наши результаты убедительно подтверждают связь между способностью читать слова и скоростью последующего увеличения словарного запаса, измеренной с помощью устного языкового задания. Однако маловероятно, что одной только способности читать слова в четвертом классе будет достаточно, чтобы объяснить эти результаты. Вместо этого мы рассматриваем наш показатель умения читать в четвертом классе как индикаторную переменную, которая связана с деятельностью детей, связанной с чтением, которая разворачивалась между четвертым и десятым классами. Эти связанные с чтением занятия служат основными причинами увеличения словарного запаса, обнаруженного в этом исследовании.Мы могли бы добавить, что тип текста, который читает ребенок, также должен быть переменной, потому что материал для чтения, который открывает ребенку более широкий диапазон словарного запаса, также должен способствовать увеличению словарного запаса. По этому поводу Пфост, Дорфлер и Артельт (2013) сообщили, что время чтения повествований гораздо лучше предсказывает словарный запас, чем время чтения газет, журналов, комиксов или документальной литературы. Таким образом, результаты этого анализа согласуются с предложением Становича (1986), а также с предложением Надя и др.считает (1985), что рост словарного запаса в школьные годы в значительной степени обусловлен случайным заучиванием письменных текстов. Учитывая важность чтения, в идеале мы бы измерили эти переменные. В рамках этого проекта было собрано несколько показателей вовлеченности в чтение, таких как признание авторов, но их достоверность оказалась сомнительной. Однако другие исследования показали связь между навыками чтения и объемом опыта чтения (Allington, 1983; Martin-Chang & Gould, 2008; Nagy & Anderson, 1984).Тем не менее, хотя мы предполагаем, что опыт чтения является посредником во взаимосвязи между чтением слов и результатом увеличения словарного запаса, это посредничество не тестировалось в рамках данного исследования. Таким образом, результаты настоящего исследования не позволяют сделать выводы о том, действительно ли опыт чтения является посредником обнаруженного нами эффекта.
После того, как уровень словарного запаса в детском саду был учтен, чтение слов в четвертом классе составило 8% от общего разброса в темпах увеличения словарного запаса между четвертым и десятым классами.Это означает, что влияние чтения слов на рост словарного запаса нетривиально. Фактически, величина влияния чтения слов на темпы роста словарного запаса сопоставима с влиянием образования матери на темпы роста словарного запаса в течение того же периода развития. Если рассматривать влияние этой разницы в показателях с точки зрения абсолютного словарного запаса в 10-м классе, эффект будет большим.
Как заявил Станович (2000), его статья 1986 года содержит «множество микропредсказаний и микротеорий» (стр.150). Предыдущие исследования других эффектов Мэтью сообщили о различных результатах. Эти неоднозначные результаты для эффектов Мэтью в предыдущих исследованиях могут быть вызваны несколькими причинами. Во-первых, вряд ли можно ожидать найти эффекты Мэтью для всех переменных, связанных с чтением. Пэрис (2005) определил ограниченных навыков как навыки, которые ограничены по объему, быстро усваиваются и требуют, чтобы один и тот же материал был усвоен всеми учащимися, и утверждал, что ограниченные в развитии навыки «не должны концептуализироваться как устойчивые переменные индивидуальных различий» (п.184). В тех случаях, когда переменными результата в других исследованиях были ограниченные навыки, такие как навыки словесной атаки, вряд ли можно ожидать найти значимые различия, особенно для более старших или более опытных читателей. С другой стороны, понимание прочитанного зависит от различных компонентных навыков в процессе развития чтения. Для очень ранних читателей умение понимать прочитанное в значительной степени зависит от умения читать или декодировать слова. Для более продвинутых читателей навыки понимания речи вносят более существенный вклад в понимание прочитанного.Поскольку компоненты, влияющие на оценку понимания прочитанного, различаются по своему вкладу в процессе развития, лонгитюдные сравнения навыков понимания прочитанного могут или не могут показывать эффект Мэтью. Эти проблемы усугубляются при использовании комбинированных показателей чтения слов и понимания прочитанного. Следовательно, возможно, что в некоторых предыдущих исследованиях не было обнаружено доказательств, подтверждающих существование эффекта Мэтью, потому что критерии исхода были либо ограничены с точки зрения развития, либо менее ограничены с точки зрения развития, но были измерены в возрастных диапазонах до того, как можно было бы ожидать появления эффектов.Этот анализ будет подтвержден метаанализом Пфоста и его коллег (Pfost et al., 2014), который предположил, что существует меньше доказательств эффекта Мэтью для переменных, связанных с развитием, таких как точность декодирования. В случае настоящего исследования ожидается, что чтение повлияет на рост словарного запаса после того, как дети познакомятся с большим количеством новых слов в процессе чтения, начиная примерно с третьего или четвертого класса. Это точка развития, исследуемая в данном исследовании.
Во-вторых, как обсуждалось ранее, предыдущие исследования эффекта Мэтью для словарного запаса не учитывали навыки изучения слов до формального обучения чтению. Действительно, результаты текущего исследования показывают, что эта переменная оказывает значительное влияние на скорость увеличения словарного запаса в годы между четвертым и десятым классами. Это может быть еще одной причиной различных результатов предыдущих исследований.
В-третьих, в текущем исследовании использовались оценки способностей к развитию, основанные на IRT, чтобы дать возможность значимого сравнения между успеваемостью в разных возрастных группах, что не соответствовало предыдущим исследованиям эффекта Мэтью для словарного запаса.Основанием для использования оценок на основе IRT было то, что они, по-видимому, обладают лучшими свойствами, такими как равноправная интервальная шкала, для характеристики роста умственных способностей. Высказывались опасения по поводу того, что эти оценки, вероятно, будут демонстрировать снижение дисперсии с увеличением возраста, в то время как оценки эквивалентности классов, по-видимому, приводят к увеличению дисперсии (например, Hoover, 1984; Yen, 1986). Эти паттерны, однако, не воспроизводятся последовательно (Williams, Pommerich, & Thissen, 1998), и остается неясным, искажают ли и при каких обстоятельствах оценки IRT или другие формы оценок развития изменения способностей с течением времени.Тем не менее, использование оценок IRT (Rasch) подвергалось критике в исследованиях распространения эффекта Мэтью (Bast & Reitsma, 1998; Stanovich, 2000) на том основании, что принуждение оценок в пределах возраста к нормальному распределению может вызвать снижение различия в оценке развития с возрастом (Hoover, 1984). Например, Станович (2000) предположил, что использование оценок способностей к развитию могло бы объяснить компенсирующий эффект, обнаруженный для оценок чтения в исследовании Shaywitz et al. (1995). В текущем исследовании использование оценок способностей к развитию не привело к снижению дисперсии и, таким образом, не препятствовало нашей способности обнаруживать влияние способности читать слова на рост словарного запаса.Возможно, результаты Shaywitz et al. (1995) в отношении чтения связаны с использованием составной оценки чтения, которая включает идентификацию слов, идентификацию псевдослова и понимание прочитанного. Как утверждали также Баст и Рейтсма (1998), совокупная оценка этих трех навыков не будет иметь сопоставимого значения с течением времени, что значительно затрудняет интерпретацию результатов.
Кроме того, в текущем исследовании использовалась выборка, основанная на эпидемиологии. Это исследование проводилось с группой детей, которые происходили из выборки населения и поэтому более разнообразны, чем это часто бывает в исследовательских исследованиях, особенно когда участникам необходимо прийти в лабораторные условия.Таким образом, результаты настоящего исследования, скорее всего, будут репрезентативными для населения в целом.
Взаимосвязь между чтением и ростом словарного запаса на разных уровнях навыков чтения
Второй вопрос этого исследования заключался в том, одинакова ли взаимосвязь между навыками чтения и ростом словарного запаса как у сильных, так и у слабых читателей. Действительно, дальнейшее изучение данных показало, что влияние ранней способности читать слова на словарный запас не было одинаковым для разных уровней начальной способности читать слова.Вместо этого могло показаться, что сильные читатели сделали больший словарный запас по сравнению со средними и слабыми читателями. Говоря языком эффекта Матфея, богатые становились богаче из-за лучшего чтения, но бедные не становились беднее из-за их слабого чтения. Morgan et al. (2008) также сообщили об эффекте Мэтью, который не относился как к сильным, так и к слабым читателям, хотя они сообщили об асимметрии в противоположном направлении: учащиеся, подвергающиеся наибольшему риску расстройств чтения, с большей вероятностью отстают в чтении, тогда как учащиеся из группы наименьшего риска - нет. приобретение по отношению к типичным читателям.Другое предсказание модели эффекта Мэтью проверялось в этом исследовании, и это, вероятно, объясняет разницу в результатах.
В текущем исследовании, несколько факторов могут объяснить этот односторонний эффект Мэтью с неоднородным влиянием навыков чтения слов на рост словарного запаса на разных уровнях навыков. Настоящее исследование не делает различий между этими возможностями и, естественно, они не исключают друг друга. Первая возможность состоит в том, что разрыв в объеме чтения между сильными и средними читателями больше, чем разрыв в объеме чтения между средними и слабыми читателями.Возможность того, что существует большая разница в объеме чтения между сильными и средними читателями, по сравнению с различиями между средними и слабыми читателями, является несколько умозрительной. Однако Каннингем (Cunningham, 2005) обсудил данные, показывающие, что для самостоятельного чтения у учащихся пятого класса абсолютные различия между заядлыми и средними читателями (90-й и 50-й процентили объема чтения) больше, чем абсолютные различия между средними и слабыми читателями ( 50-й и 10-й процентили объема чтения).Это согласуется с гипотезой о том, что различия в опыте чтения не находятся в линейной зависимости от уровня навыков. В дополнение к количеству чтения, которым занимаются отдельные дети, может также случиться так, что материал для чтения, выбранный сильными читателями, содержит большую степень новой лексики, чем материал, назначенный или выбранный средним или слабым читателям.
Вторая возможность состоит в том, что учащиеся различаются по степени полезности чтения новых слов, и что эти индивидуальные различия являются наибольшими между средним и сильным читателем.Есть свидетельства того, что дети различаются по своей способности извлекать значения слов из письменных контекстов (Cain, Oakhill, & Elbro, 2003; Cain, Oakhill, & Lemmon, 2004; McKeown, 1985). Индивидуальные различия в усвоении слов с помощью текста связаны с различиями в рабочей памяти и со способностью изучать новый словарный запас в ходе прямого обучения (Cain et al., 2004). Существование этих индивидуальных различий мотивирует вмешательства, направленные на улучшение навыков детей в определении значений слов из контекста (Cain, 2007; Goerss, Beck, & McKeown, 1999; Nash & Snowling, 2006).Генетические данные также подтверждают идею о том, что факторы окружающей среды могут неодинаково влиять на рост словарного запаса на разных уровнях навыков. ДеТорн, Петрилл, Хайю-Томас и Пломин (2005) сообщили, что дети с очень низким словарным запасом обладают более высокой наследуемостью и меньшим влиянием общей среды по сравнению с детьми с менее серьезным словарным дефицитом. Опять же, возможность того, что эти индивидуальные различия между сильными и средними читателями больше по сравнению с различиями между слабыми и средними читателями, является спекулятивной.
Также возможно, что слабым читателям были предоставлены образовательные мероприятия для улучшения навыков чтения или словарного запаса, что уменьшило совокупный эффект неблагоприятного положения для них. Текущее исследование не включает информацию об истории вмешательства, поэтому это предположение. Однако эти данные свидетельствуют о том, что сочетание поведения, выбранного учащимися, различий в способности учиться, знакомясь с новыми словами в тексте, и образовательной политики не ставят в еще более невыгодное положение слабых читателей, по крайней мере, с точки зрения роста их словарного запаса.Для тех, кто обеспокоен тем, что бедные становятся беднее, это обнадеживающий результат.
Ограничения текущего исследования
Как и в случае любого неэкспериментального дизайна, эти выводы основаны на ассоциациях, а не на более сильных экспериментальных доказательствах, включающих случайное отнесение к независимым переменным условиям лечения. Ограничение наблюдательного плана, такого как это исследование, состоит в том, что другие смешивающие переменные могут играть роль в наблюдаемых эффектах. Одним из таких факторов может быть начальный уровень словарного запаса.Дети с лучшими навыками чтения слов в четвертом классе также, вероятно, будут иметь лучший словарный запас на слух, как и участники этого исследования. В результате наш анализ включил показатель словарного запаса в детском саду в качестве коварианты. Этот анализ возможен отчасти потому, что текущее исследование анализирует данные большой продольной выборки из 485 участников, что обеспечивает адекватную статистическую мощность. Мы можем предположить, что на этот показатель словарного запаса в детском саду в значительной степени не повлиял опыт чтения ребенка, но он будет отражать общую способность ребенка к обучению лексике, а также аспекты окружающей среды ребенка, которые могут быть связаны с индивидуальными различиями в изучении слов.Таким образом, мы можем утверждать, что влияние способности чтения в четвертом классе на последующий словарный запас на слух, вероятно, не зависит от общей способности ребенка к обучению.
Еще одним ограничением текущего исследования является использование линейной модели, что означает, что словарные данные между четвертым и десятым классами были подобраны с использованием только линейного наклона и точки пересечения. Однако общие показатели словарного запаса между детским садом и 10-м классом предполагают криволинейную тенденцию, и возможно, что данные могут быть лучше представлены нелинейной моделью, но для этого потребуются данные в большем количестве временных точек, чем доступно с этим набором данных.Это означает, что текущий анализ не может отвечать на вопросы, относящиеся к ускорению или замедлению темпов роста словарного запаса, а вместо этого отражает основную особенность траектории роста, а именно общие изменения во времени.
Целью оригинального лонгитюдного исследования было ответить на вопросы, касающиеся исходов у детей с языковыми нарушениями. Избыточная выборка детей с языковыми и / или когнитивными нарушениями потенциально могла повлиять на результаты текущего исследования.Однако это было учтено с использованием взвешенных баллов. Таким образом, полученные данные применимы как к детям, так и к подросткам с языковыми нарушениями и обычно развивающимся.
определение случая | эпидемиология | Britannica
определение случая , в эпидемиологии, набор критериев, используемых при принятии решения о том, есть ли у человека интересующее заболевание или событие со здоровьем. Установление определения случая - обязательный шаг в количественной оценке масштабов заболевания в популяции.Определения случаев заболевания используются в текущем эпиднадзоре за общественным здоровьем для отслеживания возникновения и распространения болезни в данной области, а также во время расследований вспышек в полевой эпидемиологии.
Определение случая должно быть ясным, простым и кратким, чтобы его можно было легко применить ко всем лицам в интересующей популяции. Обычно он включает в себя как клинические, так и лабораторные характеристики, которые устанавливаются одним или несколькими методами, которые могут включать диагностику врачом, завершение опроса или обычные методы скрининга населения.Лица, соответствующие определению случая, могут быть разделены на «подтвержденные», «вероятные» или «подозреваемые».
Национальные и международные организации опубликовали списки единообразных определений случаев для обязательной отчетности по отдельным заболеваниям. Такие списки содержат четкие определения случаев заболевания, что позволяет врачам сообщать о случаях заболеваний, представляющих интерес, органам общественного здравоохранения стандартным и единообразным образом в разных географических точках. Это особенно полезно для исследований, в которых сравнивается распространенность болезни по регионам, поскольку они могут использовать одни и те же определения случаев и, следовательно, получить относительно точную оценку болезни.
Во время вспышки болезни определение случая разрабатывается на ранней стадии расследования вспышки, что облегчает выявление отдельных случаев. Хотя те же критерии применяются для разработки определения случая в рамках обычного эпиднадзора за общественным здоровьем, при расследовании вспышки определение случая может также включать информацию о человеке, месте и времени в дополнение к клиническим и лабораторным характеристикам. Например, определение случая, разработанное для вспышки болезни пищевого происхождения, может включать только тех людей, которые ели в определенном ресторане в течение определенного периода времени.Кроме того, определение случая может быть широко определено на начальных этапах сценария расследования вспышки, чтобы повысить чувствительность, позволяя регистрировать как можно больше случаев, а также сводя к минимуму возможность пропуска случаев. По мере продолжения расследования и получения дополнительных сведений о характере дел определение может быть сужено, сделав его более конкретным. Это особенно важно для вновь возникающего заболевания, для которого еще не существует стандартного определения случая.
Получите подписку Britannica Premium и получите доступ к эксклюзивному контенту. Подпишитесь сейчасКак посчитать, сколько раз слово появляется в Excel (простые формулы)
Одним из распространенных требований при работе с большими наборами данных является подсчет того, сколько раз встречается определенное слово или значение.
Возможно, вам потребуется узнать, сколько раз слово появляется в ячейке, столбце или на всем листе.
Эта проблема может быть двух типов. Возможно, вам потребуется подсчитать, сколько ячеек содержит данное слово или сколько раз данное слово встречается в ячейке.
В этом руководстве мы увидим оба типа проблем и различные способы их решения, включая использование VBA.
Подсчитать конкретное слово в диапазоне с помощью COUNTIF
Основная задача функции СЧЁТЕСЛИ - подсчитать, сколько раз выполняется условие.
Одно из наиболее распространенных применений этой функции - сопоставление определенного значения со значениями ячеек в диапазоне. Это значение может быть строкой или числом.
Синтаксис функции СЧЁТЕСЛИ:
СЧЁТЕСЛИ (диапазон , условие )
Здесь,
- диапазон - это диапазон ячеек, который вы хотите сопоставить и считать от
- условие - это условие, которое должно быть выполнено, чтобы засчитать ячейку как совпадение
Вышеупомянутая функция выполняет поиск всех ячеек в заданном диапазоне и подсчитывает все ячейки, которые соответствуют заданному условию . После завершения поиска по всем ячейкам в диапазоне будет возвращено количество совпавших ячеек.
Давайте применим эту функцию к простому примеру. Допустим, мы хотим подсчитать, сколько раз имя «Питер» встречается в диапазоне A2: A10, как показано ниже:
Чтобы применить функцию СЧЁТЕСЛИ для указанной выше проблемы, выполните следующие действия:
- Выберите ячейку, в которую вы хотите записать счетчик (в нашем случае ячейка D3).
- В этой ячейке введите формулу:
= СЧЁТЕСЛИ (A2: A10, «Питер»)
- Нажмите клавишу возврата.
Это даст количество раз, когда слово « Питер » встречается в диапазоне ячеек A2: A10.
Примечание : Этот метод подсчитывает только количество ячеек, которые содержат , ровно слово «Питер». Если, например, в одной из ячеек есть слова «Питер Питер» в одной ячейке, функция СЧЁТЕСЛИ не будет рассматривать это как совпадение и, следовательно, не будет считать ячейку.
Подсчитайте конкретное слово в ячейке с помощью LEN и SUBSTITUTE
Вышеупомянутый метод отлично работает, если вы хотите подсчитать ячейки, в которых точно соответствуют заданному слову.Однако это не сработает, если вы хотите узнать, сколько раз слово встречается внутри строки ячейки.
Например, предположим, что у вас есть следующая строка в ячейке (A2), и вы хотите знать, сколько раз встречается слово «счастливый»:
Для решения этой проблемы существует ряд методов, которые вы можете использовать.
Например, вы можете использовать формулу, которая содержит комбинацию функций Excel, таких как ПОДСТАВИТЬ и LEN. Вы также можете использовать код VBA, чтобы быстро выполнить работу.
Функция LENФункция ДЛСТР - очень часто используемая функция Excel. Он используется для определения длины строки (количества символов в строке). Синтаксис функции:
= LEN ( строка )
Где строка может быть текстом или ссылкой на ячейку, содержащую текст, длину которого вы хотите найти.
Функция ЗАМЕНАФункция ЗАМЕНА используется для удаления определенного слова из строки.Общий синтаксис этой функции:
= ПОДСТАВИТЬ ( исходная_строка , старый_текст , новый_текст )
Здесь,
- исходная_строка - это текст или ссылка на ячейку, над которыми вы хотите работать.
- старый_текст - слово или подстрока, которую вы хотите заменить
- новый_текст - это слово или подстрока, которой вы хотите заменить старый_текст .
По отдельности обе вышеуказанные функции, похоже, не имеют ничего общего с подсчетом того, сколько раз слово появляется в ячейке.Но когда они умело объединены в формулу, они справляются с задачей.
Чтобы подсчитать, сколько раз слово появляется в ячейке, мы можем использовать формулу:
= (LEN ( cell_reference ) -LEN (SUBSTITUTE ( cell_reference, word , ""))) / LEN ( word )
Здесь слово - это слово, которое вы хотите подсчитать, а cell_reference - это ссылка на ячейку, из которой вы хотите произвести подсчет.
Вот как можно применить приведенную выше формулу к проблеме:
- Выберите ячейку, в которую вы хотите записать счетчик (в данном случае ячейка B5).
- В этой ячейке введите формулу:
= (LEN ( A2 ) -LEN (ПОДСТАВИТЬ (A2, «счастливый» , «»))) / LEN ( «счастливый» ). Вместо указания заменяемого слова вы также можете указать ссылку на ячейку, содержащую это слово, например: = (LEN ( A2 ) -LEN (SUBSTITUTE (A2, A5, ""))) / LEN (A5 ).
- Нажмите клавишу возврата.
Это даст количество раз, когда слово « счастливых, » появляется в ячейке A2.
Если вы также хотите скопировать ту же формулу для подсчета количества вхождений других слов в ячейку A2, вы можете исправить ссылку на ячейку A2, добавив знак $:
= (LEN ( долл. США 2 ) -LEN (ПОДСТАВИТЬ (2 долл. США, A5, ""))) / LEN (A5)
Теперь вы можете легко скопировать формулу для других слов, перетащив маркер заполнения вниз.
Как работала эта формула?Чтобы понять, как работает эта формула, нам нужно разбить ее на части:
- Сначала мы использовали функцию ЗАМЕНА, чтобы удалить слово «счастливый» из исходной строки (заменив его пробелом): ЗАМЕНА (A2, «счастливый», »»)
- Затем мы использовали функцию LEN, чтобы найти длину исходной строки без вхождения в ней слова «счастливый»: LEN (SUBSTITUTE (A2, «happy», »»))
- После этого мы вычли эту длину из длины исходной строки (со словами «счастливый» в ней): LEN (A2) - LEN (ПОДСТАВИТЬ (A2, «счастливый», »))
- Это дает общее количество символов в всех вхождениях слова «счастливый».Это слово из 5 букв, поэтому, если оно встречается 4 раза, вышеуказанная операция вернет 20 .
- Наконец, это значение делится на длину слова «счастливый»: = (LEN ( $ A $ 2 ) -LEN (SUBSTITUTE ($ A $ 2, A5, ””))) / LEN (А5) .
Это должно дать вам, сколько раз слово «счастливый» встречается в исходном тексте! Таким образом, мы получаем 20/5 = 4 . Слово «счастливый» встречается в ячейке A2 4 раза.
Примечание : Функция ЗАМЕНА чувствительна к регистру.В результате эта формула будет подсчитывать только то, сколько раз слово «счастливый» появляется на всех строчных буквах. Если вы будете искать слово, написанное заглавными буквами, вы не получите правильный ответ.
Хороший способ обойти это - убедиться, что все преобразовано в строчные буквы. Поэтому, чтобы убедиться, что наша формула не чувствительна к регистру, ее можно преобразовать в:
= (LEN ( cell_reference ) -LEN (SUBSTITUTE (LOWER ( cell_reference ), LOWER ( word ), ""))) / LEN ( word )
Здесь функция LOWER используется для преобразования исходного и нового текста в нижний регистр.
Count Сколько раз слово появляется в диапазоне
Вышеупомянутый метод работает только в том случае, если вы хотите узнать, сколько раз слово появляется в одной ячейке . Но что, если вам нужно выяснить, сколько раз одно и то же слово встречается в строках в нескольких ячейках ?
Для этого вам нужно будет заключить функцию СУММПРОИЗВ вокруг приведенной выше формулы. Итак, если у вас есть диапазон ячеек для работы, ваша формула должна быть:
= СУММПРОИЗВ (LEN ( диапазон_ячеек ) -LEN (ПОДСТАВИТЬ ( диапазон_ячеек , слово , ""))) / LEN ( слово ))
Функция СУММПРОИЗВ гарантирует, что вы получите массив, содержащий счетчик для каждой ячейки в диапазоне.
Допустим, у вас есть следующий набор текстовых строк (A2: A3), и вы хотите узнать, сколько раз слово « happy » встречается в всех из них:
Просто выполните следующие действия:
- Выберите ячейку, в которую вы хотите записать счетчик (в данном случае ячейка B6).
- В этой ячейке введите формулу:
= СУММПРОИЗВ ((LEN (A2: A3) -LEN (ПОДСТАВИТЬ (A2: A3, «счастливый», «»))) / LEN («счастливый»)). Вместо указания заменяемого слова вы также можете указать ссылку на ячейку, содержащую это слово, например: = СУММПРОИЗВ ((LEN (A2: A3) -LEN (SUBSTITUTE (A2: A3, A6, ""))) / LEN (A6))
- Нажмите клавишу возврата.
Это даст количество раз, когда слово «счастливый» встречается в диапазоне A2: A3.
Если вы также хотите скопировать ту же формулу для подсчета количества вхождений других слов в том же диапазоне, вы можете исправить ссылку на ячейку диапазона A2: A3, добавив знак $:
= СУММПРОИЗВ ((LEN ($ A $ 2: $ A $ 3) -LEN (ПОДСТАВИТЬ ($ A $ 2: $ A $ 3, A6, ""))) / LEN (A6))
Теперь вы можете легко скопировать формулу для других слов, перетащив маркер заполнения вниз.
Использование VBA для подсчета количества появлений слова в любом диапазоне
Вы можете выполнить ту же задачу, что и выше, с помощью сценария VB.
Вот код VBA, который мы будем использовать, чтобы подсчитать, сколько раз слово «счастливый» появляется в коде. Не стесняйтесь выбирать и копировать.
Подложка count_word_occurrences ()
Счетчик = 0
search_word = "счастливый"
Dim rng As Range
Тусклая ячейка как диапазон
Установите rng = Application.Selection
Для каждой ячейки In rng
Count = Count + ((Len (ячейка) - Len (Заменить $ (cell, search_word, ""))) / Len (search_word))
Следующая ячейка
MsgBox ("Строка" & search_word & "произошло" & Count & "раз")
Концевой переводник Выполните следующие действия:
- На ленте меню Developer выберите Visual Basic .
- Когда откроется окно VBA, нажмите I nsert-> Module . Теперь вы можете приступить к программированию. Введите или скопируйте и вставьте приведенные выше строки кода в окно модуля. Теперь ваш код готов к запуску.
- Выберите одну или несколько ячеек, содержащих текст, по которому нужно вести подсчет.
- Перейдите к Developer-> Macros-> count_word_occurrences-> Run .
- Теперь вы увидите окно сообщения, в котором сообщается, сколько раз слово «счастливый» встречается в выбранном вами диапазоне.
Примечание: Если вы не видите ленту Developer , в меню «Файл» перейдите к Параметры . Выберите Настроить ленту и отметьте опцию Developer на основных вкладках . Наконец, нажмите ОК .
Самое замечательное в этом методе то, что не имеет значения, выбираете ли вы одну ячейку или диапазон из ячеек. Это работает в обоих направлениях.
Вот несколько способов настроить приведенный выше код в соответствии с вашими требованиями:
- Вы можете настроить этот код, изменив значение search_word в строке 3 на слово, которое вы хотите посчитать.Поэтому, если вы хотите подсчитать, сколько раз появляется слово «, потому что », вы можете заменить эту строку на: search_word = »потому что«
- Вы можете использовать ссылку на ячейку вместо указания фактического слова для поиска в самом коде. Итак, если вы хотите использовать ссылку на ячейку, например A6, вместо указания поискового слова «счастливый», вы можете заменить строку 3 на: search_word = Cells (6, «A»). Значение
- Точно так же вы можете отобразить результат в ячейке вместо окна сообщения.Итак, если вы хотите отобразить счетчик в ячейке, скажем B6, вместо отображения его в окне сообщения, вы можете заменить строку 10 на: Cells (6, «B»). Value = Count
- Если вы хотите, чтобы поиск был нечувствительным к регистру, вы можете использовать функцию LCase. Итак, вам нужно будет изменить строку 8 на: Count = Count + ((Len (ячейка) - Len (Заменить $ (LCase (ячейка), LCase (search_word), «»))) / Len (search_word))
В этом руководстве мы продемонстрировали , как можно подсчитать, сколько раз слово появляется в Excel .Мы показали, как подсчитать точных вхождений слова в диапазоне ячеек, используя СЧЁТЕСЛИ.
Затем мы показали вам, как можно подсчитать, сколько раз слово появляется внутри строки одной ячейки, используя функции ПОДСТАВИТЬ и ДСТР.
После этого мы продемонстрировали, как вы можете применить это ко всему диапазону ячеек, содержащих строки, просто заключив ту же формулу в функцию СУММПРОИЗВ.