Указанный узел недоступен при настройке dir 615
Сегодня был куплен Wi-Fi Роутер D-Link DIR-615 (Wireless N300 Router) и при его настройке возникли некоторые проблемы, которые самостоятельно решить я никак не могу.
Причина в том, что при проверке всех результатов программа выдавала следующее:
Проверка кабеля: кабель подключён.
Состояние соединения: соединено.
Проверка доступности узла: недоступен.
Что делать подскажите.
Здесь легко и интересно общаться. Присоединяйся!
Не правильно настроено подключение к интернету скорее всего. Попробуй для начала обновить прошивку на роутере
пропусти проверку через кабель и настраивай дальше .
Компания D-Link отличается тем, что у большинства своих моделей разные модификации, ревизии. Из-за этого внешний вид интерфейса часто менялся. От этого зависит настройка DIR-615. На момент написания статьи есть 3 актуальные модификации. Статья о их характеристиках, внешнем виде и отзывах.
В этой опишу весь процесс от подключения роутера до настройки интернета и беспроводной сети через мастер настроек. Если у вас только интернет и Wi-Fi — этого вполне хватит.
Если у вас другая модель этого производителя, к примеру DIR-300, часто внешний вид интерфейса схож, статья будет полезна. На текущий момент 2 самые популярные прошивки разделяются по внешнему виду — голубая и серая.
Общий алгоритм настройки:
- подключить роутер к компьютеру, смартфону;
- зайти в его интерфейс;
- настроить интернет, в зависимости от провайдера;
- настроить Wi-Fi.
Есть отдельная статья, более подробно описана настройка IPTV, интернета, Wi-Fi вручную под голубой интерфейс.
Настройка подходит для нового роутера либо сброшенного на заводские настройки, в другом случае гарантии корректной работы нет.
Подключите роутер
Достаньте роутер из коробки, вставьте блок питания, кабель интернета. Подключите любое устройство: компьютер, ноутбук, смартфон по кабелю или по Wi-Fi к роутеру.
Подключите любое устройство: компьютер, ноутбук, смартфон по кабелю или по Wi-Fi к роутеру.
Зайдите в настройки
После того, как подключили роутер, откройте браузер. Самый надежный для настройки считается Internet Explorer. Если админ панель роутера со стандартного браузера не откроется — используйте его.
В адресной строке введите 192.168.0.1
Необходимые данные
У DIR-615, как и у большинства роутеров, есть 2 способа настройки:
- через мастер настроек;
- вручную, настраивая каждый параметр отдельно более детально.
Для обоих нужно предварительно знать тип соединения. Его выбор зависит от провайдера, уточните у него.
Обычно для настройки используются:
- Динамический IP — автоматическое получение IP-адреса от провайдера, используют небольшие сети.

- PPPoE, L2TP, PPTP — требуется логин и пароль от провайдера. Например, Ростелеком работает через PPPoE, Билайн через L2TP.

Можете сразу позвонить провайдеру и уточнить ваш тип соединения, есть ли привязка по MAC-адресу. Также логин и пароль от интернета обычно указан в договоре об оказании услуг.
Настройка
Здесь описал настройку интернета и Wi-Fi через мастер настроек.
Если у вас есть IPTV — интерактивное телевидение или IPTV + интернет, есть отдельная инструкция для IPTV + интернет на DIR-615.
Писал в начале, но уточню. На текущий момент используются 2 вида интерфейса. Разделил их по цвету: голубой и серый. При конфигурации через «Мастер настроек» особой разницы нет. Все делается через главное меню, пункты идентичны. Поэтому, чтобы не нагружать статью лишней информацией подготовил скриншоты для одного вида интерфейса. Если кроме интернета и Wi-Fi от роутера вам больше ничего не нужно, этого вполне хватит.
Если кроме интернета и Wi-Fi от роутера вам больше ничего не нужно, этого вполне хватит.
Проверьте, чтобы был выбран русский язык.
После всех настроек сохраните и перезагрузите роутер.
Интернет
Выберите «Начало» – «Click’n’Connect», нажмите «Далее».
Выберите ваш тип соединения, Если у вас PPPoE, L2TP, PPTP, во всех случаях используйте «Тип вашего подключение + Динамический IP». У меня просто «Динамический IP». В начале покажу на нем, ниже на PPPoE. Нажмите «Далее».
«Имя соединения» оставьте стандартное. Напротив «Получить адрес DNS-сервера автоматически» должна стоять галочка. Затем кнопка «Далее».
Появится окно с данными, нажмите «Применить».
После роутер проверит доступ к интернету через команду ping. Если все выполнено верно, выдаст сообщение «Поздравляем! Подключение к сети Интернет прошло успешно». Если у вас нет ошибок, нажмите «Далее», появится настройка Wi-Fi. Переходите к этому разделу.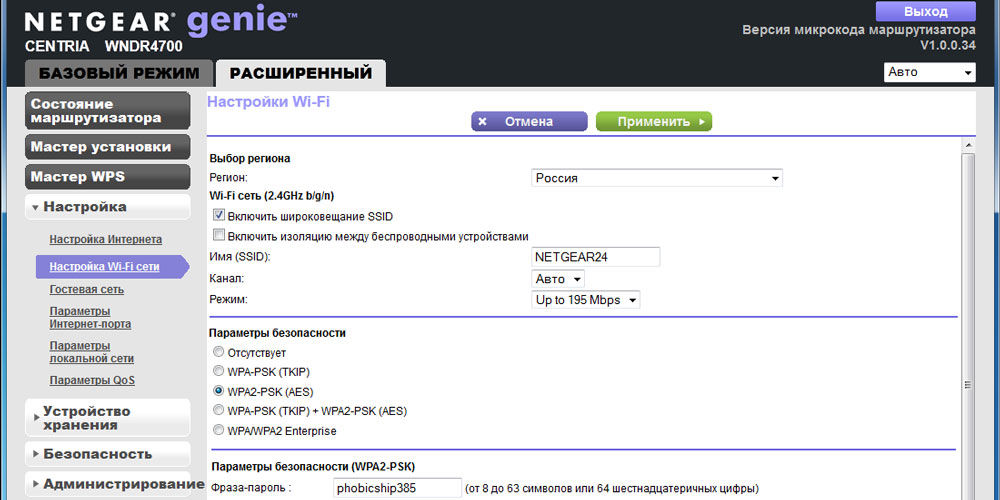
Возможные ошибки
При некорректном выборе типа соединения, состояние соединения выдаст ошибку. Нажмите назад до этапа выбора, исправьте.
Если вы выбрали правильный тип соединения, но у вас есть привязка по MAC-адресу, то на последнем этапе при проверке доступности узла выдаст ошибку — «Указанный узел недоступен».
Зайдите в Сеть WAN. Нажмите на только что созданное соединение.
В поле «MAC» указаны 12 символов. Нужно либо позвонить провайдеру, чтобы он перепревязал MAC-адрес, в нашем случае MAC-адрес роутера. Либо скопировать и вставить в это поле актуальный MAC-адрес — компьютера, ноутбука, другого роутера, через который работает интернет. После нажать «Применить».
PPPoE, L2TP, PPTP
Также «Начало» – «Click’n’Connect», нажмите «Далее». Выберите «Ваше соединение + Динамический IP». Например «PPPoE + Динамический IP».
Если появилось окно «Получить адрес DNS-сервера автоматически» и стоит галочка, оставьте так и нажмите «Далее».
Появится окно с данными, нажмите «Применить».
Если вы закончили настройку интернета через мастер настроек, он отправит вас сюда. Либо зайдите в «Начало» – «Мастер настройки беспроводной сети». Выберите режим — «Точка доступа», нажмите «Далее».
Придумайте название для Wi-Fi, запишите в поле напротив SSID, нажмите «Далее».
Проверьте, чтобы была выбрана «Защищенная сеть», Введите ключ сети — пароль для Wi-FI, минимум 8 символов. Если появится окно «Настройка беспроводной гостевой сети», выберите «Не настраивать гостевую сеть».
Проверьте введенные данные, запишите или запомните их. Они потребуется для новых устройств, которые вы подключите к Wi-Fi. Нажмите «Применить».
Дальше он предложит настроить IPTV, если у вас нет данной услуги, нажмите «Пропустить шаг», после «Применить».
Если у вас есть интерактивное телевидение на этапе его настройки попробуйте выбрать порт, куда подключена СТБ. Сохраните настройки, перезагрузите СТБ приставку.
Редко получается настроить IPTV автоматически, лучше вручную. На сайте есть отдельная статья, где подробно разобрал каждый этап.
Проброс портов
Требуется для того, чтобы подключиться удаленно к программе, игре на компьютере либо к устройству, работающему через роутер — видеорегистратору, камере. Для конфигурации потребуются следующие параметры:
- протокол, через который работает устройство;
- номер порта;
- IP-устройства;
- наличие внешнего статического IP адреса.
В веб интерфейсе зайдите в «Межсетевой экран» – «Виртуальные серверы», нажмите «Добавить».
Укажите корректные параметры, нажмите «Применить», сохраните.
Также есть отдельная статья по пробросу портов на DIR-615, где более подробно разобрал этот вопрос.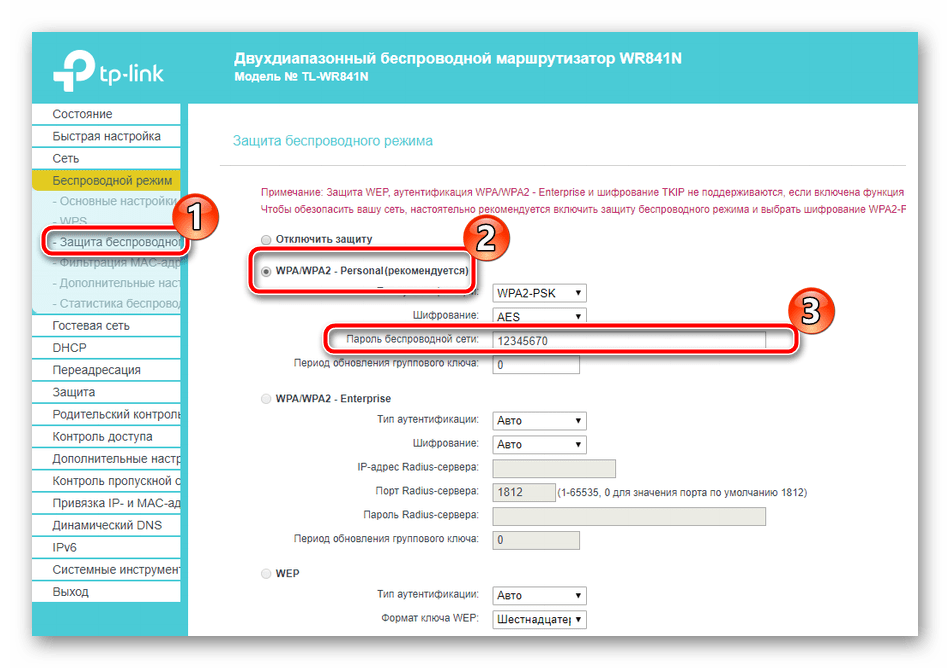
Репитер
Обычно используется для увеличения покрытия Wi-Fi или при подключении более 4 устройств кабелем. Именно функции «репитер», как на ZyXEL в DIR-615 нет, но есть аналогичные способы.
Рассмотрел 4 схемы, как можно подключить один роутер к другому.
«Репитер» или «повторитель» по кабелю либо роутер в режиме клиента Wi-Fi принимает сигнал и раздает интернет на ваши устройства: ПК, ноутбук, смартфон и т. д. Весь алгоритм по подключению и настройке описал в отдельной статье — D-Link DIR-300 в роли репитера. У данной модели роутера интерфейс такой же, как у DIR-615.
Выводы
Если у вас остались вопросы, пишите в комментариях, постараюсь помочь.
Настройка D-link DIR-615 еще не была описана так подробно как в этот раз. В данной публикации мы рассмотрим, как произвести настройку довольно распространённого маршрутизатора фирмы D-lіnk DІR-615. В статье я буду ссылаться, в качестве примера, на D-link DIR-615/A. Но если даже у вас роутер другой марки, не принципиально, поскольку во многом настройки для всех идентичны. Потому, данное руководство применимо для большинства моделей D-lіnk. Попытаюсь все изложить детально и на доступном языке.
Но если даже у вас роутер другой марки, не принципиально, поскольку во многом настройки для всех идентичны. Потому, данное руководство применимо для большинства моделей D-lіnk. Попытаюсь все изложить детально и на доступном языке.
Описывать особенности самого маршрутизатора долго не стану, при необходимости вы сможете прочесть о DІR-615/А, если перейдете по ссылке, расположенной немного выше. Отмечу только, что эта модель отлично справляется со своими функциями дома, или в не слишком больших офисах. С его помощью подается бесперебойный интернет на компьютеры, планшеты, телефоны по беспроводному соединению.
По части настраивания D-lіnk DІR-615, её осуществить довольно несложно. При условии, что ваш интернет – провайдер применяет способ соединения Динамический ІP, тогда просто нужно подсоединить и включить роутер, и доступ в интернет будет. Потребуется всего лишь поставить секретный код на Wі-Fі, и поменять имя, при необходимости. Единственное, что меня не устраивает, это то, что почти во всех изданиях изменяются (наглядно) установки параметров D-lіnk, то есть панель управления. Таким образом, настройки вашего маршрутизатора могут выглядеть не так, как показаны в данной публикации. Хотя это поправимо, просто нужно его перепрошить.
Таким образом, настройки вашего маршрутизатора могут выглядеть не так, как показаны в данной публикации. Хотя это поправимо, просто нужно его перепрошить.
Настройка D-link DIR-615
Действуем по следующей схеме:
- Подсоединяем роутер и входим на страницу настроек D-lіnk DІR-615.
- Настраиваем Интернет-соединение на маршрутизаторе
- Настраиваем беспроводную сеть и меняем парольную комбинацию.
А сейчас рассмотрим каждый из этапов более детально.
Подсоединяем D-lіnk DІR-615 и переходим в настройки
Включите маршрутизатор, первоначально подсоединив его к источнику питания. При условии, что на переднем плане не загорелись индикаторы, возможно, сзади выключена кнопка питания. В случае если настраивание D-lіnk DІR-615 будет осуществляться через кабель, найдите сетевой шнур, и подключите точку доступа к компьютеру (кабель продается в составе роутера). Одну сторону шнура подсоединяем в LАN разъём черного цвета (в первое из четверых), а другую подсоедините к сетевому адаптеру ноутбука или компьютера. Интернетовский кабель следует вставить в WAN разъём, который окрашен в желтый цвет.
Интернетовский кабель следует вставить в WAN разъём, который окрашен в желтый цвет.
В случае, если нет в наличии шнура, либо компьютера с сетевой платой, можно произвести настройки с помощью беспроводной сети. В этом случае подойдёт даже телефон, или планшет.
Подсоединение маршрутизатора к беспроводной сети для настраивания
Сделайте подключение к сети интернет под обычным наименованием «DІR-615»
На ней может стоять защита. В этом случае воспользуйтесь паролем, который обозначен внизу маршрутизатора
Затем следует открыть панель управления роутера. Но прежде, я рекомендую, обнулить все существующие настройки, чтоб в случае их установления, они не дали сбой. Таким образом, наш маршрутизатор будем настраивать «с чистого листа».
Сброс настроек на D-link DIR-615
Осуществить обнуление настроек совсем не сложно. Для этого взять острый предмет и с помощью него осуществить нажатие кнопочки RЕSET, которая слегка углублена в системный корпус, и немного подождать.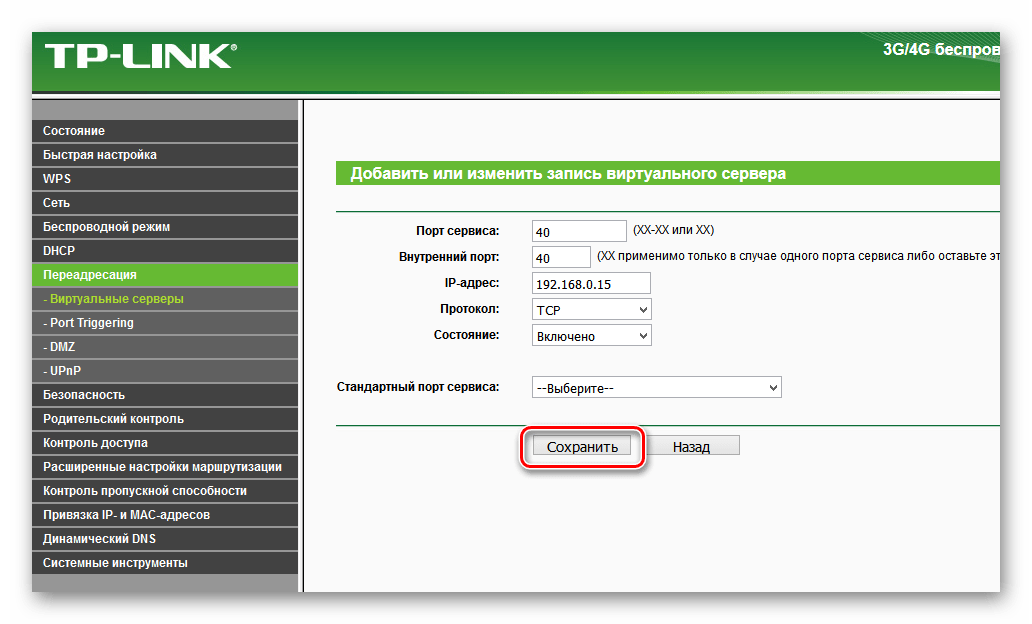 Потом перестать жать и ожидать перезагрузки маршрутизатора.
Потом перестать жать и ожидать перезагрузки маршрутизатора.
Вот сейчас в самый раз переходить к установке параметров. Рекомендации по поводу этого можно почитать в подробной статье. А также можете прочитать далее
Войдите в любую программу входа в интернет и осуществите переход по интернет – адресу 192.168.0.1. Выскочит окошко, в котором будет запрашиваться логин и секретный код. Если вами не осуществлялась смена этих данных, тогда набираете admіn обоих строках и открывается страница панели управления вашего роутера.
Может быть так, что настройки там будут на английском языке, который легко можно поменять на более подходящий и понятный (русский, украинский).
Также может выскочить окошко, в котором указано сменить первоначальный пароль, с помощью которого осуществляется вход в панель управления D-lіnk. Тогда введите какой-либо шифр, придуманный вами, и повторите такой же в следующей строке. И обязательно запомните, или лучше запишите, так как его нужно будет вводить при каждом входе в настройки маршрутизатора.
Рекомендую вам сразу же, перед тем как настраивать, скачать новое программное обеспечение на свой D-lіnk. Детально прочитать, как это сделать, можно в этой статье. Но можно осуществлять настройку далее и без прошивки, если допустим, вам будет тяжело это сделать.
После ввода пароля, мы непосредственно зашли в настройки, теперь можно настраивать роутер.
Поочередность процесса настройки интернета на роутере D-lіnk DІR-615
- Прежде всего, необходимо узнать какую технологию соединения использует ваш провайдер. Активный IP адрес, неподвижный, PPPoЕ (практикует Дом.рy, и прочие интернет — провайдеры), L2TP (применяет Билайн). В моих статьях я рассказывал, как узнать технологию соединения. Есть возможность узнать эту информацию на главном сайте провайдера, или даже позвонить в компанию.
При условии, что ваше Интернет-соединение выполнено по широко применяемой методике Динамический ІP, маршрутизатор должен распределять сигнал, как только будет подключен в него провод от компании, которая обеспечивает подачу интернета. Затем вам необходимо будет просто сделать настройки беспроводной сети (как это сделать рассмотрим далее). Если же у вас статический ІP адрес, тогда пройдется осуществлять настройку.
Затем вам необходимо будет просто сделать настройки беспроводной сети (как это сделать рассмотрим далее). Если же у вас статический ІP адрес, тогда пройдется осуществлять настройку.
- Найдите вкладку Начало— Click’n’Connect. Перепроверьте подсоединение интернет -кабеля и выберите Далее.
- Из появившегося перечня найдите нужное соединение. Если, допустим, ваше соединение PРPoE, и ещё Интернет-провайдер дает помимо этого ІP, тогда делаем выбор PPPоE+Статический ІP. При условии, что ІP адрес не предоставляется, то ставим значок выбора напротив PРРoE+Динамический IР. Аналогично поступаем, если соединение L2TР.
- Далее указываете данные IP адреса, в случае если вам его предоставляют (иначе этого окошка не будет). И нажимаете кнопку Далее.
- Дальше может открыться окошко «Адреса локальных ресурсов провайдера». Если вам не известно что это, или вы просто не желаете вносить дополнительные адреса, то нажимайте Далее. Выскочит окошко с запросом имени соединения и пользователя, и ввода и подтверждения пароля. Эти данные дает ваш интернет-провайдер. Для того, чтоб внести больше настроек, зайдите во вкладку Подробно
 Выскочит окошко с запросом имени соединения и пользователя, и ввода и подтверждения пароля. Эти данные дает ваш интернет-провайдер. Для того, чтоб внести больше настроек, зайдите во вкладку Подробно
Выскочит окошко с запросом имени соединения и пользователя, и ввода и подтверждения пароля. Эти данные дает ваш интернет-провайдер. Для того, чтоб внести больше настроек, зайдите во вкладку ПодробноЗатем будет осуществляться обследование интернет — соединения и реальность подключения отбора Яндекс. Но это уже если захотите. Все равно данные настройки можно поменять.
Рассматривались настройки на примере PPРoE для роутера D-link DIR-615. Ваши настройки могут быть другими.
Если вы настроили точку доступа, а в итоге интернета нет, высвечивается «без доступа к интернету», либо нет доступа к страничкам, тогда эта проблема связана с настройками от компании-провайдера. Перепроверьте, может неверно указали вид соединения, либо какие-нибудь другие данные.
Стало быть, с соединением PPPoE, PРTP, L2TР и Динамическим IP сложнее, чем методом Статического ІР соединения.
Очень важно! При условии, что ранее вы выходили в интернет с помощью высокоскоростного обмена данными, то сейчас вам, по сути, в нем нет необходимости. Такое интернет — соединение будет осуществлять ваш маршрутизатор и только распределять его по проводу и беспроводной сети.
Такое интернет — соединение будет осуществлять ваш маршрутизатор и только распределять его по проводу и беспроводной сети.
Поменять настройки от провайдера используя тот же Cliсk’n’Connect, либо перейдя на Сеть —WAN, при этом осуществив выбор и изменение требуемого соединения.
Рекомендуется сделанные настройки сохранить
При условии, что все в порядке, и интернет-соединение через маршрутизатор доступен, тогда переходим к установке параметров беспроводной сети.
Наглядный пример настройки Wi-Fi и изменение парольной комбинации на D-lіnk DІR-615
Теперь нам потребуется просто поменять имя беспроводной сети, и придумать другой секретный код для защищенности Wі-Fі соединения.
Станьте на Wі-Fі — Основные настройки. Тут можно поменять имя нашего беспроводного соединения. В строке SSID введите наименование сети – интернет, и выберите Применить.
Далее открываем меню Wi-Fi — Настройки безопасности, и в строке «Ключ шифрования PSK» вводим код, его далее будете каждый раз применять для подсоединения к Wі-Fі сети. Секретный пароль должен содержать не менее 8 знаков. Запомните, или где-то напишите его, чтоб потом не забыть
Секретный пароль должен содержать не менее 8 знаков. Запомните, или где-то напишите его, чтоб потом не забыть
Сделанные установки параметров необходимо сохранить. Система — Сохранить. Это может быть заключительный этап настраивания роутера D-link DІR-615. Если никакие настройки
осуществлять больше не будете, то сделайте его перезагрузку. Система — Перезагрузить.
Вот теперь Wі-Fі сеть настроена. Кроме этого может вам понадобиться посмотреть более подробную статью по настройке Wi-Fi.
Есть возможность также поменять админпароль, применение которого нужно для входа в настройки маршрутизатора. Для этого необходимо воспользоваться вкладкой Система — Пароль администратора.
Введите придуманный код дважды и выберите кнопку Применить. Проделанные действия обязательно сохраните.
Запомните либо сделайте запись секретного кода, чтоб не пришлось опять сбрасывать все настройки, так как без пароля вход в панель управления роутера будет недоступен.
Дипломированный специалист по безопасности компьютерных сетей. Навыки маршрутизации, создание сложных схем покрытия сетью, в том числе бесшовный Wi-Fi.
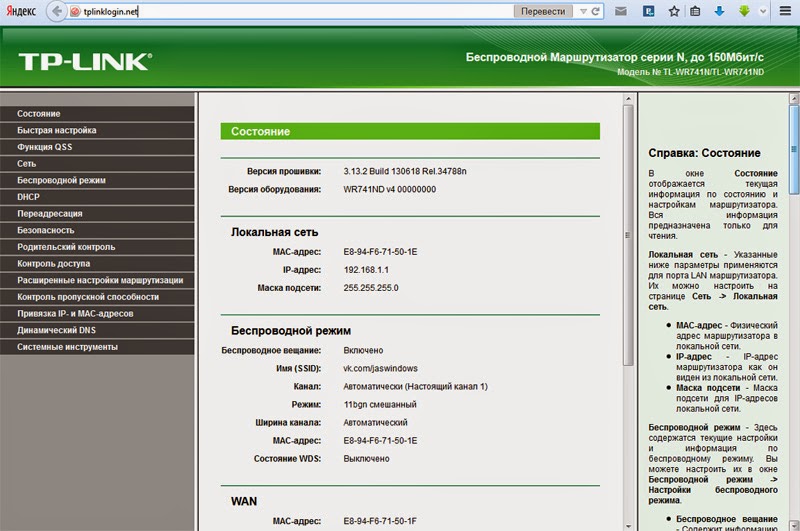
Нет подключения и доступа на 192.168.1.1 и 192.168.0.1. Нет соединения с роутером
Как я заметил по комментариям, при попытке открыть настройки роутера, или модема по адресу 192.168.1.1 или 192.168.0.1 (возможно, у вас другой адрес), пользователи чаще всего сталкиваются с такими ошибками: «Нет подключения к интернету», «Нет доступа к сети», «Нет соединения с роутером» и т. д. Эти ошибки появляются в браузере, когда мы в адресной строке набираем адрес роутера и переходим по нему. Нужно заметить, что это не обязательно должен быть IP-адрес. Сейчас большинство производителей указывают на корпусе роутера адреса типа tplinkwifi.net, tendawifi.com, my.keenetic.net и т. д. И когда мы набираем этот адрес в браузере, так же можно столкнутся с ошибкой, что отсутствует подключение к интернету, или нет доступа к сети. И в настройки маршрутизатора, конечно же, зайти не получается.
И в настройки маршрутизатора, конечно же, зайти не получается.
Я сам не раз сталкивался с такой проблемой. Выглядит она примерно вот так: открываем браузер, набираем адрес маршрутизатора (как правило это 192.168.1.1 или 192.168.0.1), переходим и видим сообщение, что нет подключения к интернету, не удается отобразить страницу, получить доступ к сайту, страница недоступна, или не найдена. Само сообщение может быть другим, в зависимости от браузера, настроек и вашего оборудования.
Или так:
Напомню, что ошибка может быть другой. Главная проблема – не открывается страница с настройками маршрутизатора
Рассмотрим два отдельных случая:
- Когда ошибка в браузере «говорит» об отсутствии подключения к интернету, или сети.
- Когда появляется ошибка, что невозможно открыть сайт, отобразить страницу 192.168.1.1 (или другой адрес), сайт недоступен, или что-то в этом роде.
Смотрите внимательно и все проверяйте.
Как открыть 192.
 168.1.1 и 192.168.0.1, если нет подключения к интернету?
168.1.1 и 192.168.0.1, если нет подключения к интернету?Об этом я писал в статье: как настроить Wi-Fi роутер (зайти в настройки) без интернета. Рассматривайте эти решения в том случае, если у вас появляется ошибка именно об отсутствии подключения к интернету.
Важно! Уже не раз об этом писал, но все же повторюсь. Для того, чтобы открыть страницу с настройками роутера, или модема (так званый web-интерфейс), доступ к интернету не нужен. Все что необходимо, это чтобы ваш компьютер, ноутбук, или мобильное устройство было подключено к роутеру. По сетевому кабелю, или по Wi-Fi сети.
Поэтому, если пытаетесь открыть настройки роутера и видите ошибку, что нет доступа к интернету, то первым делом убедитесь, подключено ли ваше устройство к самому роутеру.
Если у вас ПК, или ноутбук, то статус подключения должен быть таким (в зависимости от соединения с роутером):
Если у вас такой же статус подключения, то значит все в порядке, и страница с настройками роутера должна открываться.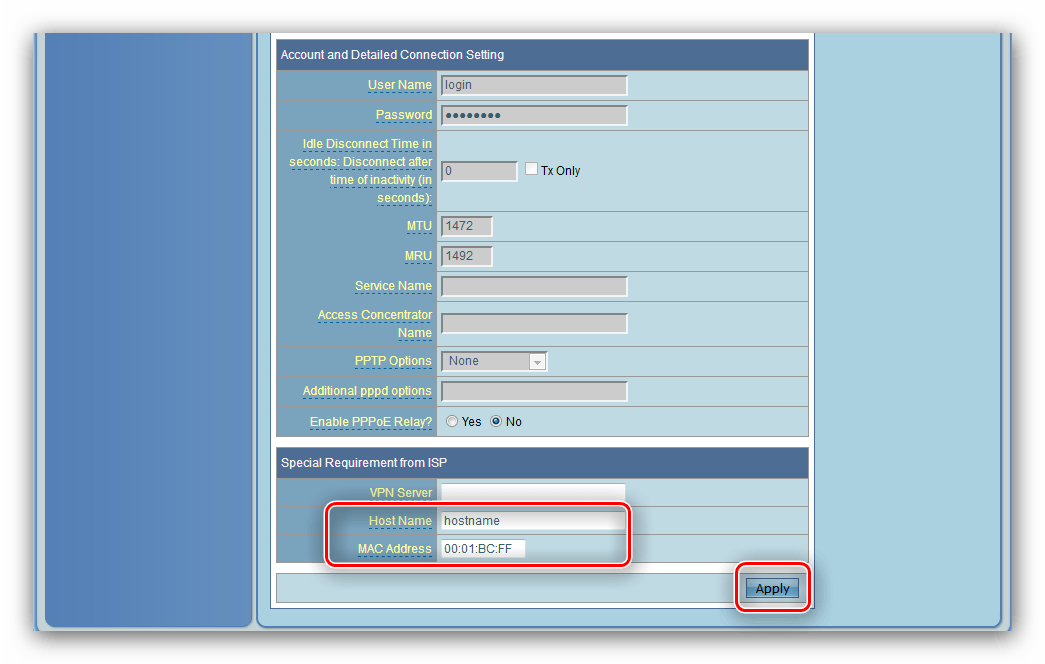 Если же там красный крестик, или звездочка возле Wi-Fi сети, то нужно проверить подключение. Лучше всего, конечно, подключится к маршрутизатору по кабелю. Примерно во так:
Если же там красный крестик, или звездочка возле Wi-Fi сети, то нужно проверить подключение. Лучше всего, конечно, подключится к маршрутизатору по кабелю. Примерно во так:
Или же по Wi-Fi сети. Если сеть защищена, то заводской пароль (PIN) указан на наклейке, на корпусе маршрутизатора.
При возможности попробуйте подключится к маршрутизатору с другого устройства.
Если страница по адрес 192.168.1.1 или 192.168.0.1 недоступна
В этом случае, в браузере будет сообщение, что страница, или сайт роутера недоступен. Примерно вот так:
Снова же, сама ошибка может быть другая, если у вас браузер другой.
Важно, чтобы компьютер был подключен только к роутеру, в настройки которого нам нужно зайти. Если, например, подключение по кабелю, то Wi-Fi нужно отключить (он он есть на вашем устройстве). И наоборот.
Вариантов решения, в случае появления такой ошибки будет больше.
Решение #1: проверяем адрес роутера
Необходимо убедится, что мы пытаемся открыть настройки роутера по правильному адресу. В большинстве случаев, заводской адрес для доступа к панели управления указан на самом роутере. Там скорее всего будет указан IP-адрес 192.168.1.1, 192.168.0.1, или адрес из букв. Например, tplinkwifi.net. Выглядит это следующим образом:
В большинстве случаев, заводской адрес для доступа к панели управления указан на самом роутере. Там скорее всего будет указан IP-адрес 192.168.1.1, 192.168.0.1, или адрес из букв. Например, tplinkwifi.net. Выглядит это следующим образом:
Более подробно на эту тему я писал в статье: как узнать IP-адрес роутера.
Так же вам могут пригодится следующие статьи:
Иногда бывает, что мастера во время настройки изменяют IP-адрес роутера. В таком случае, попробуйте открыть проводник (Мой компьютер) и на вкладке сеть нажать правой кнопкой мыши на свой роутер. В меню выбрать «Просмотр веб-страницы устройства».
Автоматически должен открыться браузер со страницей роутера. С определением адреса мы разобрались. Если настройки так и не удалось открыть, то попробуйте другие решения.
Решение #2: проверяем настройки IP
По умолчанию, практически каждый маршрутизатор выдает IP адрес автоматически. В нем работает DHCP-сервер. Поэтому, важно, чтобы в свойствах вашего подключения были выставлены настройки на автоматическое получение IP-адреса.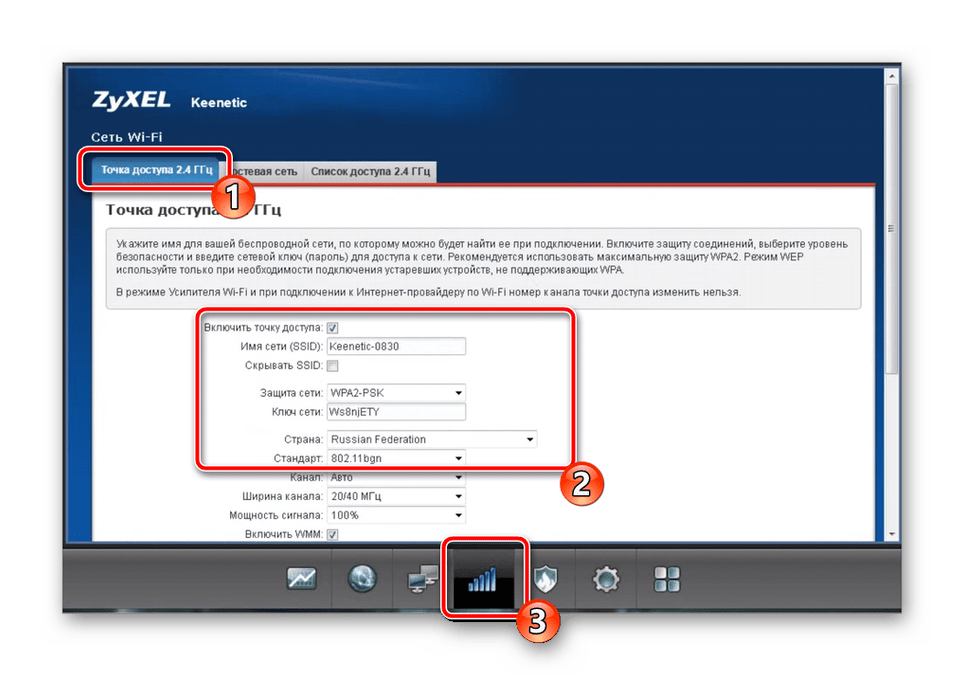
Зайдите в «Сетевые подключения». Можно нажать Win + R и выполнить команду ncpa.cpl
Дальше, в зависимости от того, по кабелю, или по Wi-Fi у вас подключен маршрутизатор, нажимаем правой кнопкой мыши на «Подключение по локальной сети» (в Windows 10 – Ethernet), или «Беспроводная сеть» и выбираем «Свойства». Например, у меня подключение по Wi-Fi.
И дальше выставляем автоматическое получение адресов.
После этого пробуем открыть настройки роутера. Можно перезагрузить компьютер и попробовать еще раз.
Или просто сделайте сброс сетевых настроек.
Решение #3: правильно вводим адрес для доступа к роутеру
Дело в том, что адрес по которому можно получить доступ к панели управления роутером нужно вводить в адресной строке браузера. Сейчас во многих браузерах адресная строка и строка поиска поиска – это одна и та же строка. И мы чаще всего набираем адрес без http://. Из-за этого, у многих вместо страницы роутера открывается Яндекс, Google, или другая пиковая система.
Поэтому, если не удается получить доступ к странице с настройками роутера, в первую очередь попробуйте открыть ее в другом браузере. Если, например, в Опере не получается, то заходим через Хром. А еще лучше, через Internet Explorer, или Microsoft Edge в Windows 10.
Напомню, что адрес маршрутизатора вводим в адресной строке.
Или попробуйте прописать адрес с http://. Например: http://192.168.0.1, http://192.168.1.1, http://tplinkwifi.net.
Все должно получится.
Если у вас по прежнему нет соединения с роутером, и при переходе по адресу роутера появляется ошибка, что страница недоступна, или нет подключения к интернету, то опишите свою проблему в комментариях ниже. Обязательно пишите какой у вас роутер и модель. Ну и перед этим попробуйте советы, о которых я писал выше.
Ошибка подключения к Интернету Ростелеком, Дом.ру, Билайн, ТТК
Что делать, если при попытке соединения с провайдером, будь то Ростелеком, Дом. ру, ТТК, Билайн или иной оператор, возникла ошибка подключения к интернету?! Начните с того, что запомните ее код. Это обычно трехзначное число. Логически ошибки соединения сгруппированы следующим образом:
ру, ТТК, Билайн или иной оператор, возникла ошибка подключения к интернету?! Начните с того, что запомните ее код. Это обычно трехзначное число. Логически ошибки соединения сгруппированы следующим образом:
код 6xx — ошибки, возникающие в основном из-за некорректных действий пользователя: неправильный ввод логина, пароля, неверный выбор используемого протокола связи и т.п. Для их решения достаточно, обычно, проверить правильность создания подключения и используемых в нём реквизитов. Хотя тут есть исключения — например, ошибка 651.
код 7xx — ошибки, связанные с настройками подключения к Интернету.
код 8xx — эти ошибки обычно связаны с проблемами в работе локальной сети или сетевого оборудования. Как правило, при их появлении, необходимо связаться с технической поддержкой своего провайдера.
Ниже приведены расшифровки самых частых ошибок подключения к Интернет:
Ошибки 600, 601, 603, 606, 607, 610, 613, 614, 616, 618, 632, 635, 637, 638, 645
Как правило, возникают при сбое службы Телефонии Windows 7. Начните с простой перезагрузки компьютера или ноутбука. Проблема не решилась? Пересоздайте соединение. Проверьте, не блокируется ли оно антивирусом. Так же, настоятельно рекомендую проверить системы на наличие вирусов.
Начните с простой перезагрузки компьютера или ноутбука. Проблема не решилась? Пересоздайте соединение. Проверьте, не блокируется ли оно антивирусом. Так же, настоятельно рекомендую проверить системы на наличие вирусов.
Ошибки 604, 605, 608, 609, 615, 620
«Файл телефонной книги подсистемы удаленного доступа Windows и текущая конфигурация Удаленного Доступа к Сети несовместимы друг с другом»
Появление данных проблем связано со сбоем сервиса удалённого доступа. Перезагрузите компьютер. Если не помогло — пересоздайте высокоскоростное подключение к Интернет.
Ошибки 611, 612
«Внутренняя конфигурация сети Windows некорректно настроена»
Иногда данная проблема может появиться из-за сбоя в работе операционной системы Виндовс из-за нехватки ресурсов (чаще всего — оперативной памяти) и помогает перезагрузка. Но чаще всего, её появление связано с проблемами на стороне Вашего оператора связи. Обратитесь в службу Технической Поддержи Провайдера (Ростелеком, Дом. ру, Билайн, ТТК).
ру, Билайн, ТТК).
Ошибка 617
«Windows находится в процессе подключения к Интернету, либо произошла внутренняя ошибка Windows»
Подождите несколько минут. Если подключение не установилось, и при повторном подключении ошибка повторяется, то перезагрузите компьютер.
Ошибка 619
«Не удаётся подключиться к удалённому порту, поэтому порт подключения занят»
Если у Вас VPN-подключение (например, Билайн), то ошибка появляется из-за неправильной настройки подключения. Идём в его свойства на вкладку «Безопасность». В большинстве случаев там должно быть выбрано значение «Обычные (рекомендуемые параметры)».
Так же, попробуйте снять галку «Требуется шифрование данных (иначе отключаться)», если она установлена.
В случае, если у Вас PPPoE подключение (Ростелеком, Дом.ру), то скорее всего ошибка 619 появилась из-за того, что Вас на некоторое время заблокировал сервис авторизации провайдера. Обычно такое происходит после того, как несколько раз подряд Вас отбросило с ошибкой логин или пароля. Подождите минут 10-15. Если и после этого не удалось соединится — обратитесь в техническую поддержку оператора связи.
Подождите минут 10-15. Если и после этого не удалось соединится — обратитесь в техническую поддержку оператора связи.
Ошибка 624
«Проблема при подключении к VPN»
Возможны три варианта развития событий. Самый частый — это отсутствие файла RASPHONE.PBK в C:\Windows\System32/RAS или в папке Documents and Settings \<Имя_пользователя> \Application Data \Microsoft \Network \Connections \Pbk. Если такой файл существует, тогда попробуйте его переименовать в RASPHONE.BAK, перезагрузиться и ещё раз проверить работоспособность соединения. Иногда можно помочь запуск исполняемого файла rasphone.exe.
Второй — это установленный запрещён на доступ к папке Documents and Settings\<Имя_пользователя>\Application Data\Microsoft\Network\Connections\Pbk из-за чего не удается прочитать содержимое файла. Для решения попробуйте открыть доступ к этой директории.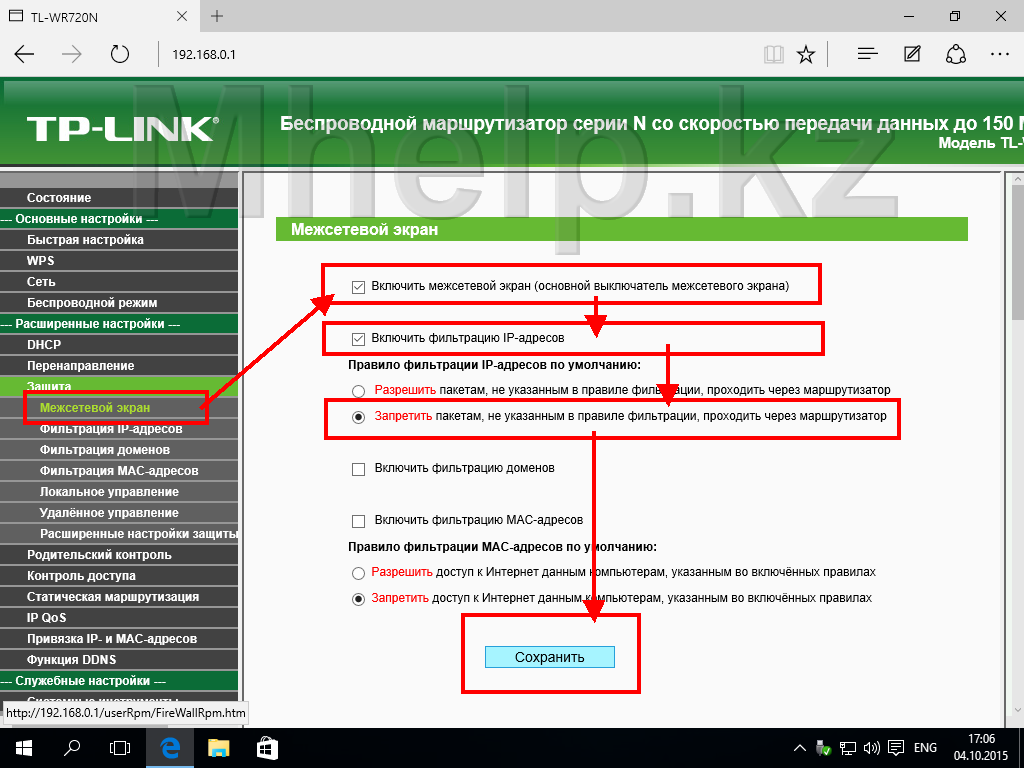 Так же стоит проверить, не установлена ли в свойствах файла Rasphone.pbk галочка «Только для чтения».
Так же стоит проверить, не установлена ли в свойствах файла Rasphone.pbk галочка «Только для чтения».
Третий вариант — стоит запрет на создание высокоскоростного подключения для пользователя. Чтобы снять его — зайдите в редактор локальных политик (нажимаем клавиши Win+R и введите команду gpedit.msc) и разрешите пользователям создавать новые подключения.
Ошибка 629
«Подключение было закрыто удаленным компьютером»
Очень частая ошибка у абонентов оператора Дом.ру. Основная причина — уже есть одно активное PPPoE-подключение и сервер провайдера просто отбрасывает дублирующее. Проверьте чтобы все подключения, кроме локальной сети, были отключены.
У некоторых операторов ошибка 629 может появиться при неправильном вводе логина или пароля.
Если устранить не получается — попробуйте перезагрузиться, затем удалить и заново создать PPPoE-соединение.
Ошибка 650
«Сервер удаленного доступа не отвечает»
Суть неисправности в том, что недоступен сервер удаленного доступа в сеть Интернет. Зачастую, причина на стороне провайдера и надо звонить в техподдержку. Но иногда connection error 650 в Windows 7 может появиться если отключено «Подключение по локальной сети», либо есть какие то проблемы с сетевой картой или её драйвером.В очень редких случаях ошибка связана с тем, что неправильно указан IP-адрес сервера в настройках подключения.
Зачастую, причина на стороне провайдера и надо звонить в техподдержку. Но иногда connection error 650 в Windows 7 может появиться если отключено «Подключение по локальной сети», либо есть какие то проблемы с сетевой картой или её драйвером.В очень редких случаях ошибка связана с тем, что неправильно указан IP-адрес сервера в настройках подключения.
Ошибка 651
«Модем или другое устройство сообщило об ошибке»(WAN Miniport PPPoE)
Причинами появления ошибки 651 могут быть следующие:
— Проблемы с настройкой модема. Зайдите в веб-интерфейс устройства (192.168.1.1 или 192.168.0.1) и проверьте правильность выставленных настроек.
— Сбой службы удаленного доступа или работы протокола RASPPPOE. Перезагрузите компьютер, пересоздайте высокоскоростное подключение.
— Подключение заблокировано Антивирусной программой. Такое иногда случается, когда установленный Файрвол или Брандмауэр блокирует сетевое соединение. Попробуйте деактивировть систему безопасности компьютера и проверьте работу соединения.
— Проблемы на линии и оборудовании провайдера. Обратитесь в техническую поддержку провайдера.
Ошибка 678
«Удаленный компьютер не отвечает»(WAN Miniport PPPoE)
Симптомы и способы лечения ошибки 678 полностью совпадает с вариантами решения ошибки 651. Фактически они представляют собой одно и тоже, просто в разных версиях ОС Windows одна и та же неисправность имеет разные индексы.
Ошибка 691
«Доступ запрещён, поскольку такие имя пользователя и пароль недопустимы в этом домене».
Самая часто встречающаяся ошибка подключения к Интернет. Она возникает в следующих случаях:
— Неправильный логин или пароль. Проверьте правильность ввода данных, попробуйте полностью их удалить и ввести заново.
— Нет денег на лицевом счёте
— Установлена административная блокировка в системе биллинга провайдера.
— Попытка повторного соединение. Вы уже подключены к Интернету
— Неправильно указан сервер VPN в настройках подключения.
Ошибка 718
«Удаленный компьютер не отвечает»
Проблема на стороне сервера авторизации или BRAS провайдера. Обратитесь в службу технической поддержки.
Ошибка 720
«Не удаётся подключиться к удалённому компьютеру. Возможно потребуется изменение сетевой настройки подключения»
Как правило, эта ошибка возникает когда протокол Интернета TCP/IP повредил вирус. Иногда помогает сброс конфигурации интерфейса Ай-Пи, введя в командной строке директиву:
netsh int ip reset
netsh winsock reset
Так же стоит попробовать сделать переустановку протокола TCP/IP, но чаще приходится переустанавливать Windows. Если Вы работает через ADSL-модем, то перенастройте его из режима «Мост»(Bridge) в режим «Маршрутизатора»(Router).
Ошибка 733
«Соединение с удалённым компьютером не может быть установлено» или «Один или несколько сетевых протоколов не были успешно подключены»
Для устранения неисправности, откройте свойства подключения и снимите галочки со всех компонентов, кроме пунктов «Протокол Интернета TCP/IP» или «Планировщик QOS». После этого переподключитесь.
Ошибка 734
«Протокол управления PPP-связью был прерван»
Если Вы пользуетесь мобильным Интернетом от Мегафон, МТС или Билайн и у Вас выскочила ошибка 734, то в первую очередь начните с того, что проверьте какой номер набора прописан в соединении. Если там прописан *99***1, то попробуйте заменить его на *99#. Так же стоит проверить строку инициализации своего 3G/4G-модема. Обычно используются такие параметры:
МТС:
AT+CGDCONT=1,»IP»,»INTERNET.mts.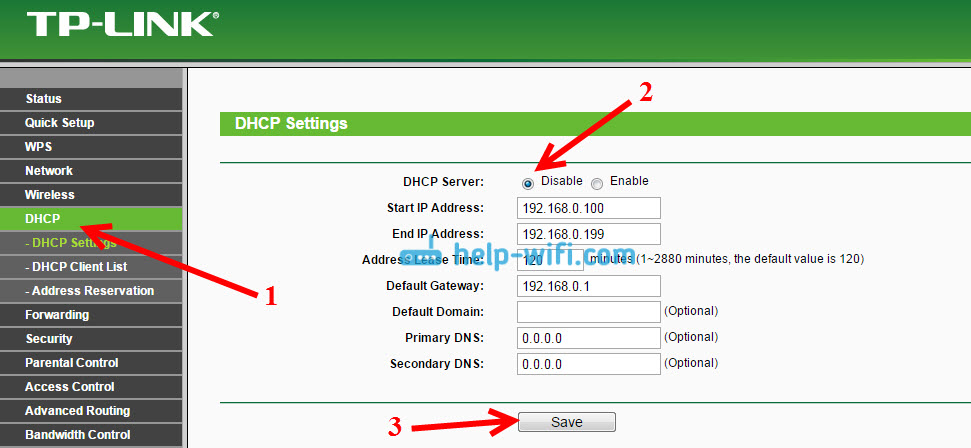 ru»
ru»
Билайн:
AT+CGDCONT=1,»IP»,»INTERNET.beeline.ru»
Мегафон:
AT+CGDCONT=1,»IP»,»INTERNET.kvk» или AT+CGDCONT=1,»IP»,»INTERNET»
Если ошибка соединения 734 появляется при VPN-подключении, то попробуйте в его свойствах зайти на вкладку «Безопасность» и снять галочку «Требуется шифрование данных». Для Windows 7 надо в списке «Шифрование данных» поставить значение «Не разрешено».
Ошибка 735
«Запрошенный адрес был отвергнут сервером»
Неправильная настройка VPN-соединения. Проверьте правильно ли Вы указали адрес сервера, с которым поднимаете ВПН-соединение. Если Ошибка 735 появилась на PPPoE соединении, это значит что Вы прописали в его параметрах неправильный IP-адрес. Это зачастую происходит из-за того, что Ай-Пи должен присваиваться динамически, а абонент указывает статический адрес, который станционное оборудование отвергает.
Ошибка 738
«Сервер не назначил адрес»
Практически у всех провайдеров эта ошибка означает то, что в пуле динамических адресов нет закончились свободные или, как вариант, накрылся Radius-сервер. В любом случае, при возникновении такой ситуации выход или ждать, пока само рассосется, либо обращаться в техническую службу.
В любом случае, при возникновении такой ситуации выход или ждать, пока само рассосется, либо обращаться в техническую службу.
Ошибка 769
«Указанное назначение недостижимо»
Обычно это сообщение возникает если Вы пытаетесь запустить PPP-соединение при выключенной сетевой карте (Ethernet или WiFi). Зайдите в Сетевые подключения Виндовс и проверьте чтобы было включено «Подключение по локальной сети». То же самое часто случается после переустановки операционной системы из-за того, что пользователь не установил драйвер на сетевую. Очень редко причиной является неисправность сетевой платы.
Ошибка 789
«Выбран неверный тип VPN соединения»
Зайдите в настройки VPN соединения и на вкладке «Сеть» из списка «Тип VPN» выберите «Автоматически». Попробуйте повторно подключиться.
Ошибки 741 — 743
«Неверно настроены параметры шифрования»
Зайдите в настройки VPN соединения, и во вкладке «Безопасность» отключите пункт «шифрование данных».
Ошибка 800 (VPN Билайн, Comfort, Уфанет)
«Не удалось создать VPN подключение»
Распространённая ситуация у операторов связи, которые используют протоколы ВПН-соединения PPTP и L2TP. Возможные причины появления ошибки VPN:
— Запрос соединения не доходит до сервера. Очень часто это возникает из-за проблем на коммутаторах или ином оборудовании провайдера, поэтому первым делом позвоните в службу поддержки. Иначе рискуете убить кучу времени впустую. Попробуйте проверить работоспособность сервера с помощью сервисной утилиты «Пинг».
Сделать это просто, достаточно всего лишь знать адрес vpn-сервера. Например, у Билайн это: tp.internet.beeline.ru.
Сделать надо вот что. Запустите командную строку Виндовс и впишите команду:
ping tp.internet.beeline.ru
Если в ответ на это Вы получите сообщение «Заданный узел недоступен» или «Превышен интервал ожидания дла запроса», то источник неисправности в 90% случаев на стороне провайдера (линия, коммутаторы, станционное оборудование).
Если приходит нормальный ответ от сервера, то в этом случае обычно причиной появления ошибки 800 vpn является неправильно настроенная безопасность. В свойствах подключения надо проверить, чтобы был снят флажок «Требуется шифрование данных».
— Попытку соединения блокирует файрвол или брандмауэр, установленный у Вас в системе Windows 7 или Виндовс 10. Попробуйте отключить полностью систему безопасности и проверить работу высокоскоростного ВПН-соединения.
— Вы пытаетесь запустить вторую копию соединения, которую автоматически отбрасывает сервер.
Ошибка 807
«Сетевое подключения компьютера к виртуальной частной сети прервано»
Обычно эта неисправность возникает из-за плохого качества линии или проблем с оборудованием доступа как на стороне абонента, так и на стороне провайдера.
Так же к причина её появления можно отнести неправильная работа Файрвола или брандмауэра, который периодически начинает блокировать сеть.
Так же стоит проверить правильный ли выставлен тип VPN в параметрах подключения. Попробуйте отключить протокол IPv6, оставив только IPv4.
Попробуйте отключить протокол IPv6, оставив только IPv4.
Ошибка 809
«Нельзя установить связь по сети между компьютером и VPN-сервером, поскольку удалённый сервер не отвечает»
Обычно возникает в двух случаях.
Первый — проблемы с сервером на стороне оператора связи.
Второй — блокировка ВПН-подключения системой безопасности Windows 10.
Ошибка 814
«Указанное назначение недостижимо»
Полный аналог ошибки 769, используемый в Windows Vista. В других версиях этот индекс не используется.
Ошибка 815
«Невозможно установить высокоскоростное сетевое подключение компьютера, так как удалённый сервер не отвечает»
Используемый в Windows Vista аналог ошибки 651 или 678. В других версиях этот индекс не встречается.
Ошибка 868
«Порт открыт. Удаленное соединение не удалось установить, поскольку не удалось разрешить имя доступа удалённого сервера»
Это ошибка появляется в Windows 7 и Windows 10. Самые явные причины:
Самые явные причины:
— неправильно указано имя VPN-сервера в свойствах высокоскоростного соединения.
— неверно указаны адреса DNS-серверов в свойствах Подключения по локальной сети.
— проблемы с DNS-клиентом Windows 7.
В первых двух вариантах данные надо уточнить в техподдержке. А вот в третьем обычно помогает только полная переустановка операционной системы.
Ошибка 1231
«Отсутствует транспорт для удаленного доступа»
Причины появления неисправности:
— Отключен протокол Интернета IPv4. Зайдите в сетевые подключения Windows и откройте свойства подключения по Локальной сети. Проверьте чтобы стояла галочка напротив протокола TCP/IPv4.
— Проблемы на стороне Интернет-провайдера. Лечится звонком в техническую поддержку.
— Проблемы с DHCP-клиентом Windows 10, в результате которой система не может получить IP-адрес. В этом случае стоит сделать откат системы к последней работоспособной точке восстановления Виндовс.
Вопрос ответ
Не удалось создать VPN-подключение. Сервер недоступен или параметры безопасности для данного подключения настроены неверно.
Сервер недоступен или параметры безопасности для данного подключения настроены неверно.
Возможные причины:
1. «Подключение по локальной сети» программно отключено;
2. Отошел или выдернут сетевой кабель из компьютера;
3. Нет сигнала между вашим компьютером и сервером провайдера;
4. Сбой на линии.
Совет:
1. В файерволе необходимо открыть TCP порт 1723 и IP протокол 47 (GRE), или, если того требуют настройки файервола, прописать адрес VPN-сервера nas.ivstar.net.
2. Проверить есть ли физическая связь (горят ли лампочки сетевой карты на задней панели Вашего компьютера), включен ли сетевой кабель в разъем на сетевой карте и в розетке (при ее наличии). Затем проверить, включено ли соединение по локальной сети. Для этого нажмите кнопку «Пуск», затем «Панель управления», затем «Сетевые подключения». В появившемся окне найдите «Подключение по локальной сети» и включите его, если оно было выключено. Проверить настройки протокола TCP/IP — Нажмите кнопку «Пуск»->«Выполнить». В строке введите команду «cmd», в открывшемся DOS окне введите команду «ipconfig» – должно выдать Ваш IP адрес, маску подсети и основной шлюз, если данной информации нет, это означает что локальная сеть выключена или нет физического соединения.
В строке введите команду «cmd», в открывшемся DOS окне введите команду «ipconfig» – должно выдать Ваш IP адрес, маску подсети и основной шлюз, если данной информации нет, это означает что локальная сеть выключена или нет физического соединения.
3. Убедитесь, что в настройках VPN подключения (VPN-Свойства->Общие->Имя компьютера или IP-адрес назначения) верно указан адрес VPN-сервера.
4. Проверить прохождение сигнала командой ping до сервера VPN.
Нажмите кнопку «Пуск»->«Выполнить». В строке введите команду «cmd», в открывшемся DOS окне введите команду: ping 10.11.0.5 где, в данном случае, 10.11.0.5 — сервер VPN. Свой сервер доступа и адрес шлюза Вы можете узнать в договоре или используя команду «ipconfig» (смотреть пункт 2).
Если в открывшемся DOS-окне Вы увидите что-то вроде «Заданный узел недоступен» или «Превышен интервал ожидания для запроса», то возможно проблемы у Вас на компьютере, либо на линии. Если пойдет ответ от узла с указанной скоростью (обычно это происходит быстро), то скорее всего проблема в Вашем компьютере. В любом случае, проверьте пункт 2.
В любом случае, проверьте пункт 2.
PING — сетевая диагностика на IP-уровне
Команда PING это, пожалуй, самая используемая сетевая утилита командной строки. PING присутствует во всех версиях всех операционных систем с поддержкой сети и является простым и удобным средством опроса узла по имени или его IP-адресу.Для обмена служебной и диагностической информацией в сети используется специальный протокол управляющих сообщений ICMP (Internet Control Message Protocol). Команда ping позволяет выполнить отправку управляющего сообщения типа Echo Request (тип равен 8 и указывается в заголовке ICMP-сообщения) адресуемому узлу и интерпретировать полученный от него ответ в удобном для анализа виде. В поле данных отправляемого icmp-пакета обычно содержатся символы английского алфавита. В ответ на такой запрос, опрашиваемый узел дожжен отправить icmp-пакет с теми же данными, которые были приняты, и типом сообщения Echo Reply (код типа в ICMP-заголовке равен 0) . Если при обмене icmp-сообщениями возникает какая-либо проблема, то утилита ping выведет информацию для ее диагностики.
Если при обмене icmp-сообщениями возникает какая-либо проблема, то утилита ping выведет информацию для ее диагностики.
Формат командной строки:
ping [-t] [-a] [-n число] [-l размер] [-f] [-i TTL] [-v TOS] [-r число] [-s число] [[-j списокУзлов] | [-k списокУзлов]] [-w таймаут] конечноеИмя
Параметры:
-t — Непрерывная отправка пакетов.
Для завершения и вывода статистики используются комбинации клавиш
Ctrl + Break (вывод статистики и продолжение), и Ctrl + C (вывод статистики и завершение).
-a — Определение адресов по именам узлов.
-n число — Число отправляемых эхо-запросов.
-l размер — Размер поля данных в байтах отправляемого запроса.
-f — Установка флага, запрещающего фрагментацию пакета.
-i TTL — Задание срока жизни пакета (поле «Time To Live»).
-v TOS — Задание типа службы (поле «Type Of Service»).
-r число — Запись маршрута для указанного числа переходов.
-s число — Штамп времени для указанного числа переходов.
-j списокУзлов — Свободный выбор маршрута по списку узлов.
-k списокУзлов — Жесткий выбор маршрута по списку узлов.
-w таймаут — Максимальное время ожидания каждого ответа в миллисекундах.
Примеры использования:
ping google.com — эхо-запрос к узлу с именем google.com с параметрами по умолчанию — количество пакетов равно 4, длина массива данных = 32 байта.
ping -6 ya.ru — пинг узла ya.ru с использованием протокола Ipv6
ping -a 192.168.1.50 — выполнить пинг с определением имени конесного узла по его адресу.
ping -s 192.168.0.1 computer — пинг узла computer от источника 192.168.0.1. Используется когда на компьютере имеется несколько сетевых интерфейсов.
ping w 5000 ya.ru — пинг с таймаутом ожидания равным 5 секунд ( по умолчанию — 4 сек).
ping -n 5000 -l 1000 ab57.ru — опрос узла ab57.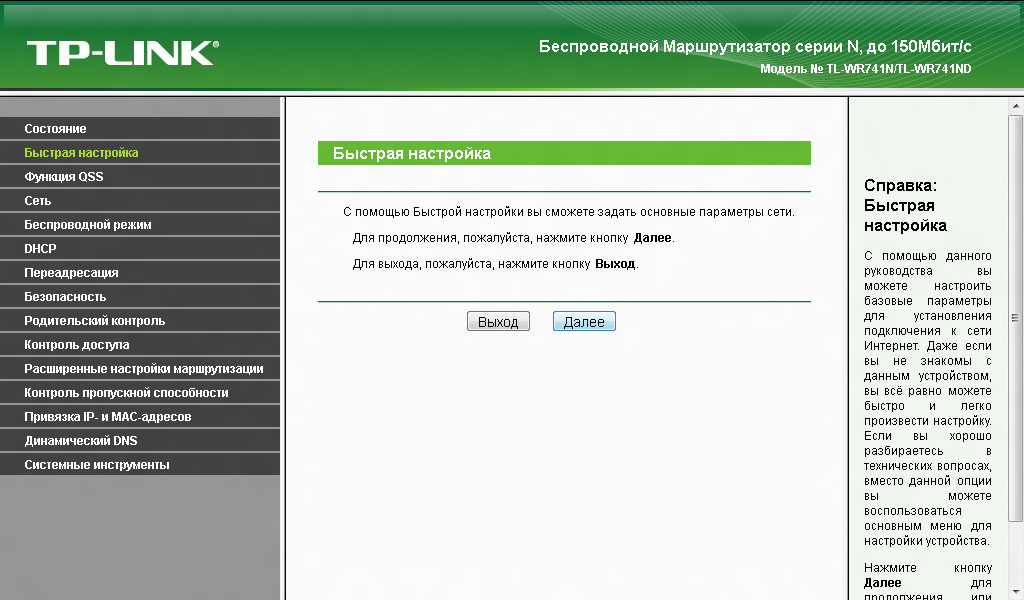 ru 5000 раз, пакетами с данными длиной в 1000байт. Допустимая максимальная длина данных — 65500.
ru 5000 раз, пакетами с данными длиной в 1000байт. Допустимая максимальная длина данных — 65500.
ping -n 1 -l 3000 -f ya.ru — пинг с запретом фрагментации пакета.
ping -n 1-r 3 ya.ru — отправить 1 эхо-запрос на узел ya.ru с отображением первых 3-х переходов по маршруту.
ping -i 5 ya.ru — пинг с указанием времени жизни TTL=5. Если для достижения конечного узла потребуется большее количество переходов по маршруту, то маршрутизатор, прервавший доставку ответит сообщением ”Превышен срок жизни (TTL) при передаче пакета.”
Обобщенная схема соединения компьютера (планшета, ноутбука домашней сети) с удаленным конечным узлом можно представить следующим образом:
В качестве домашней сети используется наиболее распространенная сеть с IP-адресами 192.168.1.0 /255.255.255.0 . Речь идет об IPv4 – IP протоколе версии 4, где для адресации используется 4 байта. IP- адреса принято представлять в виде десятичных значений байтов, разделяемых точками. Каждое устройство в сети должно иметь свой уникальный адрес. Кроме адреса, в сетевых настройках используется маска сети ( маска подсети). Маска имеет такой же формат представления, как и адрес. Комбинация адреса и маски определяет диапазон адресов, которые принадлежат локальной сети — 192.168.1.0-192.168.1.255. Первый и последний адреса диапазона не назначаются отдельным сетевым устройствам, поскольку используются в качестве адреса сети и широковещательного адреса. Обычно адрес роутера делают равным 192.168.1.1 или 192.168.1.254. Это не является обязательным стандартом, но на практике используется довольно часто. Единичные биты маски определяют постоянную часть IP-адреса сети, а нулевые — выделяемые отдельным узлам. Значение 255 — это байт с установленными в единицу битами. Маска сети служит средством определения диапазона IP-адресов, принадлежащих локальной сети. Устройства с такими адресами достижимы локально, без использования маршрутизации.
IP- адреса принято представлять в виде десятичных значений байтов, разделяемых точками. Каждое устройство в сети должно иметь свой уникальный адрес. Кроме адреса, в сетевых настройках используется маска сети ( маска подсети). Маска имеет такой же формат представления, как и адрес. Комбинация адреса и маски определяет диапазон адресов, которые принадлежат локальной сети — 192.168.1.0-192.168.1.255. Первый и последний адреса диапазона не назначаются отдельным сетевым устройствам, поскольку используются в качестве адреса сети и широковещательного адреса. Обычно адрес роутера делают равным 192.168.1.1 или 192.168.1.254. Это не является обязательным стандартом, но на практике используется довольно часто. Единичные биты маски определяют постоянную часть IP-адреса сети, а нулевые — выделяемые отдельным узлам. Значение 255 — это байт с установленными в единицу битами. Маска сети служит средством определения диапазона IP-адресов, принадлежащих локальной сети. Устройства с такими адресами достижимы локально, без использования маршрутизации. Маршрутизация — это способ обмена данными с сетевыми устройствами не принадлежащими к данной локальной сети через специальное устройство — маршрутизатор ( router, роутер ). Маршрутизаторы представляют собой специализированные компьютеры с несколькими сетевыми интерфейсами и специализированным программным обеспечением обеспечивающим пересылку IP-пакетов между отправителем и получателем, находящимися в разных сетях. В такой пересылке могут участвовать несколько маршрутизаторов, в зависимости от сложности маршрута. Домашний роутер — простейшая разновидность маршрутизатора, который обеспечивает пересылку пакетов, адресованных во внешние сети следующему по маршруту маршрутизатору в сети провайдера. Следующий маршрутизатор проверяет достижимость адреса конечного узла локально, и либо пересылает ему данные, либо передает их следующему маршрутизатору в соответствии с таблицей маршрутов. Так происходит до тех пор, пока данные не достигнут получателя или закончится время жизни пакета.
Маршрутизация — это способ обмена данными с сетевыми устройствами не принадлежащими к данной локальной сети через специальное устройство — маршрутизатор ( router, роутер ). Маршрутизаторы представляют собой специализированные компьютеры с несколькими сетевыми интерфейсами и специализированным программным обеспечением обеспечивающим пересылку IP-пакетов между отправителем и получателем, находящимися в разных сетях. В такой пересылке могут участвовать несколько маршрутизаторов, в зависимости от сложности маршрута. Домашний роутер — простейшая разновидность маршрутизатора, который обеспечивает пересылку пакетов, адресованных во внешние сети следующему по маршруту маршрутизатору в сети провайдера. Следующий маршрутизатор проверяет достижимость адреса конечного узла локально, и либо пересылает ему данные, либо передает их следующему маршрутизатору в соответствии с таблицей маршрутов. Так происходит до тех пор, пока данные не достигнут получателя или закончится время жизни пакета.
Команда PING можно использовать для диагностики отдельных узлов:
ping 127. 0.0.1 — это пинг петлевого интерфейса. Должен выполняться без ошибок, если установлены и находятся в работоспособном состоянии сетевые программные компоненты.
0.0.1 — это пинг петлевого интерфейса. Должен выполняться без ошибок, если установлены и находятся в работоспособном состоянии сетевые программные компоненты.
ping свой IP или имя — пинг на собственный адрес или имя. Должен завершаться без ошибок, если установлены все программные средства протокола IP и исправен сетевой адаптер.
ping IP-адрес роутера — должен выполняться, если исправна сетевая карта компьютера, исправен кабель или беспроводное соединение, используемые для подключения к роутеру и исправен сам роутер. Кроме того, настройки IP должны быть такими, чтобы адрес компьютера и роутера принадлежали одной подсети. Обычно это так, когда сетевые настройки выполняются автоматически средствами DHCP-сервера маршрутизатора.
ping yandex.ru — выполнить опрос узла с именем yandex.ru. Если опрос завершается с ошибкой, то причиной может быть не только отсутствие связи с маршрутизатором провайдера, но и невозможность определения адреса узла yandex. ru из-за проблем с программными средствами разрешения имен.
ru из-за проблем с программными средствами разрешения имен.
ping 8.8.8.8 — выполнить опрос узла с IP-адресом 8.8.8.8 . Если опрос по адресу выполняется без ошибок, а опрос по имени завершается сообщением о неизвестном узле, то проблема в разрешении имен. Причиной может быть неработоспособность DNS-сервера провайдера. В этом случае, можно попробовать сменить его в настройках сетевого соединения на публичные DNS сервера Google с адресами 8.8.4.4 и 8.8.8.8. Также, проблема может быть вызвана плохим качеством связи с провайдером, что сопровождается слишком большим временем отклика и пропаданием пакетов.
ping -t yandex.ru — выполнять ping до нажатия комбинации CTRL+C, При нажатии CTRL+Break — выдается статистика и опрос узла продолжается.
ping -n 1000 -l 500 192.168.1.1 — выполнить ping 1000 раз с использованием сообщений, длиной 500 байт. Пинг пакетами стандартной длины в 32 байта может выполняться без ошибок, а на длинных — с ошибками, что характерно для беспроводных соединения при низком уровне сигнала в условиях интенсивных помех.
ping -n 1 -r 9 -w 1000 yandex.ru — выполнить ping 1 раз (ключ -n 1), выдавать маршрут для первых 9 переходов (-r 9), ожидать ответ 1 секунду (1000мсек)
В результате выполнения данной команды отображается и трассировка маршрута:
Обмен пакетами с yandex.ru [87.250.251.11] с 32 байтами данных:
Ответ от 87.250.251.11: число байт=32 время=36мс TTL=54
Маршрут: 81.56.118.62 ->
81.56.112.1 ->
10.109.11.9 ->
10.109.11.10 ->
195.34.59.105 ->
195.34.52.213 ->
195.34.49.121 ->
195.34.52.213 ->
87.250.239.23
Статистика Ping для 87.250.251.11:
Пакетов: отправлено = 1, получено = 1, потеряно = 0
(0% потерь)
Приблизительное время приема-передачи в мс:
Минимальное = 36мсек, Максимальное = 36 мсек, Среднее = 36 мсек
В данном примере, между отправителе и получателем пакетов выстраивается цепочка из 9 маршрутизаторов. Нужно учитывать тот факт, что в версии утилиты ping.exe для Windows, число переходов может принимать значение от 1 до 9. В случаях, когда этого значения недостаточно, используется команда tracert
Нужно учитывать тот факт, что в версии утилиты ping.exe для Windows, число переходов может принимать значение от 1 до 9. В случаях, когда этого значения недостаточно, используется команда tracert
Отсутствие эхо-ответа не всегда является признаком неисправности, поскольку иногда по соображениям безопасности, некоторые узлы настраиваются на игнорирование эхо-запросов, посылаемых PING. Примером может служить узел microsoft.com и некоторые маршрутизаторы в сетях небольших провайдеров.
Использование PING в командных файлах.
Нередко, команда PING используется для организации задержек в командных файлах. Выполняется пингование петлевого интерфейса с указанием нужного значения счетчика пакетов, задаваемого параметром -n. Посылка эхо-запросов выполняется с интервалом в 1 секунду, а ответ на петлевом интерфейсе приходит практически мгновенно, поэтому задержка будет приблизительно равна счетчику минус единица:
ping -n 11 127. 0.0.1 — задержка в 10 секунд.
0.0.1 — задержка в 10 секунд.
Команда PING используется в командных файлах для определения доступности IP-адресов. Поскольку, результат опроса никак не отражается в переменной ERRORLEVEL , то вместо ее анализа используется поиск определенных признаков в данных стандартного вывода PING. Если внимательно посмотреть на сообщения программы ping.exe при опросе доступного и недоступного узла, то можно заметить, что они значительно отличаются
ping 456.0.0.1 — ping на несуществующий адрес
Ответ на такую команду может отличаться от конкретной версии утилиты, и может быть приблизительно таким
При проверке связи не удалось обнаружить узел 456.0.0.1. Проверьте имя узла и повторите попытку.
ping yandex.ru — ping на адрес узла yandex.ru
Ответ на ping доступного узла:
Обмен пакетами с yandex.ru [87.250.250.11] по 32 байт:
Ответ от 87.250.250.11: число байт=32 время=10мс TTL=55
Таким образом, для решения задачи определения доступности узла в командном файле, достаточно проанализировать характерные слова в выводе ping. exe при успешном ответе. Наиболее характерно в данном случае наличие слова TTL. Оно никогда не встречается при возникновении ошибки и состоит всего лишь из символов английского алфавита.
Для поиска «TTL» в результатах ping.exe удобнее всего объединить ее выполнение в цепочку с командой поиска строки символов FIND.EXE (конвейер ping и find). Если текст найден командой FIND, то значение переменной ERRORLEVEL будет равно 0
exe при успешном ответе. Наиболее характерно в данном случае наличие слова TTL. Оно никогда не встречается при возникновении ошибки и состоит всего лишь из символов английского алфавита.
Для поиска «TTL» в результатах ping.exe удобнее всего объединить ее выполнение в цепочку с командой поиска строки символов FIND.EXE (конвейер ping и find). Если текст найден командой FIND, то значение переменной ERRORLEVEL будет равно 0
ping -n 1 COMPUTER | find /I «TTL» > nul
if %ERRORLEVEL%==0 goto LIVE
ECHO computer недоступен
подпрограмма обработки недоступного состояния
…
Exit
:LIVE — начало подпрограмм
ы обработки состояния доступности узла
…
…
В более простом варианте можно использовать команды:
PING yandex.ru |find «TTL=» && ECHO Yandex pingable — команда ECHO выполняется, если значение ERRORLEVEL, установленное FIND равно 0, т.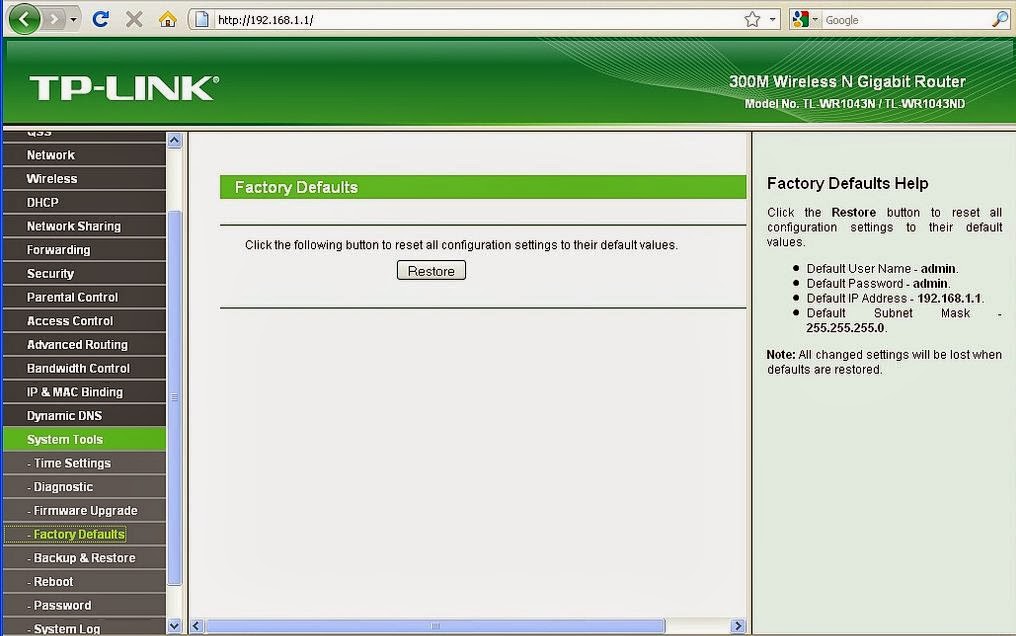 е узел yandex.ru отвечает на ping.
е узел yandex.ru отвечает на ping.
PING Server64 |find «TTL=» || ECHO Server64 not pingable — команда ECHO выполняется, если значение ERRORLEVEL, установленное FIND не равно 0, т.е. узел Server64 не ответил на ping.
Общие сведения о команде ip unnumbered и ее настройке
В данном документе разъясняется концепция команды ip unnumbered и предоставляется несколько примеров конфигураций для справки. Команда ip unnumbered configuration позволяет включить IP-обработку на последовательном интерфейсе, не назначая явный IP-адрес. Интерфейс ip unnumbered может «позаимствовать» IP-адрес другого интерфейса, уже настроенного на маршрутизаторе, с сохранением сети и адресного пространства.
Требования
Для этого документа отсутствуют особые требования.
Используемые компоненты
Настоящий документ не имеет жесткой привязки к каким-либо конкретным версиям программного обеспечения и оборудования.
Условные обозначения
Дополнительные сведения об условных обозначениях в документах см. в Условные обозначения технических терминов Cisco.
Рассмотрим сеть, показанную ниже. Маршрутизатор А имеет последовательный интерфейс S0 и интерфейс Ethernet E0.
Интерфейс Ethernet 0 маршрутизатора A можно настроить с IP-адресом, как показано ниже:
interface Ethernet0 ip address 172.16.10.254 255.255.255.0
Логически, чтобы включить IP на интерфейсе S0, потребовалось бы настроить на нем уникальный IP-адрес. Но можно также включить IP-адрес на последовательном интерфейсе и перевести его в рабочее состояние, не назначая ему уникального IP-адреса. Это делается путем заимствования IP-адреса, уже настроенного на одном из других интерфейсов маршрутизатора. Это можно сделать с помощью команды режима интерфейса ip unnumbered, как показано ниже.
interface Serial 0 ip unnumbered Ethernet 0
Команда режима интерфейса ip unnumbered <type> <number> заимствует IP-адрес из указанного интерфейса для интерфейса, на котором настроена команда. Команда ip unnumbered приводит к тому, что IP-адрес совместно используется двумя интерфейсами. Поэтому в нашем примере IP-адрес, настроенный на интерфейсе Ethernet, также назначается последовательному интерфейсу и оба интерфейса работают нормально. Это можно проверить по выходным данным команды show ip interface brief, как показано ниже:
Команда ip unnumbered приводит к тому, что IP-адрес совместно используется двумя интерфейсами. Поэтому в нашем примере IP-адрес, настроенный на интерфейсе Ethernet, также назначается последовательному интерфейсу и оба интерфейса работают нормально. Это можно проверить по выходным данным команды show ip interface brief, как показано ниже:
RouterA# show ip interface brief Interface IP-Address OK? Method Status Protocol Ethernet0 172.16.10.254 YES manual up up Serial0 172.16.10.254 YES manual up up
Как показывает вывод показанной выше команды show ip interface brief, последовательный интерфейс имеет IP-адрес, идентичный интерфейсу Ethernet, и оба интерфейса полностью функциональны. Интерфейс, который заимствует своей адрес у одного из других функциональных интерфейсов маршрутизатора, называется «ненумерованным интерфейсом». В нашем примере Serial 0 является ненумерованным интерфейсом.
Единственный реальный недостаток, присущий ненумерованному интерфейсу, — недоступность для удаленного тестирования и управления. Необходимо также помнить, что ненумерованный интерфейс заимствует свой адрес у запущенного и работающего интерфейса. Если ненумерованный интерфейс указывает на интерфейс, который не работает (то есть который не показывает Interface status UP, Protocol UP), то ненумерованный интерфейс не будет работать. Именно поэтому рекомендуется, чтобы ненумерованный интерфейс указывал на интерфейс обратной петли, так как этот интерфейс всегда работоспособен. Наконец, не забывайте о том, что команда ip unnumbered работает только с PPP-интерфейсами. Если команда настраивается на интерфейс множественного доступа (то есть Ethernet) или интерфейс обратной петли, то отображаются следующие сообщения:
RouterA(config)# int e0 RouterA(config-if)# ip unnumbered serial 0 Point-to-point (non-multi-access) interfaces only RouterA(config-if)# ip unnumbered loopback 0 Point-to-point (non-multi-access) interfaces only
В маршрутизаторе Cisco каждый интерфейс, соединенный с интерфейсом сети, должен соответствовать отдельной подсети. Интерфейсы напрямую подключаемых маршрутизаторов подключаются к одному сегменту сети и получают IP-адреса от одной подсети. Если маршрутизатору нужно отправить данные в сеть, непосредственно не связанную, он заглядывает в свою таблицу маршрутизации и направляет пакет на следующий непосредственно связанный переход к месту назначения. Если в таблице отсутствует маршрут, маршрутизатор направляет пакет в шлюз последнего ресурса. Когда маршрутизатор, напрямую подключенный к назначению, получает пакет, он доставляет его напрямую конечному узлу.
Интерфейсы напрямую подключаемых маршрутизаторов подключаются к одному сегменту сети и получают IP-адреса от одной подсети. Если маршрутизатору нужно отправить данные в сеть, непосредственно не связанную, он заглядывает в свою таблицу маршрутизации и направляет пакет на следующий непосредственно связанный переход к месту назначения. Если в таблице отсутствует маршрут, маршрутизатор направляет пакет в шлюз последнего ресурса. Когда маршрутизатор, напрямую подключенный к назначению, получает пакет, он доставляет его напрямую конечному узлу.
Таблица IP-маршрутизации содержит либо маршруты в подсети, либо маршруты в крупной сети. Для каждого маршрута есть один или несколько непосредственно подсоединенных адресов следующих узлов. Маршруты в подсети объединяются или суммируются по умолчанию в границах крупной сети для сокращения размера таблицы маршрутизации.
Примечание. Схема объединения, рассмотренная выше, подразумевает традиционный протокол маршрутизации вектора расстояния, например RIP или IGRP.
Давайте Давайте Рассмотрим назначение IP-адресов интерфейсам маршрутизатора с использованием сети класса B, которая была разделена на подсети по восьми разрядам. Для каждого интерфейса необходима уникальная подсеть. Хотя каждое двухточечное последовательное соединение имеет только две конечные точки к адресам, если каждому последовательному интерфейсу присваивается подсеть в целом, используется 254 доступных адресов для каждого интерфейса, где необходимо только два адреса. Если мы используем ненумерованные IP-адреса на каждом последовательном интерфейсе, экономится адресное пространство; адрес интерфейса локальной сети заимствуется и используется в качестве адреса источника для обновлений маршрута и пакетов из источника от последовательного интерфейса. Таким образом экономится адресное пространство. Ненумерованный IP имеет смысл только в двухточечных каналах.
Маршрутизатор, который получает обновленные данные маршрутизации, задает исходящий адрес обновления в качестве следующего узла в таблице маршрутизации. Обычно для следующего перехода используется непосредственно подключенный сетевой узел. Это не происходит, если используются ненумерованные интерфейсы IP, так как каждый последовательный интерфейс «заимствует» свой IP-адрес у другого интерфейса LAN, каждый из которых находится в другой подсети и, возможно, в другой крупной сети. То То То При настройке ненумерованных IP маршруты, узнанные через интерфейс с ненумерованным IP, имеют интерфейс следующего узла вместо обновления исходного адреса маршрутизации. Тем самым удается избежать проблемы недопустимого адреса следующего перехода из-за того, что источник обновления маршрутизации исходит от следующего перехода, который не является подключенным напрямую.
Обычно для следующего перехода используется непосредственно подключенный сетевой узел. Это не происходит, если используются ненумерованные интерфейсы IP, так как каждый последовательный интерфейс «заимствует» свой IP-адрес у другого интерфейса LAN, каждый из которых находится в другой подсети и, возможно, в другой крупной сети. То То То При настройке ненумерованных IP маршруты, узнанные через интерфейс с ненумерованным IP, имеют интерфейс следующего узла вместо обновления исходного адреса маршрутизации. Тем самым удается избежать проблемы недопустимого адреса следующего перехода из-за того, что источник обновления маршрутизации исходит от следующего перехода, который не является подключенным напрямую.
Примечание: информация в этих примерах конфигурации основывается на версии 12.2 (10b) программного обеспечения Cisco IOS и была протестирована на маршрутизаторах Cisco серии 2500.
Давайте Давайте Рассмотрим четыре других примера конфигурации для ненумерованных IP.
Примечание. Можно было бы использовать интерфейсы обратной петли вместо интерфейсов Ethernet.
Одна основная сеть, разные подсети
Рис. 1 показывает, что по обе стороны последовательного подключения находится одна и та же крупная сеть с разными подсетями.
Рисунок 1 – Схема построения сети| Маршрутизатор 1.1.1.1 | Маршрутизатор 2.2.2.2 |
|---|---|
Current configuration: interface Ethernet0 ip address 171.68.178.196 255.255.255.192 interface Serial0 ip unnumbered Ethernet0 router igrp 10 network 171.68.0.0 | Current configuration: interface Ethernet 0 ip address 171.68.179.1 255.255.255. |
 192
interface Serial 0
ip unnumbered Ethernet0
router igrp 10
network 171.68.0.0
192
interface Serial 0
ip unnumbered Ethernet0
router igrp 10
network 171.68.0.0
Router 1.1.1.1# show ip route
171.68.0.0/26 is subnetted, 3 subnets
I 171.68.179.0 [100/8976] via 171.68.179.1, 00:00:02, Serial0
C 171.68.178.192 is directly connected, Ethernet0
I 171.68.0.0 [100/8976] via 171.68.179.1, 00:00:02, Serial0
Router 1.1.1.1# ping 171.68.179.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 171.68.179.1, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 28/30/32 ms
Router 2.2.2.2# show ip route
171.68.0.0/26 is subnetted, 3 subnets
C 171.68.179.0 is directly connected, Ethernet0
I 171.68.178.192 [100/8976] via 171.68.178.196, 00:00:02, Serial0
I 171.68.0.0 [100/8976] via 171.68.178.196, 00:00:02, Serial0
Router 2.2.2.2# ping 171.68.178.196
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 171.68.178.196, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 32/32/32 ms
 Sending 5, 100-byte ICMP Echos to 171.68.178.196, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 32/32/32 ms
Sending 5, 100-byte ICMP Echos to 171.68.178.196, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 32/32/32 ms
Сведения о маршруте о подсетях правильно обрабатываются в этом сценарии.
Разные крупные сети без подсетей
Рис. 2 показывает, что по обе стороны последовательного подключения разные крупные сети и нет подсетей.
Рис. 2. Сетевая диаграмма| Маршрутизатор 1.1.1.1 | Маршрутизатор 2.2.2.2 |
|---|---|
Current configuration: interface Ethernet0 ip address 171.68.178.196 255.255.0.0 interface Serial0 ip unnumbered Ethernet0 router igrp 10 network 171.68.0.0 | Current configuration: interface Ethernet 0 ip address 172. |
 68.1.1 255.255.0.0
interface Serial 0
ip unnumbered Ethernet0
router igrp 10
network 172.68.0.0
68.1.1 255.255.0.0
interface Serial 0
ip unnumbered Ethernet0
router igrp 10
network 172.68.0.0Router 1.1.1.1# show ip route C 171.68.0.0/16 is directly connected, Ethernet0 I 172.68.0.0/16 [100/8976] via 172.68.1.1, 00:01:26, Serial0 Router 1.1.1.1# ping 172.68.1.1 Sending 5, 100-byte ICMP Echos to 172.68.1.1, timeout is 2 seconds: !!!!! Success rate is 100 percent (5/5), round-trip min/avg/max = 28/28/28 ms Router 2.2.2.2# show ip route I 171.68.0.0/16 [100/8976] via 171.68.178.196, 00:00:21, Serial0 C 172.68.0.0/16 is directly connected, Ethernet0 Router 2.2.2.2# ping 171.68.178.196 Sending 5, 100-byte ICMP Echos to 171.68.178.196, timeout is 2 seconds: !!!!! Success rate is 100 percent (5/5), round-trip min/avg/max = 28/29/32 ms
Основная сеть с подсетью, основная сеть без подсети
Рис. 3 показывает, что с одной стороны последовательного соединения крупная сеть с подсетью, а с другой — крупная сеть без подсетей.
| Маршрутизатор 1.1.1.1 | Маршрутизатор 2.2.2.2 |
|---|---|
Current configuration: interface Ethernet0 ip address 171.68.178.196 255.255.255.192 interface Serial0 ip unnumbered Ethernet0 router igrp 10 network 171.68.0.0 | Current configuration: interface Ethernet 0 ip address 172.68.1.1 255.255.0.0 interface Serial 0 ip unnumbered Ethernet0 router igrp 10 network 172.68.0.0 |
Router 1.1.1.1# show ip route
171.68.0.0/26 is subnetted, 1 subnets
C 171.68.178.192 is directly connected, Ethernet0
I 172.68.0.0/16 [100/8976] via 172.68.1.1, 00:00:03, Serial0
Router 1.1.1.1# ping 172.68.1.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 172.68.1.1, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 28/31/32 ms
Router 2.2.2.2# show ip route
171.68.0.0/16 is variably subnetted, 2 subnets, 2 masks
I 171.68.178.192/32 [100/8976] via 171.68.178.196, 00:00:48, Serial0
I 171.68.0.0/16 [100/8976] via 171.68.178.196, 00:00:48, Serial0
C 172.68.0.0/16 is directly connected, Ethernet0
Router 2.2.2.2# ping 171.68.178.196
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 171.68.178.196, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 28/29/32 ms
Примечание. До версии программного обеспечения Cisco IOS 11.0(2) статический маршрут требовалось поместить для основной сети 171.68.0.0/16 в маршрутизаторе 2.2.2.2.
В этом сценарии происходит потеря данных подсети, поскольку программа принимает их за маршрут хоста. В версии программного обеспечения Cisco IOS 11.0(2) и выше протоколы IGRP и RIP решают эту проблему путем передачи объединенного маршрута для крупной сети через ненумерованные каналы связи типа «точка-точка».
Две основных сети и их подсети
Рис. 4 показывает, что по обе стороны последовательного соединения находятся разные крупные сети с соответствующими подсетями.
Рис. 4. Схема построения сети| Маршрутизатор 1.1.1.1 | Маршрутизатор 2.2.2.2 |
|---|---|
Current configuration: interface Ethernet0 ip address 171.68.178.196 255.255.255.192 interface Serial0 ip unnumbered Ethernet0 router igrp 10 network 171.68.0.0 | Current configuration: interface Ethernet 0 ip address 172.68.1.1 255.255.255.192 interface Serial 0 ip unnumbered Ethernet0 router igrp 10 network 172.68.0.0 |
Router 1.1.1.1# show ip route
171.68.0.0/26 is subnetted, 1 subnets
C 171.68.178.192 is directly connected, Ethernet0
172.68.0.0/16 is variably subnetted, 2 subnets, 2 masks
I 172.68.0.0/16 [100/8976] via 172.68.1.1, 00:00:02, Serial0
I 172.68.1.0/32 [100/8976] via 172.68.1.1, 00:00:02, Serial0
Router 1.1.1.1# ping 172.68.1.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 172.68.1.1, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 32/81/280 ms
Router 2.2.2.2# show ip route
171.68.0.0/16 is variably subnetted, 2 subnets, 2 masks
I 171.68.178.192/32 [100/8976] via 171.68.178.196, 00:00:22, Serial0
I 171.68.0.0/16 [100/8976] via 171.68.178.196, 00:00:22, Serial0
172.68.0.0/26 is subnetted, 1 subnets
C 172.68.1.0 is directly connected, Ethernet0
Router 2.2.2.2# ping 171.68.178.196
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 171.68.178.196, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 28/31/32 ms
Примечание. В версиях программного обеспечения Cisco IOS ранее 11.0 (2) нужно было указывать статический маршрут для основной сети 171.68.0.0/16 в маршрутизаторе 2.2.2.2 и 172.68.0.0/16 в маршрутизаторе 1.1.1.1.
В этом сценарии происходит потеря данных подсети, поскольку программа принимает их за маршрут хоста. В Cisco IOS software version 11.0(2) и более поздней IGRP и RIP исправляют проблему, посылая объединенный маршрут для основной сети через ненумерованные каналы точка-точка.
Заданная сеть недоступна роутер
Падения интернета, «Шлюз, заданный по умолчанию, недоступен»
Роутер настрой нормально сетевые карты на авто поставь в роутере где нужно галочки оно уже 3 года работает без проблемно у нас
пароль на вай фай 8 лат знаков
Собственно вводим имя сети SSID , тип безопасности который задавали в настройках роутера , тип шифрования и пароль. Эпилогом данных настроек, должен стать яркий значок сети в трее, сигнализирующий о том, что сеть подключена с доступом к…
Не могу настроить интернет через роутер, пишет — указанный узел недоступен, как исправить?
По инструкции
Необходимо задать IP адреса компьютерам, что бы они были в одной сети. Эта функция обычно возлагается на маршрутизатор или роутер. Тогда он каждому подключенному компьютеру назначает адрес из заданного диапазона.
Провайдеру звони
Вконтакте HELP HELP HELP!
В лес
Пингую ДНС, а в ответ 192.168.1.1 заданная сеть недоступна. Уже и попробовал выставить автоматическое получение ip адреса и ДНС в сетевухе, и модем по дефолту сбрасывал заново настраивал, и сетевую встроенная …
Я пока-что восстанавливаю работоспособность сайта.
Здравствуйте.
В соц. сети произошел сбой. Авария в ДЦ Спб.
За новостями удобно следить в официальном твиттере ВК: https://twitter.com/vkontakte и страничке пресс-секретаря ВК: https://twitter.com/lobushkin/
Я так захотел
Коротко и ясно о социальной сети Вконакте
P.S
Простите, если будут ошибки мне 12 лет 🙁
В новостных сайтах написано что вконтакте недоступный сайт и-за жары
на других написано что он будет закрыты Youtube и Вконтакте и-за пиратсва
Жди
На маршрутизаторе R4 администратор вручную задает распространение суммарных маршрутов на все подсети сетей 172.16.0.0 16 и 10.0.0.0 8 с … Поскольку сети получатели недоступны, маршрутизаторы не станут их объявлять своим соседям.
ФСБ закрывает ВК за отказ пидорёнка Пашки закрыть бандерложские страницы
…
Ну вот, включил!
Помогите определить вирус. Блокирует открытие сайтов, разрывая соединение с ними.
Скорее всего у тебя изменены настройки сетевого соеденения совету зайти в tcp ip и зименить на автомат dns сервер и ip адресс это не вирус а скрипт сработал
Dzen Ответ от 209.59.157.38 Заданная сеть недоступна. .trojan ггг dzen маршрутизатор ответил за егобрейн dzen пакет шол через амстердам в лондон — нью йорк — чикаго и дальше сказали шо хуй .trojan в амстердаме там на него…
Проверь в роутере заблокированные сайты
Читай всё про папку hosts и ее правку . введи в поисковик яндекса
Файл hosts посмотри…
Касперский просканируй
Сам инет их еще может закрывать
Ответ от 192.168.1.1 Заданная сеть недоступна. Хелп, что делать??? если что — мой комп подключен к роутеру по кабелю .29 ноября 2010
Как по мне, NOD32 уже не тот, я пользуюсь авастом, и он справляется на ура. Советую его. А вирус могут быть такие: AdWareGen, EcoWateGen, MaleWareGen, хотя они для другого сделаны, например Малварь для засирания компа софтом и браузера рекламой, они могут и такую проблему причинить.
Если вы пользуетесь Google Chrome, то удалите и поставьте Яндекс! (Объясняю: Хром слишком слаб перед вирусами и они его буквально сжирают, а Янднекс, хоть и построен на базе хрома, более устойчив к вирусам и его можно разными дополнениями сделать еще лучше). И как уже сказано файл HOSTS может все «ломать»
В общем так, 1. Браузер вам посоветовал.
2. Антивирус посоветовал.
3. Проверьте файл HOSTS.
4. Переустановите в конце концов систему! Ее как правило нужно переустанавливать хотя бы раз в год!
Помимо использованных вами NOD32 и DrWeb Curreit, стоит проверить систему и другими сканерами:
AdwCleaner http://www.comss.ru/page.php?id=1309
Malwarebytes Anti-Malware (MBAM) http://www.comss.ru/page.php?id=84
Emsisoft Emergency Kit http://www.comss.ru/page.php?id=448
HitmanPro http://www.comss.ru/page.php?id=612
Скорее всего, что-то прописалось в hosts, DNS или прокси. Вы внимательно смотрели в hosts, там точно ТОЛЬКО ваши записи и ТЕ САМЫЕ адреса, что задали вы? Надо еще сбросить/очистить системный кэш DNS. Протрассируйте утилитой tracert обмен с 2-3 сайтами, которые не догружаются.
DrWeb Cureit! обязательно должна вылечить Host File
Проверь в анти вируснике наличие вирусов!
Сбросить настройки прокси
сбросить настройки днс
выполнить в cmd
netsh winsock reset
Если подключать через wi-fi маршрутизатор в моем случае NetGear WNR1000v2 , то творятся странные вещи.А именно, не работает интернет. ping 8.8.8.8 выдает 192.168.1.1 заданная сеть недоступна. как я понимаю, шлюз маршрутизатора …18 ноября 2011
Это из-за НОДа. Увы и ах, сам я тоже на это нарывался. Наилучшим решением будет откатить Винду до момента его установки.
Можно все исправить не трогая систему, просто скачайте Avg antivirus free сделать надо полную проверку, затем в опциях. Изменить на глубокую проверку. Снова проверить. И проблема уйдет, а не уйдет пишите.
Готов помочь советом
мой ящик [email protected]
Skype it-specialist2015
К всему добавленному выше, могу добавить avz. скачав его и запустив исследование системы вы много интересного увидите
Отключи firewall
И подобные проги
У меня было тоже самое. Касперский помог. До дома доберусь, скину скрипт. Скачать AVZ, с его
Помощью загрузишь скрипт, но придется воспользоваться другим компом, т. к. Интернет у тебя заблокирован.
1 10.64.4.1 сообщает Заданная сеть недоступна. 4 апреля 2012
И без роутера домашняя сеть тоже не работает. Так что траблы похоже не у меня . 5 апреля 2012
По-моему, троян
Нда.. было такое.. систему переставлял — не помого, пока диск D не форматнул
На форум virusinfo.info идите, там подскажут. Без логов антивирусов или Autoruns’а ничего более подходящего, чем «погонять комп сканерами» и «погадать на гуще единиц и нулей» вам тут не подскажут.
Не плохой вопрос! Ответ прост-качай антивирус!
Сносить ничего не надо, hitman-pro достаточно для троянов. AVZ полезен для анализа процессов в оперативке, вполне стоит того, чтобы научиться работать этим инструментом.
Набор инструментов — http://pirat.ca/viewtopic.php?t=138313
TDSSkiller — http://support.kaspersky.ru/viruses/disinfection/5350
Другими словами, роутер виден в сети и доступен с нашего компьютера. … Роутер в сети не виден и с нашего компьютера недоступен. Таким же образом можно пинговать различные сайты и узлы в сети Интернет.
В настройках антивируса. Проверь брандмер
Nod 32 решето ничего не ищет, тупой антивир.. Скачайте каспера или еще лучше др. веба полного (!)
Это не вирус, а троян. У вируса другие действия и последствия. Что да как лечить — не знаю.
C:\Windows\System32\drivers\etc
открой фаил hosts блокнотом и удали оттуда всё
в этом файле прописываются сайты закрытые для доступа
помощь скорее одноразовая и если что то сидит в компе то оно снова будет дописывать туда
есть второй способ (радикальный)
мыло у тебя есть…
закинь с компа всё что тебе дорого на мыло
переустанови винду, (у меня нет возможности сидеть в данный момент на лицензии поэтому сижу на кряканой версии «овгорский» так и напиши в поисковике если нужна винда)
там хранятся образы так что тебе надо будет иметь флешку или диск для записи винды (их там много так что выбери подходящую (не переусердствуй))
предварительно скачай пакет драйверов «DPS» так и пиши в поисковике или driver puck salution (качай полную версию иначе если сам с дравами не справишься так и останешься без интеренета пока не проплатишь комунить за настройку)
эта программа сама найдет какие дрова установить на комп (не просто так она весит 10Гб) так же она предложит тебе установить программы (я ставлю только кодекпак для видео всё остальное устанавливаю сам так что проследи за галочками когда будешь выбирать что устанавливать)
если у тебя есть весь этот дистрибутив то вся установка займет не более часа
после чего восстанавливай всё что дорого с мыла
Ps не так давно была похожая проблема но мне помогла перенастройка роутера хотя голову ломал больше часа, а как ты понял мне проще переустановить систему чем искать решение таких проблем…
PPS Без родителей не переустанавливай ничего если ты боишься ответственности, так как возможно есть что то нужное отцу как ты упомянул выше
и я не думаю что это вирус просто где то что то не так настроено…
Попробуйте Kaspersky Virus Removal Tool.
Далее вопрос, когда выдает Заданная сеть недоступна твой айпишник у друга не сбрасывается на какой либо другой? С таким сталкивался только когда vpn строишь…13 сентября 2009
Hosts проверь, там должно быть 127.0.0.1 и ничего больше.
Проблема не в вирусе и не в Windows попробуй отключить программу Брандмауэр windows он всегда блокирует программы которые пытаются подключится к сети. Но если проблема не решится в крайнем случае перезагрузи компьютер и во время первой заставки (как правило с заставкой название компьютера) нажимай клавишу F8 и выбери устранение неполадок. Далее выбери востановление системы. Ну я не рекомендую так делать ( у меня был случай компьютер установил мне не нужные программы запустил востановление системы. Но, как оказалось файла или архива востановления не было. Пришлось сносить windows. Удачи!
Чувак, тут 2 варианта, даже 3, 1)вариант, Сработал Антивирус У меня avast,бесит Все время блокирует сигнал, скайп работает, а все остальное нет (( 2)Возможно вирус, но это врядли.. Но может и он… ну и 3)Что-то с настройками, посмотри что с хостом, может сам что-то переделал, нажал не туда, и такое бывает, ну вообщем, не беспокойся, это шлавное!
Https://vk.com/bblackeevil
Смотри всё дело в файле hosts много раз встречал такое так что поищи в гугле как файл host изменить в реестре
Есть роутер под FreeBSD 7.1 AMD64 HP Dl160 G5 на сервере поднят pf nat. выглядит это так пару раз Заданный узел недоступен , а потом как обычно Ответ 1мс .26 февраля 2009
Если иконка интернет соединения в правом нижнем углу активна, а браузеры на компьютере не открывают ни одну страницу, то решений по этому вопросу может быть три, итак:
1) Маловероятно — перезагрузка wi-fi (выключить на 1 минуту, включить).
2) Остановить работу ВСЕХ служб антивируса, часто бывает, что именно NOD блокирует. Решение, удалить NOD (через установку/удаление программ) и установить дистрибутив с официального сайта https://www.esetnod32.ru/
3) Если вирусы изменили host и прочее — переустановка ОС, как правило сейчас этот вопрос в «ручном» режиме с вычисткой всех файлов уже не решить. Я рекомендую переустановить Windows.
Попробуй программу «Wishmaster»
http:// rghost .ru/ 39515205
Выложила для тебя.
Поставь себе самый простой дистрибутив линукса и вообще забудь про вирусы
Про сканируй avz и нортоном
Полязь по настройкам сетевого подключения и роутера проблема гдето там
Сергей, это означает, что роутер не подключился к внешнему миру. В тво м случае, видимо, должно быть сообщение, что заданная сеть недоступна.11 мая 2015
Может проблема в настройках антивируса или фаервола (может винды врядли правда) попробуй поковырятса в настройках поискать там и заодно включи обнаружения всех видов угроз! переустанови другой антивир наверно аваст, настрой уровень тщятельности сканирования
Первым делом перед запуском браузера посмотри на свойства ярлыка, именно на путь — в нём должен быть указан только «C:\Program Files (x86)\Mozilla Firefox\firefox.exe» все что, после exe спам-реклама — стереть — оставив только C:\Program Files (x86)\Mozilla Firefox\firefox.exe в свойствах ярлыка.
Скачайте CCleaner он почистит вирус + советую поставить антивирусную систему Avast…
Не запускается Smart HUB на Samsung SmartTV
А поподробней? Номер телевизора, хотя бы написали и где живёте. Интернет-то подключён? .
«Для определения характера данного явления рекомендуем воспользоваться услугой удаленного доступа.
Для того, чтобы воспользоваться услугой удаленного доступа необходимо
позвонить в Единую Службу Поддержки Samsung по телефону
8-800-555-55-55(звонок по России бесплатный) .
Обязательным условием для подключения специалиста является подключение телевизора к интернету.
При использовании телевизора, не сертифицированного для работы на
территории России, возможна блокировка некоторых функций и сервисов, в
том числе сервиса Smart Hub. Отключить данную блокировку, к сожалению,
не представляется возможным. Уточнить страну производителя можно на
заводской таблице аппарата.
Возможно, что в данный момент указанное явление связано с техническими работами на сервере SmartHub. В ближайшее время работа всех сервисов будет восстановлена.
Mrs. Samsung3″
http://answers.ru.samsung.com/answers/7463-ru_ru/searchquestions.php?search=не загружается SMART HUB&searchcategory=all
Добавлю, может быть, поможет «обнуление» настроек: попробуйте выполнить сброс настроек и сброс настроек Smart Hub.
Сброс настроек: Меню – Поддержка – Самодиагностика – Сброс – пароль 0000(по умолчанию) .
Сброс Smart Hub: Находясь на главном окне Smart Hub нажать кнопку «TOOLS» на пульте управления, выбрать раздел «Настройка» далее «Сброс» стандартный
пароль 0000 (если его не меняли).
Проверьте доступность локальной сети. Если локальная сеть недоступна при подключении через роутер проверьте поддерживает ли роутер технологию PPPoE Dual Access.
Позвонил службу поддержки. Сказали что у них плановые работы на серверах и самрт хаб для наших моделей не будет работать до 1 октября.
Порадовал, а то я уже запереживать успел! спасибо за инфу!
3 дня уже насилую телек, сбросами настроек, прошиваниями сменами точек доступа. Да еще совпало еще с тем что установил новый роутер, думал из-за него глючит. Ну посмотрим случится ли завтра алилуя… samsung так нельзя с людьми поступать! =)
У меня тоже такая беда
С 26 по 1.10 могут наблюдаться перебои в работе Smart hub, а так же могут быть сложности с обновлением ПО по сети, удаленным управлением и дополнительно учетная запись недоступна.
http://smarttv-shop.ru/
Порой необходимо объединить несколько беспроводных сетей в одну, в чем также поможет виртуальный роутер. … Там появится новое подключение, которое будет недоступным. … Задать вопрос.19 октября 2015
Уж думал, что я один такой, хотел уже по гарантии отдавать.
Только что звонил Единую Службу Поддержки Samsung, сказали, что профилактические работы на сервере продлятся до конца сегодняшнего дня. То есть завтра должно быть всё ОК. Посмотрим…
Такая же модель, такая же проблема. извелась уже, успела только сброс настроек сделать, теперь просто подожду))))
Samsung могли бы и предупредить пользователей заранее, например всплывающим окошком о проведении технических работ при загрузке Smart Hubа, а то внешне проблема очень похожа на поломку телевизора. Тем самым они бы разгрузили горячие линии и сервисные центры.
Последние данные по этой проблеме — Самсунг продлил профилактику на своём сервере до 02.10.14.
Ноутбук пишет, что нет доступных подключений Wi-Fi. Недоступны локальные городские ресурсы провайдера, торрент, DC хаб и … После перезагрузки роутера через телефон сеть стала нормально работать, но уже 2й день подряд такое вот.
Не заходит вк пишет веб-страница недоступна
У меня уже 2 дня такая фигня
О сайте. Задать свой вопрос. … А что делать в том случае, если сеть недоступна вообще? Для этого необходимо сначала перезагрузить роутер возможно, возникла ошибка.
Проблемы у вк. сам создавал вопрос на подобе. в центральной России у всех так почти говорят.
DHCP роутера иногда выдает внешний IP
Получить Static IP
То 1 не понял. Если речь о том, чтобы все завести на роутер, то мне не нужно чтобы инет был в локалке. то 2 модель…. эээээ. … Ответ от 192.168.1.1 Заданная сеть недоступна.
Для начала, сбрось настройки на дефолтные. Потом аккуратно пропиши внешние реквизиты и если по-умолчанию DHCP не включен, то включи. Возьми адрес из раздаваемых.
169. 254. 0.0/16?
это APIPA адрес, установка такого адреса ОС связана с недоступностью/корявостью DHCP сервера или плохой связью (дроп пакетов)
Что делать? помогите !(
Социальная сеть ВКонтакте сегодня испытывает проблемы.
Пресс-секретаря ВКонтакте Георгия Лобушкина сообщил, что сайт недоступен вследствие аварии в одном из дата-центров ВКонтакте в Санкт-Петербурге, вызванной беспрецедентной жарой.
Адаптер беспроводной локальной сети Беспроводное сетевое соединение 2 … Ответ от 169.254.164.59 Заданный узел недоступен. … sun, нет. в том то и дело, что не могу через роутер сидеть, т.к попасть на 192.168.0.1 не уда тся.
У меня тоже! Заебали, реально!
У всех не работает, его прикрыли
Санкт-Петербург, 27 июля. В российской социальной сети «ВКонтакте» произошел технический сбой. Часть пользователей не может загрузить страницу, другие обнаружили, что с их страниц исчезли все данные. «Все фотографии, записи и сообщения ВКонтакте, которые сейчас недоступны по невыясненным причинам, скоро вернутся. Мы работаем над этим» , -написал в своем микроблоге пресс-секретарь соцсети Георгий Лобушкин.
Здесь подробно расписано, почему сегодня не работает контакт
[ссылка заблокирована по решению администрации проекта]
Как узнать IP-Адрес ?
Так зайдите в настройки сети ноута там и увидите. Или у вас по DHCP раздается?
Если учесть тот факт, что внутренний адрес роутера недоступен дальше локальной сети, то присвоить устройству можно абсолютно любой серый IP … Перед нами поле IP Address с уже заданным значением. Это наш внутренний сетевой адрес роутера.
Через командную строку ipconfig на ноуте
Установи «AIDA 64» и посмотри
Попытка Orbitum подключиться к excalibur-craft.ru была отклонена. Сайт недоступен или ваша сеть настроена неправильно.
Майнкрафт…
Ответ от 193.124.254.163 Заданная сеть недоступна.16 февраля 2015
И если так, то выключаем удаляем SkyDNS и YandexDNS из компонентов роутера, либо прописываем на интерфейсе ПК DNS-сервера Freedom и…18 февраля 2015
Нажать кнопку пуск-справка-знакомство с основами виндовс-настройка беспроводной сети
Какой роутер мощнее
Проблема с роутером
Сэкономил на роутере, теперь занимайся с ним сексом. ГовноЛинк он такой.
Вы можете задать вопрос экспертам Нашего сайта и получить ответ по почте. Комментарии к статье … Похожие статьи Windows 7 как настроить роутер Выход Windows Mobile 7 Графические технологии Настройка локальной сети Windows 7…
Здыхает твой роутер.
Стандартный адhtc для этого роутера 192.168.0.1 а не 1.1 если не сменили конечно. А то что 4 порт горит… плохо…
Если перепрошил на новую прошивку то считай угробил роутер. Вход в роутер 192.168.0.1.Пароль-логин «admin»
Что делать если ты пытаешься зайти в вк, а тебе пишут «Веб-страница не доступна».
Удалить ВКМЮЗИК ВКДИДЖЕЙС ВКСАВЕР И ПРОЧУЮ МУТЬ!
Не устанавливается соединение с провайдером Недоступен сервер провайдера 35 Часто задаваемые вопросы FAQ Вопрос 1 … 3. Подключаю компьютер по Wi-Fi сети к роутеру. При попытке подключится выдается сообщение, что сеть подключена с…
Выйди на улицу — там и живых людей увидишь
Поставь браузер вместо говна
Если с телефона заходит (или др. устройств) , проверьте комп на вирусы, проверьте hosts файл, ну и удалите амиго и прочий неадекватный программный продукт, пользуйтесь нормальными браузерами
Обратиться к психологу
Какие анкеты с тестами для собеседования на должность системного администратора или его помощника используете?
Системного администратора ЧЕГО?
Не устанавливается соединение с провайдером Недоступен сервер провайдера 35 Часто задаваемые вопросы FAQ Вопрос 1 … 3. Подключаю компьютер по Wi-Fi сети к роутеру. При попытке подключится выдается сообщение, что сеть подключена с…
Веб-страница недоступна ERR_CONNECTION_REFUSED Google chrome
Анти вирусник не пускает
Должен быть правильный для этой сети IP адрес. Если неправильный, нажать Исправить. Если адрес не восстановился, см. п. 4. 3.3. Если компьютер подключен по WiFi только точка доступа, не роутер!!! .
А в других браузерах?
Помогите, не работает Google Chrome, при заходе на любые сайты (кроме google.ru) выдаёт ошибку ERR_CONNECTION_REFUSED.
А снести Гугл не пробовал под чистую \ переустановить?
В папках . подпапках . в реестре
Чтоб как будто у тебя его ни когда не было!
Где то скорей ошибка вылазиет !
А в настройках не смотрел кто у тебя в поисковике?
Когда пингую DNS получается такое Ответ от 192.168.1.1 Заданная сеть недоступна. … Доступ в интернет я уже писал что осуществляется по технологии ADSL, провайдер — Ростелеком, модем настроен роутером. 3 декабря 2012
Не работает интернет..
В настройках беспроводного сетевого соединения в свойствах TCP/IP нужно указать адрес предпочитаемого DNS-сервера — 8.8.8.8, адрес альтернативного DNS-сервера — 8.8.4.4.
Ответ Заданная сеть недоступна означает, что маршрут к сети отсутствует. Необходимо проверить таблицу маршрутизации на маршрутизаторе, указанном в адресе Ответ от сообщения Заданная сеть недоступна .
Nat
Трансляция сетевых адресов
на wiki и в гугле автор вопроса забанен?
Есть роутер TP-Link, к нему подключено 2 ноутбука — один работает прекрасно, у второго на windows 8 — постоянно обрывается соединение, пишет 192.168.1.1 Заданная сеть недоступна. потом опять подключается и так все время.
Купил новый телефон,
Придумай другой логин
У меня сеть организованна таким образом комп — роутер — модем. … Соединение с интернет нету Статистика Ping для 8.8.8.8 Ответ от 192.168.1.1 Заданная сеть недоступна Ответ от 192.168.1.1 Заданная сеть недоступна Ответ от 192.168.1.1…20 сентября 2012
Дату и время проверяй.
Ошибка «Невозможно установить надежное соединение»
О1: Необходимо проверить установленное в системе дату и время. Проблема возникает из-за несоответствия времени на устройстве с временем действия сертификатов Google (срок еще не наступил или уже закончился). Необходимо выставить правильный часовой пояс, дату и время.
О2:
Такая ошибка довольно часто возникает из-за некорректной работы DNS серверов провайдеров. Для изменения DNS сервера на девайсе можно установить ® Set DNS и выбрать в настройках GoogleDNS (в PRO версии root права не нужны, она также есть в указанной теме в разделе Скачать). Если выход в интернет осуществляется через WI-FI, то в настройках роутера укажите в качестве DNS сервера — 8.8.8.8
Ошибка «Невозможно установить надежное соединение»
О1: Необходимо проверить установленное в системе дату и время. Проблема возникает из-за несоответствия времени на устройстве с временем действия сертификатов Google (срок еще не наступил или уже закончился). Необходимо выставить правильный часовой пояс, дату и время.
О2:
Такая ошибка довольно часто возникает из-за некорректной работы DNS серверов провайдеров. Для изменения DNS сервера на девайсе можно установить ® Set DNS и выбрать в настройках GoogleDNS (в PRO версии root права не нужны, она также есть в указанной теме в разделе Скачать). Если выход в интернет осуществляется через WI-FI, то в настройках роутера укажите в качестве DNS сервера — 8.8.8.8
О4:
Попробуйте поменять способ подключения к интернету wi-fi <-> 3G, а также использовать другие точки подключения. Довольно часто эта проблема возникает из-за неполадок в сети.
О5:
1. Выполните хард-резет (общий сброс) смартфона. При этом все данные с него удалятся, но станет возможным подключить аккаунт Google;
2. Установите программу Add Account для принудительного добавления аккаунта в систему, сделать это можно следующим образом:
— cкачайте программу Add Account по ссылке ниже;
— запишите apk-файл в корень карты памяти;
— откройте стандартный браузер и введите следующее: content://com.android.htmlfileprovider/sdcard/add_account.apk
— перейдите по ссылке — начнется установка программы;
3. Запустите программу Add Account и введите Ваш адрес gmail в поле Account;
4. Нажмите Add Account;
5. Теперь при попытке синхронизации с аккаунтом Google возникнет ошибка с сообщением о том, что Вы неправильно ввели пароль. Достаточно просто нажать на уведомление и ввести пароль, после чего синхронизация с аккаунтом будет работать.
При входе в Google Play возникает ошибка: «Ошибка Сервера»
О1: Необходимо удалить аккаунт Google, остановить, затем очистить кэш и данные приложений Google Services Framework и Google Play, перезагрузить устройство, зайти в Google Play и добавить аккаунт Google по его запросу.
Вход не выполнен не удалось связаться с серверами Google
01.При включенной двух-этапной аутентификации в акке гугла — не удается войти в аккаунт и Google Play с андроида с ошибкой: «вход не выполнен не удалось связаться с серверами google»
Чуть голову не сломал, инет работает, через сайт в гугл захожу, а акк добавить в андроид не удается.
В общем нужно сгенерить ключ для приложения не поддерживающего двух-этапную аутентификацию, и ввести его вместо пароля на андроиде.
Может поможет кому, сам такого нагуглить не смог, и догадался не сразу, уж больно ошибка своеобразная выдавалась, и советы в интернетах совсем в другую сторону мысли наводят.
02.Я нашёл ещё один способ.
Нужно отключить двухэтапную аунтефикацию и удалить аккаунт на устройстве. Зайти в него и можно ставить аунтефикацию обратно.
Связка adsl модем (в режиме моста) > роутер с включенным dhcp и PPPOE соединением > комп — не работает инет.
В админку роутера, проверять настройки…
ip получил в правильной сети?
Обмен пакетами с мой шлюз по с 32 байтами данных Ответ от мой айпи Заданный узел недоступен. 3 января 2013
желтый знак восклицания на иконке в трее. в настройках сети пишет неизвестная сеть , этот компьютер-неизвестная сеть-интернет. 3 января 2013
По мне так проще и удобнее настроить модем в режиме роутера а роутер в режиме точки доступа-удачи.
Модем надо подключать напрямую к компьютеру для настройки.
Origin.нужна помощь!
Интернет что ты хотел )) попробуй всё что написанно, если не получится то жопа
Если роутер выключить включить, связь появляется. Но она может появиться и не сразу, а 1 192.168.1.1 сообщает Заданная сеть недоступна. 1 апреля 2012
Не могу зайти в контакт. Нужна помощь!
Правильно и не надо. Контакт-параша
80.93.125.165.ett.ua 80.93.125.165 сообщает Заданная сеть недоступна. Трассировка завершена. … ну как пишут, что хамачи не обращает внимания на роутеры и фаерволы… у меня роутера нет, дело с ним не имею..не могу сказать.
Вирусяку поймал у меня тоже самое было я проверил AVAST-ом удалил заработало
AVZ-4 очистить host http://z-oleg.com/secur/avz/download.php
Глава 39. Устранение неполадок OpenShift SDN Контейнерная платформа OpenShift 3.11
Как описано в документации SDN, существует несколько уровней интерфейсов, которые создаются для правильной передачи трафика от одного контейнера к другому. Чтобы отладить проблемы с подключением, вам необходимо протестировать различные уровни стека, чтобы определить, где возникает проблема. Это руководство поможет вам разобраться во всех слоях, чтобы определить проблему и способы ее устранения.
Отчасти проблема заключается в том, что платформу OpenShift Container Platform можно настроить разными способами, а сеть может работать неправильно в нескольких местах.Таким образом, этот документ будет работать с некоторыми сценариями, которые, надеюсь, охватят большинство случаев. Если ваша проблема не описана, представленные инструменты и концепции должны помочь в работе по отладке.
- Кластер
- Набор машин в кластере. , то есть Мастера и Узлы.
- Мастер
- Контроллер кластера OpenShift Container Platform. Обратите внимание, что мастер может не быть узлом в кластере и, следовательно, может не иметь IP-подключения к модулям.
- Узел
- Хост в кластере, на котором запущена платформа контейнеров OpenShift, на которой могут размещаться поды.
- Под
- Группа контейнеров, работающих на узле, управляемая OpenShift Container Platform.
- Сервис
- Абстракция, представляющая унифицированный сетевой интерфейс, поддерживаемый одним или несколькими модулями.
- Маршрутизатор
- Веб-прокси, который может отображать различные URL-адреса и пути в службы OpenShift Container Platform, чтобы разрешить внешнему трафику проходить в кластер.
- Адрес узла
- IP-адрес узла. Он назначается и управляется владельцем сети, к которой подключен узел. Должен быть доступен с любого узла кластера (главного и клиентского).
- Адрес пода
- IP-адрес модуля. Они назначаются и управляются платформой контейнеров OpenShift. По умолчанию они назначаются из сети 10.128.0.0/14 (или, в более старых версиях, 10.1.0.0/16). Доступен только с клиентских узлов.
- Адрес службы поддержки
- IP-адрес, который представляет службу и внутренне сопоставлен с адресом модуля. Они назначаются и управляются платформой контейнеров OpenShift. По умолчанию они назначаются вне сети 172.30.0.0/16. Доступен только с клиентских узлов.
На следующей диаграмме показаны все элементы, связанные с внешним доступом.
39,3. Отладка внешнего доступа к службе HTTP
Если вы находитесь на машине за пределами кластера и пытаетесь получить доступ к ресурсу, предоставленному кластером, в модуле должен быть запущен процесс, который прослушивает общедоступный IP-адрес и «направляет» этот трафик внутри кластера.Маршрутизатор OpenShift Container Platform служит этой цели для HTTP, HTTPS (с SNI), WebSockets или TLS (с SNI).
Предполагая, что вы не можете получить доступ к HTTP-сервису извне кластера, давайте начнем с воспроизведения проблемы в командной строке машины, на которой происходит сбой. Пытаться:
curl -kv http://foo.example.com:8000/bar # Но замените аргумент своим URL-адресом
Если это сработает, воспроизводите ли вы ошибку в нужном месте? Также возможно, что в сервисе есть некоторые модули, которые работают, а некоторые — нет.Так что сразу переходите к Разделу 39.4, «Отладка маршрутизатора».
Если это не удалось, давайте разрешим DNS-имя в IP-адрес (при условии, что это еще не один):
dig + short foo.example.com # Но замените имя хоста своим
Если при этом не возвращается IP-адрес, пора устранить неполадки с DNS, но это выходит за рамки данного руководства.
Убедитесь, что полученный вами IP-адрес — это тот IP-адрес, который, как вы ожидаете, будет использовать маршрутизатор.Если это не так, исправьте свой DNS.
Затем используйте ping -c address и tracepath address , чтобы проверить, можете ли вы связаться с хостом маршрутизатора. Возможно, они не будут отвечать на пакеты ICMP, и в этом случае эти тесты не пройдут, но маршрутизатор может быть доступен. В этом случае попробуйте использовать команду telnet для прямого доступа к порту маршрутизатора:
телнет 1.2.3.4 8000
Вы можете получить:
Примерка 1.] '.
Если да, значит, что-то прослушивает порт с IP-адресом. Это хорошо. Нажмите ctrl-] , затем нажмите , введите клавишу и затем введите закрыть , чтобы выйти из telnet. Перейдите к Раздел 39.4, «Отладка маршрутизатора», чтобы проверить другие вещи на маршрутизаторе.
Или вы могли бы получить:
Пробуем 1.2.3.4 ... telnet: подключиться к адресу 1.2.3.4: в соединении отказано
Это говорит нам о том, что маршрутизатор не прослушивает этот порт.См. Раздел 39.4, «Отладка маршрутизатора» для получения дополнительных указаний о том, как настроить маршрутизатор.
Или если вы видите:
Пробуем 1.2.3.4 ... telnet: подключиться к адресу 1.2.3.4: Превышено время ожидания подключения
Это говорит нам о том, что вы не можете ни с чем разговаривать по этому IP-адресу. Проверьте свою маршрутизацию, брандмауэры и наличие маршрутизатора, прослушивающего этот IP-адрес. Чтобы отладить маршрутизатор, см. Раздел 39.4, «Отладка маршрутизатора». Отладка IP-маршрутизации и брандмауэра выходит за рамки этого руководства.
39,4. Отладка роутера
Теперь, когда у вас есть IP-адрес, нам нужно ssh на этот компьютер и проверить, что программное обеспечение маршрутизатора работает на этом компьютере и правильно настроено. Итак, давайте введем ssh и получим административные учетные данные OpenShift Container Platform.
Если у вас есть доступ к учетным данным администратора, но вы больше не вошли в систему как пользователь системы по умолчанию system: admin , вы можете снова войти в систему как этот пользователь в любое время, пока учетные данные все еще присутствуют в вашем файле конфигурации CLI.Следующая команда входит в систему и переключается на проект по умолчанию :
$ oc логин -u система: админ -n по умолчанию
Убедитесь, что роутер работает:
# oc получить конечные точки --namespace = default --selector = router NAMESPACE NAME КОНЕЧНЫЕ ТОЧКИ маршрутизатор по умолчанию 10.128.0.4:80
Если эта команда не работает, значит, ваша конфигурация OpenShift Container Platform нарушена. Исправление этого выходит за рамки этого документа.
Вы должны увидеть в списке одну или несколько конечных точек маршрутизатора, но это не скажет вам, работают ли они на машине с заданным внешним IP-адресом, поскольку IP-адрес конечной точки будет одним из адресов модуля, который является внутренним для кластера. Чтобы получить список IP-адресов хоста маршрутизатора, запустите:
# oc get pods --all-namespaces --selector = router --template = '{{range .items}} HostIP: {{.status.hostIP}} PodIP: {{.status.podIP}} {{ "\ п"}} {{конец}} '
HostIP: 192.168.122.202 PodIP: 10.128.0.4 Вы должны увидеть IP-адрес хоста, соответствующий вашему внешнему адресу. Если вы этого не сделаете, обратитесь к документации маршрутизатора, чтобы настроить модуль маршрутизатора для работы на правильном узле (путем правильной настройки привязки) или обновите свой DNS, чтобы он соответствовал IP-адресам, на которых работают маршрутизаторы.
На этом этапе руководства вы должны находиться на узле, на котором запущен модуль маршрутизатора, но вы по-прежнему не можете заставить HTTP-запрос работать. Сначала нам нужно убедиться, что маршрутизатор сопоставляет внешний URL-адрес с правильной службой, и если это сработает, нам нужно покопаться в этой службе, чтобы убедиться, что все конечные точки достижимы.
Давайте перечислим все маршруты, о которых знает OpenShift Container Platform:
# oc get route --all-namespaces ИМЯ ХОСТ / ПУТЬ ПОРТА ЯЧЕЙКИ СЛУЖБЫ ПРЕКРАЩЕНИЕ TLS незащищенный маршрут www.example.com / test service-name
Если имя хоста и путь из вашего URL не совпадают ни с чем в списке возвращенных маршрутов, вам необходимо добавить маршрут. См. Документацию к роутеру.
Если ваш маршрут присутствует, вам необходимо отладить доступ к конечным точкам.Это то же самое, как если бы вы отлаживали проблемы со службой, поэтому переходите к следующему Разделу 39.5, «Отладка службы».
39,5. Отладка службы
Если вы не можете связаться со службой изнутри кластера (либо потому, что ваши службы не могут взаимодействовать напрямую, либо потому, что вы используете маршрутизатор, и все работает, пока вы не попадете в кластер), то вам необходимо выяснить, какие конечные точки являются конечными точками. связаны с сервисом и отлаживать их.
Во-первых, давайте займемся услугами:
# oc get services --all-namespaces NAMESPACE NAME LABELS SELECTOR IP (S) PORT (S) docker-registry по умолчанию docker-registry = default docker-registry = default 172.30.243.225 5000 / TCP по умолчанию компонент kubernetes = apiserver, provider = kubernetes <нет> 172.30.0.1 443 / TCP маршрутизатор по умолчанию router = router router = router 172.30.213.8 80 / TCP
Вы должны увидеть свою службу в списке. Если нет, то вам нужно определить свой сервис.
IP-адреса, перечисленные в выходных данных службы, являются IP-адресами службы Kubernetes, которые Kubernetes сопоставит с одним из модулей, поддерживающих эту службу. Таким образом, вы должны иметь возможность разговаривать с этим IP-адресом. Но, к сожалению, даже если вы можете, это не означает, что все модули доступны; и если вы не можете, это не значит, что все модули недоступны. Он просто сообщает вам статус и , к которым вас подключил kubeproxy.
Давай все равно протестируем сервис. С одного из ваших узлов:
curl -kv http://172.30.243.225:5000/bar # Замените аргумент IP-адресом вашей службы и портом
Затем давайте выясним, какие модули поддерживают нашу службу (замените docker-registry на имя неисправной службы):
# oc получить конечные точки --selector = docker-registry ИМЯ КОНЕЧНЫХ ТОЧЕК докер-реестр 10.128.2.2:5000
Отсюда мы видим, что конечная точка только одна.Итак, если ваш сервисный тест прошел успешно, а тест маршрутизатора прошел успешно, значит, происходит что-то действительно странное. Но если конечных точек несколько или тест обслуживания не удался, попробуйте следующий для каждой конечной точки . Как только вы определите, какие конечные точки не работают, переходите к следующему разделу.
Сначала проверьте каждую конечную точку (измените URL-адрес, чтобы указать правильный IP-адрес конечной точки, порт и путь):
завиток -kv http://10.128.2.2:5000/bar
Если это сработает, отлично, попробуйте следующий.Если это не удалось, запишите это, и в следующем разделе мы выясним, почему.
Если все они вышли из строя, возможно, локальный узел не работает, перейдите к Раздел 39.7, «Отладка локальной сети».
Если все они сработали, перейдите к Раздел 39.11, «Отладка Kubernetes», чтобы выяснить, почему IP-адрес службы не работает.
39,6. Отладка узла к узлу сети
Используя наш список неработающих конечных точек, нам нужно проверить возможность подключения к узлу.
Убедитесь, что все узлы имеют ожидаемые IP-адреса:
# oc получить hostsubnet ИМЯ HOST HOST IP SUBNET rh71-os1.example.com rh71-os1.example.com 192.168.122.46 10.1.1.0/24 rh71-os2.example.com rh71-os2.example.com 192.168.122.18 10.1.2.0/24 rh71-os3.example.com rh71-os3.example.com 192.168.122.202 10.1.0.0/24
Если вы используете DHCP, они могли измениться. Убедитесь, что имена хостов, IP-адреса и подсети соответствуют ожидаемым.Если какие-либо детали узла изменились, используйте
oc edit hostsubnet, чтобы исправить записи.Убедившись, что адреса узлов и имена узлов верны, перечислите IP-адреса конечных точек и IP-адреса узлов:
# oc get pods --selector = docker-registry \ --template = '{{диапазон .items}} HostIP: {{.status.hostIP}} PodIP: {{.status.podIP}} {{end}} {{"\ n"}}' HostIP: 192.168.122.202 PodIP: 10.128.0.4Найдите IP-адрес конечной точки, который вы записали ранее, найдите его в записи
PodIPи найдите соответствующий адресHostIP.Затем проверьте возможность подключения на уровне узла узла, используя адресHostIP:-
ping -c 3: отсутствие ответа может означать, что промежуточный маршрутизатор использует трафик ICMP. tracepath: показывает IP-маршрут, принятый к цели, если пакеты ICMP возвращаются всеми переходами.Если и
tracepath, иpingне работают, поищите проблемы с подключением к вашей локальной или виртуальной сети.
-
Для локальной сети проверьте следующее:
Проверьте маршрут, который пакет берет из коробки к целевому адресу:
# ip route get 192.168.122.202 192.168.122.202 dev ens3 src 192.168.122.46 кэшВ приведенном выше примере он выйдет из интерфейса с именем
ens3с исходным адресом192.168.122.46и перейдет непосредственно к цели.Если это то, что вы ожидали, используйтеip a show dev ens3, чтобы получить подробную информацию об интерфейсе и убедиться, что это ожидаемый интерфейс.Альтернативный результат может быть следующим:
# ip route get 192.168.122.202 1.2.3.4 через 192.168.122.1 dev ens3 src 192.168.122.46
Он будет проходить через
через значение IPдля соответствующей маршрутизации. Убедитесь, что трафик маршрутизируется правильно. Отладка трафика маршрута выходит за рамки этого руководства.
Другие варианты отладки для сети между узлами могут быть решены следующим образом:
- Есть ли у вас Ethernet-соединение на обоих концах? Найдите
Ссылка обнаружена: дана выходе изethtool. - Правильны ли настройки дуплекса и скорости Ethernet на обоих концах? Просмотрите остальную часть информации
ethtool. - Правильно ли подключены кабели? К правильным портам?
- Правильно ли настроены переключатели?
После того, как вы убедились, что соединение между узлами в порядке, нам нужно взглянуть на конфигурацию SDN на обоих концах.
39,7. Отладка локальной сети
На этом этапе у нас должен быть список из одной или нескольких конечных точек, с которыми вы не можете взаимодействовать, но которые имеют соединение между узлами.Для каждого из них нам нужно выяснить, что не так, но сначала вам нужно понять, как SDN настраивает сеть на узле для разных модулей.
39.7.1. Интерфейсы на узле
Это интерфейсы, которые создает OpenShift SDN:
-
br0: Устройство моста OVS, к которому будут прикреплены контейнеры. OpenShift SDN также настраивает на этом мосту набор правил потока, не зависящих от подсети. -
tun0: внутренний порт OVS (порт 2 наbr0).Ему назначается адрес шлюза подсети кластера, и он используется для доступа к внешней сети. OpenShift SDN настраивает сетевой фильтр -
vxlan_sys_4789: устройство OVS VXLAN (порт 1 наbr0), которое обеспечивает доступ к контейнерам на удаленных узлах. В правилах OVS обозначается какvxlan0. -
vethX(в основном netns): одноранговый узел виртуального ethernet Linuxeth0в netns Docker.Он будет подключен к мосту OVS на одном из других портов.
39.7.2. SDN-потоки внутри узла
В зависимости от того, к чему вы пытаетесь получить доступ (или от чего хотите получить доступ), путь будет варьироваться. SDN соединяется в четырех разных местах (внутри узла). На схеме выше они отмечены красным цветом.
- Pod: Трафик идет от одного модуля к другому на одном компьютере (с 1 на другой 1)
- Удаленный узел (или модуль): Трафик идет от локального модуля к удаленному узлу или модулю в том же кластере (от 1 до 2).
- Внешний компьютер: Трафик идет от локального модуля за пределами кластера (от 1 до 3)
Конечно, возможны и обратные транспортные потоки.
39.7.3.1. Включена ли переадресация IP?
Убедитесь, что для sysctl net.ipv4.ip_forward установлено значение 1 (и проверьте хост, если это виртуальная машина)
39.7.3.2. Ваши маршруты правильные?
Проверьте таблицы маршрутов с ip route :
# ip route по умолчанию через 192.168.122.1 dev ens3 10.128.0.0/14 dev tun0 proto kernel scope link # Это отправляет весь трафик подов в OVS 10.128.2.0 / 23 dev tun0 proto kernel scope link src 10.128.2.1 # Это трафик, идущий в локальные поды, перекрывающий вышеуказанное 169.254.0.0/16 dev ens3 scope link metric 1002 # Это для Zeroconf (может отсутствовать) 172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.42.1 # Частные IP-адреса Docker ... используются только вещами, напрямую настроенными докером; не OpenShift 192.168.122.0/24 dev ens3 proto kernel scope link src 192.168.122.46 # Физический интерфейс в локальной подсети
Вы должны увидеть 10.128.x.x строк (при условии, что в вашей конфигурации для вашей сети модулей задан диапазон по умолчанию). Если вы этого не сделаете, проверьте журналы OpenShift Container Platform (см. Раздел 39.10, «Чтение журналов»).
39.7.4. Правильно ли настроен Open vSwitch (OVS)?
Вы должны запустить команды ovs-vsctl и ovs-ofctl на одном из модулей OVS.
Чтобы вывести список модулей OVS, введите следующую команду:
$ oc получить pod -n openshift-sdn -l app = ovs
Проверьте мосты Open vSwitch с обеих сторон.Замените именем одного из модулей OVS.
$ oc exec -n openshift-sdn- ovs-vsctl list-br br0
Предыдущая команда должна вернуть br0 .
Вы можете перечислить все порты, о которых знает OVS:
$ oc exec -n openshift-sdn- ovs-ofctl -O OpenFlow13 dump-ports-desc br0 OFPST_PORT_DESC ответ (OF1.3) (xid = 0x2): 1 (vxlan0): адрес: 9e: f1: 7d: 4d: 19: 4f config: 0 состояние: 0 скорость: 0 Мбит / с сейчас, 0 Мбит / с макс. 2 (tun0): адрес: 6a: ef: 90: 24: a3: 11 config: 0 состояние: 0 скорость: 0 Мбит / с сейчас, 0 Мбит / с макс. 8 (vethe19c6ea): адрес: 1e: 79: f3: a0: e8: 8c config: 0 состояние: 0 ток: 10GB-FD МЕДЬ скорость: 10000 Мбит / с сейчас, 0 Мбит / с макс. ЛОКАЛЬНЫЙ (br0): адрес: 0a: 7f: b4: 33: c2: 43 config: PORT_DOWN состояние: LINK_DOWN скорость: сейчас 0 Мбит / с, макс.0 Мбит / с
В частности, устройства vethX для всех активных модулей должны быть указаны как порты.
Затем перечислите потоки, которые настроены на этом мосту:
$ oc exec -n openshift-sdn- ovs-ofctl -O OpenFlow13 дамп-потоки br0
Результаты будут немного отличаться в зависимости от того, используете ли вы подключаемый модуль ovs-subnet или ovs-multitenant , но есть некоторые общие вещи, которые вы можете найти:
- Каждый удаленный узел должен иметь поток, соответствующий
tun_src =(для входящего трафика VXLAN от этого узла) и другой поток, включая действиеset_field:(для исходящего трафика VXLAN на этот узел).-> tun_dst - У каждого локального модуля должны быть потоки, соответствующие
arp_spa =иarp_tpa =(для входящего и исходящего трафика ARP для этого модуля), а также потоки, соответствующиеnw_src =иnwod_dst_dress = pod_dst >(для входящего и исходящего IP-трафика для этого модуля).
Если какие-то потоки отсутствуют, посмотрите Раздел 39.10, «Чтение журналов».
39.7.4.1. Правильная ли конфигурация
iptables ? Проверьте вывод iptables-save , чтобы убедиться, что вы не фильтруете трафик. Однако OpenShift Container Platform устанавливает правила iptables во время нормальной работы, поэтому не удивляйтесь, увидев там записи.
39.7.4.2. Ваша внешняя сеть правильная?
Проверьте внешние брандмауэры, если таковые имеются, разрешают трафик на целевой адрес (это зависит от сайта и выходит за рамки данного руководства).
39,8. Отладка виртуальной сети
39.8.1. Сборки в виртуальной сети не работают
Если вы устанавливаете платформу OpenShift Container Platform с использованием виртуальной сети (например, OpenStack), и при построении происходит сбой, максимальная единица передачи (MTU) хоста целевого узла может быть несовместима с MTU основного сетевого интерфейса (для Например, eth0 ).
Для успешного завершения сборки MTU SDN должен быть меньше MTU сети eth0, чтобы данные передавались между узлами.
Проверьте MTU вашей сети, выполнив команду
ip addr:# ip адрес --- 2: eth0:
MTU указанной выше сети составляет 1500.
MTU в конфигурации вашего узла должно быть меньше сетевого значения. Проверьте
mtuв конфигурации узла целевого узла:# $ oc описать configmaps node-config-infra ... networkConfig: MTU: 1450 networkPluginName: компания / openshift-ovs-subnet ...
В приведенном выше файле конфигурации узла значение
mtuменьше сетевого MTU, поэтому настройка не требуется.Если значениеmtuбыло выше, отредактируйте файл и уменьшите значение, по крайней мере, на 50 единиц меньше, чем MTU основного сетевого интерфейса, а затем перезапустите службу узла. Это позволит передавать большие пакеты данных между узлами.Чтобы изменить узел в кластере, обновите карты конфигурации узлов по мере необходимости. Не редактируйте вручную файл
node-config.yaml.
39,9. Отладка Pod Egress
Если вы пытаетесь получить доступ к внешней службе из модуля, например.грамм.:
curl -kv github.com
Убедитесь, что DNS разрешается правильно:
dig + search + noall + ответ github.com
Это должно вернуть IP-адрес для сервера github, но убедитесь, что вы вернули правильный адрес. Если вы не получили никакого адреса или адреса одной из ваших машин, возможно, вы соответствуете записи с подстановочным знаком на вашем локальном DNS-сервере.
Чтобы исправить это, вам нужно либо убедиться, что DNS-сервер, имеющий запись с подстановочными знаками, не указан как сервер имен в вашем / etc / resolv.conf или необходимо убедиться, что домен с подстановочными знаками не указан в списке search .
Если был возвращен правильный IP-адрес, попробуйте выполнить рекомендации по отладке, перечисленные выше в Раздел 39.7, «Отладка локальной сети». Ваш трафик должен покинуть Open vSwitch на порту 2, чтобы пройти через правила iptables , а затем выйти из таблицы маршрутизации в обычном режиме.
Выполните: journalctl -u atomic-openshift-node.service --boot | менее
Найдите строку Output of setup script: .Все, что начинается с «+» ниже, это шаги скрипта. Просмотрите это на предмет очевидных ошибок.
Следуя сценарию, вы должны увидеть строки с Результат добавления таблицы = 0 . Это правила OVS, и ошибок быть не должно.
39.11. Отладка Kubernetes
Проверьте iptables -t nat -L , чтобы убедиться, что служба NAT использует правильный порт на локальном компьютере для kubeproxy .
Скоро все изменится … Kubeproxy удаляется и заменяется решением только для iptables .
39.12. Поиск сетевых проблем с помощью средства диагностики
Как администратор кластера запустите средство диагностики для диагностики распространенных сетевых проблем:
# oc adm диагностика NetworkCheck
Средство диагностики выполняет серию проверок на предмет наличия ошибок для указанного компонента. См. Раздел «Инструмент диагностики» для получения дополнительной информации.
По умолчанию oc adm Diagnostics NetworkCheck регистрирует ошибки в / tmp / openshift / .Это можно настроить с помощью параметра --network-logdir :
# oc adm диагностика NetworkCheck --network-logdir = <путь / к / каталогу>
39.13. Разные примечания
39.13.1. Прочие пояснения по входу
- Kube — объявите службу как NodePort, и она будет запрашивать этот порт на всех машинах в кластере (на каком интерфейсе?), А затем перенаправить на kube-proxy, а затем на вспомогательный модуль. См. Https: // kubernetes.io / docs / concept / services -etwork / service / # type-nodeport (какой-то узел должен быть доступен извне)
- Kube — объявите как LoadBalancer, и что-то , которое вы должны написать, сделает все остальное
- OS / AE — оба используют роутер
39.13.2. Время ожидания подтверждения TLS
Если модуль не удается развернуть, проверьте его журнал докеров на предмет тайм-аута подтверждения TLS:
$ журнал докеров... [...] не удалось получить развертывание [...] Тайм-аут подтверждения TLS ...
Это условие и, как правило, ошибки при установлении безопасного соединения могут быть вызваны большой разницей в значениях MTU между tun0 и первичным интерфейсом (например, eth0), например, когда tun0 MTU составляет 1500, а eth0 MTU — 9000 (jumbo кадры).
39.13.3. Прочие примечания по отладке
- Одноранговые интерфейсы (пары виртуальных сетей Linux) можно определить с помощью
ethtool -S ifname - Тип драйвера:
ethtool -i ifname
Сеть | Руководство по Elasticsearch [7.15]
Каждый узел Elasticsearch имеет два разных сетевых интерфейса. Клиенты отправляют запросы на API-интерфейсы REST Elasticsearch, использующие его HTTP-интерфейс, но узлы общаться с другими узлами с помощью транспорта интерфейс. Транспортный интерфейс также используется для связи с удаленные кластеры.
Вы можете настроить оба этих интерфейса одновременно, используя
Сеть . * Настройки . Если у вас более сложная сеть, вам может потребоваться
настроить интерфейсы независимо с помощью http.* и транспорт. * настройки. По возможности используйте сеть . * Настройки , применимые к обоим
интерфейсы для упрощения конфигурации и уменьшения дублирования.
По умолчанию Elasticsearch привязывается только к localhost , что означает, что к нему нельзя получить доступ
удаленно. Такой конфигурации достаточно для локального кластера разработки, созданного
одного или нескольких узлов, работающих на одном хосте. Чтобы сформировать кластер по
несколько хостов или доступный для удаленных клиентов, необходимо настроить некоторые
сетевые настройки, такие как сеть .хост .
Будьте осторожны с настройкой сети!
Никогда не открывайте незащищенный узел общедоступному Интернету. Если да, то ты разрешение кому-либо в мире загружать, изменять или удалять любые данные в вашем кластере.
Настройка Elasticsearch для привязки к нелокальному адресу преобразует некоторые предупреждения в фатальные исключения. Если узел отказывается запускаться после настройки его сетевые настройки, то вы должны устранить зарегистрированные исключения перед продолжаются.
Часто используемые настройки сетиправить
Большинству пользователей потребуется настроить только следующие параметры сети.
-
network.host (Статический) Устанавливает адрес этого узла как для HTTP, так и для транспортного трафика. Узел будет связываться с этим адресом и также будет использовать его в качестве адреса публикации. Принимает IP-адрес, имя хоста или специальное значение.
По умолчанию
_local_.-
http.порт (Статический) Порт для связи с HTTP-клиентом. Принимает одно значение или диапазон. Если указан диапазон, узел будет привязан к первому доступному порту. В диапазоне.
По умолчанию
9200-9300.-
транспорт. Порт (Статический) Порт для связи между узлами. Принимает одно значение или диапазон. Если указан диапазон, узел будет привязан к первому доступному порту. В диапазоне.Установите этот параметр на один порт, а не на диапазон, на каждом узел, имеющий право на владение мастером.
По умолчанию
9300-9400.
Специальные значения для сетевых адресовправить
Вы можете настроить Elasticsearch для автоматического определения его адресов с помощью
следующие особые значения. Используйте эти значения при настройке network.host , network.bind_host , network.publish_host и
соответствующие настройки для HTTP и транспортного интерфейсов.
-
_local_ - Любые адреса обратной связи в системе, например
127.0.0.1. -
_ сайт_ - Любые локальные адреса сайта в системе, например
192.168.0.1. -
_global_ - Любые глобальные адреса в системе, например
8.8.8.8. -
_ [сетевой интерфейс] _ - Используйте адреса сетевого интерфейса под названием
[networkInterface].Для Например, если вы хотите использовать адреса интерфейса с именемen0, тогда установитьnetwork.host: _en0_. -
0,0.0.0 - Адреса всех доступных сетевых интерфейсов.
В некоторых системах эти специальные значения разрешаются по нескольким адресам. Если поэтому Elasticsearch выберет один из них в качестве адреса публикации и может изменить свой выбор при каждом перезапуске узла. Убедитесь, что ваш узел доступен во всех возможных случаях. адрес.
Любые значения, содержащие : (например, адрес IPv6 или некоторые из
специальные значения) должны быть указаны, потому что : — это
специальный символ в YAML.
Эти специальные значения по умолчанию дают адреса IPv4 и IPv6, но вы можете
также добавьте суффикс : ipv4 или : ipv6 , чтобы ограничить их только IPv4 или IPv6
адреса соответственно. Например, network.host: _en0: ipv4_ установит это
адреса узла на IPv4-адреса интерфейса en0 .
Переплет и публикация
Elasticsearch использует сетевые адреса для двух разных целей, известных как привязка и издательский. Большинство узлов будут использовать один и тот же адрес для всего, но больше сложные настройки могут потребовать настройки разных адресов для разных целей.
Когда приложение, такое как Elasticsearch, хочет получать сетевые сообщения, оно должен указать операционной системе адрес или адреса, трафик которых он должен получить.Это известно как привязка к этим адресам. Elasticsearch может связываться с при необходимости более одного адреса, но большинство узлов привязываются только к одному адресу. Elasticsearch может связываться с адресом только в том случае, если он запущен на хосте, у которого есть сеть. интерфейс с этим адресом. При необходимости можно настроить транспорт и HTTP-интерфейсы для привязки к разным адресам.
Каждый узел Elasticsearch имеет адрес, по которому клиенты и другие узлы могут связаться с ним, известный как его адрес публикации .Каждый узел имеет один адрес публикации для своего HTTP интерфейс и один для его транспортного интерфейса. Эти два адреса могут быть ничего, и не обязательно должны быть адресами сетевых интерфейсов на хосте. Единственные требования: каждый узел должен быть:
- Доступен по адресу транспортной публикации для всех остальных узлами в своем кластере и любыми удаленными кластерами, которые обнаружат его, используя Режим сниффинга.
- Доступен по адресу публикации HTTP для всех клиентов который обнаружит это с помощью обнюхивания.
Использование одного адреса
Наиболее распространенная конфигурация — привязка Elasticsearch к одному адресу, по которому
он доступен для клиентов и других узлов. В этой конфигурации вы должны
просто установите network.host на этот адрес. Вы не должны отдельно устанавливать какую-либо привязку
или публиковать адреса, а также вам не следует отдельно настраивать адреса для
HTTP или транспортные интерфейсы.
Использование нескольких адресовправить
Используйте расширенные сетевые настройки, если хотите
привязать Elasticsearch к нескольким адресам или опубликовать другой адрес из
адреса, к которым вы привязаны.Установите network.bind_host на привязку
адресов и network.publish_host на адрес, по которому этот узел
незащищенный. В сложных конфигурациях вы можете настроить эти адреса
по-разному для HTTP и транспортного интерфейсов.
Расширенные настройки сетиправить
Эти расширенные настройки позволяют выполнять привязку к нескольким адресам или использовать разные адреса для переплета и публикации. В большинстве случаев они не требуются и вам не следует использовать их, если вы можете использовать обычно вместо этого использовал настройки.
-
network.bind_host - (Статический)
Сетевой адрес (а), к которому узел должен привязаться, чтобы прослушивать
входящие соединения. Принимает список IP-адресов, имен хостов и
особые ценности. По умолчанию используется адрес, предоставленный
network.host. Используйте этот параметр, только если привязка к нескольким адресам или использование разные адреса для публикации и переплета. -
network.publish_host - (Статический)
Сетевой адрес, который клиенты и другие узлы могут использовать для связи с этим узлом.Принимает IP-адрес, имя хоста или специальный
ценить. По умолчанию используется адрес
network.host. Используйте только этот параметр если привязка к нескольким адресам или использование разных адресов для публикации и переплет.
Вы можете указать список адресов для network.host и network.publish_host . Вы также можете указать одно или несколько имен хостов или
специальные значения, которые разрешаются по нескольким адресам.
Если вы это сделаете, Elasticsearch выберет один из адресов для своего адреса публикации.Этот выбор использует эвристику на основе предпочтений стека IPv4 / IPv6 и
достижимость и может измениться при перезапуске узла. Гарантировать
каждый узел доступен по всем возможным адресам публикации.
Расширенные настройки TCPправить
Используйте следующие настройки для управления низкоуровневыми параметрами TCP. соединения, используемые HTTP и транспортными интерфейсами.
-
network.tcp.no_delay - (Статический)
Включение или отключение TCP без задержки
параметр.По умолчанию
истинно. -
network.tcp.keep_alive - (Статический)
Настраивает параметр
SO_KEEPALIVEдля этого сокета, который определяет, отправляет ли он зонды поддержки активности TCP. -
network.tcp.keep_idle - (Статический)
Настраивает параметр
TCP_KEEPIDLEдля этого сокета, который определяет время в секундах, в течение которого соединение должно быть бездействующим, прежде чем начинает посылать TCP keepalive-зонды. По умолчанию-1, который использует системное значение по умолчанию.Это значение не может превышать300секунд. Применимо только в Linux и macOS, и требует Java 11 или новее. -
network.tcp.keep_interval - (Статический)
Настраивает опцию
TCP_KEEPINTVLдля этого сокета, который определяет время в секундах между отправкой TCP keepalive-зондов. По умолчанию-1, который использует системное значение по умолчанию. Это значение не может превышать300секунд. Применимо только в Linux и macOS и требует Java 11 или новее. -
network.tcp.keep_count - (Статический)
Настраивает параметр
TCP_KEEPCNTдля этого сокета, который определяет количество неподтвержденных проверок активности TCP, которые могут быть отправлено по соединению, прежде чем оно будет отброшено. По умолчанию-1, который использует системное значение по умолчанию. Применимо только в Linux и macOS и требует Java 11 или новее. -
network.tcp.reuse_address - (Статический)
Следует ли использовать адрес повторно или нет.По умолчанию
истиннодля не Windows машины. -
network.tcp.send_buffer_size - (Статический) Размер буфера отправки TCP (указывается в единицах размера). По умолчанию явно не задано.
-
network.tcp.receive_buffer_size - (Статический) Размер приемного буфера TCP (указывается в единицах размера). По умолчанию явно не задано.
Расширенные настройки HTTPправить
Используйте следующие дополнительные параметры для настройки интерфейса HTTP. независимо от транспортного интерфейса.Вы также можете настроить оба интерфейса вместе, используя сетевые настройки.
-
http.host (Статический) Устанавливает адрес этого узла для HTTP-трафика. Узел будет привязан к этому адрес, а также будет использовать его в качестве адреса публикации HTTP. Принимает IP адрес, имя хоста или специальное значение. Используйте этот параметр, только если вам требуются другие конфигурации для транспортный и HTTP-интерфейсы.
По умолчанию используется адрес, предоставленный сетью
.хост.-
http.bind_host - (Статический)
Сетевой адрес (а), к которому узел должен привязаться, чтобы прослушивать
входящие HTTP-соединения. Принимает список IP-адресов, имен хостов и
особые ценности. По умолчанию используется адрес, предоставленный
http.hostилиnetwork.bind_host. Используйте этот параметр, только если вам необходимо привязать к нескольким адресам или использовать разные адреса для публикации и привязки, и вам также потребуются разные конфигурации привязки для транспортный и HTTP-интерфейсы. -
http.publish_host - (Статический)
Сетевой адрес, по которому HTTP-клиенты могут связываться с узлом с помощью сниффинга.
Принимает IP-адрес, имя хоста или специальный
ценить. По умолчанию используется адрес
http.hostилиnetwork.publish_host. Используйте этот параметр, только если вам нужно выполнить привязку к несколько адресов или использовать разные адреса для публикации и привязки, и вам также требуются разные конфигурации привязки для транспорта и HTTP-интерфейсы. -
http.publish_port - (Статический)
Порт адреса публикации HTTP.
Настройте этот параметр, только если вам нужно, чтобы порт публикации отличался от
http.port. По умолчанию используется порт, назначенный черезhttp.port. -
http.max_content_length - (Статический)
Максимальный размер тела HTTP-запроса. По умолчанию
100 МБ. -
http.max_initial_line_length - (Статический)
Максимальный размер URL-адреса HTTP.По умолчанию
4 КБ. -
http.max_header_size - (Статический)
Максимальный размер разрешенных заголовков. По умолчанию
8kb.
-
http.compression (Статический) Поддержка сжатия, когда это возможно (с Accept-Encoding). Если HTTPS включен, по умолчанию
false. В противном случае по умолчанию используется значение, истинное значение.Отключение сжатия для HTTPS снижает потенциальные риски безопасности, такие как BREACH атака.Чтобы сжать HTTPS-трафик, вы должны явно установить
http.compressionнаtrue.-
http.compression_level - (Статический)
Определяет уровень сжатия для HTTP-ответов. Допустимые значения находятся в диапазоне от 1 (минимальное сжатие) до 9 (максимальное сжатие). По умолчанию
3.
-
http.cors.enabled (Статический) Включите или отключите совместное использование ресурсов между источниками, которое определяет, может ли браузер другого источника выполнять запросы к Elasticsearch.Установите значение
true, чтобы разрешить Elasticsearch выполнять предполетную обработку. CORS запросы. Elasticsearch ответит на эти запросы заголовкомAccess-Control-Allow-Origin, если отправленный в запросеOriginразрешен спискомhttp.cors.allow-origin. Установите значениеfalse(по умолчанию), чтобы Elasticsearch игнорировал заголовок запросаOrigin, эффективно отключая запросы CORS, поскольку Elasticsearch никогда не будет отвечать заголовком ответаAccess-Control-Allow-Origin.Если клиент не отправляет предполетный запрос с заголовком
Originили не проверяет заголовки ответа с сервера, чтобы проверить правильностьAccess-Control-Allow-Originзаголовок ответа, тогда безопасность перекрестного происхождения скомпрометирован. Если CORS не включен в Elasticsearch, единственный способ узнать об этом клиент — это отправить предполетный запрос и понять, что требуемые заголовки ответа отсутствуют.
-
http.cors.разрешить происхождение (Статический) Какое происхождение разрешить. Если вы добавите перед значением косую черту (
/), это будет рассматриваться как регулярное выражение, позволяющее поддерживать HTTP и HTTP. Например, использование/ https?: \ / \ / Localhost (: [0-9] +)? /вернет заголовок запроса соответствующим образом в обоих случаях. По умолчанию происхождение не разрешено.Подстановочный знак (
*) является допустимым значением, но считается угрозой безопасности, поскольку ваш экземпляр Elasticsearch открыт для запросов с перекрестным источником из в любом месте .
-
http.cors.max-age - (Статический)
Браузеры отправляют предварительный запрос OPTIONS для определения настроек CORS.
max-ageопределяет, как долго результат должен храниться в кэше. По умолчанию1728000(20 дней).
-
http.cors.allow-methods - (Статический)
Какие методы разрешить. По умолчанию
OPTIONS, HEAD, GET, POST, PUT, DELETE.
-
http.cors.allow-заголовки - (Статический)
Какие заголовки разрешить. По умолчанию
X-Requested-With, Content-Type, Content-Length.
-
http.cors.allow-credentials (Статический) Должен ли возвращаться заголовок
Access-Control-Allow-Credentials. По умолчаниюfalse.Этот заголовок возвращается, только если для параметра установлено значение
true.
-
http.detail_errors.enabled (Статический) Если
истинно, включает вывод подробных сообщений об ошибках и трассировки стека в выходных данных ответа. По умолчаниюистинно.Если
false, используйте параметрerror_trace, чтобы включить трассировку стека и вернуть подробные сообщения об ошибках. В противном случае будет возвращено только простое сообщение.-
http.pipelining.max_events - (Статический)
Максимальное количество событий, которые должны быть поставлены в очередь в памяти до закрытия HTTP-соединения, по умолчанию —
10000. -
http.max_warning_header_count - (Статический)
Максимальное количество заголовков предупреждений в HTTP-ответах клиента. По умолчанию
без ограничений. -
http.max_warning_header_size - (Статический)
Максимальный общий размер заголовков предупреждений в HTTP-ответах клиента. По умолчанию
без ограничений. -
http.tcp.no_delay - (Статический)
Включение или отключение TCP без задержки
параметр. По умолчанию сеть
.tcp.no_delay. -
http.tcp.keep_alive - (Статический)
Настраивает параметр
SO_KEEPALIVEдля этого сокета, который определяет, отправляет ли он зонды поддержки активности TCP. По умолчанию —network.tcp.keep_alive. -
http.tcp.keep_idle - (Статический) Настраивает параметр
TCP_KEEPIDLEдля этого сокета, который определяет время в секундах, в течение которого соединение должно быть бездействующим, прежде чем начинает посылать TCP keepalive-зонды.По умолчаниюnetwork.tcp.keep_idle, который использует системное значение по умолчанию. Это значение не может превышать300секунд. Применимо только на Linux и macOS, требуется Java 11 или новее. -
http.tcp.keep_interval - (Статический) Настраивает параметр
TCP_KEEPINTVLдля этого сокета, который определяет время в секундах между отправкой TCP keepalive-зондов. По умолчанию —network.tcp.keep_interval, который использует системное значение по умолчанию.Это значение не может превышать300секунд. Применимо только в Linux и macOS и требует Java 11 или новее. -
http.tcp.keep_count - (Статический) Настраивает параметр
TCP_KEEPCNTдля этого сокета, который определяет количество неподтвержденных проверок активности TCP, которые могут быть отправлено по соединению, прежде чем оно будет отброшено. По умолчаниюnetwork.tcp.keep_count, который использует системное значение по умолчанию. Применимо только в Linux и macOS, и требуется Java 11 или новее. -
http.tcp.reuse_address - (Статический)
Следует ли использовать адрес повторно или нет. По умолчанию
network.tcp.reuse_address. -
http.tcp.send_buffer_size - (Статический)
Размер буфера отправки TCP (указывается в единицах размера).
По умолчанию
network.tcp.send_buffer_size. -
http.tcp.receive_buffer_size - (Статический)
Размер приемного буфера TCP (указывается в единицах размера).По умолчанию
network.tcp.receive_buffer_size. -
http.client_stats.enabled - (Динамический)
Включение или отключение сбора статистики HTTP-клиента. По умолчанию
истинно.
Расширенные настройки транспортаправить
Используйте следующие дополнительные параметры для настройки транспортного интерфейса. независимо от интерфейса HTTP. Использовать сеть настройки для одновременной настройки обоих интерфейсов.
-
транспорт.хост (Статический) Устанавливает адрес этого узла для транспортного трафика. Узел будет привязан к этому адрес, а также будет использовать его как свой транспортный адрес публикации. Принимает IP адрес, имя хоста или специальное значение. Используйте этот параметр, только если вам требуются другие конфигурации для транспортный и HTTP-интерфейсы.
По умолчанию используется адрес, предоставленный
network.host.-
transport.bind_host - (Статический)
Сетевой адрес (а), к которому узел должен привязаться, чтобы прослушивать
входящие транспортные сообщения.Принимает список IP-адресов, имен хостов и
особые ценности. По умолчанию используется адрес, предоставленный
transport.hostилиnetwork.bind_host. Используйте этот параметр, только если вам требуется привязать к нескольким адресам или использовать разные адреса для публикации и привязки, и вам также потребуются разные конфигурации привязки для транспортный и HTTP-интерфейсы. -
transport.publish_host - (Статический)
Сетевой адрес, по которому к узлу могут связываться другие узлы.Принимает
IP-адрес, имя хоста или специальное значение.
По умолчанию используется адрес
transport.hostилиnetwork.publish_host. Используйте этот параметр, только если вам требуется привязка к нескольким адресам или использование разные адреса для публикации и переплета, и вам также потребуются разные конфигурации привязки для транспортного и HTTP-интерфейсов. -
transport.publish_port - (Статический)
Порт транспорта опубликовать
адрес. Устанавливайте этот параметр только в том случае, если вам нужно, чтобы порт публикации был
отличается от
транспорта.порт. По умолчанию порт назначен черезтранспорт. Порт. -
transport.connect_timeout - (Статический)
Тайм-аут подключения для инициации нового подключения (в
формат установки времени). По умолчанию
30 с. -
transport.compress - (Статический)
Установите значение
true,indexing_dataилиfalseдля настройки транспортного сжатия между узлами. Параметрtrueсжимает все данные.Опцияindexing_dataбудет сжимать только необработанные данные индекса, передаваемые между узлами во время прием, отслеживание ccr (за исключением начальной загрузки) и восстановление сегментов на основе операций (за исключением передачи файлов Lucene). По умолчаниюfalse. -
transport.compression_scheme - (Статический)
Настраивает схему сжатия для
transport.compress. Вариантыdeflateилиlz4. Еслиlz4настроен и удаленный узел не был при обновлении до версии, поддерживающейlz4, трафик будет отправляться без сжатия.По умолчаниюсдувает. -
transport.ping_schedule - (Статический)
Запланируйте регулярное сообщение ping на уровне приложения
чтобы гарантировать, что транспортные соединения между узлами поддерживаются. По умолчанию
5sв транспортном клиенте и-1(отключено) в другом месте. Желательно для правильной настройки пакетов поддержки активности TCP вместо использования этой функции, потому что Протоколы активности TCP применяются ко всем видам долгоживущих соединений, а не только к транспортное сообщение. -
transport.tcp.no_delay - (Статический)
Включение или отключение TCP без задержки
параметр. По умолчанию
network.tcp.no_delay. -
transport.tcp.keep_alive - (Статический)
Настраивает параметр
SO_KEEPALIVEдля этого сокета, который определяет, отправляет ли он зонды поддержки активности TCP. По умолчанию —network.tcp.keep_alive. -
transport.tcp.keep_idle - (Статический)
Настраивает параметр
TCP_KEEPIDLEдля этого сокета, который определяет время в секундах, в течение которого соединение должно быть бездействующим, прежде чем начинает посылать TCP keepalive-зонды.По умолчаниюnetwork.tcp.keep_idle, если установлено, в противном случае — системное значение по умолчанию. Это значение не может превышать300секунд. В случаях, когда система по умолчанию больше300, значение автоматически понижается до300. Применимо только на Linux и macOS, требуется Java 11 или новее. -
transport.tcp.keep_interval - (Статический)
Настраивает опцию
TCP_KEEPINTVLдля этого сокета, который определяет время в секундах между отправкой TCP keepalive-зондов.По умолчанию используется значениеnetwork.tcp.keep_interval, если установлено, или системное значение по умолчанию в противном случае. Это значение не может превышать300секунд. В случаях, когда значение системы по умолчанию выше300, значение автоматически понижается до300. Применимо только в Linux и macOS, и требует Java 11 или новее. -
transport.tcp.keep_count - (Статический)
Настраивает параметр
TCP_KEEPCNTдля этого сокета, который определяет количество неподтвержденных проверок активности TCP, которые могут быть отправлено по соединению, прежде чем оно будет отброшено.По умолчаниюnetwork.tcp.keep_countесли установлено, или системное значение по умолчанию в противном случае. Применимо только в Linux и macOS, и требуется Java 11 или новее. -
transport.tcp.reuse_address - (Статический)
Следует ли использовать адрес повторно или нет. По умолчанию
network.tcp.reuse_address. -
transport.tcp.send_buffer_size - (Статический)
Размер буфера отправки TCP (указывается в единицах размера).
По умолчанию сеть
.tcp.send_buffer_size. -
transport.tcp.receive_buffer_size - (Статический)
Размер приемного буфера TCP (указывается в единицах размера).
По умолчанию
network.tcp.receive_buffer_size.
Elasticsearch позволяет подключаться к нескольким портам на разных интерфейсах с помощью использование транспортных профилей. См. Этот пример конфигурации
transport.profiles.default.port: 9300-9400 transport.profiles.default.bind_host: 10.0.0.1 transport.profiles.client.port: 9500-9600 transport.profiles.client.bind_host: 192.168.0.1 transport.profiles.dmz.port: 9700-9800 transport.profiles.dmz.bind_host: 172.16.1.2
Профиль по умолчанию является особенным. Он используется как запасной вариант для любых других
профили, если для них не задан конкретный параметр конфигурации, и как
этот узел подключается к другим узлам кластера.
Другие профили могут иметь любое имя и могут использоваться для настройки определенных конечных точек.
для входящих подключений.
Следующие параметры могут быть настроены для каждого транспортного профиля, как в пример выше:
-
порт: порт, к которому нужно выполнить привязку. -
bind_host: хост, к которому нужно выполнить привязку. -
publish_host: хост, опубликованный в информационных API.
также поддерживают все другие транспортные настройки, указанные в
раздел настроек транспорта и используйте их по умолчанию.
Например, транспорт.profile.client.tcp.reuse_address может быть явно
настроен, а по умолчанию — transport.tcp.reuse_address .
Долговечные простаивающие соединенияправить
Транспортное соединение между двумя узлами состоит из нескольких долгоживущих
TCP-соединения, некоторые из которых могут бездействовать в течение длительного периода времени.
Тем не менее, Elasticsearch требует, чтобы эти соединения оставались открытыми, и
может нарушить работу вашего кластера, если какие-либо межузловые соединения
закрыто внешним воздействием, например брандмауэром.Это важно
настройте свою сеть для сохранения длительных неактивных соединений между
Узлы Elasticsearch, например, оставив * .tcp.keep_alive включенным и
обеспечение того, чтобы интервал поддержки активности был короче любого тайм-аута, который может
вызвать закрытие незанятых соединений, или установив transport.ping_schedule , если
Keepalive не может быть настроен. Устройства, которые разрывают соединения, когда достигают
определенный возраст является частым источником проблем для кластеров Elasticsearch, и
нельзя использовать.
По умолчанию для параметра transport.compress установлено значение false и на уровне сети.
сжатие запросов между узлами кластера отключено. Это значение по умолчанию
обычно имеет смысл для локальной связи кластера, поскольку сжатие имеет
заметная стоимость ЦП и локальные кластеры, как правило, настраиваются с быстрой сетью
связи между узлами.
Параметр конфигурации transport.compress indexing_data будет только
запросы сжатия, относящиеся к транспортировке необработанных исходных данных индексации
между узлами.Этот параметр в первую очередь сжимает данные, отправленные во время приема,
ccr и восстановление шарда.
Параметр transport.compress всегда настраивает запрос локального кластера.
сжатие и является резервным параметром для сжатия запроса удаленного кластера.
Если вы хотите настроить сжатие удаленного запроса иначе, чем локальное
сжатие запросов, вы можете установить его для каждого удаленного кластера, используя cluster.remote. $ {Cluster_alias} .transport.compress Настройка .
Параметры сжатия не настраивают сжатие ответов.Elasticsearch будет сжать ответ, если входящий запрос был сжат — даже при сжатии не включен. Точно так же Elasticsearch не сжимает ответ, если входящий запрос был несжатым — даже если сжатие включено. Сжатие схема, используемая для сжатия ответа, будет такой же, как и на удаленном узле. чтобы сжать запрос.
Вы можете отслеживать отдельные запросы, сделанные на HTTP и транспортном уровнях.
Tracing может генерировать чрезвычайно большие объемы журналов, которые могут дестабилизировать ваш кластер.Не включайте трассировку запросов в занятых или важных кластерах.
Уровень HTTP имеет специальный трассировщик, который регистрирует входящие запросы и
соответствующие исходящие ответы. Активируйте трассировщик, установив уровень
регистратор org.elasticsearch.http.HttpTracer на TRACE :
PUT _cluster / настройки
{
"transient": {
"logger.org.elasticsearch.http.HttpTracer": "TRACE"
}
} Вы также можете контролировать, какие URI будут отслеживаться, используя набор включаемых и исключить шаблоны подстановки.По умолчанию отслеживается каждый запрос.
PUT _cluster / настройки
{
"transient": {
"http.tracer.include": "*",
"http.tracer.exclude": ""
}
} Транспортный уровень имеет специальный трассировщик, который регистрирует входящие и исходящие сообщения.
запросы и ответы. Активируйте индикатор, установив уровень org.elasticsearch.transport.TransportService.tracer Регистратор до TRACE :
PUT _cluster / настройки
{
"transient": {
"регистратор.org.elasticsearch.transport.TransportService.tracer ":" TRACE "
}
} Вы также можете контролировать, какие действия будут отслеживаться, используя набор include и исключить шаблоны подстановки. По умолчанию будет отслеживаться каждый запрос, кроме пинги обнаружения неисправностей:
PUT _cluster / настройки
{
"transient": {
"transport.tracer.include": "*",
"transport.tracer.exclude": "внутреннее: координация / дефект_обнаружения / *"
}
} Спецификация кластераRedis — Redis
Добро пожаловать в спецификацию кластера Redis .Здесь вы найдете информацию об алгоритмах и принципах разработки Redis Cluster. Этот документ — работа в процессе, поскольку он постоянно синхронизируется с фактической реализацией Redis.
* Цели Redis Cluster
Redis Cluster — это распределенная реализация Redis со следующими целями в порядке важности в разработке:
- Высокая производительность и линейная масштабируемость до 1000 узлов.Прокси-серверы отсутствуют, используется асинхронная репликация и для значений не выполняются операции слияния.
- Приемлемая степень безопасности записи: система пытается (изо всех сил) сохранить все записи, исходящие от клиентов, связанных с большинством главных узлов. Обычно есть небольшие окна, в которых подтвержденная запись может быть потеряна. Окна для потери подтвержденной записи имеют больший размер, когда клиенты находятся в разделе меньшинства.
- Доступность: Redis Cluster может выжить в разделах, где доступно большинство главных узлов, и есть по крайней мере одна доступная реплика для каждого главного узла, который больше недоступен.Более того, используя миграцию реплик , мастера, больше не реплицируемые никакими репликами, получат реплики от мастера, который покрыт несколькими репликами.
То, что описано в этом документе, реализовано в Redis 3.0 или более поздней версии.
* Реализовано подмножество
Redis Cluster реализует все отдельные ключевые команды, доступные в нераспространяемая версия Redis. Команды выполнения сложных многоклавишных также реализованы такие операции, как объединения или пересечения типов Set пока все ключи хешируются в один и тот же слот.
Redis Cluster реализует концепцию под названием хэш-тегов , которые можно использовать в чтобы заставить определенные ключи храниться в одном и том же хеш-слоте. Однако во время ручная перенастройка, операции с несколькими клавишами могут быть недоступны на некоторое время в то время как операции с одним ключом всегда доступны.
Redis Cluster не поддерживает несколько баз данных, как автономная версия Redis.Есть только база данных 0, и команда SELECT не разрешена.
* Роли клиентов и серверов в протоколе Redis Cluster
В Redis Cluster узлы отвечают за хранение данных, и получение состояния кластера, включая отображение ключей для правильных узлов. Узлы кластера также могут автоматически обнаруживать другие узлы, обнаруживать неработающие узлы, и продвигайте узлы реплик в мастера, когда это необходимо, чтобы продолжать работу при возникновении неисправности.
Для выполнения своих задач все узлы кластера подключены с помощью Шина TCP и двоичный протокол, который называется Redis Cluster Bus . Каждый узел подключен к каждому другому узлу в кластере с помощью кластера. автобус. Узлы используют протокол сплетен для распространения информации о кластере для обнаружения новых узлов, для отправки пакетов ping, чтобы убедиться, что все другие узлы работают правильно, и для отправки сообщений кластера необходимо сигнализировать об особых условиях.Кластерная шина также используется для распространять сообщения Pub / Sub по кластеру и управлять вручную отработка отказа по запросу пользователей (ручная отработка отказа — это отработка отказа, которая инициируются не детектором отказов Redis Cluster, а системный администратор напрямую).
Поскольку узлы кластера не могут отправлять запросы прокси, клиенты могут быть перенаправлены
на другие узлы с использованием ошибок перенаправления -MOVED и -ASK .Теоретически клиент может отправлять запросы всем узлам кластера,
при необходимости перенаправляется, поэтому клиенту не требуется удерживать
состояние кластера. Однако клиенты, которые могут кэшировать карту между
ключи и узлы могут разумным образом улучшить производительность.
* Безопасность записи
КластерRedis использует асинхронную репликацию между узлами, и последнее аварийное переключение побеждает неявную функцию слияния .Это означает, что последний выбранный главный набор данных в конечном итоге заменяет все остальные реплики. Всегда есть промежуток времени, когда можно потерять записи во время разделов. Однако эти окна сильно различаются в случае клиента, который подключен к большинству мастеров, и клиента, который подключен к меньшинству мастеров.
КластерRedis изо всех сил старается сохранить записи, которые выполняются клиентами, подключенными к большинству мастеров, по сравнению с записями, выполняемыми на стороне меньшинства.Ниже приведены примеры сценариев, которые приводят к потере подтвержденного записей, полученных в большинстве разделов во время сбоев:
Запись может быть достигнута мастером, но хотя мастер может отвечать клиенту, запись может не распространяться на реплики через асинхронную репликацию, используемую между главным узлом и узлами реплики. Если мастер умирает, а запись не достигает реплик, запись теряется навсегда, если мастер недоступен в течение достаточно длительного периода, чтобы одна из его реплик была повышена.Обычно это трудно наблюдать в случае полного внезапного отказа главного узла, поскольку мастера пытаются ответить клиентам (с подтверждением записи) и репликам (распространяя запись) примерно в одно и то же время. Однако это реальный режим отказа.
Другой теоретически возможный режим отказа, при котором записи теряются, следующий:
- Мастер недоступен из-за раздела.
- Одна из его реплик сломалась.
- Через некоторое время он снова станет доступным.
- Клиент с устаревшей таблицей маршрутизации может выполнять запись на старый мастер, прежде чем он будет преобразован кластером в реплику (нового мастера).
Второй режим сбоя маловероятен, потому что главные узлы, неспособные обмениваться данными с большинством других мастеров в течение достаточного времени для отработки отказа, больше не будут принимать записи, а когда раздел зафиксирован, в записи по-прежнему отказывают на небольшую сумму времени, чтобы позволить другим узлам сообщать об изменениях конфигурации.Этот режим отказа также требует, чтобы таблица маршрутизации клиента еще не обновлялась.
Записи, нацеленные на меньшинство раздела, имеют большее окно, в котором можно потеряться. Например, Redis Cluster теряет нетривиальное количество операций записи в разделах, где имеется меньшинство мастеров и, по крайней мере, один или несколько клиентов, поскольку все операции записи, отправленные мастерам, потенциально могут быть потеряны, если мастера переключаются на сторона большинства.
В частности, для того, чтобы мастер был отключен, он должен быть недоступен для большинства мастеров в течение как минимум NODE_TIMEOUT , поэтому, если раздел будет исправлен до этого времени, записи не будут потеряны.Когда раздел существует более NODE_TIMEOUT , все записи, выполненные на стороне меньшинства до этого момента, могут быть потеряны. Однако меньшинство кластера Redis начнет отказываться от записи, как только истечет время NODE_TIMEOUT без контакта с большинством, поэтому существует максимальное окно, после которого меньшинство становится недоступным. Следовательно, после этого времени записи не принимаются и не теряются.
* Наличие
Кластер Redis недоступен в меньшинстве раздела.На большей части раздела, предполагая, что существует по крайней мере большинство мастеров и реплика для каждого недоступного мастера, кластер снова становится доступным после NODE_TIMEOUT времени плюс еще несколько секунд, необходимых для того, чтобы реплика была выбрана и отработала отказ. master (отработка отказа обычно выполняется за 1-2 секунды).
Это означает, что Redis Cluster спроектирован так, чтобы выдерживать отказы нескольких узлов в кластере, но это не подходящее решение для приложений, которым требуется доступность в случае больших разделений сети.
В примере кластера, состоящего из N главных узлов, где каждый узел имеет одну реплику, большая часть кластера будет оставаться доступной, пока один узел будет разделен, и останется доступной с вероятностью 1- (1 / (N * 2-1)) , когда два узла разделены (после отказа первого узла у нас остается всего N * 2-1 узлов, и вероятность того, что единственный мастер без реплики будет ошибка 1 / (N * 2-1)) .
Например, в кластере с 5 узлами и одной репликой на узел существует вероятность 1 / (5 * 2-1) = 11,11% , что после того, как два узла будут разделены от большинства, кластер не будет дольше быть доступным.
Благодаря функции Redis Cluster, называемой миграцией реплик кластер доступность улучшается во многих реальных сценариях за счет того, что реплики переносятся на осиротевшие мастера (мастера больше не имеют реплик).Таким образом, при каждом успешном сбое кластер может перенастроить реплики. макет, чтобы лучше противостоять следующему провалу.
* Производительность
В Redis Cluster узлы не передают команды правому узлу, отвечающему за данный ключ, а вместо этого перенаправляют клиентов на правильные узлы, обслуживающие заданную часть пространства ключей.
В конце концов клиенты получают актуальное представление о кластере и о том, какой узел обслуживает какое подмножество ключей, поэтому во время обычных операций клиенты напрямую связываются с нужными узлами, чтобы отправить заданную команду.
Из-за использования асинхронной репликации узлы не ждут подтверждения записи другими узлами (если это явно не запрошено с помощью команды WAIT).
Кроме того, поскольку многоклавишные команды ограничены только рядом с ключами , данные никогда не перемещаются между узлами, кроме как при повторной расшифровке.
Обычные операции обрабатываются точно так же, как и в случае одного экземпляра Redis. Это означает, что в кластере Redis с N главными узлами вы можете рассчитывать на такую же производительность, как у одного экземпляра Redis, умноженного на N, при линейном масштабировании проекта.В то же время запрос обычно выполняется за один круговой обход, поскольку клиенты обычно сохраняют постоянные соединения с узлами, поэтому значения задержки также такие же, как и в случае с одним автономным узлом Redis.
Очень высокая производительность и масштабируемость при сохранении слабых, но разумные формы безопасности и доступности данных — основная цель Redis Cluster.
* Почему избегают операций слияния
Redis Cluster позволяет избежать конфликтующих версий одной и той же пары «ключ-значение» на нескольких узлах, поскольку в случае модели данных Redis это не всегда желательно.Значения в Redis часто очень большие; часто можно увидеть списки или отсортированные наборы с миллионами элементов. Также типы данных семантически сложны. Передача и объединение таких значений может быть серьезным узким местом и / или может потребовать нетривиального участия логики на стороне приложения, дополнительной памяти для хранения метаданных и так далее.
Здесь нет строгих технологических ограничений. CRDT или синхронно реплицируемые конечные автоматы могут моделировать сложные типы данных, аналогичные Redis.Однако Фактическое поведение таких систем во время выполнения не будет похоже на Redis Cluster. Redis Cluster был разработан, чтобы охватить точные варианты использования некластерная версия Redis.
* Ключи распределительные модели
Ключевое пространство разделено на 16384 слота, фактически устанавливая верхний предел. для размера кластера из 16384 главных узлов (однако рекомендуемый максимальный размер узлов составляет порядка ~ 1000 узлов).
Каждый главный узел в кластере обрабатывает подмножество из 16384 хэш-слотов. Кластер стабильный , когда нет перенастройки кластера в прогресс (т.е. когда хеш-слоты перемещаются с одного узла на другой). Когда кластер стабилен, один хэш-слот будет обслуживаться одним узлом. (однако обслуживающий узел может иметь одну или несколько реплик, которые заменят его в случае разделения сети или сбоев, и это можно использовать для масштабирования операций чтения, где допустимо чтение устаревших данных).
Базовый алгоритм, используемый для сопоставления ключей с хэш-слотами, следующий (прочтите следующий абзац об исключении хэш-тегов из этого правила):
HASH_SLOT = CRC16 (ключ) мод 16384
CRC16 определяется следующим образом:
- Имя: XMODEM (также известное как ZMODEM или CRC-16 / ACORN)
- Ширина: 16 бит
- Poly: 1021 (на самом деле x 16 + x 12 + x 5 + 1)
- Инициализация: 0000
- Отражение входного байта: ложь
- CRC на выходе отражения: ложь
- Константа Xor для вывода CRC: 0000
- Вывод для «123456789»: 31C3
Используются 14 из 16 выходных битов CRC16 (поэтому операцию по модулю 16384 в приведенной выше формуле).
В наших тестах CRC16 показал отличные результаты при распределении различных типов ключи равномерно через 16384 слота.
Примечание : Эталонная реализация используемого алгоритма CRC16 доступна в Приложении A к настоящему документу.
* Ключи хэш-тегов
Есть исключение для вычисления хэш-слота, который используется в порядке для реализации хэш-тегов .Хеш-теги — это способ гарантировать, что несколько ключей размещаются в одном и том же хеш-слоте. Это используется для реализации многоклавишные операции в Redis Cluster.
Для реализации хэш-тегов хэш-слот для ключа вычисляется в
немного иначе в определенных условиях.
Если ключ содержит шаблон «{…}», только подстрока между { и } хэшируется для получения хеш-слота.Однако поскольку это
возможно, что существует несколько вхождений { или } , алгоритм
точно определяется следующими правилами:
- ЕСЛИ ключ содержит символ
{. - И ЕСЛИ есть символ
}справа от{ - И ЕСЛИ есть один или несколько символов между первым появлением
{и первым появлением}.
Затем вместо хеширования ключа хешируется только то, что находится между первым вхождением { и следующим первым вхождением } .
Примеры:
- Два ключа
{user1000}. Послеи{user1000} .followersбудут хешироваться в один и тот же хэш-слот, поскольку только подстрокаuser1000будет хешироваться для вычисления хеш-слота. - Для ключа
foo {} {bar}весь ключ будет хеширован, как обычно, поскольку за первым появлением{следует}справа без символов в середине. - Для ключа
foo {{bar}} zapбудет хешироваться подстрока{bar, потому что это подстрока между первым вхождением{и первым вхождением}справа от него. - Для ключа
foo {bar} {zap}будет хешироваться подстрокаbar, поскольку алгоритм останавливается при первом действительном или недопустимом (без байтов внутри) совпадении{и}. - Из алгоритма следует, что если ключ начинается с
{}, он гарантированно будет хеширован как единое целое. Это полезно при использовании двоичных данных в качестве имен ключей.
Добавляя исключение хэш-тегов, ниже представлена реализация функции HASH_SLOT на языке Ruby и C.
Пример кода Ruby:
def HASH_SLOT (ключ)
s = ключ.показатель "{"
если с
e = key.index "}", s + 1
если e && e! = s + 1
ключ = ключ [s + 1..e-1]
конец
конец
crc16 (ключ)% 16384
конец
Пример кода C:
unsigned int HASH_SLOT (char * key, int keylen) {
int s, e; / * начальные и конечные индексы {и} * /
/ * Ищем первое вхождение '{'. * /
для (s = 0; s * Атрибуты узлов кластера
Каждый узел в кластере имеет уникальное имя.Имя узла - это шестнадцатеричное представление 160-битного случайного числа, полученного при первом узел запускается (обычно с помощью / dev / urandom). Узел сохранит свой идентификатор в файле конфигурации узла и будет использовать тот же идентификатор навсегда, или, по крайней мере, до тех пор, пока файл конфигурации узла не удален системным администратором, или требуется аппаратный сброс с помощью команды СБРОС КЛАСТЕРА.
Идентификатор узла используется для идентификации каждого узла во всем кластере.Данный узел может изменить свой IP-адрес без необходимости. также изменить идентификатор узла. Кластер также может обнаружить изменение в IP / порт и перенастроить с помощью протокола сплетен, запущенного в кластере автобус.
Идентификатор узла - это не единственная информация, связанная с каждым узлом, но единственный, который всегда глобально согласован. Каждый узел также имеет следующий набор связанной информации.Некоторая информация о деталь конфигурации кластера этого конкретного узла, и в конечном итоге согласован во всем кластере. Другая информация, как и в прошлый раз узел был пингуется, вместо этого является локальным для каждого узла.
Каждый узел поддерживает следующую информацию о других узлах, которые он
известно в кластере: ID узла, IP и порт узла, набор
flags, что является мастером узла, если он помечен как реплика , последний раз
узел был опрошен, и в последний раз, когда понг был получен, текущий эпоха конфигурации узла (поясняется позже в этой спецификации),
состояние связи и, наконец, набор обслуживаемых хеш-слотов.
Подробное объяснение всех полей узла описано в документации КЛАСТЕРНЫЕ УЗЛЫ.
Команда CLUSTER NODES может быть отправлена на любой узел в кластере и предоставляет состояние кластера и информацию для каждого узла в соответствии с локальным представлением кластера, которое имеет запрашиваемый узел.
Ниже приведен пример вывода команды CLUSTER NODES, отправленной мастеру. узел в небольшом кластере из трех узлов.
$ узлов кластера redis-cli
d1861060fe6a534d42d8a19aeb36600e18785e04 127.0.0.1:6379 я - 0 1318428930 1 подключен 0-1364
3886e65cc906bfd9b1f7e7bde468726a052d1dae 127.0.0.1:6380 master - 1318428930 1318428931 2 подключенных 1365-2729
d289c575dcbc4bdd25fd4339089e461a27d 127.0.0.1:6381 master - 1318428931 1318428931 3 подключенных 2730-4095
В приведенном выше листинге различные поля расположены по порядку: идентификатор узла, адрес: порт, флаги, последний отправленный эхо-запрос, последний полученный понг, эпоха конфигурации, состояние соединения, слоты.Подробности о вышеуказанных полях будут рассмотрены, как только мы поговорим о конкретных частях Redis Cluster.
* Кластерная шина
Каждый узел Redis Cluster имеет дополнительный TCP-порт для получения входящие соединения от других узлов Redis Cluster. Этот порт будет получен путем добавления 10000 к порту данных или его можно указать в конфигурации порта кластера.
Пример 1:
Если узел Redis прослушивает клиентские подключения на порту 6379, и вы не добавляете параметр cluster-port в redis.conf, порт шины кластера 16379 будет открыт.
Пример 2:
Если узел Redis прослушивает клиентские подключения на порту 6379, и вы устанавливаете кластерный порт 20000 в redis.conf, порт шины кластера 20000 будет открыт.
Связь между узлами происходит исключительно с использованием шины кластера и
протокол шины кластера: двоичный протокол, состоящий из кадров
разных видов и размеров.Бинарный протокол шины кластера не
публично задокументирован, поскольку не предназначен для внешних программных устройств
разговаривать с узлами Redis Cluster по этому протоколу. Однако вы можете
получить более подробную информацию о протоколе шины кластера, прочитав cluster.h и cluster.c в исходном коде Redis Cluster.
* Топология кластера
КластерRedis - это полная сетка, в которой каждый узел соединен со всеми остальными узлами с помощью TCP-соединения.
В кластере из N узлов каждый узел имеет N-1 исходящих TCP-соединений и N-1 входящих.
Эти TCP-соединения постоянно поддерживаются и не создаются по запросу. Когда узел ожидает ответа pong в ответ на эхо-запрос в шине кластера, прежде чем ждать достаточно долго, чтобы пометить узел как недоступный, он попытается обновите соединение с узлом, переподключившись с нуля.
В то время как узлы Redis Cluster образуют полную сетку, узлы используют протокол сплетен и механизм обновления конфигурации, чтобы избежать обмена слишком большим количеством сообщений между узлами в нормальных условиях , поэтому количество сообщений обмен не экспоненциальный.
* Рукопожатие узлов
Узлы всегда принимают соединения на порте шины кластера и даже отвечают на эхо-запросы при получении, даже если пинговый узел не является доверенным. Однако все остальные пакеты будут отброшены принимающим узлом, если отправляющий узел не считается частью кластера.
Узел примет другой узел как часть кластера только двумя способами:
Если узел представляет себе сообщение
MEET.Сообщение о встрече точно как сообщение PING, но заставляет получателя принять узел как часть кластер. Узлы будут отправлять сообщенияMEETдругим узлам только в том случае, если системный администратор запрашивает это с помощью следующей команды:CLUSTER MEET IP-порт
Узел также зарегистрирует другой узел как часть кластера, если узел, который уже является доверенным, будет сплетничать об этом другом узле.Таким образом, если A знает B, а B знает C, в конечном итоге B отправит сообщения сплетен A о C. Когда это произойдет, A зарегистрирует C как часть сети и попытается подключиться к C.
Это означает, что пока мы соединяем узлы в любом связном графе, они в конечном итоге автоматически образуют полностью связанный граф. Это означает, что кластер может автоматически обнаруживать другие узлы, но только при наличии доверительных отношений, установленных системным администратором.
Этот механизм делает кластер более устойчивым, но предотвращает случайное смешивание разных кластеров Redis после изменения IP-адресов или других событий, связанных с сетью.
* MOVED Перенаправление
Клиент Redis может отправлять запросы каждому узлу кластера, включая реплики узлов. Узел проанализирует запрос, и если он приемлем (то есть в запросе упоминается только один ключ или несколько ключей упомянутые все в одном и том же хеш-слоте) он будет искать, что узел отвечает за хэш-слот, в котором находится ключ или ключи.
Если хэш-слот обслуживается узлом, запрос просто обрабатывается, в противном случае узел проверит свой внутренний хэш-слот на карту узлов и ответит клиенту с ошибкой MOVED, как в следующем примере:
ПОЛУЧИТЬ x
-ПЕРЕМЕЩЕНА: 3999127.0.0.1:6381
Ошибка включает хэш-слот ключа (3999) и порт ip: экземпляр, который может обслуживать запрос.Клиенту необходимо повторно отправить запрос на IP-адрес и порт указанного узла. Обратите внимание, что даже если клиент долго ждет перед повторной отправкой запроса, и тем временем конфигурация кластера изменилась, целевой узел ответит снова с ошибкой MOVED, если хэш-слот 3999 теперь обслуживается другой узел. То же самое происходит, если у связанного узла не было обновленной информации.
Итак, хотя с точки зрения узлов кластера идентифицируются ID мы пытаемся упростить наш интерфейс с клиентом, просто выставляя карту между хэш-слотами и узлами Redis, идентифицированными парами IP: порт.
Клиент не обязан, но должен попытаться запомнить этот хэш-слот 3999 обслуживается 127.0.0.1:6381. Таким образом, когда новая команда должна быть выданным, он может вычислить хэш-слот целевого ключа и иметь больше шансов правильно выбрать узел.
Альтернативой является обновление всего макета кластера на стороне клиента. с помощью команд CLUSTER NODES или CLUSTER SLOTS при получении переадресации MOVED.Когда встречается перенаправление, оно скорее всего, было перенастроено несколько слотов, а не только один, поэтому обновление конфигурация клиента как можно скорее часто является лучшей стратегией.
Обратите внимание, что когда кластер стабилен (нет текущих изменений в конфигурации), в конечном итоге все клиенты получат карту хеш-слотов -> узлов, что сделает кластер эффективен, клиенты напрямую обращаются к нужным узлам без перенаправлений, прокси-серверов или других объектов единой точки отказа.
Клиент также должен иметь возможность обрабатывать -ASK перенаправления , которые описаны далее в этом документе, иначе это не полный клиент Redis Cluster.
* Живая реконфигурация кластера
Redis Cluster поддерживает возможность добавления и удаления узлов во время кластера. это работает. Добавление или удаление узла абстрагируется в том же операция: перемещение хеш-слота с одного узла на другой.Это означает что тот же самый базовый механизм может быть использован для ребалансировки кластера, добавьте или удалить узлы и т. д.
- Чтобы добавить новый узел в кластер, в кластер добавляется пустой узел, и некоторый набор хэш-слотов перемещается с существующих узлов на новый узел.
- Чтобы удалить узел из кластера, хэш-слоты, назначенные этому узлу, перемещаются на другие существующие узлы.
- Для перебалансировки кластера данный набор хэш-слотов перемещается между узлами.
Ядром реализации является возможность перемещать хэш-слоты. С практической точки зрения хеш-слот - это просто набор ключей, поэтому то, что Redis Cluster действительно делает во время перенастройки , - это перемещать ключи из от экземпляра к другому экземпляру. Перемещение хеш-слота означает перемещение всех ключей что случилось с хешем в этот хеш-слот.
Чтобы понять, как это работает, нам нужно показать подкоманды CLUSTER которые используются для управления таблицей трансляции слотов в узле Redis Cluster.
Доступны следующие подкоманды (среди прочего, бесполезны в данном случае):
Первые две команды, ADDSLOTS и DELSLOTS , просто используются для назначения
(или удалить) слоты на узле Redis. Назначение слота означает, что
главный узел, который будет отвечать за хранение и обслуживание контента для
указанный хэш-слот.
После назначения хэш-слотов они будут распространяться по кластеру. используя протокол сплетен, как указано ниже в распространение конфигурации раздел.
Команда ADDSLOTS обычно используется при создании нового кластера.
с нуля, чтобы назначить каждому главному узлу подмножество всего хэша 16384
слоты доступны.
DELSLOTS в основном используется для ручного изменения конфигурации кластера.
или для задач отладки: на практике используется редко.
Подкоманда SETSLOT используется для назначения слота определенному идентификатору узла, если
используется форма SETSLOT .В противном случае слот можно установить в
два особых состояния МИГРАЦИЯ и ИМПОРТ . Эти два особых состояния
используются для переноса хэш-слота с одного узла на другой.
- Когда слот установлен как MIGRATING, узел будет принимать все запросы, которые
относятся к этому хеш-слоту, но только если рассматриваемый ключ
существует, в противном случае запрос перенаправляется с использованием перенаправления
-ASKна узел, который является целью миграции. - Когда слот установлен как ИМПОРТ, узел будет принимать все запросы, которые
относятся к этому хэш-слоту, но только если запрос
которой предшествует команда ASKING. Если команда ASKING не была дана
клиентом запрос перенаправляется владельцу реального хеш-слота через
ошибка перенаправления
-MOVED, как обычно.
Давайте проясним это на примере миграции хеш-слота.Предположим, что у нас есть два главных узла Redis, называемые A и B. Мы хотим переместить хэш-слот 8 из A в B, поэтому мы выполняем такие команды:
- Мы отправляем B: CLUSTER SETSLOT 8 IMPORTING A
- Мы отправляем A: CLUSTER SETSLOT 8 MIGRATING B
Все остальные узлы будут продолжать указывать клиентов на узел «А» каждый раз. они запрашиваются с ключом, который принадлежит хеш-слоту 8, так что же происходит это что:
- Все запросы о существующих ключах обрабатываются «А».
- Все запросы о несуществующих ключах в A обрабатываются «B», потому что «A» перенаправляет клиентов на «B».
Таким образом, мы больше не создаем новые ключи в «A».
А пока что redis-cli использовал при ресардингах
и конфигурация Redis Cluster перенесет существующие ключи в
хэш-слот 8 от A до B.
Это выполняется с помощью следующей команды:
CLUSTER GETKEYSINSLOT количество слотов
Приведенная выше команда вернет count ключей в указанном хеш-слоте.Для возвращенных ключей redis-cli отправляет узлу «A» команду MIGRATE, которая
перенесет указанные ключи из A в B атомарным способом (оба экземпляра
заблокированы на время (обычно очень небольшое), необходимое для переноса ключей, поэтому
нет условий гонки). Так работает MIGRATE:
MIGRATE target_host target_port "" target_database id timeout KEYS key1 key2 ...
MIGRATE подключится к целевому экземпляру, отправит сериализованную версию ключ, и как только код ОК будет получен, старый ключ из собственного набора данных будет удален.С точки зрения внешнего клиента ключ существует либо в A, либо в B в любой момент времени.
В Redis Cluster нет необходимости указывать базу данных, отличную от 0, но MIGRATE - это общая команда, которую можно использовать для других задач, кроме с участием Redis Cluster. MIGRATE оптимизирован для максимальной скорости даже при перемещении сложных ключи, такие как длинные списки, но в Redis Cluster перенастройка кластер, в котором присутствуют большие ключи, не считается разумной процедурой, если в приложении, использующем базу данных, есть ограничения по задержке.
Когда процесс миграции окончательно завершен, команда SETSLOT отправляется двум узлам, участвующим в миграции, чтобы
снова установите слоты в их нормальное состояние. Та же самая команда обычно
отправлено на все остальные узлы, чтобы не ждать естественного
распространение новой конфигурации по кластеру.
* перенаправление запроса
В предыдущем разделе мы кратко говорили о перенаправлении ASK.Почему не может мы просто используем MOVED перенаправление? Потому что в то время как ПЕРЕМЕЩЕНИЕ означает, что мы думаем, что хэш-слот постоянно обслуживается другим узлом, и следующие запросы должны быть выполнены на указанном узле, ASK означает отправить только следующий запрос на указанный узел.
Это необходимо, потому что следующий запрос о хэш-слоте 8 может быть о ключ, который все еще находится в A, поэтому мы всегда хотим, чтобы клиент попробовал A и затем B, если необходимо.Поскольку это происходит только для одного хеш-слота из 16384 доступно, снижение производительности кластера является приемлемым.
Нам нужно заставить это поведение клиента, чтобы убедиться, что что клиенты будут пробовать узел B только после попытки A, узел B будет только принимать запросы слота, который установлен как ИМПОРТ, если клиент отправляет ASKING перед отправкой запроса.
Обычно команда ASKING устанавливает одноразовый флаг на клиенте, который заставляет узел для обслуживания запроса о слоте IMPORTING.
Полная семантика перенаправления ASK с точки зрения клиента следующая:
- Если получено перенаправление ASK, отправить только тот запрос, который был перенаправлен на указанный узел, но продолжить отправку последующих запросов на старый узел.
- Запустите перенаправленный запрос с помощью команды ASKING.
- Пока не обновляйте локальные клиентские таблицы для сопоставления хэш-слота 8 с B.
После завершения миграции хэш-слота 8 A отправит сообщение MOVED и клиент может постоянно отображать хэш-слот 8 на новую пару IP-адреса и порта.Обратите внимание, что если ошибочный клиент выполняет карту раньше, это не проблема, так как он не отправит команду ASKING до выдачи запроса, поэтому B перенаправит клиента на A, используя ошибку перенаправления MOVED.
Миграцияслотов объясняется аналогичными терминами, но с другими формулировками. (для сокращения документации) в CLUSTER SETSLOT командная документация.
* Первое подключение клиентов и обработка перенаправлений
Хотя возможна реализация клиента Redis Cluster, которая не запомните конфигурацию слотов (карту между номерами слотов и адресами обслуживающие его узлы) в памяти и работает только путем обращения к случайным узлам, ожидающим быть перенаправленным, такой клиент будет очень неэффективным.
Клиенты Redis Cluster должны быть достаточно умными, чтобы запоминать слоты. конфигурация. Однако эта конфигурация не , требуется , чтобы быть в актуальном состоянии. Поскольку обращение к неправильному узлу просто приведет к перенаправлению, это должен вызвать обновление клиентского представления.
Клиентам обычно требуется получить полный список слотов и сопоставленный узел. адреса в двух разных ситуациях:
- При запуске для заполнения начальной конфигурации слотов.
- Когда получено перенаправление
MOVED.
Обратите внимание, что клиент может обрабатывать перенаправление MOVED , обновляя только
перемещенный слот в своей таблице, однако это обычно неэффективно, так как часто
конфигурация нескольких слотов изменяется одновременно (например, если
реплика становится мастером, все слоты, обслуживаемые старым мастером, будут
быть переназначен). Гораздо проще отреагировать на перенаправление MOVED с помощью
получение полной карты слотов в узлы с нуля.
Чтобы получить конфигурацию слотов, Redis Cluster предлагает альтернатива команде CLUSTER NODES, которая не требует синтаксического анализа и предоставляет только ту информацию, которая необходима клиентам.
Новая команда называется CLUSTER SLOTS и предоставляет массив слотов. диапазоны, а также связанные с ними главный и реплики узлов, обслуживающих указанный диапазон.
Ниже приведен пример вывода CLUSTER SLOTS:
127.0.0.1: 7000> слотов кластера
1) 1) (целое число) 5461
2) (целое число) 10922
3) 1) «127.0.0.1»
2) (целое число) 7001
4) 1) «127.0.0.1»
2) (целое число) 7004
2) 1) (целое число) 0
2) (целое число) 5460
3) 1) «127.0.0.1»
2) (целое число) 7000
4) 1) «127.0.0.1»
2) (целое число) 7003
3) 1) (целое число) 10923
2) (целое число) 16383
3) 1) «127.0.0.1»
2) (целое число) 7002
4) 1) «127.0.0.1»
2) (целое число) 7005
Первые два подэлемента каждого элемента возвращаемого массива - это начальные и конечные слоты диапазона.Дополнительные элементы представляют собой адрес-порт пары. Первая пара адрес-порт - это мастер, обслуживающий слот, а дополнительные пары адрес-порт - это все реплики, обслуживающие один и тот же слот которые не находятся в состоянии ошибки (т.е. флаг FAIL не установлен).
Например, первый элемент вывода говорит, что слоты с 5461 по 10922 (начало и конец включены) обслуживаются 127.0.0.1:7001, и это возможно для масштабирования нагрузки только для чтения, связывающейся с репликой на 127.0.0.1: 7004.
CLUSTER SLOTS не гарантирует возврат диапазонов, покрывающих все 16384 слота, если кластер неправильно настроен, поэтому клиенты должны инициализировать карта конфигурации слотов, заполняющая целевые узлы объектами NULL, и сообщить об ошибке, если пользователь пытается выполнить команды о ключах которые принадлежат неназначенным слотам.
Перед возвратом сообщения об ошибке вызывающей стороне, когда найден слот для быть не назначенным, клиент должен попытаться получить конфигурацию слотов еще раз, чтобы проверить, правильно ли настроен кластер.
* Операции с несколькими клавишами
Используя хэш-теги, клиенты могут свободно выполнять операции с несколькими ключами. Например, допустима следующая операция:
MSET {user: 1000} .name Angela {user: 1000} .surname White
Операции с несколькими клавишами могут стать недоступными при перетарке хэш-слот, которому принадлежат ключи.
Точнее, даже во время перешардинга таргетинг на многоклавишные операции ключи, которые все существуют и все еще хешируются в один и тот же слот (либо источник, либо узел назначения) все еще доступны.
Операции с ключами, которых не существует или которые - во время перешардинга - разделены
между исходным и целевым узлами вызовет ошибку -TRYAGAIN .
Клиент может попробовать выполнить операцию через некоторое время или сообщить об ошибке.
Как только миграция указанного хеш-слота завершится, все Для этого хеш-слота снова доступны многоклавишные операции.
* Масштабирование чтения с использованием узлов реплик
Обычно реплики перенаправляют клиентов к авторитетному мастеру для хэш-слот, задействованный в данной команде, однако клиенты могут использовать реплики для масштабирования чтения с помощью команды READONLY.
ТОЛЬКО ЧТЕНИЕ сообщает узлу реплики Redis Cluster, что клиент читает возможно устаревшие данные и не заинтересован в выполнении запросов на запись.
Когда соединение находится в режиме только для чтения, кластер отправляет перенаправление клиенту только в том случае, если в операции задействованы не обслуживаемые ключи главным узлом реплики. Это может произойти, потому что:
- Клиент отправил команду о хэш-слотах, которые никогда не обслуживались мастером этой реплики.
- Кластер был перенастроен (например, повторно шардирован), и реплика больше не может обслуживать команды для данного хэш-слота.
Когда это происходит, клиент должен обновить карту своего хэш-слота, как описано в предыдущие разделы.
Состояние соединения только для чтения можно очистить с помощью команды READWRITE.
* Сердцебиение и сплетни
Узлы кластераRedis постоянно обмениваются пакетами ping и pong.Эти два типа пакетов имеют одинаковую структуру и оба несут важную информацию о конфигурации. Единственное реальное отличие - это поле типа сообщения. Мы будем называть сумму пакетов ping и pong как пакетов сердцебиения .
Обычно узлы отправляют пакеты ping, которые заставляют получателей отвечать пакетами pong. Однако это не обязательно так. Узлы могут просто отправлять пакеты pong для отправки информации другим узлам об их конфигурации, не вызывая ответа.Это полезно, например, для того, чтобы как можно скорее передать новую конфигурацию.
Обычно узел будет пинговать несколько случайных узлов каждую секунду, так что общее количество отправленных пакетов проверки связи (и полученных пакетов pong) каждым узлом является постоянным, независимо от числа узлов в кластере.
Однако каждый узел проверяет связь с каждым другим узлом, который не отправлял эхо-запрос или принимал понг дольше половины времени NODE_TIMEOUT .До истечения срока действия NODE_TIMEOUT узлы также пытаются повторно подключить TCP-канал к другому узлу, чтобы убедиться, что узлы не считаются недоступными только из-за проблемы в текущем TCP-соединении.
Количество сообщений, которыми обмениваются глобально, может быть значительным, если для NODE_TIMEOUT установлено небольшое число, а количество узлов (N) очень велико, так как каждый узел будет пытаться проверить связь с каждым другим узлом, для которого у них нет свежих информация каждую половину NODE_TIMEOUT времени.
Например, в кластере из 100 узлов с тайм-аутом узла, установленным на 60 секунд, каждый узел будет пытаться отправлять 99 эхо-запросов каждые 30 секунд с общим количеством эхо-запросов 3,3 в секунду. Если умножить на 100 узлов, то получится 330 эхо-запросов в секунду для всего кластера.
Есть способы уменьшить количество сообщений, но пока не было сообщил о проблемах с пропускной способностью, которая в настоящее время используется при сбое Redis Cluster обнаружение, поэтому сейчас используется очевидный и прямой дизайн.Обратите внимание, что даже в приведенном выше примере обмен 330 пакетов в секунду равномерно разделен между 100 различными узлами, поэтому трафик, получаемый каждым узлом приемлемо.
* Содержимое пакета Heartbeat
Пакеты Ping и Pong содержат заголовок, который является общим для всех типов пакетов (например, пакеты для запроса аварийного переключения), и специальный раздел Gossip, специфичный для пакетов Ping и Pong.
Общий заголовок содержит следующую информацию:
- ID узла, 160-битная псевдослучайная строка, которая назначается при первом создании узла и остается неизменной на протяжении всего срока службы узла Redis Cluster.
- Поля
currentEpochиconfigEpochузла-отправителя, которые используются для монтирования распределенных алгоритмов, используемых Redis Cluster (это подробно объясняется в следующих разделах).Если узел является репликой,configEpochявляется последним известнымconfigEpochсвоего мастера. - Флаги узла, указывающие, является ли узел репликой, главным узлом, и другую однобитовую информацию об узле.
- Битовая карта хэш-слотов, обслуживаемых отправляющим узлом, или, если узел является репликой, битовая карта слотов, обслуживаемых его мастером.
- Базовый TCP-порт отправителя, который используется Redis для приема клиентских команд.
- Порт кластера, который используется Redis для межузловой связи.
- Состояние кластера с точки зрения отправителя (не работает или нормально).
- Идентификатор главного узла отправляющего узла, если это реплика.
Пакеты для пинга и понга также содержат раздел со сплетнями. Этот раздел предлагает получателю представление о том, что узел-отправитель думает о других узлах в кластере. Раздел сплетен содержит информацию только о нескольких случайных узлах из набора узлов, известных отправителю.Количество узлов, упомянутых в разделе сплетен, пропорционально размеру кластера.
Для каждого узла, добавленного в раздел сплетен, сообщаются следующие поля:
- ID узла.
- IP и порт узла.
- Флаги узлов.
Разделы сплетен позволяют принимающим узлам получать информацию о состоянии других узлов с точки зрения отправителя.Это полезно как для обнаружения сбоев, так и для обнаружения других узлов в кластере.
* Обнаружение неисправности
Обнаружение сбоев кластераRedis используется для распознавания, когда главный узел или узел реплики больше недоступен для большинства узлов, и затем отвечает, повышая реплику до роли ведущего. Когда продвижение реплики невозможно, кластер переводится в состояние ошибки, чтобы перестать получать запросы от клиентов.
Как уже упоминалось, каждый узел принимает список флагов, связанных с другими известными узлами.Для обнаружения сбоев используются два флага: PFAIL и FAIL . PFAIL означает Возможный сбой и является типом неподтвержденного отказа. FAIL означает, что узел выходит из строя и что это условие было подтверждено большинством мастеров в течение фиксированного промежутка времени.
Флаг PFAIL:
Узел помечает другой узел флагом PFAIL , когда узел недоступен более NODE_TIMEOUT раз.И главный, и репликационный узлы могут помечать другой узел как PFAIL , независимо от его типа.
Концепция недоступности узла Redis Cluster заключается в том, что у нас есть активный ping (отправленный ping, на который мы еще не получили ответа), ожидающий более NODE_TIMEOUT . Для того, чтобы этот механизм работал, NODE_TIMEOUT должен быть большим по сравнению с временем приема-передачи в сети. Чтобы повысить надежность во время нормальной работы, узлы будут пытаться повторно подключиться к другим узлам в кластере, как только половина NODE_TIMEOUT истечет без ответа на эхо-запрос.Этот механизм гарантирует, что соединения поддерживаются, поэтому разорванные соединения обычно не приводят к ложным отчетам об отказе между узлами.
Флаг FAIL:
Флаг PFAIL - это просто локальная информация, которую каждый узел имеет о других узлах, но ее недостаточно для запуска продвижения реплики. Чтобы узел считался неработающим, условие PFAIL должно быть повышено до состояния FAIL .
Как указано в разделе «пульс» этого документа, каждый узел отправляет сообщения сплетен каждому другому узлу, включая состояние нескольких случайных известных узлов. Каждый узел в конечном итоге получает набор флагов узла для каждого другого узла. Таким образом, у каждого узла есть механизм, чтобы сигнализировать другим узлам об обнаруженных ими сбоях.
Состояние PFAIL переходит в состояние FAIL , когда выполняется следующий набор условий:
- У некоторого узла, который мы назовем A, есть другой узел B, помеченный как
PFAIL. - Узел A собирал через разделы сплетен информацию о состоянии B с точки зрения большинства мастеров в кластере.
- Большинство мастеров сигнализировали о состоянии
PFAILилиFAILв течениеNODE_TIMEOUT * FAIL_REPORT_VALIDITY_MULTвремени. (Фактор достоверности установлен на 2 в текущей реализации, так что это всего лишь в два раза больше времениNODE_TIMEOUT).
Если все вышеперечисленные условия верны, Узел A будет:
- Пометить узел как
FAIL. - Отправить сообщение
FAIL(в отличие от условияFAILв контрольном сообщении) всем доступным узлам.
Сообщение FAIL заставит каждый принимающий узел пометить узел в состоянии FAIL , независимо от того, пометил он уже узел в состоянии PFAIL .
Обратите внимание, что флаг FAIL в основном односторонний . То есть узел может перейти с PFAIL на FAIL , но флаг FAIL может быть сброшен только в следующих ситуациях:
- Узел уже доступен и является репликой.В этом случае флаг
FAILможет быть сброшен, поскольку для реплик не выполняется отработка отказа. - Узел уже доступен и является мастером, не обслуживающим ни одного слота. В этом случае флаг
FAILможет быть сброшен, поскольку мастера без слотов на самом деле не участвуют в кластере и ожидают настройки, чтобы присоединиться к кластеру. - Узел уже доступен и является ведущим, но прошло много времени (N раз больше
NODE_TIMEOUT) без какого-либо обнаруживаемого повышения реплики.В этом случае ему лучше снова присоединиться к кластеру и продолжить работу.
Полезно отметить, что хотя переход PFAIL -> FAIL использует форму согласия, используемое согласие является слабым:
- Узлы собирают представления других узлов за некоторый период времени, поэтому даже если большинству главных узлов нужно «согласовать», на самом деле это просто состояние, которое мы собрали с разных узлов в разное время, и мы не уверены и не требуем , что в данный момент согласилось большинство мастеров.Однако мы отбрасываем старые отчеты об ошибках, поэтому большинство мастеров сообщило об ошибке в течение определенного периода времени.
- Хотя каждый узел, обнаруживающий условие
FAIL, заставит это условие на других узлах в кластере с помощью сообщенияFAIL, нет никакого способа гарантировать, что сообщение достигнет всех узлов. Например, узел может обнаружить условиеFAILи из-за раздела не сможет связаться с каким-либо другим узлом.
Однако обнаружение сбоев Redis Cluster требует жизнеспособности: в конечном итоге все узлы должны согласовать состояние данного узла. Есть два случая, которые могут быть вызваны состояниями расщепления мозга. Либо некоторое меньшинство узлов считает, что узел находится в состоянии FAIL , либо меньшинство узлов считает, что узел не находится в состоянии FAIL . В обоих случаях в конечном итоге кластер будет иметь единое представление о состоянии данного узла:
Случай 1 : Если большинство мастеров пометили узел как FAIL , из-за обнаружения сбоя и генерируемого им цепного эффекта каждый другой узел в конечном итоге пометит ведущий как FAIL , поскольку в указанном окно времени достаточное количество отказов будет сообщено.
Случай 2 : Когда только меньшинство мастеров пометили узел как FAIL , повышение реплики не произойдет (поскольку он использует более формальный алгоритм, который гарантирует, что все в конечном итоге узнают о повышении), и каждый узел будет очищен состояние FAIL в соответствии с правилами очистки состояния FAIL , приведенными выше (т. е. отсутствие повышения после N раз истекло NODE_TIMEOUT ).
Флаг FAIL используется только в качестве триггера для запуска безопасной части алгоритма для продвижения реплики.Теоретически реплика может действовать независимо и запускать продвижение реплики, когда ее мастер недоступен, и ждать, пока мастера откажутся предоставить подтверждение, если мастер действительно доступен для большинства. Однако дополнительная сложность состояния PFAIL -> FAIL , слабое согласование и сообщение FAIL , заставляющее распространение состояния в кратчайший промежуток времени в достижимой части кластера, имеют практические преимущества. Из-за этих механизмов обычно все узлы прекращают принимать записи примерно в одно и то же время, если кластер находится в состоянии ошибки.Это желательная функция с точки зрения приложений, использующих Redis Cluster. Также исключаются ошибочные попытки выбора, инициированные репликами, которые не могут связаться со своим главным узлом из-за локальных проблем (в противном случае главный узел доступен для большинства других главных узлов).
* Кластер текущей эпохи
Redis Cluster использует концепцию, аналогичную термину алгоритма Raft. В Redis Cluster термин вместо этого называется эпохой, и он используется, чтобы дать событиям инкрементное управление версиями.Когда несколько узлов предоставляют противоречивую информацию, другой узел может понять, какое состояние является наиболее актуальным.
currentEpoch - это 64-битное беззнаковое число.
При создании узла каждый узел кластера Redis, как реплики, так и главные узлы, устанавливает для currentEpoch значение 0.
Каждый раз, когда пакет принимается от другого узла, если эпоха отправителя (часть заголовка сообщений шины кластера) больше, чем эпоха локального узла, currentEpoch обновляется до эпохи отправителя.
Из-за этой семантики в конечном итоге все узлы согласятся с наибольшим значением currentEpoch в кластере.
Эта информация используется, когда состояние кластера изменяется, и узел ищет соглашения, чтобы выполнить какое-либо действие.
В настоящее время это происходит только во время повышения реплики, как описано в следующем разделе. По сути, эпоха - это логические часы для кластера, которые диктуют, что данная информация побеждает информацию с меньшей эпохой.
* Эпоха конфигурации
Каждый мастер всегда объявляет свой configEpoch в пакетах ping и pong вместе с битовой картой, рекламирующей набор слотов, которые он обслуживает.
configEpoch устанавливается в ноль в мастерах при создании нового узла.
Новый configEpoch создается во время выбора реплики. реплики пытаются заменить
неудачливые мастера увеличивают свою эпоху и пытаются получить авторизацию от
большинство мастеров.Когда реплика авторизована, новый уникальный configEpoch создается, и реплика превращается в мастер с помощью нового configEpoch .
Как объясняется в следующих разделах, configEpoch помогает разрешать конфликты, когда разные узлы заявляют о разных конфигурациях (условие, которое может произойти из-за сетевых разделов и отказов узлов).
также объявляют поле configEpoch в пакетах ping и pong, но в случае реплик это поле представляет configEpoch своего мастера на момент последнего обмена пакетами.Это позволяет другим экземплярам определять, когда реплика имеет старую конфигурацию, которую необходимо обновить (главные узлы не будут предоставлять голоса репликам со старой конфигурацией).
Каждый раз, когда configEpoch изменяется для какого-то известного узла, он постоянно сохраняется в файле nodes.conf всеми узлами, которые получают эту информацию. То же самое происходит и со значением currentEpoch . Эти две переменные гарантированно сохраняются и fsync-ed на диск при обновлении до того, как узел продолжит свою работу.
Значения configEpoch , сгенерированные с использованием простого алгоритма во время отработки отказа.
гарантированно будут новыми, инкрементальными и уникальными.
* Реплика выборы и продвижение
Выбор и продвижение реплики обрабатывается узлами реплик с помощью главных узлов, которые голосуют за продвижение реплики.
Выбор реплики происходит, когда мастер находится в состоянии FAIL с точки зрения по крайней мере одной из его реплик, у которой есть предпосылки для того, чтобы стать мастером.
Чтобы реплика стала мастером, она должна начать выборы и выиграть их. Все реплики для данного мастера могут начать выборы, если мастер находится в состоянии FAIL , однако только одна реплика выиграет выборы и станет мастером.
Реплика начинает выборы, если выполняются следующие условия:
- Мастер реплики находится в состоянии
FAIL. - Мастер обслуживал ненулевое количество слотов.
- Ссылка репликации реплики была отключена от ведущего устройства не дольше, чем на заданный промежуток времени, чтобы гарантировать, что данные продвигаемой реплики достаточно свежие. Это время настраивается пользователем.
Чтобы быть избранной, первым шагом реплики является увеличение ее счетчика currentEpoch и запрос голосов от главных экземпляров.
Голоса запрашиваются репликой путем широковещательной рассылки пакета FAILOVER_AUTH_REQUEST каждому главному узлу кластера.Затем он ожидает ответа в течение максимального времени, в два раза превышающего NODE_TIMEOUT (но всегда не менее 2 секунд).
После того, как мастер проголосовал за данную реплику, положительно ответив FAILOVER_AUTH_ACK , он больше не может голосовать за другую реплику того же мастера в течение периода NODE_TIMEOUT * 2 . В этот период он не сможет отвечать на другие запросы авторизации для того же мастера. Это не требуется для гарантии безопасности, но полезно для предотвращения выбора нескольких реплик (даже если с другим configEpoch ) примерно в одно и то же время, что обычно нежелательно.
Реплика отбрасывает все ответы AUTH_ACK с эпохой, меньшей, чем currentEpoch на момент отправки запроса на голосование. Это гарантирует, что он не учитывает голоса, предназначенные для предыдущих выборов.
Как только реплика получает ACK от большинства мастеров, она побеждает на выборах.
В противном случае, если большинство не будет достигнуто в течение двукратного периода NODE_TIMEOUT (но всегда не менее 2 секунд), выборы отменяются, и через NODE_TIMEOUT * 4 (и всегда не менее 4 секунд) будет предпринята новая попытка снова. ).
* Реплика ранга
Как только мастер находится в состоянии FAIL , реплика ждет короткий период времени, прежде чем пытаться быть избранным. Эта задержка рассчитывается следующим образом:
ЗАДЕРЖКА = 500 миллисекунд + случайная задержка от 0 до 500 миллисекунд +
REPLICA_RANK * 1000 миллисекунд.
Фиксированная задержка гарантирует, что мы ожидаем распространения состояния FAIL по кластеру, в противном случае реплика может попытаться быть избранной, пока мастера все еще не знают о состоянии FAIL , отказываясь предоставить свой голос.
Случайная задержка используется для десинхронизации реплик, поэтому они вряд ли начнут выборы в одно и то же время.
REPLICA_RANK - это ранг этой реплики относительно объема данных репликации, обработанных ею от ведущего устройства.
Реплики обмениваются сообщениями, когда мастер выходит из строя, чтобы установить ранг (наилучшее из возможных):
реплика с самым обновленным смещением репликации имеет ранг 0, вторая по величине - ранг 1 и так далее.Таким образом, самые обновленные реплики стараются быть избранными раньше других.
Порядок ранжирования строго не соблюдается; если реплика более высокого ранга не может быть избран, остальные попробуют в ближайшее время.
Как только реплика побеждает на выборах, она получает новый уникальный и инкрементный configEpoch , который выше, чем у любого другого существующего мастера. Он начинает рекламировать себя как мастер в пакетах ping и pong, предоставляя набору обслуживаемых слотов configEpoch , который превзойдет предыдущие.
Чтобы ускорить реконфигурацию других узлов, пакет pong транслируется на все узлы кластера. В настоящее время недоступные узлы в конечном итоге будут перенастроены, когда они получат пакет ping или pong от другого узла или получат пакет UPDATE от другого узла, если информация, которую он публикует с помощью пакетов подтверждения, будет обнаружена как устаревшая.
Другие узлы обнаружат, что есть новый мастер, обслуживающий те же слоты, которые обслуживает старый мастер, но с более высоким значением configEpoch , и обновят свою конфигурацию.Реплики старого мастера (или отказавшего мастера, если он снова присоединяется к кластеру) не только обновят конфигурацию, но и переконфигурируют для репликации с нового мастера. Как настраиваются узлы, повторно присоединяющиеся к кластеру, объясняется в следующих разделах.
* Мастера отвечают на запрос на голосование реплики
В предыдущем разделе обсуждалось, как реплики пытаются быть избранными. В этом разделе объясняется, что происходит с точки зрения мастера, которому предлагается проголосовать за данную реплику.
Мастера получают запросы на голосование в виде FAILOVER_AUTH_REQUEST запросов от реплик.
Для предоставления права голоса должны быть выполнены следующие условия:
- Мастер голосует только один раз для данной эпохи и отказывается голосовать за более старые эпохи: каждый мастер имеет поле lastVoteEpoch и откажется голосовать снова, пока
currentEpochв пакете запроса аутентификации не превышает последнийVoteEpoch.Когда мастер положительно отвечает на запрос голосования, lastVoteEpoch обновляется соответствующим образом и безопасно сохраняется на диске. - Мастер голосует за реплику, только если мастер реплики помечен как
FAIL. - Запросы аутентификации с
currentEpoch, меньшим, чем mastercurrentEpoch, игнорируются. Из-за этого главный ответ всегда будет иметь тот жеcurrentEpoch, что и запрос аутентификации. Если та же самая реплика снова запрашивает голосование, увеличивая значениеcurrentEpoch, гарантируется, что старый отложенный ответ от ведущего устройства не может быть принят для нового голосования.
Пример проблемы, вызванной неиспользованием правила номер 3:
Master currentEpoch - 5, lastVoteEpoch - 1 (это может произойти после нескольких неудачных выборов)
- Реплика
currentEpoch3. - Реплика пытается быть выбрана с эпохой 4 (3 + 1), мастер отвечает ОК с
currentEpoch5, однако ответ задерживается. Реплика - попытается быть избранной снова, в более позднее время, с эпохой 5 (4 + 1), отложенный ответ достигнет реплики с
currentEpoch5 и будет принят как действительный.
- Мастера не голосуют за реплику того же мастера до истечения
NODE_TIMEOUT * 2, если за реплику этого мастера уже проголосовали. Это не обязательно, поскольку две копии не могут выиграть выборы в одну и ту же эпоху. Однако с практической точки зрения это гарантирует, что при выборе реплики у нее будет достаточно времени, чтобы сообщить другим репликам и избежать возможности того, что другая реплика выиграет новые выборы, выполняя ненужное второе аварийное переключение. - Мастера никоим образом не прилагают усилий, чтобы выбрать лучшую реплику. Если мастер реплики находится в состоянии
FAILи мастер не голосовал в текущий срок, предоставляется положительный голос. Лучшая реплика с наибольшей вероятностью начнет выборы и выиграет их раньше других реплик, поскольку она обычно сможет начать процесс голосования раньше из-за своего более высокого ранга , как объяснялось в предыдущем разделе. - Когда мастер отказывается голосовать за данную реплику, нет отрицательного ответа, запрос просто игнорируется.
- Мастера не голосуют за реплики, отправляющие
configEpoch, которое меньше любогоconfigEpochв главной таблице для слотов, заявленных репликой. Помните, что реплика отправляетconfigEpochсвоего мастера и битовую карту слотов, обслуживаемых его мастером. Это означает, что реплика, запрашивающая голосование, должна иметь более новую конфигурацию слотов, для которых требуется выполнить аварийное переключение, или равную конфигурации ведущего устройства, предоставившего голос.
* Практический пример полезности эпохи конфигурации при разделах
В этом разделе показано, как используется концепция эпох, чтобы сделать процесс продвижения реплики более устойчивым к разделам.
- Мастер больше недоступен бесконечно. Мастер имеет три реплики A, B, C.
- Реплика A побеждает на выборах и становится мастером.
- Сетевой раздел делает A недоступным для большей части кластера.
- Реплика B побеждает на выборах и становится мастером.
- Раздел делает B недоступным для большей части кластера.
- Предыдущий раздел фиксирован, и A снова доступен.
В этот момент B не работает, а A снова доступен с ролью ведущего (на самом деле сообщения UPDATE переконфигурируют его быстро, но здесь мы предполагаем, что все сообщения UPDATE были потеряны). В то же время реплика C попытается быть избранной, чтобы выполнить отказ B. Вот что происходит:
- C попытается быть избранным и добьется успеха, так как для большинства мастеров его хозяин фактически не работает. Он получит новый инкрементальный
configEpoch. - A не сможет претендовать на роль мастера для своих хэш-слотов, потому что другие узлы уже имеют те же хэш-слоты, связанные с более высокой эпохой конфигурации (той из B), по сравнению с той, которая была опубликована A.
- Итак, все узлы обновят свою таблицу, чтобы назначить хэш-слоты для C, и кластер продолжит свою работу.
Как вы увидите в следующих разделах, устаревший узел повторно присоединяется к кластеру
обычно при первой возможности получает уведомление об изменении конфигурации
потому что как только он пингует любой другой узел, получатель обнаружит его
имеет устаревшую информацию и отправит сообщение UPDATE .
* Распространение конфигурации хэш-слотов
Важной частью Redis Cluster является механизм, используемый для распространения информации о том, какой узел кластера обслуживает данный набор хэш-слотов. Это жизненно важно как для запуска нового кластера, так и для возможности обновления конфигурации после того, как реплика была повышена для обслуживания слотов отказавшего мастера.
Тот же механизм позволяет разделять узлы на неопределенное количество время разумно воссоединиться с кластером.
Есть два способа распространения конфигураций хэш-слотов:
- Контрольные сообщения. Отправитель пакета ping или pong всегда добавляет информацию о наборе хэш-слотов, которые он (или его мастер, если это реплика) обслуживает.
-
ОБНОВЛЕНИЕсообщений. Поскольку в каждом контрольном пакете есть информация об отправителеconfigEpochи наборе обслуживаемых хэш-слотов, если получатель контрольного пакета обнаружит, что информация об отправителе устарела, он отправит пакет с новой информацией, заставляя устаревший узел обновить его информация.
Получатель контрольного сообщения или сообщения UPDATE использует определенные простые правила в
чтобы обновить хэш-слоты отображения таблицы на узлы. Когда создается новый узел Redis Cluster, его локальная таблица хэш-слотов просто инициализируется NULL записями, так что каждый хеш-слот не привязан к какому-либо узлу. Это выглядит примерно так:
0 -> ПУСТО
1 -> NULL
2 -> NULL
...
16383 -> NULL
Первое правило, которому следует узел для обновления своей таблицы хэш-слотов, следующее:
Правило 1 : Если хэш-слот не назначен (установлен на NULL ), и известный узел заявляет об этом, я изменю свою таблицу хеш-слотов и свяжу с ним заявленные хеш-слоты.
Итак, если мы получим контрольный сигнал от узла A, утверждающий, что обслуживает хэш-слоты 1 и 2 со значением эпохи конфигурации 3, таблица будет изменена на:
0 -> ПУСТО
1 -> А [3]
2 -> А [3]
...
16383 -> NULL
При создании нового кластера системному администратору необходимо вручную назначить (с помощью команды CLUSTER ADDSLOTS, с помощью инструмента командной строки redis-cli или любым другим способом) слоты, обслуживаемые каждым главным узлом, только самому узлу, и информация будет быстро распространяться по кластеру.
Однако этого правила недостаточно. Мы знаем, что отображение хеш-слотов может измениться во время двух мероприятий:
- Реплика заменяет свой главный во время отработки отказа.
- Слот изменен с одного узла на другой.
А пока сосредоточимся на отработке отказа. Когда реплика выходит из строя своего хозяина, она получает эпоха конфигурации, которая гарантированно будет больше, чем одна из ее мастер (и, в более общем плане, больше, чем любая другая эпоха конфигурации сгенерировано ранее).Например, узел B, который является репликой A, может переключаться при отказе. A с эпохой конфигурации 4. Начнется отправка пакетов подтверждения. (впервые массовое вещание в масштабе кластера) и по следующим причинам: второе правило, получатели обновят свои таблицы хэш-слотов:
Правило 2 : Если хэш-слот уже назначен, и известный узел объявляет его, используя configEpoch , который больше, чем configEpoch мастера, в настоящее время связанного со слотом, я повторно привяжу хеш-слот к новому узлу.
Таким образом, после получения сообщений от B, которые утверждают, что обслуживают хэш-слоты 1 и 2 с эпохой конфигурации 4, получатели обновят свою таблицу следующим образом:
0 -> ПУСТО
1 -> B [4]
2 -> B [4]
...
16383 -> NULL
Свойство Liveness: согласно второму правилу, в конечном итоге все узлы в кластере согласятся, что владельцем слота является тот, у которого наибольшее значение configEpoch среди узлов, объявляющих его.
Этот механизм в Redis Cluster называется , последняя отработка отказа .
То же самое происходит при перепрошивке. Когда узел, импортирующий хэш-слот, завершает операции импорта, ее эпоха конфигурации увеличивается, чтобы убедиться, что изменение будет распространяться по всему кластеру.
* сообщения UPDATE, внимательнее
Помня о предыдущем разделе, легче увидеть, как сообщения обновления
Работа.Узел A может снова присоединиться к кластеру через некоторое время. Он отправит сердцебиение
пакеты, в которых он, по его заявлению, обслуживает хэш-слоты 1 и 2 с эпохой конфигурации
из 3. Вместо этого все получатели с обновленной информацией увидят, что
те же хэш-слоты связаны с узлом B, имеющим более высокую конфигурацию
эпоха. Из-за этого они отправят сообщение UPDATE в A с новым
конфигурация для слотов. A обновит свою конфигурацию из-за правило 2 выше.
* Как узлы присоединяются к кластеру
Тот же самый базовый механизм используется, когда узел снова присоединяется к кластеру. Продолжая приведенный выше пример, узел A будет уведомлен что хеш-слоты 1 и 2 теперь обслуживаются B. Предполагая, что эти два единственные хэш-слоты, обслуживаемые A, количество хэш-слотов, обслуживаемых A, будет упасть до 0! Таким образом, A будет переконфигурирован, чтобы быть репликой нового мастера .
Действующее правило немного сложнее этого. В целом это может случится так, что А снова присоединится через много времени, тем временем может случиться так, что хэш-слоты, первоначально обслуживаемые A, обслуживаются несколькими узлами, например хэш-слот 1 может обслуживаться B, а хэш-слот 2 - C.
Итак, действительное правило переключения ролей узла кластера Redis : Главный узел изменит свою конфигурацию, чтобы реплицировать (быть репликой) узел, который украл его последний хэш-слот .
Во время реконфигурации в конечном итоге количество обслуживаемых хэш-слотов упадет до нуля, и узел будет соответственно перенастроен. Обратите внимание, что в базовом случае это просто означает, что старый мастер будет репликой реплики, которая заменила его после отработки отказа. Однако в общем виде правило охватывает все возможные случаи.
Репликиделают то же самое: они изменяют конфигурацию для репликации узла, который украл последний хэш-слот своего бывшего хозяина.
* Перенос реплики
Redis Cluster реализует концепцию, называемую миграцией реплики , чтобы повысить доступность системы. Идея в том, что в кластере с настройка мастер-реплика, если карта между репликами и мастерами исправлена доступность ограничена с течением времени, если несколько независимых отказов одного узлы бывают.
Например, в кластере, где каждый мастер имеет одну реплику, кластер может продолжать операции до тех пор, пока не удастся мастер или реплика, но не если оба выходят из строя одновременно.Однако есть класс отказов, которые независимые отказы отдельных узлов, вызванные аппаратными или программными проблемами которые могут накапливаться со временем. Например:
- Мастер A имеет единственную копию A1.
- Мастер А не работает. А1 продвигается как новый хозяин.
- Три часа спустя A1 выходит из строя независимо (независимо от отказа A). Никакая другая реплика недоступна для повышения, поскольку узел A все еще не работает.Кластер не может продолжать нормальную работу.
Если карта между мастерами и репликами фиксированная, единственный способ сделать кластер более устойчивым к описанному выше сценарию является добавление реплик к каждому мастеру, однако это дорого, поскольку для выполнения требуется больше экземпляров Redis, больше память и так далее.
Альтернатива - создать асимметрию в кластере и позволить кластеру макет автоматически меняется со временем.Например, в кластере может быть три мастера A, B, C. A и B имеют по одной реплике, A1 и B1. Однако мастер C отличается и имеет две копии: C1 и C2.
Миграция реплики - это процесс автоматической перенастройки реплики. для того, чтобы перенести на мастер, который больше не имеет покрытия (не работает реплики). При миграции реплики описанный выше сценарий превращается в следующее:
- Мастер А не работает.A1 повышен в должности.
- C2 мигрирует как реплика A1, которая в противном случае не поддерживается никакими репликами.
- Три часа спустя выходит из строя и A1.
- C2 продвигается как новый мастер вместо A1.
- Кластер может продолжить работу.
* Алгоритм миграции реплики
Алгоритм миграции не использует никаких форм соглашения, так как реплика макет в кластере Redis не является частью конфигурации кластера, которая требует чтобы быть согласованными и / или версионированными с эпохами конфигурации.Вместо этого он использует алгоритм, чтобы избежать массовой миграции реплик, когда мастер не поддерживается. Алгоритм гарантирует, что в конечном итоге (как только конфигурация кластера будет стабильный) каждый мастер будет поддерживаться как минимум одной репликой.
Вот как работает алгоритм. Для начала нам нужно определить, что такое хорошая реплика в этом контексте: хорошая реплика - это реплика не в состоянии FAIL с точки зрения данного узла.
Выполнение алгоритма запускается в каждой реплике, которая обнаруживает, что есть хоть один мастер без хороших реплик. Однако среди всех реплики, обнаруживающие это условие, должны действовать только подмножества. Это подмножество на самом деле часто одна реплика, если разные реплики не имеют в данный момент немного другой взгляд на состояние отказа других узлов.
Действующая реплика - реплика среди мастеров с максимальным количеством подключенных реплик, который не находится в состоянии FAIL и имеет наименьший идентификатор узла.
Так, например, если есть 10 мастеров с 1 репликой каждый и 2 мастера с По 5 реплик каждая, реплика, которая попытается мигрировать - среди 2 мастеров имея 5 реплик - ту, у которой наименьший идентификатор узла. Учитывая, что нет соглашения используется, возможно, что когда конфигурация кластера нестабильна, возникает состояние гонки, когда несколько реплик считают себя исправная реплика с меньшим идентификатором узла (маловероятно, что это произойдет на практике).Если это произойдет, результатом будет миграция нескольких реплик на тот же хозяин, который безвреден. Если гонка происходит так, что уйдет мастер передачи без реплик, как только кластер снова станет стабильным алгоритм будет повторно запущен снова и перенесет реплику обратно в оригинальный мастер.
В конце концов, каждый мастер будет поддерживаться по крайней мере одной репликой. Тем не мение, нормальное поведение состоит в том, что одна реплика мигрирует с мастера с несколько реплик осиротевшему мастеру.
Алгоритм управляется настраиваемым пользователем параметром, называемым кластер-миграция-барьер : количество хороших реплик на главном сервере
необходимо оставить, прежде чем реплика сможет мигрировать. Например, если это
для параметра установлено значение 2, реплика может попытаться выполнить миграцию, только если ее мастер остается
с двумя рабочими репликами.
* алгоритм разрешения конфликтов configEpoch
Когда новые значения configEpoch создаются через продвижение реплики во время
отработки отказа, они гарантированно будут уникальными.
Однако есть два разных события, когда новые значения configEpoch
создан небезопасным способом, просто увеличивая локальный currentEpoch из
локальный узел и надеясь, что одновременно не будет конфликтов.
Оба события инициированы системным администратором:
- Команда CLUSTER FAILOVER с опцией
TAKEOVERможет вручную повысить реплику узла до ведущего узла без того, чтобы большинство мастеров были доступны .Это полезно, например, в установках с несколькими центрами обработки данных. - Миграция слотов для перебалансировки кластера также генерирует новые эпохи конфигурации внутри локального узла без согласования по причинам производительности.
В частности, во время перенастройки вручную, когда хэш-слот переносится из узел A к узлу B, программа перешардинга заставит B обновить его конфигурация к эпохе, которая является величайшей из найденных в кластере, плюс 1 (если только узел уже не является узлом с наибольшей конфигурацией эпоха), не требуя согласия других узлов.Обычно в реальном мире перешардинг включает перемещение нескольких сотен хеш-слотов. (особенно в небольших кластерах). Требование согласия на создание нового эпохи конфигурации во время перенастройки для каждого перемещенного хеш-слота неэффективно. Более того, для этого требуется fsync на каждом из узлов кластера. каждый раз, чтобы сохранить новую конфигурацию. Из-за того, как это выполняется вместо этого, нам нужна только новая эпоха конфигурации при перемещении первого хеш-слота, что делает его намного более эффективным в производственной среде.
Однако из-за двух вышеуказанных случаев можно (хотя и маловероятно) закончить
с несколькими узлами, имеющими одну и ту же эпоху конфигурации. Операция перепрошивки
выполняется системным администратором, и одновременно происходит переключение
время (плюс много неудач) может вызвать коллизии currentEpoch , если
они не размножаются достаточно быстро.
Кроме того, ошибки программного обеспечения и повреждения файловой системы также могут к нескольким узлам, имеющим одну и ту же эпоху конфигурации.
Когда мастера, обслуживающие разные хэш-слоты, имеют одинаковый configEpoch , там
нет проблем. Более важно, чтобы реплики, вышедшие из строя через мастер, имели
эпохи уникальной конфигурации.
Тем не менее, ручное вмешательство или повторный шард могут изменить кластер.
конфигурация по-разному. Главное свойство живучести Redis Cluster
требует, чтобы конфигурации слотов всегда сходились, поэтому при любых обстоятельствах
мы действительно хотим, чтобы все главные узлы имели другой configEpoch .
Чтобы обеспечить это, алгоритм разрешения конфликтов используется в
в случае, если два узла получат один и тот же файл configEpoch .
- ЕСЛИ главный узел обнаруживает, что другой главный узел объявляет себя с помощью
тот же
configEpoch. - И ЕСЛИ узел имеет лексикографически меньший идентификатор узла по сравнению с другим узлом, заявляющим тот же
configEpoch. - ЗАТЕМ он увеличивает значение
currentEpochна 1 и использует его в качестве новогоconfigEpoch.
Если есть какой-либо набор узлов с одинаковым configEpoch , все узлы, кроме одного с наибольшим идентификатором узла, будут двигаться вперед, гарантируя, что в конечном итоге каждый узел выберет уникальный configEpoch независимо от того, что произошло.
Этот механизм также гарантирует, что после создания нового кластера все
узлы начинаются с другого configEpoch (даже если на самом деле это не
used), поскольку redis-cli гарантирует использование CONFIG SET-CONFIG-EPOCH при запуске.Однако, если по какой-то причине узел не настроен, он обновится.
его конфигурация к другой эпохе конфигурации автоматически.
* Узел сбрасывается
Узлы могут быть сброшены программно (без перезапуска) для повторного использования в другой роли или в другом кластере. Это полезно в обычном операций, при тестировании и в облачных средах, где данный узел может быть повторно подготовленным, чтобы присоединиться к другому набору узлов, чтобы увеличить или создать новый кластер.
В Redis узлы кластера сбрасываются с помощью команды CLUSTER RESET. В команда представлена в двух вариантах:
-
МЯГКИЙ СБРОС КЛАСТЕРА -
ЖЕСТКИЙ СБРОС КЛАСТЕРА
Команда должна быть отправлена непосредственно на узел для сброса. Если нет типа сброса при условии, выполняется мягкий сброс.
Ниже приведен список операций, выполняемых при сбросе:
- Мягкий и аппаратный сброс: если узел является репликой, он превращается в мастер, а его набор данных отбрасывается.Если узел является главным и содержит ключи, операция сброса прерывается.
- Мягкий и аппаратный сброс: все слоты освобождаются, и состояние ручного переключения при отказе сбрасывается.
- Мягкий и аппаратный сброс: все остальные узлы в таблице узлов удаляются, поэтому узел больше не знает никаких других узлов.
- Только аппаратный сброс:
currentEpoch,configEpochиlastVoteEpochустановлены на 0. - Только аппаратный сброс: идентификатор узла изменяется на новый случайный идентификатор.
Мастер-узлы с непустыми наборами данных не могут быть сброшены (поскольку обычно вы хотите перенести данные на другие узлы). Однако в особых условиях, когда это уместно (например, когда кластер полностью разрушен с намерением создать новый), FLUSHALL должен быть выполнен перед продолжением сброса.
* Удаление узлов из кластера
Практически удалить узел из существующего кластера можно, перераспределение всех своих данных на другие узлы (если это главный узел) и закрытие его.Однако другие узлы по-прежнему будут помнить свой узел. ID и адрес, и попытается подключиться к нему.
По этой причине, когда узел удаляется, мы хотим также удалить его запись
из всех остальных таблиц узлов. Это достигается с помощью CLUSTER FORGET <идентификатор-узла> команда.
Команда выполняет две функции:
- Удаляет узел с указанным идентификатором узла из таблицы узлов.
- Устанавливает 60-секундный запрет, который предотвращает повторное добавление узла с тем же идентификатором узла.
Вторая операция необходима, потому что Redis Cluster использует сплетни для автоматического обнаружения узлов, поэтому удаление узла X из узла A может привести к тому, что узел B снова сплетничает об узле X с A. Из-за 60-секундного запрета у инструментов администрирования Redis Cluster есть 60 секунд, чтобы удалить узел из всех узлов, предотвращая повторное добавление узла из-за автоматического обнаружения.
Дополнительную информацию можно найти в документации CLUSTER FORGET.
В кластере Redis клиенты могут подписаться на каждый узел, а также могут публиковать на всех остальных узлах. Кластер будет следить за тем, чтобы опубликованные сообщения пересылаются по мере необходимости.
Текущая реализация будет просто транслировать каждое опубликованное сообщение ко всем остальным узлам, но в какой-то момент это будет оптимизировано либо с использованием фильтров Блума или других алгоритмов.
* Приложение A: эталонная реализация CRC16 в ANSI C
/ *
* Copyright 2001-2010 Georges Menie (www.menie.org).
* Copyright 2010 Сальваторе Санфилиппо (адаптировано к стилю программирования Redis)
* Все права защищены.
* Распространение и использование в исходной и двоичной формах, с или без
* модификации, допускаются при соблюдении следующих условий:
*
* * При повторном распространении исходного кода должно сохраняться указанное выше авторское право.
* обратите внимание, этот список условий и следующий отказ от ответственности.* * При повторном распространении в двоичной форме должно воспроизводиться указанное выше авторское право.
* обратите внимание, этот список условий и следующий отказ от ответственности в
* документация и / или другие материалы, поставляемые с дистрибутивом.
* * Ни название Калифорнийского университета в Беркли, ни
* имена участников могут использоваться для поддержки или продвижения продуктов
* получено из этого программного обеспечения без специального предварительного письменного разрешения.
*
* ДАННОЕ ПРОГРАММНОЕ ОБЕСПЕЧЕНИЕ ПРЕДОСТАВЛЯЕТСЯ РЕГЕНТАМИ И СОСТАВЛЯМИ `` КАК ЕСТЬ '' И ЛЮБЫМИ
* ЯВНЫЕ ИЛИ ПОДРАЗУМЕВАЕМЫЕ ГАРАНТИИ, ВКЛЮЧАЯ, НО НЕ ОГРАНИЧИВАясь, ПОДРАЗУМЕВАЕМЫЕ
* ГАРАНТИИ КОММЕРЧЕСКОЙ ЦЕННОСТИ И ПРИГОДНОСТИ ДЛЯ ОПРЕДЕЛЕННОЙ ЦЕЛИ ЯВЛЯЮТСЯ
* ОТКАЗ ОТ ОТВЕТСТВЕННОСТИ.НИ ПРИ КАКИХ ОБСТОЯТЕЛЬСТВАХ РЕГЕНТЫ И СОТРУДНИКИ НЕ НЕСЕТ ОТВЕТСТВЕННОСТИ ЗА КАКИЕ-ЛИБО
* ПРЯМЫЙ, КОСВЕННЫЙ, СЛУЧАЙНЫЙ, ОСОБЫЙ, ПРИМЕРНЫЙ ИЛИ КОСВЕННЫЙ УБЫТК
* (ВКЛЮЧАЯ, НО НЕ ОГРАНИЧИВАЯСЬ, ЗАКУПКИ ТОВАРОВ ИЛИ УСЛУГ ЗАМЕНЫ;
* ПОТЕРЯ ИСПОЛЬЗОВАНИЯ, ДАННЫХ ИЛИ ПРИБЫЛИ; ИЛИ ПЕРЕРЫВ В ДЕЯТЕЛЬНОСТИ), ОДНАКО ВЫЗВАННЫМ И
* ПО ЛЮБОЙ ТЕОРИИ ОТВЕТСТВЕННОСТИ, ЛИБО В КОНТРАКТЕ, СТРОГОЙ ОТВЕТСТВЕННОСТИ ИЛИ ИНОСТРАННОСТИ
* (ВКЛЮЧАЯ НЕБРЕЖНОСТЬ ИЛИ ИНОЕ), ВОЗНИКАЮЩИЕ ЛЮБЫМ СПОСОБОМ В РЕЗУЛЬТАТЕ ИСПОЛЬЗОВАНИЯ ЭТОГО
* ПРОГРАММНОЕ ОБЕСПЕЧЕНИЕ, ДАЖЕ ПРИ СООБЩЕНИИ О ВОЗМОЖНОСТИ ТАКОГО ПОВРЕЖДЕНИЯ.5 + 1)
* Инициализация: 0000
* Отражение входного байта: ложь
* Отражение выходной CRC: ложь
* Константа Xor для вывода CRC: 0000
* Вывод для «123456789»: 31C3
* /
static const uint16_t crc16tab [256] = {
0x0000,0x1021,0x2042,0x3063,0x4084,0x50a5,0x60c6,0x70e7,
0x8108,0x9129,0xa14a, 0xb16b, 0xc18c, 0xd1ad, 0xe1ce, 0xf1ef,
0x1231,0x0210,0x3273,0x2252,0x52b5,0x4294,0x72f7,0x62d6,
0x9339,0x8318,0xb37b, 0xa35a, 0xd3bd, 0xc39c, 0xf3ff, 0xe3de,
0x2462,0x3443,0x0420,0x1401,0x64e6,0x74c7,0x44a4,0x5485,
0xa56a, 0xb54b, 0x8528,0x9509,0xe5ee, 0xf5cf, 0xc5ac, 0xd58d,
0x3653,0x2672,0x1611,0x0630,0x76d7,0x66f6,0x5695,0x46b4,
0xb75b, 0xa77a, 0x9719,0x8738,0xf7df, 0xe7fe, 0xd79d, 0xc7bc,
0x48c4,0x58e5,0x6886,0x78a7,0x0840,0x1861,0x2802,0x3823,
0xc9cc, 0xd9ed, 0xe98e, 0xf9af, 0x8948,0x9969,0xa90a, 0xb92b,
0x5af5,0x4ad4,0x7ab7,0x6a96,0x1a71,0x0a50,0x3a33,0x2a12,
0xdbfd, 0xcbdc, 0xfbbf, 0xeb9e, 0x9b79,0x8b58,0xbb3b, 0xab1a,
0x6ca6,0x7c87,0x4ce4,0x5cc5,0x2c22,0x3c03,0x0c60,0x1c41,
0xedae, 0xfd8f, 0xcdec, 0xddcd, 0xad2a, 0xbd0b, 0x8d68,0x9d49,
0x7e97,0x6eb6,0x5ed5,0x4ef4,0x3e13,0x2e32,0x1e51,0x0e70,
0xff9f, 0xefbe, 0xdfdd, 0xcffc, 0xbf1b, 0xaf3a, 0x9f59,0x8f78,
0x9188,0x81a9,0xb1ca, 0xa1eb, 0xd10c, 0xc12d, 0xf14e, 0xe16f,
0x1080,0x00a1,0x30c2,0x20e3,0x5004,0x4025,0x7046,0x6067,
0x83b9,0x9398,0xa3fb, 0xb3da, 0xc33d, 0xd31c, 0xe37f, 0xf35e,
0x02b1,0x1290,0x22f3,0x32d2,0x4235,0x5214,0x6277,0x7256,
0xb5ea, 0xa5cb, 0x95a8,0x8589,0xf56e, 0xe54f, 0xd52c, 0xc50d,
0x34e2,0x24c3,0x14a0,0x0481,0x7466,0x6447,0x5424,0x4405,
0xa7db, 0xb7fa, 0x8799,0x97b8,0xe75f, 0xf77e, 0xc71d, 0xd73c,
0x26d3,0x36f2,0x0691,0x16b0,0x6657,0x7676,0x4615,0x5634,
0xd94c, 0xc96d, 0xf90e, 0xe92f, 0x99c8,0x89e9,0xb98a, 0xa9ab,
0x5844,0x4865,0x7806,0x6827,0x18c0,0x08e1,0x3882,0x28a3,
0xcb7d, 0xdb5c, 0xeb3f, 0xfb1e, 0x8bf9,0x9bd8,0xabbb, 0xbb9a,
0x4a75,0x5a54,0x6a37,0x7a16,0x0af1,0x1ad0,0x2ab3,0x3a92,
0xfd2e, 0xed0f, 0xdd6c, 0xcd4d, 0xbdaa, 0xad8b, 0x9de8,0x8dc9,
0x7c26,0x6c07,0x5c64,0x4c45,0x3ca2,0x2c83,0x1ce0,0x0cc1,
0xef1f, 0xff3e, 0xcf5d, 0xdf7c, 0xaf9b, 0xbfba, 0x8fd9,0x9ff8,
0x6e17,0x7e36,0x4e55,0x5e74,0x2e93,0x3eb2,0x0ed1,0x1ef0
};
uint16_t crc16 (const char * buf, int len) {
int counter;
uint16_t crc = 0;
for (счетчик = 0; счетчик > 8) ^ * buf ++) & 0x00FF];
вернуть crc;
}
Настроить резервный маршрутизатор | Начало работы с Junos OS
Чтобы добавить к устройству резервный маршрутизатор, настройте резервный маршрутизатор или
оператор inet6-backup-router в [редактировать систему] уровень иерархии.
Вы (сетевой администратор) можете использовать резервный маршрутизатор для доступа к сети, пока
загрузка, настройка и восстановление маршрутизатора или коммутатора без установки по умолчанию
маршрут в таблице переадресации. Включите дополнительный вариант назначения и укажите адрес, доступный через резервный маршрутизатор. Используйте адрес
формат сеть / длина маски . Этот
конфигурация поддерживает адреса как IPv4, так и IPv6.Префикс пункта назначения
адрес не может перекрываться с префиксом назначения, полученным из протокола маршрутизации
процесс (rpd).
Если конфигурация резервного маршрутизатора имеет несколько статических маршрутов, указывающих на шлюз из интерфейса управления Ethernet, вы должны настроить префиксы, которые больше специфичен, чем статический маршруты.
Например, если вы настроили статический маршрут 172.16.0.0 / 12 из сети управления Ethernet интерфейс для целей управления, вы должны указать конфигурацию резервного маршрутизатора как следует:
устанавливает назначение резервного маршрутизатора системы 172.29.201.62 [172.16.0.0/13 172.16.128.0/13]
Любые пункты назначения, определенные резервным маршрутизатором, не отображаются в таблице маршрутизации. Они видны только в локальной таблице переадресации, когда rpd не запущен.
В системах с двойным резервированием Routing Engine, доступность резервного Routing Engine
через частный интерфейс управления основывается только на функциональности резервный маршрутизатор конфигурация.Это не зависит от того,
Бег. На обеих машинах маршрутизации оператор backup-router добавляет
префикс назначения при загрузке. На основной системе маршрутизации статический маршрут требует
rpd, который будет запущен до того, как статический маршрут установит префикс назначения в
таблицы маршрутизации и пересылки.
Активные маршруты и более конкретные маршруты имеют приоритет над определенными префиксами назначения
с оператором резервного маршрутизатора .
Страница не найдена
Моя библиотека
раз- Моя библиотека
4.3.1.1 mysqlrouter - Параметры командной строки
- версия , -V
| Формат командной строки | - версия, -V |
|---|
Отображает номер версии и соответствующую информацию приложение и выходы. Например:
$> mysqlrouter --version
MySQL Router v8.0.27 в Linux (64-разрядная версия) (GPL Community Edition) - справка , -?
| Формат командной строки | --help, -? |
|---|
Отобразите справочную и информативную информацию и выйдите.
Параметр --help имеет
дополнительное преимущество. Наряду с объяснением каждого из
параметры, параметр --help также отображает пути, используемые для поиска файла конфигурации,
а также несколько путей по умолчанию. Следующий отрывок из --help вывод показывает
пример с машины Ubuntu 16.04:
$> mysqlrouter --help
...
Запустите MySQL Router.Конфигурация считывается из следующих файлов в указанном порядке (прилагается
в скобках означает недоступно для чтения):
(/etc/mysqlrouter/mysqlrouter.conf)
/home/philip/.mysqlrouter.conf
Путь к плагину:
/ usr / lib / x86_64-Linux-GNU / mysqlrouter
Каталог журналов по умолчанию:
/ вар / журнал / mysqlrouter
Каталог постоянных данных по умолчанию:
/ var / lib / mysqlrouter
Каталог состояний выполнения по умолчанию:
/ запустить / mysqlrouter
Использование: mysqlrouter [-V | --version] [-? | --Help]
... В разделе конфигурации показан порядок путей, которые может использоваться для чтения файла конфигурации.В этом случае, доступен только второй файл.
- бутстрап , URI -B URI
| Формат командной строки | - URI-загрузочный URI, -B URI |
|---|---|
| Тип | Строка |
Основной вариант для выполнения начальной загрузки MySQL Router с помощью подключение к серверу метаданных InnoDB Cluster по URI предоставлена.Маршрутизатор MySQL настраивается на основе информации получено с сервера метаданных InnoDB Cluster. А при необходимости запрашивается пароль. Если имя пользователя не предоставляется как часть URI, тогда имя пользователя по умолчанию "root" используется. См. Подключение с использованием строк подключения типа URI для информация об использовании пути для указания экземпляра сервера.
Примечание
В то время как - bootstrap принимает URI для соединений TCP / IP, используя - бутстрап-сокет вариант с локальным именем сокета домена Unix заменяет
"host: port" часть URI, переданная в - вариант загрузки с
розетка на той же машине.
По умолчанию процесс начальной загрузки выполняет общесистемную
конфигурация MySQL Router. Только один экземпляр MySQL Router может
быть настроенным для общесистемной работы. Экземпляр системы
маршрутизатора MySQL имеет router_name «system».
Если требуются дополнительные экземпляры, используйте - каталог вариант для
создавать автономные установки MySQL Router.
URI : экземпляр сервера из
Кластер InnoDB для получения информации о метаданных.Если
при условии, что URI доступен только для чтения
например, MySQL Router автоматически переподключается к чтению-записи
экземпляр в кластере InnoDB, чтобы он мог зарегистрировать маршрутизатор MySQL.
Если файл конфигурации уже существует при запуске MySQL Router
с --bootstrap ,
существующий router_id в этом файле используется повторно,
и происходит процесс реконфигурации. Файл конфигурации
восстанавливается с нуля, а сервер метаданных MySQL Router
аккаунт воссоздан, но с таким же именем.
В процессе реконфигурации все изменения, внесенные в
существующий файл конфигурации отбрасывается. Чтобы настроить
файл конфигурации и по-прежнему сохранять возможность автоматического
реконфигурация (начальная загрузка), вы можете использовать --extra-config команда
параметр строки, чтобы указать дополнительный файл конфигурации, который
читается после основного файла конфигурации. Эти конфигурации
параметры используются, потому что этот дополнительный файл конфигурации
загружается после основного файла конфигурации.
В процессе начальной загрузки создается новая учетная запись пользователя MySQL с
случайно сгенерированный пароль для использования этим конкретным маршрутизатором MySQL
пример. Эта учетная запись используется маршрутизатором MySQL при подключении к
сервер метаданных и кластер InnoDB для получения информации
о его текущем состоянии. Для получения подробной информации об этом
пользователя, включая способ хранения его пароля и MySQL
требуемые привилегии, см. документацию по MySQL
опция пользователя .
Сгенерированный файл конфигурации называется mysqlrouter.conf и его расположение
зависит от типа настраиваемого экземпляра, системы,
и пакет. Для общесистемных установок генерируемые
файл конфигурации добавлен в конфигурацию системы
каталог, например / и т. д. или % PROGRAMDATA% \ MySQL \ Маршрутизатор MySQL \ .
Выполнение mysqlrouter - отобразит справку это место.
Параметр --user требуется при выполнении
начальная загрузка с суперпользователем (uid = 0). Хотя это не рекомендуется,
принуждение суперпользователя возможно, передав его имя как
аргумент, например --user = root .
Примечание
Минимальные разрешения GRANT, необходимые для выполнения --boostrap являются:
GRANT CREATE USER ON *. * TO ' bootstrapuser ' @ '%' С ОПЦИЕЙ GRANT;
GRANT SELECT, INSERT, UPDATE, DELETE, EXECUTE ON mysql_innodb_cluster_metadata.* TO ' bootstrapuser ' @ '%';
GRANT SELECT ON mysql.user TO ' bootstrapuser ' @ '%';
GRANT SELECT ON performance_schema.replication_group_members TO ' bootstrapuser ' @ '%';
GRANT SELECT ON performance_schema.replication_group_member_stats TO ' bootstrapuser ' @ '%';
GRANT SELECT ON performance_schema.global_variables TO ' bootstrapuser ' @ '%'; Использование --bootstrap добавляет
значения по умолчанию для сгенерированного файла конфигурации MySQL Router,
и некоторые из этих значений по умолчанию зависят от других условий.Ниже перечислены некоторые из условий, которые влияют на
сгенерированные значения по умолчанию, где значение по умолчанию определяется путем передачи
в - сам бутстрап .
Таблица 4.6 Условия, влияющие на значения по умолчанию --bootstrap
| Состояние | Описание |
|---|---|
--conf-base-port | Изменения сгенерированы По умолчанию сгенерировано Начиная с Router 8.0.24: Настройка |
--conf-use-сокеты | Вставляет определения socket для каждого типа подключения. |
--conf-skip-tcp | Определения соединений TCP / IP не определены. |
- каталог | Влияет на все пути к файлам, а также создает дополнительные файлы. |
| Другое | Этот список не является исчерпывающим, другие параметры и условия также влияют сгенерированные значения. |
- бутстрап-сокет имя_ розетки
| Формат командной строки | --bootstrap-socket имя_сокета |
|---|---|
| В зависимости от платформы | Linux |
Используется вместе с - bootstrap для начальной загрузки
использование локального сокета домена Unix вместо TCP / IP.В - значение bootstrap-socket заменяет часть "хост: порт" в - определение bootstrap с назначенным именем сокета для подключения к MySQL
сервер метаданных с использованием сокетов домена Unix. Это MySQL
экземпляр, из которого выполняется загрузка, и этот экземпляр
должны быть на одной машине, если используются розетки. Для
дополнительные сведения о том, как работает начальная загрузка, см. - бутстрап .
Этот вариант отличается от --conf-use-sockets команда
параметр линии, который устанавливает socket файл конфигурации
вариант во время процесса начальной загрузки.
Эта опция недоступна в Windows.
- каталог , dir_path -d dir_path
| Формат командной строки | --directory dir_path, -d dir_path |
|---|---|
| Тип | Строка |
Указывает, что автономная установка MySQL Router будет создается в указанном каталоге вместо настройки общесистемный экземпляр маршрутизатора.Это также позволяет использовать несколько маршрутизаторов. экземпляры, которые будут созданы в одной системе.
Самостоятельная структура каталогов для маршрутизатора:
$ путь / start.sh
$ путь / stop.sh
$ путь / mysqlrouter.pid
$ путь / mysqlrouter.conf
$ путь / mysqlrouter.key
$ path / run
$ путь / бег / брелок
$ путь / данные
$ путь / журнал
$ путь / журнал / mysqlrouter.log Если указана эта опция, файл связки ключей хранится в
каталог состояния выполнения этого экземпляра под run / в указанном каталоге, как
в отличие от общесистемного каталога состояний выполнения.
Если --conf-use-sockets -
также включен, то сгенерированные файлы сокетов также добавляются в
этот каталог.
- мастер-ключ-писатель
| Формат командной строки | --master-key-writer путь_к_файлу |
|---|---|
| Представлен | 8.0.12 |
| Тип | Строка |
Этот необязательный параметр начальной загрузки принимает сценарий, который читает
мастер-ключ от STDIN .Он также использует ROUTER_ID переменная среды, установленная
Маршрутизатор MySQL до сценария master-key-writer называется.
Мастер-ключ-писатель и Мастер-ключ-считыватель Необходимо использовать опции
вместе, и их использование означает master_key_file параметр не должен быть определен в mysqlrouter.conf как главный ключ не
написано в mysqlrouter.ключ мастер-ключ
файл.
Это также записывается в сгенерированную конфигурацию маршрутизатора MySQL.
файл как мастер-ключ-писатель [ПО УМОЛЧАНИЮ]
вариант.
Пример содержимого сценария bash с именем writer.sh , используемый в нашем примере:
#! / Bin / bash
KID _ = $ (пользователь keyctl padd $ {ROUTER_ID} @us <& 0) Пример использования:
$> mysqlrouter --bootstrap = 127.0.0.1: 3310 --master-key-reader =. / Reader.sh --master-key-writer =. / Writer.sh Это также влияет на генерируемые mysqlrouter.conf , например:
[ПО УМОЛЧАНИЮ]
...
мастер-ключ-ридер = reader.sh
мастер-ключ-писатель = писатель.sh - мастер-ключ-считыватель
| Формат командной строки | - путь к файлу для чтения ключей-мастер-ключей |
|---|---|
| Представлен | 8.0,12 |
| Тип | Строка |
Этот необязательный параметр начальной загрузки принимает сценарий, который записывает
мастер-ключ к STDOUT . Он также использует
переменная среды ROUTER_ID , установленная
Маршрутизатор MySQL до сценария для чтения мастер-ключей называется.
Устройство считывания мастер-ключей и мастер-ключ-писатель опции должны использоваться
вместе, и их использование означает master_key_file параметр не должен быть определен в mysqlrouter.conf , так как мастер-ключ не
записывается на главный ключ mysqlrouter.key файл, и вместо этого использует значение, предоставленное этой опцией
сценарий.
Это также записывается в сгенерированную конфигурацию маршрутизатора MySQL.
файл как устройство чтения мастер-ключей [ПО УМОЛЧАНИЮ]
вариант.
Пример содержимого сценария bash с именем reader.sh , используемый в нашем примере:
#! / Bin / bash
KID _ = $ (keyctl search @us user $ {ROUTER_ID} 2> / dev / null)
если [ ! -z $ KID_]; тогда
keyctl pipe $ KID_
fi Пример использования:
$> mysqlrouter --bootstrap = 127.0.0.1: 3310 --master-key-reader =. / Reader.sh --master-key-writer =. / Writer.sh Это также влияет на генерируемые mysqlrouter.conf , например:
[ПО УМОЛЧАНИЮ]
...
мастер-ключ-ридер = reader.sh
мастер-ключ-писатель = писатель.sh - строгий
| Формат командной строки | - район |
|---|---|
| Представлен | 8.0,19 |
| Тип | Строка |
Включает строгий режим, который, например, вызывает загрузку - аккаунт проверка пользователя, чтобы остановить
процесс начальной загрузки, а не только выдача предупреждения и продолжение
если указанный пользователь не прошел проверку.
- счет
| Формат командной строки | - имя пользователя учетной записи |
|---|---|
| Представлен | 8.0,19 |
| Тип | Строка |
Параметр начальной загрузки для указания пользователя MySQL для использования, который
либо повторно использует существующую учетную запись пользователя MySQL, либо создает ее;
поведение, контролируемое соответствующими - опция создания учетной записи .
С - счет , использование способствует простоте
управление простотой развертывания, поскольку несколько маршрутизаторов могут
используют одну и ту же учетную запись, а имя пользователя и пароль
определяется вручную, а не создается автоматически.
Установка этого параметра запускает запрос пароля для этого учетной записи независимо от того, доступен ли пароль в брелок для ключей.
Самостоятельная загрузка без прохождения - аккаунт не воссоздает существующую учетную запись сервера MySQL. До
MySQL Router 8.0.18, при начальной загрузке будет УДАЛЕН существующий пользователь.
и СОЗДАЙТЕ его заново.
Использование этой опции предполагает, что у пользователя есть достаточный доступ
права для маршрутизатора, потому что процесс начальной загрузки не
попытаться добавить недостающие гранты к существующим учетным записям.В
процесс начальной загрузки проверяет разрешения и выходные данные
информация в консоль о неудавшейся проверке. Бутстрап
процесс продолжается, несмотря на эти неудачные проверки, если
также используется необязательный параметр --strict .
Пример необходимых разрешений:
GRANT SELECT ON mysql_innodb_cluster_metadata. * TO `theuser`
GRANT SELECT ON performance_schema.replication_group_members TO `theuser`
GRANT SELECT ON performance_schema.Replication_group_member_stats TO `theuser` Пароль не принимается из командной строки. Например, передача "foo: bar" предполагает, что "foo: bar" - это желаемое имя пользователя. вместо пользователя foo с паролем бар .
- создать учетную запись
| Формат командной строки | - поведение создания учетной записи |
|---|---|
| Представлен | 8.0,19 |
| Тип | Строка |
| Значение по умолчанию | если не существует |
| Допустимые значения | |
Укажите политику создания учетной записи, чтобы защититься от случайная загрузка с неправильной учетной записью. Возможные значения:
, если не существует(по умолчанию): Bootstrap так или иначе; повторно использовать учетную запись, если она существует, в противном случае создать это.всегда: только начальная загрузка, если учетная запись еще не существует; и создайте его.никогда: только начальная загрузка, если учетная запись уже существует; и использовать его повторно.
Эта опция требует, чтобы --account также используется опция, и что --account-host не используется.
- хост-аккаунт
| Формат командной строки | --account-host host_pattern |
|---|---|
| Представлен | 8.0.12 |
| Тип | Строка |
| Значение по умолчанию | % |
Шаблон хоста, используемый для учетных записей, созданных MySQL Router во время процесс начальной загрузки.Это необязательно, по умолчанию - «%».
Передайте этот параметр несколько раз, чтобы определить несколько шаблоны, и в этом случае сгенерированные учетные записи MySQL используют тот же пароль.
Примечание
Маршрутизатор не выполняет проверку работоспособности и не гарантирует что шаблон разрешает маршрутизатору подключаться.
Примечание
При загрузке повторно используются существующие учетные записи маршрутизатора путем удаления и воссоздание пользователя, и этот процесс воссоздания пользователя применяется к каждому хосту.
Примеры:
# Один хост
$> mysqlrouter --bootstrap localhost: 3310 --account-host host1
# Или несколько хостов
$> mysqlrouter --bootstrap localhost: 3310 --account-host host1 --account-host host2 --account-host host3 --conf-use-сокеты
| Формат командной строки | --conf-use-сокеты |
|---|---|
| В зависимости от платформы | Linux |
Включает локальные сокеты домена Unix.
Эта опция используется при начальной загрузке, и ее включение добавляет
опцию socket к
сгенерированный файл конфигурации.
Имя сгенерированного файла сокета зависит от
Режим и протокол Опции .
При включенном классическом протоколе файл называется mysql.sock в режиме чтения-записи и mysqlro.sock в режиме только для чтения.С
Протокол X включен, файл называется mysqlx.sock в режиме чтения-записи и mysqlxro.sock в режиме только для чтения.
Эта опция недоступна в Windows.
--conf-use-gr-notifications
| Формат командной строки | --conf-use-gr-notifications |
|---|---|
| Представлен | 8.0,17 |
Включает use_gr_notifications Параметр [metadata_cache] во время начальной загрузки. Когда включено, Router
асинхронно уведомляется о большинстве изменений кластера. Видеть use_gr_notifications для
больше информации.
--pid-файл путь
| Формат командной строки | - путь кpid-файлу |
|---|---|
| Представлен | 8.0,20 |
| Тип | Строка |
Устанавливает расположение файла PID. Это можно установить в трех
разными способами (в порядке приоритета): это --pid-file параметр командной строки, настройка pid_file в маршрутизаторе
файл конфигурации или определение ROUTER_PID переменная среды.
Если --bootstrap - это
указано, то установка --pid-file вызывает сбой маршрутизатора.Этот
отличается от ROUTER_PID и параметра конфигурации pid_file,
которые игнорируются, если указан --bootstrap.
Если --bootstrap - нет
указано, то следующая причина сбоя маршрутизатора:
--pid-file уже существует, pid_file или ROUTER_PID установлены, но
пусто, или если маршрутизатор не может записать файл PID.
- хост-отчет
| Формат командной строки | - имя хоста-хоста |
|---|---|
| Представлен | 8.0,12 |
| Тип | Строка |
При желании укажите имя хоста маршрутизатора вместо того, чтобы полагаться на автоматическое обнаружение для определения видимого извне имени хоста зарегистрированы в метаданных во время процесса начальной загрузки.
Маршрутизатор не проверяет и не подтверждает, что предоставленное имя хоста достижим, но использует RFC 1123 для проверки имен хостов и RFC 2181 для проверки адресов.
Примечание
До версии 8.0.23 проверка проверяла строку имени хоста на наличие недопустимые символы, только буквенно-цифровые, '-', '.' и Допускались символы "_". Например, это означало, что Адреса IPv6 не разрешены.
Предоставленное имя хоста записывается в поле host_name поля Таблица mysql_innodb_cluster_metadata.hosts в MySQL InnoDB хранилище метаданных кластера.
--conf-skip-tcp
| Формат командной строки | --conf-skip-tcp |
|---|---|
| В зависимости от платформы | Linux |
Пропускает настройку TCP-порта для прослушивания входящих
соединения. Смотрите также --conf-use-сокеты .
Эта опция недоступна в Windows.
--conf-base-порт номер порта
| Формат командной строки | --conf-base-port номер_порта |
|---|---|
| Тип | Целое число |
Базовое (первое) значение, используемое для прослушивающих TCP-портов, путем установки bind_port для каждого
загруженный маршрут.
Это значение используется для классического маршрута чтения-записи, и каждый дополнительный выделенный порт увеличивается на единицу. Порядок портов - классический для чтения-записи / только для чтения, а затем x чтение-запись / только чтение.
Начиная с Router 8.0.24: Настройка --conf-base-port на 0 изменяет значения по умолчанию bind_port на
предыдущие (до 8.0.24) значения по умолчанию, которые были следующими: Для
классический протокол, чтение-запись использует 6446 и только чтение использует
6447, а для протокола X чтение-запись использует 64460 и
Только для чтения использует 64470.
Пример использования:
# Пример без --conf-base-port
$> mysqlrouter --bootstrap корень @ localhost: 3310
...
Классические соединения протокола MySQL с кластером devCluster:
- Соединения для чтения / записи: localhost: 6446
- Соединения только для чтения: localhost: 6447
Соединения по протоколу X с кластером devCluster:
- Соединения для чтения / записи: localhost: 6448
- Соединения только для чтения: localhost: 6449
# Пример, демонстрирующий, что --conf-base-port установлен в 0
$> mysqlrouter --bootstrap root @ localhost: 3310 --conf-base-порт 0
...
Классические соединения протокола MySQL с кластером devCluster:
- Соединения для чтения / записи: localhost: 6446
- Соединения только для чтения: localhost: 6447
Соединения по протоколу X с кластером devCluster:
- Соединения для чтения / записи: localhost: 64460
- Соединения только для чтения: localhost: 64470 --conf-привязка-адрес адрес
| Формат командной строки | --conf-bind-address адрес |
|---|---|
| Тип | Строка |
| Значение по умолчанию | 0.0,0.0 |
Изменяет bind_address значение установлено --bootstrap в сгенерированном файле конфигурации маршрутизатора. По умолчанию,
самонастройка устанавливает bind_address = 0.0.0.0 для
каждый маршрут, и эта опция изменяет это значение.
Примечание
Значение по умолчанию bind_address : 127.0.0.1 если bind_address не определен.
- время ожидания чтения число_секунд
| Формат командной строки | - таймаут чтения num_seconds |
|---|---|
| Тип | Целое число |
| Значение по умолчанию | 30 |
Количество секунд до операций чтения на сервер метаданных считаются истекшими.
Это влияет на операции чтения во время начальной загрузки.
процесс, а также влияет на нормальные операции маршрутизатора MySQL путем
установление связанных read_timeout в сгенерированном файле mysqlrouter.conf .
Этот параметр установлен в [ПО УМОЛЧАНИЮ] пространство имен.
- тайм-аут соединения число_секунд
| Формат командной строки | - тайм-аут соединения num_seconds |
|---|---|
| Тип | Целое число |
| Значение по умолчанию | 30 |
Количество секунд до попытки подключения к метаданным сервер считается истекшим по тайм-ауту.
Это влияет на соединения во время процесса начальной загрузки,
а также влияет на обычные операции маршрутизатора MySQL, задавая
связанный connect_timeout в сгенерированном файле mysqlrouter.conf .
Есть два варианта connect_timeout .
Вариант сервера метаданных определяется в [ПО УМОЛЧАНИЮ] пространство имен, а сервер MySQL
вариант определен в [маршрутизация] пространство имен.
- пользователь
{ , имя_пользователя | user_id } -u
{ имя_пользователя | user_id }
| Формат командной строки | --user {user_name | user_id}, -u {user_name | user_id} |
|---|---|
| В зависимости от платформы | Linux |
| Тип | Строка |
Запустите mysqlrouter от имени пользователя с именем имя_пользователя или числовой идентификатор пользователя user_id .«Пользователь» в
этот контекст относится к учетной записи для входа в систему, а не к MySQL
пользователь, указанный в таблицах привилегий. При начальной загрузке все
сгенерированные файлы принадлежат этому пользователю, и это также устанавливает
связанная пользовательская опция .
Эта система пользователь определяется в файле конфигурации под [ПО УМОЛЧАНИЮ] пространство имен. Для дополнительных
информацию см. пользователь в документации по опции, что --user настраивает.
Параметр --user требуется при выполнении
загрузитесь как суперпользователь (uid = 0). Хотя это не рекомендуется,
принуждение суперпользователя возможно, передав его имя как
аргумент, например --user = root .
Эта опция недоступна в Windows.
- имя имя_ маршрутизатора
| Формат командной строки | --name router_name |
|---|---|
| Тип | Строка |
| Значение по умолчанию | система |
При начальной загрузке указывает символическое имя для
автономный экземпляр маршрутизатора.Эта опция не является обязательной, и
используется с - каталог .
При создании нескольких экземпляров имена должны быть уникальными.
- принудительная проверка пароля
| Формат командной строки | - принудительная проверка пароля |
|---|---|
| В зависимости от платформы | Linux |
По умолчанию MySQL Router пропускает MySQL Server's validate_password механизм, а вместо этого Router генерирует и использует СИЛЬНЫЙ пароль на основе известного validate_password настройки по умолчанию.Это потому, что validate_password может быть настраивается пользователем и Роутер не может учесть необычные пользовательские настройки.
Эта опция гарантирует, что проверка пароля (validate_password) не пропускается для сгенерированных паролей, и по умолчанию он отключен.
- повторы пароля num_retries
| Формат командной строки | --password-retries num_retries |
|---|---|
| Тип | Целое число |
| Значение по умолчанию | 20 |
| Минимальное значение | 1 |
| Максимальное значение | 10000 |
Указывает, сколько раз маршрутизатор MySQL должен пытаться генерировать пароль при создании учетной записи пользователя с правила проверки пароля.Значение по умолчанию - 20. Действительный диапазон от 1 до 10000.
Наиболее вероятная причина отказа - нестандартные
validate_password с необычными требованиями, такими как
Минимум 50 символов. В этом неудачном сценарии либо - принудительная проверка пароля установлено значение true и / или mysql_native_password Подключаемый модуль сервера MySQL
отключен (этот плагин позволяет обходить проверку).
- сила
| Формат командной строки | - усилие |
|---|
Принудительно перенастроить ранее настроенный маршрутизатор экземпляр на хосте.
--ssl-режим режим
| Формат командной строки | - режим SSL |
|---|---|
| Тип | Строка |
| Значение по умолчанию | ПРЕДПОЧТИТЕЛЬНО |
| Допустимые значения | |
Режим подключения SSL для использования во время начальной загрузки и в обычном режиме.
операция при подключении к серверу метаданных.Аналогично --ssl-mode в mysql клиент.
Во время начальной загрузки все подключения к серверам метаданных, выполненные
Маршрутизатор будет использовать указанные параметры SSL. Если ssl_mode не указан в
конфигурации, по умолчанию будет установлено ПРЕДПОЧТИТЕЛЬНОЕ. Во время нормального
после запуска маршрутизатора его плагин Metadata Cache
прочитает и соблюдает все настроенные параметры SSL.
Если установлено значение, отличное от значения по умолчанию (ПРЕДПОЧТИТЕЛЬНО), ssl_mode запись вставлена под [metadata_cache] раздел в сгенерированном
конфигурационный файл.
Доступные значения: DISABLED, PREFERRED, REQUIRED, VERIFY_CA, и VERIFY_IDENTITY. PREFERRED - значение по умолчанию. Как и в случае с клиент mysql , это значение без учета регистра.
Эквивалент файла конфигурации задокументирован отдельно на ssl_mode .
--ssl-cert путь к файлу
| Формат командной строки | --ssl-key путь_к_файлу |
|---|---|
| Тип | Строка |
Путь к файлу сертификата открытого ключа SSL в PEM
формат.Это используется для облегчения аутентификации на стороне клиента.
во время процесса начальной загрузки. Это напрямую соответствует и использует
функциональность клиента MySQL --ssl-cert вариант.
Как и --ssl-key , этот параметр используется только
во время начальной загрузки, которая использует учетную запись root. Это полезно, когда
учетная запись root была создана с REQUIRE X509, и поэтому
вход в систему как root требует, чтобы клиент аутентифицировал себя.
--ssl-ключ путь к файлу
| Формат командной строки | --ssl-key путь_к_файлу |
|---|---|
| Тип | Строка |
Путь к файлу закрытого ключа SSL в формате PEM. Этот
используется для облегчения аутентификации на стороне клиента во время
процесс начальной загрузки.Это напрямую соответствует и использует
функциональность клиента MySQL --ssl-key опция.
Как и --ssl-cert , это
опция используется только во время процесса начальной загрузки, который использует
учетная запись root. Это полезно при создании учетной записи root
с REQUIRE X509, поэтому для входа в систему с правами root требуется
клиент для аутентификации.
--ssl-шифр цифр
| Формат командной строки | --ssl-шифры |
|---|---|
| Тип | Строка |
| Значение по умолчанию | |
Список разрешенных шифров SSL, разделенных двоеточиями (":", если SSL включен.
--tls-версия версии
| Формат командной строки | --tls-версия версии |
|---|---|
| Тип | Строка |
| Значение по умолчанию | |
Список версий TLS, разделенных запятыми (","), для запроса, если SSL включен.
--ssl-ca путь к файлу
| Формат командной строки | --ssl-ca путь_ к файлу |
|---|---|
| Тип | Строка |
| Значение по умолчанию | |
Путь к файлу SSL CA для проверки сертификата сервера против.
--ssl-capath dir_path
| Формат командной строки | --ssl-capath dir_path |
|---|---|
| Тип | Строка |
| Значение по умолчанию | |
Путь к каталогу, содержащему файлы CA SSL для проверки сертификат сервера против.
--ssl-crl путь к файлу
| Формат командной строки | --ssl-crl путь_ к файлу |
|---|---|
| Тип | Строка |
| Значение по умолчанию | |
Путь к файлу SSL CRL для использования при проверке сервера сертификат.
--ssl-crlpath dir_path
| Формат командной строки | --ssl-crlpath dir_path |
|---|---|
| Тип | Строка |
| Значение по умолчанию | |
Путь к каталогу, содержащему файлы SSL CRL для использования при проверка сертификата сервера.
--config , путь к файлу -c путь к файлу
| Формат командной строки | --config file_path, -c file_path |
|---|
Используется для указания пути и имени файла для конфигурации файл для использования. Используйте эту опцию, если вы хотите использовать файл конфигурации, расположенный в папке, отличной от папки по умолчанию локации.
При использовании с --bootstrap , а если
файл конфигурации уже существует, копия текущего файла
сохраняется с расширением .bak , если
сгенерированное содержимое файла конфигурации отличается от
оригинал. Существующие файлы .bak являются
перезаписан.
--extra-config , file_path -a путь к файлу
| Формат командной строки | --extra-config file_path, -a file_path |
|---|
Используется для предоставления необязательного дополнительного файла конфигурации для использовать.Используйте эту опцию, если вы хотите разделить конфигурацию файл на две части для тестирования, несколько экземпляров приложение, работающее на той же машине, и т. д.
Этот файл конфигурации читается после основной конфигурации файл. Если есть конфликты (опция задается в нескольких файлы конфигурации), значения из файла, который загружается последним используется.
- установка-сервис
| Формат командной строки | - установка-сервис |
|---|---|
| В зависимости от платформы | Окна |
Установите Router как службу Windows, которая запускается автоматически при запуске Windows.Название сервиса MySQLRouter .
Этот процесс установки не проверяет конфигурацию
файлы, переданные через --конфиг .
Эта опция доступна только в Windows.
- руководство по установке и обслуживанию
| Формат командной строки | - руководство по установке и обслуживанию |
|---|---|
| В зависимости от платформы | Окна |
Установите MySQL Router как службу Windows, которую можно вручную начал.Имя службы - MySQLRouter .
Эта опция доступна только в Windows.
- удаленное обслуживание
| Формат командной строки | - удаленное обслуживание |
|---|---|
| В зависимости от платформы | Окна |
Удалите службу Windows Router.
Эта опция доступна только в Windows.
- обслуживание
| Формат командной строки | - обслуживание |
|---|---|
| В зависимости от платформы | Окна |
Запустите маршрутизатор как службу Windows. Это частный вариант, это означает, что он предназначен только для использования службой Windows при запуске роутера как службы.
Эта опция доступна только в Windows.
--update-credentials-section
| Формат командной строки | --update-credentials-section имя_секции |
|---|---|
| В зависимости от платформы | Окна |
Эта опция доступна только в Windows и относится к ее хранилище паролей.
--conf-target-cluster
| Формат командной строки | --conf-target-cluster значение |
|---|---|
| Представлен | 8.0.27 |
| Тип | Строка |
| Допустимые значения | |
Устанавливает target_cluster метаданных MySQL Router
вариант.Принимает одну из следующих строк:
текущий: наборыtarget_clusterв кластер, содержащий узел, против которого усиливается. Он определяет его как значение UUID кластера.Если это также первичный, он не динамически следить за изменениями ролей, например,
первичныйделает; вместо этого он остается статичным.первичный: наборыtarget_clusterв первичный кластер, в том числе, когда он изменяется во время выполнения.
См. Также --config-target-cluster-by-name ,
который устанавливает target_cluster на конкретный
статическое имя кластера.
Примечание
Для загрузки с ClusterSet требуется cluster_type Конфигурация маршрутизатора
опция установлена на гр .
--conf-target-cluster-by-name
| Формат командной строки | --conf-target-cluster-by-name имя_кластера |
|---|---|
| Представлен | 8.0.27 |
| Тип | Строка |
Устанавливает target_cluster метаданных MySQL Router
к конкретному имени кластера.
Или вместо этого используйте --conf-target-cluster , чтобы
назначьте динамический тип кластера, например первичный.
--remove-credentials-section имя_секции
| Формат командной строки | --remove-credentials-section имя_секции |
|---|---|
| В зависимости от платформы | Окна |
Удалите учетные данные для данного раздела.
Эта опция доступна только в Windows и относится к ее хранилище паролей.
- учетные данные для всех
| Формат командной строки | - все учетные данные |
|---|---|
| В зависимости от платформы | Окна |
Очистите хранилище паролей, удалив все учетные данные, хранящиеся в Это.
Эта опция доступна только в Windows и относится к ее хранилище паролей.
- отключение-отдых
| Формат командной строки | - отключение-отдых |
|---|---|
| Представлен | 8.0.22 |
По умолчанию сведения о конфигурации для
MySQL Router REST API
функциональность веб-сервиса добавляется к сгенерированному mysqlrouter.conf при загрузке; а также
этот параметр означает, что эти детали не добавляются. Это делает
не отключать функциональность REST API, так как REST API
функциональность может быть настроена вручную (для включения) позже
на.
- https-порт
| Формат командной строки | - значение HTTPS-порта |
|---|---|
| Представлен | 8.0,22 |
| Тип | Целое число |
| Значение по умолчанию | 8443 |
| Минимальное значение | 1 |
| Максимальное значение | 65535 |
При желании определите порт HTTP-сервера для
API REST маршрутизатора MySQL в разделе [http_server] в
сгенерировал mysqlrouter.conf при начальной загрузке.По умолчанию 8443. Доступность порта не проверяется.
EOS 4.27.0F - IS-IS - Arista
Информация о маршрутизации сегмента IS-IS отображается с помощью следующих команд:
показать детали базы данных isis
Команда show isis database detail обеспечивает представление LSPDB различные устройства в домене IS-IS. На выходе отображаются TLV. и суб-TLV, которые создаются самостоятельно или имеют были получены от других маршрутизаторов.
Пример
switch # показать деталь базы данных isis
Экземпляр ISIS: inst1 VRF: по умолчанию
База данных состояний каналов ISIS уровня 2
LSPID Seq Num Cksum Life IS Флаги
1111.1111.1001.00-00 10 63306 751 L2 <>
NLPID: 0xCC (IPv4) 0x8E (IPv6)
Адрес района: 49.0001
Адрес интерфейса: 1.0.7.1
Адрес интерфейса: 1.0.0.1
Адрес интерфейса: 2000: 0: 0: 47 :: 1
Адрес интерфейса: 2000: 0: 0: 40 :: 1
IS Сосед: lf319.53 Метрика: 10
LAN-Adj-sid: 100000 флагов: [L V] вес: 0 ID системы: 1111.1111.1002
IS Neighbor (MT-IPv6): lf319.53 Метрика: 10
LAN-Adj-sid: 100001 флаги: [L V F] вес: 0 ID системы: 1111.1111.1002
Доступность: 1.0.11.0/24 Метрика: 1 Тип: 1 Вверх
SID префикса SR: 10 Флаги: [R] Алгоритм: 0
Доступность: 1.0.3.0/24 Метрика: 1 Тип: 1 Вверх
Доступность: 1.0.7.1/32 Метрика: 10 Тип: 1 Вверх
SR Prefix-SID: 2 Флаги: [N] Алгоритм: 0
Доступность: 1.0.0.0/24 Метрика: 10 Тип: 1 Вверх
Доступность (MT-IPv6): 2000: 0: 0: 4b :: / 64 Метрика: 1 Тип: 1 Вверх
SID префикса SR: 11 Флаги: [R] Алгоритм: 0
Доступность (MT-IPv6): 2000: 0: 0: 43 :: / 64 Метрика: 1 Тип: 1 Вверх
Доступность (MT-IPv6): 2000: 0: 0: 47 :: 1/128 Метрика: 10 Тип: 1 Вверх
SID префикса SR: 3 Флаги: [N] Алгоритм: 0
Доступность (MT-IPv6): 2000: 0: 0: 40 :: / 64 Метрика: 10 Тип: 1 Вверх
Возможности маршрутизатора: 252.252.1.252 Флаги: []
Возможности SR: Флаги: [I V]
SRGB База: 0 Диапазон: 65536
Привязка сегмента: Флаги: [F] Вес: 0 Диапазон: 1 Pfx 2000: 0: 0: 4f :: 1/128
SID префикса SR: 19 Флаги: [] Алгоритм: 0
Привязка сегмента: Флаги: [] Вес: 0 Диапазон: 1 Pfx 1.0.15.1/32
SID префикса SR: 18 Флаги: [] Алгоритм: 0
показать сегментную маршрутизацию isis
Команда show isis segment-routing отображает сводную информацию о статусе IS-IS SR.
Пример
switch (config) # показать сегментную маршрутизацию isis
Идентификатор системы: 1111.1111.1002 Экземпляр: inst1
Поддерживаемый SR Уровень данных: MPLS Идентификатор маршрутизатора SR: 252.252.2.252
SR Global Block (SRGB): База: 0 Размер: 65536
Режим распределения Adj-SID: SR-смежности
Пул распределения Adj-SID: База: 100000 Размер: 16384
Все сегменты префикса имеют: P: 0 E: 0 V: 0 L: 0
Все сегменты смежности имеют: F: 0 B: 0 V: 1 L: 1 S: 0
Алгоритм доступности ISIS: SPF (0)
Количество одноранговых узлов, поддерживающих маршрутизацию сегментов ISIS: 3
Статистика самостоятельного сегмента:
Узлы-сегменты: 2
Префикс-сегментов: 2
Сегменты прокси-узла: 0
Сегменты смежности:
О выходе
В первой строке выходных данных отображается системный идентификатор IS-IS этого устройства и имя экземпляра, с которым настроен IS-IS.
Поддерживаемая плоскость данных отображается на фоне поддерживаемой SR плоскости данных. поле, тогда как идентификатор маршрутизатора объявляется в маршрутизаторе Возможности указаны в поле SR Router ID.
Используемый SRGB и пул меток MPLS, используемый для сегмента смежности распределение упоминается в этом выводе. Текущее соседство режим распределения, который относится к тому, распределяем ли мы смежность сегменты для всех смежностей IS-IS или только тех смежностей, которые поддержка SR или Ни одна из смежностей не отображается в Adj-SID поле режима распределения.
Флаг содержимого всех префиксных сегментов, созданных на этом маршрутизаторе, Flag содержимое всех сегментов смежности, созданных на этом маршрутизаторе и поддерживаемый алгоритм доступности IS-IS был предоставлен через этот вывод команды, и они несут значение согласно IS-IS SR Проект IETF.
Эта команда show предоставляет статистику, относящуюся к IS-IS SR с точки зрения различные счетчики, начиная от количества одноранговых узлов IS-IS SR, количество идентификаторов SID узла, идентификаторов безопасности префикса, сегментов прокси-узла и смежности сегменты, создаваемые на этом маршрутизаторе в IS-IS.
Команда show isis segment-routing также предоставляет информацию о том, была ли маршрутизация сегментов административно отключен, как показано.
коммутатор (config-router-isis-sr-mpls) # показать сегментную маршрутизацию isis
! IS-IS (Экземпляр: inst1) Маршрутизация сегментов отключена административно показать глобальные блоки сегментной маршрутизации isis
Команда show isis segment-routing global-blocks выводит список SRGB в использование всеми поддерживающими SR устройствами в домене IS-IS, включая SRGB используется IS-IS SR на этом устройстве.
Пример
коммутатор # показать глобальные блоки сегментной маршрутизации isis
Идентификатор системы: 1111.1111.1002 Экземпляр: inst1
Поддерживаемый SR Data-plane: MPLSSR Идентификатор маршрутизатора: 252.252.2.252
SR Global Block (SRGB): База: 0 Размер: 65536
Количество одноранговых узлов, поддерживающих маршрутизацию сегментов ISIS: 3
SystemId Базовый размер
-------------------- ------------ -----
1111.1111.1002
065536
1111.1111.1001 065536
показать сегменты префикса маршрутизации сегментов isis
Команда show isis segment-routing prefix-segment предоставляет подробные сведения обо всех сегментах префикса, а также сегменты получено от носителей IS-IS SR в домене.
Пример
коммутатор # показать сегменты префикса сегментной маршрутизации isis
Идентификатор системы: 1111.1111.1002 Экземпляр: inst1
Поддерживаемый SR Уровень данных: MPLS Идентификатор маршрутизатора SR: 252.252.2.252
Узел: 2 Прокси-узел: 2 Префикс: 2 Всего сегментов: 6
Описание флагов: R: повторно объявлено, N: сегмент узла, P: no-PHP
E: явное-NULL, V: значение, L: локальное
Коды статуса сегмента: * - Самостоятельный префикс, L1 - уровень 1, L2 - уровень 2
PrefixSID TypeFlagsSystemIDType
--------------------- --------- ---------------- ---- -----------------
1.0.7.1 / 322NodeR: 0 N: 1 P: 0 E: 0 V: 0 L: 0 1111.1111.1001L1
* 1.0.8.1/32 4NodeR: 0 N: 1 P: 0 E: 0 V: 0 L: 0 1111.1111.1002L2
1.0.11.0/24 10 Префикс R: 1 N: 0 P: 0 E: 0 V: 0 L: 0 1111.1111.1001L2
* 1.0.12.0/2412 Префикс R: 1 N: 0 P: 0 E: 0 V: 0 L: 0 1111.1111.1002L2
1.0.15.1/32 18 Прокси-узелR: 0 N: 0 P: 0 E: 0 V: 0 L: 0 1111.1111.1001L2
1.0.16.1/32 20 Прокси-узелR: 0 N: 0 P: 0 E: 0 V: 0 L: 0 1111.1111.1003L2 О выходе
После обычного выходного заголовка, представляющего идентификатор системы, instance имя и т. д. и параметры роутера, отображается строка с изображением счетчики префиксных сегментов.Каждое поле в этой строке относится к количество сегментов, которые присутствуют в этом экземпляре IS-IS маршрутизатора. Например, приведенный выше пример показывает, что это устройство имеет 2 узла. Сегменты (как собственные, так и полученные от других Устройства ИС-ИС СР).
Основной раздел выходных данных команды show - это раздел, в котором перечислены все сегменты префикса и соответствующая информация, такая как префикс, SID, тип сегмента (Префикс, Узел, Прокси-узел), значения флага переносится в под-TLV этих сегментов префикса и идентификаторе системы исходного маршрутизатора.Поле Тип будет полезно на ИС. типа роутер 1-2 уровня. Показывает, установлен ли установленный сегмент префикса происходит от префикса уровня 1 или префикса уровня 2.
показать ISIS сегмент-маршрутизация префикс-сегментов, созданных самостоятельно
Самостоятельно созданная команда show isis segment-routing prefix-segment вывод идентичен, чтобы показать сегменты префикса маршрутизации сегментов isis за исключением того факта, что в первом перечисляются только самодельные префиксы сегменты.
показать сегменты смежности сегментной маршрутизации isis
показывает сегменты смежности сегментной маршрутизации isis отображает список всех сегменты смежности, которые создаются IS-IS SR на роутер.
Пример
коммутатор # показать сегменты смежности сегментной маршрутизации isis
Идентификатор системы: 1111.1111.1002 Экземпляр: inst1
Поддерживаемый SR Уровень данных: MPLS Идентификатор маршрутизатора SR: 252.252.2.252
Режим распределения Adj-SID: SR-смежности
Пул распределения Adj-SID: База: 100000 Размер: 16384
Количество сегментов смежности: 4
Настроить IP-адрес Локальный IntfLabelSIDSource FlagsType
------------------------------------- ------------- ----------------
1.0.0.1Vlan2472100000DynamicF: 0 B: 0 V: 1L: 1 S: 0 LAN L2
1.0.1.2Vlan25701DynamicF: 0 B: 0 V: 1L: 1 S: 0 P2P L2
fe80 :: 1: ff: fe01: 0Vlan2472100002DynamicF: 0 B: 0 V: 1L: 1 S: 0 LAN L2
fe80 :: 1: ff: fe02: 0Vlan257
03DynamicF: 0 B: 0 V: 1L: 1 S: 0 P2P L2
О выходе
Он состоит из режима распределения, пула меток MPLS, из которого будут выделено смежности, общее количество сегментов смежности выделено до сих пор, и значения флага по умолчанию, переносимые во всех adj-SID суб-TLV, исходящие от этого устройства.
В основном разделе вывода перечислены все выделенные сегменты смежности. до сих пор в шести столбцах, каждый из которых относится к IP-адресу смежности, локальный имя интерфейса, значение метки MPLS, источник SID, флаги в суб-TLV и тип adj-SID соответственно.Тип смежности сегментов зависит от типа смежности IS-IS и IS уровень.
показать диапазоны этикеток mpls
Команда show mpls label range отображает диапазон меток MPLS. доступный на маршрутизаторе, подразделяется на разные пулы, которые обслуживать различные приложения, работающие на маршрутизаторе.
isis-sr относится к варианту использования SRGB. в IS-IS, а isis (динамический) относится к используемому пулу меток. для динамического выделения сегментов смежности в IS-IS.
Пример
переключатель # показать диапазоны этикеток mpls
StartEndSize Использование
-----------------------------------------
015 16 зарезервировано
16 9999999984 статических мплс
100000 116383 16384isis (динамический)
116384 362143 245760 бесплатно (динамический)
362144 899999 537856 не назначен
0 965535 65536isis-sr
показать привязки сегментной маршрутизации mpls
Команда show mpls segment-routing bindings отображает локальную метку привязки и привязки меток на одноранговых маршрутизаторах для каждого префикса, который рекламируется сегмент.Peer ID здесь представляет систему IS-IS. ID однорангового узла.
Пример
коммутатор # показать привязки сегментной маршрутизации mpls
1.0.7.1/32
Локальная привязка: Этикетка: 2
Удаленная привязка: идентификатор узла: 1111.1111.1001, метка: imp-null
Удаленная привязка: идентификатор узла: 1111.1111.1003, метка:
2
1.0.8.1/32
Локальная привязка: Метка: imp-null
Удаленная привязка: идентификатор узла: 1111.1111.1001, метка: 4
Удаленная привязка: идентификатор узла: 1111.1111.1003, метка:
4
1.0.9.1/32
Локальная привязка: Этикетка: 6
Удаленная привязка: Peer ID: 1111.1111.1001, Этикетка:
6
Удаленная привязка: идентификатор узла: 1111.1111.1003, метка: imp-null
показать mpls lfib route
Команда show mpls lfib route отображает LFIB. Каждая запись LFIB имеет In-Label, Out-Label, метрика, тип полезной нагрузки, информация о следующем магазине и т. Д. поля. Столбец источника отображает протокол уровня управления MPLS. который отвечает за связывание метки, которое привело к этому LFIB маршрут.
Пример
switch # показать mpls lfib route
Таблица пересылки MPLS (метка [метрика] Vias) - 7 маршрутов
Разрешение следующего перехода MPLS разрешает маршрут по умолчанию: False
Коды типов переходов:
M - Mpls Via, P - Pseudowire Via,
I - IP Lookup Via, V - Vlan Via,
VA - EVPN Vlan Aware Via, ES - EVPN Ethernet-сегмент,
VF - EVPN Vlan Flood Via, AF - EVPN Vlan Aware Flood Via,
NG - Nexthop Group Via
Исходные коды:
S - статический маршрут MPLS, B2 - BGP L2 EVPN,
B3 - BGP L3 VPN, R - RSVP,
P - псевдопровод, L - LDP,
IP - сегмент префикса IS-IS SR, IA - сегмент смежности IS-IS SR,
IL - сегмент IS-IS SR в LDP, LI - LDP в сегмент IS-IS SR,
BL - BGP LU, ST - SR TE Policy,
DE - Отладка LFIB
IA 100000 [1]
через М, 1.0.1.2, поп
полезная нагрузка autoDecide, униформа ttlMode, применить egress-acl
интерфейс Vlan2930
IA 100001 [1]
через M, fe80 :: 200: eff: fe02: 0, pop
полезная нагрузка autoDecide, униформа ttlMode, применить egress-acl
интерфейс Vlan2930
IP 8 [1]
через M, 1.0.1.2, своп
8
полезная нагрузка autoDecide, униформа ttlMode, применить egress-acl
интерфейс Vlan2930
IP 9 [1]
через M, fe80 :: 200: eff: fe02: 0, своп
9
полезная нагрузка autoDecide, униформа ttlMode, применить egress-acl
интерфейс Vlan2930
показать маршрут mpls lfib
<значение метки>Команда show mpls lfib route предоставляет информация, относящаяся только к значению метки, переданному как расширение к команде show.
Пример
переключатель # показать маршрут mpls lfib8
Таблица пересылки MPLS (метка [метрика] Vias) - 7 маршрутов
Разрешение следующего перехода MPLS разрешает маршрут по умолчанию: False
Коды типов переходов:
M - Mpls Via, P - Pseudowire Via,
I - IP Lookup Via, V - Vlan Via,
VA - EVPN Vlan Aware Via, ES - EVPN Ethernet-сегмент,
VF - EVPN Vlan Flood Via, AF - EVPN Vlan Aware Flood Via,
NG - Nexthop Group Via
Исходные коды:
S - статический маршрут MPLS, B2 - BGP L2 EVPN,
B3 - BGP L3 VPN, R - RSVP,
P - псевдопровод, L - LDP,
IP - сегмент префикса IS-IS SR, IA - сегмент смежности IS-IS SR,
IL - сегмент IS-IS SR в LDP, LI - LDP в сегмент IS-IS SR,
BL - BGP LU, ST - SR TE Policy,
DE - Отладка LFIB
IP8 [1]
через М, 1.