Процессор / Хабр
Сколько я себя помню, всегда мечтала сделать процессор. Наконец, вчера я его сделала. Не бог весть что: 8 бит, RISC, текущая рабочая частота — 4 кГц, но он работает. Пока что в программе моделирования логических цепей, но все мы знаем: «сегодня — на модели, завтра — на деле!».
Под катом несколько анимаций, краткое введение в двоичную логику для самых маленьких, короткий рассказ про основные микросхемы логики процессора и, собственно, схема.
Двоичная логика
Двоичная система счисления (для тех, кто не в курсе) — это такая система счисления, в которой нет цифр больше единицы. Такое определение многих сбивает с толку, пока они не вспомнят, что в десятичной системе счисления нет цифр больше девятки.
Двоичная система используется в компьютерах потому, что числа в ней легко кодировать напряжением: есть напряжение — значит, единица; нет напряжения — значит, ноль. Кроме того, «ноль» и «один» легко можно понимать как «ложно» и «истинно». Более того, большая часть устройств, работающих в двоичной системе счисления, обычно относится к числам как к массиву «истинностей» и «ложностей», то есть оперирует с числами как с логическими величинами. Для самых маленьких и тех, кто не в курсе, я расскажу и покажу, как работают простейшие элементы двоичной логики.
Более того, большая часть устройств, работающих в двоичной системе счисления, обычно относится к числам как к массиву «истинностей» и «ложностей», то есть оперирует с числами как с логическими величинами. Для самых маленьких и тех, кто не в курсе, я расскажу и покажу, как работают простейшие элементы двоичной логики.
Элемент «Буфер»
Представьте, что вы сидите в своей комнате, а ваш друг — на кухне. Вы кричите ему: «Друг, скажи, в коридоре горит свет?». Друг отвечает: «Да, горит!» или «Нет, не горит». Ваш друг — буфер между источником сигнала (лампочкой в коридоре) и приемником (вами). Более того, ваш друг — не какой-нибудь там обычный буфер, а буфер управляемый. Он был бы обычным буфером, если бы постоянно кричал: «Лампочка светится» или «Лампочка не светится».
Элемент «Не» — NOT
А теперь представьте, что ваш друг — шутник, который всегда говорит неправду. И если лампочка в коридоре светится, то он скажет вам «Нет, в коридоре совсем-совсем темно», а если не светится — то «Да, в коридоре свет горит». Если у вас есть такой друг на самом деле, значит, он воплощение элемента «Не».
Если у вас есть такой друг на самом деле, значит, он воплощение элемента «Не».
Элемент «Или» — OR
Для объяснения сути элемента «Или» одной лампочки и одного друга, к сожалению, не хватит. Нужно две лампочки. Итак, у вас в коридоре две лампочки — торшер, к примеру, и люстра. Вы кричите: «Друг, скажи, хотя бы одна лампочка в коридоре светит?», и ваш друг отвечает «Да» или «Нет». Очевидно, что для ответа «Нет» все лампочки обязательно должны быть выключены.
Элемент «И» — AND
Та же самая квартира, вы, друг на кухне, торшер и люстра в коридоре. На ваш вопрос «В коридоре обе лампочки горят?» вы получаете ответ «Да» или «Нет». Поздравляю, теперь ваш друг — это элемент «И».
Элемент «Исключающее Или» — XOR
Повторим еще раз эксперимент для элемента «Или», но переформулируем свой вопрос к другу: «Друг, скажи, в коридоре только одна лампочка светит?». Честный друг ответит на такой вопрос «Да» только в том случае, если в коридоре действительно горит только одна лампочка.
Сумматоры
Четвертьсумматор
Четвертьсумматором называют элемент «Исключающее Или». Почему? Давайте разберемся.
Составим таблицу сложения для двух чисел в двоичной системе счисления:
0+0= 0
0+1= 1
1+0= 1
1+1= 10
Теперь запишем таблицу истинности элемента «Исключающее Или». Для этого обозначим светящуюся лампочку за 1, потухшую — за 0, и ответы друга «Да»/«Нет» как 1 и 0 соответственно.
0 XOR 1 = 1
1 XOR 0 = 1
1 XOR 1 = 0
Очень похоже, не так ли? Таблица сложения и таблица истинности «Исключающего Или» совпадают полностью, кроме одного-единственного случая. И этот случай называется «Переполнение».
Полусумматор
При переполнении результат сложения уже не помещается в столько же разрядов, во сколько помещались слагаемые. Слагаемые — два однозначных числа (одна значащая цифра, понимаете?), а сумма — уже двузначное (две значащих цифры). Две цифры одной лампочкой («Светится»/«Не светится») уже не передать.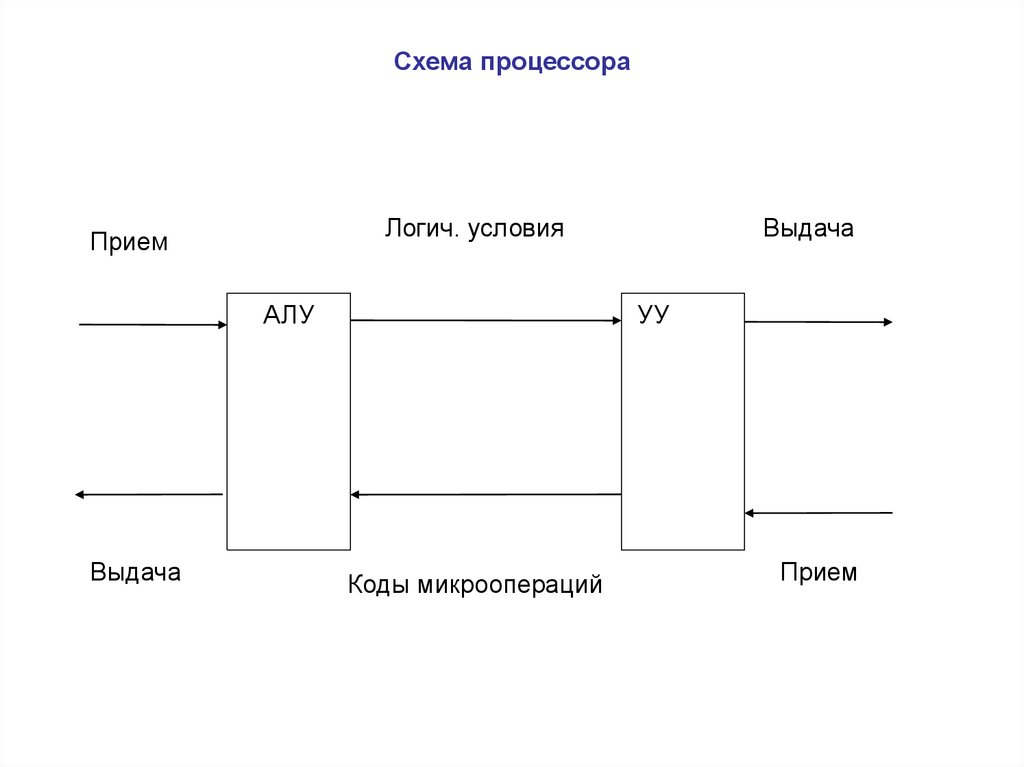
Кроме XOR, для сумматора нам потребуется элемент «И» (AND).
0 XOR 0 = 0 0 AND 0 = 0
0 XOR 1 = 1 0 AND 1 = 0
1 XOR 0 = 1 1 AND 0 = 0
1 XOR 1 = 0 1 AND 1 = 1
Тадам!
0+0= 00
0+1= 01
1+0= 01
1+1= 10
Наша вундервафля полусумматор работает. Его можно считать простейшим специализированным процессором, который складывает два числа. Полусумматор называется полусумматором потому, что с его помощью нельзя учитывать перенос (результат работы другого сумматора), то есть нельзя складывать три однозначных двоичных числа. В связи с этим из нескольких одноразрядных полусумматоров нельзя сделать один многоразрядный.
Я не буду вдаваться в подробности работы полных и многоразрядных сумматоров, просто надеюсь, что основную идею вы уловили.
Более сложные элементы
Мультиплексор
Предлагаю снова включить воображение. Итак, представьте.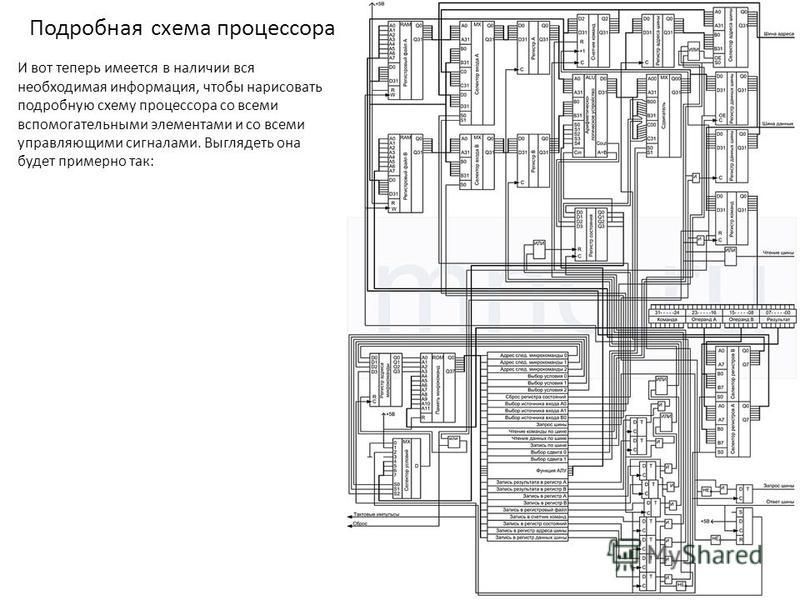 Вы живете в частном одноквартирном доме, возле двери этого дома стоит ваш почтовый ящик. Выходя на прогулку, вы замечаете странного почтальона, который стоит возле этого самого почтового ящика. И вот что он делает: достает кучу писем из сумки, читает номер на почтовом ящике, и в зависимости от номера на ящике бросает в него то или иное письмо. Почтальон работает мультиплексором. Он определенным образом (номер на конверте) определяет, какой отправить сигнал (письмо) по сигнальной линии (почтовый ящик).
Вы живете в частном одноквартирном доме, возле двери этого дома стоит ваш почтовый ящик. Выходя на прогулку, вы замечаете странного почтальона, который стоит возле этого самого почтового ящика. И вот что он делает: достает кучу писем из сумки, читает номер на почтовом ящике, и в зависимости от номера на ящике бросает в него то или иное письмо. Почтальон работает мультиплексором. Он определенным образом (номер на конверте) определяет, какой отправить сигнал (письмо) по сигнальной линии (почтовый ящик).
Мультплексоры состоят обычно только из сочетаний элементов «И», «Или» и «Не». У одноразрядного мультиплексора один вход называется «выбор адреса», два входа с общим названием «входной сигнал» и один выход, который так и называется: «выходной сигнал».
Когда на «выбор адреса» подается 0, то «выходной сигнал» становится таким же, как первый «входной сигнал». Соответственно, когда на «выбор» подается 1, то «выходной сигнал» становится равным второму «входному сигналу».
Демультиплексор
А вот эта штучка работает с точностью до наоборот.
Счетчик
Для понимания работы счетчика вам опять понадобится ваш друг. Позовите его из кухни (надеюсь, он не сильно там скучал, и, главное, не съел всю вашу еду), и попросите делать вот что: пусть он запомнит число 0. Каждый раз, когда вы будете прикасаться к нему, он должен прибавить единицу к тому числу, которое помнит, сказать результат и запомнить его. Когда результат будет равен (допустим) 3, он должен выкрикнуть «Абракадабра!» и отвечать при следующем прикосновении, что сейчас он помнит число 0. Немного сложно? Смотрите:
Вы прикасаетесь к другу. Друг говорит «Один».
Вы прикасаетесь к другу. Друг говорит «Два».
Вы прикасаетесь к другу. Друг говорит «Три». Друг выкрикивает «Хабрахабр!». Критическая атака! Вы временно парализованы и не можете двигаться.
Вы прикасаетесь к другу. Друг говорит «Ноль».
Ну, и так далее.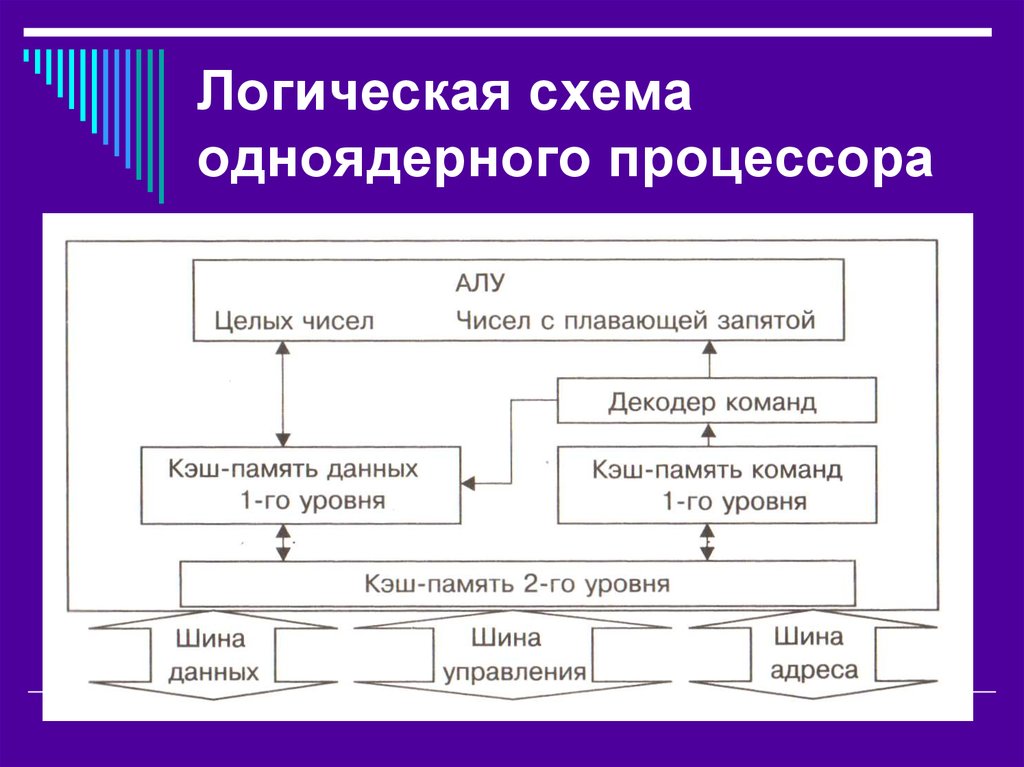 Очень просто, верно?
Очень просто, верно?
Вы, конечно, поняли, что ваш друг сейчас — это счетчик. Прикосновение к другу можно считать «тактирующим сигналом» или, попросту говоря, сигналом продолжения счета. Крик «Абракадабра» показывает, что запомненное значение в счетчике — максимальное, и что при следующем тактирующем сигнале счетчик будет установлен в ноль. Есть два отличия двоичного счетчика от вашего друга. Первое: настоящий двоичный счетчик выдает запомненное значение в двоичном виде. Второе: он всегда делает только то, что вы ему говорите, и никогда не опускается до дурацких шуточек, способных нарушить работу всей процессорной системы.
Память
Триггер
Давайте продолжим издеваться над вашим несчастным (возможно, даже воображаемым) другом. Пусть теперь он запомнит число ноль. Когда вы касаетесь его левой руки, он должен запоминать число ноль, а когда правой — число один. При вопросе «Какое число ты помнишь?» друг должен всегда отвечать то число, которое запоминал — ноль или один.![]()
Простейшей запоминающей ячейкой является RS-триггер («триггер» значит «переключатель»). RS-триггер может хранить в себе один бит данных («ноль»/«один»), и имеет два входа. Вход Set/Установка (совсем как левая рука вашего друга) записывает в триггер «один», а вход Reset/Сброс (соответственно, правая рука) — «ноль».
Регистр
Немного сложнее устроен регистр. Ваш друг превращается в регистр тогда, когда вы просите его что-нибудь запомнить, а потом говорите «Эй, напомни мне, что я говорил тебе запомнить?», и друг правильно отвечает.
Регистр обычно может хранить в себе чуть больше, чем один бит. У него обязательно есть вход данных, выход данных и вход разрешения записи. С выхода данных вы в любой момент можете прочитать то, что в этом регистре записано. На вход данных вы можете подавать те данные, которые хотите в этот регистр записать. Можете подавать данные до тех пор, пока не надоест. В регистр все равно ничего не запишется до тех пор, пока на вход разрешения записи не подать один, то есть «логическую единицу».
Сдвиговый регистр
Вы когда-нибудь стояли в очередях? Наверняка стояли. Значит, вы представляете, каково быть данными в сдвиговом регистре. Люди приходят и становятся в конец очереди. Первый человек в очереди заходит в кабинет к большой шишке. Тот, кто был вторым в очереди, становится первым, а тот, кто был третьим — теперь второй, и так далее. Очередь — это такой хитрый сдвиговый регистр, из которого «данные» (ну, то есть люди) могут убегать по делам, предварительно предупредив соседей по очереди. В настоящем сдвиговом регистре, разумеется, «данные» из очереди сбегать не могут.
Итак, у сдвигового регистра есть вход данных (через него данные попадают в «очередь») и выход данных (из которого можно прочитать самую первую запись в «очереди»). Еще у сдвигового регистра есть вход «сдвинуть регистр». Как только на этот вход приходит «логическая единица», вся очередь сдвигается.
Есть одно важное различие между очередью и сдвиговым регистром. Если сдвиговый регистр расчитан на четыре записи (например, на четыре байта), то первая в очереди запись дойдет до выхода из регистра только после четырех сигналов на вход «сдвинуть регистр».
Оперативная память
Если много-много триггеров объединить в регистры, а много-много регистров объединить в одной микросхеме, то получится микросхема оперативной памяти. У микросхемы памяти обычно есть вход адреса, двунаправленный вход данных (то есть в этот вход можно записывать, и с него же можно считывать) и вход разрешения записи. На вход адреса подаем какое-нибудь число, и это число выберет определенную ячейку памяти. После этого на входе/выходе данных мы можем прочитать то, что записано в эту самую ячейку.
Теперь мы одновременно подадим на вход/выход данных то, что хотим в эту ячейку записать, а на вход разрешения записи — «логическую единицу». Результат немного предсказуем, не так ли?
Процессор
BitBitJump
Процессоры иногда делят на CISC — те, которые умеют выполнять много разных команд, и RISC — те, которые умеют выполнять мало команд, но выполняют их хорошо. Одним прекрасным вечером мне подумалось: а было бы здорово, если бы можно было сделать полноценный процессор, который умеет выполнять всего одну команду.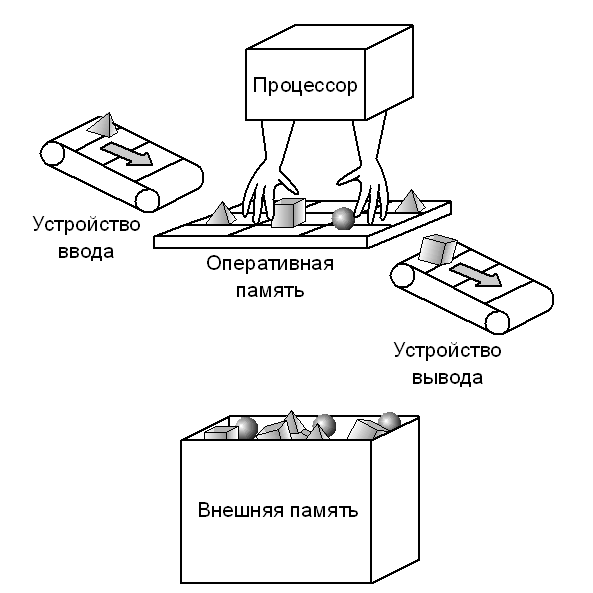 Вскоре я узнала, что существует целый класс однокомандных процессоров — OISC, чаще всего они используют команду Subleq (вычесть, и если меньше или равно нулю, то перейти) или Subeq (вычесть, и если равно нулю, то перейти). Изучая различные варианты OISC-процессоров, я нашла в сети сайт Олега Мазонки, который разработал простейший однокомандный язык BitBitJump. Единственная команда этого языка так и называется — BitBitJump (скопировать бит и перейти по адресу). Этот, безусловно эзотерический, язык является полным по Тьюрингу — то есть на нем можно реализовать любой компьютерный алгоритм.
Вскоре я узнала, что существует целый класс однокомандных процессоров — OISC, чаще всего они используют команду Subleq (вычесть, и если меньше или равно нулю, то перейти) или Subeq (вычесть, и если равно нулю, то перейти). Изучая различные варианты OISC-процессоров, я нашла в сети сайт Олега Мазонки, который разработал простейший однокомандный язык BitBitJump. Единственная команда этого языка так и называется — BitBitJump (скопировать бит и перейти по адресу). Этот, безусловно эзотерический, язык является полным по Тьюрингу — то есть на нем можно реализовать любой компьютерный алгоритм.
Подробное описание BitBitJump и ассемблер для этого языка можно найти на сайте разработчика. Для описания алгоритма работы процессора достаточно знать следующее:
1. При включении процессора в регистрах PC, A и B записаны 0
2. Считываем ячейку памяти с адресом PC и сохраняем прочитанное в регистр A
3. Увеличиваем PC
4. Считываем ячейку памяти с адресом PC и сохраняем прочитанное в регистр B
5. Увеличиваем PC
Увеличиваем PC
6. Записываем в ячейку с адресом, записанным в регистре B, содержимое бита с адресом А.
7. Считываем ячейку памяти с адресом PC и сохраняем прочитанное в регистр B
8. Записываем в регистр PC содержимое регистра B
9. Переходим к пункту 2 нашего плана10. PROFIT!!!
К сожалению, алгоритм бесконечный, и потому PROFIT достигнут не будет.
Собственно, схема
Схема строилась стихийно, поэтому правят бал в ней страх, ужас и кавардак. Тем не менее, она работает, и работает прилично. Чтобы включить процессор, нужно:
1. Ввести программу в ОЗУ
2. Нажать на включатель
3. Установить счетчик в положение 4 (это можно делать и аппаратно, но схема стала бы еще более громоздкой)
4. Включить тактовый генератор
Как видите, использованы один регистр, один сдвиговый регистр, одна микросхема ОЗУ, два двоичных счетчика, один демультиплексор (представленный компараторами), два мультиплексора и немного чистой логики.
Можете скачать схему в формате circ для программы Logisim, и поиграться.
Что дальше?
Во-первых, можно увеличить разрядность процессора — заменив 8-битные элементы на 16-битные.
Во-вторых, можно вынести ОЗУ из процессора, и добавить несложную схему, которая будет приостанавливать процессор, изменять ОЗУ и снова включать процессор. Такая схема будет выполнять функции простого контроллера ввода-вывода. Тогда можно будет сделать на базе этого процессора калькулятор, контроллер или еще какую-нибудь забавную бесполезную штуку.
В-третьих, можно воплотить всю эту схему в железе. Что я собираюсь сделать. Как только сделаю — обязательно расскажу и покажу.
Спасибо всем за внимание!
P.S. Ссылки (для тех, кому лень читать):
1. Процессоры URISC — ru.wikipedia.org/wiki/Urisc
2. Сайт языка BitBitJump — mazonka.com/bbj/index.html
3. Программа для моделирования логических схем Logisim — http://ozark.hendrix.edu/~burch/logisim/
4. Самодельный URISC (ORISC) процессор для Logisim — narod.ru/disk/31367690001/oo.circ.html
Самодельный URISC (ORISC) процессор для Logisim — narod.ru/disk/31367690001/oo.circ.html
Упрощенная логическая схема одноядерного процессора
1. Процессор
УПРОЩЕННАЯ ЛОГИЧЕСКАЯ СХЕМА ОДНОЯДЕРНОГО ПРОЦЕССОРААрифметико-логическое устройство
Целых чисел
Чисел с плавающей запятой
Декодер команд
Кэш-память данных
1-го уровня
Кэш-память команд
1-го уровня
Кэш-память 2-го уровня
Шина
данных
Шина
управления
Шина
адреса
Оперативная память
Процессор
Шина данных (8, 16, 32, 64 бита)
Информационная магистраль (шина)
Шина адреса (16, 20, 24, 32, 36, 64 бита)
Шина управления
ТЕХНОЛОГИЯ ИЗГОТОВЛЕНИЯ ПРОЦЕССОРА
Восемь слоев кристалла процессора в 65нанометровом технологическом процессе
ПРОЦЕССОРЫ
Размер элемента:
10 мк = 10-5 м
Количество элементов:
2300
Самый первый процессор
Intel 4004 (1971 год)
Размер элемента:
65 нм = 0,065 мк = 10-8 м
Количество элементов:
291 000 000
Современный процессор
Intel Core 2 Duo (2007 год)
Ядро процессора Intel Core 2 Duo
ПРОИЗВОДИТЕЛЬНОСТЬ ПРОЦЕССОРА
Производительность процессора характеризует скорость выполнения приложений.

Производительность ~ Разрядность × Частота × Кол-во команд за такт
Разрядность процессора определяется количеством
двоичных разрядов, которые процессор обрабатывает за один
такт.
С момента появления первого процессора 4004 разрядность
процессора увеличилась в 16 раз ( с 4 бит до 64 битов).
Частота соответствует количеству тактов обработки данных,
которые процессор производит за 1 секунду.
С момента появления первого процессора частота
процессора увеличилась в 37 000 раз ( с 0,1 МГц до 3700 МГц).
Выделение процессором теплоты Q пропорционально
потребляемой мощности P, которая, в свою очередь
пропорциональна квадрату частоты ν2: Q ~ P ~ ν2
Для отвода тепла от процессора применяют массивные
воздушные системы охлаждения (кулеры).
Кулер для процессора
ПРОИЗВОДИТЕЛЬНОСТЬ ПРОЦЕССОРА
В настоящее время
производительность
процессора увеличивается
путем совершенствования
архитектуры процессора.

Во-первых, в структуру
процессора вводится кэшпамять 1-го и 2-го уровней,
которая позволяет ускорить
выборку команд и данных и тем
самым уменьшить время
выполнения одной команды.
Во-вторых, вместо одного
ядра процессора используется
два ядра, что позволяет
повысить производительность
процессора примерно на 80%.
КОМПЬЮТЕРНЫЙ ПРАКТИКУМ
1. Определение объемов кэш-памяти процессора
Кэш-память данных 1-го уровня –
16 Кбайт
Кэш-память команд 1-го уровня –
12 Кбайт
Кэш-память 2-го уровня –
1024 Кбайт
КОМПЬЮТЕРНЫЙ ПРАКТИКУМ
2. Определение температуры процессора
Количество оборотов в
минуту кулера процессора –
2884 об/мин
Температура процессора –
46 °С
КОМПЬЮТЕРНЫЙ ПРАКТИКУМ
3. Производительность процессора
КОМПЬЮТЕРНЫЙ ПРАКТИКУМ
3. Производительность процессора
Количество целочисленных операций:
6565 MIPS
.
КОМПЬЮТЕРНЫЙ ПРАКТИКУМ
3.
 Производительность процессора
Производительность процессораКоличество операций с плавающей точкой :
8440 MFLOPS
.
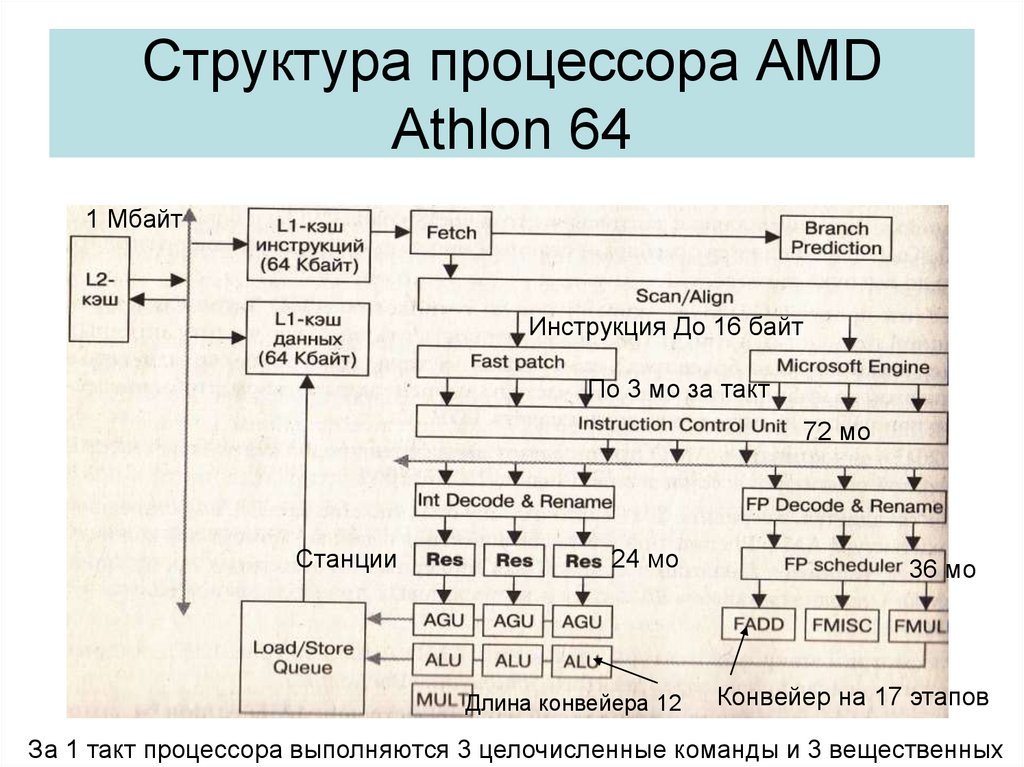
03. Назначение и структура процессора. Назначение и взаимодействие основных блоков. Классификация процессоров.
Назначение. Принцип работы.
Процессором — называется устройство, непосредственно осуществляющее процесс обработки данных и программное управление этим процессом. Процессор дешифрует и выполняет команды программ, организует обращение к ОП, инициирует работу ПУ, воспринимает и обрабатывает внешние события.
Процессор осуществляет управление взаимодействием всех устройств ЭВМ. (при наличии специальных процессоров эти функции рассредотачиваются).
Общая функциональная структура МП.
Структурная схема процессора:
Разъяснения к структурной схеме:
— ОП обычно не входит в состав МП и реализуется внешними схемами, но в небольших ЭВМ, ОЭВМ может совмещаться с ЦП.
— АЛУ процессора
выполняет логические, арифметические операции над данными. В МП может имеется
одно универсальное АЛУ для всех операций или несколько специальных АЛУ для
отдельных видов операций.
В МП может имеется
одно универсальное АЛУ для всех операций или несколько специальных АЛУ для
отдельных видов операций.
— УУ вырабатывает последовательность управляющих сигналов, инициирующих выполнение соответствующей последовательности микроопераций обеспечивающей реализацию текущей команды.
— Блок управляющих регистров предназначен для временного хранения управляющей информации. Он содержит регистры и счетчики, участвующие в управлении вычислительным процессом: состояние МП, регистр — счетчик адреса команды, счетчики тактов, регистр запросов прерываний.
— Блок регистровой памяти — местная память более высокого быстродействия чем ОП. Регистры этого блока служат для хранения операндов, в качестве аккумуляторов, базовых и индексных регистров, указателя стека.
— Блок связи с ОП организует обмен информацией процессора с ОП и защиту участков ОП от недозволенных данной программе обращений, а также связь МП с ПУ.
— Блок контроля и
диагностики служит для обнаружения сбоев и отказов в аппаратуре МП,
восстановление работы программы после сбоев и поиска места неисправности при
отказах.
|
|||
 75 А
75 АОбщие сведения о настройке питания и производительности для Windows Server
- Чтение занимает 15 мин
Оцените свои впечатления
Да Нет
Хотите оставить дополнительный отзыв?
Отзывы будут отправляться в корпорацию Майкрософт.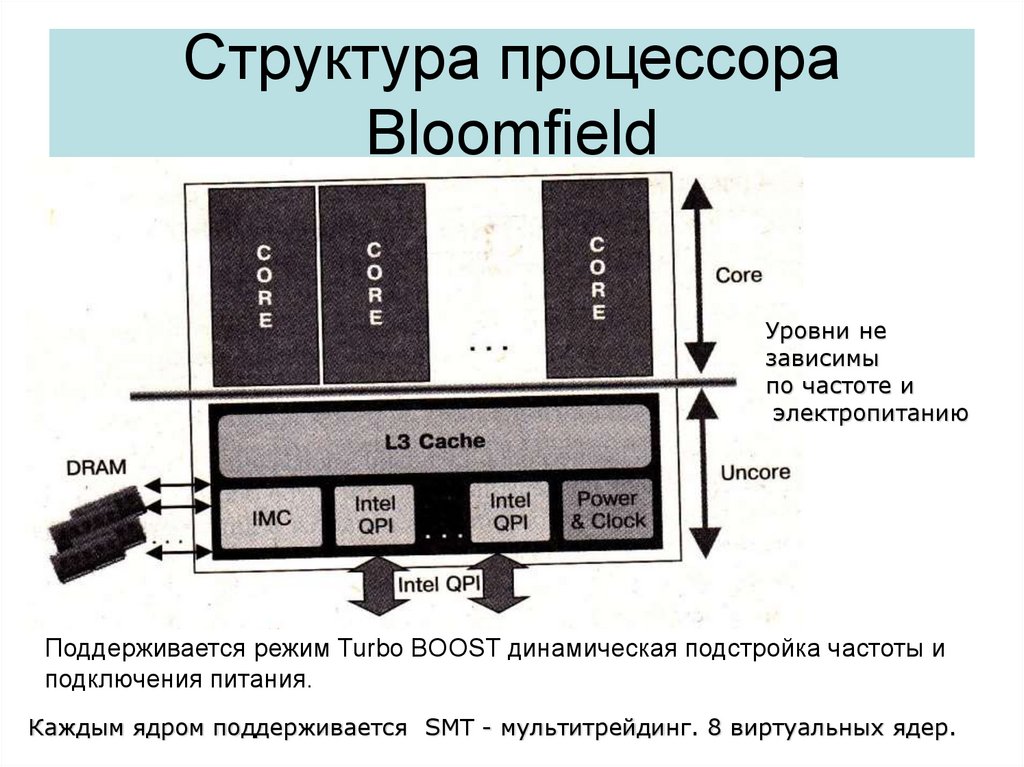 Нажав кнопку «Отправить», вы разрешаете использовать свой отзыв для улучшения продуктов и служб Майкрософт. Политика конфиденциальности.
Нажав кнопку «Отправить», вы разрешаете использовать свой отзыв для улучшения продуктов и служб Майкрософт. Политика конфиденциальности.
Отправить
Спасибо!
В этой статье
Эффективность энергопотребления в корпоративных средах и центрах обработки данных все равно важна, и она добавляет еще один набор компромиссов к сочетаниям параметров конфигурации. При управлении серверами важно убедиться, что они выполняются максимально эффективно, при этом удовлетворяют потребности в производительности рабочих нагрузок. Windows Server оптимизирован для обеспечения высокой эффективности энергопотребления с минимальным влиянием на производительность в самых разных рабочих нагрузках клиентов. настройка управления питанием процессора (система УПП) для схемы управления питанием с балансировкой Windows Server описывает рабочие нагрузки, используемые для настройки параметров по умолчанию в нескольких версиях Windows Server, а также предоставляет рекомендации по настройке.
В этом разделе разворачиваются компромиссы, помогающие принимать взвешенные решения, если необходимо изменить параметры управления питанием по умолчанию на сервере. однако большинство серверного оборудования и рабочих нагрузок не должны требовать настройки управления питанием администратора при работе Windows server.
Выбор метрик поворота
При настройке сервера для энергосбережения необходимо также учитывать производительность. Настройка влияет на производительность и энергопотребление, иногда в непропорциональной сумме. Для каждой возможной корректировки рассмотрите требования к бюджету питания и производительности, чтобы определить, приемлемо ли компромисс.
настройка параметров по умолчанию для Windows сервера использует экономичность энергии в качестве ключевой метрики для балансировки мощности и производительности. Эффективность энергопотребления — это отношение работы к среднему питанию, которое требуется в течение определенного периода времени.
Эту метрику можно использовать для установки практических целей, учитывающих компромисс между питанием и производительностью. В отличие от этого, цель экономии энергии в 10% в центре обработки данных не позволяет захватить соответствующие эффекты на производительность и наоборот.
В отличие от этого, цель экономии энергии в 10% в центре обработки данных не позволяет захватить соответствующие эффекты на производительность и наоборот.
Аналогичным образом, если настроить сервер для повышения производительности на 5%, что приводит к увеличению энергопотребления на 10 процентов, то общий результат может быть неприемлемым для ваших бизнес-целей. Метрика эффективности энергопотребления позволяет принимать более обоснованные решения, а не только метрики мощности или производительности.
Измерение энергопотребления системы
Прежде чем настраивать сервер для повышения эффективности энергопотребления, следует установить базовое измерение мощности.
если сервер имеет необходимую поддержку, можно использовать функции измерения и управления питанием в Windows Server 2016 для просмотра потребления энергии на уровне системы с помощью системного монитора.
один из способов определить, поддерживает ли ваш сервер отслеживание и бюджетирование, — просматривать каталог Windows server.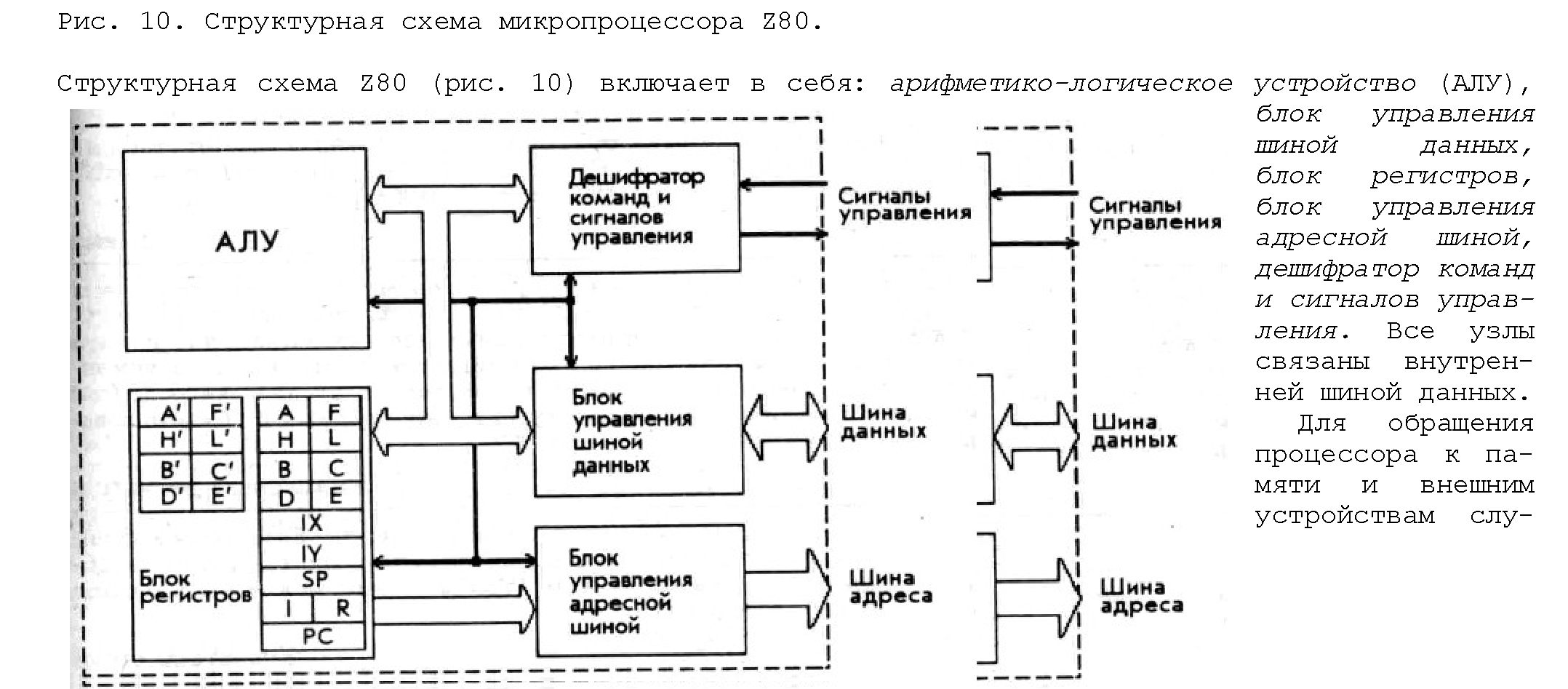 если модель сервера соответствует новой расширенной квалификации по управлению питанием в программе Windows сертификации оборудования, гарантируется поддержка функций измерения и бюджетирования.
если модель сервера соответствует новой расширенной квалификации по управлению питанием в программе Windows сертификации оборудования, гарантируется поддержка функций измерения и бюджетирования.
Другой способ проверить поддержку отслеживания использования — вручную найти счетчики в системном мониторе. Откройте системный монитор, выберите Добавить счетчики, а затем найдите группу счетчиков индикатора питания .
Если в поле экземпляры выбранного объектаотображаются именованные экземпляры Power метры, ваша платформа поддерживает измерение. Счетчик питания , отображающий питание в ватт, отображается в выбранной группе счетчиков. Точное наследование значения данных о питании не указано. Например, это может быть мгновенное Рисование энергии или среднее энергопотребление за некоторый интервал времени.
Если серверная платформа не поддерживает измерение, можно использовать физическое устройство, подключенное к источнику питания, чтобы измерять энергопотребление системы или энергопотребление.
Чтобы установить базовый уровень, необходимо измерять среднюю мощность, необходимую для различных точек загрузки системы, от бездействия до 100% (максимальная пропускная способность) для создания линии загрузки. На следующем рисунке показаны линии загрузки для трех образцов конфигураций:
Строки загрузки можно использовать для оценки и сравнения производительности и потребления энергии конфигураций во всех точках загрузки. В этом конкретном примере можно легко увидеть, что такое лучшая конфигурация. Однако возможны ситуации, когда одна конфигурация лучше всего подходит для интенсивных рабочих нагрузок, и одна из них лучше всего подходит для облегченных рабочих нагрузок.
Чтобы выбрать оптимальную конфигурацию, необходимо тщательно разобраться в требованиях к рабочей нагрузке. Не следует думать, что при обнаружении хорошей конфигурации она всегда будет оптимальной. Вы должны измерять использование системы и энергопотребление на регулярной основе и после изменений рабочих нагрузок, уровней рабочей нагрузки или серверного оборудования.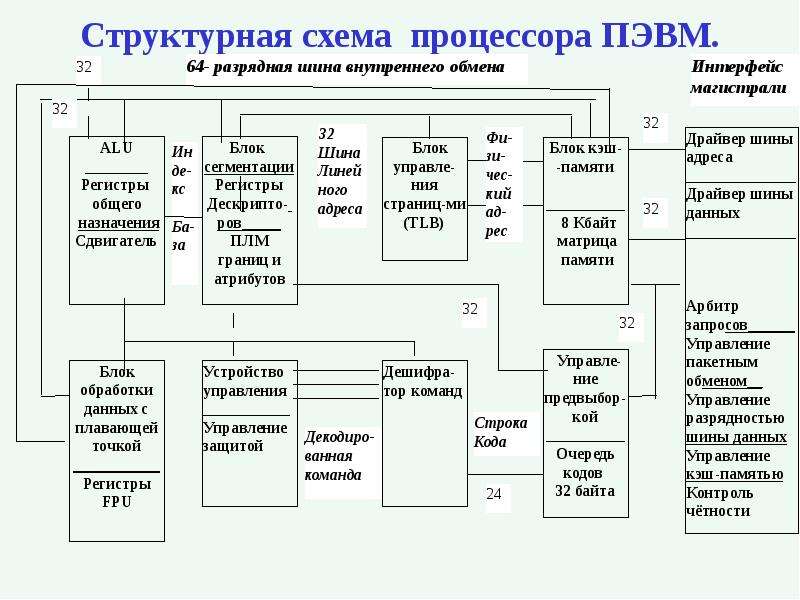
Диагностика проблем с энергосбережением
PowerCfg.exe поддерживает параметр командной строки, который можно использовать для анализа эффективности сервера в неактивном энергопотреблении. При запуске PowerCfg.exe с параметром /енерги средство выполняет проверку 60-секунд для обнаружения потенциальных проблем с энергосбережением. Средство создает простой HTML-отчет в текущем каталоге.
Важно!
Чтобы обеспечить точный анализ, перед запуском PowerCfg.exeубедитесь, что все локальные приложения закрыты.
Сокращение частоты тактов таймера, драйверов, в которых отсутствует поддержка управления питанием и чрезмерное использование ЦП, — это несколько проблем поведения, обнаруженных командой powercfg/енерги . Это средство предоставляет простой способ обнаружения и устранения проблем управления питанием, что может привести к значительному снижению затрат в большом центре обработки данных.
Дополнительные сведения о PowerCfg. exe см. в разделе Параметры командной строки Powercfg.
exe см. в разделе Параметры командной строки Powercfg.
использование схем управления питанием в Windows Server
Windows Server 2016 имеет три встроенных плана управления питанием, разработанных для удовлетворения различных бизнес-потребностей. Эти планы предоставляют простой способ настройки сервера в соответствии с целями питания или производительности. В следующей таблице описаны планы, перечислены распространенные сценарии использования каждого плана и приведены некоторые сведения о реализации каждого плана.
| План | Описание | Распространенные применимые сценарии | Основные особенности реализации |
|---|---|---|---|
| Сбалансированный (рекомендуется) | Значение по умолчанию. Нацелены на экономичное энергопотребление с минимальным влиянием на производительность. | Общие вычисления | Соответствует емкости по запросу. Экономия энергии обеспечивает баланс мощности и производительности. |
| Высокая производительность | Повышение производительности за счет использования высокой энергии. Действуют ограничения по питанию и температуре, эксплуатационные расходы и надежность. | Приложения с низкой задержкой и код приложения, которые чувствительны к изменениям производительности процессора | Процессоры всегда блокируются с наибольшим состоянием производительности (включая частоты «Turbo»). Все ядра не будут приостановлены. Данные для термальной температуры могут быть значительными. |
| Экономия энергии | Ограничивает производительность для экономии энергии и снижения эксплуатационных расходов. Не рекомендуется без тщательного тестирования, чтобы обеспечить достаточную производительность. | Развертывания с ограниченными бюджетами питания и температурными ограничениями | Частота процессора с поддержкой CAPS в процентах от максимального (если поддерживается) и включает другие функции энергосбережения. |
эти схемы управления питанием существуют в Windows для чередующихся систем с питанием от сети и прямого тока (DC), но предполагается, что серверы всегда используют источник питания AC.
Дополнительные сведения о схемах управления питанием и конфигурациях политик питания см. в разделе Параметры командной строки Powercfg.
Примечание
Некоторые серверные производства имеют собственные возможности управления питанием, доступные в настройках BIOS. если операционная система не имеет контроля над управлением питанием, изменение схем управления питанием в Windows не повлияет на энергопотребление и производительность системы.
Настройка параметров управления питанием процессора
Каждая схема управления питанием представляет собой сочетание многочисленных параметров управления питанием. Встроенные планы — это три коллекции рекомендуемых параметров, охватывающие разнообразные рабочие нагрузки и сценарии. Однако мы понимаем, что эти планы не будут соответствовать потребностям каждого клиента.
В следующих разделах описаны способы настройки некоторых параметров управления питанием процессора в соответствии с целями, которые не были решены тремя встроенными планами. Если необходимо получить представление о более широком массиве параметров питания, см. раздел Параметры командной строки Powercfg.
Если необходимо получить представление о более широком массиве параметров питания, см. раздел Параметры командной строки Powercfg.
Intel управляется оборудованием P-States (ХВП)
начиная с процессоров intel Broadwell, использующих WS2016, Windows система УПП использует программное обеспечение intel, управляемое оборудованием P-states (хвп). ХВП — это новая возможность для совместного управления оборудованием и программной производительностью. Когда ХВП включен, ЦП наблюдает за работой и масштабируемостью и выбирает частоту в аппаратном масштабе времени. ОС больше не требуется для мониторинга активности и выбора частоты через равные промежутки времени. Переключение на ХВП имеет несколько преимуществ:
- Быстро отвечайте на пакетные рабочие нагрузки. Windows интервал проверки система УПП установлен как 30ms по умолчанию и может быть уменьшен как минимум до 15ms. Однако ХВП может настроить частоту на быстром уровне при каждом 1 мс.
- ЦП дает лучшие знания о производительности оборудования каждого состояния P.
 Это позволяет лучше выбрать частоту процессора для достижения максимальной эффективности энергопотребления.
Это позволяет лучше выбрать частоту процессора для достижения максимальной эффективности энергопотребления. - ЦП может использовать другие аппаратные возможности, например память, GPU и т. д., в учетную запись для достижения максимальной эффективности работы при определенных TDPах (тепловой мощности).
 Это позволяет лучше выбрать частоту процессора для достижения максимальной эффективности энергопотребления.
Это позволяет лучше выбрать частоту процессора для достижения максимальной эффективности энергопотребления.Windows может по-прежнему устанавливать минимальное и максимальное состояния процессора, чтобы ограничить диапазон частот, которые могут выполняться процессорами. Кроме того, он может установить следующий параметр политики настройки производительности энергопотребления процессора (EPP), чтобы указать ХВП в качестве приоритета для мощности или производительности.
- Политика настройки производительности энергопотребления процессора для установки баланса между питанием и производительностью. Чем меньше значение, тем выше производительность, а более высокое значение — преимущество. Значение может находиться в диапазоне от 0 до 100. Значение по умолчанию 50, которое используется для балансировки мощности и производительности.
Приведенные ниже команды уменьшают значение EPP до 0 в текущей схеме управления питанием, чтобы полностью повысить производительность по сравнению с энергопотреблением.
Powercfg -setacvalueindex scheme_current sub_processor PERFEPP 0
Powercfg -setactive scheme_current
Минимальное и максимальное состояние производительности процессора
Процессоры меняются между состояниями производительности (P-состояния) очень быстро, чтобы соответствовать спросу, обеспечивая производительность по мере необходимости и экономию энергии, когда это возможно. Если сервер имеет определенные высокопроизводительные или минимальные требования к энергопотреблению, можно подумать о настройке минимального значения параметра состояния производительности процессора или параметра состояния максимальной производительности процессора .
Значения минимального состояния производительности процессора и максимального состояния производительности процессора выражаются в процентах от максимальной частоты процессора и значения в диапазоне от 0 до 100.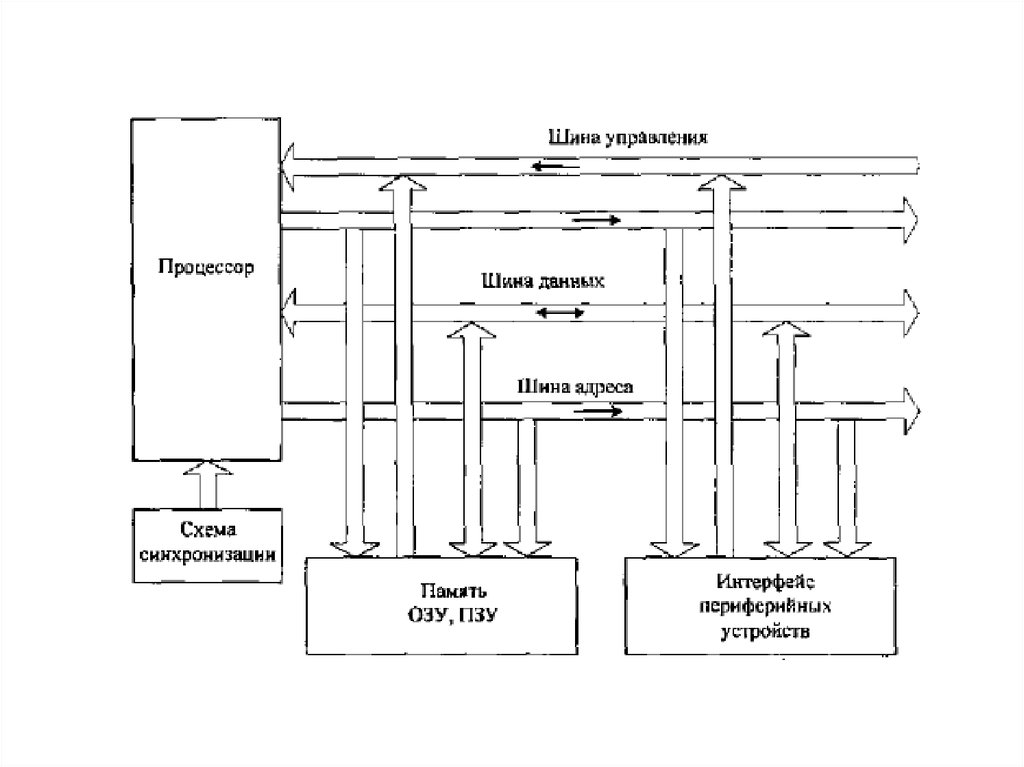
Если сервер требует высокой задержки, неизменяемой частоты ЦП (например, для повторяемого тестирования) или наивысшего уровня производительности, процессоры могут переключаться на более низкие состояния производительности. Для такого сервера можно ограничить минимальное состояние производительности процессора на 100% с помощью следующих команд:
Powercfg -setacvalueindex scheme_current sub_processor PROCTHROTTLEMIN 100
Powercfg -setactive scheme_current
Если сервер требует снижения энергопотребления энергии, может потребоваться закрепление состояния производительности процессора в процентах от максимума. Например, можно ограничить процессор до 75% от максимальной частоты с помощью следующих команд:
Powercfg -setacvalueindex scheme_current sub_processor PROCTHROTTLEMAX 75
Powercfg -setactive scheme_current
Примечание
При ограничении производительности процессора в процентах от максимума требуется поддержка процессора. Проверьте документацию по процессору, чтобы определить, существует ли такая поддержка, или просмотрите счетчик производительности » % максимальной частоты » в группе » процессор «, чтобы узнать, были ли применены какие либо ограничения по частоте.
Проверьте документацию по процессору, чтобы определить, существует ли такая поддержка, или просмотрите счетчик производительности » % максимальной частоты » в группе » процессор «, чтобы узнать, были ли применены какие либо ограничения по частоте.
Переопределение скорости реагирования процессора
Алгоритмы управления питанием на основе использования ЦП обычно используют среднюю загрузку ЦП в окне проверки времени, чтобы определить, нужно ли увеличивать или уменьшать частоту. Это может отрицательно понизить задержку дисковых операций ввода-вывода или интенсивных сетевых нагрузок. Логический процессор может быть бездействующим при ожидании завершения дискового ввода-вывода или сетевых пакетов, что приводит к нехватке общего использования ЦП. В результате Управление питанием будет выбирать низкую частоту для этого процессора. Эта проблема существует и в управлении питанием на основе ХВП. DPC и потоки, обрабатывающие завершение операций ввода-вывода или сетевые пакеты, находятся в критическом пути и не должны выполняться с низкой скоростью.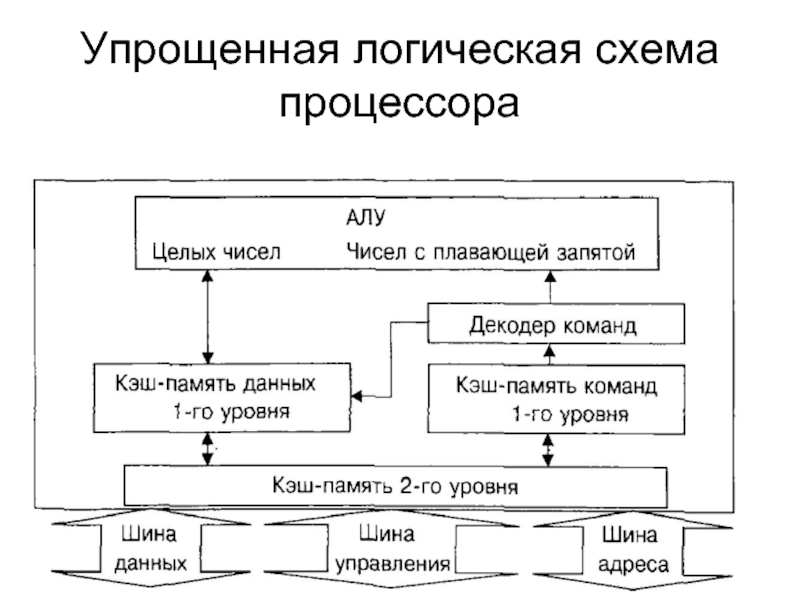 чтобы устранить эту проблему, Windows система УПП учитывает число dpc. если число DPC превышает определенный порог в прошлом окне мониторинга, система УПП введет период скорости реагирования ввода-вывода и порождает частоту, связанную с более высоким уровнем. Такт частоты будет сброшен, когда число DPC достаточно мало для некоторого времени. Поведение может быть настроено с помощью следующих параметров.
чтобы устранить эту проблему, Windows система УПП учитывает число dpc. если число DPC превышает определенный порог в прошлом окне мониторинга, система УПП введет период скорости реагирования ввода-вывода и порождает частоту, связанную с более высоким уровнем. Такт частоты будет сброшен, когда число DPC достаточно мало для некоторого времени. Поведение может быть настроено с помощью следующих параметров.
| Параметр | Описание | Значение по умолчанию | Минимальное значение | Максимальное значение |
|---|---|---|---|---|
| Переопределение включения скорости реагирования процессора | Число DPC в рамках проверки производительности, выше которых должны быть включены переопределения скорости реагирования процессора | 10 | 0 | Недоступно |
| Переопределение порогового значения отключения процессора | Число DPC в рамках проверки производительности, по которой следует отключить переопределение скорости реагирования процессора | 5 | 0 | Недоступно |
| Переопределение времени реагирования процессора | Число последовательных проверок производительности, которые должны соответствовать пороговому значению включения до включения переопределений скорости реагирования процессора | 1 | 1 | 100 |
| Время отключения процессора — переопределение | Число последовательных проверок производительности, которые должны соответствовать пороговому значению отключения до отключения переопределений скорости реагирования процессора | 3 | 1 | 100 |
| Основание производительности при отклике процессора | Минимальная допустимая производительность процессора при включенных переопределениях скорости реагирования процессора | 100 | 0 | 100 |
| Повышение скорости реагирования процессора переопределение настроек производительности энергии | Значение политики максимального приоритета энергии, если переопределение скорости реагирования процессора включено | 100 | 0 | 100 |
Например, если Рабочая нагрузка сервера не чувствительна к задержке и требуется освободить переопределение скорости реагирования, можно увеличить переопределение скорости реагирования процессора, а также разрешить переопределение скорости реагирования процессора, уменьшить пороговое значение отключения процессора и переопределить время отклика процессора. После этого система будет трудно ввести в состояние переопределение отклика. Значение по умолчанию для счетчика производительности «время реагирования процессора» задается как 100, так что период переопределения скорости реагирования будет выполняться с максимальной частотой. Кроме того, можно уменьшить производительность процессора и уменьшить скорость реагирования процессора, чтобы позволить ХВП настраивать частоту. Ниже приведены примеры команд для задания параметров текущей активной схемы управления питанием.
После этого система будет трудно ввести в состояние переопределение отклика. Значение по умолчанию для счетчика производительности «время реагирования процессора» задается как 100, так что период переопределения скорости реагирования будет выполняться с максимальной частотой. Кроме того, можно уменьшить производительность процессора и уменьшить скорость реагирования процессора, чтобы позволить ХВП настраивать частоту. Ниже приведены примеры команд для задания параметров текущей активной схемы управления питанием.
Powercfg -setacvalueindex scheme_current sub_processor RESPENABLETHRESHOLD 100
Powercfg -setacvalueindex scheme_current sub_processor RESPDISABLETHRESHOLD 1
Powercfg -setacvalueindex scheme_current sub_processor RESPENABLETIME 10
Powercfg -setacvalueindex scheme_current sub_processor RESPDISABLETIME 1
Powercfg -setacvalueindex scheme_current sub_processor RESPPERFFLOOR 5
Powercfg -setacvalueindex scheme_current sub_processor RESPEPPCEILING 50
Powercfg -setactive scheme_current
Режим повышения производительности процессора
Эта настройка параметров применяется только к системам, не являющимся ХВП.
Технологии Intel Turbo Boost и AMD Turbo CORE — это функции, позволяющие процессорам добиться дополнительной производительности, когда она наиболее полезна (то есть при высоких нагрузках на систему). однако эта функция увеличивает энергопотребление цп, поэтому Windows Server 2016 настраивает технологии Turbo на основе используемой политики электропитания и конкретной реализации процессора.
Для высокопроизводительных схем управления питанием на всех процессорах Intel и AMD включена поддержка Turbo, и для них отключены схемы Power энергосберегающая. Для сбалансированных схем управления питанием в системах, основанных на традиционном управлении частотой, основанной на состоянии P-состояния, Turbo включается по умолчанию, только если платформа поддерживает Регистр ЕПБ.
Примечание
Регистр ЕПБ поддерживается только в процессорах Intel Вестмере и более поздних версий.
Для процессоров Intel Нехалем и AMD по умолчанию Turbo отключено на платформах, основанных на состоянии P-State. однако, если система поддерживает управление производительностью совместного использования процессора (кппк), то есть новый альтернативный режим взаимодействия между операционной системой и оборудованием (определенный в ACPI 5,0), можно использовать Turbo, если Windows операционная система динамически запрашивает оборудование для обеспечения максимального числа возможных уровней производительности.
однако, если система поддерживает управление производительностью совместного использования процессора (кппк), то есть новый альтернативный режим взаимодействия между операционной системой и оборудованием (определенный в ACPI 5,0), можно использовать Turbo, если Windows операционная система динамически запрашивает оборудование для обеспечения максимального числа возможных уровней производительности.
Чтобы включить или отключить функцию Turbo Boost, параметр режима повышения производительности процессора должен быть настроен администратором или параметрами по умолчанию для выбранной схемы управления питанием. Режим повышения производительности процессора имеет пять допустимых значений, как показано в таблице 5.
Для элементов управления на основе P-состояния варианты отключаются, включаются (устройство Turbo доступно оборудованию при запросе номинальной производительности) и эффективно (Turbo доступно только при реализации регистра ЕПБ).
для элемента управления на основе кппк варианты отключаются, эффективность включена (Windows указывает точный объем быстрого доступа) и агрессивный (Windows запрашивает максимальную производительность, чтобы включить Turbo).
в Windows Server 2016 значение по умолчанию для режима усиления — 3.
| имя; | Поведение на основе P-состояния | Поведение КППК |
|---|---|---|
| 0 (отключено) | Выключено | Выключено |
| 1 (включено) | Активировано | Эффективность включена |
| 2 (агрессивно) | Включен | Aggressive |
| 3 (эффективность включена) | Эффективно | Эффективность включена |
| 4 (эффективный агрессивный) | Эффективно | Aggressive |
Следующие команды включают режим повышения производительности процессора в текущей схеме управления питанием (укажите политику с помощью псевдонима GUID):
Powercfg -setacvalueindex scheme_current sub_processor PERFBOOSTMODE 1
Powercfg -setactive scheme_current
Важно!
Чтобы включить новые параметры, необходимо выполнить команду powercfg-сетактиве . Перезагружать сервер не требуется.
Перезагружать сервер не требуется.
Чтобы задать это значение для схем управления питанием, отличных от текущего выбранного плана, можно использовать псевдонимы, такие как SCHEME_MAX (экономия энергии), SCHEME_MIN (высокая производительность) и SCHEME_BALANCED (сбалансированная) вместо SCHEME_CURRENT. Замените «схема Current» в командах Powercfg-сетактиве, которые ранее отображались с нужным псевдонимом, чтобы включить эту схему управления питанием.
Например, чтобы настроить режим усиления в плане экономии энергии и сделать его текущим планом, выполните следующие команды:
Powercfg -setacvalueindex scheme_max sub_processor PERFBOOSTMODE 1
Powercfg -setactive scheme_max
Увеличение производительности процессора и снижение пороговых значений и политик
Эта настройка параметров применяется только к системам, не являющимся ХВП.
Скорость, с которой увеличивается или уменьшается состояние производительности процессора, управляется несколькими параметрами. Следующие четыре параметра имеют наиболее заметные последствия:
Порог увеличения производительности процессора определяет значение использования, по достижении которого увеличится состояние производительности процессора. Большие значения снижают скорость увеличения состояния производительности в ответ на повышенные действия.
Порог уменьшения производительности процессора определяет значение использования, ниже которого будет снижаться состояние производительности процессора. Большие значения увеличивают скорость уменьшения состояния производительности во время периодов простоя.
Производительность процессора увеличение политики и снижение производительности процессора Политика определяет, какое состояние производительности должно быть задано при изменении. Политика «Single» означает, что она выбирает следующее состояние. «Rocket» — максимальное или минимальное состояние производительности электропитания. «Идеальный вариант» пытается найти баланс между питанием и производительностью.
Например, если сервер требует высокой задержки, при этом вы по-прежнему захотите воспользоваться преимуществами низкого энергопотребления в периодах простоя, то можно было бы увеличить состояние производительности для любого увеличения нагрузки и замедлить уменьшение времени, когда нагрузка выйдет из строя. Следующие команды устанавливают для политики увеличения значение «Rocket» для ускорения увеличения состояния и устанавливают для политики уменьшения значение «Single». Пороговые значения увеличения и уменьшения задаются равными 10 и 8 соответственно.
Powercfg.exe -setacvalueindex scheme_current sub_processor PERFINCPOL 2
Powercfg.exe -setacvalueindex scheme_current sub_processor PERFDECPOL 1
Powercfg.exe -setacvalueindex scheme_current sub_processor PERFINCTHRESHOLD 10
Powercfg.exe -setacvalueindex scheme_current sub_processor PERFDECTHRESHOLD 8
Powercfg.exe /setactive scheme_current
Максимальное и минимальное число ядер для ядер производительности процессора
стоянка ядер — это функция, появившаяся в Windows Server 2008 R2. подсистема управления питанием процессора (система УПП) и планировщик работают вместе для динамического регулирования количества ядер, доступных для выполнения потоков. подсистема система УПП выбирает минимальное количество ядер для потоков, которые будут запланированы.
Для ядер, которые приостановлены, обычно не запланировано ни одного потока, и они будут переведены в очень низкие состояния питания, если они не обрабатывают прерывания, DPC или другие строго привязаны работы. Остальные ядра отвечают за оставшуюся часть рабочей нагрузки. Стоянка ядер потенциально может повысить эффективность энергопотребления во время пониженного использования.
Для большинства серверов поведение ядра по умолчанию обеспечивает разумное распределение пропускной способности и энергии. На процессорах, где стоянка ядра может не показывать как можно больше преимуществ универсальных рабочих нагрузок, по умолчанию она может быть отключена.
Если сервер имеет определенные основные требования к стоянке, можно управлять количеством ядер, доступных для приостановки, с помощью параметра максимального числа ядер ядра производительности процессора или параметра «минимальное число ядер ядра производительности процессора » в Windows Server 2016.
Один из сценариев, в котором основная стоянка не всегда оптимальна для, — когда один или несколько активных потоков привязаны к нетривиальному подмножеству ЦП узла NUMA (то есть более 1 ЦП, но меньше, чем весь набор ЦП на узле). Когда основной алгоритм стоянки выполняет комплектацию ядер для освобождения (при условии увеличения интенсивности рабочей нагрузки), он может не всегда выбирать ядра в активном подмножестве привязаны (или подмножествах) для освобождения, что может привести к неприпаркованным ядрам, которые фактически не используются.
Значения этих параметров задаются в процентах в диапазоне от 0 до 100. Параметр максимального числа ядер ядра производительности процессора управляет максимальным процентом ядер, которые могут быть неприпаркованными (доступными для выполнения потоков) в любое время, в то время как параметр минимального числа ядер ядра производительности процессора управляет минимальным процентом ядер, которые могут быть неприпаркованными. Чтобы отключить приостановка ядра, задайте для параметра минимального количества ядер ядра производительности процессора значение 100% с помощью следующих команд:
Powercfg -setacvalueindex scheme_current sub_processor CPMINCORES 100
Powercfg -setactive scheme_current
Чтобы уменьшить количество планируемых ядер до 50% от максимального значения счетчика, задайте для параметра Максимальная доля ядер ядра производительности процессора значение 50 следующим образом:
Powercfg -setacvalueindex scheme_current sub_processor CPMAXCORES 50
Powercfg -setactive scheme_current
Распространение служебной программы парковки ядра производительности процессора
распространение служебной программы — это алгоритм оптимизации в Windows Server 2016, предназначенный для повышения эффективности энергопотребления для некоторых рабочих нагрузок. Он отслеживает неперемещаемую активность ЦП (то есть DPC, прерываний или строго привязаны потоков) и прогнозирует будущую работу на каждом процессоре в зависимости от предположения, что любая перемещаемая работа может равномерно распределяться по всем неприпаркованным ядрам.
Распространение служебной программы включено по умолчанию для сбалансированной схемы управления питанием для некоторых процессоров. Это позволяет сократить энергопотребление процессора, уменьшая запрошенные частоты ЦП рабочих нагрузок, которые находятся в определенном стабильном состоянии. Однако распространение служебной программы не обязательно является хорошим выбором алгоритма для рабочих нагрузок, для которых накладываются высокие объемы действий или для программ, в которых Рабочая нагрузка быстро и случайно смещается между процессорами.
Для таких рабочих нагрузок рекомендуется отключить распространение служебной программы с помощью следующих команд:
Powercfg -setacvalueindex scheme_current sub_processor DISTRIBUTEUTIL 0
Powercfg -setactive scheme_current
Дополнительные ссылки
Архитектура процессора Intel 80486 – схема, регистры
КомпьютерПресс №3 1993. А. Борзенко
Интегральная схема микропроцессора i80486 была анонсирована фирмой Intel в 1989 году на выставке Comdex в Чикаго. И хотя, очевидно, нам не долго уже осталось ждать появления нового 586-го микропроцессора, на сегодняшний день одним из самых мощных универсальных микропроцессоров является i80486.
Архитектура микропроцессора i80486
«В архитектуре взаимосвязаны функциональные, технические и эстетические
начала — польза, прочность, красота».
(Из словаря)
Микропроцессор i80486 достойный продолжатель семейства i80x86‚ поскольку он позволяет создавать вычислительные системы намного более производительные, чем, предположим, на микропроцессоре i80386. В принципе микросхема i80486 состоит из полного микропроцессора i80386, арифметического сопроцессора i80387 и контроллера кэш-памяти i82385. Понятно, что речь не идет о механическом соединении функциональных устройств на одном кристалле. Высокая степень интеграции (более миллиона транзисторов) — это не просто технологическое достижение, а возможность реализовать новые архитектурные решения, которые позволяют повысить производительность микропроцессора. Так, например, в микропроцессоре i80486 используется конвейерная обработка команд, достаточно широко применяемая в RISC-процессорах. При одной и той же тактовой частоте с i80386 микропроцессор i80486 работает в три-четыре раза производительнее. Это связано с уменьшением количества циклов (тактов), необходимых для выполнения команды (инструкции).
Три в одном
На рис. 1 приведена примерная блок-схема микропроцессора i80486, на которой достаточно легко выделить его основные функциональные узлы — устройство управления памятью (Memory Management Unit, MMU), модуль арифметического сопроцессора (Floating Point Unit, FPU) и блок кэш-памяти (Cache Unit). Несмотря на то, что микропроцессор i80486 обладает всеми свойствами, присущими i80386, имеются, конечно, и различия. Например, в набор команд микропроцессора i80486 наряду с известными инструкциями для i80386, включено несколько дополнительных команд. Однако устройство управления памятью MMU полностью совместимо с аналогичным устройством в i80386. То же можно сказать и о FPU. А это, вообще говоря, означает, что все программное обеспечение, работающее на серии микропроцессоров 80×86/80×87, без внесения каких-либо изменений будет работать и на i80486.
Рис. 1. Блок-схема микропроцессора 80486 увеличить рисунокУстройство управления памятью MMU состоит в свою очередь из устройства сегментации (Segmentation Unit) и устройства управления страницами (Paging Unit). Благодаря делению памяти на сегменты (сегментации) коды программ и области данных могут находиться практически в любом месте логического адресного пространства. Иными словами, при сегментной организации памяти каждый модуль занимает свою собственную сплошную область памяти, тогда как при страничной организации модуль разбивается на отдельные страницы. В свою очередь, устройство управления страницами позволяет реализовать механизм страничной организации памяти, который функционирует на более низком уровне и является прозрачным по отношению к процессу сегментации. Это дает возможность управления физическим адресным пространством. Следует также отметить, что страничная организация памяти (paging) может быть отключена чисто программным способом.
Каждый сегмент памяти может подразделяться на один или несколько 4-Кбайтных блоков. А память, в свою очередь, может быть организована в виде одного или нескольких таких сегментов, размер которых может достигать 4 Гбайт. Причем каждому такому сегменту могут придаваться соответствующие атрибуты, которые определяют его расположение в памяти, величину, вид (стек, код, данные) и характеристику защиты. Каждая задача, выполняемая на i80486, может в принципе состоять из 16 381 сегмента, по 4 Гбайта каждый. Таким образом, диапазон виртуальной адресации достигает 64 Тбайт. Устройство сегментации микропроцессора поддерживает четыре механизма защиты приложений и системного режима друг от друга. Благодаря этому на базе микропроцессора i80486 возможно построение высокозащищенных систем.
Принципиально микропроцессор i80486 имеет два режима работы: реальный режим (Real Mode, иначе 8086-Mode) и защищенный (Protected Mode). При этом в реальном режиме он ведет себя просто как очень быстрый микропроцессор i8086. Из этого режима i80486 может легко переключиться в защищенный режим, в котором имеются богатые возможности управления памятью. Например, в этом режиме возможно переключение с одной задачи на другую, причем их обработка будет происходить как обработка независимых задач на своих i8086 микропроцессорах (режим «виртуальных 8086-машин»). Такое название связано с тем, что каждая задача ведет себя таким же образом, как если бы она выполнялась на собственном процессоре i8086 (соответственно i8088).
Устройство арифметического сопроцессора в i80486 работает параллельно с АЛУ и поддерживает большое количество арифметических команд для различных типов операндов. Это, в частности, многочисленные трансцендентные функции, такие как синус, косинус, тангенс, логарифм и т.д. Нужно отметить, что FPU полностью поддерживает стандарт ANSI/IEEE 754-1985 на арифметические операции с плавающей точкой.
Размер внутренней кэш-памяти микропроцессора i80486 составляет 8 Кбайт. Сразу следует сказать, что для некоторых приложений такой размер кэш-памяти вовсе не достаточен. Это касается в первую очередь САПР и настольных издательских систем. Однако в этом случае при разработке соответствующей системы можно воспользоваться кэш-контроллером i82485 и внешней кэш-памятью объемом 64 или 128 Кбайт. Внутренняя кэш-память выполнена как ассоциативная и работает в режиме write through (то есть данные заносятся одновременно и в кэш-память, и в ОЗУ). Кэш в микропроцессоре i80486, безусловно, имеет и некоторые особенности. В частности, страницы памяти могут быть обозначены либо как «кэшируемые», либо как «некэшируемые», причем такое обозначение можно вводить как аппаратно, так и программно. Впрочем, даже само устройство кэша может быть также отключено как аппаратно, так и программно. По некоторым оценкам, использование встроенной кэш-памяти экономит до 80% времени, необходимого для обращения к ОЗУ.
Регистры, регистры, регистры…
Микропроцессор i80486 содержит, конечно, все регистры, имеющиеся в микросхемах i80386 и i80387. Регистры рассматриваемого микропроцессора можно условно подразделить на три большие группы: базовые регистры, регистры системного уровня и регистры плавающей точки. Рассмотрим эти группы регистров несколько подробнее.
Программная модель i80486 определяется главным образом базовыми регистрами, которые приведены на рис. 2. Это — восемь 32-разрядных регистров общего назначения, которые могут работать с операндами данных размерами 1, 2 и 4 байта или полями бит от 1 до 32. Однако операнды адреса могут иметь длину только либо 2, либо 4 байта. Эти 32-разрядные регистры обозначаются как EAX, EBX, ECX, EDX, ESI, EDI, EBP и ESP. Обозначения двух младших байт этих регистров пользователям микропроцессоров i8088/86/286 уже хорошо известны. Конечно, это — AX, BX, CX, DX, SI, DI, BP и SP. Причем следует отметить, что при доступе к старшим двум байтам этих 32-разрядных регистров содержимое двух младших байтов не изменяется. Этим обуславливается совместимость сверху-вниз с микропроцессором i80286. Операции с байтовыми операндами (старший и младший байты) доступны только для четырех регистров AX, BX, CX, DX, причем старшие байты соответствуют обозначениям AH, BH, CH и DH, а младшие — AL, BL, CL и DL.
Рис. 2. Регистры 80486Регистр указателя команд (Instruction Pointer, EIP) — также 32-разрядный и указывает на следующую выполняемую команду, конечно же, косвенно. Этот регистр указывает только смещение относительно начала кодового сегмента адреса, который образуется с использованием содержимого регистра CS и элемента дескрипторной таблицы (подробнее об этом несколько позже). Два младших байта регистра EIP соответствую 16-разрядному регистру IP, который используется только при 16-битной адресации.
Для обозначения базового 32—разрядного регистра побитной индикации состояния процессора используется так называемый регистр флагов — EFLAGS. Этот регистр содержит биты, характеризующие последнюю выполненную процессором операцию, и некоторую другую служебную информацию. На рис. 3 приведены обозначения битов в регистре EFLAGS. Поясним назначение некоторых из них. Если в регистре EFLAGS установлен 17-й бит — VM (Virtual 8086 Mode), то микропроцессор i80486 переходит в режим «виртуальных 8086-машин». Конечно, это возможно только в защищенном режиме. Бит 16 — RF (Resume Flag) используется обычно для отладочных режимов. При его установке прерывание, вызванное фатальной ошибкой, игнорируется и выполняется переход на следующую инструкцию. Бит 14 — NT (Nested Task) используется в i80486 для наблюдения за несколькими прерванными или вызванными по инструкции CALL программами. Два бита 12 и 13 IOPL (Input/Output Privilege Level) определяют право доступа в защищенном режиме к инструкциям ввода-вывода.
Рис. 3. Биты регистра EFLAGSИз шести 16-разрядных сегментных регистров четыре (DS, ES, FS и GS) называются регистрами сегментов данных, CS — регистром кодового сегмента, а SS — регистром сегмента стека. Как работают эти регистры в режиме микропроцессора i8086, достаточно хорошо известно. Для получения 20-разрядного физического адреса необходимо суммировать 16-битное смещение с базовым адресом, хранящимся в одном из сегментных регистров. Причем сложение происходит так, что содержимое сегментного регистра сдвинуто относительно второго слагаемого (смещения) влево на 4 разряда. То есть, по сути, происходит сложение 20-битового базового адреса (4 младших разряда которого, безусловно, всегда нули) с 16-битовым смещением, в результате, конечно, получается необходимый 20-разрядный адрес. При работе же микропроцессора i80486 (ну и, разумеется, i80386) в защищенном режиме исполнительный физический адрес образуется несколько иначе. Можно сказать, что он образуется из пяти компонент. Прежде всего отметим, что в защищенном режиме сегментные регистры называются селекторными, или просто селекторами. Селекторный регистр указывает на соответствующий элемент в одной из Дескрипторных Таблиц, расположенных в памяти. Причем базовый адрес этой Таблицы хранится либо в регистре Глобальной Дескрипторной Таблицы, либо в регистре Локальной Дескрипторной Таблицы, хотя в общем случае может храниться и в ином регистре микропроцессора. Каждый элемент Дескрипторной Таблицы содержит базовый адрес определенного сегмента, его величину и права доступа. У i80486 элемент Глобальной Дескрипторной Таблицы имеет размер 8 байт и состоит из 32-разрядного базового адреса, 20-разрядного поля размера сегмента и атрибутов дескриптора. В поле размера сегмента, например, может храниться либо количество байт (до 1 Мбайта), которое содержит данный сегмент, либо количество страниц по 4096 байт каждая. Следовательно, размер сегмента в защищенном режиме может варьироваться от 1 байта до 4 Гбайт. Таким образом, результирующий адрес в защищенном режиме может быть образован в общем случае суммированием содержимого базового регистра с содержимым индексного регистра, умноженного на масштабный коэффициент (1, 2, 4 или 8), плюс смещение в самой команде и плюс базовый адрес сегмента из элемента Дескрипторной Таблицы (рис. 4).
Рис. 4. Формирование адреса в защищенном режимеМикропроцессор i80486 имеет три управляющих регистра (Control Registers) системного уровня — CR0, CR2, и CR3 (регистр CR1 зарезервирован фирмой Intel для дальнейшего расширения). В регистре CR0 из имеющихся 32 бит для целей управления и определения статуса используется только 10 (рис. 5). Причем 5 из этих 10 бит появились только в i80486 (в i80386 их нет). Это биты — CD, NW, AM, WP и NE. Функционально все эти 10 бит характеризуют следующее: режимы микропроцессора i80486 — PG, PE, режимы встроенного устройства кэш-памяти — CD, NW, встроенное устройство управления плавающей арифметикой — TS, EM, MP и NE, управление контролем выравнивания — AM, защита записи супервизора — WP. Младшее слово регистра CR0 используется также в качестве статусного слова (слова состояния) микропроцессора (Machine Status Word, MSW), для того чтобы сохранить совместимость с защищенным режимом i80286. Следовательно, команды LMSW и SMSW (Load MSW, Store MSW) действуют только для нижних 16 бит CR0 и игнорируют новые биты. Для того чтобы можно было работать с этими новыми битым, в набор команд микропроцессора i80486 включена специальная инструкция MOV CR0, Reg.
Рис. 5. Регистр CR0В управляющем регистре CR2 накопится адрес, по которому появилась ошибка при разбиении памяти на страницы. Управляющий регистр CR3 используется только тогда, когда в регистре CR0 установлен бит PG. В этом случае регистр содержит базовый адрес таблицы страниц, которые может использовать микропроцессор для каждой задачи. Сама же эта таблица всегда выровнена на одну страницу (4 Кбайт).
Четыре адресных системных регистра в микропроцессорах i80386/486 используются для таблиц или сегментов, которые хранятся в основной памяти. Это — Глобальная Дескрипторная Таблица (Global Descriptor Table, GDT), Локальная Дескрипторная Таблица (Local Descriptor Table, LDT), Дескрипторная Таблица Прерываний (Interrupt Descriptor Table, IDT) и Сегмент Состояния Задачи (Task State Segment, TSS). Для обозначений соответствующих регистров используются аббревиатуры — GDTR, LDTR, IDTR и TR. Регистры GDTR и IDTR содержат 32-разрядный базовый адрес, а также 16-разрядную границу для таблиц GDT и IDT. Таблицы GDT и IDT находятся в распоряжении всех задач как глобальные сегменты, в то время как LDT и TSS зависят от конкретной задачи. В регистрах LDTR и TR хранятся 16-разрядные селекторы для выбора LDT и соответственно TSS-дескриптора.
Набор регистров для операций с плавающей точкой включает в себя восемь 80-разрядных регистров данных, 48-разрядные указатели данных и команд, а также 16-разрядные регистры управления, состояния и слова признаков. Поскольку принцип работы FPU полностью соответствует работе i80387, а арифметические сопроцессоры — хорошая тема для отдельного разговора, подробно останавливаться на эти регистрах мы пока не будем.
В следующих выпусках нашего журнала мы обязательно вернемся к разговору о микропроцессорах фирмы Intel, и не только о них.
А. Борзенко
КомпьютерПресс 3’92
См. также описание семейства процессоров x86.
Персональный сайт — Обобщенная схема центрального процессора
Краткое напоминание о фоннеймановской архитектуре (модели) ЭВМЧтобы получить представление о структуре и функциях процессора, обратимся к схеме гипотетической ЭВМ, модель которой традиционно называют фоннеймановской (рис. 24.1).
Рис. 24.1. Структурная схема гипотетической ЭВМ
Устройство управления (УУ) организует автоматическое выполнение
программ и функционирование ЭВМ как единой системы. Основная задача УУ
– выработка управляющих сигналов (УС) и распределение их по цепям
управления.
Арифметическологическое устройство (АЛУ) предназначено для выполнения
арифметических и логических операций над поступающими в него данными.
Оперативная память (ОП) представляет собой массив запоминающих
элементов (ЗЭ), организованных в виде ячеек, способных хранить некую
единицу информации.
Процессором называется функциональная часть ЭВМ, предназначенная для
непосредственного осуществления процесса преобразования (обработки)
информации и управления этим процессом. Другими словами – это
совокупность арифметическологического устройства и устройства
управления.
На рис. 24.2 приведена функциональная структура гипотетического процессора.
Рис. 2.2. Структура гипотетического процессора
Регистр адреса
Регистр адреса (РА) предназначен для хранения адреса ячейки основной
памяти вплоть до завершения операции (считывание или запись) с этой
ячейкой.
Указатель стека
Указатель стека (УкС) — это регистр, где хранится адрес вершины стека.
В реальных вычислительных машинах стек реализуется в виде участка
основной памяти обычно расположенного в области наибольших адресов.
Заполнение стека происходит в сторону уменьшения адресов, при этом
вершина стека — это ячейка, куда была произведена последняя по времени
запись. Для хранения адреса такой ячейки и предназначен УкС. При
выполнении операции занесения в стек содержимое УкС сначала уменьшается
на единицу, после чего используется в качестве адреса, по которому
производится запись. Соответствующая ячейка становится новой вершиной
стека. Считывание из стека происходит из ячейки, на которую указывает
текущий адрес в УкС, после чего содержимое указателя стека
увеличивается на единицу. Таким образом, вершина стека опускается, а
считанное слово считается удаленным из стека. Хотя физически считанное
слово и осталось в ячейке памяти, при следующей записи в стек оно будет
заменено новой информацией.
Счетчик команд
Счетчик команд (СК) — неотъемлемый элемент процессора любой ЭВМ,
построенной в соответствии с фоннеймановским принципом программного
управления. Согласно этому принципу соседние команды программы
располагаются в ячейках памяти со следующими по порядку адресами и
выполняются преимущественно в той же очередности, в какой они размещены
в памяти ЭВМ. Таким образом, адрес очередной команды может быть получен
путём увеличения адреса ячейки, из которой была считана текущая
команда, на длину выполняемой команды, представленную числом занимаемых
ею ячеек. Реализацию такого режима и призван обеспечивать счетчик
команд — двоичный счетчик, в котором хранится и модифицируется адрес
очередной команды программы. Перед началом вычислений в СК заносится
адрес ячейки основной памяти, где хранится команда, которая должна быть
выполнена первой. В процессе выполнения каждой команды путем увеличения
содержимого СК на длину выполняемой команды в счетчике формируется
адрес следующей подлежащей выполнению команды. В данном случае любая
команда занимает одну ячейку, поэтому содержимое СК увеличивается на
единицу. По завершении текущей команды адрес следующей команды
программы всегда берется из счетчика команд. Для изменения
естественного порядка вычислений (перехода в иную точку программы)
достаточно занести в СК адрес точки перехода.
Регистр команды
Счетчик команд определяет лишь местоположение команды в памяти, но не
содержит информации о том, что это за команда. Чтобы приступить к
выполнению команды, ее необходимо извлечь из памяти и разместить в
регистре команды (РК). Этот этап носит название выборки команды. Только
с момента загрузки команды в РК она становится «видимой» для
процессора. В РК команда хранится в течение всего времени ее
выполнения.
Регистры общего назначения
Регистры общего назначения (РОН), служат для временного хранения
операндов и результатов вычислений. Это самый быстрый, но и минимальный
по емкости тип памяти, который иногда объединяют понятием
сверхоперативное запомина¬ющее устройство — СОЗУ. Как правило,
количество регистров невелико, хотя в архитектурах с сокращенным
набором команд их число может доходить до не¬скольких десятков.
Индексные регистры
Индексные регистры (ИР) служат для формирования адресов операндов при реализации циклических участков программ.
Регистр признака результата
Регистр признака результата (РПР) предназначен для фиксации и хранения
признака, характеризующего результат последней выполненной
арифметической или логической операции. Такие признаки могут
информировать о равенстве результата нулю, о знаке результата, о
возникновении переноса из старшего разряда, переполнении разрядной
сетки и т. д. Содержимое РПР обычно используется устройством управления
для реализации условных переходов по результатам операций АЛУ. Под
каждый из возможных признаков отводится один разряд РПР.
Аккумулятор
Аккумулятор (Акк) — это регистр, на который возлагаются самые
разнообразные функции. Так, в него предварительно загружается один из
операндов, участвующих в арифметической или логической операции. В Акк
может храниться результат предыдущей команды и в него же заносится
результат очередной операции. Через Акк зачастую производятся операции
ввода и вывода.
Строго говоря, аккумулятор в равной мере можно отнести как к АЛУ, так и
к УУ, а в ЭВМ с регистровой архитектурой его можно рассматривать как
один из регистров общего назначения.
Буфер данных
Буфер данных призван компенсировать разницу в быстродействии
запоминающих устройств и устройств, выступающих в роли источников и
потребителей хранимой информации. В буфер данных при чтении заносится
содержимое ячейки ОП, а при записи — помещается информация, подлежащая
сохранению в ячейке ОП.
Буфер адреса
Наличие буфера адреса также позволяет компенсировать различия в быстродействии оперативной памяти и других устройств ЭВМ.
— BTW Electronic Parts
Описание
Описание:
- NTE1784 — это интегральная схема в 16-выводном корпусе типа DIP, предназначенная для использования в качестве горизонтального
- Схема процессора для Ч / Б и цветных телевизионных приемников.
Характеристики:
- Сепаратор горизонтальной синхронизации с шумоподавлением
- Сепаратор вертикальной синхронизации с шумоподавлением
- Осциллятор Horizonyal с ограничителем диапазона частот
- Фазовый компаратор между синхроимпульсами и импульсами генератора (ФАПЧ)
- Фазовый компаратор между импульсами обратного хода и импульсами генератора (ФАПЧ)
- Контурное усиление и переключение с постоянной времени (ВКМ)
- Генератор комбинированного гашения и ключевых импульсов
- Цепи защиты
- Выходные каскады с возможностью высокого тока
Абсолютные максимальные рейтинги:
- (TA = + 25 ° C, если не указано иное)
- Напряжение питания (контакт 1), VS.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15 В
- Напряжение цепи, В2. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18 В
- Напряжение цепи, В4, В11. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . VS
- Напряжение цепи, В8.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . VS к −6V
- Напряжение цепи, В 9. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . От +6 В до −6 В
- Пиковый ток цепи, I2. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1А
- Пиковый ток цепи, I3.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 500 мА
- Ток цепи, I6, I10. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30 мА
- Ток цепи, I7. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20 мА
- Суммарное рассеивание мощности (TA ≤ + 70 ° C), Ptot.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1Вт
- Диапазон рабочих температур спая, ТДж. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . От −40 ° до + 150 ° C
- Диапазон температур хранения, Tstg. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . От −40 ° до + 150 ° C
- Максимальное тепловое сопротивление, соединение-окружающая среда, RthJA. . . .. . . . . . . . . . . . . . . . . . . . . . 80 ° C / Вт
Простая схема включает вентилятор при обработке
Аннотация: Показана схема, которая определяет температуру удаленного термодиода на кристалле ЦП, ПЛИС, графического процессора или другой высокопроизводительной ИС. Когда температура термодиода превышает предварительно заданную точку срабатывания, включается охлаждающий вентилятор, тем самым обеспечивая простую функцию управления вентилятором.
Охлаждающие вентиляторы широко используются в ПК, рабочих станциях и других системах, которые могут выделять значительное количество тепла во время нормальной работы.Однако во многих таких системах охлаждение не требуется в 100% случаев. В этих системах предпочтительнее включать вентилятор только при необходимости охлаждения, а не постоянно. Использование вентилятора только при необходимости увеличивает срок его службы и снижает уровень шума системы.Схема, показанная ниже, использует очень простой и недорогой подход к управлению работой вентилятора на основе температуры кристалла микропроцессора, FPGA или другого высокомощного чипа. Целевая ИС должна иметь доступный термочувствительный PN-переход (обычно база и эмиттер PNP-подложки).Схема основана на дистанционном переключателе температуры MAX6513 (IC1). IC1 пропускает ток с точно контролируемыми соотношениями через чувствительный переход на целевой ИС, измеряет прямое напряжение перехода при каждом токе и вычисляет температуру удаленного перехода на основе этой информации. Если измеренная температура превышает установленную на заводе пороговую температуру, выходной контакт MAX6513 (TOVER) становится активным, включая N-канальный полевой МОП-транзистор и подает питание на вентилятор.
Пороговая температура может быть выбрана в соответствии с потребностями целевой ИС.В показанной здесь схеме IC1 имеет порог 55 ° C. Типичные значения для управления вентилятором находятся в диапазоне от примерно 45 ° C до примерно 65 ° C, но могут быть приняты и более высокие значения. После включения вентилятора гистерезис удерживает вентилятор включенным до тех пор, пока температура не упадет на 10 ° C ниже температуры срабатывания. Если предпочтителен гистерезис 5 ° C, подключите контакт HYST к земле. Для достижения наилучших результатов расположите IC1 близко к целевой ИС и держите высокоскоростные цифровые трассы подальше от трасс DXP и DXN, чтобы избежать помех.
Рисунок 1.Этот простой контроллер вентилятора включает вентилятор, когда температура целевой ИС превышает 55 ° C.
Рисунок 2. Вентилятор включается при превышении температуры отключения. Перед выключением вентилятора температура должна упасть ниже температуры отключения за вычетом гистерезиса. Подключив контакт HYST к земле или V CC , можно выбрать гистерезис 5 ° C или 10 ° C.
| ©, Maxim Integrated Products, Inc. |
| ПРИЛОЖЕНИЕ 481: ПРИМЕЧАНИЕ ПО ПРИМЕНЕНИЮ 481, AN481, АН 481, APP481, Appnote481, Appnote 481 |
maxim_web: en / products / сенсоры, maxim_web: en / products / сенсоры и интерфейс сенсоров
maxim_web: en / products / сенсоры, maxim_web: en / products / сенсоры и интерфейс сенсоров
Simple CPU 🙂 — обновлено 30.10.2019
Simple CPU v1Рисунок 1: Простой ЦП
Современные процессоры — сложные звери, высоко оптимизированные и трудные для понимания.Из-за этого очень трудно понять, почему один был построен таким, каким он был. Частично проблема заключается в требовании обратной совместимости, то есть новый процессор должен иметь возможность запускать код предыдущих поколений. Это постепенное развитие может привести к очень запутанному набору инструкций и «загроможденной» аппаратной архитектуре. Кроме того, когда вы начинаете копаться в литературе, многие вещи не всегда раскрываются полностью, то есть для защиты этих промышленных секретов. Однако в их сердцах все процессоры — простые машины и в некоторых отношениях не так сильно изменились с 1940-х годов i.е. они по-прежнему используют инструкции и выполняют цикл Fetch-Decode-Execute. Поэтому, чтобы доказать, что процессоры на самом деле очень просты в сборке и понимании, я разработал простую 8-битную архитектуру ЦП, которая может быть реализована в FPGA. Если честно, на самом деле он не был разработан, он эволюционировал, поэтому оборудование можно было немного оптимизировать. Однако цель заключалась в том, чтобы разбить процессор на его фундаментальные строительные блоки, то есть логические логические элементы. Затем их объединение в более сложные компоненты e.грамм. сумматоры, мультиплексоры, триггеры, счетчики и т. д., которые лежат в основе любого компьютера. Базовая блок-схема этого компьютера показана на рисунке 1, это очень простая машина, состоящая из регистров, мультиплексоров и сумматора. Работа этой машины и ее компонентов будет объяснена снизу вверх, логические элементы «Hello World», реализованные в Spartan 3 FPGA, ее аппаратное обеспечение определено на схемах. Исходные файлы для каждой версии этого процессора можно загрузить (ссылки в каждом разделе) и смоделировать с помощью Xilinx ISE 14.7 Инструмент ISim.
Содержание
Назад к основам — simpleCPU_v1
Тестирование: «Hello World»
Тестирование: полностью протестировано 🙂
ПРИМЕЧАНИЕ , некоторые принципиальные схемы довольно большие, поэтому вы не сможете увидеть имена сигналов / компонентов, если будете смотреть с этой страницы. Однако, если вы нажмете на изображение, вы получите изображение с высоким разрешением, но некоторые из них довольно большие, поэтому загрузка может занять некоторое время. PDF-файлы также доступны для некоторых изображений.
Назад к основам — simpleCPU_v1
Рисунок 2: Логические вентили, символы (вверху), форма сигнала (внизу)
На самом низком уровне каждая операция в компьютере выполняется логическими вентилями, подобными показанным на рисунке 2, для получения дополнительной информации о логической логике см .: (Link) (Link).Используя эти базовые строительные блоки, мы можем построить четыре основных компонента любого компьютера:
- Логика: каждый блок в компьютере можно рассматривать как созданный из логических вентилей, однако эта категория относится к конкретным более крупным логическим блокам, например сумматоры, декодеры адресов, декодеры команд и т. д.
- Мультиплексоры: с одной точки зрения компьютер просто перемещает информацию из одной точки в другую. Путь, по которому проходит эта информация, контролируют мультиплексоры: переключающие соединения, позволяющие передавать информацию между функциональными блоками.
- Регистры: быстрая, кратковременная память. В рамках цикла Fetch-Decode-Execute компьютер должен запомнить свое состояние, инструкцию, которую нужно обработать, и любые сгенерированные результаты.
- Память: в этом компьютере используется классическая архитектура фон Неймана, то есть одна память, в которой хранятся как программа (инструкции), которые должны быть выполнены, так и данные, которые должны быть обработаны, в одном устройстве памяти.
Вернувшись к рисунку 1, вы можете увидеть, что этот процессор имеет три мультиплексора (MUX), управляющих шинами данных и адреса. Примечание , в простейшей форме шина — это просто группа проводов, по которым передаются двоичные числа (ссылка). Мультиплексоры — это переключатели, позволяющие процессору выбирать информацию из нескольких источников (шин) и направлять ее в один пункт назначения. Чтобы выбрать, какой источник данных следует использовать, мультиплексор имеет одну или несколько линий управления, как показано на рисунке 3. Этот мультиплексор 2: 1 имеет два входа данных (A, B), один выход (Z) и вход (SEL), выбирая какой из двух входов данных должен быть подключен к его выходу, как определено его таблицей истинности, показанной в нижней части рисунка 3.Когда SEL = 0, вход A подключается к выходу Z. Когда SEL = 1, вход B подключается к выходу Z.
Рисунок 3: 2: 1-битный мультиплексор, принципиальная схема (вверху), таблица истинности (внизу)
Этот мультиплексор может выбирать между двумя битами (двоичными цифрами), однако в процессоре нам нужно выбирать между 8-битными (байтовыми) шинами, то есть альтернативными данными или значениями адреса. Для этого мультиплексор дублируется восемь раз, то есть по одному на бит в шине, как показано на рисунке 4. Примечание , каждый прямоугольник (символ) mux2_1_1 содержит схему, показанную на рисунке 3.Для экономии места я показал только первые три мультиплексора, полная принципиальная схема доступна здесь: (Ссылка). Символ схемы для этого 8-битного мультиплексора показан на рисунке 5, его интерфейс имеет три 8-битные шины (толстые линии) и один сигнал (тонкие линии):
- A (7: 0) — входная шина, восьмибитные значения, биты с метками A7, A6, A5, A4, A3, A2, A1, A0
- B (7: 0) — входная шина, восьмибитные значения, биты с метками B7, B6, B5, B4, B3, B2, B1, B0
- Z (7: 0) — выходная шина, восьмибитные значения, биты помечены как Z7, Z6, Z5, Z4, Z3, Z2, Z1, Z0
- SEL — входной сигнал, логический, выбирает, какой вход подключен к выходу
Рисунок 4: Схема мультиплексора 2: 1 байта (только первые три ступени)
Рисунок 5: байтовый мультиплексор 2: 1, символ (вверху), форма сигнала (внизу)
Примечание , этот подход с использованием иерархических схем является хорошим примером фундаментального принципа проектирования в информатике. I.е. абстракция. Выявление ключевых функций, разделение их на отдельные компоненты, которые затем могут быть повторно использованы при построении других компонентов или систем, упрощение схематической компоновки, конструкции и скрытие ненужных деталей.
Очевидно, что проектирование сложных вычислительных систем — это сложный процесс, существует большой разрыв между требованиями пользователя и реализацией системы, которую «трудно» (невозможно) выполнить за один шаг. Чтобы упростить процесс проектирования, мы разбиваем систему на несколько функциональных блоков e.грамм. блок-схема верхнего уровня, показанная на рисунке 1. Затем мы можем постепенно дорабатывать эти компоненты до окончательной реализации, игнорируя нерелевантные детали.
В дополнение к мультиплексорам 2: 1, показанным на рисунке 1, ALU также нуждается в мультиплексоре 4: 1 (обсуждается позже), то есть мультиплексоре с четырьмя входами и одним выходом. Он может быть построен из трех байтовых мультиплексоров 2: 1, как показано на рисунке 6. Примечание , каждый прямоугольник (символ) mux2_1_8_v1 содержит схему, показанную на рисунке 3 i.е. 3 x 8 x 4 = 96 логических вентилей. Схемы и символы Xilinx для этих мультиплексоров можно скачать здесь: (Ссылка). Для получения дополнительной информации о мультиплексорах см .: (Ссылка).
- A (7: 0) — входная шина, восьмибитные значения, биты с метками A7, A6, A5, A4, A3, A2, A1, A0
- B (7: 0) — входная шина, восьмибитные значения, биты с метками B7, B6, B5, B4, B3, B2, B1, B0
- C (7: 0) — входная шина, восьмибитные значения, биты с метками C7, C6, C5, C4, C3, C2, C1, C0
- D (7: 0) — входная шина, восьмибитные значения, биты помечены как D7, D6, D5, D4, D3, D2, D1, D0
- Z (7: 0) — выходная шина, восьмибитные значения, биты помечены как Z7, Z6, Z5, Z4, Z3, Z2, Z1, Z0
- SEL0 — входной сигнал, логический, выбор первой ступени
- SEL1 — входной сигнал, логический, выбор второй ступени
Рисунок 6: Мультиплексор 4: 1 байта, принципиальная схема и таблица истинности
Вся обработка чисел выполняется в арифметико-логическом блоке (ALU), реализующем основные арифметические функции центрального процессора (CPU).Для реализации функции ADD (одной из основных инструкций любого компьютера) существует ряд различных аппаратных решений, каждое из которых имеет свои преимущества и недостатки. Однако, чтобы избежать подробного обсуждения их относительных достоинств, я буду придерживаться основного полусумматора, как показано на рисунке 7. Для получения дополнительной информации о сумматорах обратитесь к: (Ссылка) (Ссылка). Эта схема складывает два бита A и B, получая сумму и перенос. Работая с таблицей истинности, вы можете увидеть процесс сложения 0 + 0 = 0, 0 + 1 = 1, 1 + 0 = 1.Поскольку это двоичная машина (с основанием 2), максимальное значение, которое может сохранить любая цифра, равно 1, поэтому, когда A = B = 1, выход Sum не может представлять результат 2, поэтому генерируется перенос. Затем этот перенос будет добавлен к следующей цифре в номере.
Рисунок 7: Полусумматор, принципиальная схема (вверху), таблица истинности (внизу)
Сам по себе полусумматор не так полезен, поскольку нам нужно складывать 8-битные числа, но его можно использовать в качестве строительного блока для полного сумматора, как показано на рисунке 8. Примечание , каждый прямоугольник (символ) half_adder содержит схему, показанную на рисунке 7. Эта схема может складывать вместе три бита: A, B и Cin. Еще один способ подумать об этой схеме — это подсчитать количество единиц:
- 0 + 0 + 0 = 00: все нули, результат 00
- 0 + 0 + 1 = 01: one 1, результат 01
- 0 + 1 + 1 = 10: две единицы, результат 10 или десятичное число 2
- 1 + 1 + 1 = 11: три единицы, результат 11 или десятичное число 3
Рисунок 8: Полный сумматор, принципиальная схема (вверху), таблица истинности (посередине), форма сигнала (внизу)
Опять же, на первый взгляд, возможность складывать три бита вместе может показаться не такой уж полезной, однако, если мы реплицируем это оборудование восемь раз, соединив выполнение (Cout) предыдущего этапа с переносом (Cin) следующего этапа. можно построить сумматор Ripple, как показано на рисунке 9. Примечание , опять же, каждый прямоугольник (символ) содержит подсхему, в данном случае full_adder , показанный на рисунке 8. Для экономии места я показал только первые три полных сумматора, полная принципиальная схема доступна здесь: (Ссылка ). Альтернативным способом рассмотрения этого оборудования является псевдокод, показанный на рисунке 10. Каждый полный сумматор представляет собой сумматор по модулю 2, концептуально процесс сложения начинается с наименее значащей цифры (LSD) и «колеблется» через оборудование до самой старшей цифры. (MSD) i.е. биты X0 и Y0 складываются вместе для получения суммы Z0 и переноса C1, этот перенос затем добавляется к следующим значащим цифрам X1 и Y1 и т. д. Такое последовательное поведение ограничивает производительность оборудования. Однако не забывайте, что все оборудование, связанное с сложением каждой цифры, работает параллельно, например. производительность в лучшем случае: 987 + 12 = 999, переносов не будет, добавления 9 + 0, 8 + 1 и 7 + 2 будут выполняться параллельно и завершаться за одну единицу времени. Однако в худшем случае производительность: 999 + 1 = 1000, это займет четыре единицы времени из-за того, что переносы должны проходить через оборудование от LSD к MSD. Обратите внимание на , это глупо, но важно помнить, что оборудование — это не программное обеспечение. При анализе оборудования некоторые элементы могут вести себя последовательно, но ВСЕ логические элементы будут работать параллельно (активны все время).
Рисунок 9: Схема сумматора пульсаций (только первые три ступени)
Рисунок 10: Архитектура сумматора пульсаций
Рисунок 11: Символ сумматора пульсаций
Символ схемы верхнего уровня для сумматора пульсаций показан на рисунке 11 (содержащий схему, показанную на рисунке 9), интерфейс этого символа имеет три 8-битные шины (толстые линии) и два сигнала (тонкие линии):
- A (7: 0) — входная шина, восьмибитные значения, биты с метками A7, A6, A5, A4, A3, A2, A1, A0
- B (7: 0) — входная шина, восьмибитные значения, биты с метками B7, B6, B5, B4, B3, B2, B1, B0
- Cin — входной сигнал, логический, перенос данных из предыдущих вычислений
- Cout — выходной сигнал, логический, вывод от сумматора пульсаций
Полная принципиальная схема ALU показана на рисунке 12.С небольшими изменениями сумматор пульсаций можно использовать для реализации функции вычитания. Аппаратное вычитание может быть реализовано с использованием дополнения до 2 (Link), то есть вычитания путем сложения отрицательных чисел. Чтобы сгенерировать отрицательное число, каждый бит инвертируется, а затем к результату добавляется 1, как показано в примере ниже.
123 45 = 000101101 123 = 01111011 001111011
- 45 inv = 111010010 + 111010011
----- +1 = 111010011 -----------
78 001001110 = 78
----- -----------
11111 1
Для инвертирования каждого бита используется массив логических вентилей XOR, bitwise_inv_v1 , как показано на рисунке 13.Эта схема имеет 8-битную входную шину (A), каждый бит подвергается операции XOR с сигналом EN. Выполнение XOR бита с 0 возвращает то же значение. Выполняя операцию XOR с 1, возвращает значение, обратное этому значению. Чтобы добавить 1, сигнал переноса (Cin) в сумматор пульсаций устанавливается на 1, увеличивая конечный результат. В ALU это контролируется с помощью сигналов S2 и S3. Функции ADD и SUB можно моделировать с помощью программных средств Xilinx ISim, как показано на рисунке 14. На этой диаграмме формы сигнала выполняются вычисления 123 + 45 и 123-45.Помните, когда вы используете представление с дополнением до 2 в вычислениях, окончательный перенос игнорируется. Схемы, символы и тестовый стенд Xilinx для этого ALU можно скачать здесь: (Ссылка).
А Б Я 0 0 0 А ИСКЛЮЧАЮЩЕЕ ИЛИ 0 = А 0 1 1 A XOR 1 = НЕ А 1 0 1 1 1 0
Рисунок 12: Принципиальная схема ALU
Рисунок 13: Побитовое исключающее ИЛИ
Рисунок 14: Моделирование ALU, ADD и SUB
Вход переноса может также использоваться для выполнения функции приращения i.е. Z = А + 0 + 1. Это довольно распространенное требование в программе, например. увеличение счетчика / переменной или счетчика программы процессора. Для достижения этой функции вход B сумматора должен быть установлен на ноль. Для этого используются схемы replicate_v1 и bitwise_and_v1 , показанные на рисунках 15 и 16. Компонент replicate_v1 использует буферы (BUF) для подачи одного и того же сигнала на каждый бит своей выходной шины Z. Затем эти сигналы объединяются с данными на входе B ALU.Если они связаны с 1, значение на входе B сумматора не изменится. Если они связаны с 0, значение на входе B сумматора устанавливается на ноль. В ALU это контролируется с помощью сигналов S2 и S4. Функцию INC можно моделировать с помощью программных средств Xilinx ISim, как показано на рисунке 17. На этой диаграмме формы сигнала выполняются вычисления 123 + 1 и 45 + 1.
Рисунок 15: Реплика
Рисунок 16: Побитовое И
Рисунок 17: Моделирование ALU, INC
Компонент bitwise_and_v1 также используется в ALU для выполнения функции побитового И i.е. Z = A AND B, как показано в примере ниже. Примечание , на первый взгляд может показаться, что это не такая полезная функция, но, как мы увидим позже, она часто используется в программах для проверки состояния внутренних регистров и т.д.
А Б Я 10101010 0 0 0 А И 0 = 0 & 11110000 0 1 0 А И 1 = А ---------- 1 0 0 10100000 1 1 1 ----------
Для выбора функции ALU используется последний мультиплексор 4: 1, управляющие линии S0 и S1 выбирают либо выход сумматора, либо побитовое И, либо вход A, либо вход B.Полный набор управляющих сигналов показан ниже.
S4 S3 S2 S1 S0 Z 0 0 0 0 0 ДОБАВИТЬ (A + B) 0 0 0 0 1 БИТУСНОЕ И (A&B) 0 0 0 1 0 ВХОД A 0 0 0 1 1 ВХОД B 0 1 1 0 0 ВЫЧИСЛЕНИЕ (A-B) 1 0 1 0 0 ПРИРОСТ (A + 1) 1 0 0 0 0 ВХОД A 0 0 1 0 0 ДОБАВИТЬ (A + B) +1 0 1 0 0 0 ВЫЧИСЛЕНИЕ (A-B) -1
Рисунок 18: Символ арифметико-логического устройства (ALU)
Компьютер выполняет инструкции с использованием цикла Fetch-Decode-Execute (Link), поэтому процессор должен помнить, в какой фазе он находится, чтобы перейти к следующей.Эта временная память реализована с помощью триггеров, каждый из которых хранит 1 бит данных, как определено таблицей состояний, показанной на рисунке 19. Триггер имеет входной контакт D и выходной контакт Q, значение на D записывается в Q, когда есть изменение с логического 0 на логическую 1 на выводе CLK. Другой способ думать о выводе CLK заключается в том, что это сигнал управления записью или обновлением, то есть линия CLK имеет импульс для сохранения значения. Из-за электронных причин, которые я быстро пропущу, все линии CLK должны быть подключены к одним и тем же системным часам i.е. глобальный прямоугольный сигнал, определяющий скорость работы процессора. Это означало бы, что каждый триггер будет обновлять свой вывод каждый такт, что не очень полезно. Поэтому, чтобы контролировать, когда разные триггеры обновляют свои выходные данные, мы используем входной контакт CE включения синхронизации. Если CE = 0, вывод CLK игнорируется. Если CE = 1, используется вывод CLK.
Рисунок 19: Откидная панель D-типа
В процессоре временные значения хранятся в регистрах, в регистре каждый бит хранится в триггере, как показано на рисунках 20, 21 и 22.Чтобы сделать регистры большего размера, несколько меньших регистров сгруппированы вместе. Примечание , прямоугольные компоненты register_4, и register_8 содержат принципиальные схемы, показанные на рисунках 20 и 21 соответственно. Работа 8-битного регистра может быть смоделирована с помощью программных средств Xilinx ISim, как показано на рисунке 23. На этой диаграмме формы сигнала значения 123 и 45 сохранены в регистре, с использованием линий CLK, CLR и CE для управления, когда эти значения обновлены.Схемы Xilinx, символы и тестовый стенд VHDL для этих регистров можно скачать здесь: (Ссылка).
Рисунок 20. Четырехбитный регистр, символ (слева), схема (справа)
Рисунок 21: Восьмиразрядный регистр, символ (слева), схема (справа)
Рисунок 22. Шестнадцатиразрядный регистр, символ (слева), схема (справа)
Рисунок 23: Моделирование восьмибитного регистра
Как показано на рисунке 1, этот процессор имеет три основных регистра:
- Программный счетчик (ПК): 8-битный регистр, используемый для хранения адреса в памяти текущей выполняемой инструкции.
- Регистр инструкций (IR): 16-битный регистр, обновляемый в конце фазы выборки инструкцией, которая должна быть обработана (декодирована и выполнена).
- Аккумулятор (ACC): 8-битный регистр, регистр данных общего назначения, предоставляющий данные (операнд) для обработки ALU и использования для хранения любого полученного результата. Примечание , мы можем хранить в процессоре только одно 8-битное значение за раз, другие значения данных необходимо буферизовать во внешней памяти.
Триггеры также используются для генерации последовательности управляющих сигналов, необходимых для выполнения функций, определенных каждой инструкцией.Они содержатся в блоке декодера или управляющей логики (рисунок 1), символ принципиальной схемы для этого компонента показан на рисунке 24. Внутри этого компонента находятся логика декодирования команд и генераторы последовательности, необходимые для управления процессором, как показано на рисунке. 25. Схему в высоком разрешении можно скачать здесь: (Ссылка).
- MUXA: выход, ALU A вход Управление мультиплексором
- MUXB: выход, вход ALU B Управление мультиплексором
- MUXC: выход, управление адресом MUX, выбор ПК или IR
- EN_DA: выход, управление обновлением регистра аккумулятора (ACC)
- EN_PC: выход, контроль обновления регистра программного счетчика (ПК)
- EN_IR: выход, управление обновлением регистра команд (IR)
- RAM_WE: выход, управление разрешением записи в память
- ALU_S0: выход, линия управления ALU
- ALU_S1: выход, линия управления ALU
- ALU_S2: выход, линия управления ALU
- ALU_S3: выход, линия управления ALU
- ALU_S4: выход, линия управления ALU
- IR: входная шина, 8 бит, старший байт регистра команд, содержит код операции
- ZERO: вход, управляемый 8-битным логическим элементом NOR, подключенным к выходу ALU, если 1 означает, что результат равен нулю
- CARRY: ввод, управляемый выполнением (Cout) ALU
- CLK: вход, системные часы
- CE: вход, включение часов, обычно устанавливается на 1, если установлено на 0, процессор HALT
- CLR: вход, сброс системы, при высоком импульсе система будет сброшена
Рисунок 24: Символ декодера
Рисунок 25: Принципиальная схема декодера
Этот процессор имеет немного измененный цикл Fetch-Decode-Execute.Чтобы сохранить сумматор (уменьшить количество оборудования), я добавил дополнительную фазу, теперь у нее есть цикл Fetch-Decode-Execute-Increment, последняя фаза увеличивает ПК до адреса следующей инструкции (при необходимости).
Примечание , обычно обновление ПК выполняется на этапе выборки / декодирования, я переместил это в отдельную фазу, чтобы выделить эти типы «служебных» операций, которые необходимы в цикле Fetch-Decode-Execute, т.е. вам необходимо поддерживать механизм внутри процессора, который позволяет обрабатывать инструкции и данные.
Для определения фазы процессора в генераторе последовательности используется, как показано на рисунках 26 и 27. Это простой счетчик звонков (Link), использующий закодированное значение one-hot (Link) для индикации состояния процессора, как показано на рисунке 28. Первоначально значение 1000 загружается в счетчик (код выборки), затем на каждом тактовом импульсе бит с одним горячим битом перемещается по цепочке триггеров, возвращаясь к началу после четырех тактов. Чтобы определить состояние процессора, вы просто указываете, какая битовая позиция установлена на логическую 1.Одноразовое кодирование, то есть когда число имеет только один бит, очень легко декодировать аппаратно, но его разреженное кодирование означает, что вам нужно много битов для представления больших значений, поскольку не все состояния битов используются. Четырехбитное значение one-hot может представлять 4 состояния или значение от 0 до 3, используя двоичное кодирование, вы можете представить значение от 0 до 15, но вам нужно будет декодировать все биты, чтобы определить его значение, тогда как при использовании одного- горячо нужно смотреть только на один бит.
- 1000: Получить
- 0100: декодировать
- 0010: Выполнить
- 0001: Приращение
Рисунок 26: Символ генератора последовательности
Рисунок 27: Генератор последовательности
Рисунок 28: Моделирование генератора последовательности
Во время фазы выборки текущая инструкция, на которую указывает счетчик программ (ПК), загружается в регистр команд (IR).Затем на этапе декодирования старший байт 16-битной инструкции фиксированной длины декодируется декодером инструкций, показанным на рисунке 29. Диаграмму с высоким разрешением можно загрузить здесь: (Ссылка). Для упрощения конструкции этот процессор имеет очень ограниченный набор команд:
- ACC нагрузки kk: 0000 XXXX KKKKKKKK
- Добавить ACC kk: 0100 XXXX KKKKKKKK
- и ACC kk: 0001 XXXX KKKKKKKK
- Дополнительный ACC kk: 0110 XXXX KKKKKKKK
- Вход ACC pp: 1010 XXXX PPPPPPPP
- Выход ACC pp: 1110 XXXX PPPPPPPP
- Прыжок U aa: 1000 XXXX AAAAAAAA
- Перейти Z aa: 1001 00XX AAAAAAAA
- Прыжок C aa: 1001 10XX AAAAAAAA
- Перейти NZ aa: 1001 01XX AAAAAAAA
- Прыжок NC aa: 1001 11XX AAAAAAAA
В этом синтаксисе команды X = Не используется, K = Константа, A = Адрес инструкции, P = Адрес данных.Сложность инструкции также определяется ее режимом адресации, то есть не только тем, сколько вычислений она выполняет, но и тем, как она выбирает свои операнды (данные). Опять же, чтобы упростить необходимое оборудование, эти инструкции ограничены простыми режимами адресации:
- Немедленно: операнд KK, постоянное значение, оно доступно немедленно, поскольку оно хранится в регистре команд, то есть часть инструкции, считываемой во время фазы выборки.
- Абсолютный: операнд AA или PP, адрес в памяти.Опять же, адрес хранится в регистре инструкций, либо указывая, где хранятся данные, которые должны быть обработаны, то есть инструкция INPUT, либо где полученный результат должен быть сохранен в памяти, то есть инструкция OUTPUT. Также используется для определения адреса в памяти следующей извлекаемой инструкции, то есть JUMP.
Описание уровня передачи регистров (RTL) каждой из этих инструкций:
- Нагрузка ACC kk: ACC <- KK
- Добавить ACC kk: ACC <- ACC + KK
- и ACC kk: ACC <- ACC и KK
- Дополнительный ACC kk: ACC <- ACC - KK
- Вход ACC pp: ACC <- M [PP]
- Выход ACC pp: M [PP] <- ACC
- Перейти U aa: PC <- AA
- Перейти Z aa: IF Z = 1 PC <- AA ELSE PC <- PC + 1
- Перейти C aa: IF C = 1 PC <- AA ELSE PC <- PC + 1
- Перейти NZ aa: IF Z = 0 PC <- AA ELSE PC <- PC + 1
- Jump NC aa: IF C = 0 PC <- AA ELSE PC <- PC + 1
Примечание , в синтаксисе RTL «Ссылка».
Верхние 4-6 бит каждой инструкции определяют код операции: уникальный двоичный шаблон, который позволяет ЦП определять, какую функцию необходимо выполнить, где находятся данные (операнды) и где должен быть сохранен любой полученный результат. Примечание , верхний полубайт (4 бита) каждой инструкции уникален для этой инструкции. Для тех из вас, кто знает свой машинный код, вы поймете, что эти инструкции основаны на исходном машинном коде PicoBlaze (Ссылка), еще одном красивом маленьком 8-битном процессоре, который я использовал в лекциях.Декодер команд, показанный на рисунке 29, преобразует уникальный код операции в одноразовое значение, которое затем используется на этапах декодирования и выполнения для управления аппаратным обеспечением процессора. Чтобы гарантировать, что эти сигналы не активны во время фаз выборки и инкремента, они обнуляются (обнуляются) с результатом логического ИЛИ сигналов декодирования и выполнения от генератора последовательности, как показано на рисунке 30.
Рисунок 29: Декодер команд
Примечание , логические элементы И на рисунке 29 декодируют поле кода операции i.е. каждый ноль в полубайте кода операции проходит через вентиль НЕ, так что, когда конкретный код операции декодируется, только один вентиль И будет иметь все свои входы, приведенные к логической единице, то есть никогда не будет двух вентилей И, создающих логическую единицу на в то же время (вывод с горячим кодированием).
Рисунок 30: Полный декодер команд, схема (вверху), форма сигнала (внизу)
Процессор поддерживает безусловные и условные инструкции JUMP. Команды условного перехода основаны на результате последней операции ALU i.е. биты ZERO и CARRY для инструкций ADD, SUB и AND. Они хранятся в 2-битном регистре, как показано на рисунке 31. Примечание , бит НУЛЯ генерируется 8-битным логическим элементом ИЛИ-НЕ, подключенным к выходной шине АЛУ, то есть ИЛИ производит 1 только тогда, когда все его входы равны 0.
Рисунок 31: Регистр состояния
Генератор_последовательностей , декодер_ инструкций и регистр_статуса образуют основные элементы блока управления процессора (блок декодера на рисунке 1).Сигналы от этих блоков используются для генерации управляющих сигналов для системных мультиплексоров, ALU и REG, как показано на рисунке 32. Эта таблица определяет состояние каждого управляющего сигнала для каждой фазы, чтобы реализовать функцию этой инструкции. В этой таблице также определены управляющие сигналы, необходимые для фаз выборки и увеличения. Логика, которая управляет этими управляющими сигналами (правая часть рисунка 25), взята из этой таблицы.
Рисунок 32: Управляющие сигналы
Большая часть этой управляющей логики довольно интуитивно понятна, вы просто комбинируете одноразовый выходной сигнал декодера с битами состояния из счетчика звонков для получения логических единиц в каждой строке таблицы на рисунке 32.Немного более сложный бит — это логика перехода, показанная на рисунке 33. Если процессор находится в фазе выполнения, декодер команд и сигналы состояния определяют, следует ли обновлять счетчик программ (ПК), т. Е. Следует ли загружать адрес перехода в ПК. . Если принята инструкция JUMP, то системе не нужно увеличивать ПК, поскольку она уже содержит адрес следующей инструкции. Следовательно, когда процессор находится в фазе приращения, он проверяет, был ли выполнен переход, был ли ПК не включен i.е. результат PC + 1 не сохраняется в счетчике программ.
Рисунок 33: Логика перехода
Рисунок 34: Тестовый код
Чтобы проиллюстрировать работу этого компьютера, рассмотрим простую программу на рисунке 34. Эта программа складывает два 8-битных числа без знака и проверяет их переполнение. Если происходит переполнение, результат насыщается, т.е. устанавливается максимальное значение (255). Пошаговый анализ выполнения этой программы показан на рисунках с 35 по 37, добавлены значения данных 250 и 10.Это вызовет переполнение, в результате чего конечный результат будет насыщен до 255. Однако, если используемые значения данных равны 250 и 5, переполнения не произойдет, как показано на рисунке 37. Примечание , в каждой фазе активный адрес и пути к данным выделены темно-СИНИМ цветом.
Рисунок 35: шаги с 1 по 5
- Шаг 1: сброс, очистка линии с импульсным сигналом для сброса всех триггеров, инициализация всех регистров до значений по умолчанию. Инициируются первые фазы выборки, ADDR MUX выбирает ПК i.е. значение 0, адрес памяти 0 прочитан, первая инструкция (INPUT) хранится в IR.
- Шаг 2: декодирование, декодирование поля кода операции, инструкция, идентифицированная как инструкция INPUT, управляющая логика настраивает пути данных для маршрутизации абсолютного адреса (6), хранящегося в IR, на адресную шину с использованием ADDR MUX. Чтение из памяти, доступ к данным по адресу 6 (250), данные, передаваемые на шину ввода данных, направляются через DATA MUX на вход ACC.
- Шаг 3: выполнить, ACC обновляется данными, к которым был осуществлен доступ, в конце этой фазы ACC = 250.
- Шаг 4: инкремент, инструкция выполнена, процессору нужно инкрементировать PC до адреса следующей инструкции. Управляющая логика конфигурирует ALU для выполнения функции приращения, ПК направляется на ALU, значение увеличивается и сохраняется обратно в ПК.
- Шаг 5: выборка, инструкция по адресу 1 считывается (ADD) и сохраняется в IR.
Рисунок 36: шаги с 6 по 11
- Шаг 6: декодирование, декодирование поля кода операции, инструкция, идентифицированная как инструкция ADD, управляющая логика конфигурирует пути данных для маршрутизации непосредственных данных (10), хранящихся в IR, в ALU.Второй операнд, хранящийся в ACC, также направляется в ALU. Управляющая логика настраивает ALU для выполнения функции добавления.
- Шаг 7: выполнить, выполнено сложение двух чисел, т. Е. 250 + 10 = 260. Поскольку это 8-битная машина, она не может сохранить 9-битный результат в ACC, т. Е. Произошло переполнение (максимальное значение для 8 бит — 255). Следовательно, устанавливается флаг переноса и значение 4 сохраняется в ACC. Примечание , причина 4 сохраняется в том, что получается девятибитный результат, т.е. 260 = 256 + 4 = 100000100. Девятый бит фактически является битом переноса, оставляя младшие 8 бит в ACC (00000100).После обновления ACC ПК переходит к следующему адресу (2).
- Шаг 8: выборка, декодирование, выполнение. Команда условного перехода JUMPNC «выполняется», поскольку перенос был сгенерирован, «переход при отсутствии переноса» не переходит на адрес 4, поэтому ПК увеличивается до адреса следующей инструкции (3).
- Шаг 9: выборка, декодирование. Следующая инструкция выбирается и декодируется, инструкция идентифицируется как инструкция ЗАГРУЗИТЬ, управляющая логика конфигурирует пути данных для маршрутизации непосредственных данных (255), хранящихся в IR, в ALU.Управляющая логика конфигурирует ALU для выполнения сквозной функции (данные без изменений).
- Шаг 10: выполнить, ACC обновляется значением 255. Затем PC увеличивается до следующего адреса (4).
- Шаг 11: выборка, декодирование. Следующая инструкция выбирается и декодируется, инструкция идентифицируется как инструкция OUTPUT, управляющая логика настраивает пути данных для маршрутизации абсолютного адреса (7) через ADDR MUX на адресную шину. Данные ACC передаются в память по шине вывода данных. Шина управления памятью установлена для индикации операции записи.
Примечание , обычное недоразумение заключается в различиях между командами LOAD и INPUT. Для этого процессора LOAD не читает память. Чтобы прочитать содержимое области внешней памяти, мы будем использовать инструкцию INPUT. Инструкция LOAD — это внутренняя операция, копирующая непосредственное значение, хранящееся в IR, в ACC, в приведенном выше примере это константа 255. Я согласен, что это сбивает с толку, если вы использовали другие процессоры, но для этого процессора я решил следовать синтаксису PicoBlaze: )
Рисунок 37: шаги с 12 по 17
- Шаг 12: выполнение, данные на шине вывода данных (255) записываются по адресу 7.В конце операции записи ПК увеличивается до адреса следующей инструкции (5).
- Шаг 13: выборка, декодирование. инструкция по адресу 5 считывается (JUMP) и сохраняется в IR. Поле кода операции декодировано, инструкция идентифицирована как безусловная инструкция JUMP, т.е. переход выполняется всегда, логика управления настраивает пути данных для маршрутизации абсолютного адреса (0), хранящегося в IR, на ПК.
- Шаг 14: Выполняется безусловная инструкция JUMP, обновляя ПК до адреса 0. Поскольку произошла инструкция перехода, фаза приращения не выполняется, поскольку ПК уже содержит адрес следующей инструкции.
- Шаг 15: повторить, управление вернулось к запуску программы, операции повторяются.
- Шаг 16: выборка, декодирование. Программа была изменена, чтобы продемонстрировать, что произойдет, если не будет сгенерирован перенос, непосредственное значение, используемое инструкцией ADD, изменилось с 10 на 5. Операция сложения была выполнена с результатом 255. Это соответствует 8 битам (11111111), поэтому флаг переноса не установлен. . Управляющая логика обнаруживает, что этот флаг не установлен, настраивает ALU на передачу абсолютного адреса, хранящегося в IR, без изменений, значение направляется на вход ПК.
- Шаг 17: выполнить, ПК обновлен адресом перехода (4). Поскольку произошла инструкция перехода, фаза приращения не выполняется, поскольку ПК уже содержит адрес следующей инструкции. Команда LOAD перескакивает, т.е. игнорируется.
Память, используемая в системе (рисунок 38), хранит как инструкции, так и данные, то есть архитектура фон Неймана. Его можно построить из компонентов встроенной памяти, используемых в ПЛИС, но их очень сложно настроить. I.е. инициализировать с помощью необходимых инструкций (машинный код) и значений данных. Поэтому я решил схитрить и использовать немного VHDL. Это представление на языке описания оборудования (HDL) того, что должна делать память, абстрагируясь от логических элементов низкого уровня, из которых она фактически сделана. Это позволяет мне просто вводить двоичные значения, как показано на рисунке 39. Примечание , я показал только несколько первых значений. Затем это описание синтезируется (преобразуется) инструментами Xilinx в необходимые аппаратные компоненты.Полная компьютерная система показана на рисунке 40. Диаграмму с высоким разрешением можно скачать здесь: (Ссылка).
Рисунок 38: RAM
Рисунок 39: VHDL (асинхронный, позже измененный для синхронного)
Тестовая программа, показанная на рисунке 38 (машинный код, комментарии справа выделены зеленым цветом), загружает значение, хранящееся в ячейке памяти 10, и добавляет к нему 10 (десятичное 10, а не двоичное 10). Если это не приводит к переполнению, т.е.значению больше 255, результат записывается обратно в ячейку памяти 10.Если он действительно генерирует переполнение, например 250 + 10, значение насыщается до максимального значения, например 255. Следовательно, программа считает от 0 до 250, а затем останавливается, как показано в моделировании, показанном на рисунке 41, посмотрите на нижнюю строку, это показывает содержимое ячейки памяти 10 как шестнадцатеричное значение (основание 16). Примечание , схемы Xilinx, символы и тестовый стенд VHDL для всей системы можно загрузить по ссылкам ниже (в следующем разделе). Поиграйте, измените значения данных или напишите свою собственную программу, а затем повторно запустите моделирование (top_level_v1_tb).
Рисунок 40: Полная система
Рисунок 41: Моделирование тестовой программы
Интересный дизайнерский момент, который я, признаться, сейчас пропустил, — это то, как организована память компьютера. SimpleCPU использует архитектуру фон Неймана, поэтому инструкции и данные хранятся в одной и той же памяти. Это вызывает конфликт относительно ширины ячейки памяти, то есть того, сколько бит хранится в каждой ячейке, поскольку инструкции имеют размер 16 бит, а данные — 8 бит.Количество адресуемых ячеек памяти фиксируется адресной шиной, в данном случае 8 бит (256 ячеек). Это дает дизайнеру несколько вариантов выбора:
- RAM 256 x 8 бит: каждая ячейка памяти хранит 8 бит, поэтому инструкция должна быть разделена на две ячейки памяти. В результате фаза выборки процессора теперь должна будет прочитать две ячейки памяти, чтобы получить старший и младший байт инструкции. Для этого требуется, чтобы ПК увеличивался вдвое, поэтому добавляется дополнительная фаза к генератору последовательности, показанному на рисунке 26.В качестве альтернативы в систему можно добавить дополнительное оборудование, например инкрементатор, но для этого потребовался бы дополнительный вход на адресный мультиплексор для подачи PC + 1 на адресную шину, все это увеличивает сложность оборудования. Преимущество этого подхода в том, что процессор может хранить данные по любому адресу памяти.
- RAM 256 x 16 бит: каждая ячейка памяти хранит 16 бит, поэтому инструкция может быть получена за одну транзакцию памяти. Однако, поскольку ALU и ACC являются 8-битными, теперь возникает проблема того, как 8-битное значение сохраняется в 16-битной ячейке памяти.Простое решение — сохранить данные ЦП в младшем байте и дополнить старший байт значением 0x00. Это означает, что ячейки памяти, используемые для хранения данных, теперь будут тратить 8 бит, поскольку ЦП может только читать и записывать в младший байт. Для системы только с 256 ячейками памяти потеря 50% вашей памяти данных является большим ударом, но, для простоты, это решение, которое использует эта версия simpleCPU, то есть самое простое / наименьшее аппаратное решение.
- RAM 128 x 16 бит: память теперь имеет побайтовую адресацию, каждая ячейка памяти хранит 16-битные значения, однако процессор также может читать / записывать как старший, так и младший байт.Следовательно, эффективная адресная шина сокращается до 7 бит (128 x 16 битных ячеек), поскольку создание адресуемой байтовой памяти означает, что процессор все еще должен указывать 256 x 8 битных ячеек памяти. Реализовать это на оборудовании немного сложно. Самым простым решением является параллельное подключение двух запоминающих устройств 128 x 8 бит, в одной из которых хранится старший байт, а в другом — младший. Линии адресной шины A7 — A1 используются как «адресная шина», адресная строка A0 используется для выбора, к какой памяти следует обращаться при выполнении чтения / записи байтов. E.грамм. A0 = 0: младший байт, A0 = 1: старший байт. С помощью небольшой связующей логики это также упрощает запись байтов, поскольку неиспользуемое устройство памяти можно просто отключить, то есть при записи в младший байт нельзя изменять старший байт. Выборка инструкций по-прежнему может выполняться за одну транзакцию, но теперь инструкции выровнены по четным адресам, например. по адресам 0,2,4,6,8 …
Тестирование: «Hello World»
Требование при написании вашей первой программы на любом новом процессоре — вывести на экран «HELLO WORLD».Однако обычно простая задача для процессора без экрана и только с семью основными инструкциями немного сложнее. Самый простой способ добавить экран — использовать последовательный терминал (Link) (Link), а затем передавать пакеты последовательных данных (Link). Однако сначала вам понадобится выходной порт, как показано на рисунке 42. Это просто триггер, вывод CE которого включен только для определенного адреса, в этом примере адрес 0xFF (255). Когда данные записываются на этот адрес (с использованием инструкции OUTPUT), RAM обновляется как обычно, но бит данных 0 также сохраняется в этом триггере, его выход Q подключается к линии передачи (TX) последовательной шины. .
Рисунок 42: Последовательный выходной порт
Каждый символ в строке сообщения «HELLO WORLD» сохраняется в памяти, в ячейках от 0xF0 до 0xFD, как значение ASCII (ссылка). Чтобы упростить программу, они фактически хранятся как их перевернутые формы, например. H = 0x48 (01001000), инвертированный = 0xB7 (10110111). Программа считывает биты каждого символа и выводит их на последовательный порт. Формат пакета последовательных данных для символа «K» (0x4B = 01001011) показан на рисунке 43 (Ссылка). Каждому биту выделяется временной интервал на линии последовательного порта.Скорость по умолчанию для последовательного порта составляет 9600 бит в секунду, то есть каждый бит действителен для 104 мкс (1/9600), пакеты начинаются со стартового бита (1) и заканчиваются стоповым битом (0). Эти пакеты принимаются терминальной программой, запущенной на удаленном компьютере, и отображаются на ее экране. Последовательные пакеты и дисплей терминала показаны на рисунках 43 — 46.
Рисунок 43: Формат последовательного пакета (ссылка вики выше)
Рисунок 44: Последовательный пакет HELLO WORLD (захвачен осциллографом)
Рис. 45: Первые три символа «HEL» (захвачено в прицел)
Рисунок 46: Полное сообщение отображается на терминале
Программа для отправки строки сообщения «HELLO WORLD» на последовательный терминал показана ниже.Надеюсь, большая часть кода не требует пояснений :). Следующий передаваемый символ считывается из ячейки памяти 0xE0, применяется битовая маска с помощью побитового И для выбора желаемого бита. На основе этого результата условный переход затем выбирает 0 или 1, которые сохраняются в ячейке памяти 0xFF, то есть в порту вывода (последовательный бит). Это повторяется еще семь раз, пока не будут выведены все восемь битов символов. Приведенная ниже программа могла бы быть существенно сокращена, если бы была включена инструкция SHIFT.Последний поворот — это то, как программа просматривает строку сообщения. Поскольку этот процессор не поддерживает режимы косвенной адресации, для доступа к следующему символу в строке используется самомодифицирующийся код (ссылка), то есть инструкции от 0x4F до 0x58. Программа считывает инструкцию INPUT из памяти, а затем добавляет к этой инструкции 1. Поскольку адресное поле инструкции INPUT находится в младшем байте, это изменяет адрес, который будет считан, на адрес следующего символа в строке. Затем эта измененная инструкция записывается обратно в память и выполняется программой.Само собой разумеется, что самомодифицирующийся код, то есть программа, которая перезаписывает себя, не является хорошей идеей, однако в этом случае она очень полезна. Примечание , в ранних компьютерах именно так реализовывались первые подпрограммы, то есть функции, на EDSAC. Затем программа выбирает следующий символ, сохраняя его в ячейке памяти 0xE0, если это NULL (значение 0), программа завершается, в противном случае программа переходит в ячейку памяти 0x02 и повторяет код TX. С точки зрения структуры программного обеспечения было бы неплохо, если бы процессор поддерживал подпрограммы, возможно, для версии 2.
DATA_RAM_WORD '("1010000011110000"), --00 INPUT ACC 0xF0 - загрузить первый символ
DATA_RAM_WORD '("1110000011100000"), --01 OUTPUT ACC 0xE0 - обновить tx-память
DATA_RAM_WORD '("0000000000000001"), --02 ЗАГРУЗИТЬ ACC 1 - Стартовый бит
DATA_RAM_WORD '("1110000011111111"), --03 OUTPUT ACC 0xFF - установить высокий уровень последовательного порта
DATA_RAM_WORD '("0000000011001110"), --04 ЗАГРУЗИТЬ ACC 0xCE - цикл ожидания (104us)
DATA_RAM_WORD '("0100000000000001"), --05 ADD ACC 1 - счетчик приращения
DATA_RAM_WORD '("1001110000000101"), --06 JUMP NC 0x05 - повторить 50 раз
DATA_RAM_WORD '("1010000011100000"), --07 INPUT ACC 0xE0 - прочитать символ
DATA_RAM_WORD '("0001000000000001"), --08 И ACC 0X01 - бит маски 0
DATA_RAM_WORD '("1001000000001011"), --09 JUMP Z 0x0B - при нулевом выходе
DATA_RAM_WORD '("0000000000000001"), --0A НАГРУЗКА ACC 1 - иначе установить 1
DATA_RAM_WORD '("1110000011111111"), --0B OUTPUT ACC 0xFF - Установить бит последовательного порта
DATA_RAM_WORD '("0000000011001110"), --04 ЗАГРУЗИТЬ ACC 0xCE - цикл ожидания (104us)
DATA_RAM_WORD '("0100000000000001"), --0D ADD ACC 1 - счетчик приращения
DATA_RAM_WORD '("1001110000001101"), --0E JUMP NC 0x0D - повторить 50 раз
DATA_RAM_WORD '("1010000011100000"), --0F INPUT ACC 0xE0 - прочитать символ
DATA_RAM_WORD '("0001000000000010"), --10 И ACC 0X02 - бит маски 1
DATA_RAM_WORD '("1001000000010011"), --11 JUMP Z 0x13 - при нулевом выходе
DATA_RAM_WORD '("0000000000000001"), --12 ЗАГРУЗИТЬ ACC 1 - иначе установить 1
DATA_RAM_WORD '("1110000011111111"), --13 OUTPUT ACC 0xFF - Установить бит последовательного порта
DATA_RAM_WORD '("0000000011001110"), --04 ЗАГРУЗИТЬ ACC 0xCE - цикл ожидания (104us)
DATA_RAM_WORD '("0100000000000001"), --15 ADD ACC 1 - счетчик приращения
DATA_RAM_WORD '("1001110000010101"), --16 JUMP NC 0x15 - повторить 50 раз
DATA_RAM_WORD '("1010000011100000"), --17 INPUT ACC 0xE0 - прочитать символ
DATA_RAM_WORD '("0001000000000100"), --18 И ACC 0X04 - бит маски 2
DATA_RAM_WORD '("1001000000011011"), --19 JUMP Z 0x1B - при нулевом выходе
DATA_RAM_WORD '("0000000000000001"), --1A LOAD ACC 1 - иначе установить 1
DATA_RAM_WORD '("1110000011111111"), --1B OUTPUT ACC 0xFF - Установить бит последовательного порта
DATA_RAM_WORD '("0000000011001110"), --04 ЗАГРУЗИТЬ ACC 0xCE - цикл ожидания (104us)
DATA_RAM_WORD '("0100000000000001"), --1D ADD ACC 1 - счетчик приращения
DATA_RAM_WORD '("1001110000011101"), --1E JUMP NC 0x1D - повторить 50 раз
DATA_RAM_WORD '("1010000011100000"), --1F INPUT ACC 0xE0 - прочитать символ
DATA_RAM_WORD '("0001000000001000"), --20 И ACC 0X08 - бит маски 3
DATA_RAM_WORD '("1001000000100011"), --21 JUMP Z 0x23 - при нулевом выходе
DATA_RAM_WORD '("0000000000000001"), --22 ЗАГРУЗИТЬ ACC 1 - иначе установить 1
DATA_RAM_WORD '("1110000011111111"), --23 OUTPUT ACC 0xFF - Установить бит последовательного порта
DATA_RAM_WORD '("0000000011001110"), --04 ЗАГРУЗИТЬ ACC 0xCE - цикл ожидания (104us)
DATA_RAM_WORD '("0100000000000001"), --25 ADD ACC 1 - счетчик приращения
DATA_RAM_WORD '("1001110000100101"), --26 JUMP NC 0x25 - повторить 50 раз
DATA_RAM_WORD '("1010000011100000"), --27 INPUT ACC 0xE0 - прочитать символ
DATA_RAM_WORD '("0001000000010000"), --28 И ACC 0X10 - бит 4 маски
DATA_RAM_WORD '("1001000000101011"), --29 JUMP Z 0x2B - при нулевом выходе
DATA_RAM_WORD '("0000000000000001"), --2A НАГРУЗКА ACC 1 - иначе установить 1
DATA_RAM_WORD '("1110000011111111"), --2B OUTPUT ACC 0xFF - Установить бит последовательного порта
DATA_RAM_WORD '("0000000011001110"), --04 ЗАГРУЗИТЬ ACC 0xCE - цикл ожидания (104us)
DATA_RAM_WORD '("0100000000000001"), --2D ADD ACC 1 - счетчик приращения
DATA_RAM_WORD '("1001110000101101"), --2E JUMP NC 0x2D - повторить 50 раз
DATA_RAM_WORD '("1010000011100000"), --2F INPUT ACC 0xE0 - прочитать символ
DATA_RAM_WORD '("0001000000100000"), --30 И ACC 0X20 - бит маски 5
DATA_RAM_WORD '("1001000000110011"), --31 JUMP Z 0x33 - при нулевом выходе
DATA_RAM_WORD '("0000000000000001"), --32 ЗАГРУЗИТЬ ACC 1 - иначе установить 1
DATA_RAM_WORD '("1110000011111111"), --33 OUTPUT ACC 0xFF - Установить бит последовательного порта
DATA_RAM_WORD '("0000000011001110"), --04 ЗАГРУЗИТЬ ACC 0xCE - цикл ожидания (104us)
DATA_RAM_WORD '("0100000000000001"), --35 ADD ACC 1 - счетчик приращения
DATA_RAM_WORD '("1001110000110101"), --36 JUMP NC 0x35 - повторить 50 раз
DATA_RAM_WORD '("1010000011100000"), --37 INPUT ACC 0xE0 - прочитать символ
DATA_RAM_WORD '("0001000001000000"), --38 И ACC 0X40 - бит маски 6
DATA_RAM_WORD '("1001000000111011"), --39 JUMP Z 0x3B - при нулевом выходе
DATA_RAM_WORD '("0000000000000001"), --3A НАГРУЗКА ACC 1 - иначе установить 1
DATA_RAM_WORD '("1110000011111111"), --3B OUTPUT ACC 0xFF - Установить бит последовательного порта
DATA_RAM_WORD '("0000000011001110"), --04 ЗАГРУЗИТЬ ACC 0xCE - цикл ожидания (104us)
DATA_RAM_WORD '("0100000000000001"), --3D ADD ACC 1 - счетчик приращения
DATA_RAM_WORD '("1001110000111101"), --3E JUMP NC 0x3D - повторить 50 раз
DATA_RAM_WORD '("1010000011100000"), --3F INPUT ACC 0xE0 - прочитать символ
DATA_RAM_WORD '("0001000010000000"), --40 И ACC 0X80 - бит маски 7
DATA_RAM_WORD '("1001000001000011"), --41 JUMP Z 0x43 - при нулевом выходе
DATA_RAM_WORD '("0000000000000001"), --42 ЗАГРУЗИТЬ ACC 1 - иначе установить 1
DATA_RAM_WORD '("1110000011111111"), --43 OUTPUT ACC 0xFF - Установить бит последовательного порта
DATA_RAM_WORD '("0000000011001110"), --04 ЗАГРУЗИТЬ ACC 0xCE - цикл ожидания (104us)
DATA_RAM_WORD '("0100000000000001"), --45 ADD ACC 1 - счетчик приращения
DATA_RAM_WORD '("1001110001000101"), --46 JUMP NC 0x45 - повторить 50 раз
DATA_RAM_WORD '("0000000000000000"), --47 LOAD ACC 0 - стоповый бит
DATA_RAM_WORD '("1110000011111111"), --48 OUTPUT ACC 0xFF - Установить бит последовательного порта
DATA_RAM_WORD '("0100000000000001"), --49 ADD ACC 1 - счетчик приращения
DATA_RAM_WORD '("1001110001001001"), --4A JUMP NC 0x49 - повторить 256 раз
DATA_RAM_WORD '("0000000000000000"), --4B LOAD ACC 0 - стоповый бит
DATA_RAM_WORD '("1110000011111111"), --4C OUTPUT ACC 0xFF - Установить бит последовательного порта
DATA_RAM_WORD '("0100000000000001"), --4D ADD ACC 1 - счетчик приращения
DATA_RAM_WORD '("1001110001001101"), --4E JUMP NC 0x4D - повторить 256 раз
DATA_RAM_WORD '("1010000001010010"), --4F INPUT ACC 52 - инструкция чтения
DATA_RAM_WORD '("0100000000000001"), --50 ADD ACC 1 - увеличить поле адреса
DATA_RAM_WORD '("1110000001010010"), --51 OUT ACC 52 - инструкция обновления
DATA_RAM_WORD '("1010000011110000"), --52 INPUT ACC 0xF0 - выполнить инструкцию
DATA_RAM_WORD '("1110000011100000"), --53 OUTPUT ACC 0xE0 - обновить tx-память
DATA_RAM_WORD '("0001000011111111"), --54 И ACC 0xFF - char NULL?
DATA_RAM_WORD '("1001010000000010"), --55 JUMP NZ, 2 - нет, TX
DATA_RAM_WORD '("0000000011110000"), --56 LOAD ACC 0xF0 - восстановить исходную инструкцию
DATA_RAM_WORD '("1110000001010010"), --57 OUT ACC 52
DATA_RAM_WORD '("1000000001010110"), --58 JUMP 56 - да, остановка
DATA_RAM_WORD '("0000000010110111"), --F0 H = 0x48 inv 10110111
DATA_RAM_WORD '("0000000010111010"), --F1 E = 0x45 inv 10111010
DATA_RAM_WORD '("0000000010110011"), --F2 L = 0x4C inv 10110011
DATA_RAM_WORD '("0000000010110011"), --F3 L = 0x4C inv 10110011
DATA_RAM_WORD '("0000000010110000"), --F4 O = 0x4F inv 10110000
DATA_RAM_WORD '("0000000011011111"), --F5' SP '= 0x20 inv 11011111
DATA_RAM_WORD '("0000000010101000"), --F6 W = 0x57 inv 10101000
DATA_RAM_WORD '("0000000010110000"), --F7 O = 0x4F inv 10110000
DATA_RAM_WORD '("0000000010101101"), --F8 R = 0x52 inv 10101101
DATA_RAM_WORD '("0000000010110011"), --F9 L = 0x4C inv 10110011
DATA_RAM_WORD '("0000000010111011"), --FA D = 0x44 inv 10111011
DATA_RAM_WORD '("0000000011110010"), --FB' CR '= 0x0D inv 11110010
DATA_RAM_WORD '("0000000011110101"), --FC' LF '= 0x0A inv 11110101
DATA_RAM_WORD '("0000000000000000"), --FD' NULL '= 0x00
DATA_RAM_WORD '("0000000000000000"), --FE
DATA_RAM_WORD '("0000000000000000") --FF
Пришлось внести несколько небольших изменений в схемы и файлы VHDL, чтобы минимизировать размер оборудования. E.грамм. В нынешнем виде память реализована программными средствами как 16-битный мультиплексор 256: 1, который занимает довольно много места. Добавление часов позволяет отображать память в BlockRam, то есть в RAM по умолчанию на FPGA. Последний проект, печатающий «HELLO WORLD», можно скачать здесь: (Ссылка). ПРИМЕЧАНИЕ : в этой версии ниже исправлена версия с «ошибками».
Что будет дальше с этим компьютером, я хочу посмотреть, смогу ли я заставить его вписаться в Xilinx 9572 CPLD, который мы используем для обучения проектированию оборудования, должен будет использовать внешнее ОЗУ / ПЗУ, однако основным ограничением является то, что этот программируемый оборудование имеет очень небольшое количество оборудования e.грамм. 72 шлепанца. Обновление, отказался от этой идеи в основном из-за проблем с источниками компонентов для ОЗУ и СППЗУ, необходимых для памяти инструкций и данных.
Тестирование: полностью протестировано 🙂
Изначально этот процессор был кратким примером использования, чтобы проиллюстрировать процесс реализации простой архитектуры процессора на основе логических вентилей. Признайтесь, я протестировал только оборудование, достаточное для того, чтобы получить работу «Hello World», в результате я не проверил, все ли инструкции работают правильно :).Получил электронное письмо с просьбой предоставить более подробную информацию / объяснения о работе этого процессора, я подозреваю, что были некоторые опечатки / ошибки, поэтому я подумал, что мне лучше провести «полный» тест. Набор инструкций для этого станка:
- ACC нагрузки kk: 0000 XXXX KKKKKKKK
- Добавить ACC kk: 0100 XXXX KKKKKKKK
- и ACC kk: 0001 XXXX KKKKKKKK
- Дополнительный ACC kk: 0110 XXXX KKKKKKKK
- Вход ACC pp: 1010 XXXX PPPPPPPP
- Выход ACC pp: 1110 XXXX PPPPPPPP
- Прыжок U aa: 1000 XXXX AAAAAAAA
- Перейти Z aa: 1001 00XX AAAAAAAA
- Прыжок C aa: 1001 10XX AAAAAAAA
- Перейти NZ aa: 1001 01XX AAAAAAAA
- Прыжок NC aa: 1001 11XX AAAAAAAA
Следовательно, приведенный ниже тестовый код должен позволить мне протестировать «все» инструкции:
DATA_RAM_WORD '("0000000000000001"), --00 ЗАГРУЗИТЬ ACC 0x01 -
DATA_RAM_WORD '("0100000000000000"), --01 ADD ACC, 0x00 - тест NZ NC ACC = 1
DATA_RAM_WORD '("0100000011111111"), --02 ADD ACC, 0xFF - проверка Z C ACC = 0
DATA_RAM_WORD '("0000000010101010"), --03 ЗАГРУЗИТЬ ACC 0xAA -
DATA_RAM_WORD '("0001000000001111"), --04 И ACC, 0x0F - проверка NZ NC ACC = 0x0A
DATA_RAM_WORD '("0001000000000000"), --05 И ACC, 0x00 - проверка Z NC ACC = 0x00
DATA_RAM_WORD '("0000000000000001"), --06 ЗАГРУЗИТЬ ACC 0x01 -
DATA_RAM_WORD '("0110000000000001"), --07 SUB ACC, 0x01 - проверка Z NC ACC = 0x00
DATA_RAM_WORD '("0110000000000001"), --08 SUB ACC, 0x01 - проверка NZ C ACC = 0xFF
DATA_RAM_WORD '("1110000011110000"), --09 ВЫХОДНОЙ ACC, 0xF0 - тест M [0xF0] = 0xFF
DATA_RAM_WORD '("0000000000000000"), --0A НАГРУЗКА ACC 0x00 -
DATA_RAM_WORD '("1010000011110000"), --0B INPUT ACC, 0xF0 - тестовый ACC = 0xFF
DATA_RAM_WORD '("0100000000000000"), --0C ADD ACC, 0x00 - проверка NZ NC ACC = 0x01
DATA_RAM_WORD '("1001010000001111"), --0D JUMP NZ, 0x0F - пропустить ловушку, если верно
DATA_RAM_WORD '("1000000000001110"), --0E JUMP 0x0E - ловушка
DATA_RAM_WORD '("0100000000000001"), --0F ADD ACC, 0x01 - проверка Z NC ACC = 0x00
DATA_RAM_WORD '("1001000000010010"), --10 JUMP Z, 0x12 - пропустить ловушку, если правильно
DATA_RAM_WORD '("1000000000010001"), --11 JUMP 0x11 - ловушка
DATA_RAM_WORD '("0000000000000010"), --12 ЗАГРУЗИТЬ ACC 0x02
DATA_RAM_WORD '("0100000011111111"), --13 ДОБАВИТЬ ACC, 0xFF - проверить NZ C ACC = 0x01
DATA_RAM_WORD '("1001100000010110"), --14 JUMP C, 0x16 - пропустить ловушку, если правильно
DATA_RAM_WORD '("1000000000010101"), --15 JUMP 0x15 - ловушка
DATA_RAM_WORD '("0110000000000001"), --16 SUB ACC, 0x01 - тест Z NC ACC = 0x00
DATA_RAM_WORD '("1001100000011001"), --17 JUMP NC, 0x19 - пропустить ловушку, если правильно
DATA_RAM_WORD '("1000000000011000"), --18 JUMP 0x15 - ловушка
DATA_RAM_WORD '("1000000000000000"), --19 JUMP 0x00 - цикл
Это не полный тест всех функциональных модулей со всеми возможными значениями данных или всеми возможными комбинациями инструкций, так как это займет вечность, но этот код действительно тестирует типичное использование, поэтому должен выявить любые серьезные проблемы.Тестирование началось нормально, ЗАГРУЗИТЬ, И, ДОБАВИТЬ, казалось, все работает нормально, затем я пришел к инструкции SUB :(. Я пропустил обновление ACC, также испортил MUX_A и MUX_B. Для ADD и AND не имеет значения, какой Таким образом, операнды передаются в ALU, например (ACC = InputA, Constant = InputB) или (ACC = InputB, Constant = InputA), оба будут давать один и тот же результат. Однако нам нужно вычитание (ACC — Константа), выполняя вычитание наоборот не так полезно :(. Это было «легко» исправить, т.е. переключить пути данных от ACC и IR к двум мультиплексорам, но это означает, что мне нужно обновить логику декодера и, что еще больше раздражает, перерисовать все блок-схемы в слайдах лекции, в один прекрасный день :).Поэтому переключил шины данных и обновил декодер, теперь ACC имеет правильное значение, но, другая радость, не учел флаг переноса. ALU выполняет вычитание путем добавления отрицательного числа, поэтому, если ACC = 1, вычитание 1 установит флаг переноса, поскольку эта операция реализуется путем добавления 255. В настоящее время не знаю, как с этим справиться, я чувствую, что есть простой решение кричит на меня, но на данный момент иду на испытанный и проверенный подход игнорирования его :). Новые и улучшенные файлы проекта SimpleCPU и этот тестовый код можно скачать здесь: (Ссылка).
Эта работа находится под международной лицензией Creative Commons Attribution-NonCommercial-NoDerivatives 4.0.
Контактный адрес электронной почты: [email protected]
Назад
Высоковольтный кристалл возбуждения SOI CMOS для системы программируемого жидкостного процессора
Было продемонстрировано, что высоковольтная интегральная схема транспортирует пробы жидких капель по программируемым путям через массив приводных электродов на поверхности с гидрофобным покрытием.Этот чип возбудителя является двигателем для микрожидкостных систем «лаборатория на чипе» на основе диэлектрофореза (DEP), создающих возбуждения поля, которые впрыскивают и перемещают жидкие капли на поверхность манипуляции и вокруг нее. Архитектура этого чипа может быть расширена до массивов из N X N идентичных схем драйвера высоковольтных электродов и электродов. Микросхема возбудителя программируется в нескольких смыслах. Маршруты нескольких капель могут быть заданы произвольно в пределах массива электродов. Амплитуда, фаза и частота напряжения формы волны возбуждения электрода могут регулироваться на основе конфигурации системы и сигнала, необходимого для управления определенным составом капель жидкости.Амплитуда напряжения формы волны возбуждения электрода может быть установлена от минимального логического уровня до максимального предела напряжения пробоя технологии изготовления. Частота формы волны возбуждения электрода также может быть установлена независимо от его напряжения, вплоть до максимального значения, в зависимости от типа капель, которые необходимо запустить. На микросхему возбудителя может быть нанесено покрытие, а его оксидная поверхность может использоваться в качестве поверхности для манипулирования каплями или может использоваться с установленной сверху закрытой жидкостной камерой, состоящей из различных материалов.Высоковольтная способность микросхемы возбудителя позволяет генерируемым силам DEP проникать в закрытую область камеры, а регулируемая амплитуда напряжения может соответствовать разной толщине дна камеры. Эта демонстрационная микросхема возбудителя имеет матрицу 32 x 32 драйверов электродов номинально 100 В, которые индивидуально программируются в каждый момент времени в процедуре на любую из двух фаз: 0 ° и 180 ° относительно опорной частоты. Для этого демонстрационного чипа при работе электродов с периодической формой сигнала от пика до пика 100 В максимальная частота формы волны электрода HV составляет около 200 Гц; и стандартная скорость передачи данных 5-вольтовой КМОП-логики может изменяться до 250 кГц.Этот демонстрационный высоковольтный кристалл изготовлен по технологии изготовления КМОП-матрицы с КНИП-матрицей 1,0 мкм на 130 В, рассеивает максимум 1,87 Вт и имеет размер около 10,4 x 8,2 мм.
| Описание Печатная плата 2-го процессора Acorn 32016 (внизу) .jpg | Английский: Плата второго процессора Acorn 32016 (внизу). Это второй процессор 32016, самый редкий из процессоров второго поколения Acorn.Первоначально он должен был называться 2-й процессор 16032 и назван так в некоторой ранней литературе BBC, но NatSemi изменил название чипа на 32016 до того, как он был построен. Он имеет процессор NatSemi NS32016D-8 с тактовой частотой 6 МГц и 1 МБ (32 x 32 КБ ОЗУ) с контроллером Ferranti ULA Tube. ПЗУ загружаются в ядро ОС PANDORA, которое затем загружает PANOS с диска. Помимо второго процессора 32016, Acorn использовал ЦП NS32016 в: Вот брошюра Acorn для второго процессора 32016 На фотографиях показано:
| |||||||
| Дата | с 2004 по 2011 год дата QS: P, + 2050-00-00T00: 00: 00Z / 7, P1319, + 2004-00-00T00: 00: 00Z / 9, P1326, + 2011-00-00T00: 00 : 00Z / 9, P1480, Q5727902 | |||||||
| Источник | Желуди Криса: Acorn ANC05 32016 2-й процессор, прямой | |||||||
| Автор | Крис Уайтхед, | |||||||
| Разрешение (повторное использование этого файла) |
Крис Уайтхед, владелец авторских прав на это произведение, настоящим публикует его под следующей лицензией:
|
микроконтроллер — ссылки на контакты и функциональность процессора — документация Adafruit CircuitPython 7.1.0-beta.1
Модуль микроконтроллера определяет контакты с точки зрения
микроконтроллер.См. Плату , чтобы узнать о назначении контактов для конкретных плат.
Доступно на этих платах
- 8086 Commander
- @sarfata РУБАШКА
- AITHinker ESP32-C3S_Kit
- Значок ARAMCON 2019
- Значок ARAMCON2
- ATMegaZero ESP32-S2
- Значок Adafruit BLM
- Adafruit CLUE nRF52840 Экспресс
- Adafruit Circuit Детская площадка Bluefruit
- Adafruit Circuit Playground Express 4-H
- Adafruit CircuitPlayground Express
- Adafruit CircuitPlayground Express с библиотеками Crickit
- Adafruit CircuitPlayground Express с дисплеем
- Adafruit EdgeBadge
- Adafruit Feather Bluefruit Sense
- Adafruit Feather ESP32-S2 TFT
- Adafruit Feather ESP32S2
- Adafruit Feather M0 Adalogger
- Adafruit Feather M0 Базовый
- Adafruit Feather M0 Экспресс
- Adafruit Feather M0 Express с библиотеками Crickit
- Adafruit Feather M0 RFM69 Перо Adafruit M0 RFM69
- Adafruit Перо M0 RFM9x
- Adafruit Feather M4 CAN
- Adafruit Feather M4 Экспресс
- Adafruit Feather MIMXRT1011 Перо Adafruit
- Adafruit Feather RP2040 (Перо Adafruit)
- Adafruit Feather STM32F405 Экспресс
- Adafruit Feather nRF52840 Экспресс
- Adafruit FunHouse
- Адафрут Джемма M0
- Adafruit Gemma M0 PyCon 2018 г.
- Adafruit Grand Central M4 Express
- Adafruit Hallowing M4 Express
- Adafruit ItsyBitsy M0 Express
- Adafruit ItsyBitsy M4 Express
- Adafruit ItsyBitsy RP2040
- Adafruit ItsyBitsy nRF52840 Экспресс
- Adafruit KB2040
- Драйвер для светодиодных очков Adafruit nRF52840
- Адафрут Макропад RP2040
- Adafruit MagTag
- Матричный портал Adafruit M4
- Adafruit Metro ESP32S2
- Адафрут Метро M0 Экспресс
- Adafruit Metro M4 Airlift Lite
- Адафрут Метро М4 Экспресс
- Адафрут Метро nRF52840 Экспресс
- Адафрут Монстр M4SK
- Adafruit NeoKey Trinkey M0
- Adafruit NeoPixel Trinkey M0
- Adafruit ProxLight Trinkey M0
- Adafruit PyGamer
- Adafruit PyPortal
- Adafruit PyPortal Pynt
- Adafruit PyPortal Titano
- Adafruit PyRuler
- Adafruit Pybadge
- Adafruit QT Py ESP32S2
- Adafruit QT Py M0
- Adafruit QT Py M0 Haxpress
- Adafruit QT Py RP2040
- Adafruit QT2040 Trinkey
- Adafruit Rotary Trinkey M0
- Adafruit Slide Trinkey M0 Слайд-шоу
- Adafruit Trellis M4 Express
- Adafruit Брелок M0
- AloriumTech Evo M51
- Ардуино MKR ноль
- Ардуино MKR1300
- Ардуино Нано 33 BLE
- Arduino Nano 33 Интернет вещей
- Arduino Nano RP2040 Подключение
- Ардуино ноль
- Artisense Reference Design RD00
- AtelierDuMaker nRF52840 Прорыв
- BDMICRO VINA-D21
- BDMICRO VINA-D51
- Плата разработки BLE-SS с несколькими датчиками
- BastBLE
- BastWiFi
- BlueMicro840
- CP Саженец M0
- CP Sapling M0 с SPI Flash
- CP32-M4
- Программируемый USB-концентратор для роботов
- Cedar Grove StringCar M0 Express
- Challenger NB RP2040 Wi-Fi
- Challenger RP2040 LTE
- Challenger RP2040 Wi-Fi
- Circuit Playground Экспресс Digi-Key PyCon 2019
- CircuitBrains Basic
- CircuitBrains Deluxe
- CrumpS2
- Cytron чайник Pi RP2040
- DynOSSAT-EDU-EPS
- DynOSSAT-EDU-OBC
- DynaLoRa_USB
- ESP 12k NodeMCU
- Ловушка для кошек Electronic Cats Pro Mini M0
- Электронные кошки CatWAN USBStick
- Электронные кошки Hunter Cat NFC
- Электронные кошки NFC Copy Cat
- Электронная лаборатория Blip
- Электронут Лабс Папир
- EncoderPad RP2040
- Escornabot Makech
- Espruino Pico
- Espruino Wi-Fi
- Перо ESP32S2 без PSRAM
- Перо MIMXRT1011
- Перо MIMXRT1062
- Перо S2
- Перо S2 Neo
- FeatherS2, пререлиз
- Пух M0
- Фому
- Franzininho WIFI с комнатой
- Franzininho WIFI с Wrover
- Огурец Gravitech M
- Gravitech Cucumber MS
- Gravitech Огурец R
- Gravitech Огурец RS
- HMI-DevKit-1.1
- Взломанный Feather M0 Express с 8-мегабайтной флэш-памятью SPI
- HalloWing M0 Express
- HiiBot BlueFi
- IMXRT1010-EVK
- IkigaiSense Vita nRF52840
- База данных J&J Studios - Расстояние
- Данные J&J Studios - IMU
- J&J Studios базовый свет
- Данные J&J Studios - Погода
- Калуга 1
- LILYGO TTGO T8 ESP32-S2 с дисплеем
- Базовая плата LoC BeR M4
- MDBT50Q-DB-40
- MDBT50Q-RX Донгл
- MEOWBIT
- MORPHEANS MorphESP-240
- MakerDiary nRF52840 MDK
- MakerDiary nRF52840 USB-ключ MDK
- Makerdiary M60 Клавиатура
- Makerdiary Pitaya Go
- Makerdiary nRF52840 M.2 Комплект разработчика
- Мелоперо Шейк RP2040
- Мяу Мяу
- Метро MIMXRT1011
- MicroDev microC3
- MicroDev microS2
- Мини ЗУР М4
- NUCLEO STM32F746
- NUCLEO STM32F767
- NUCLEO STM32H743
- OPENMV-H7 R1
- Дуб Дев Тек ХЛЕБ 2040
- Дуб Dev Tech PixelWing ESP32S2
- Значок Open Hardware Summit 2020
- PCA10056 nRF52840-DK
- PCA10059 nRF52840 Донгл
- PCA10100 nRF52833 DK
- PYB LR Nano V2
- Аргон в виде частиц
- Частичный бор
- Ксенон в виде частиц
- PewPew 10.2
- PewPew 13
- PewPew M4
- PicoPlanet
- Pimoroni Interstate 75
- Пиморони Keybow 2040
- Пиморони PGA2040
- Pimoroni Pico LiPo (16 МБ)
- Pimoroni Pico LiPo (4 МБ)
- Pimoroni PicoSystem
- Пиморони Плазма 2040
- Пиморони Крошечный 2040
- PyCubedv04
- PyCubedv04-MRAM
- PyCubedv05
- PyCubedv05-MRAM
- PyKey60
- PyboardV1_1
- RP2040 Штамп
- Raspberry Pi 4B
- Плата ввода-вывода для вычислительного модуля Raspberry Pi 4
- Raspberry Pi Пико
- Raspberry Pi Zero 2 Вт
- Робо-шляпа MM1 M4
- S2 Мини
- S2Pico
- SAM E54 Xplained Pro
- САМ32в26
- SPRESENSE
- ST STM32F746G Открытие
- STM32F411E_DISCO
- STM32F412G_DISCO
- STM32F4_DISCO
- Saola 1 с туалетом
- Saola 1 с Wrover
- Терминал Seeeduino Wio
- Seeeduino XIAO
- Seeeduino XIAO KB
- Змея
- ООО «Силикогнитшн» М4-Шим
- Зиммель
- SparkFun LUMIDrive
- Процессор SparkFun MicroMod RP2040
- Процессор SparkFun MicroMod SAMD51
- Процессор SparkFun MicroMod nRF52840
- SparkFun Pro Micro RP2040
- SparkFun Pro nRF52840 Mini
- SparkFun Qwiic Micro Номер
- SparkFun RedBoard Turbo
- SparkFun SAMD21 Dev Breakout
- SparkFun SAMD21 Mini Breakout
- Процессор SparkFun STM32 MicroMod
- SparkFun Thing Plus - RP2040
- SparkFun Thing Plus - SAMD51
- Sprite_v2b
- StackRduino M0 PRO
- Лебедь R5
- TG-Boards 'Datalore IP M4
- TG-Часы
- THUNDERPACK_v11
- THUNDERPACK_v12
- Зажим для модуля Targett с Wroom
- Зажим для модуля Targett с Wrover
- Малышка 4.0
- Крошка 4.1
- Teknikio Bluebird
- Открытое книжное перо
- TinkeringTech ScoutMakes Azul
- TinyS2
- Брелок M0 Haxpress
- UARTLogger II
- WarmBit BluePixel nRF52840
- Кнопка большого гудка Winterbloom
- Солнце Винтерблума
- XinaBox CC03
- XinaBox CS11
- iMX RT 1020 EVK
- iMX RT 1060 EVK
- сникборд keithp.com
- микро: бит v2
- nanoESP32-S2 с Wrover
- nanoESP32-S2 с ванной
- ndGarage [№] Bit6: FeatherSnow-v2
- ndGarage [№] Bit6: FeatherSnow
- приятно! Нано
- senseBox MCU
- stm32f411ce-blackpill
- stm32f411ce-blackpill-со вспышкой
- uChip
- uИгра 10
- Микроконтроллер
.процессор: процессор ¶ Информация о процессоре и управление, например,
температура процессораичастота процессора(тактовая частота). Этот объект является экземпляром микроконтроллера. Процессор.
- Микроконтроллер
.процессор: процессор ¶ Информация и управление ЦП, например
cpus [0] .temperatureиcpus [1] .frequency(тактовая частота) на микросхемах с более чем 1 ЦП.Индекс выбирает, какой процессор. Этот объект является экземпляром микроконтроллера. Процессор.
- Микроконтроллер
.delay_us( задержка: int ) → Нет Специальный метод задержки, используемый для очень коротких задержек. Не делайте долгих задержек потому что это останавливает выполнение всех других функций. Думайте об этом как о пустом
, а цикл, который выполняется в течение указанного времени(задержка). Если у вас есть другие код или периферийные устройства (например,g аудиозаписи), требующих определенного времени, или обработки, пока вы ждете, исследуйте другой путь, например, используяtime.sleep ().
- Микроконтроллер
.disable_interrupts() → Нет Отключить все прерывания. Будьте очень осторожны, это может все заглохнуть.
- Микроконтроллер
.enable_interrupts() → Нет Разрешить прерывания, которые были разрешены при последнем отключении.
- Микроконтроллер
.on_next_reset( run_mode: RunMode ) → Нет Настройте рабочий режим, который будет использоваться при следующем сбросе микроконтроллера, но не выключен.
- Параметры
run_mode ( RunMode ) - Следующий режим запуска
- Микроконтроллер
.сброс() → Нет Перезагрузите микроконтроллер.После сброса микроконтроллер войдет в последний раз режим работы был установлен
on_next_reset.Предупреждение
Это может привести к повреждению файловой системы при подключении к сервер. Будьте очень осторожны при вызове этого номера! Убедитесь, что устройство «Безопасно удалено» в Windows или «извлечено» в Mac OSX и Linux.
- Микроконтроллер
.nvm: дополнительный [nvm.ByteArray] ¶ Доступная энергонезависимая память.Этот объект является единственным экземпляром
nvm.ByteArray, если он доступен, илиNoneв противном случае.- Тип
nvm.ByteArray или нет
- Микроконтроллер
.watchdog: Дополнительно [watchdog.WatchDogTimer] ¶ Имеется сторожевой таймер. Этот объект является единственным экземпляром сторожевого таймера
. WatchDogTimer, если доступен, илиНет,в противном случае.
- класс
микроконтроллер.Штифт¶ Обозначает вывод IO на микроконтроллере.
Обозначает вывод IO на микроконтроллере. Они фиксируются оборудование, поэтому они не могут быть построены по запросу. Вместо этого используйте Плата
. Выводдля ссылки на нужный вывод.
- класс
микроконтроллер.Процессор¶ Микроконтроллер ЦП информации и управления
использование:
импортный микроконтроллер печать (микроконтроллер.cpu.frequency) печать (температура микроконтроллера) Обратите внимание, что на микросхемах с более чем одним процессором (например, RP2040) microcontroller.cpu вернет значение CPU 0. Чтобы получить значения от других процессоров, используйте microcontroller.cpus, проиндексированный номер желаемого процессора. т.е. печать (микроконтроллер.cpus [0]. температура) печать (microcontroller.cpus [1] .frequency)
Вы не можете создать экземпляр микроконтроллера
. Процессор. Используйтеmicrocontroller.cpuдля доступа к единственному доступному экземпляру.-
частота: int ¶ Рабочая частота процессора в герцах. (только чтение)
-
reset_reason: ResetReason ¶ Причина запуска микроконтроллера из состояния сброса.
-
температура: Дополнительно [плавающее] ¶ Температура на кристалле в градусах Цельсия в виде поплавка. (только чтение)
Is
Нет, если температура недоступна.
-
uid: bytearray ¶ Уникальный идентификатор (также известный как серийный номер) микросхемы в виде массива байтов
-
напряжение: Дополнительно [плавающее] ¶ Входное напряжение микроконтроллера в виде поплавка. (только чтение)
Is
Нет, если напряжение отсутствует.
-
- класс
микроконтроллер.Причина сброса¶ Причина последнего сброса микрокроллера
-
POWER_ON: объект ¶ Микронтроллер был запущен при выключенном питании.
-
КОРИЧНЕВЫЙ: объект ¶ Микронтроллер был сброшен из-за слишком низкого напряжения.
-
ПРОГРАММНОЕ ОБЕСПЕЧЕНИЕ: объект ¶ Микронтроллер был сброшен с помощью программного обеспечения.
-
DEEP_SLEEP_ALARM: объект ¶ Микронтроллер был переведен в режим глубокого сна и перезапущен по сигналу тревоги.
-
RESET_PIN: объект ¶ Микронтроллер был сброшен сигналом на его контакте сброса. Контакт может быть подключен к кнопке сброса.
-
WATCHDOG: объект ¶ Микроконтроллер был сброшен сторожевым таймером.
-
НЕИЗВЕСТНО: объект ¶ Микронтроллер перезапустился по неизвестной причине.
-
RESCUE_DEBUG: объект ¶ Микронтроллер был сброшен аварийным портом отладки.
-
- класс
микроконтроллер.Режим работы¶ состояние работы микроконтроллера
Enum-подобный класс для определения режима работы микроконтроллера и CircuitPython.
-
НОРМАЛЬНОЕ: Режим работы ¶ Запустите CircuitPython как обычно.
-
SAFE_MODE: RunMode ¶ Запустите CircuitPython в безопасном режиме. Код пользователя не запускается, и файловая система будет доступна для записи через USB.
-
UF2: Режим работы ¶ Запустите загрузчик uf2.
-
ЗАГРУЗЧИК: Режим работы ¶ Запустите загрузчик по умолчанию.
-